Überlegungen zur Feldzuordnung für StandardDataflows
Wenn Sie Daten in Dataverse-Tabellen laden, ordnen Sie die Spalten der Quellabfrage in der Bearbeitungsumgebung des Dataflows den Spalten der Dataverse-Zieltabelle zu. Neben der Zuordnung von Daten gibt es noch weitere Überlegungen und bewährte Verfahren zu berücksichtigen. In diesem Artikel werden die verschiedenen Datafloweinstellungen behandelt, die das Verhalten der Dataflowaktualisierung und damit die Daten in der Zieltabelle steuern.
Steuerung, ob Dataflows bei jeder Aktualisierung Datensätze erstellen oder hochladen
Jedes Mal, wenn Sie einen Dataflow aktualisieren, werden Datensätze aus der Quelle geholt und in Dataverse geladen. Wenn Sie den Dataflow mehr als einmal ausführen - je nachdem, wie Sie den Dataflow konfigurieren - können Sie dies tun:
- Erstellen Sie bei jeder Dataflowaktualisierung neue Datensätze, auch wenn solche Datensätze bereits in der Zieltabelle vorhanden sind.
- Erstellen Sie neue Datensätze, wenn sie noch nicht in der Tabelle vorhanden sind, oder aktualisieren Sie vorhandene Datensätze, wenn sie bereits in der Tabelle vorhanden sind. Dieses Verhalten wird Upsertgenannt.
Die Verwendung einer Schlüsselspalte weist den Dataflow darauf hin, dass Datensätze in die Zieltabelle eingefügt werden sollen, während die Nichtauswahl eines Schlüssels bedeutet, dass der Datenflow neue Datensätze in der Zieltabelle erstellen soll.
Eine Schlüsselspalte ist eine Spalte, die eindeutig und deterministisch für eine Datenzeile in der Tabelle ist. Wenn zum Beispiel in einer Tabelle Bestellungen die Bestell-ID eine Schlüsselspalte ist, sollten Sie nicht zwei Zeilen mit der gleichen Bestell-ID haben. Außerdem sollte eine Auftragskennung, z. B. ein Auftrag mit der Kennung 345, nur eine Zeile in der Tabelle darstellen. Um die Schlüsselspalte für die Tabelle in Dataverse aus dem Dataflow auszuwählen, müssen Sie das Schlüsselfeld in der Erfahrung Map Tables festlegen.
Auswahl eines Primärnamens und eines Schlüsselfelds beim Erstellen einer neuen Tabelle
Das folgende Bild zeigt, wie Sie die Schlüsselspalte auswählen können, die aus der Quelle gefüllt werden soll, wenn Sie eine neue Tabelle im Dataflow erstellen.
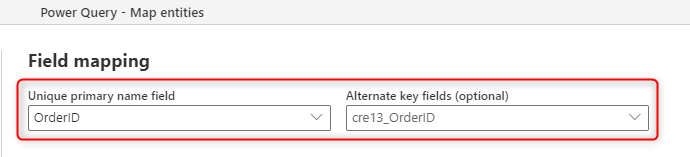
Das primäre Namensfeld, das Sie in der Feldzuordnung sehen, ist für ein Bezeichnungsfeld gedacht, und dieses Feld muss nicht eindeutig sein. Das Feld, das in der Tabelle zur Überprüfung der Duplikation verwendet wird, ist das Feld, das Sie im Feld Alternate Key eingestellt haben.
Mit einem Primärschlüssel in der Tabelle wird sichergestellt, dass selbst bei doppelten Daten in dem Feld, das dem Primärschlüssel zugeordnet ist, die doppelten Einträge nicht in die Tabelle geladen werden. Dieses Verhalten gewährleistet eine hohe Qualität der Daten in der Tabelle. Qualitativ hochwertige Daten sind für die Erstellung von Berichtslösungen auf der Grundlage der Tabelle unerlässlich.
Das Feld für den Primärnamen
Das primäre Namensfeld ist ein in Dataverse verwendetes Anzeigefeld. Dieses Feld wird in Standardansichten verwendet, um den Inhalt der Tabelle in anderen Anwendungen anzuzeigen. Dieses Feld ist nicht das Primärschlüsselfeld und sollte auch nicht als solches betrachtet werden. Dieses Feld kann doppelte Werte enthalten, da es ein Anzeigefeld ist. Am besten ist es jedoch, ein verkettetes Feld zu verwenden, das dem primären Namensfeld zugeordnet wird, so dass der Name vollständig erklärend ist.
Das Feld für den alternativen Schlüssel wird als Primärschlüssel verwendet.
Auswahl eines Schlüsselfeldes beim Laden in eine bestehende Tabelle
Wenn Sie eine Dataflowabfrage auf eine bestehende Dataverse-Tabelle abbilden, können Sie wählen, ob und welcher Schlüssel beim Laden der Daten in die Zieltabelle verwendet werden soll.
Das folgende Bild zeigt, wie Sie die Schlüsselspalte auswählen können, die beim Einfügen von Datensätzen in eine bestehende Dataverse-Tabelle verwendet werden soll:

Festlegen der eindeutigen ID-Spalte einer Tabelle und Verwendung dieser Spalte als Schlüsselfeld für das Einfügen von Datensätzen in bestehende Dataverse-Tabellen
Alle Microsoft Dataverse-Tabellenzeilen besitzen eindeutige Bezeichner, die als GUIDs definiert werden. Diese GUIDs sind der Primärschlüssel für jede Tabelle. Standardmäßig kann der Primärschlüssel einer Tabelle nicht durch Dataflows gesetzt werden, sondern wird von Dataverse automatisch generiert, wenn ein Datensatz erstellt wird. Es gibt fortgeschrittene Anwendungsfälle, in denen die Nutzung des Primärschlüssels einer Tabelle wünschenswert ist, z. B. bei der Integration von Daten aus externen Quellen, wobei dieselben Primärschlüsselwerte sowohl in der externen Tabelle als auch in der Dataverse-Tabelle beibehalten werden.
Hinweis
- Diese Funktion ist nur beim Laden von Daten in bestehende Tabellen verfügbar.
- Das Feld für den eindeutigen Bezeichner akzeptiert nur eine Zeichenkette mit GUID-Werten; jeder andere Datentyp oder Wert führt dazu, dass die Datensatzerstellung fehlschlägt.
Um das eindeutige Bezeichnerfeld einer Tabelle zu nutzen, wählen Sie Load to existing table auf der Seite Map Tables , während Sie einen Dataflow erstellen. In dem in der folgenden Abbildung dargestellten Beispiel werden Daten in die Tabelle CustomerTransactions geladen und die Spalte TransactionID aus der Datenquelle als eindeutiger Bezeichner der Tabelle verwendet.
Sie sehen, dass in der Dropdown-Liste Schlüssel auswählen der eindeutige Bezeichner - der immer „Tabellenname + id“ heißt - der Tabelle ausgewählt werden kann. Da der Tabellenname „CustomerTransactions“ lautet, wird das eindeutige Bezeichnerfeld „CustomerTransactionId“ genannt.

Nach der Auswahl wird der Abschnitt für die Spaltenzuordnung aktualisiert, um den eindeutigen Bezeichner als Zielspalte aufzunehmen. Sie können dann die Quellspalte zuordnen, die den eindeutigen Bezeichner für jeden Datensatz darstellt.

Was sind gute Kandidaten für das Schlüsselfeld?
Das Schlüsselfeld ist ein eindeutiger Wert, der eine eindeutige Zeile in der Tabelle darstellt. Dieses Feld ist wichtig, denn es hilft Ihnen, doppelte Datensätze in der Tabelle zu vermeiden. Dieses Feld kann aus drei Quellen stammen:
Der Primärschlüssel im Quellsystem (z. B. OrderID im obigen Beispiel). Verkettetes Feld, das durch Power Query-Transformationen im Dataflow erstellt wurde.
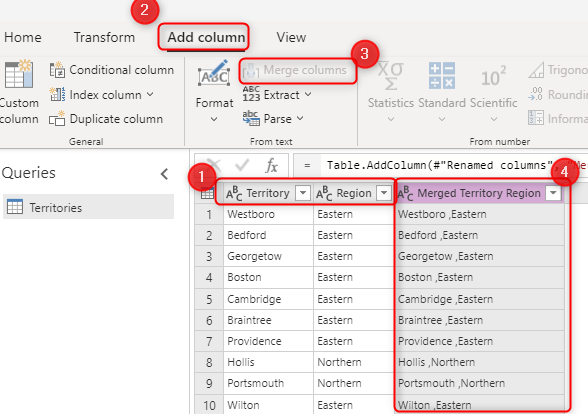
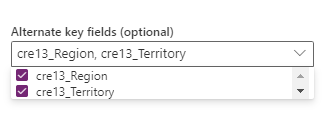
Eine Kombination von Feldern, die in der Option Alternativschlüssel auszuwählen ist. Eine Kombination von Feldern, die als Schlüsselfeld verwendet wird, wird auch als zusammengesetzter Schlüsselbezeichnet.
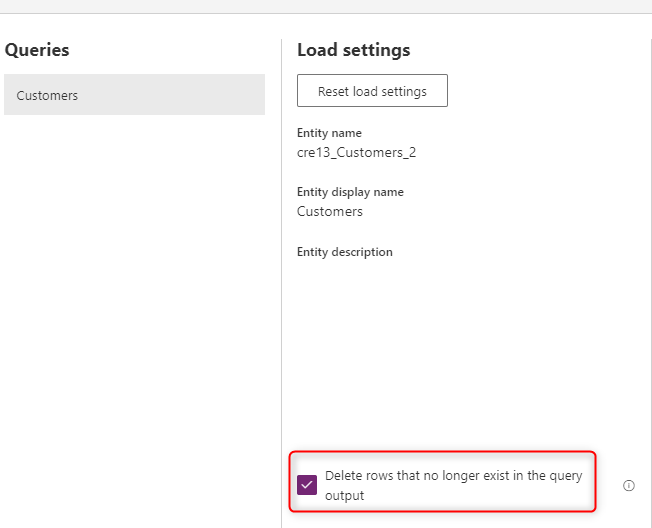
Zeilen entfernen, die nicht mehr existieren
Wenn Sie möchten, dass die Daten in Ihrer Tabelle immer mit den Daten aus dem Quellsystem synchronisiert werden, wählen Sie die Option Zeilen löschen, die in der Abfrageausgabe nicht mehr vorhanden sind. Diese Option verlangsamt jedoch den Dataflow, da ein Zeilenvergleich auf der Grundlage des Primärschlüssels (alternativer Schlüssel in der Feldzuordnung des Dataflows) erforderlich ist, damit diese Aktion durchgeführt werden kann.
Diese Option bedeutet, dass eine Datenzeile in der Tabelle, die in der Abfrageausgabe der nächsten Dataflowaktualisierung nicht vorhanden ist, aus der Tabelle entfernt wird.
Hinweis
Standard-V2-Dataflows stützen sich auf die Felder createdon und modifiedon, um Zeilen, die in der Ausgabe des Dataflows nicht vorhanden sind, aus der Zieltabelle zu entfernen. Wenn diese Spalten in der Zieltabelle nicht vorhanden sind, werden die Datensätze nicht gelöscht.
Bekannte Einschränkungen
- Die Zuordnung zu den Feldern polymorphic lookup wird derzeit nicht unterstützt.
- Die Zuordnung zu einem mehrstufigen Nachschlagefeld, d. h. einem Nachschlagefeld, das auf ein Nachschlagefeld einer anderen Tabelle verweist, wird derzeit nicht unterstützt.
- Die Zuordnung zu den Feldern Status und Statusgrund wird derzeit nicht unterstützt.
- Das Mappen von Daten in mehrzeiligen Text, der Zeilenumbrüche enthält, wird nicht unterstützt und die Zeilenumbrüche werden entfernt. Stattdessen könnten Sie das Zeilenumbruch-Tag
<br>verwenden, um mehrzeiligen Text zu laden und zu erhalten. - Zuordnung zu Auswahlfeldern, die mit aktivierter Mehrfachauswahloption konfiguriert sind, werden nur unter bestimmten Bedingungen unterstützt. Der Dataflow lädt nur Daten in die Auswahlfelder, wenn die Option Mehrfachauswahl aktiviert ist und eine durch Kommata getrennte Liste von Werten (ganze Zahlen) für die Bezeichnungen verwendet wird. Wenn die Beschriftungen beispielsweise „Wahl1, Wahl2, Wahl3“ mit den entsprechenden ganzzahligen Werten „1, 2, 3“ lauten, sollten die Spaltenwerte „1,3“ lauten, um die erste und die letzte Wahlmöglichkeit auszuwählen.
- Standard-V2-Dataflows stützen sich auf die Felder
createdonundmodifiedon, um Zeilen, die in der Ausgabe des Dataflows nicht vorhanden sind, aus der Zieltabelle zu entfernen. Wenn diese Spalten in der Zieltabelle nicht vorhanden sind, werden die Datensätze nicht gelöscht. - Die Zuordnung zu Feldern, deren Eigenschaft IsValidForCreate auf
falseeingestellt ist, wird nicht unterstützt (z. B. das Feld „Konto“ der Entität „Kontakt“).