Leitfaden für zusammengesetzte Modelle in Power BI Desktop
Dieser Artikel richtet sich an Datenmodellierer, die Power BI-Verbundmodelle entwickeln. Er beschreibt Anwendungsfälle zusammengesetzter Modelle und bietet Ratschläge für das Design. In erster Linie hilft Ihnen dieser Leitfaden festzustellen, ob ein zusammengesetztes Modell für Ihre Lösung geeignet ist. Wenn dies der Fall ist, hilft Ihnen dieser Artikel auch beim Design optimaler Modelle und Berichte.
Hinweis
Dieser Artikel ist keine Einführung in zusammengesetzte Modelle. Wenn Sie nicht vollständig mit zusammengesetzten Modellen vertraut sind, sollten Sie zunächst den Artikel Verwenden zusammengesetzter Modelle in Power BI Desktop lesen.
Da zusammengesetzte Modelle aus mindestens einer DirectQuery-Quelle bestehen, sollten Sie auch mit Modellbeziehungen, DirectQuery-Modellen und dem Designleitfaden für DirectQuery-Modelle vertraut sein.
Anwendungsfälle für zusammengesetzte Modelle
Per Definition kombiniert ein zusammengesetztes Modell mehrere Quellgruppen. Bei einer Quellgruppe kann es sich um importierte Daten oder eine Verbindung mit einer DirectQuery-Quelle handeln. Eine DirectQuery-Quelle kann entweder eine relationale Datenbank oder ein anderes tabellarisches Modell sein, bei dem es sich um ein Power BI-Semantikmodell oder ein tabellarisches Analysis Services-Modell handeln kann. Ein tabellarisches Modell, das mit einem anderen tabellarischen Modell verknüpft ist, wird als Verkettung bezeichnet. Weitere Informationen finden Sie unter Verwenden von zusammengesetzten Modellen in Power BI Desktop.
Hinweis
Wenn ein Modell mit einem tabellarischen Modell verknüpft ist, das die ursprünglichen Modelldaten jedoch nicht erweitert, handelt es sich um kein zusammengesetztes Modell. Es ist lediglich ein DirectQuery-Modell, das mit einem Remotemodell verknüpft ist – tatsächlich also nur eine Quellgruppe umfasst. Sie können diesen Modelltyp erstellen, um die Eigenschaften des Quellmodellobjekts zu ändern, wie zum Beispiel den Tabellennamen, die Sortierreihenfolge der Spalten, die Formatzeichenfolge oder andere.
Eine Verknüpfung mit tabellarischen Modellen bietet sich besonders dann an, wenn ein semantisches Unternehmensmodell, bei dem es sich um ein Power BI-Semantikmodell oder ein Analysis Services-Modell handelt, erweitert werden soll. Ein semantisches Unternehmensmodell ist für das Design und den Betrieb eines Data Warehouse von grundlegender Bedeutung. Es stellt zur Darstellung von Geschäftsdefinitionen und Terminologie eine Abstraktionsebene für die Daten im Data Warehouse bereit. Häufig wird es als Bindeglied zwischen physischen Datenmodellen und Berichterstellungstools wie Power BI verwendet. In den meisten Organisationen wird es von einem zentralen Team verwaltet, weshalb es auch als Unternehmensmodell bezeichnet wird. Weitere Informationen finden Sie im Nutzungsszenario zu Enterprise BI.
Sie können die Entwicklung eines zusammengesetzten Modells in den folgenden Situationen in Betracht ziehen:
- Sie haben bereits ein DirectQuery-Modell, dessen Leistung Sie verbessern möchten. In einem zusammengesetzten Modell können Sie die Leistung verbessern, indem Sie für jede Tabelle geeigneten Speicher einrichten. Sie können auch benutzerdefinierte Aggregationen hinzufügen. Beide Optimierungen werden weiter unten in diesem Artikel näher erläutert.
- Sie möchten ein DirectQuery-Modell durch zusätzliche Daten erweitern, die in das Modell importiert werden müssen. Die importierten Daten können Sie aus einer anderen Datenquelle oder aus berechneten Tabellen laden.
- Sie möchten zwei oder mehr DirectQuery-Datenquellen in einem einzelnen Modell kombinieren. Bei diesen Quellen kann es sich um relationale Datenbanken oder andere tabellarische Modelle handeln.
Hinweis
Zu einigen externen Analysedatenbanken können zusammengesetzte Modelle keine Verknüpfungen herstellen. Zu diesen Datenbanken zählen unter anderem SAP Business Warehouse und SAP HANA, sofern SAP HANA als multidimensionale Quelle behandelt wird.
Auswerten anderer möglicher Modelldesigns
Zusammengesetzte Power BI-Modelle können zwar bestimmte Designprobleme lösen, jedoch auch die Leistung beeinträchtigen. In einigen Situationen, die weiter unten in diesem Artikel beschrieben werden, sind auch unerwartete Berechnungsergebnisse bekannt. Aus diesen Gründen sollten Sie für Ihre Lösung auch andere mögliche Modelldesigns auswerten.
Wenn möglich, sollten Sie ein Modell im Importmodus entwickeln. Er bietet größtmögliche Flexibilität für Entwürfe und die beste Leistung. Allerdings können Herausforderungen, die im Zusammenhang mit großen Datenmengen oder der Berichterstellung bei Quasi-Echtzeitdaten stehen, nicht immer durch Importmodelle gelöst werden. In diesen Fällen würde sich ein DirectQuery-Modell anbieten, vorausgesetzt, Ihre Daten sind in einer einzelnen Datenquelle gespeichert, die vom DirectQuery-Modus unterstützt wird. Weitere Informationen finden Sie unter DirectQuery-Modelle in Power BI Desktop.
Tipp
Wenn Ihr Ziel allein darin besteht, ein vorhandenes tabellarisches Modell durch weitere Daten zu erweitern, sollten Sie diese Daten nach Möglichkeit der vorhandenen Datenquelle hinzufügen.
Tabellenspeichermodus
In einem zusammengesetzten Modell können Sie den Speichermodus jeder Tabelle (mit Ausnahme berechneter Tabellen) konfigurieren.
- DirectQuery-: Es wird empfohlen, diesen Modus für Tabellen festzulegen, die große Datenvolumes darstellen oder nahezu Echtzeitergebnisse liefern müssen. Daten werden nie in diese Tabellen importiert. In der Regel werden diese Tabellen zu Faktentabellen, also zusammengefasste Tabellen.
- Import: Dieser Modus empfiehlt sich für Tabellen, die nicht zum Filtern und Gruppieren von Faktentabellen im DirectQuery- oder Hybridmodus verwendet werden. Dieser Modus ist außerdem die einzige Option für Tabellen, die auf Quellen basieren, die nicht vom DirectQuery-Modus unterstützt werden. Bei berechneten Tabellen handelt es sich immer um Importtabellen.
- Dual: Diesen Modus sollten Sie für Tabellen des Typs Dimension verwenden, wenn die Chance besteht, dass sie zusammen mit DirectQuery-Faktentabellen aus derselben Quelle abgefragt werden.
- Hybrid-: Es wird empfohlen, diesen Modus festzulegen, indem Sie Importpartitionen und eine DirectQuery-Partition zu einer Faktentabelle hinzufügen, wenn Sie die neuesten Datenänderungen in Echtzeit einschließen möchten oder wenn Sie schnellen Zugriff auf die am häufigsten verwendeten Daten über Importpartitionen bereitstellen möchten, während sie den Großteil seltener verwendeter Daten im Data Warehouse verlassen.
Beim Abfragen eines zusammengesetzten Modells durch Power BI sind mehrere Szenarios denkbar:
- Es werden nur Import- oder Dualtabellen abgefragt: Power BI ruft alle Daten aus dem Modellcache ab. Dadurch wird die schnellstmögliche Leistung erzielt. Dieses Szenario kommt häufig bei Tabellen des Typs „Dimension“ vor, die mit Filtern oder Datenschnittvisuals abgefragt werden.
- Es werden nur Dual- oder DirectQuery-Tabellen abgefragt, die aus derselben Quelle stammen: Power BI ruft alle Daten durch eine oder mehrere native Abfragen an die DirectQuery-Quelle ab. Dadurch wird eine gute Leistung erzielt, insbesondere wenn in den Quelltabellen geeignete Indizes vorhanden sind. Dieses Szenario ist üblich für Abfragen, die Tabellen mit doppelter Dimension und DirectQuery-Faktentabellen verknüpfen. Diese Abfragen sind quellgruppenintern, d. h., dass alle 1:1- oder 1:n-Beziehungen als reguläre Beziehungen bewertet werden.
- Es werden nur Dual- oder Hybridtabellen abgefragt, die aus derselben Quelle stammen: Dies ist eine Kombination der beiden vorherigen Szenarien. Power BI ruft die Daten aus dem Modellcache ab, sofern sie in Importpartitionen verfügbar sind. Andernfalls sendet Power BI eine oder mehrere native Abfragen an die DirectQuery-Quelle. Dies bietet die schnellstmögliche Leistung, da nur ein Slice der Daten im Data Warehouse abgefragt wird, vor allem dann, wenn geeignete Indizes für die Quelltabellen vorhanden sind. Wie bei dualen Dimensionstabellen und DirectQuery-Tabellen erfolgen diese Abfragen innerhalb der Quellgruppe, so dass alle 1:1- oder 1:n-Beziehungen als reguläre Beziehungen ausgewertet werden.
- Alle anderen Abfragen: Diese Abfragen umfassen quellgruppenübergreifende Beziehungen. Dies liegt darin begründet, dass eine Importtabelle mit einer DirectQuery-Tabelle oder eine Dualtabelle mit einer DirectQuery-Tabelle aus einer anderen Quelle verknüpft ist und sich die Ausgangstabelle deshalb wie eine Importtabelle verhält. Alle Beziehungen werden als beschränkte Beziehungen bewertet. Das bedeutet auch, dass Gruppierungen, die auf Nicht-DirectQuery-Tabellen angewendet werden, als materialisierte Unterabfragen (virtuelle Tabellen) an die DirectQuery-Quelle gesendet werden müssen. In diesem Fall kann die native Abfrage ineffizient sein, insbesondere bei großen Gruppierungssätzen.
Zusammenfassend empfiehlt sich Folgendes:
- Überlegen Sie gut, ob ein zusammengesetztes Modell die richtige Lösung für Sie ist. Es erlaubt zwar die Integration verschiedener Datenquellen auf Modellebene, gestaltet das Design aber auch komplexer. Die Konsequenzen werden weiter unten in diesem Artikel beschrieben.
- Legen Sie den Speichermodus auf DirectQuery- fest, wenn es sich bei einer Tabelle um eine Faktentabelle handelt, die große Datenvolumes speichert oder wenn sie nahezu Echtzeitergebnisse liefern muss.
- Erwägen Sie die Verwendung des Hybridmodus, indem Sie eine Richtlinie für die inkrementelle Aktualisierung und Echtzeitdaten definieren oder die Faktentabelle mit TOM, TMSL oder dem Tool eines Drittanbieters partitionieren. Weitere Informationen finden Sie unter Inkrementelle Aktualisierung und Echtzeitdaten für semantische Modelle sowie im Nutzungsszenario Erweiterte Datenmodellverwaltung.
- Legen Sie den Speichermodus auf Dual fest, wenn eine Tabelle als Dimensionstabelle dient; sie wird dann zusammen mit DirectQuery- oder Hybrid-Faktentabellen, die sich in derselben Quellgruppe befinden, angefragt.
- Stellen Sie das Aktualisierungsintervall so ein, dass der Modellcache für Dual- und hybride Tabellen (und für alle abhängigen berechneten Tabellen) mit den Quelldatenbanken synchron gehalten wird.
- Bemühen Sie sich um quellgruppenübergreifende Datenintegrität (auch im Modellcache), denn wenn in beschränkten Beziehungen verknüpfte Spaltenwerte nicht übereinstimmen, können in den Abfrageergebnissen Reihen verloren gehen.
- Optimieren Sie DirectQuery-Datenquellen wenn möglich mit geeigneten Indizes für effiziente Joins, Filter, Gruppierungen.
Benutzerdefinierte Aggregationen
DirectQuery-Tabellen können Sie benutzerdefinierte Aggregationen hinzufügen. Deren Zweck besteht darin, die Leistung bei Abfragen mit höherer Granularität zu verbessern.
Aggregationen, die im Modell zwischengespeichert werden, verhalten sich wie Importtabellen, können aber nicht wie Modelltabellen verwendet werden. Wenn Sie einem DirectQuery-Modell Importaggregationen hinzufügen, erhalten Sie ein zusammengesetztes Modell.
Hinweis
Hybridtabellen unterstützen keine Aggregationen, da einige der Partitionen im Importmodus ausgeführt werden. Aggregationen können nicht auf der Ebene einer einzelnen DirectQuery-Partition hinzugefügt werden.
Für Aggregationen gilt folgende Grundregel: Die Anzahl ihrer Zeilen sollte mindestens um den Faktor 10 kleiner sein als die Zeilenanzahl der zugrunde liegenden Tabelle. Wenn die zugrunde liegende Tabelle z. B. 1 Milliarde Zeilen hat, sollte die Aggregationstabelle nicht länger als 100 Millionen Zeilen sein. Wenn Sie sich an diese Regel halten, erhalten Sie im Gegenzug für die Erstellungs- und Verwaltungskosten einer Aggregationstabelle auch eine angemessene Leistungssteigerung.
quellgruppenübergreifende Beziehungen
Wenn eine Modellbeziehung Quellgruppen umfasst, wird sie als quellgruppenübergreifende Beziehung bezeichnet. Auch bei quellgruppenübergreifenden Beziehungen handelt es sich um eingeschränkte Beziehungen, da es keine garantierte „Eins“-Seite gibt. Weitere Informationen finden Sie im Abschnitt Bewertung von Beziehungen.
Hinweis
In einigen Situationen lassen sich quellgruppenübergreifende Beziehungen vermeiden. Lesen Sie hierzu auch die Informationen im Abschnitt Verwenden von Synchronisierungsslicern weiter unten in diesem Artikel.
Beachten Sie beim Definieren von quellgruppenübergreifenden Beziehungen die folgenden Empfehlungen.
- Verwenden Sie Beziehungsspalten mit niedriger Kardinalität: Für eine optimale Leistung sollten Beziehungsspalten eine niedrige Kardinalität aufweisen, d. h. weniger als 50.000 eindeutige Werte speichern. Diese Empfehlung gilt insbesondere bei einer Kombination tabellarischer Modelle sowie bei Nicht-Text-Spalten.
- Vermeiden Sie in Beziehungen große Textspalten: Wenn Sie Textspalten in einer Beziehung verwenden müssen, berechnen Sie die erwartete Textlänge für den Filter, indem Sie die Kardinalität mit der durchschnittlichen Länge der Textspalte multiplizieren. Die maximal mögliche Textlänge sollte 1.000.000 Zeichen nicht überschreiten.
- Erhöhen Sie die Granularität der Beziehung: Erstellen Sie nach Möglichkeit Beziehungen auf einer höheren Granularitätsebene. Ordnen Sie beispielsweise eine Datumstabelle nicht ihrem Datumsschlüssel zu, sondern verwenden Sie stattdessen den Monatsschlüssel. Dieser Designansatz setzt voraus, dass die verknüpfte Tabelle eine Spalte mit dem Monatsschlüssel enthält und die Berichte keine täglichen Fakten abrufen.
- Bemühen Sie sich, ein einfaches Beziehungsdesignzu erreichen: Erstellen Sie nur bei Bedarf eine quellübergreifende Gruppenbeziehung, und versuchen Sie, die Anzahl der Tabellen im Beziehungspfad einzuschränken. Dieser Designansatz trägt zur Verbesserung der Leistung und zur Vermeidung mehrdeutiger Beziehungspfade bei.
Warnung
Da Power BI Desktop quellenübergreifende Gruppenbeziehungen nicht bis ins Detail überprüft, ist es möglich, mehrdeutige Beziehungen zu erstellen.
Szenario 1 für quellgruppenübergreifende Beziehungen
Nachfolgend finden Sie die Beschreibung eines Szenarios mit einem komplexen Beziehungsdesign, das unterschiedliche, aber dennoch gültige Ergebnisse zurückgeben kann.
In diesem Szenario weist die Region-Tabelle in der Quellgruppe A eine Beziehung zur Date- und Sales-Tabelle in der Quellgruppe Bauf. Die Beziehung zwischen der Region Tabelle und der Date Tabelle ist aktiv, während die Beziehung zwischen der Region Tabelle und der Sales Tabelle inaktiv ist. Außerdem gibt es eine aktive Beziehung zwischen der Region Tabelle und der Sales Tabelle, die beide in der Quellgruppe Bsind. Die Sales Tabelle enthält ein Maß namens TotalSales, und die Region Tabelle enthält zwei Maße namens RegionalSales und RegionalSalesDirect.
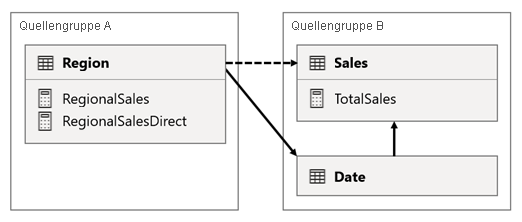
Die Measures sind wie folgt definiert.
TotalSales = SUM(Sales[Sales])
RegionalSales = CALCULATE([TotalSales], USERELATIONSHIP(Region[RegionID], Sales[RegionID]))
RegionalSalesDirect = CALCULATE(SUM(Sales[Sales]), USERELATIONSHIP(Region[RegionID], Sales[RegionID]))
Beachten Sie, wie sich das RegionalSales-Measure auf das TotalSales-Measure bezieht, während sich das RegionalSalesDirect-Measure nicht darauf bezieht. Stattdessen verwendet das RegionalSalesDirect-Measure den Ausdruck SUM(Sales[Sales]), was der Ausdruck des TotalSales-Measures ist.
Der Unterschied im Ergebnis ist subtil. Wenn Power BI das RegionalSales-Measure auswertet, wird der Filter aus der Region-Tabelle sowohl auf die Sales-Tabelle als auch auf die Date-Tabelle angewendet. Daher wird der Filter auch aus der Date-Tabelle auf die Sales-Tabelle übertragen. Im Gegensatz dazu wird, wenn Power BI das RegionalSalesDirect-Measure auswertet, der Filter nur von der Region-Tabelle auf die Sales-Tabelle weitergegeben. Die vom RegionalSales-Measure zurückgegebenen Ergebnisse und das RegionalSalesDirect-Measure können unterschiedlich sein, obwohl die Ausdrücke bedeutungsgleich sind.
Wichtig
Bei Verwendung der Funktion CALCULATE mit einem Ausdruck, der gleichzeitig ein Measure in einer Remotequellgruppe ist, sollten Sie die Berechnungsergebnisse daher gründlich testen.
Szenario 2 für quellgruppenübergreifende Beziehungen
Nachfolgend finden Sie die Beschreibung eines Szenarios mit einer quellgruppenübergreifenden Beziehung, deren Beziehungsspalten eine hohe Kardinalität aufweisen.
In diesem Szenario bezieht sich die Date-Tabelle auf die Sales-Tabelle in den DateKey-Spalten. Der Datentyp der DateKey-Spalten ist Ganzzahl und sie speichern ganze Zahlen, die das Format yyyymmdd verwenden. Die Tabellen gehören zu verschiedenen Quellgruppen. Darüber hinaus handelt es sich um eine Beziehung mit hoher Kardinalität, da das früheste Datum in der Date Tabelle der 1. Januar 1900 ist und das neueste Datum der 31. Dezember 2100 ist. Daher gibt es insgesamt 73.414 Zeilen in der Tabelle (eine Zeile für jedes Datum in der Zeitspanne von 1900-2100).
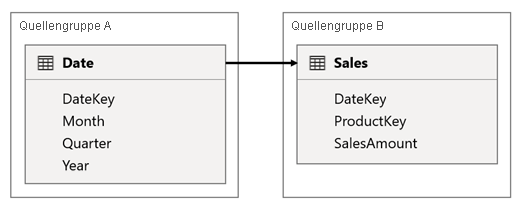
In diesem Szenario gibt es zwei Problempunkte.
Der erste Problempunkt: Wenn Sie die Spalten der TabelleDate als Filter verwenden, wird durch Filterübertragung die Spalte DateKey der Tabelle Sales ebenfalls gefiltert, um deren Measures auszuwerten. Wenn Sie nach einem einzelnen Jahr filtern, beispielsweise nach dem Jahr 2022, enthält die DAX-Abfrage einen Filterausdruck wie diesen: Sales[DateKey] IN { 20220101, 20220102, …20221231 }. Die Textgröße der Abfrage kann in diesem Fall extrem groß werden, wenn der Filterausdruck sehr viele Werte enthält oder es sich bei den Filterwerten um lange Zeichenfolgen handelt. Die Generierung und anschließende Ausführung einer solch langen Abfrage ist in punkto Ressourcenverbrauch sowohl für Power BI als auch für die Datenquelle sehr kostspielig.
Der zweite Problempunkt: Wenn Sie die Spalten der Tabelle Date – wie Year, Quarter oder Month – als Gruppierungsspalten für Filter verwenden, werden alle nur möglichen eindeutigen Kombinationen aus Jahr, Quartal oder Monat und den Werten der Spalte DateKey gebildet. Die Abfragezeichenfolge, die Filter für die Gruppierungsspalten und die Beziehungsspalte enthält, kann in einem solchen Fall extrem groß werden. Dies gilt insbesondere, wenn die Anzahl der Gruppierungsspalten und/oder die Kardinalität der Verknüpfungsspalte (Spalte DateKey) groß ist.
Leistungsprobleme lassen sich wie folgt umgehen:
- Fügen Sie der Datenquelle die
DateTabelle hinzu, was zu einem einzelnen Quellgruppenmodell führt (d. h. es ist kein zusammengesetztes Modell mehr). - Erhöhen Sie die Granularität der Beziehung. Beispielsweise können Sie beiden Tabellen die Spalte
MonthKeyhinzufügen und die Beziehung mit diesen Spalten bilden. Indem Sie jedoch die Granularität der Beziehung vergrößern, verlieren Sie die Möglichkeit, über tägliche Verkaufsaktivitäten zu berichten (es sei denn, Sie verwenden die SpalteDateKeyaus derSales-Tabelle).
Szenario 3 für quellgruppenübergreifende Beziehungen
Nachfolgend finden Sie die Beschreibung eines Szenarios mit einer quellgruppenübergreifenden Beziehung, deren Tabellen keine übereinstimmenden Werte aufweisen.
In diesem Szenario weist die Date-Tabelle in der Quellgruppe B eine Beziehung zur Sales-Tabelle in dieser Quellgruppe und auch zur Target-Tabelle in der Quellgruppe A auf. Alle Beziehungen lauten 1:n aus der Date-Tabelle, die die Year-Spalten verknüpft. Die Sales Tabelle enthält eine SalesAmount Spalte, in der Umsatzbeträge gespeichert werden, während die Target Tabelle eine TargetAmount Spalte enthält, in der Zielbeträge gespeichert werden.

In der tabelle Date werden die Jahre 2021 und 2022 gespeichert. In der tabelle Sales werden Umsatzbeträge für Die Jahre 2021 (100) und 2022 (200) gespeichert, während die Target Tabelle Zielbeträge für 2021 (100), 2022 (200), und 2023 (300)speichert – ein zukünftiges Jahr.
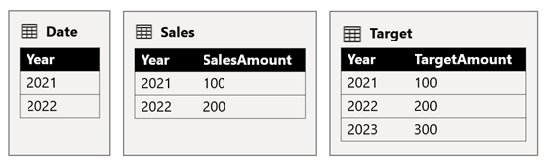
Wenn ein Tabellenvisual in Power BI das zusammengesetzte Modell durch Gruppieren der Spalte Year der Tabelle Date und Summieren der Spalten SalesAmount und TargetAmount abfragt, wird für das Jahr 2023 kein Zielbetrag zurückgegeben. Grund hierfür ist, dass es sich bei der quellgruppenübergreifenden Beziehung um eine eingeschränkte Beziehung handelt, die sich der INNER JOIN-Semantik bedient, durch die aber keine Zeilen zurückgegeben werden, die nicht auf beiden Seiten übereinstimmende Werte haben. Jedoch ergibt diese Beziehung einen korrekten Gesamtzielbetrag (600), da auf die Auswertung kein Filter angewendet wird, der sich der Tabelle Date bedient.
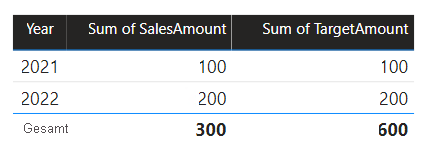
Wenn es sich bei der Beziehung zwischen der Tabelle Date und der Tabelle Target um eine quellgruppeninterne Beziehung handelt (dies unter der Voraussetzung, dass die Tabelle Target zur Quellgruppe B gehört), würde das Visual für den Zielbetrag im Jahr 2023 (und alle weiteren Jahre ohne Übereinstimmung) den Eintrag (leer) enthalten.
Wichtig
Um bei Dimensions- und Faktentabellen, die sich in unterschiedlichen Quellgruppen befinden, falsche Berichtsrückgaben zu vermeiden, sollten Sie stets sicherstellen, dass die Beziehungsspalten übereinstimmende Werte enthalten.
Weitere Informationen zu eingeschränkten Beziehungen finden Sie unter Beziehungsauswertung.
Berechnungen
Beachten Sie bei zusammengesetzten Modellen mit berechneten Spalten und Berechnungsgruppen unbedingt die in diesem Fall geltenden besonderen Einschränkungen.
Berechnete Spalten
Berechnete Spalten, die einer DirectQuery-Tabelle hinzugefügt wurden und ihre Daten aus einer relationalen Datenbank wie Microsoft SQL Server beziehen, können nur Ausdrücke verwenden, die jeweils für nur eine Zeile ausgeführt werden. Diese Ausdrücke dürfen keine DAX-Iteratorfunktionen wie SUMXoder Funktionen zur Änderung des Filterkontexts wie CALCULATE enthalten.
Hinweis
Es ist nicht möglich, berechnete Spalten oder berechnete Tabellen hinzuzufügen, die von verketteten tabellarischen Modellen abhängen.
Ein berechneter Spaltenausdruck in einer DirectQuery-Remotetabelle kann nur zeilenintern auswerten. Sie können einen solchen Ausdruck zwar erstellen, jedoch führt er in einem Visual zu einem Fehler. Wenn Sie beispielsweise eine berechnete Spalte zu einer Remote-DirectQuery-Tabelle namens DimProduct hinzufügen, indem Sie den Ausdruck [Product Sales] / SUM (DimProduct[ProductSales])verwenden, können Sie den Ausdruck erfolgreich im Modell speichern. Bei Verwendung in einem Visual kommt es jedoch aufgrund der Missachtung der Einschränkung der zeileninternen Auswertung zu einem Fehler.
Dagegen können berechnete Spalten in einer DirectQuery-Remotetabelle, bei der es sich um ein tabellarisches Modell (also ein Power BI-Semantikmodell oder ein Analysis Services-Modell) handelt, flexibler verwendet werden. In diesem Fall sind alle DAX-Funktionen möglich, da der Ausdruck innerhalb des tabellarischen Quellmodells ausgewertet wird.
Viele Ausdrücke setzen voraus, dass die berechnete Spalte vor der Verwendung oder Aggregierung als Gruppe oder Filter in Power BI materialisiert wird. Wenn eine berechnete Spalte über eine große Tabelle materialisiert wird, kann dies – in Abhängigkeit der Kardinalität der Spalten, anhand derer die Berechnung erfolgt – in Bezug auf CPU und Arbeitsspeicher äußerst kostspielig sein. Wir empfehlen in diesem Fall, berechnete Spalten dem Quellmodell hinzuzufügen.
Hinweis
Bei berechneten Spalten in einem zusammengesetzten Modell sollten Sie alle Modellberechnungen testen. Upstreamberechnungen geben möglicherweise keine korrekten Werte zurück, da ihr Einfluss auf den Filterkontext nicht berücksichtigt wird.
Berechnungsgruppen
Bei Berechnungsgruppen in einer Quellgruppe, die mit einem Power BI-Semantikmodell oder einem Analysis Services-Modell verknüpft ist, gibt Power BI möglicherweise unerwartete Ergebnisse zurück. Weitere Informationen finden Sie unter Berechnungsgruppen, Abfragen und Measureauswertung.
Modelldesign
Für optimierte Power BI-Modelle sollten Sie nach Möglichkeit ein Sternschemadesign verwenden.
Tipp
Weitere Informationen finden Sie im Artikel Informationen zum Sternschema und der Wichtigkeit für Power BI.
Erstellen Sie Dimensionstabellen getrennt von Faktentabellen, damit Power BI Verknüpfungen richtig interpretieren und effiziente Abfragepläne erstellen kann. An sich gilt diese Empfehlung für jedes Power BI-Modell, im besonderen jedoch für Modelle, die Quellgruppe eines zusammengesetzten Modells werden sollen. Ein solches Design erlaubt eine einfachere und effizientere Integration weiterer Tabellen in Downstreammodellen.
Vermeiden Sie nach Möglichkeit Dimensionstabellen in einer Quellgruppe, die sich auf eine Faktentabelle in einer anderen Quellgruppe beziehen. Denn quellgruppeninterne Beziehungen sind wesentlich einfacher zu handhaben als quellgruppenübergreifende Beziehungen, insbesondere bei Beziehungsspalten mit hoher Kardinalität. Wie zuvor beschrieben, müssen die Beziehungsspalten bei quellgruppenübergreifenden Beziehungen übereinstimmende Werte aufweisen. Andernfalls sind die Ergebnisse in Berichtsvisuals oft nicht korrekt.
Sicherheit auf Zeilenebene
Wenn Ihr Modell benutzerdefinierte Aggregationen, berechnete Spalten in Importtabellen oder berechnete Tabellen enthält, stellen Sie die ordnungsgemäße Einrichtung sowie gründliche Tests der Sicherheit auf Zeilenebene (Row-Level Security, RLS) sicher.
Wenn das zusammengesetzte Modell mit anderen tabellarischen Modellen verknüpft ist, werden RLS-Regeln nur auf die Quellgruppe, d. h. auf das lokale Modell angewendet, in dem sie definiert sind. Auf andere Quellgruppen bzw. Remotemodelle werden sie nicht angewendet. Außerdem können Sie RLS-Regeln nicht für eine Tabelle einer anderen Quellgruppe oder für eine lokale Tabelle definieren, die sich auf eine andere Quellgruppe bezieht.
Berichtsentwurf
In einigen Situationen können Sie die Leistung eines zusammengesetzten Modells durch ein optimiertes Berichtslayout verbessern.
Visuals mit nur einer Quellgruppe
Erstellen Sie nach Möglichkeit Visuals, die Felder aus nur einer Quellgruppe verwenden. Von Visuals generierte Abfragen funktionieren besser, wenn das Ergebnis aus nur einer Quellgruppe abgerufen wird. Wenn Sie Daten aus verschiedenen Quellgruppen abrufen müssen, empfiehlt es sich nach Möglichkeit, zwei Visuals nebeneinander anzuordnen – eines für jede Quellgruppe.
Verwenden von Synchronisierungsslicern
In einigen Situationen können Sie quellgruppenübergreifende Beziehungen in Modellen durch Synchronisierungsslicer umgehen. Dadurch lassen sich Quellgruppen bei verbesserter Leistung visuell kombinieren.
Betrachten wir hierzu ein Szenario, in dem das Modell zwei Quellgruppen aufweist. Jede Quellgruppe verfügt über eine Produkttabelle des Typs „Dimension“, die zum Filtern von Reseller- und Internetverkäufen verwendet wird.
In diesem Szenario enthält die Quellgruppe A die Product Tabelle, die mit der ResellerSales Tabelle verknüpft ist. Die Quellgruppe B enthält die Product2 Tabelle, die mit der InternetSales Tabelle verknüpft ist. In diesem Szenario gibt es keine quellgruppenübergreifenden Beziehungen.
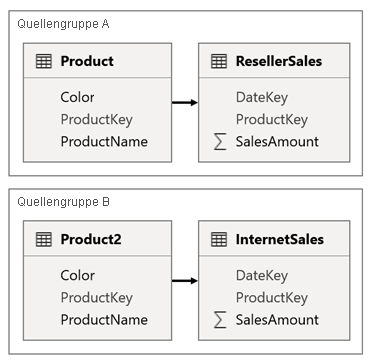
Im Bericht fügen Sie einen Slicer hinzu, der die Seite anhand der Spalte Color der Tabelle Product filtert. Standardmäßig filtert der Slicer die ResellerSales-Tabelle, aber nicht die InternetSales-Tabelle. Danach fügen Sie einen ausgeblendeten Slicer hinzu, für den Sie die Spalte Color der Tabelle Product2 verwenden. Wenn Sie nun in den Erweiterten Optionen der Synchronisierungsslicer einen identischen Gruppennamen konfigurieren, werden Filter, die auf den sichtbaren Slicer angewendet werden, automatisch auch auf den ausgeblendeten Slicer übertragen.
Hinweis
Mit Synchronisierungsslicern lassen sich zwar quellgruppenübergreifende Beziehungen vermeiden, allerdings wird das Modelldesign dadurch komplexer. Sie sollten andere Benutzer daher unbedingt darüber informieren, weshalb die Dimensionstabelle im Modell gedoppelt ist. Wir raten davon ab, Dimensionstabellen, die von anderen Benutzern nicht verwendet werden sollen, auszublenden, denn dadurch schaffen Sie nur Verwirrung. Wenn sich dies nicht vermeiden lässt, können Sie ausgeblendeten Tabellen auch einen beschreibenden Text hinzufügen, der den Zweck der Tabelle dokumentiert.
Weitere Informationen finden Sie unter Synchronisieren separater Slicer.
Weitere Empfehlungen
Hier finden Sie weitere Tipps und Empfehlungen zum Design und zur Verwaltung zusammengesetzter Modelle.
- Leistung und Skalierung: Wenn Ihre Berichte zuvor live mit einem Power BI-Semantikmodell oder Analysis Services-Modell verbunden waren, kann der Power BI-Dienst visuelle Caches über Berichte hinweg wiederverwenden. Wenn Sie die Liveverbindung zugunsten eines lokalen DirectQuery-Modells konvertiert haben, ist Berichten der Rückgriff auf diese Caches nicht mehr möglich. Womöglich kommt es daher zu Leistungseinbußen oder sogar zu Aktualisierungsfehlern. Auch die Workload des Power BI-Dienstes steigt dadurch. Vermutlich müssen Sie daher die Kapazität erhöhen oder die Workload auf andere Kapazitäten verteilen. Weitere Informationen zur Datenaktualisierung und Caching finden Sie unter Aktualisieren von Daten in Power BI.
- Umbenennen: Es wird davon abgeraten, in zusammengesetzten Modellen verwendete semantische Modelle oder deren Arbeitsbereiche umzubenennen. Der Grund hierfür ist, dass zusammengesetzte Modelle Verbindungen mit Power BI-Semantikmodellen nicht über interne eindeutige Bezeichner, sondern über die Namen der Arbeitsbereiche und semantischen Modelle herstellen. Durch Umbenennen eines semantischen Modells oder Arbeitsbereichs können die vom zusammengesetzten Modell verwendeten Verbindungen verloren gehen.
- Governance: Wenn Ihr Modell Ihre Single Version of the Truth ist, also Ihr einziges Modell, das Ihnen zuverlässige Daten zurückgibt, raten wir von einem zusammengesetzten Modell ab. Der Grund hierfür ist, dass zusammengesetzte Modelle von anderen Datenquellen oder Modellen abhängig sind. Wenn an diesen aber Änderungen vorgenommen werden, kann es passieren, dass das zusammengesetzte Modell nicht mehr funktioniert. Stattdessen empfehlen wir als „Single Version of the Truth“ die Veröffentlichung eines semantisches Unternehmensmodells. Dieses Modell kann als zuverlässige Basis betrachtet werden. Andere Datenmodellierer können dieses Basismodell dann durch spezialisierte zusammengesetzte Modelle erweitern.
- Datenherkunft: Wir raten Ihnen dringend, vor der Veröffentlichung von Änderungen an zusammengesetzten Modellen die Funktionen Datenherkunft und Semantikmodellauswirkungsanalyse auszuführen. Diese Funktionen des Power BI-Dienstes helfen Ihnen, die Beziehungen zwischen semantischen Modellen und deren Verwendung besser zu verstehen. Für externe semantische Modelle, die in der Herkunftsansicht angezeigt werden, sich tatsächlich aber in einem anderen Arbeitsbereich befinden, können keine Auswirkungsanalysen ausgeführt werden. Wenn Sie eine Auswirkungsanalyse für ein externes semantisches Modell durchführen möchten, müssen Sie hierfür zum Quellarbeitsbereich navigieren.
- Schemaaktualisierungen: Sie sollten Ihr zusammengesetztes Modell in Power BI Desktop aktualisieren, wenn Schemaänderungen an upstream-Datenquellen vorgenommen werden. Das Modell muss anschließend im Power BI-Dienst erneut veröffentlicht werden. Stellen Sie nach einer solchen Aktualisierung sicher, dass Berechnungen und abhängige Berichte gründlich getestet werden.
Zugehöriger Inhalt
Weitere Informationen zu den Themen dieses Artikels finden Sie in den folgenden Ressourcen.
- Verwenden zusammengesetzter Modelle in Power BI Desktop
- Modellieren von Beziehungen in Power BI Desktop
- DirectQuery-Modelle in Power BI Desktop
- Verwenden von DirectQuery in Power BI Desktop
- Speichermodus in Power BI Desktop
- Benutzerdefinierte Aggregationen
- Haben Sie Fragen? Versuchen Sie, die Fabric-Community zu kontaktieren
- Vorschläge? Einbringen von Ideen zur Verbesserung von Fabric