Horizontale Skalierung von Power BI-Semantikmodellen
Die horizontale Skalierung von Semantikmodellen unterstützt Power BI dabei, eine schnelle Leistung zu erzielen, wenn Ihre Berichte und Dashboards von einer großen Zielgruppe genutzt werden. Die horizontale Skalierung von Semantikmodellen verwendet Ihre Premium-Kapazität zum Hosten von schreibgeschützten Replikaten Ihres primären Semantikmodells. Durch Erhöhung des Durchsatzes stellen die schreibgeschützten Replikate sicher, dass die Leistung nicht verlangsamt wird, wenn mehrere Benutzer gleichzeitig Abfragen übermitteln.
Wenn Power BI schreibgeschützte Replikate erstellt, werden diese vom primären Semantikmodell mit Lese-/Schreibzugriff getrennt. Die schreibgeschützten Replikate dienen für Power BI-Berichts- und -Dashboardabfragen, und das Semantikmodell mit Lese-/Schreibzugriff wird verwendet, wenn Schreib- und Aktualisierungsvorgänge ausgeführt werden. Während Schreib- und Aktualisierungsvorgängen werden Ihre Bericht- und Dashboardabfragen von den schreibgeschützten Replikaten weiterhin ohne Unterbrechungen verarbeitet. Standardmäßig werden die schreibgeschützten und die Semantikmodelle mit Lese-/Schreibzugriff automatisch synchronisiert, sodass die schreibgeschützten Replikate auf dem neuesten Stand gehalten werden. Sie können die automatische Synchronisierung jedoch deaktivieren und manuell über die Befehlszeile oder per Skript synchronisieren.
Die folgende Tabelle zeigt die erforderliche Synchronisierung für jede Aktualisierungsmethode, wenn die horizontale Skalierung für Power BI-Semantikmodelle aktiviert und die automatische Synchronisierung deaktiviert ist:
| Refresh-Methode | Synchronisierung |
|---|---|
| OnDemand-Benutzeroberfläche | Immer synchronisieren |
| Geplante Aktualisierung | Immer synchronisieren |
| Grundlegende REST-API | Manuelle Synchronisierung erforderlich 1 |
| Erweiterte REST-API | Manuelle Synchronisierung erforderlich 1 |
| XMLA | Manuelle Synchronisierung erforderlich 1 |
1 – autoSyncReadOnlyReplicas in queryScaleOutSettings ist auf „false“ festgelegt.
Replikatverwaltung
Die horizontale Skalierung erstellt ein Replikat des semantischen Modells mit Lese-/Schreibzugriff und so viele schreibgeschützte Replikate wie nötig. Alle Schreibvorgänge werden an die Lese-/Schreibreplikate weitergeleitet. Dies gilt auch für Abfragen auf Sitzungen, die explizit auf das Lese-/Schreibreplikat abzielen, d.h. kein ?readonly in der Verbindungszeichenfolge verwenden. Diese Abfragen können eine hohe interaktive CPU-Auslastung für das Lese-/Schreibreplikat verursachen. In solchen Fällen wird kein neues Replikat erstellt, da die Abfragelast, die auf das Lese-/Schreibreplikat abzielt, nicht auf die schreibgeschützten Replikate verteilt werden kann.
Die Anzahl der schreibgeschützten Replikate wird basierend auf der Anzahl der CUs bestimmt, die Ihre Abfragen nutzen. Wenn die Nachfrage die derzeit auf einem Knoten verfügbaren Computeressourcen überschreitet, auf dem das Modell geladen wird und hoch bleibt, wird möglicherweise ein zusätzliches schreibgeschütztes Replikat auf einem anderen Knoten erstellt, um die Last zu verteilen. Die Gesamtzahl der von allen Replikaten verbrauchten CUs kann jedoch nicht die maximale Anzahl von CUs überschreiten, die ein einzelnes Modell für Ihre angegebene Kapazitäts-SKU verbrauchen darf.
Beispielsweise verfügt ein bestimmtes semantisches Modell für eine F64-Kapazität über genügend Ressourcen auf einem einzelnen Knoten, um alle zulässigen CUs für diese SKU zu nutzen. Daher skalieren F64-Kapazitäten in der Regel nicht über ein einzelnes schreibgeschütztes Replikat hinaus. Andererseits erstellen F256- und F1024+-Kapazitäten eher ein zweites schreibgeschütztes Replikat, da ein einzelner Knoten möglicherweise nicht ausreicht, um alle CUs bereitzustellen, die für eine F256/F1024+-Kapazität verwendet werden dürfen.
QSO wurde entwickelt, um die verfügbare Rechenleistung einer bestimmten Kapazitäts-SKU so effizient und nahtlos wie möglich mit der geringsten Anzahl schreibgeschützter Replikate und ohne Verwaltungsaufwand für Semantikmodellbesitzer zu nutzen.
Die aktuelle Auslastung einer Kapazität kann jedoch hoch genug sein, um eine Drosselung zu verursachen, wenn weitere Replikate hinzugefügt werden. Durch die Drosselung wird verhindert, dass weitere schreibgeschützte Replikate eine anhaltend hohe CPU-Auslastung erreichen. In solchen Fällen wird kein neues horizontal skaliertes, schreibgeschütztes Replikat erstellt.
Ein Replikat wird entfernt, wenn die CU-Verwendung für das Modell ausreichend reduziert und konsistent niedrig genug bleibt.
Voraussetzungen
Standardmäßig ist die horizontale Skalierung für Ihren Mandanten aktiviert, aber für Semantikmodelle in Ihrem Mandanten deaktiviert. Zum Aktivieren der horizontalen Skalierung für ein Semantikmodell müssen Sie die Power BI-REST-APIs verwenden. Die folgenden Voraussetzungen müssen vor der Aktivierung erfüllt sein:
Die Einstellung Aufskalieren von Abfragen für große Semantikmodelle für Ihren Mandanten ist aktiviert (Standard).
Ihr Arbeitsbereich befindet sich auf einer Power BI Premium-Kapazität:
- Premium-Einzelbenutzerlizenz (Premium Per User, PPU)
- Power BI Premium P-SKUs
- Power BI A-SKUs für Power BI Embedded (auch bekannt als Einbetten für Ihre Kunden).
- Fabric F-SKUs
Die Einstellung Speicherformat für große Semantikmodelle ist aktiviert.
Um Semantikmodelle mithilfe der REST-API zu verwalten, verwenden Sie Power BI Management-Cmdlets. Öffnen Sie zum Installieren PowerShell im Administratormodus, und führen Sie den Befehl aus:
Install-Module -Name MicrosoftPowerBIMgmtDie folgenden (oder höheren) App-, Bibliotheks- und Dienstversionen unterstützen das Herstellen einer Verbindung mit schreibgeschützten Replikaten:
App, Bibliothek oder Dienst Version Microsoft Analysis Services OLE DB-Anbieter für Microsoft SQL Server (MSOLAP) 16.0.20.201 (März 2022) Microsoft.AnalysisServices.AdomdClient (ADOMD.NET) 19.36.0 (März 2022) Power BI Desktop Juni 2022 SQL Server Management Studio (SSMS) 19,0 Tabular Editor 2 2.16.6 Tabular Editor 3 3.2.3 DAX Studio 3.0.0
Konfigurieren der horizontalen Skalierung für ein Semantikmodell
Informationen zum Aktivieren oder Deaktivieren der horizontalen Skalierung für ein Semantikmodell und zum Abrufen des Status der horizontalen Skalierung mithilfe von PowerShell und den REST-APIs finden Sie unter Konfigurieren der horizontalen Skalierung von Semantikmodellen.
Verbinden mit einem bestimmten Semantikmodelltyp
Wenn die horizontale Skalierung aktiviert ist, werden die folgenden Verbindungen beibehalten:
Standardmäßig stellt Power BI Desktop eine Verbindung zu einem schreibgeschützten Replikat her.
Liveverbindungsberichte stellen eine Verbindung mit einem schreibgeschützten Replikat her.
XMLA-Clientanwendungen stellen standardmäßig eine Verbindung mit dem Semantikmodell mit Lese-/Schreibzugriff her.
Aktualisierungen im Power BI-Dienst und Aktualisierungen mithilfe der REST-API für erweiterte Aktualisierungen sind mit dem Semantikmodell mit Lese-/Schreibzugriff verbunden.
Sie können eine Verbindung mit einem schreibgeschützten Replikat oder dem Semantikmodell mit Lese-/Schreibzugriff herstellen, indem Sie eine der folgenden Zeichenfolgen an die URL des Semantikmodells anfügen:
- Schreibgeschützt -
?readonly - Lesen/Schreiben -
?readwrite
Deaktivieren der horizontalen Skalierung von Semantikmodellen für Ihren Mandanten.
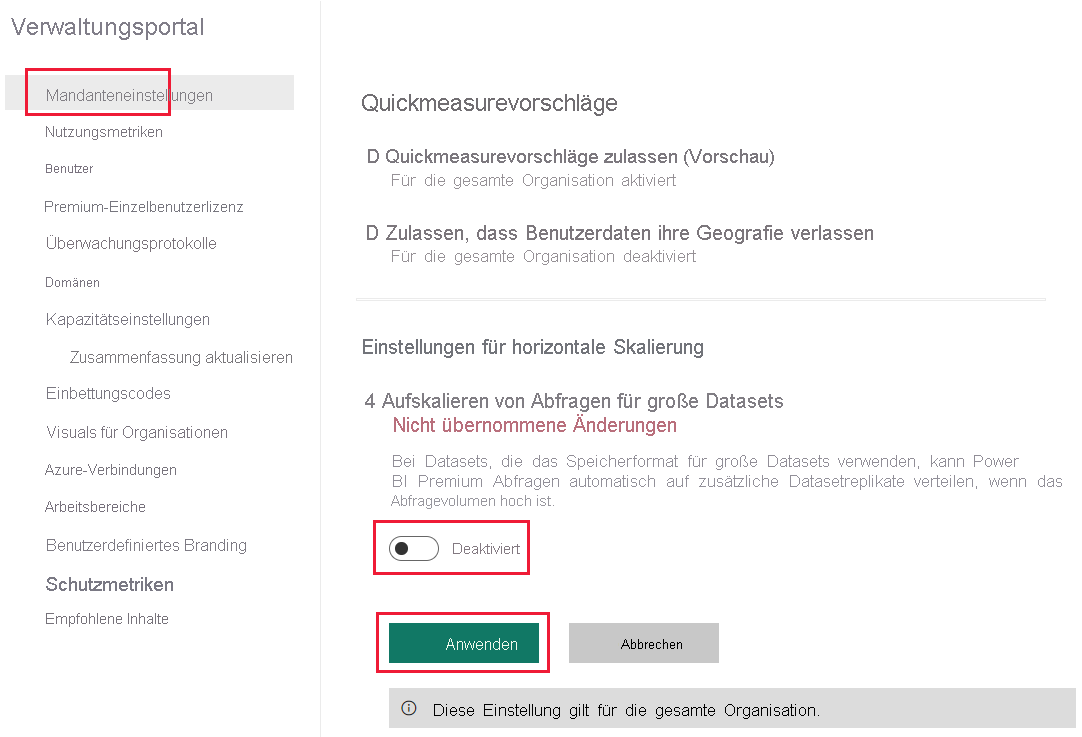
Die horizontale Skalierung von Power BI-Semantikmodellen ist standardmäßig für einen Mandanten aktiviert. Power BI-Mandantadministratoren können diese Einstellung deaktivieren. Gehen Sie wie folgt vor, um die horizontale Skalierung von Semantikmodellen für den Mandanten zu deaktivieren:
Wechseln Sie zu Ihren Mandanteneinstellungen.
Erweitern Sie in den Einstellungen für horizontale Skalierung die Option Aufskalieren von Abfragen für große Semantikmodelle.
Stellen Sie den Umschalter auf Deaktiviert um.
Wählen Sie Übernehmen.
Überlegungen und Einschränkungen
Clientanwendungen können über den XMLA-Endpunkt eine Verbindung mit einem schreibgeschützten Replikat herstellen, sofern sie den in der Verbindungszeichenfolge angegebenen Modus unterstützen. Clientanwendungen können auch mithilfe des XMLA-Endpunkts eine Verbindung mit der Lesen/Schreiben-Instanz herstellen.
Manuelle und geplante Aktualisierungen werden immer automatisch mit der neuesten Version der schreibgeschützten Replikate synchronisiert. REST-API-Aktualisierungen berücksichtigen die Konfiguration der automatischen Synchronisierung. Wenn die automatische Synchronisierung deaktiviert ist, muss Ihr Semantikmodell mithilfe der REST-API für die manuelle Synchronisierung mit den schreibgeschützten Replikaten synchronisiert werden.
Bei deaktivierter automatischer Synchronisierung müssen XMLA-Updates und -Aktualisierungen mithilfe der Synchronisierungs-REST-API mit den schreibgeschützten Semantikmodellkopien synchronisiert werden.
Wenn Sie ein Power BI-Semantikmodell mit horizontaler Skalierung löschen und ein weiteres Semantikmodell mit demselben Namen erstellen, warten Sie dafür fünf Minuten. Es kann eine Weile dauern, bis Power BI die Replikate des primären Semantikmodells entfernt hat.
Wenn die horizontale Skalierung des semantischen Power BI-Modells aktiviert ist und
autoSyncReadOnlyReplicas=false, werden Änderungen an den folgenden Funktionen nicht unterstützt:- Hinzufügen oder Löschen von Rollen
- Aktualisieren der Rollenmitgliedschaften für jede Rolle
- Ändern einer Datenquelle
- Löschen von Datenquellen, die von DirectQuery oder einer Dual-Tabelle verwendet werden
- Änderungen an Ausdrücken für Sicherheit auf Objektebene (OLS) oder dynamische Sicherheit auf Zeilenebene (RLS)
Um Änderungen an diesen Funktionen vorzunehmen, deaktivieren Sie die horizontale Skalierung, und warten Sie ein paar Minuten, bis die Änderung erfolgt, bevor Sie sie wieder aktivieren.
Die Ermittlung von Rollenmitgliedschaften mit dem DMV (Dynamic Management View)-Rowset TMSCHEMA_ROLE_MEMBERSHIPS liefert keine Ergebnisse, wenn sie gegen das schreibgeschützte Replikat ausgeführt wird.
Berichte, die eine Liveverbindung verwenden, stellen immer eine Verbindung zum schreibgeschützten Replikat her, auch wenn die Verbindungszeichenfolge
?readwriteverwendet. In Power BI Desktop stellen Berichte mit Liveverbindung, die?readwriteverwenden, jedoch eine Verbindung zum Lese-/Schreibreplikat her.Die DMV-Rowsets (Dynamic Management View) DBSCHEMA_CATALOGS und DISCOVER_XML_METADATA geben bei Verwendung von
?readonlyin der Verbindungszeichenfolge Informationen über Lese-/ Schreibreplikate zurück.Der SQL Server Profiler funktioniert nicht mit der Verbindungszeichenfolge
?readonly.Diese Vorgänge lösen die automatische Synchronisierung aus, auch wenn die automatische Synchronisierung ausgeschaltet ist (
AutoSync=Off).- Migrieren eines Arbeitsbereichs von einer Kapazität zu einer anderen.
- Wechseln (oder Rotieren) der Version des Schlüssels, die für Bring Your Own Encryption Keys (BYOK) verwendet wird.
- Verschieben des Arbeitsbereichs eines semantischen Modells von einer Kapazität, die BYOK nicht verwendet, zu einer Kapazität, die BYOK verwendet.
- Verschieben des Arbeitsbereichs eines semantischen Modells von einer Kapazität, die BYOK verwendet, zu einer Kapazität, die BYOK nicht verwendet.
- Wiederherstellung eines semantischen Modells unter Verwendung des öffentlichen XMLA-Endpunkts.
Durch die Deaktivierung des Speicherformats „Großes semantisches Modell“ wird die horizontale Skalierung deaktiviert und alle Synchronisierungsinformationen gehen verloren.