Stichprobenentnahme für visuelle Linienelemente mit hoher Dichte in Power BI
Der Samplingalgorithmus in Power BI Visuals verbessert, die Stichproben von Daten mit hoher Dichte verwenden. Sie können z. B. ein Liniendiagramm aus den Verkaufsergebnissen Ihres Einzelhandelsgeschäfts erstellen, auch wenn jedes Geschäft mehr als 10.000 Verkaufsbelege jährlich verzeichnet. Ein Liniendiagramm mit derartigen Verkaufsinformationen entnimmt stichprobenartig Daten aus den Daten jedes Geschäfts und erstellt ein Mehrfachliniendiagramm, das die zugrunde liegenden Daten veranschaulicht. Stellen Sie sicher, eine aussagekräftige Darstellung dieser Daten auszuwählen, um zu veranschaulichen, wie der Umsatz im Laufe der Zeit variiert. Dies ist eine gängige Methode für das Visualisieren von Daten mit hoher Dichte. Die Details der Stichprobenentnahme von Daten mit hoher Dichte werden in diesem Artikel beschrieben.
Hinweis
Der in diesem Artikel beschriebene Algorithmus zur Stichprobenentnahme mit hoher Dichte ist in Power BI Desktop und in Power BI-Dienst verfügbar.
So funktioniert die Strichprobenentnahme für visuelle Linienelemente mit hoher Dichte
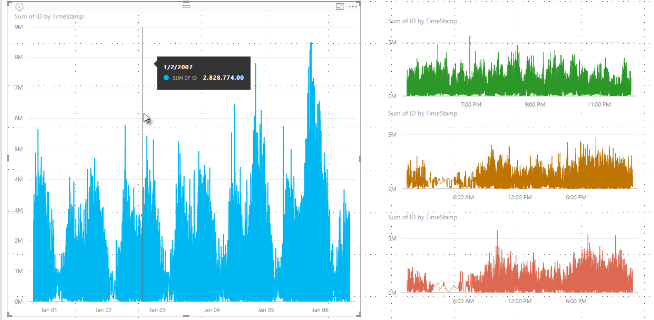
Früher hat Power BI eine Sammlung von Beispieldatenpunkten im vollständigen Bereich der zugrunde liegenden Daten auf deterministische Weise ausgewählt. Es kann z.B. sein, dass für Daten mit hoher Dichte in einer Visualisierung eines Kalenderjahrs 350 Beispieldatenpunkte angezeigt werden, die jeweils ausgewählt wurden, um sicherzustellen, dass der vollständige Datenbereich im Visual dargestellt wird. Um dies besser zu verstehen, können Sie sich vorstellen, dass ein Aktienkurs über ein Jahr aufgezeichnet und 365 Datenpunkte ausgewählt wurden, um eine Liniendiagrammvisualisierung zu erstellen. Das ist ein Datenpunkt für jeden Tag.
In diesem Fall gibt es allein am Tag mehrere Werte für den Aktienkurs. Natürlich gibt es ein Tageshoch und -tief, aber diese können zu jedem Zeitpunkt am Tag während der Öffnung des Börsenmarkts auftreten. Für Linienstichproben mit hoher Dichte erhalten Sie eine repräsentative Momentaufnahme der zugrunde liegenden Daten, wie etwa der Preis um 10:30 Uhr und um 12:00 Uhr, wenn das zugrunde liegenden Datenbeispiel an jedem Tag um 10:30 Uhr und 12:00 Uhr entnommen wurde. Allerdings wird dadurch nicht gewährleistet, dass das tatsächliche Tageshoch und -tief des Aktienkurses (an diesem Tag) für diesen repräsentativen Datenpunkt erfasst wird. In dieser und in anderen Situationen ist die Stichprobenentnahme für die zugrunde liegenden Daten repräsentativ. Allerdings werden die wichtigsten Punkte nicht immer erfasst. In diesem Fall wären dies das Tageshoch und -tief gewesen.
Definitionsgemäß werden Stichproben von Daten mit hoher Dichte entnommen, um schnell Visualisierungen zu erstellen, die auf Interaktivität reagieren. Zu viele Datenpunkte in einem Visual können dieses verlangsamen und die Sichtbarkeit von Trends beeinträchtigen. Das Erstellen des Algorithmus zur Stichprobenentnahme hängt davon ab, wie die Daten entnommen werden, um die beste Visualisierung zu bieten. Durch den Algorithmus in Power BI Desktop werden Reaktionsfähigkeit, Darstellung und die Erhaltung von wichtigen Punkten in jedem Zeitsegment optimal miteinander vereint.
So funktioniert der neue Algorithmus für die Strichprobenentnahme für visuelle Linienelemente mit hoher Dichte
Der Algorithmus für Linienstichproben mit hoher Dichte steht für Visuals mit Liniendiagrammen und Flächendiagrammen mit fortlaufender X-Achse zur Verfügung.
Für ein Visual mit hoher Dichte teilt Power BI Ihre Daten auf intelligente Weise in hochauflösende Blöcke ein und wählt anschließend wichtige Punkte für jeden Block aus. Dieses Aufteilen von hochauflösenden Daten wurde so optimiert, dass sich das entstehende Diagramm optisch nicht von einem Diagramm unterscheidet, für das alle zugrunde liegenden Datenpunkte geladen wurden – und zudem ist es schneller und interaktiver.
Mindest- und Höchstwerte für visuelle Linienelemente mit hoher Dichte
Für alle Visualisierungen gelten die folgenden Einschränkungen:
Die maximale Anzahl von Datenpunkten, die in den meisten Visuals angezeigt werden können, beträgt 3.500, unabhängig von der Anzahl der zugrunde liegenden Datenpunkte oder -reihen (siehe dazu die Ausnahmen in der folgenden Aufzählung). Beispielsweise ist bei 10 Reihen mit jeweils 350 Datenpunkten die Höchstgrenze an Datenpunkten für das Visual erreicht. Wenn Sie eine Reihe haben, kann diese bis zu 3.500 Datenpunkte haben, wenn der Algorithmus dies für die beste Stichprobenentnahme für die zugrunde liegenden Daten hält.
Jedes Visual kann maximal 60 Reihen enthalten. Wenn Sie mehr als 60 Reihen haben, teilen Sie die Daten auf, und erstellen Sie mehrere Visuals mit jeweils höchstens 60 Reihen. Es wird empfohlen, einen Datenschnitt zu verwenden, um nur Segmente der Daten anzuzeigen (nur bestimmte Reihen). Wenn Sie z.B. alle Unterkategorien in der Legende anzeigen, können Sie einen Datenschnitt verwenden, um nach der übergeordneten Kategorie auf der gleichen Berichtseite zu filtern.
Die maximale Anzahl von Datenlimits ist für die folgenden Arten von Visuals höher, die Ausnahmen vom Datenpunktlimit 3.500 sind:
- Maximal 150.000 Datenpunkte für R-Visuals.
- 30.000 Datenpunkte für Azure Map-Visuals.
- 10.000 Datenpunkte für einige Punktdiagrammkonfigurationen (Standardeinstellung 3500).
- 3.500 für alle anderen Visuals, die die Stichprobenentnahme mit hoher Dichte verwenden. Einige andere visuellen Elemente visualisieren möglicherweise mehr Daten, verwenden aber keine Stichprobenerstellung.
Durch diese Parameter wird sichergestellt, dass die Visuals in Power BI Desktop schnell gerendert werden und weiter auf Interaktion von Benutzern reagieren können. Zudem wird sichergestellt, dass diese keinen unnötigen Rechenmehraufwand auf dem Computer verursachen, der das Visual rendert.
Auswerten von repräsentativen Datenpunkten für Linienvisuals mit hoher Dichte
Wenn die Anzahl von zugrunde liegenden Datenpunkten die der maximalen Datenpunkte übersteigt, die im Visual dargestellt werden können, wird der sogenannte Diskretisierungsvorgang gestartet. Bei der Quantisierung werden die zugrunde liegenden Daten in Gruppen unterteilt, die als Intervalle bezeichnet werden, und diese Intervalle werden anschließend iterativ verfeinert.
Der Algorithmus erstellt so viele Gruppen wie möglich, um dem visuellen Element die höchstmögliche Granularität zu bieten. Innerhalb jeder Gruppierung sucht der Algorithmus den Mindest- und Höchstdatenwert, um sicherzustellen, dass wichtige und aussagekräftige Werte, wie etwa Ausreißer, erfasst und im visuellen Element angezeigt werden. Auf Grundlage der Ergebnisse der Diskretisierung und der anschließenden Auswertung der Daten durch Power BI wird die Mindestauflösung der X-Achse für das Visual bestimmt, um die höchstmögliche Granularität für das Visual zu gewährleisten.
Wie bereits erwähnt, liegt die Mindestgranularität für jede Reihe bei 350 Punkten, und die höchste beträgt 3.500 für die meisten Visuals. Die Ausnahmen sind in den vorherigen Absätzen aufgeführt.
Jede Gruppierung wird durch zwei Datenpunkte dargestellt, die im visuellen Element die repräsentativen Datenpunkte der Gruppierung werden. Die Datenpunkte sind der Höchst- und Tiefwert für dieses Intervall. Indem Sie Höchst- oder Tiefwerte auswählen, stellt der Gruppierungsprozess sicher, dass jeder relevante Höchstwert oder aussagekräftige Tiefwert im visuellen Element erfasst und gerendert wird.
Falls Sie das für einen sehr hohen Analyseaufwand halten, um sicherzustellen, dass vereinzelte Ausreißer erfasst und ordnungsgemäß im Visual dargestellt werden, haben sie Recht. Genau deshalb gibt es den Algorithmus und die Quantisierung.
QuickInfos und Stichprobenentnahme für visuelle Linienelemente mit hoher Dichte
Beachten Sie, dass der Diskretisierungsvorgang, der die Mindest- und Höchstwerte in einer gegebenen Gruppe erfasst und darstellt, sich darauf auswirken kann, wie QuickInfos Daten anzeigen, wenn Sie mit der Maus auf Datenpunkte zeigen. Wir sehen uns noch mal unser Beispiel zu Aktienkursen an, um zu erläutern, wie und warum dies passiert.
Angenommen, Sie erstellen ein Visual auf der Grundlage von Aktienkursen, und Sie vergleichen zwei unterschiedliche Aktien miteinander, die beide die Stichprobenentnahme mit hoher Dichte verwenden. Die zugrunde liegenden Daten für jede Reihe weisen viele Datenpunkte auf. Beispielsweise erfassen Sie vielleicht den ganzen Tag lang sekündlich den Aktienkurs. Der Algorithmus für Linienstichproben mit hoher Dichte führt die Diskretisierung für jede Reihe einzeln durch.
Nehmen wir weiterhin an, dass der Preis der ersten Aktie um 12:02 Uhr steigt und 10 Sekunden später wieder schnell absinkt. Das ist ein wichtiger Datenpunkt. Wenn die Gruppierung für diese Aktie durchgeführt wird, ist das Tageshoch um 12:02 Uhr der repräsentative Datenpunkt für diese Gruppe.
Bei der zweiten Aktie gab es um 12:02 Uhr allerdings weder ein Tageshoch noch ein Tagestief in der Gruppe, die diesen Zeitpunkt enthält. Das Tageshoch oder -tief der Gruppe, die 12:02 Uhr enthält, kann drei Minuten später aufgetreten sein. Wenn das Liniendiagramm erstellt wird und Sie den Mauszeiger über 12:02 halten, wird als QuickInfo ein Wert für die erste Aktie angezeigt. Dies liegt daran, dass er um 12:02 Uhr stark angestiegen ist und dieser Wert als höchster Datenpunkt dieses Intervalls ausgewählt wurde. Um 12:02 Uhr wird jedoch kein Wert für die zweite Aktie als QuickInfo angezeigt. Dies liegt daran, dass die zweite Aktie kein ein Tageshoch oder -tief in dem Intervall hatte, das 12:02 Uhr enthalten hat. Deshalb können für die zweite Aktie für 12:02 Uhr keine Daten angezeigt werden, und deshalb werden auch keine QuickInfo-Daten angezeigt.
Dies tritt mit QuickInfos häufig auf. Möglicherweise stimmen die Höchst- und Tiefwerte eines Intervalls nicht genau mit den gleichmäßig skalierten Wertpunkten der X-Achse überein, und deshalb wird der Wert nicht als QuickInfo angezeigt.
So aktivieren Sie die Strichprobenentnahme für visuelle Linienelemente mit hoher Dichte
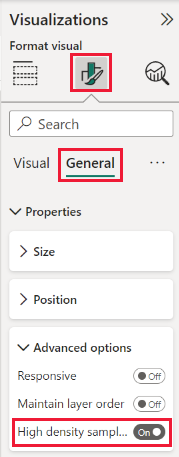
Standardmäßig ist der Algorithmus Ein. Um diese Einstellung zu ändern, wechseln Sie in den Bereich Formatierung auf der Karte Allgemein. Am unteren Rand sehen Sie den Schieberegler Stichprobenentnahme mit hoher Dichte. Schalten Sie den Schieberegler auf Ein oder Aus.
Überlegungen und Einschränkungen
Der Algorithmus für Linienstichproben mit hoher Dichte ist eine wichtige Verbesserung in Power BI. Es gibt jedoch einige Aspekte, die Sie berücksichtigen sollten, wenn Sie mit Werten und Daten mit hoher Dichte arbeiten.
Aufgrund der erhöhten Granularität und des erweiterten Gruppierungsprozesses, zeigt QuickInfos möglicherweise nur dann einen Wert an, wenn repräsentative Daten nach dem Cursor übereinstimmen. Weitere Informationen finden Sie im Abschnitt QuickInfos und Linienstichproben mit hoher Dichte dieses Artikels.
Wenn die Größe einer allgemeinen Datenquelle zu groß ist, eliminiert der Algorithmus Reihen (Legendenelemente), um sie an das Maximum an importierten Daten anzupassen.
- In diesem Fall ordnet der Algorithmus Legendenreihen alphabetisch und durchläuft die Liste von Legendenelementen von oben nach unten in alphabetischer Reihenfolge, bis das Maximum an importierten Daten erreicht ist. Danach werden keine weiteren Reihen mehr importiert.
Wenn ein zugrunde liegendes Dataset mehr als 60 Reihen hat, also die Höchstzahl an Reihen, ordnet der Algorithmus die Reihen alphabetisch und löscht Reihen, die in alphabetischer Ordnung nach der 60. Reihe stehen.
Wenn die Werte in den Daten nicht vom Typ numeric oder date/time sind, verwendet Power BI nicht den Algorithmus, sondern den vorherigen, nicht für hohe Dichte ausgelegten Stichprobenentnahmealgorithmus.
Die Einstellung Elemente ohne Daten anzeigen wird vom Algorithmus nicht unterstützt.
Der Algorithmus wird nicht unterstützt, wenn Sie die Liveverbindung zu einem Modell verwenden, das in SQL Server Analysis Services (Version 2016 oder früher) gehostet wird. Er wird aber in Modellen unterstützt, die in Power BI oder Azure Analysis Services gehostet werden.