Exportierte Dataverse-Daten in Azure Data Factory erfassen
Nach dem Exportieren von Daten aus Microsoft Dataverse nach Azure Data Lake Storage Gen2 mit Azure Synapse Link for Dataverse können Sie mit Azure Data Factory Dataflows erstellen, Ihre Daten transformieren und Analysen ausführen.
Hinweis
Azure Synapse Link for Dataverse war früher als „In Data Lake exportieren“ bekannt. Der Dienst wurde mit Wirkung zum Mai 2021 umbenannt und exportiert weiterhin Daten nach Azure Data Lake sowie Azure Synapse Analytics.
Dieser Artikel zeigt Ihnen, wie Sie die folgenden Aufgaben ausführen:
Legen Sie das Data Lake Storage Gen2-Speicherkonto mit den Dataverse-Daten als Quelle in einem Data Factory-Dataflow fest.
Wandeln Sie Dataverse-Daten in Data Factory mit einem Datenflow um.
Legen Sie das Data Lake Storage Gen2-Speicherkonto mit den Dataverse-Daten als Senke in einem Data Factory-Dataflow fest.
Führen Sie Ihren Dataflow aus, indem Sie eine Pipeline erstellen.
Voraussetzungen
In diesem Abschnitt werden die Voraussetzungen für die Aufnahme der exportierten Dataverse-Daten mit Data Factory beschrieben.
Azure-Rollen. Das Benutzerkonto, mit dem Sie sich bei Azure anmelden, muss Mitglied der Rolle Mitwirkender oder Besitzer oder ein Administrator des Azure-Abonnements sein. Um die Berechtigungen anzuzeigen, die Sie im Abonnement haben, gehen Sie zum Azure-Portal, wählen Sie Ihren Benutzernamen in der oberen rechten Ecke, wählen Sie ... und dann Meine Berechtigungen aus. Wenn Sie Zugriff auf mehrere Abonnements haben, wählen Sie das entsprechende aus. Um untergeordnete Ressourcen für Data Factory im Azure-Portal – einschließlich Datasets, verknüpften Diensten, Pipelines, Triggern und Integration Runtimes – zu erstellen und zu verwalten, müssen Sie der Rolle Data Factory-Mitwirkender auf Ressourcengruppenebene oder höher angehören.
Azure Synapse Link for Dataverse. In dieser Anleitung wird davon ausgegangen, dass Sie bereits Dataverse-Daten mithilfe von Azure Synapse Link for Dataverse exportiert haben. In diesem Beispiel werden die Kontotabellendaten in den Data Lake exportiert.
Azure Data Factory. In diesem Handbuch wird davon ausgegangen, dass Sie bereits eine Data Factory unter derselben Abonnement- und Ressourcengruppe wie das Speicherkonto erstellt haben, das die exportierten Dataverse-Daten enthält.
Das Data Lake Storage Gen2-Speicherkonto als Quelle festlegen
Öffnen Sie Azure Data Factory, und wählen Sie die Data Factory aus, die sich in derselben Abonnement- und Ressourcengruppe befindet wie das Speicherkonto, das Ihre exportierten Dataverse-Daten enthält. Wählen Sie dann Datenflow erstellen von der Homepage aus.
Aktivieren Sie den Modus Datenflow-Debug, und wählen Sie Ihre bevorzugte Zeit für die Liveschaltung aus. Dies kann bis zu 10 Minuten dauern, Sie können jedoch mit den folgenden Schritten fortfahren.

Wählen Sie Quelle hinzufügen aus.

Unter Quelleinstellungen können Sie dann folgende Schritte ausführen:
- Name des Ausgabestreams: Geben Sie den gewünschten Namen ein.
- Quellentyp: Wählen Sie Inline aus.
- Inline-DataSet-Typ: Wählen Sie Common Data Model aus.
- Verknüpfter Dienst: Wählen Sie das Speicherkonto aus dem Dropdown-Menü aus, und verknüpfen Sie einen neuen Dienst, indem Sie Ihre Abonnementdetails angeben und alle Standardkonfigurationen beibehalten.
- Musteraufnahme: Wenn Sie alle Ihre Daten verwenden möchten, wählen Sie Deaktivieren.
Unter Quellopitionen können Sie dann folgende Schritte ausführen:
Metadatenformat: Wählen Sie Model.json aus.
Stammspeicherort: Geben Sie den Containernamen in das erste Feld (Container) ein, oder suchen Sie nach dem Containernamen, und wählen Sie OK aus.
Entität: Geben Sie den Tabellennamen ein, oder suchen Sie die Tabelle.

Überprüfen Sie die Registerkarte Projektion, um sicherzustellen, dass Ihr Schema erfolgreich importiert wurde. Wenn Sie keine Spalten sehen, wählen Sie Schemaoptionen aus, und überprüfen Sie die Option Abgewichene Spaltentypen ableiten. Konfigurieren Sie die Formatierungsoptionen so, dass sie mit Ihrem Dataset übereinstimmen, und wählen Sie dann Anwenden aus.
Sie können Ihre Daten auf der Registerkarte Datenvorschau anzeigen, um sicherzustellen, dass die Quellenerstellung vollständig und korrekt war.
Ihre Dataverse-Daten transformieren
Nach dem Einstellen der exportierten Dataverse-Daten in das Azure Data Lake Storage Gen2-Konto als Quelle im Data Factory-Dataflow gibt es viele Möglichkeiten, Ihre Daten zu transformieren. Mehr Informationen: Azure Data Factory
Befolgen Sie diese Anweisungen, um für jede Zeile einen Rang nach dem Feld Einnahmen der Kontotabelle zu erstellen.
Wählen Sie + in der unteren rechten Ecke der vorherigen Transformation aus, und suchen Sie dann nach Rang, und wählen Sie ihn aus.
Gehen Sie auf der Registerkarte Rangeinstellungen wie folgt vor:
Name des Ausgabestreams: Geben Sie den gewünschten Namen ein, z. B. Rang1.
Eingehender Stream: Wählen Sie den gewünschten Quellennamen aus. In diesem Fall handelt es sich um den Quellennamen aus dem vorherigen Schritt.
Optionen: Lassen Sie die Optionen deaktiviert.
Rangspalte: Geben Sie den Namen der generierten Rangspalte ein.
Sortierbedingungen: Wählen Sie die Spalte Einnahmen aus und sortieren Sie sie in absteigender Reihenfolge.
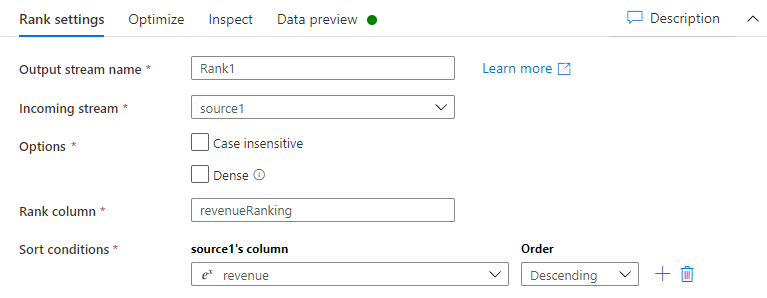
Sie können Ihre Daten auf der Registerkarte Datenvorschau anzeigen, auf der Sie die neue Spalte RevenueRank ganz rechts finden.
Das Data Lake Storage Gen2-Speicherkonto als Senke festlegen
Letztendlich müssen Sie eine Senke für Ihren Datenfluss festlegen. Befolgen Sie diese Anweisungen, um Ihre transformierten Daten als begrenzte Textdatei im Data Lake abzulegen.
Wählen Sie + in der unteren rechten Ecke der vorherigen Transformation aus, und suchen Sie dann nach Senke, und wählen Sie sie aus.
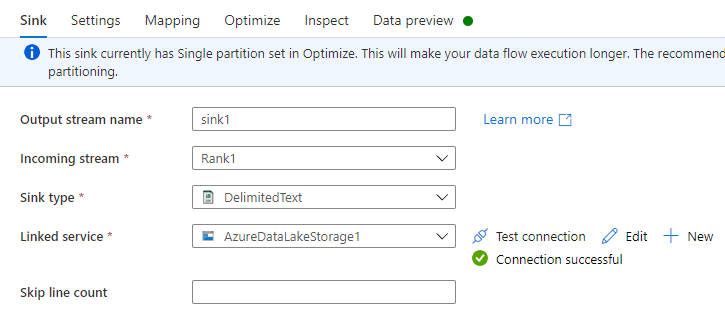
Führen Sie auf der Registerkarte Senke die folgenden Schritte aus:
Name des Ausgabestreams: Geben Sie den gewünschten Namen ein, z. B. Senke1.
Eingehender Stream: Wählen Sie den gewünschten Quellennamen aus. In diesem Fall handelt es sich um den Quellennamen aus dem vorherigen Schritt.
Typ der Senke: Wählen Sie DelimitedText aus.
Verknüpfter Dienst: Wählen Sie Ihren Data Lake Storage Gen2-Speichercontainer aus, der die exportierten Daten enthält, indem Sie den Azure Synapse Link for Dataverse-Service benutzen.
Auf der Registerkarte Einstellungen können Sie folgende Schritte ausführen:
Ordnerpfad: Geben Sie den Containernamen in das erste Feld (Dateisystem) ein, oder suchen Sie nach dem Containernamen, und wählen Sie OK aus.
Dateinamenoption: Wählen Sie Ausgabe in eine einzelne Datei aus.
Ausgabe in einzelne Datei: Geben Sie einen Dateinamen ein, z. B. ADFOutput.
Behalten Sie alle anderen Standardeinstellungen bei.
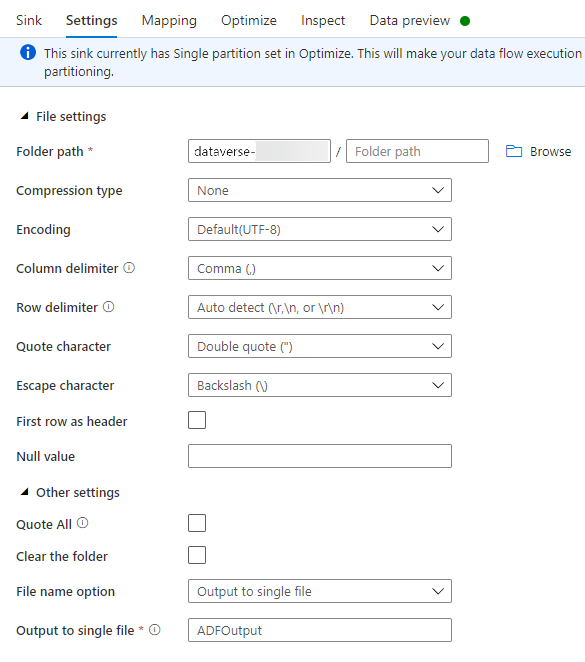
Legen Sie auf der Registerkarte Optimieren die Partitionsoption auf Einzelne Partition fest.
Sie können Ihre Daten auf der Registerkarte Datenvorschau anzeigen.
Ihren Datenfluss ausführen
Im linken Bereich unter Werksressourcen wählen Sie + und dann Pipeline aus.

Unter Aktivitäten wählen Sie Verschieben und transformieren und ziehen dann den Datatflow zum Arbeitsbereich.
Wählen Sie Vorhandenen Dataflow verwenden und wählen Sie dann den Dataflow aus, den Sie in den vorherigen Schritten erstellt haben.
Wählen Sie aus der Befehlsleiste Debuggen aus.
Lassen Sie den Dataflow laufen, bis die Unteransicht anzeigt, dass er abgeschlossen ist. Dies kann einige Minuten dauern.
Wechseln Sie zum endgültigen Zielspeichercontainer und suchen Sie die transformierte Tabellendatendatei.
Siehe auch
Azure Synapse Link for Dataverse mit Azure Data Lake konfigurieren
Dataverse-Daten in Azure Data Lake Storage Gen2 mit Power BI analysieren
Hinweis
Können Sie uns Ihre Präferenzen für die Dokumentationssprache mitteilen? Nehmen Sie an einer kurzen Umfrage teil. (Beachten Sie, dass diese Umfrage auf Englisch ist.)
Die Umfrage dauert etwa sieben Minuten. Es werden keine personenbezogenen Daten erhoben. (Datenschutzbestimmungen).