Transparency note and use cases for Document Intelligence
What is a transparency note?
An AI system includes not only the technology, but also the people who will use it, the people who will be affected by it, and the environment in which it is deployed. Creating a system that is fit for its intended purpose requires an understanding of how the technology works, its capabilities and limitations, and how to achieve the best performance.
Microsoft provides transparency notes to help you understand how our AI technology works. This includes the choices system owners can make that influence system performance and behavior, and the importance of thinking about the whole system, including the technology, the people, and the environment. You can use transparency notes when developing or deploying your own system, or share them with the people who will use or be affected by your system.
Transparency notes are part of a broader effort at Microsoft to put our AI principles into practice. To find out more, see Microsoft's AI principles.
The basics of Document Intelligence
Introduction
Document Intelligence is accessed via a set of APIs and allows developers to easily extract text, structure, and fields from their documents. It is composed of features like:
- Read for text extraction.
- Layout and General Documents for structural insights and general ke-values and entities such as names, places, and things.
- Prebuilt models for specific document types like invoices, receipts, business cards, W2s, and IDs.
- Custom models for building models specific to your document types.
Document Intelligence supports one or more languages and locales for each of the features, as listed in the Supported languages article.
Key terms
| Term | Definition |
|---|---|
| Read | This feature extracts text lines, words, and their locations from images and documents, along with other information such as detected languages. |
| Layout | This feature extracts text, selection marks, and table structure (the row and column numbers associated with the text). See Document Intelligence Layout. |
| General Documents | Analyze documents and associate values to keys and entries to tables that it discovers. For more information, see Document Intelligence General Documents. |
| Prebuilt models | Prebuilt models are document-specific models for unique form types. These models don't require custom training before use. For example, the prebuilt invoice model extracts key fields from invoices. For more information, see Document Intelligence prebuilt invoice model. |
| Custom models | Document Intelligence allows you to train a custom model that's tailored to your forms and documents. This model extracts text, key-value pairs, selection marks, and table data. Custom models can be improved with human feedback by applying human review, updating the labels, and retraining the model by using the API. |
| Confidence value | All Get Analysis Results operations return confidence values in the range between 0 and 1 for all extracted words and key-value mappings. This value represents the service's estimate of how many times it correctly extracts the word out of 100 or correctly maps the key-value pairs. For example, a word that's estimated to be extracted correctly 82% of the time results in a confidence value of 0.82. |
| Add-on features | Document Intelligence offers a set of add-on features to extend the results to include more elements from your documents. Some add-on features incur an extra cost and can be enabled and disabled depending on the scenario of the document extraction. We currently offer high resolution, formula, styleFont, barcodes, languages, keyValuePairs, and queryFields extraction capabilities. For more information, see Document Intelligence Add-on capabilities. |
Capabilities
System behavior
Azure AI Document Intelligence is a cloud-based Azure AI service that's built by using optical character recognition (OCR), Text Analytics, and Custom Text from Azure AI services. Custom models currently use Azure OpenAI service's GPT-3.5 model. OCR is used to extract typeface and handwritten text documents. Document Intelligence uses OCR to detect and extract information from forms and documents supported by AI to provide more structure and information to the text extraction.
Use cases
Intended uses
Document Intelligence includes features that enable customers from various industries to extract data from their documents. The following scenarios are examples of appropriate use cases:
Accounts payable: A company can increase the efficiency of its accounts payable clerks by using the prebuilt invoice model and custom forms to speed up invoice data entry with a human in the loop. The prebuilt invoice model can extract key fields, such as Invoice Total and Shipping Address.
Insurance form processing: A customer can train a model by using custom forms to extract a key-value pair in insurance forms and then feeds the data to their business flow to improve the accuracy and efficiency of their process. For their unique forms, customers can build their own model that extracts key values by using custom forms. These extracted values then become actionable data for various workflows within their business.
Bank form processing: A bank can use the prebuilt ID model and custom forms to speed up the data entry for "know your customer" documentation, or to speed up data entry for a mortgage packet. If a bank requires their customers to submit personal identification as part of a process, the prebuilt ID model can extract key values, such as Name and Document Number, speeding up the overall time for data entry.
Robotic process automation (RPA): Using the custom extraction model, customers can extract specific data needed from various types of documents. The key-value pair extracted can then be entered into various systems such as databases, or CRM systems, through RPA, replacing manual data entry. Customers can also use custom classification model to categorize documents based on their content and file them in proper location. As such, an organized set of data extracted from the custom model can be an essential first step to document RPA scenarios for businesses that handle large volumes of documents regularly.
Considerations when choosing other use cases
Consider the following factors when you choose a use case:
Carefully consider applying human review when sensitive data or scenarios are involved: It's important to include a human in the loop for a manual review when you're dealing with high-stakes scenarios (e.g affecting someone's consequential rights) or sensitive data. Machine learning models aren't perfect. Consider carefully when to include a manual review step for certain workflows. For example, identity verification at a port of entry such as airports should include human oversight.
Carefully consider when using for awarding or denying of benefits: Doc intelligence was not designed or evaluated for the award or denial of benefits, and use in these scenarios may have unintended consequences. These scenarios include:
- Medical insurance: This would include using healthcare records and medical prescriptions as the basis for decisions on insurance reward or denial.
- Loan approvals: These include applications for new loans or refinancing of existing ones.
Carefully consider the supported document types and locales: Prebuilt models have a predefined list of supported fields and are built for specific locales. Be sure to carefully check the officially supported locales and document types to ensure the best results. For example, see Document Intelligence prebuilt receipt locales.
Limitations
Technical limitations, operational factors, and ranges
Prebuilt model limitations
Document Intelligence prebuilt models are used for processing specific document types and are pretrained on thousands of forms. This capability allows developers to get started and get results within minutes, with no training data or labeling required. For prebuilt models, it's important to note the list of input requirements, supported document types, and locales for each prebuilt model for optimal results. For example, refer to the prebuilt Invoice input requirements.
Custom model limitations
Document Intelligence custom models are trained using your own training data so that the model can train to your specific forms and documents. This capability is heavily dependent on the way you label the data, as well as the type of training data set you provide. For custom models, it’s important to note the limits of training data set size, document page limits, and minimum number of samples needed for each type of document. Custom models currently use Azure OpenAI Service's GPT-3.5 model. Further information on the Azure OpenAI models can be found in the Azure OpenAI Transparency Note.
The Service limits page contains more information on Azure AI Document Intelligence service quotas and limits for all pricing tiers. It also contains model limitations and best practices for model usage and avoiding request throttling.
Feature support
See the Analysis features table for a list of the different operations that Document Intelligence models can perform.
System performance
Accuracy
Text is composed of lines and words at the foundational level and entities such as names, prices, amounts, company names, and products at the document understanding level.
Word-level accuracy
A popular measure of accuracy for OCR is word error rate (WER), or how many words were incorrectly output in the extracted results. The lower the WER, the higher the accuracy.
WER is defined as:
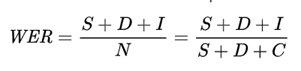
Where:
| Term | Definition | Example |
|---|---|---|
| S | Count of incorrect words ("substituted") in the output. | "Velvet" gets extracted as "Veivet" because "l" is detected as "i." |
| D | Count of missing ("deleted") words in the output. | For the text "Company Name: Microsoft," Microsoft isn't extracted because it's handwritten or hard to read. |
| I | Count of nonexistent ("inserted") words in the output. | "Department" gets incorrectly segmented into three words as "Dep artm ent." In this case, the result is one deleted word and three inserted words. |
| C | Count of correctly extracted words in the output. | All words that are correctly extracted. |
| N | Count of total words in the reference (N=S+D+C) excluding I because those words were missing from the original reference and were incorrectly predicted as present. | Consider an image with the sentence, "Microsoft, headquartered in Redmond, WA announced a new product called Velvet for finance departments." Assume the OCR output is " , headquartered in Redmond, WA announced a new product called Veivet for finance dep artm ents." In this case, S (Velvet) = 1, D (Microsoft) = 1, I (dep artm ents) = 3, C (11), and N = S + D + C = 13. Therefore, WER = (S + D + I) / N = 5 / 13 = 0.38 or 38% (out of 100). |
Using a confidence value
As covered in an earlier section, the service provides a confidence value for each predicted word in the OCR output. Customers use this value to calibrate custom thresholds for their content and scenarios to route the content for straight-through processing or forwarding to the human-in-the-loop process. The resulting measurements determine the scenario-specific accuracy.
OCR system performance implications can vary by scenarios where the OCR technology is applied. We'll review a few examples to illustrate that concept.
- Medical device compliance: In this first example, a multinational pharmaceutical company with a diverse product portfolio of patents, devices, medications, and treatments needs to analyze FDA-compliant product label information and analysis results documents. The company might prefer a low confidence value threshold for applying human-in-the-loop because the cost of incorrectly extracted data can have significant impact for consumers and fines from regulatory agencies.
- Image and documents processing: In this second example, a company performs insurance and loan application processing. The customer using OCR might prefer a medium confidence value threshold because the automated text extraction is combined downstream with other information inputs and human-in-the-loop steps for a holistic review of applications.
- Content moderation: For a large volume of e-commerce catalog data imported from suppliers at scale, the customer might prefer a high confidence value threshold with high accuracy because even a small percentage of falsely flagged content can generate a lot of overhead for their human review teams and suppliers.
Document and entity-level accuracy
At the document level, for example, in the case of an invoice or receipt, an error of only one character in the entire document might be rated insignificant. But if that error is in the text that represents the paid amount, the entire invoice or receipt might get flagged as incorrect.
Another useful metric is the entity error rate (EER). It's the percentage of incorrectly extracted entities, such as names, prices, amounts, and phone numbers, out of the total number of the corresponding entities in one or more documents. For example, for a total of 30 words representing 10 names, 2 incorrect words out of 30 equals 0.06 (6%) WER. But if that results in 2 names out of 10 as incorrect, the Name EER is 0.20 (20%), which is much higher than the WER.
Measuring both WER and EER is a useful exercise to get a full perspective on document understanding accuracy.
Best practices for improving system performance
Consider the following points about limitations and performance:
The service supports images and documents. For the allowable limits for number of pages, image sizes, paper sizes, and file sizes, see What is Document Intelligence?.
- Many variables can affect the accuracy of the OCR results upon which Document Intelligence depends. These variables include document scan quality, resolution, contrast, light conditions, rotation, and text attributes such as size, color, and density. For example, we recommend that the image be at least 50 x 50 pixels. Refer to the product specifications and test the service on your documents to validate the fit for your situation.
- Note the limitations of each service with regard to currently supported inputs, languages and locales, and document types. For example, refer to the Layout supported languages.
Best practices to improve custom model quality
When you're using the Document Intelligence custom model, you provide your own training data so that the model can train to your specific forms and documents. The following list uses the custom form model type to share starter tips for improving your model quality.
- For filled-in forms, use examples that have all of their fields filled in.
- Use forms with real-world values that you expect to see for each field.
- If your form images are of lower quality, use a larger data set (at least 10-15 images, for example).
For a full guide and input requirements, see Build a training data set for a custom model.
Evaluation of Document Intelligence
Document Intelligence's performance will vary depending on the real-world solutions for which it's implemented. To ensure optimal performance in their scenarios, customers should conduct their own evaluations. The service provides a confidence value in the range between 0 and 1 for each extracted word and key-value mapping. Customers should run a pilot or a proof of concept representing their use case to understand the range of confidence values and the extraction quality from Document Intelligence. They can then estimate the confidence value thresholds for the results to be either sent for straight-through processing (STP) or reviewed by a human. For example, the customer might submit results with confidence values greater than or equal to .80 for straight-through processing and apply human review to results with confidence values less than .80.
Evaluating and integrating Document Intelligence for your use
Microsoft wants to help you responsibly develop and deploy solutions that use Document Intelligence. We're taking a principled approach to upholding personal agency and dignity by considering the AI systems' fairness, reliability and safety, privacy and security, inclusiveness, transparency, and human accountability. These considerations are in line with our commitment to developing Responsible AI.
When you're getting ready to deploy AI-powered products or features, the following activities help to set you up for success:
Understand what it can do: Fully assess the potential of Document Intelligence to understand its capabilities and limitations. Understand how it will perform in your particular scenario and context. For example, if you're using the prebuilt invoice model, test with real-world invoices from your business processes to analyze and benchmark the results against your existing process metrics.
Respect an individual's right to privacy: Only collect data and information from individuals for lawful and justifiable purposes. Only use data and information that you have consent to use for this purpose.
Legal review: Obtain appropriate legal review, particularly if you plan to use it in sensitive or high-risk applications. Understand what restrictions you might need to work within, and your responsibility to resolve any issues that might come up in the future.
Human-in-the-loop: Keep a human in the loop, and include human oversight as a consistent pattern area to explore. This means ensuring constant human oversight of the AI-powered product or feature and to maintain the role of humans in decision-making. Ensure that you can have real-time human intervention in the solution to prevent harm. A human in the loop enables you to manage situations when Document Intelligence does not perform as required.
Security: Ensure your solution is secure and that it has adequate controls to preserve the integrity of your content and prevent unauthorized access.
Recommendations for preserving privacy
A successful privacy approach empowers individuals with information and provides controls and protection to preserve their privacy.
- If Document Intelligence is part of a solution designed to incorporate personally identifiable information (PII), think carefully about whether and how to record that data. Follow applicable national and regional regulations on privacy and sensitive data.
- Privacy managers should consider the retention policies on the extracted text and values, and the underlying documents or images of those documents. The retention policies will be tied to the intended use of each application.
Learn more about responsible AI
- Microsoft AI principles
- Microsoft responsible AI resources
- Microsoft Azure Learning courses on responsible AI