Lernprogramm: Verwenden von Aggregationsfunktionen
Gilt für: ✅Microsoft Fabric✅Azure Data Explorer✅Azure Monitor✅Microsoft Sentinel
Mithilfe von Aggregationsfunktionen können Sie Daten aus mehreren Zeilen in einen Zusammenfassungswert gruppieren und kombinieren. Der Zusammenfassungswert hängt von der ausgewählten Funktion ab, z. B. einer Anzahl, einem Maximum oder einem Mittelwert.
In diesem Tutorial lernen Sie Folgendes:
- Verwenden des Zusammenfassungsoperators
- Visualisieren von Abfrageergebnissen
- Bedingte Anzahl von Zeilen
- Gruppieren von Daten in Container
- Berechnen von Min., Max., Mittelwert und Summe
- Berechnen von Prozentsätzen
- Extrahieren eindeutiger Werte
- Bucketdaten nach Bedingung
- Durchführen der Aggregation über ein gleitendes Fenster
Die Beispiele in diesem Lernprogramm verwenden die StormEvents Tabelle, die im Hilfecluster öffentlich verfügbar ist. Um ihre eigenen Daten zu erkunden, erstellen Sie Ihren eigenen kostenlosen Cluster.
In den Beispielen in diesem Lernprogramm wird die StormEvents Tabelle verwendet, die in den Beispieldaten der Wetteranalyse öffentlich verfügbar ist.
Dieses Lernprogramm baut auf der Grundlage des ersten Lernprogramms auf, lernen Sie allgemeine Operatoren kennen.
Voraussetzungen
Zum Ausführen der folgenden Abfragen benötigen Sie eine Abfrageumgebung mit Zugriff auf die Beispieldaten. Sie können eine der folgenden Anwendungen verwenden:
- Ein Microsoft-Konto oder eine Microsoft Entra-Benutzeridentität, um sich beim Hilfecluster anzumelden
- Ein Microsoft-Konto oder eine Microsoft Entra-Benutzeridentität
- Ein Fabric-Arbeitsbereich mit einer Microsoft Fabric-fähigen Kapazität
Verwenden des summarize-Operators
Der Zusammenfassungsoperator ist für die Durchführung von Aggregationen über Ihre Daten unerlässlich. Der summarize Operator gruppiert Zeilen basierend auf der by Klausel und verwendet dann die bereitgestellte Aggregationsfunktion, um jede Gruppe in einer einzelnen Zeile zu kombinieren.
Suchen Sie die Anzahl von Ereignissen anhand des Zustands mithilfe summarize der Count Aggregation-Funktion.
StormEvents
| summarize TotalStorms = count() by State
Ausgabe
| State | TotalStorms |
|---|---|
| TEXAS | 4701 |
| KANSAS | 3166 |
| IOWA | 2337 |
| ILLINOIS | 2022 |
| MISSOURI | 2016 |
| ... | ... |
Visualisieren von Abfrageergebnissen
Durch die Visualisierung von Abfrageergebnissen in einem Diagramm können Sie Muster, Trends und Ausreißer in Ihren Daten identifizieren. Dazu können Sie den Renderoperator verwenden.
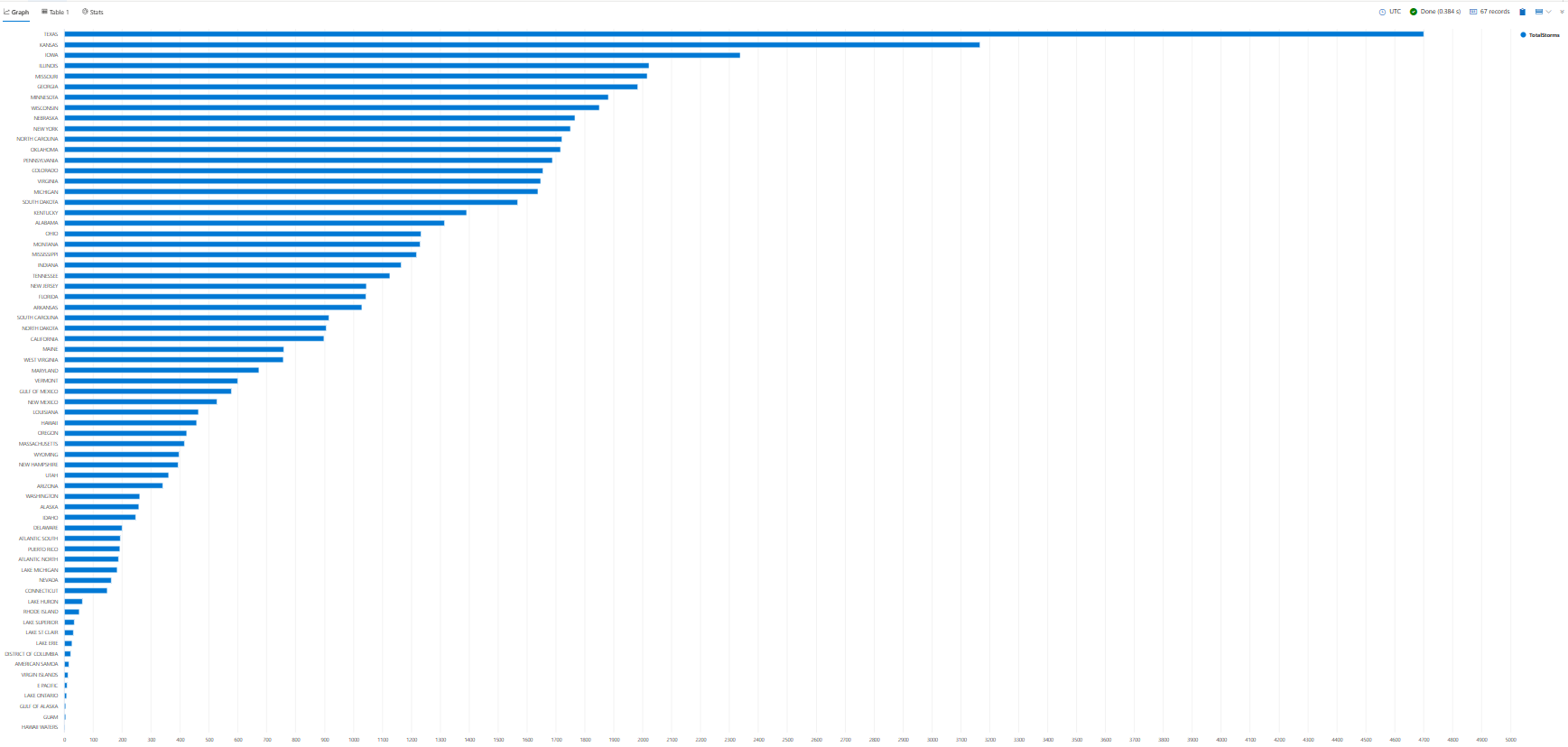
Im gesamten Lernprogramm sehen Sie Beispiele für die Verwendung render zum Anzeigen Ihrer Ergebnisse. Lassen render Sie uns nun die Ergebnisse aus der vorherigen Abfrage in einem Balkendiagramm anzeigen.
StormEvents
| summarize TotalStorms = count() by State
| render barchart
Bedingte Anzahl von Zeilen
Verwenden Sie beim Analysieren Ihrer Daten zählen Sie mithilfe von Countif() Zeilen basierend auf einer bestimmten Bedingung, um zu verstehen, wie viele Zeilen den angegebenen Kriterien entsprechen.
Die folgende Abfrage verwendet countif() die Anzahl von Stürmen, die Schäden verursacht haben. Die Abfrage verwendet dann den top Operator, um die Ergebnisse zu filtern und die Zustände mit der höchsten Menge an Zuschneideschäden anzuzeigen, die durch Stürme verursacht werden.
StormEvents
| summarize StormsWithCropDamage = countif(DamageCrops > 0) by State
| top 5 by StormsWithCropDamage
Ausgabe
| State | StormsWithCropDamage |
|---|---|
| IOWA | 359 |
| NEBRASKA | 201 |
| MISSISSIPPI | 105 |
| NORTH CAROLINA | 82 |
| MISSOURI | 78 |
Gruppieren von Daten in Container
Um nach numerischen oder Zeitwerten zu aggregieren, sollten Sie die Daten zunächst mithilfe der Bin() -Funktion in Bins gruppieren. Die Verwendung bin() kann Ihnen helfen, zu verstehen, wie Werte innerhalb eines bestimmten Bereichs verteilt werden und Vergleiche zwischen verschiedenen Zeiträumen durchführen.
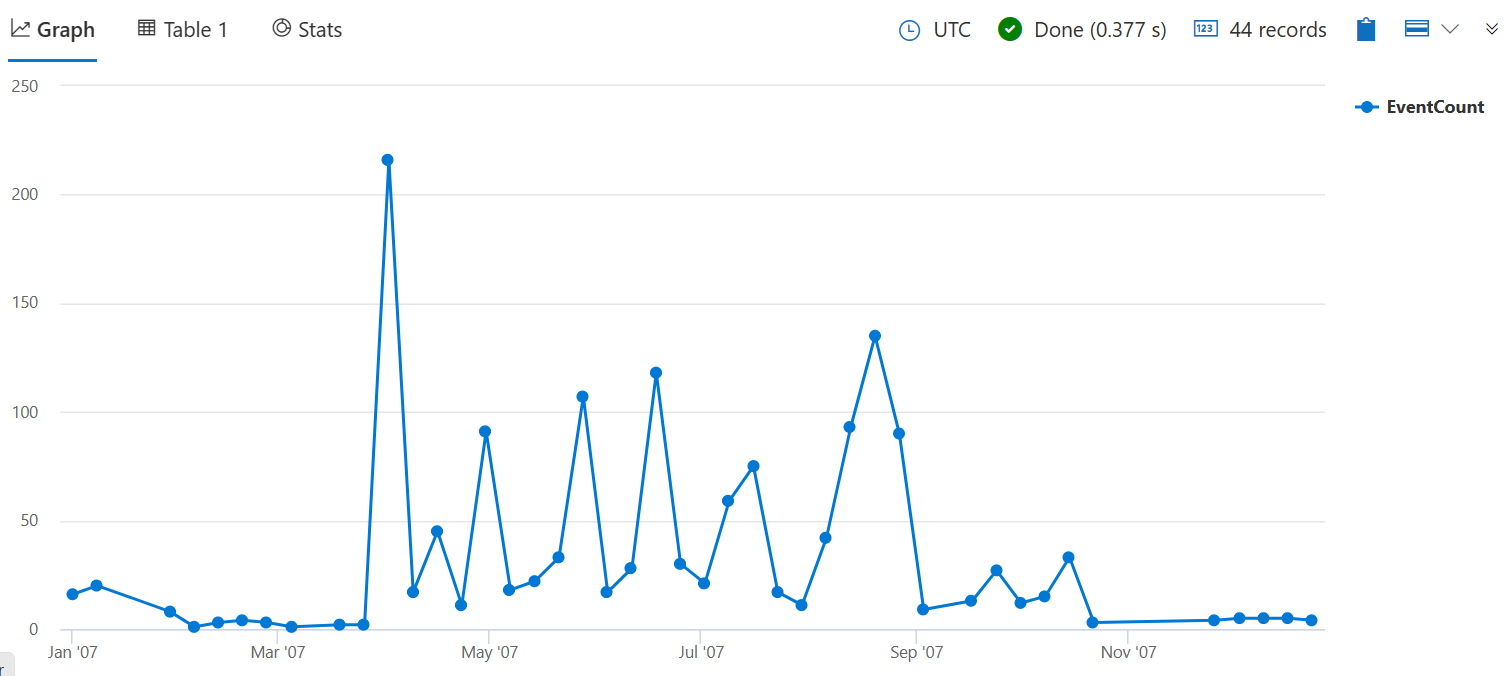
Die folgende Abfrage zählt die Anzahl der Stürme, die 2007 Zuschneideschäden für jede Woche verursacht haben. Das 7d Argument stellt eine Woche dar, da für die Funktion ein gültiger Zeitbereichswert erforderlich ist.
StormEvents
| where StartTime between (datetime(2007-01-01) .. datetime(2007-12-31))
and DamageCrops > 0
| summarize EventCount = count() by bin(StartTime, 7d)
Output
| StartTime | EventCount |
|---|---|
| 2007-01-01T00:00:00Z | 16 |
| 2007-01-08T00:00:00Z | 20 |
| 2007-01-29T00:00:00Z | 8 |
| 2007-02-05T00:00:00Z | 1 |
| 2007-02-12T00:00:00Z | 3 |
| ... | ... |
Fügen Sie zum Ende der Abfrage hinzu | render timechart , um die Ergebnisse zu visualisieren.
Hinweis
bin() ähnelt der floor() Funktion in anderen Programmiersprachen. Er reduziert jeden Wert auf das nächste Vielfache des von Ihnen angegebenen Moduls und ermöglicht summarize das Zuweisen der Zeilen zu Gruppen.
Berechnen von Min., Max., Mittelwert und Summe
Weitere Informationen zu Arten von Stürmen, die Zuschneideschäden verursachen, berechnen sie min (), max() und avg() Zuschneideschäden für jeden Ereignistyp, und sortieren Sie dann das Ergebnis nach dem durchschnittlichen Schaden.
Beachten Sie, dass Sie mehrere Aggregationsfunktionen in einem einzigen summarize Operator verwenden können, um mehrere berechnete Spalten zu erzeugen.
StormEvents
| where DamageCrops > 0
| summarize
MaxCropDamage=max(DamageCrops),
MinCropDamage=min(DamageCrops),
AvgCropDamage=avg(DamageCrops)
by EventType
| sort by AvgCropDamage
Ausgabe
| EventType | MaxCropDamage | MinCropDamage | AvgCropDamage |
|---|---|---|---|
| Frost/Freeze | 568600000 | 3000 | 9106087.5954198465 |
| Wildfire | 21000000 | 10000 | 7268333.333333333 |
| Dürre | 700000000 | 2.000 | 6763977.8761061952 |
| Hochwasser | 500000000 | 1.000 | 4844925.23364486 |
| Sturm | 22000000 | 100 | 920328.36538461538 |
| ... | ... | ... | ... |
Die Ergebnisse der vorherigen Abfrage deuten darauf hin, dass Frost/Freeze-Ereignisse im Durchschnitt zu den meisten Zuschneideschäden geführt haben. Die Bin()-Abfrage zeigte jedoch, dass Ereignisse mit Zuschneideschäden hauptsächlich in den Sommermonaten stattfanden.
Verwenden Sie Summe(), um die Gesamtanzahl der beschädigten Kulturen anstelle der Anzahl der Ereignisse zu überprüfen, die einen Schaden verursacht haben, wie in count() der vorherigen Bin()-Abfrage.
StormEvents
| where StartTime between (datetime(2007-01-01) .. datetime(2007-12-31))
and DamageCrops > 0
| summarize CropDamage = sum(DamageCrops) by bin(StartTime, 7d)
| render timechart
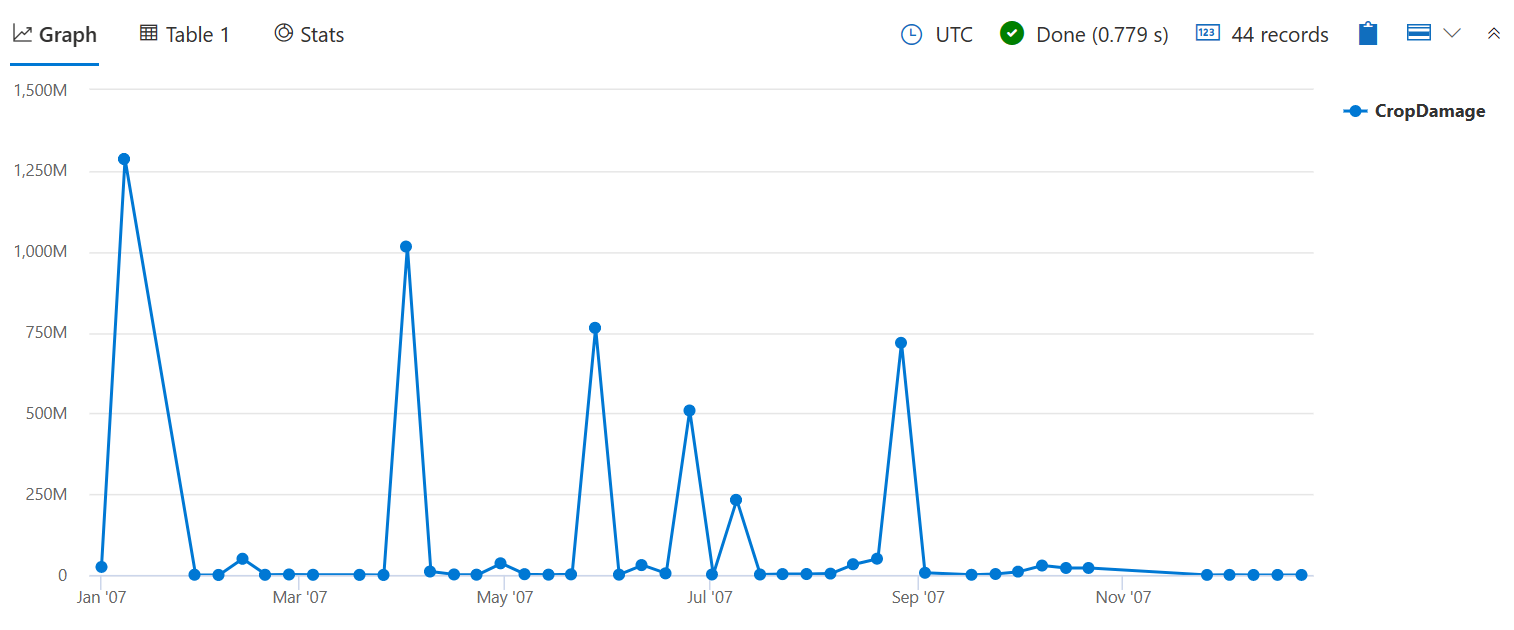
Jetzt können Sie im Januar einen Höhepunkt der Ernteschäden sehen, was wahrscheinlich auf Frost/Freeze zurückzuführen war.
Tipp
Verwenden Sie minif(), maxif(), avgif() und sumif(), um bedingte Aggregationen auszuführen, wie im Abschnitt mit bedingter Anzahl von Zeilen .
Berechnen von Prozentsätzen
Die Berechnung von Prozentsätzen kann Ihnen dabei helfen, die Verteilung und den Anteil verschiedener Werte in Ihren Daten zu verstehen. In diesem Abschnitt werden zwei allgemeine Methoden zum Berechnen von Prozentsätzen mit dem Kusto-Abfragesprache (KQL) behandelt.
Berechnen des Prozentsatzes basierend auf zwei Spalten
Verwenden Sie count() und countif , um den Prozentsatz der Sturmereignisse zu finden, die Zuschneideschäden in jedem Zustand verursacht haben. Zählen Sie zunächst die Gesamtzahl der Stürme in jedem Bundesland. Zählen Sie dann die Anzahl der Stürme, die zu Ernteschäden in jedem Zustand geführt haben.
Verwenden Sie dann "Extend ", um den Prozentsatz zwischen den beiden Spalten zu berechnen, indem Sie die Anzahl der Stürme durch die Gesamtanzahl der Sturmschäden dividieren und mit 100 multiplizieren.
Um sicherzustellen, dass Sie ein Dezimalergebnis erhalten, verwenden Sie die Todouble() -Funktion, um mindestens einen der Ganzzahlwerte in ein Double zu konvertieren, bevor Sie die Division ausführen.
StormEvents
| summarize
TotalStormsInState = count(),
StormsWithCropDamage = countif(DamageCrops > 0)
by State
| extend PercentWithCropDamage =
round((todouble(StormsWithCropDamage) / TotalStormsInState * 100), 2)
| sort by StormsWithCropDamage
Ausgabe
| State | TotalStormsInState | StormsWithCropDamage | PercentWithCropDamage |
|---|---|---|---|
| IOWA | 2337 | 359 | 15.36 |
| NEBRASKA | 1766 | 201 | 11.38 |
| MISSISSIPPI | 1218 | 105 | 8,62 |
| NORTH CAROLINA | 1721 | 82 | 4.76 |
| MISSOURI | 2016 | 78 | 3,87 |
| ... | ... | ... | ... |
Hinweis
Konvertieren Sie bei der Berechnung von Prozentsätzen mindestens einen der ganzzahligen Werte in der Division mit "todouble()" oder "toreal()". Dadurch wird sichergestellt, dass Sie aufgrund der ganzzahligen Division keine abgeschnittenen Ergebnisse erhalten. Weitere Informationen finden Sie unter Typregeln für arithmetische Vorgänge.
Berechnen des Prozentsatzes basierend auf der Tabellengröße
Um die Anzahl der Stürme nach Ereignistyp mit der Gesamtzahl der Stürme in der Datenbank zu vergleichen, speichern Sie zuerst die Gesamtzahl der Stürme in der Datenbank als Variable. Let-Anweisungen werden verwendet, um Variablen innerhalb einer Abfrage zu definieren.
Da tabellarische Ausdrucksanweisungen tabellarische Ergebnisse zurückgeben, verwenden Sie die Toscalar() -Funktion, um das tabellarische Ergebnis der count() Funktion in einen skalaren Wert zu konvertieren. Anschließend kann der numerische Wert in der Prozentberechnung verwendet werden.
let TotalStorms = toscalar(StormEvents | summarize count());
StormEvents
| summarize EventCount = count() by EventType
| project EventType, EventCount, Percentage = todouble(EventCount) / TotalStorms * 100.0
Ausgabe
| EventType | EventCount | Percentage |
|---|---|---|
| Sturm | 13015 | 22.034673077574237 |
| Hagel | 12711 | 21.519994582331627 |
| Überschwemmung | 3688 | 6.2438627975485055 |
| Dürre | 3616 | 6.1219652592015716 |
| Winterwetter | 3349 | 5.669928554498358 |
| ... | ... | ... |
Extrahieren eindeutiger Werte
Verwenden Sie make_set(), um eine Auswahl von Zeilen in einer Tabelle in ein Array eindeutiger Werte umzuwandeln.
Die folgende Abfrage verwendet make_set() , um ein Array der Ereignistypen zu erstellen, die zu Todesfällen in jedem Zustand führen. Die resultierende Tabelle wird dann nach der Anzahl der Sturmtypen in den einzelnen Arrays sortiert.
StormEvents
| where DeathsDirect > 0 or DeathsIndirect > 0
| summarize StormTypesWithDeaths = make_set(EventType) by State
| project State, StormTypesWithDeaths
| sort by array_length(StormTypesWithDeaths)
Ausgabe
| State | StormTypesWithDeaths |
|---|---|
| CALIFORNIA | ["Thunderstorm Wind","High Surf","Cold/Wind Chill","Strong Wind","Rip Current","Heat","Exzessive Hitze","Wildfire","Staubsturm","Astronomisches Ebbe","Dichte Nebel","Winterwetter"] |
| TEXAS | ["Flash Flood","Thunderstorm Wind","Tornado","Lightning","Flood","Ice Storm","Winter Weather","Rip Current","Excessive Heat","Dense Fog","Hurricane (Typhoon)","Cold/Wind Chill"] |
| OKLAHOMA | ["Flash Flood","Tornado","Cold/Wind Chill","Wintersturm","Schwerer Schnee","Übermäßige Hitze","Hitze","Eissturm","Winterwetter","Dichter Nebel"] |
| NEW YORK | ["Flut","Blitz","Gewitterwind","Blitzflut","Winterwetter","Eissturm","Extremer Kälte/Windkühl","Wintersturm","Schwerer Schnee"] |
| KANSAS | ["Thunderstorm Wind","Heavy Rain","Tornado","Flood","Flash Flood","Lightning","Heavy Snow","Winter Weather","Blizzard"] |
| ... | ... |
Bucketdaten nach Bedingung
Die Case()- Funktion gruppiert Daten basierend auf angegebenen Bedingungen in Buckets. Die Funktion gibt den entsprechenden Ergebnisausdruck für das erste zufriedene Prädikat oder den endgültigen anderen Ausdruck zurück, wenn keines der Prädikate erfüllt ist.
In diesem Beispiel werden Staaten basierend auf der Anzahl der stürmischen Verletzungen gruppiert, die ihre Bürger erlitten haben.
StormEvents
| summarize InjuriesCount = sum(InjuriesDirect) by State
| extend InjuriesBucket = case (
InjuriesCount > 50,
"Large",
InjuriesCount > 10,
"Medium",
InjuriesCount > 0,
"Small",
"No injuries"
)
| sort by State asc
Ausgabe
| State | VerletzungenAnzahl | VerletzungenBucket |
|---|---|---|
| ALABAMA | 494 | Large |
| ALASKA | 0 | Keine Verletzungen |
| AMERIKANISCH-SAMOA | 0 | Keine Verletzungen |
| ARIZONA | 6 | Klein |
| ARKANSAS | 54 | Large |
| ATLANTIC NORTH | 15 | Medium |
| ... | ... | ... |
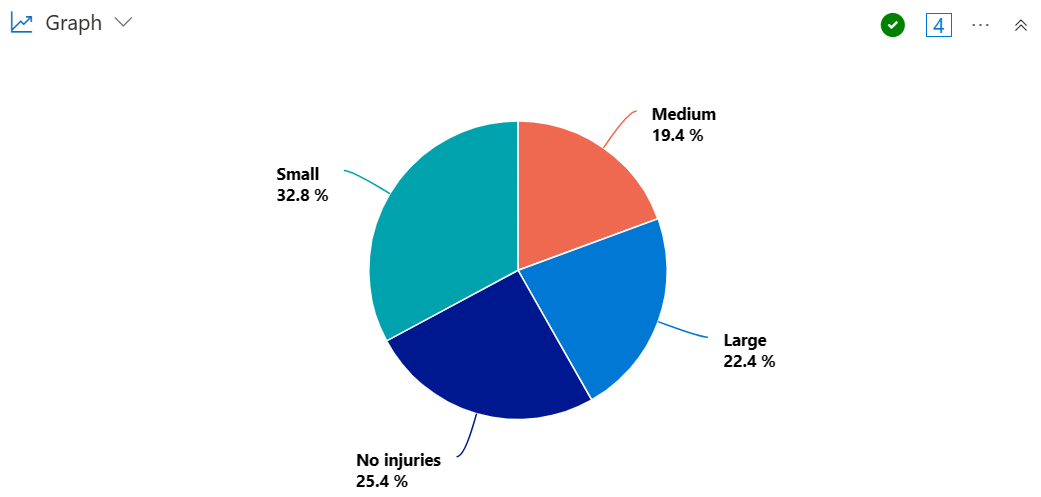
Erstellen Sie ein Kreisdiagramm, um den Anteil der Zustände zu visualisieren, die zu einer großen, mittleren oder kleinen Anzahl von Verletzungen führen.
StormEvents
| summarize InjuriesCount = sum(InjuriesDirect) by State
| extend InjuriesBucket = case (
InjuriesCount > 50,
"Large",
InjuriesCount > 10,
"Medium",
InjuriesCount > 0,
"Small",
"No injuries"
)
| summarize InjuryBucketByState=count() by InjuriesBucket
| render piechart
Durchführen von Aggregation über ein gleitendes Fenster
Das folgende Beispiel zeigt, wie Spalten mithilfe eines gleitenden Fensters zusammengefasst werden.
Die Abfrage berechnet den minimalen, maximalen und durchschnittlichen Schaden von Tornados, Überschwemmungen und Waldbränden mithilfe eines Gleitfensters von sieben Tagen. Jeder Datensatz im Resultset aggregiert die vorangegangenen sieben Tage, und die Ergebnisse enthalten einen Datensatz pro Tag im Analysezeitraum.
Hier ist eine schrittweise Erläuterung der Abfrage:
- Bin jeder Datensatz in einem einzelnen Tag relativ zu
windowStart. - Fügen Sie dem Bin-Wert sieben Tage hinzu, um das Ende des Bereichs für jeden Datensatz festzulegen. Wenn sich der Wert außerhalb des Bereichs befindet
windowStart, undwindowEndpassen Sie den Wert entsprechend an. - Erstellen Sie ein Array von sieben Tagen für jeden Datensatz ab dem aktuellen Tag des Datensatzes.
- Erweitern Sie das Array aus Schritt 3 mit mv-expand , um jeden Datensatz mit 1-Tages-Intervallen zwischen ihnen zu duplizieren.
- Führen Sie die Aggregationen für jeden Tag aus. Aufgrund von Schritt 4 fasst dieser Schritt tatsächlich die vorherigen sieben Tage zusammen.
- Schließen Sie die ersten sieben Tage vom Endergebnis aus, da es keinen Sieben-Tage-Lookbackzeitraum für sie gibt.
let windowStart = datetime(2007-07-01);
let windowEnd = windowStart + 13d;
StormEvents
| where EventType in ("Tornado", "Flood", "Wildfire")
| extend bin = bin_at(startofday(StartTime), 1d, windowStart) // 1
| extend endRange = iff(bin + 7d > windowEnd, windowEnd,
iff(bin + 7d - 1d < windowStart, windowStart,
iff(bin + 7d - 1d < bin, bin, bin + 7d - 1d))) // 2
| extend range = range(bin, endRange, 1d) // 3
| mv-expand range to typeof(datetime) // 4
| summarize min(DamageProperty), max(DamageProperty), round(avg(DamageProperty)) by Timestamp=bin_at(range, 1d, windowStart), EventType // 5
| where Timestamp >= windowStart + 7d; // 6
Output
Die folgende Ergebnistabelle wird abgeschnitten. Führen Sie die Abfrage aus, um die vollständige Ausgabe anzuzeigen.
| Timestamp | EventType | min_DamageProperty | max_DamageProperty | avg_DamageProperty |
|---|---|---|---|---|
| 2007-07-08T00:00:00Z | Tornado | 0 | 30.000 | 6905 |
| 2007-07-08T00:00:00Z | Hochwasser | 0 | 200000 | 9261 |
| 2007-07-08T00:00:00Z | Wildfire | 0 | 200000 | 14033 |
| 2007-07-09T00:00:00Z | Tornado | 0 | 100.000 | 14783 |
| 2007-07-09T00:00:00Z | Hochwasser | 0 | 200000 | 12529 |
| 2007-07-09T00:00:00Z | Wildfire | 0 | 200000 | 14033 |
| 2007-07-10T00:00:00Z | Tornado | 0 | 100.000 | 31400 |
| 2007-07-10T00:00:00Z | Hochwasser | 0 | 200000 | 12,263 |
| 2007-07-10T00:00:00Z | Wildfire | 0 | 200000 | 11694 |
| ... | ... | ... |
Nächster Schritt
Nachdem Sie nun mit allgemeinen Abfrageoperatoren und Aggregationsfunktionen vertraut sind, fahren Sie mit dem nächsten Lernprogramm fort, um zu erfahren, wie Sie Daten aus mehreren Tabellen verknüpfen.