Lernprogramm: Verknüpfen von Daten aus mehreren Tabellen
Gilt für: ✅Microsoft Fabric✅Azure Data Explorer✅Azure Monitor✅Microsoft Sentinel
Das Verknüpfen von Daten aus mehreren Tabellen ermöglicht eine umfassendere Analyse, indem Informationen aus verschiedenen Quellen kombiniert und neue Beziehungen zwischen Datenpunkten erstellt werden. Im Kusto-Abfragesprache (KQL) werden die Verknüpfungs- und Nachschlageoperatoren verwendet, um Daten über Tabellen hinweg zu kombinieren.
In diesem Tutorial lernen Sie Folgendes:
Die Beispiele in diesem Lernprogramm verwenden die StormEvents Tabelle, die im Hilfecluster öffentlich verfügbar ist. Um ihre eigenen Daten zu erkunden, erstellen Sie Ihren eigenen kostenlosen Cluster.
In den Beispielen in diesem Lernprogramm wird die StormEvents Tabelle verwendet, die in den Beispieldaten der Wetteranalyse öffentlich verfügbar ist.
Voraussetzungen
Zum Ausführen der folgenden Abfragen benötigen Sie eine Abfrageumgebung mit Zugriff auf die Beispieldaten. Sie können eine der folgenden Anwendungen verwenden:
- Ein Microsoft-Konto oder eine Microsoft Entra-Benutzeridentität, um sich beim Hilfecluster anzumelden
- Ein Microsoft-Konto oder eine Microsoft Entra-Benutzeridentität
- Ein Fabric-Arbeitsbereich mit einer Microsoft Fabric-fähigen Kapazität
Verwenden des Verknüpfungsoperators
Es gibt zwei Tabellen in der Beispieldatenbank im Zusammenhang mit Sturmereignissen. Man wird aufgerufen StormEvents , und der andere wird aufgerufen PopulationData. In diesem Abschnitt verknüpfen Sie die Tabellen, um Datenanalysen durchzuführen, die mit einer einzigen Tabelle nicht möglich wären.
Grundlegendes zu den Daten
Verwenden Sie den Operator "Take ", um zu sehen, welche Daten jede Tabelle enthält.
StormEvents
| take 5
In der folgenden Tabelle sind nur 6 der 22 zurückgegebenen Spalten aufgeführt.
| StartTime | EndTime | EpisodeId | EventId | State | EventType | ... |
|---|---|---|---|---|---|---|
| 2007-09-20T21:57:00Z | 2007-09-20T22:05:00Z | 11078 | 60913 | FLORIDA | Tornado | ... |
| 2007-12-20T07:50:00Z | 2007-12-20T07:53:00Z | 12,554 | 68796 | MISSISSIPPI | Sturm | ... |
| 2007-12-30T16:00:00Z | 2007-12-30T16:05:00Z | 11749 | 64588 | GEORGIA | Sturm | ... |
| 2007-09-29T08:11:00Z | 2007-09-29T08:11:00Z | 11091 | 61032 | ATLANTIC SOUTH | Waterspout | ... |
| 2007-09-18T20:00:00Z | 2007-09-19T18:00:00Z | 11074 | 60904 | FLORIDA | Starker Regen | ... |
PopulationData
| take 5
Ausgabe
| State | Auffüllung |
|---|---|
| ALABAMA | 4918690 |
| ALASKA | 727951 |
| ARIZONA | 7399410 |
| ARKANSAS | 3025880 |
| CALIFORNIA | 39562900 |
Beide Tabellen enthalten eine State Spalte. Die StormEvents Tabelle enthält viele weitere Spalten, und die PopulationData Spalte enthält nur eine andere Spalte, die die Population des angegebenen Zustands enthält.
Verknüpfen der Tabellen
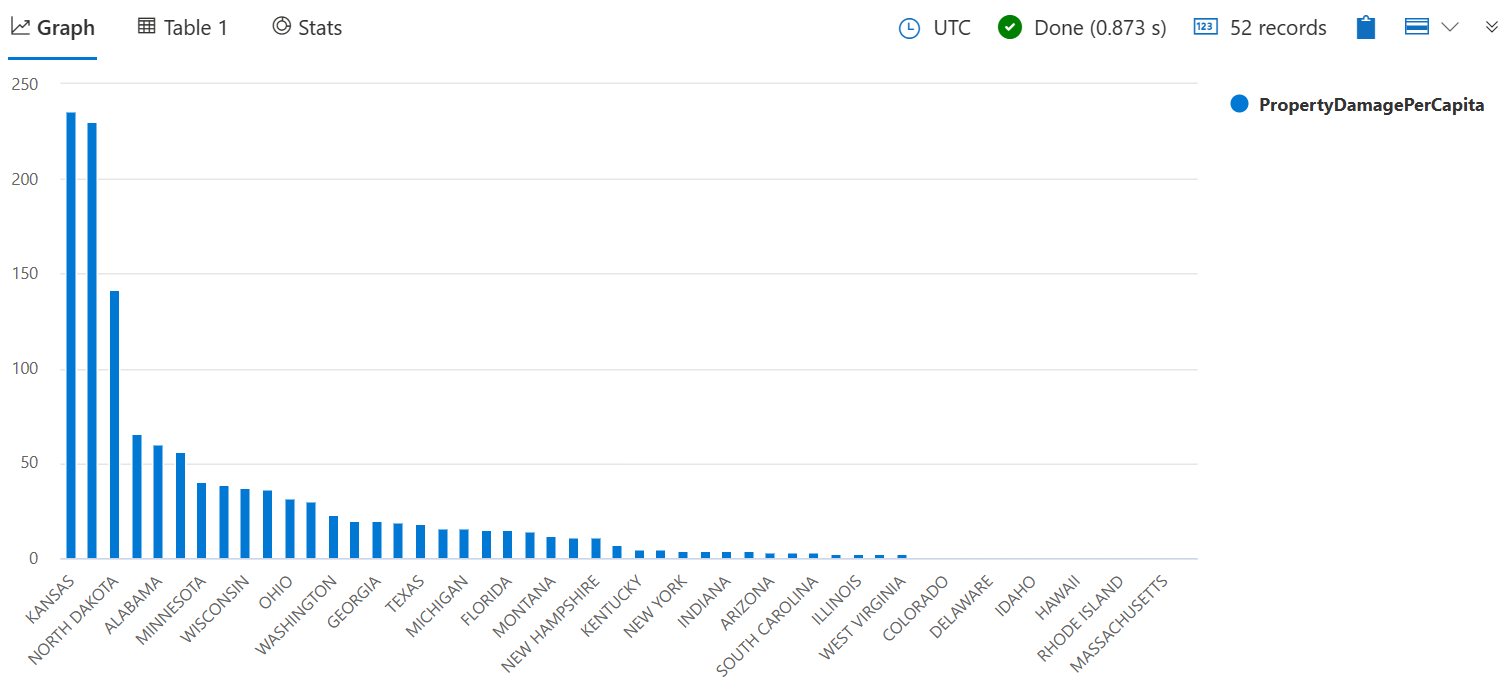
Verbinden Sie die PopulationData Tabelle mit StormEvents der gemeinsamen State Spalte, um den Gesamtschaden zu finden, der durch Stürme pro Kopf pro Staat verursacht wird.
StormEvents
| summarize PropertyDamage = sum(DamageProperty) by State
| join kind=innerunique PopulationData on State
| project State, PropertyDamagePerCapita = PropertyDamage / Population
| sort by PropertyDamagePerCapita
Fügen Sie | render columnchart der Abfrage hinzu, um das Ergebnis zu visualisieren.
Tipp
Es gibt viele Arten von Verknüpfungen, die Sie mit dem join Operator ausführen können. Sehen Sie sich eine Liste der Verknüpfungsaromen an.
Verwenden des Nachschlageoperators
Der Nachschlageoperator optimiert die Leistung von Abfragen, bei denen eine Faktentabelle mit Daten aus einer Dimensionstabelle erweitert wird. Er erweitert die Faktentabelle um Werte, die in einer Dimensionstabelle nachgeschlagen werden. Für eine optimale Leistung geht das System standardmäßig davon aus, dass die linke Tabelle die größere Faktentabelle ist, und die rechte Tabelle ist die kleinere Dimensionstabelle. Dies ist das genaue Gegenteil zu der Annahme, die vom join-Operator verwendet wird.
Im Hilfecluster gibt es eine andere Datenbank ContosoSales , die Verkaufsdaten enthält. Die folgende Abfrage verwendet lookup , um die SalesFact Tabellen aus Products dieser Datenbank zusammenzuführen, um den Gesamtumsatz nach Produktkategorie abzurufen.
SalesFact
| lookup Products on ProductKey
| summarize TotalSales = count() by ProductCategoryName
| order by TotalSales desc
Output
| ProductCategoryName | TotalSales |
|---|---|
| Games and Toys | 966782 |
| TV and Video | 715024 |
| Cameras and camcorders | 323003 |
| Computer | 313487 |
| Home Appliances | 237508 |
| Audio | 192671 |
| Cell phones | 50342 |
| Music, Movies and Audio Books | 33376 |
Hinweis
Der lookup Operator unterstützt nur zwei Verknüpfungsrichtungen: leftouter und inner.
Verknüpft abfragegenerierte Tabellen
Verknüpfungen können auch basierend auf Abfrageergebnissen aus derselben Tabelle ausgeführt werden.
Angenommen, Sie möchten eine Liste von Zuständen erstellen, in denen Blitz- und Lawinenereignisse aufgetreten sind. Verwenden Sie den Verknüpfungsoperator, um die Zeilen von zwei Tabellen zusammenzuführen, die Daten zu Blitzereignissen und die andere enthaltende Daten zu Lawinenereignissen basierend auf der State Spalte.
StormEvents
| where EventType == "Lightning"
| distinct State
| join kind=inner (
StormEvents
| where EventType == "Avalanche"
| distinct State
)
on State
| project State
Ausgabe
| State |
|---|
| OREGON |
| UTAH |
| WYOMING |
| WASHINGTON |
| COLORADO |
| IDAHO |
| NEVADA |
Zugehöriger Inhalt
- Informationen zu verschiedenen Arten von Join-Operatoren
- Erfahren Sie, wie Sie datenbankübergreifende und clusterübergreifende Abfragen ausführen .
- Folgen Sie dem Lernprogramm zum Erstellen von Geospatialvisualisierungen