dcountif() (Aggregationsfunktion)
Gilt für: ✅Microsoft Fabric✅Azure Data Explorer✅Azure Monitor✅Microsoft Sentinel
Schätzt die Anzahl der unterschiedlichen Werte des Ausdrucks für Zeilen, in denen prädikat ausgewertet wird true.
Nullwerte werden ignoriert und nicht in die Berechnung berücksichtigt.
Syntax
dcountif(Ausdruck, Prädikat, [, Genauigkeit])
Erfahren Sie mehr über Syntaxkonventionen.
Parameter
| Name | Type | Erforderlich | Beschreibung |
|---|---|---|---|
| expr | string |
✔️ | Der Ausdruck, der für die Aggregationsberechnung verwendet wird. |
| Prädikat | string |
✔️ | Der Ausdruck, der zum Filtern von Zeilen verwendet wird. |
| Genauigkeit | int |
Die Kontrolle zwischen Geschwindigkeit und Genauigkeit. Wenn nichts angegeben wird, beträgt der Standardwert 1. Siehe Schätzungsgenauigkeit für unterstützte Werte. |
Gibt zurück
Gibt eine Schätzung der Anzahl der unterschiedlichen Werte des Ausdrucks für Zeilen zurück, in denen prädikat ausgewertet wird true.
Tipp
dcountif() kann einen Fehler in Fällen zurückgeben, in denen alle zeilen oder keines der Zeilen den Predicate Ausdruck übergeben.
Beispiel
In diesem Beispiel wird gezeigt, wie viele Arten von tödlichen Sturmereignissen in jedem Zustand aufgetreten sind.
StormEvents
| summarize DifferentFatalEvents=dcountif(EventType,(DeathsDirect + DeathsIndirect)>0) by State
| where DifferentFatalEvents > 0
| order by DifferentFatalEvents
Die angezeigte Ergebnistabelle enthält nur die ersten 10 Zeilen.
| State | DifferentFatalEvents |
|---|---|
| CALIFORNIA | 12 |
| TEXAS | 12 |
| OKLAHOMA | 10 |
| ILLINOIS | 9 |
| KANSAS | 9 |
| NEW YORK | 9 |
| NEW JERSEY | 7 |
| WASHINGTON | 7 |
| MICHIGAN | 7 |
| MISSOURI | 7 |
| ... | ... |
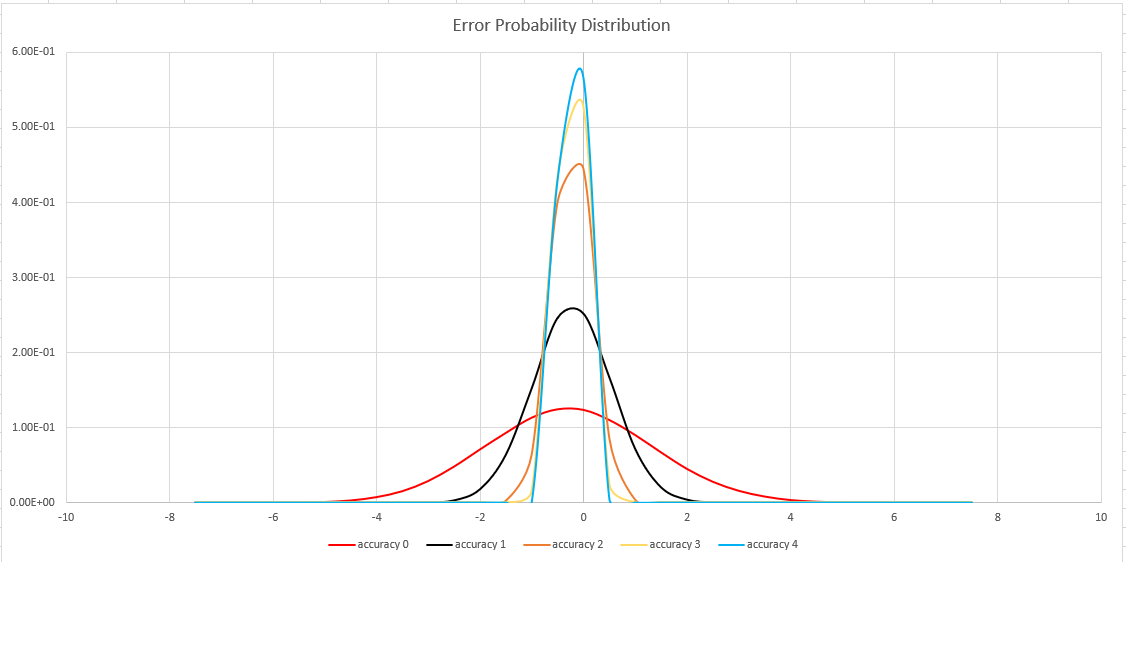
Schätzgenauigkeit
Diese Funktion verwendet eine Variante des HyperLogLog (HLL)-Algorithmus, der eine stochastische Schätzung der Set-Kardinalität durchführt. Der Algorithmus stellt einen „Knopf“ bereit, über den Genauigkeit und Ausführungszeit pro Arbeitsspeichergröße ausgeglichen werden können:
| Genauigkeit | Fehler (%) | Entry count |
|---|---|---|
| 0 | 1.6 | 212 |
| 1 | 0,8 | 214 |
| 2 | 0,4 | 216 |
| 3 | 0.28 | 217 |
| 4 | 0.2 | 218 |
Hinweis
Die Spalte „entry count“ ist die Anzahl von 1-Byte-Leistungsindikatoren in der HLL-Implementierung.
Der Algorithmus enthält einige Vorkehrungen für eine perfekte Anzahl (null Fehler), wenn die festgelegte Kardinalität klein genug ist:
- Wenn die Genauigkeitsgrad
1ist, werden 1.000 Werte zurückgegeben. - Wenn die Genauigkeitsgrad
2ist, werden 8.000 Werte zurückgegeben.
Die Fehlerbindung ist probabilistisch und keine theoretische Grenze. Der Wert ist die Standardabweichung der Fehlerverteilung (Sigma), und 99,7 % der Schätzungen weisen einen relativen Fehler von unter 3 x Sigma auf.
Die folgende Abbildung zeigt die Wahrscheinlichkeitsverteilungsfunktion des relativen Schätzfehlers in Prozent für alle unterstützten Genauigkeitseinstellungen: