series_mv_oc_anomalies_fl()
Gilt für: ✅Microsoft Fabric✅Azure Data Explorer
Die Funktion series_mv_oc_anomalies_fl() ist eine benutzerdefinierte Funktion (UDF), die multivariate Anomalien in Reihe erkennt, indem das One Class SVM-Modell von scikit-learn angewendet wird. Die Funktion akzeptiert eine Reihe als numerische dynamische Arrays, die Namen der Featurespalten und den erwarteten Prozentsatz der Anomalien aus der gesamten Datenreihe. Die Funktion trainiert für jede Serie eine Klasse SVM und markiert die Punkte, die außerhalb der Hyperkugel liegen, als Anomalien.
Voraussetzungen
- Das Python-Plug-In muss im Cluster aktiviert sein. Dies ist für die inline Python erforderlich, die in der Funktion verwendet wird.
- Das Python-Plug-In muss in der Datenbank aktiviert sein. Dies ist für die inline Python erforderlich, die in der Funktion verwendet wird.
Syntax
T | invoke series_mv_oc_anomalies_fl(, features_cols anomaly_col [ , score_col [, anomalies_pct ]])
Erfahren Sie mehr über Syntaxkonventionen.
Parameter
| Name | Type | Erforderlich | Beschreibung |
|---|---|---|---|
| features_cols | dynamic |
✔️ | Ein Array mit den Namen der Spalten, die für das multivariate Anomalieerkennungsmodell verwendet werden. |
| anomaly_col | string |
✔️ | Der Name der Spalte zum Speichern der erkannten Anomalien. |
| score_col | string |
Der Name der Spalte zum Speichern der Bewertungen der Anomalien. | |
| anomalies_pct | real |
Eine reelle Zahl im Bereich [0-50], die den erwarteten Prozentsatz der Anomalien in den Daten angibt. Standardwert: 4 %. |
Funktionsdefinition
Sie können die Funktion definieren, indem Sie den Code entweder als abfragedefinierte Funktion einbetten oder wie folgt als gespeicherte Funktion in Ihrer Datenbank erstellen:
Definieren Sie die Funktion mithilfe der folgenden Let-Anweisung. Es sind keine Berechtigungen erforderlich.
Wichtig
Eine Let-Anweisung kann nicht alleine ausgeführt werden. Auf sie muss eine tabellarische Ausdrucksanweisung folgen. Informationen zum Ausführen eines funktionierenden Beispiels series_mv_oc_anomalies_fl()finden Sie unter Beispiel.
let series_mv_oc_anomalies_fl=(tbl:(*), features_cols:dynamic, anomaly_col:string, score_col:string='', anomalies_pct:real=4.0)
{
let kwargs = bag_pack('features_cols', features_cols, 'anomaly_col', anomaly_col, 'score_col', score_col, 'anomalies_pct', anomalies_pct);
let code = ```if 1:
from sklearn.svm import OneClassSVM
features_cols = kargs['features_cols']
anomaly_col = kargs['anomaly_col']
score_col = kargs['score_col']
anomalies_pct = kargs['anomalies_pct']
dff = df[features_cols]
svm = OneClassSVM(nu=anomalies_pct/100.0)
for i in range(len(dff)):
dffi = dff.iloc[[i], :]
dffe = dffi.explode(features_cols)
svm.fit(dffe)
df.loc[i, anomaly_col] = (svm.predict(dffe) < 0).astype(int).tolist()
if score_col != '':
df.loc[i, score_col] = svm.decision_function(dffe).tolist()
result = df
```;
tbl
| evaluate hint.distribution=per_node python(typeof(*), code, kwargs)
};
// Write your query to use the function.
Beispiel
Im folgenden Beispiel wird der Aufrufoperator verwendet, um die Funktion auszuführen.
Um eine abfragedefinierte Funktion zu verwenden, rufen Sie sie nach der definition der eingebetteten Funktion auf.
let series_mv_oc_anomalies_fl=(tbl:(*), features_cols:dynamic, anomaly_col:string, score_col:string='', anomalies_pct:real=4.0)
{
let kwargs = bag_pack('features_cols', features_cols, 'anomaly_col', anomaly_col, 'score_col', score_col, 'anomalies_pct', anomalies_pct);
let code = ```if 1:
from sklearn.svm import OneClassSVM
features_cols = kargs['features_cols']
anomaly_col = kargs['anomaly_col']
score_col = kargs['score_col']
anomalies_pct = kargs['anomalies_pct']
dff = df[features_cols]
svm = OneClassSVM(nu=anomalies_pct/100.0)
for i in range(len(dff)):
dffi = dff.iloc[[i], :]
dffe = dffi.explode(features_cols)
svm.fit(dffe)
df.loc[i, anomaly_col] = (svm.predict(dffe) < 0).astype(int).tolist()
if score_col != '':
df.loc[i, score_col] = svm.decision_function(dffe).tolist()
result = df
```;
tbl
| evaluate hint.distribution=per_node python(typeof(*), code, kwargs)
};
// Usage
normal_2d_with_anomalies
| extend anomalies=dynamic(null), scores=dynamic(null)
| invoke series_mv_oc_anomalies_fl(pack_array('x', 'y'), 'anomalies', 'scores', anomalies_pct=6)
| extend anomalies=series_multiply(80, anomalies)
| render timechart
Output
Die Tabelle normal_2d_with_anomalies enthält eine Reihe von 3 Zeitreihen. Bei jeder Datenreihe werden zweidimensionale Normalverteilungen mit täglichen Anomalien um Mitternacht, 8 Uhr bzw. 4:00 Uhr hinzugefügt. Sie können dieses Beispiel-Dataset mithilfe einer Beispielabfrage erstellen.
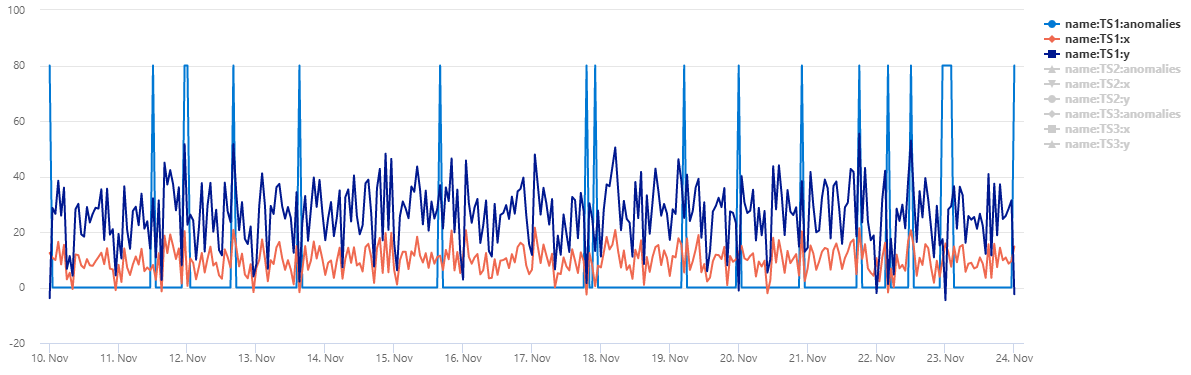
Um die Daten als Punktdiagramm anzuzeigen, ersetzen Sie den Verwendungscode durch Folgendes:
normal_2d_with_anomalies
| extend anomalies=dynamic(null)
| invoke series_mv_oc_anomalies_fl(pack_array('x', 'y'), 'anomalies')
| where name == 'TS1'
| project x, y, anomalies
| mv-expand x to typeof(real), y to typeof(real), anomalies to typeof(string)
| render scatterchart with(series=anomalies)
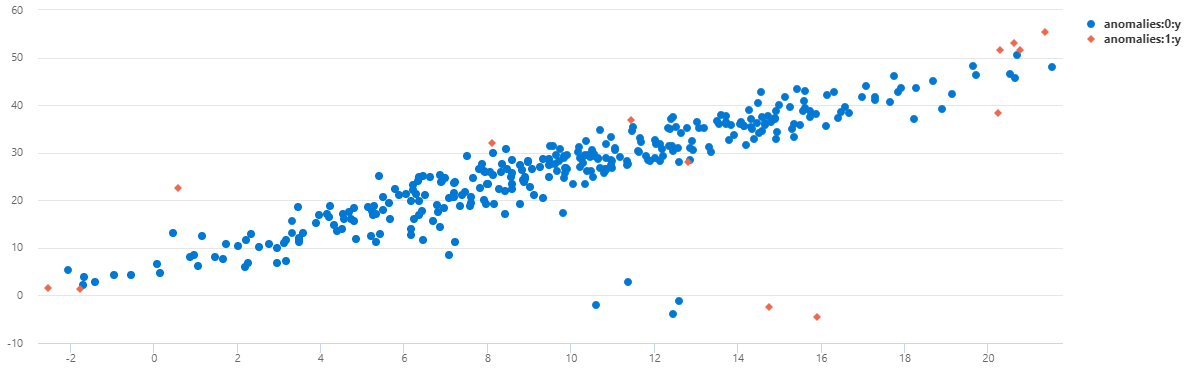
Sie können sehen, dass bei TS1 die meisten Anomalien, die bei Mitternacht auftreten, mithilfe dieses multivariaten Modells erkannt wurden.