Analysieren von Microsoft Graph-Daten in Ihrem Datenspeicher
In diesem Artikel wird ein gängiges Microsoft Graph-Integrationsmuster für ein Geschäftsszenario beschrieben, das eine komplexe Analyse von Unternehmenszusammenarbeitsdaten erfordert, um Geschäftsprozesse und Produktivität zu verbessern.
Dieses Szenario basiert auf einer großen Menge extrahierter Microsoft 365-Daten und hat die folgenden Anforderungen:
- Ein Datenintegrationstyp.
- Ein ausgehender Datenfluss von Microsoft 365-Grenzen zur App.
- Eine große Datenmenge, die sich über mehrere Monate erstreckt.
- Eine relativ hohe Datenlatenz; Der anfängliche Datenextrakt kann Nachrichten enthalten, die bis zu einem Jahr alt sind.
Die beste Option für dieses Szenario ist die Verwendung von Microsoft Graph Data Connect. Der Client muss Datenspeicher mit hoher Kapazität wie Azure Data Lake oder Azure Synapse einrichten, ein Azure-Abonnement aktivieren und eine Azure Data Factory- oder Azure Synapse-Pipeline konfigurieren.
Das folgende Diagramm zeigt die Architektur für diese Lösung.
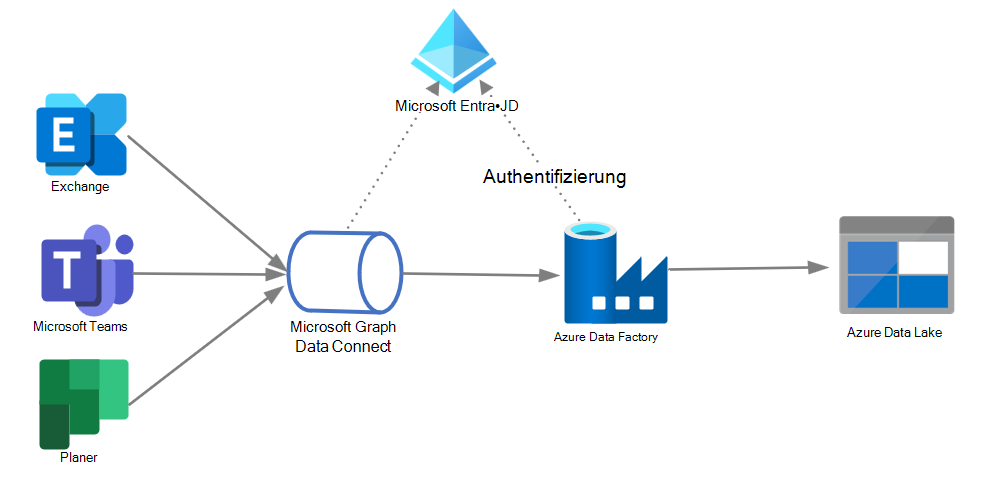
Lösungskomponenten
Die Lösungsarchitektur umfasst die folgenden Komponenten:
- Microsoft Graph Data Connect ermöglicht die Extraktion von Microsoft 365-Daten im großen Stil mit präziser Datengenehmigung und unterstützt alle nativen Azure-Dienstfunktionen wie Verschlüsselung, Geo-Fencing, Überwachung und Richtlinienerzwingung.
- Azure Data Factory (ADF) ermöglicht die einfache Erstellung von ETL-Prozessen (Extrahieren, Transformieren und Laden) und ELT-Prozessen (Extrahieren, Laden und Transformieren) in einer intuitiven Umgebung oder schreiben Ihren Code.
- Mit Azure Data Lake können Sie große Mengen von strukturierten und unstrukturierten Daten in verschiedenen Formaten speichern.
- Microsoft Entra ID, die zum Verwalten der Authentifizierung für Microsoft Graph-APIs erforderlich ist und delegierte Berechtigungen und Anwendungsberechtigungen unterstützt, um den OAuth-Fluss zu aktivieren.
Überlegungen
Die folgenden Überlegungen unterstützen die Verwendung dieses Integrationsmusters:
Verfügbarkeit: Die Client-ADF kann Daten in einem Massenvorgang nach ihrem Zeitplan oder auf Ad-hoc-Basis extrahieren.
Latenz: Die Datenlatenz in diesem Szenario kann abhängig von der Extraktion von Verlaufsdaten oder der Übermittlung neuerer Daten an den Microsoft Graph Data Connect-Speicher durch asynchrone Prozesse variieren, die als geplante Aufgaben ausgeführt werden. Die Leistung des ADF-Extrakts für große Daten ist schneller als granulare HTTP-APIs, da ADF Batchverarbeitung und Dateiübertragung verwendet.
Skalierbarkeit: Mit dieser Architektur können Sie Pipelines entwickeln, die den Datenverschiebungsdurchsatz für Ihre Umgebung maximieren. Diese Pipelines können die folgenden Ressourcen vollständig nutzen:
- Netzwerkbandbreite zwischen den Quell- und Zieldatenspeichern.
- Eingabe-/Ausgabevorgänge pro Sekunde (IOPS) und Bandbreite des Quell- oder Zieldatenspeichers.
Lösungskomplexität: Diese Datenausgangslösung ist aus Integrationsperspektive von geringer Komplexität, da sie keinen benutzerdefinierten Code erfordert, über wenige Komponenten verfügt und die Datenlatenz tolerant ist.