Abrufen von Daten aus OneLake
In diesem Artikel erfahren Sie, wie Sie Daten aus OneLake in eine neue oder vorhandene Tabelle abrufen.
Voraussetzungen
- Ein Arbeitsbereich mit einer Kapazität mit Microsoft Fabric-Unterstützung
- Lakehouse
- Eine KQL-Datenbank mit Bearbeitungsberechtigungen
Dateipfad aus Lakehouse kopieren
Wählen Sie in Ihrem Arbeitsbereich die Lakehouse-Umgebung mit der Datenquelle aus, die Sie verwenden möchten.
Platzieren Sie den Cursor über die gewünschte Datei, und wählen Sie das Menü Weitere (...) aus, und wählen Sie dann Eigenschaftenaus.
Wichtig
- Ordnerpfade werden nicht unterstützt.
- Platzhalter (*) werden nicht unterstützt.
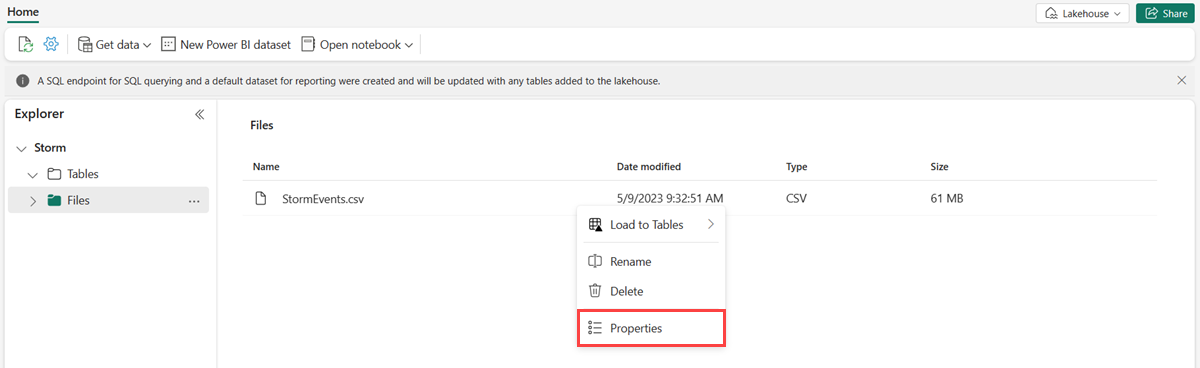
Wählen Sie unter URL das Symbol In Zwischenablage kopieren aus, und speichern Sie die URL an einer beliebigen Stelle, um sie in einem späteren Schritt wieder abzurufen.
Kehren Sie zu Ihrem Arbeitsbereich zurück, und wählen Sie eine KQL-Datenbank aus.


Quelle
Wählen Sie auf dem unteren Menüband der KQL-Datenbank die Option Daten abrufen aus.
Im Fenster Daten abrufen ist die Registerkarte Quelle ausgewählt.
Wählen Sie die Datenquelle aus der verfügbaren Liste aus. In diesem Beispiel erfassen Sie Daten aus OneLake.


Konfigurieren
Wählen Sie eine Zieltabelle aus. Wenn Sie Daten in eine neue Tabelle aufnehmen möchten, wählen Sie +Neue Tabelle aus, und geben Sie einen Tabellennamen ein.
Anmerkung
Tabellennamen können bis zu 1024 Zeichen umfassen, einschließlich Leerzeichen, alphanumerischer Zeichen, Bindestriche und Unterstriche. Sonderzeichen werden nicht unterstützt.
Fügen Sie unter OneLake-Datei den Dateipfad des Lakehouse ein, den Sie unter Kopieren des Dateipfads aus Lakehouse kopiert haben.
Anmerkung
Sie können jeweils bis zu 10 Elemente von bis zu 1 GB unkomprimierte Größe hinzufügen.

Klicken Sie auf Weiter.

Inspizieren
Die Registerkarte Untersuchen wird mit einer Vorschau der Daten geöffnet.
Um den Erfassungsprozess abzuschließen, wählen Sie Fertig stellen aus.

Falls gewünscht:
- Wählen Sie Befehlsanzeige aus, um die von Ihren Eingaben generierten automatischen Befehle anzuzeigen und zu kopieren.
- Verwenden Sie die Schemadefinitionsdatei Dropdowndatei, um die Datei zu ändern, von der das Schema abgeleitet wird.
- Ändern Sie das automatisch abgeleitete Datenformat, indem Sie das gewünschte Format aus der Dropdownliste auswählen. Weitere Informationen finden Sie unter Datenformate, die von Real-Time Intelligenceunterstützt werden.
- Spaltenbearbeiten.
- Lesen Sie den Abschnitt Erweiterte Optionen basierend auf dem Datentyp.
Spalten bearbeiten
Anmerkung
- Bei tabellarischen Formaten (CSV, TSV, PSV) können Sie eine Spalte nicht zweimal zuordnen. Um die neue Spalte einer vorhandenen Spalte zuzuordnen, löschen Sie zuerst die neue Spalte.
- Sie können keinen vorhandenen Spaltentyp ändern. Wenn Sie versuchen, einer Spalte ein anderes Format zuzuordnen, könnten Sie am Ende leere Spalten haben.
Die Änderungen, die Sie in einer Tabelle vornehmen können, hängen von den folgenden Parametern ab:
- Tabellentyp ist neu oder vorhanden
- Die Zuordnung ist neu oder vorhanden.
| Tabellentyp | Zuordnungstyp | Verfügbare Anpassungen |
|---|---|---|
| Neue Tabelle | Neue Zuordnung | Spalte umbenennen, Datentyp ändern, Datenquelle ändern, Zuordnungstransformation, Spalte hinzufügen, Spalte löschen |
| Vorhandene Tabelle | Neue Zuordnung | Spalte hinzufügen (in der Sie dann den Datentyp ändern, umbenennen und aktualisieren können) |
| Vorhandene Tabelle | Vorhandene Zuordnung | nichts |

Zuordnungstransformationen
Einige Datenformatzuordnungen (Parquet, JSON und Avro) unterstützen einfache Transformationen während der Erfassung. Erstellen oder aktualisieren Sie zum Anwenden von Zuordnungstransformationen eine Spalte im Fenster Spalten bearbeiten.
Zuordnungstransformationen können für eine Spalte vom Typ "Zeichenfolge" oder "datetime" ausgeführt werden, wobei die Quelle den Datentyp "int" oder "long" aufweist. Die folgenden Zuordnungstransformationen werden unterstützt:
- DateTimeFromUnixSeconds
- DateTimeFromUnixMilliseconds
- DateTimeFromUnixMicroseconds
- DateTimeFromUnixNanoseconds
Erweiterte Optionen basierend auf dem Datentyp
Tabellarisch (CSV, TSV, PSV):
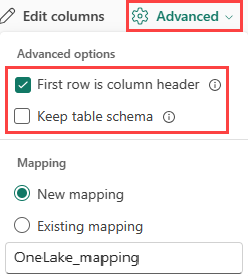
Wenn Sie Tabellenformate in eine bestehende Tabelle übernehmen, wählen Sie Erweitert>Tabellenschema beibehalten aus. Tabellarische Daten enthalten nicht unbedingt die Spaltennamen, die zum Zuordnen von Quelldaten zu den vorhandenen Spalten verwendet werden. Wenn diese Option aktiviert ist, erfolgt die Zuordnung nach Reihenfolge, und das Tabellenschema bleibt gleich. Wenn diese Option deaktiviert ist, werden neue Spalten für eingehende Daten erstellt, unabhängig von der Datenstruktur.
Wenn Sie die erste Zeile als Spaltennamen verwenden möchten, wählen Sie Erweitert>Erste Zeile ist Spaltenüberschrift.
JSON:
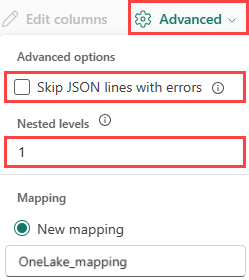
Um die Spaltenteilung von JSON-Daten zu ermitteln, wählen Sie Erweiterte>Geschachtelte Ebenenaus, von 1 bis 100.
Wenn Sie Erweitert>JSON-Zeilen mit Fehlern überspringen auswählen, werden die Daten im JSON-Format erfasst. Wenn Sie dieses Kontrollkästchen nicht ausgewählt lassen, werden die Daten im Multijson-Format aufgenommen.
Zusammenfassung
Im Datenvorbereitungsfenster sind alle drei Schritte mit grünen Häkchen gekennzeichnet, wenn der Datenimport erfolgreich abgeschlossen ist. Sie können eine Karte auswählen, um eine Abfrage durchzuführen, die aufgenommenen Daten löschen oder ein Dashboard mit der Zusammenfassung Ihrer Erfassung anzeigen.
