Verarbeiten von Ereignisdaten mit dem Ereignisprozessor-Editor
Der Ereignisprozessor-Editor ist ein No-Code-Feature, das Ihnen das Ziehen und Ablegen ermöglicht, um die Ereignisdaten-Verarbeitungslogik zu entwerfen. In diesem Artikel wird beschrieben, wie Sie den Editor verwenden, um Ihre Verarbeitungslogik zu entwerfen.
Hinweis
Erweiterte Funktionen sind standardmäßig aktiviert, wenn Sie jetzt Eventstreams erstellen. Wenn Sie Ereignisstreams haben, die mit Standardfunktionen erstellt wurden, funktionieren diese Ereignisstreams weiterhin. Sie können sie weiterhin wie gewohnt bearbeiten und verwenden. Es wird empfohlen, einen neuen Eventstream zu erstellen, um Standardeventstreams zu ersetzen, damit Sie zusätzliche Funktionen und Vorteile erweiterter Eventstreams nutzen können.
Voraussetzungen
Bevor Sie beginnen, müssen die folgenden Voraussetzungen erfüllt sein:
- Zugriff auf einen Arbeitsbereich im Fabric-Kapazitätslizenzmodus (oder) im Testlizenzmodus mit Mitwirkenden oder höheren Berechtigungen.
Entwerfen der Ereignisverarbeitung mit dem Editor
Führen Sie die folgenden Schritte aus, um Datenstromverarbeitungsvorgänge für Ihre Datenströme mit einem Code-Editor auszuführen:
Wählen Sie im Menüband "Bearbeiten" aus, wenn Sie sich noch nicht im Bearbeitungsmodus befinden. Stellen Sie sicher, dass der Upstreamknoten für die Vorgänge, die verbunden sind, über ein Schema verfügt.
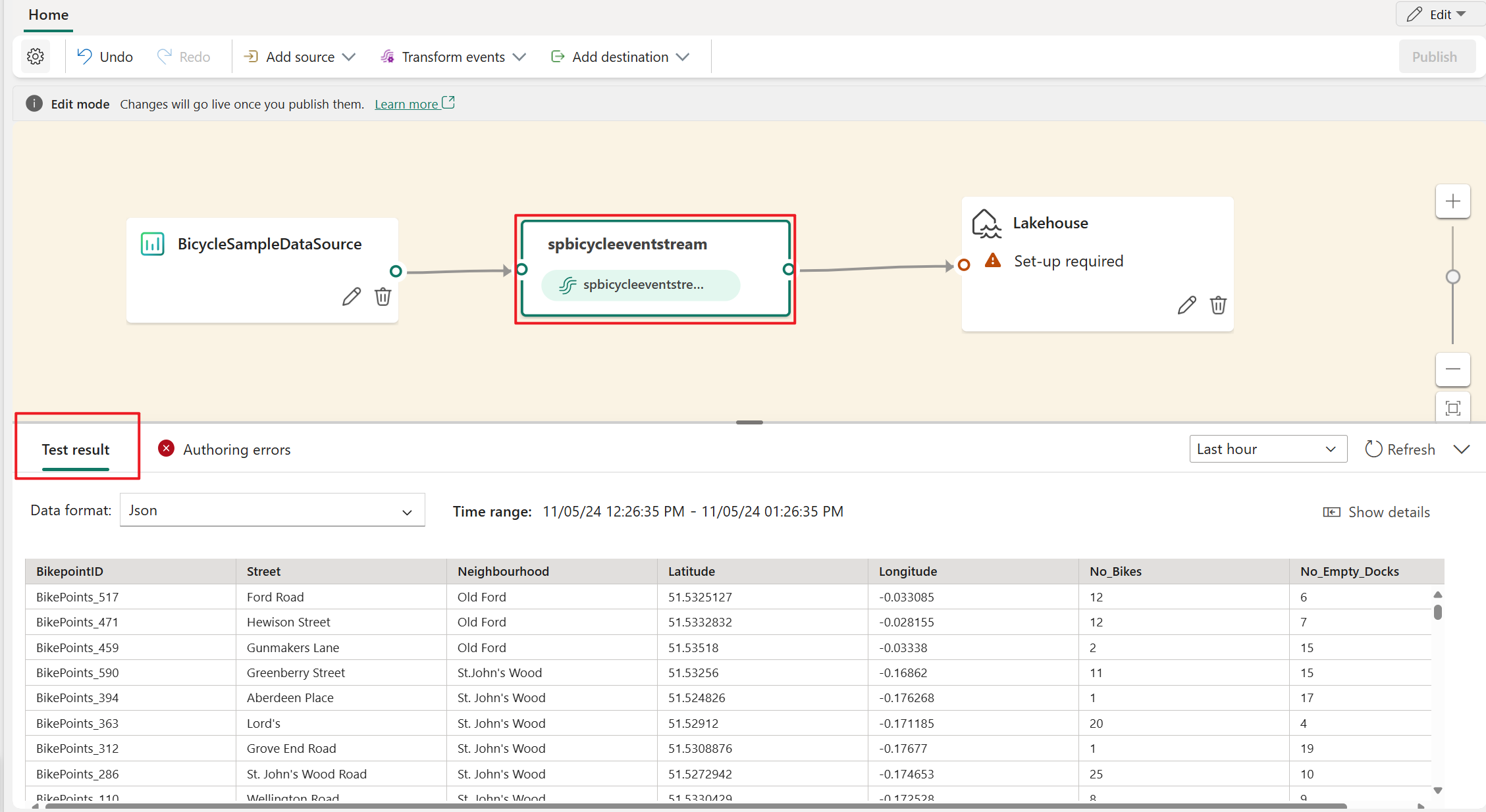
Zum Einfügen eines Ereignisverarbeitungsoperators zwischen diesem Eventstream und dem Ziel im Ereignisprozessor-Editor können Sie eine der folgenden beiden Methoden verwenden:
Fügen Sie den Operator direkt von der Verbindungslinie ein. Fahren Sie mit dem Mauszeiger über die Verbindungslinie, und wählen Sie dann die Schaltfläche + aus. Auf der Verbindungslinie wird ein Dropdownmenü angezeigt, und Sie können einen Operator aus diesem Menü auswählen.
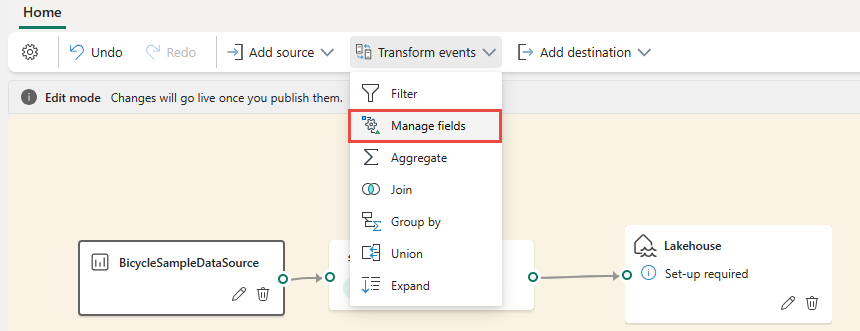
Fügen Sie den Operator über das Menübandmenü oder die Canvas ein.
Sie können einen Operator aus dem Menü Vorgänge im Menüband auswählen.
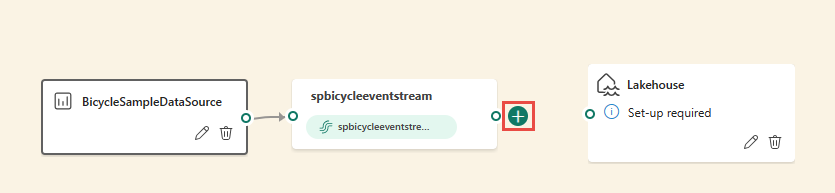
Alternativ können Sie mit dem Mauszeiger über einen der Knoten fahren und dann die Schaltfläche + auswählen, wenn Sie die Verbindungslinie gelöscht haben. Neben diesem Knoten wird ein Dropdownmenü angezeigt, und Sie können einen Operator aus diesem Menü auswählen.
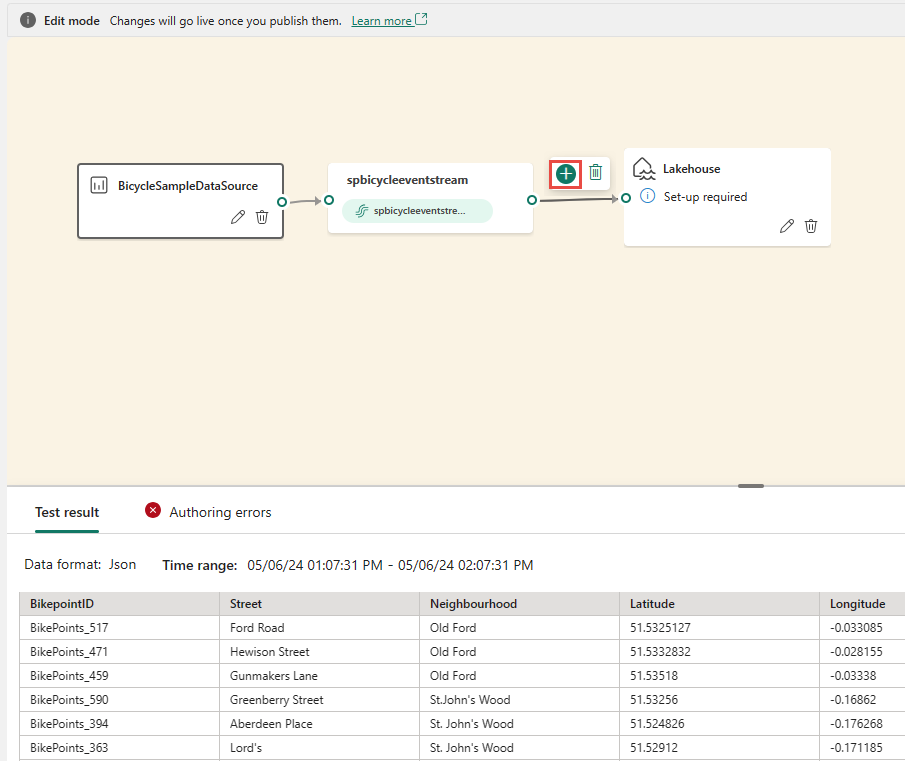
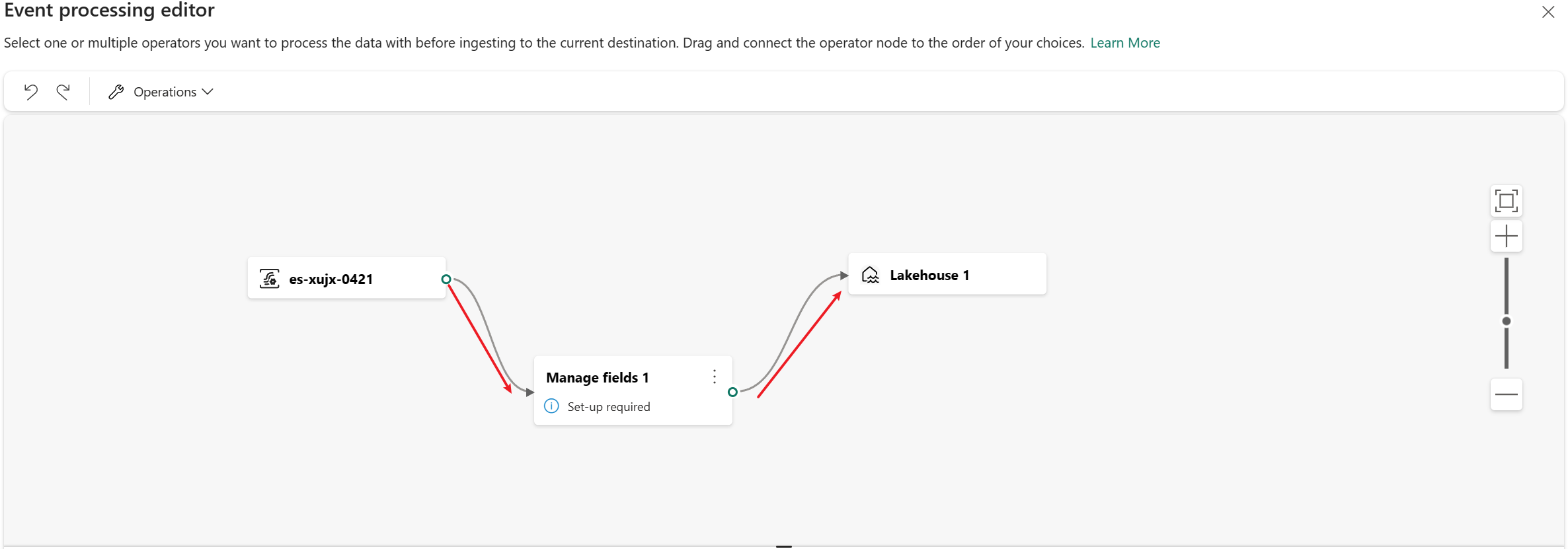
Nach dem Einfügen des Operators müssen Sie diese Knoten erneut verbinden. Fahren Sie mit dem Mauszeiger über den linken Rand des Eventstream-Knotens, wählen Sie dann den grünen Kreis aus und ziehen Sie ihn, um ihn mit dem Operatorknoten Felder verwalten zu verbinden. Führen Sie den gleichen Prozess aus, um den Operatorknoten Felder verwalten mit dem Lakehouse-Knoten zu verbinden.

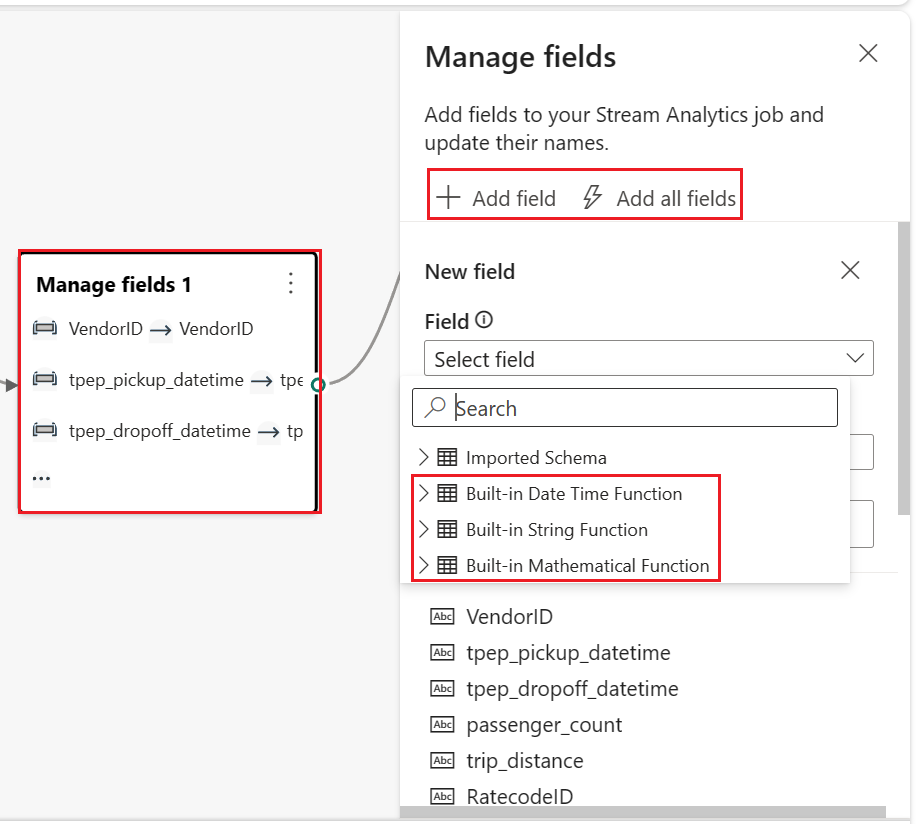
Wählen Sie den Operatorknoten Felder verwalten aus. Wählen Sie im Konfigurationsbereich Felder verwalten die Felder aus, die Sie ausgeben möchten. Wenn Sie alle Felder hinzufügen möchten, wählen Sie Alle Felder hinzufügen aus. Sie können auch mit den integrierten Funktionen ein neues Feld hinzufügen, um die Daten aus dem Upstream zu aggregieren. (Derzeit unterstützen wir einige integrierte Funktionen aus Zeichenfolgenfunktionen, Datums- und Uhrzeitfunktionen und Mathematische Funktionen. Suchen Sie nach
built-in, um sie zu ermitteln.)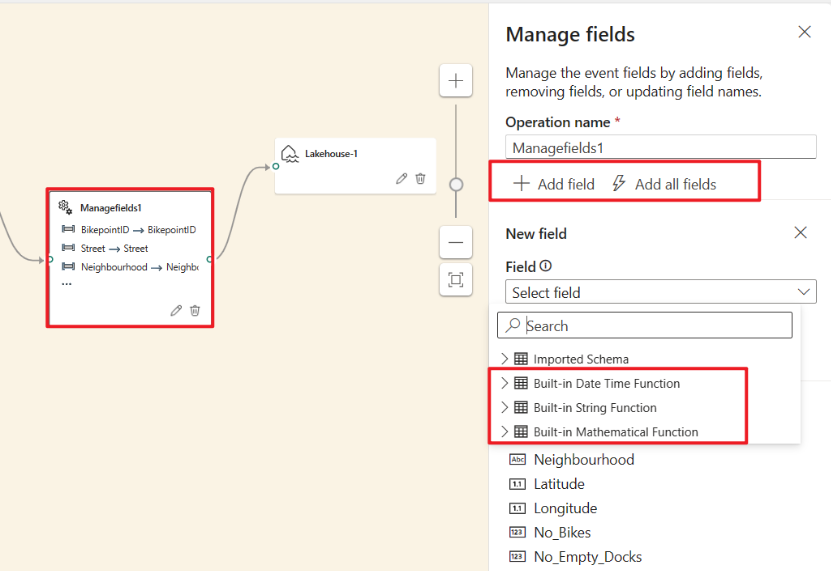
Nachdem Sie den Operator "Felder verwalten" konfiguriert haben, wählen Sie "Aktualisieren" aus, um das von diesem Operator erstellte Testergebnis zu überprüfen.
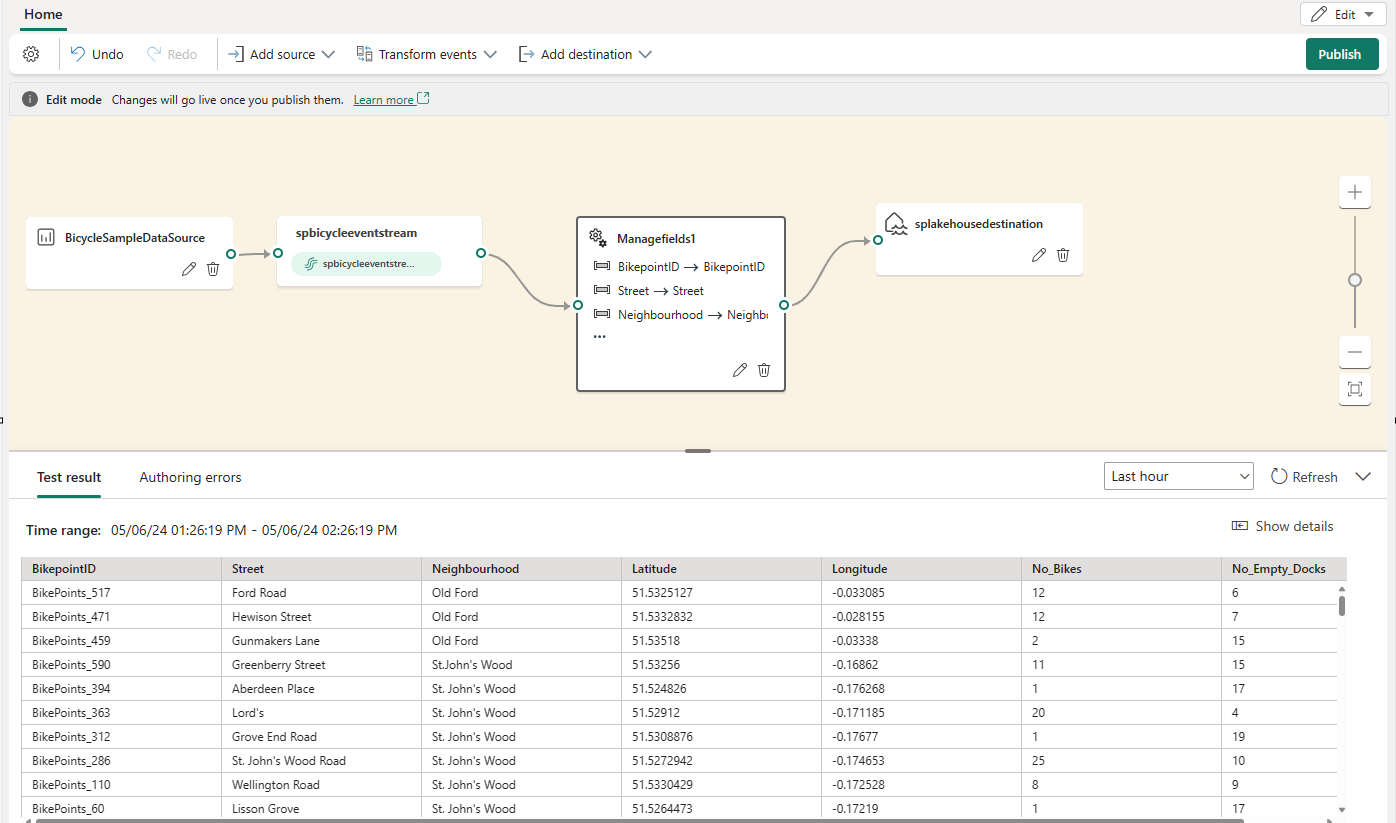
Wenn Konfigurationsfehler auftreten, werden diese im unteren Bereich auf der Registerkarte Erstellungsfehler angezeigt.
Wenn das Testergebnis korrekt aussieht, wählen Sie "Veröffentlichen " aus, um die Ereignisverarbeitungslogik zu speichern und zur Liveansicht zurückzukehren.
Nachdem Sie diese Schritte ausgeführt haben, können Sie visualisieren, wie Ihr Eventstream mit dem Stream streamen und Daten in der Liveansicht verarbeitet.
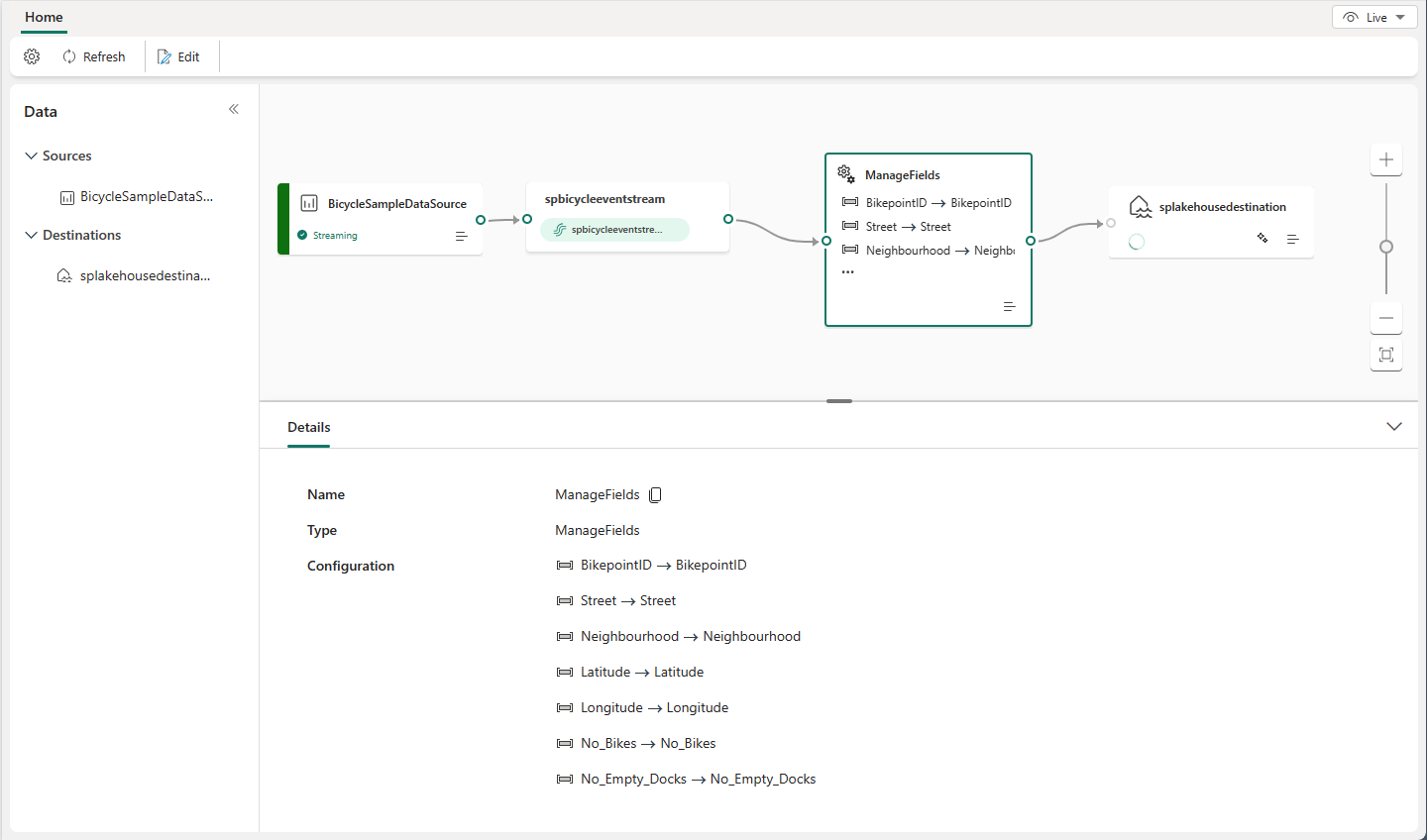









Ereignisprozessor-Editor
Mit dem Ereignisprozessor-Editor (der Canvas im Bearbeitungsmodus) können Sie Daten in verschiedene Ziele umwandeln. Geben Sie den Bearbeitungsmodus ein, um Datenstromverarbeitungsvorgänge für Ihre Datenströme zu entwerfen.

Der Ereignisprozessor-Editor enthält eine Canvas und einen unteren Bereich, in dem Sie folgende Aktionen ausführen können:
- Erstellen der Transformationslogik für Ereignisdaten per Drag & Drop
- Anzeigen einer Vorschau der Daten in den einzelnen Verarbeitungsknoten von Anfang bis Ende
- Ermitteln von Erstellungsfehlern innerhalb der Verarbeitungsknoten
Editorlayout

- Canvas mit Diagrammansicht: In diesem Bereich können Sie Ihre Datentransformationslogik entwerfen, indem Sie (im Menü Vorgänge) einen Operator auswählen und das Eventstream-Element und die Zielknoten über den neu erstellten Operatorknoten verbinden. Sie können Verbindungslinien ziehen und ablegen oder Verbindungen auswählen und löschen.
- Rechter Bearbeitungsbereich (zwei im Bild): In diesem Bereich können Sie den ausgewählten Knoten oder den Namen des Ansichtsdatenstroms konfigurieren.
- Unterer Bereich mit Registerkarten für Datenvorschau und Erstellungsfehler: In diesem Bereich können Sie über die Registerkarte Datenvorschau eine Vorschau der Daten im ausgewählten Knoten anzeigen. Auf der Registerkarte Erstellungsfehler werden unvollständige oder falsche Konfigurationen in den Vorgangsknoten aufgelistet.
Unterstützte Knotentypen und Beispiele
Hier sind die Zieltypen, die das Hinzufügen von Operatoren vor der Aufnahme unterstützen:
- Lakehouse
- Eventhouse (Ereignisverarbeitung vor der Erfassung)
- Abgeleiteter Stream
- Aktivator
Hinweis
Für Ziele, die das Hinzufügen vor der Aufnahme nicht unterstützen, können Sie zuerst einen abgeleiteten Datenstrom als Ausgabe des Operators hinzufügen. Fügen Sie dann Ihr beabsichtigtes Ziel an diesen abgeleiteten Datenstrom an.

Mit dem Ereignisprozessor in Lakehouse und der KQL-Datenbank (Ereignisverarbeitung vor der Aufnahme) können Sie Ihre Daten verarbeiten, bevor sie in Ihr Ziel aufgenommen wird.
Voraussetzungen
Bevor Sie beginnen, müssen die folgenden Voraussetzungen erfüllt sein:
- Zugriff auf einen Arbeitsbereich im Fabric-Kapazitätslizenzmodus (oder) im Testlizenzmodus mit Mitwirkenden oder höheren Berechtigungen.
- Zugriff auf einen Arbeitsbereich mit Mitwirkender-Berechtigungen oder höher, in dem sich Ihr Lakehouse oder KQL Database befindet.
Entwerfen der Ereignisverarbeitung mit dem Editor
So entwerfen Sie die Ereignisverarbeitung mit dem Ereignisprozessor-Editor
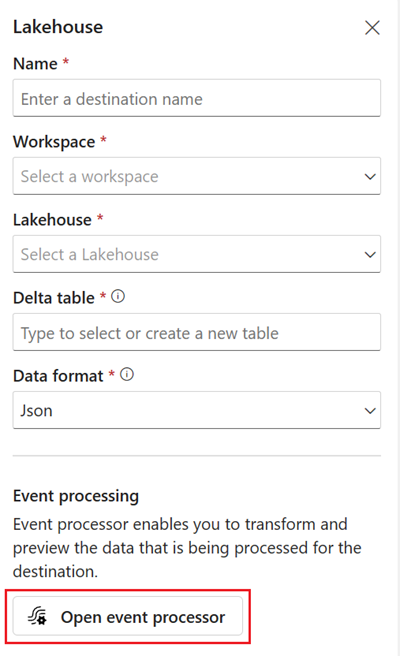
Fügen Sie ein Lakehouse-Ziel hinzu, und geben Sie die erforderlichen Parameter im rechten Bereich ein. (Ausführliche Anweisungen finden Sie unter Hinzufügen und Verwalten eines Ziels in einem Ereignisstream.)
Wählen Sie Ereignisprozessor öffnen aus. Der Bildschirm Ereignisprozessor-Editor wird angezeigt.
Wählen Sie auf der Canvas des Ereignisverarbeitungs-Editors den Eventstream-Knoten aus. Sie können eine Vorschau des Datenschemas anzeigen oder den Datentyp im rechten Bereich Eventstream ändern.
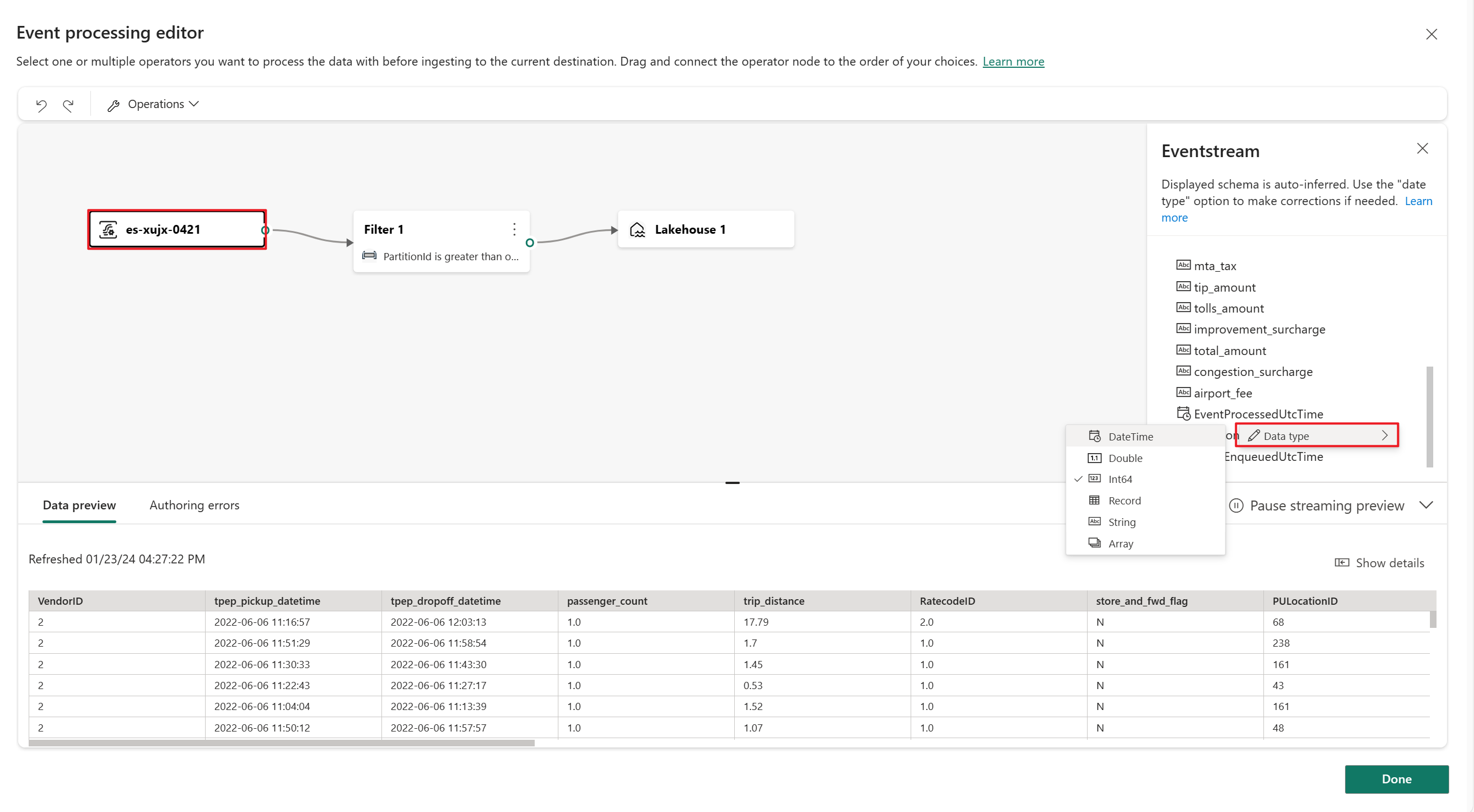
Zum Einfügen eines Ereignisverarbeitungsoperators zwischen diesem Eventstream und dem Ziel im Ereignisprozessor-Editor können Sie eine der folgenden beiden Methoden verwenden:
Fügen Sie den Operator direkt von der Verbindungslinie ein. Fahren Sie mit dem Mauszeiger über die Verbindungslinie, und wählen Sie dann die Schaltfläche „+“ aus. Auf der Verbindungslinie wird ein Dropdownmenü angezeigt, und Sie können einen Operator aus diesem Menü auswählen.
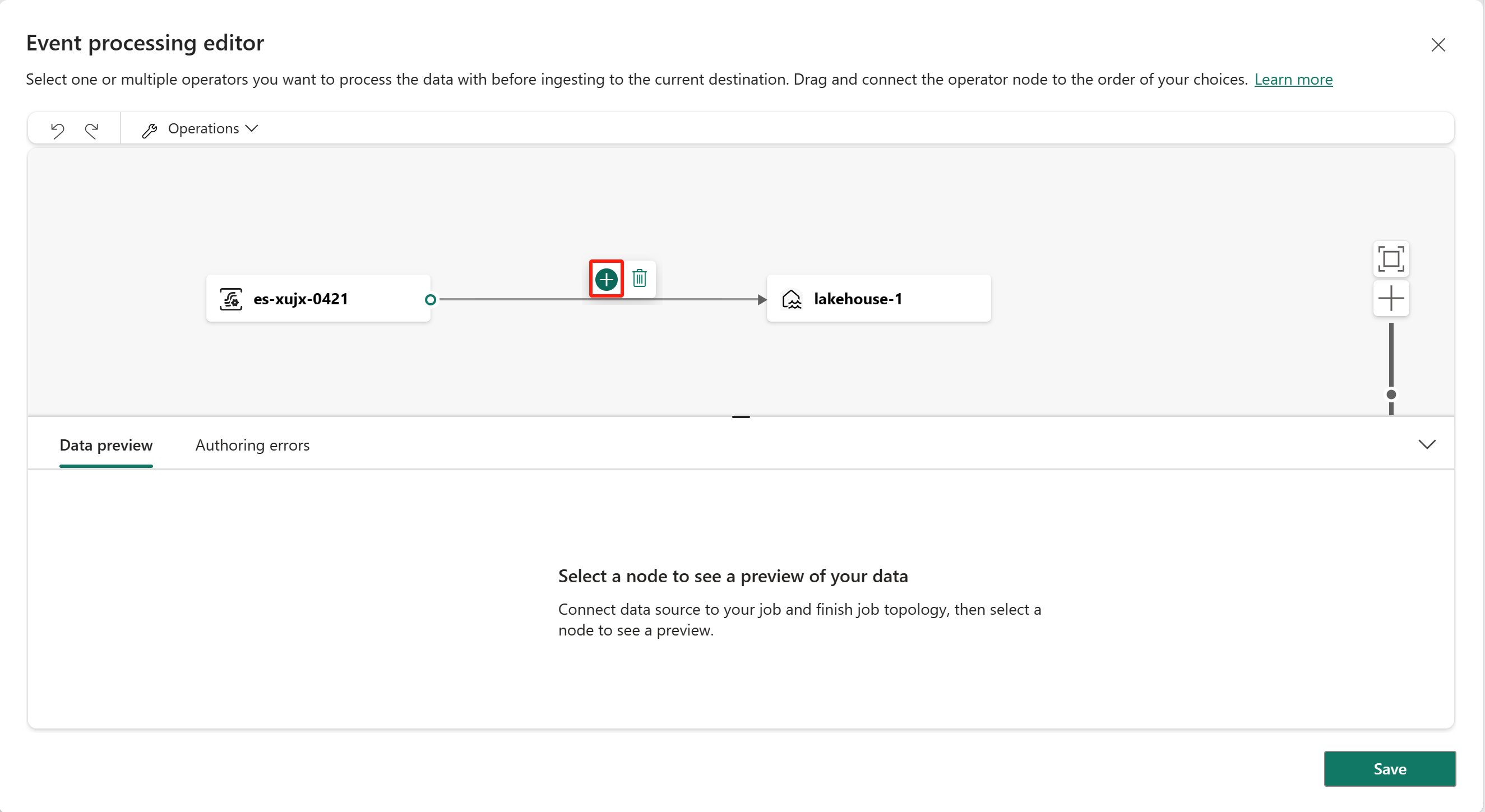
Fügen Sie den Operator über das Menübandmenü oder die Canvas ein.
Sie können einen Operator aus dem Menü Vorgänge im Menüband auswählen. Alternativ können Sie mit dem Mauszeiger über einen der Knoten fahren und dann die Schaltfläche „+“ auswählen, wenn Sie die Verbindungslinie gelöscht haben. Neben diesem Knoten wird ein Dropdownmenü angezeigt, und Sie können einen Operator aus diesem Menü auswählen.
Schließlich müssen Sie diese Knoten erneut verbinden. Zeigen Sie mit der Maus auf den linken Rand des Eventstream-Knotens, wählen Sie dann den grünen Kreis aus, und ziehen Sie ihn, um ihn mit dem Operatorknoten Felder verwalten zu verbinden. Führen Sie den gleichen Prozess aus, um den Operatorknoten Felder verwalten mit dem Lakehouse-Knoten zu verbinden.
Wählen Sie den Operatorknoten Felder verwalten aus. Wählen Sie im Konfigurationsbereich Felder verwalten die Felder aus, die Sie ausgeben möchten. Wenn Sie alle Felder hinzufügen möchten, wählen Sie Alle Felder hinzufügen aus. Sie können auch mit den integrierten Funktionen ein neues Feld hinzufügen, um die Daten aus dem Upstream zu aggregieren. (Derzeit unterstützen wir einige integrierte Funktionen aus Zeichenfolgenfunktionen, Datums- und Uhrzeitfunktionen und Mathematische Funktionen. Suchen Sie nach „integriert“, um sie zu ermitteln.)
Nachdem Sie den Operator Felder verwalten konfiguriert haben, können Sie eine Vorschau der von diesem Operator generierten Daten anzeigen, indem Sie Statische Vorschau aktualisieren auswählen.
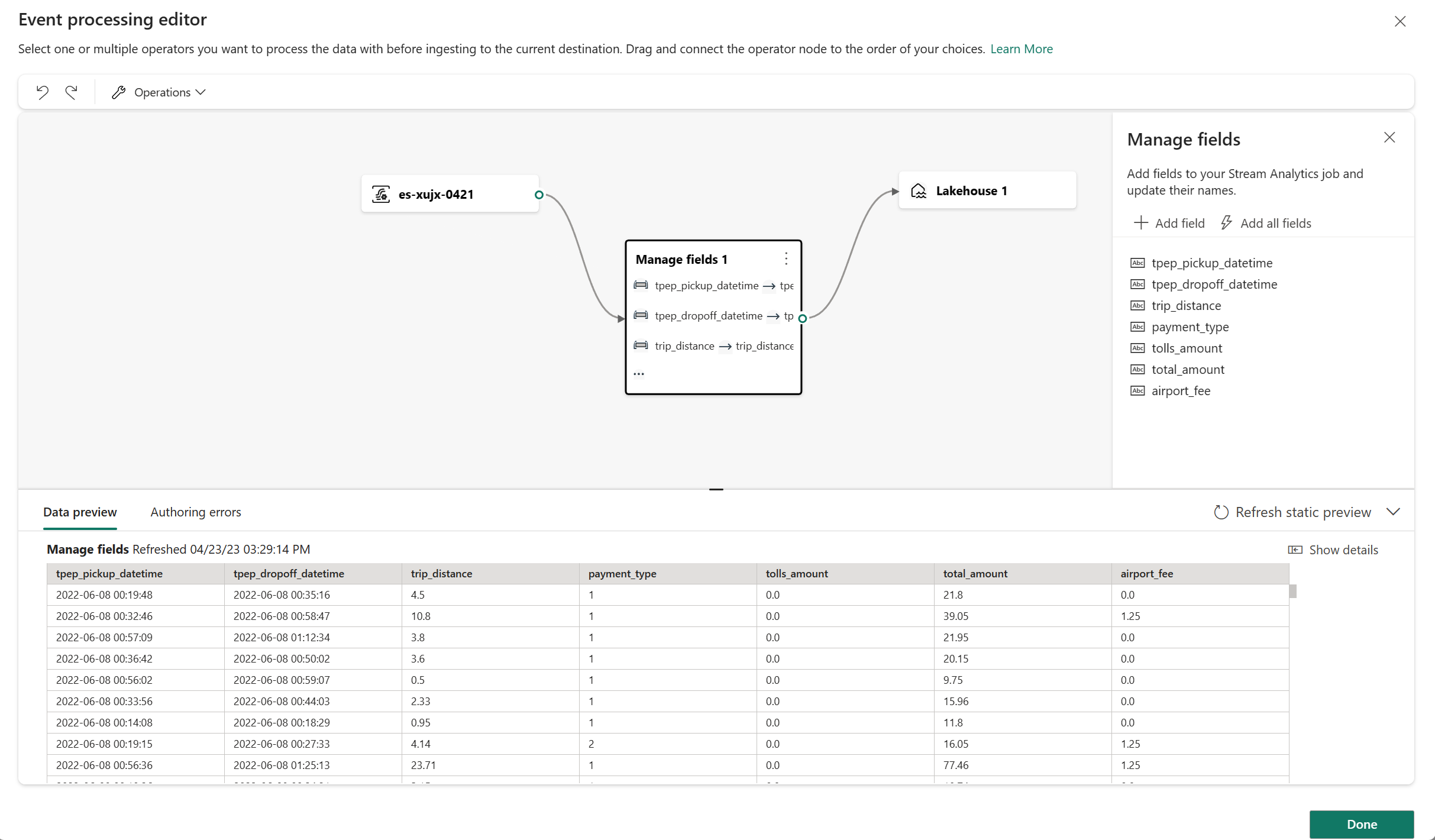
Wenn Konfigurationsfehler auftreten, werden diese im unteren Bereich auf der Registerkarte Erstellungsfehler angezeigt.
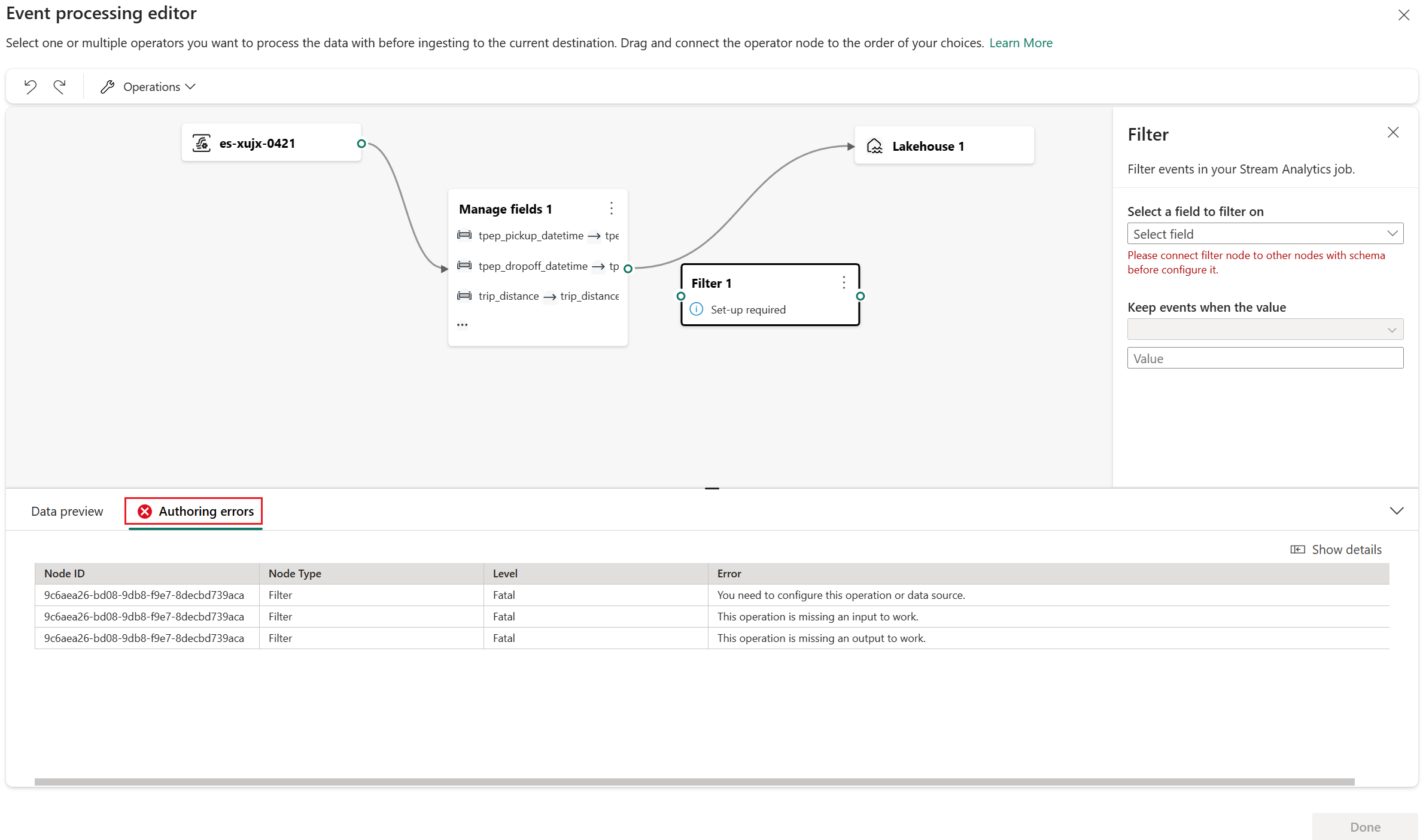
Wenn die Vorschau der Daten korrekt aussieht, wählen Sie Fertig aus, um die Ereignisverarbeitungslogik zu speichern und zum Bildschirm für die Konfiguration des Lakehouse-Ziels zurückzukehren.
Wählen Sie Hinzufügen aus, um die Erstellung Ihres Lakehouse-Ziels abzuschließen.




Ereignisprozessor-Editor
Mit dem Ereignisprozessor können Sie die Daten transformieren, die Sie in einem Lakehouse-Ziel erfassen. Wenn Sie Ihr Lakehouse-Ziel konfigurieren, finden Sie die Option Ereignisprozessor öffnen in der Mitte des Bildschirms für die Konfiguration des Lakehouse-Ziels.

Wenn Sie Ereignisprozess öffnen auswählen, wird der Bildschirm Ereignisprozessor-Editor gestartet. Dort können Sie die Logik für die Datentransformation festlegen.
Der Ereignisprozessor-Editor enthält eine Canvas und einen unteren Bereich, in dem Sie folgende Aktionen ausführen können:
- Erstellen der Transformationslogik für Ereignisdaten per Drag & Drop
- Anzeigen einer Vorschau der Daten in den einzelnen Verarbeitungsknoten von Anfang bis Ende
- Ermitteln von Erstellungsfehlern innerhalb der Verarbeitungsknoten
Das Bildschirmlayout ähnelt dem Haupt-Editor. Es besteht aus drei Abschnitten, die in der folgenden Abbildung dargestellt sind:

Canvas mit Diagrammansicht: In diesem Bereich können Sie Ihre Datentransformationslogik entwerfen, indem Sie (im Menü Vorgänge) einen Operator auswählen und das Eventstream-Element und die Zielknoten über den neu erstellten Operatorknoten verbinden. Sie können Verbindungslinien ziehen und ablegen oder Verbindungen auswählen und löschen.
Rechter Bearbeitungsbereich: In diesem Bereich können Sie den ausgewählten Vorgangsknoten konfigurieren oder das Schema des Eventstream-Elements und des Ziels anzeigen.
Unterer Bereich mit Registerkarten für Datenvorschau und Erstellungsfehler: In diesem Bereich können Sie über die Registerkarte Datenvorschau eine Vorschau der Daten im ausgewählten Knoten anzeigen. Auf der Registerkarte Erstellungsfehler werden unvollständige oder falsche Konfigurationen in den Vorgangsknoten aufgelistet.
Erstellungsfehler
Erstellungsfehler beziehen sich auf die Fehler, die aufgrund unvollständiger oder falscher Konfiguration der Vorgangsknoten im Ereignisprozessor-Editor auftreten. Sie helfen Ihnen beim Ermitteln und Beheben potenzieller Probleme in Ihrem Ereignisprozessor.
Erstellungsfehler werden im unteren Bereich des Ereignisprozessor-Editors angezeigt. Im unteren Bereich werden alle Erstellungsfehler aufgelistet, wobei es zu jedem Erstellungsfehler vier Spalten gibt:
- Knoten-ID: Gibt die ID des Vorgangsknotens an, bei dem der Erstellungsfehler aufgetreten ist.
- Knotentyp: Gibt den Typ des Vorgangsknotens an, bei dem der Erstellungsfehler aufgetreten ist.
- Grad: Gibt den Schweregrad des Erstellungsfehlers an. Es gibt die zwei Schweregrade Schwerwiegend und Information. Ein schwerwiegender Erstellungsfehler bedeutet, dass der Ereignisprozessor ernsthafte Probleme hat und nicht gespeichert oder ausgeführt werden kann. Ein zur Information dienender Erstellungsfehler bedeutet, dass der Ereignisprozessor einige Tipps oder Vorschläge hat, anhand derer Sie den Ereignisprozessor optimieren oder verbessern können.
- Fehler: Vermittelt konkrete Informationen zum Erstellungsfehler mit kurzer Beschreibung der Ursache und Auswirkung des Erstellungsfehlers. Zum Anzeigen von Details können Sie die Registerkarte Details anzeigen auswählen.
Da Eventstream und Eventhouse unterschiedliche Datentypen unterstützen, kann der Prozess der Datentypkonvertierung Erstellungsfehler verursachen.
Die folgende Tabelle zeigt die Ergebnisse der Datentypkonvertierung von Eventstream in Eventhouse. Die Spalten stellen die datentypen dar, die von Eventstream unterstützt werden, und die Zeilen stellen die datentypen dar, die von Eventhouse unterstützt werden. Die Zellen enthalten die Konvertierungsergebnisse, für die es die folgenden drei Möglichkeiten gibt:
✔️ Bedeutet eine erfolgreiche Konvertierung. Es werden keine Fehler oder Warnungen generiert.
❌ Bedeutet, dass die Konvertierung nicht möglich ist. Es wird ein schwerwiegender Erstellungsfehler generiert. Die Fehlermeldung lautet in etwa: Der Datentyp „{1}“ für die Spalte „{0}“ entspricht nicht dem erwarteten Typ „{2}“ in der ausgewählten KQL-Tabelle.
⚠ Bedeutet eine mögliche, aber ungenaue Konvertierung. Es wird ein zur Information dienender Erstellungsfehler generiert. Die Fehlermeldung lautet in etwa: Der Datentyp „{1}“ für die Spalte „{0}“ entspricht nicht genau dem erwarteten Typ „{2}“ in der ausgewählten KQL-Tabelle. Es wird automatisch auf "{2}" zurückgesetzt.
| Zeichenfolge | bool | datetime | dynamisch | guid | INT | long | real | Zeitraum | Decimal | |
|---|---|---|---|---|---|---|---|---|---|---|
| Int64 | ❌ | ❌ | ❌ | ✔️ | ❌ | ⚠️ | ✔️ | ⚠️ | ❌ | ✔️ |
| Double | ❌ | ❌ | ❌ | ✔️ | ❌ | ❌ | ❌ | ⚠️ | ❌ | ⚠️ |
| Zeichenfolge | ✔️ | ❌ | ❌ | ✔️ | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ |
| DateTime | ⚠️ | ❌ | ✔️ | ✔️ | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ |
| Datensatz | ⚠️ | ❌ | ❌ | ✔️ | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ |
| Array | ⚠️ | ❌ | ❌ | ✔️ | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ |
Wie aus der Tabelle ersichtlich, sind manche Datentypkonvertierungen erfolgreich, z.B. von Zeichenkette in Zeichenkette. Diese Konvertierungen generieren keine Erstellungsfehler und haben keine Auswirkung auf den Betrieb des Ereignisprozessors.
Manche Datentypkonvertierungen sind nicht möglich, z.B. von int in Zeichenkette. Diese Konvertierungen generieren schwerwiegende Erstellungsfehler, wodurch der Ereignisprozessor nicht gespeichert werden kann. Sie müssen den Datentyp entweder in Ihrem Eventstream oder in der KQL-Tabelle ändern, um diese Fehler zu vermeiden.
Manche Datentypkonvertierungen sind möglich, aber nicht genau, z. B. von int in real. Diese Konvertierungen generieren Erstellungsfehler, die zur Information dienen, und geben die Diskrepanz zwischen den Datentypen und die Ergebnisse der automatischen Konvertierung an. Durch diese Konvertierungen können Ihre Daten Genauigkeit oder Struktur einbüßen. Sie haben die Wahl, diese Fehler entweder zu ignorieren oder ihren Datentyp in Ihrem Eventstream oder in der KQL-Tabelle zu ändern, um den Ereignisprozessor zu optimieren.
Transformationsoperatoren
Der Ereignisprozessor stellt sechs Operatoren bereit, mit denen Sie Ihre Ereignisdaten entsprechend Ihren geschäftlichen Anforderungen transformieren können.
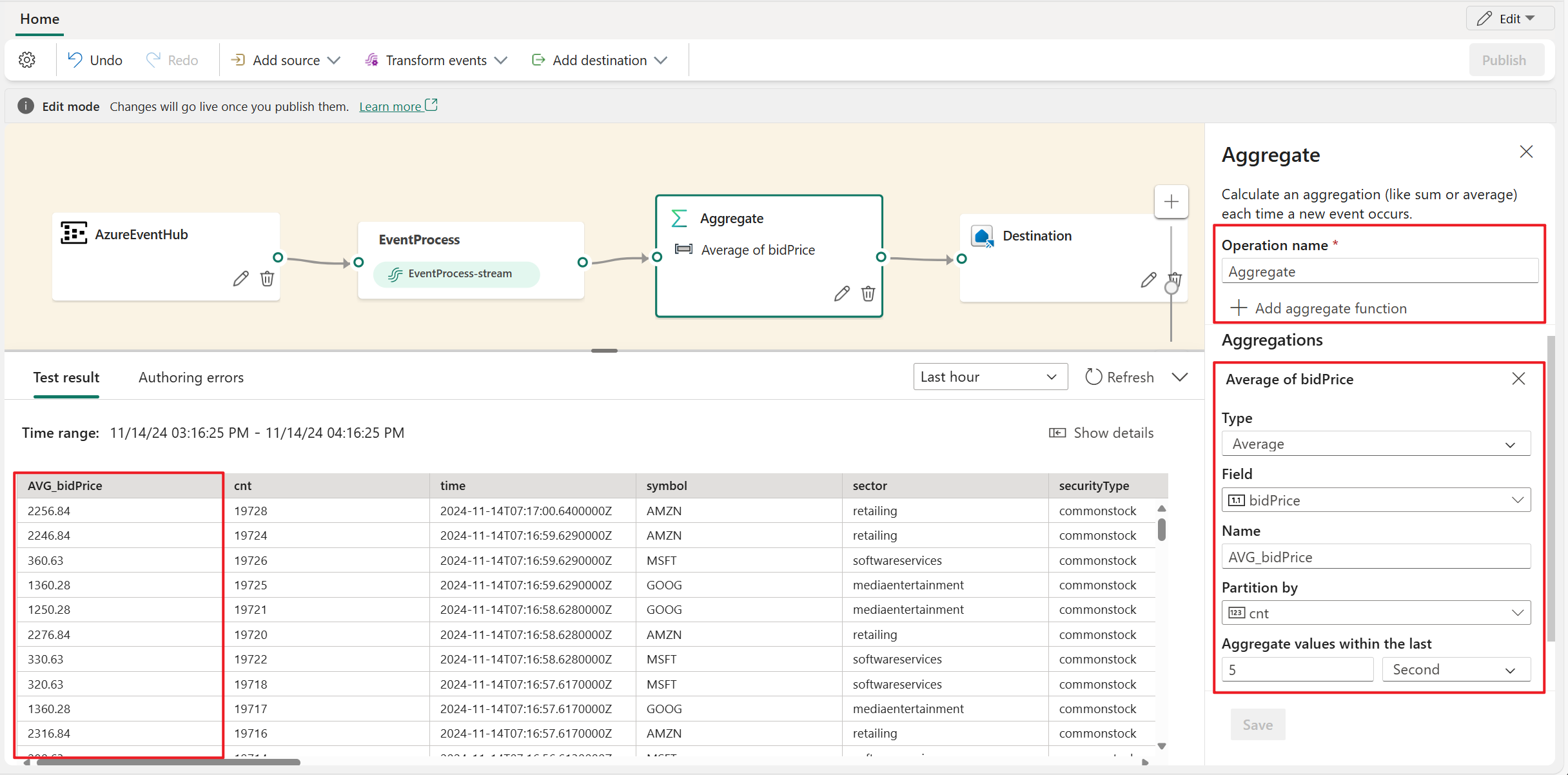
Aggregieren
Mithilfe der Aggregattransformation können Sie jedes Mal, wenn in einem Zeitraum ein neues Ereignis eintritt, eine Aggregation (Summe, Minimum, Maximum oder Durchschnitt) berechnen. Diese Operation ermöglicht auch die Umbenennung dieser berechneten Spalten und das Filtern oder Slicing der Aggregation basierend auf anderen Dimensionen in Ihren Daten. Sie können in derselben Transformation eine oder mehrere Aggregationen verwenden.
- Operatorname: Geben Sie den Namen des Aggregationsvorgangs an.
- Aggregatfunktion hinzufügen: Fügen Sie mindestens eine Aggregation in einem Aggregationsvorgang hinzu.
- Typ: Wählen Sie einen Aggregationstyp aus: Summe, Minimum, Maximum oder Durchschnitt.
- Feld: Wählen Sie die zu verarbeitende Spalte aus.
- Name: Definieren Sie einen Namen für diese Aggregationsfunktion.
- Partitionieren nach: Wählen Sie eine Spalte aus, um die Aggregation zu gruppieren.
- Aggregierte Werte innerhalb der letzten: Geben Sie ein Zeitfenster für die Aggregation an (der Standardwert ist 5 Sekunden).
Erweitern
Verwenden Sie die Arraytransformationsoption Erweitern, um eine neue Zeile für jeden Wert innerhalb eines Arrays zu erstellen. Sie können wahlweise eine Zeile für ein fehlendes/leeres Array erstellen oder keine Zeile für ein fehlendes/leeres Array erstellen.
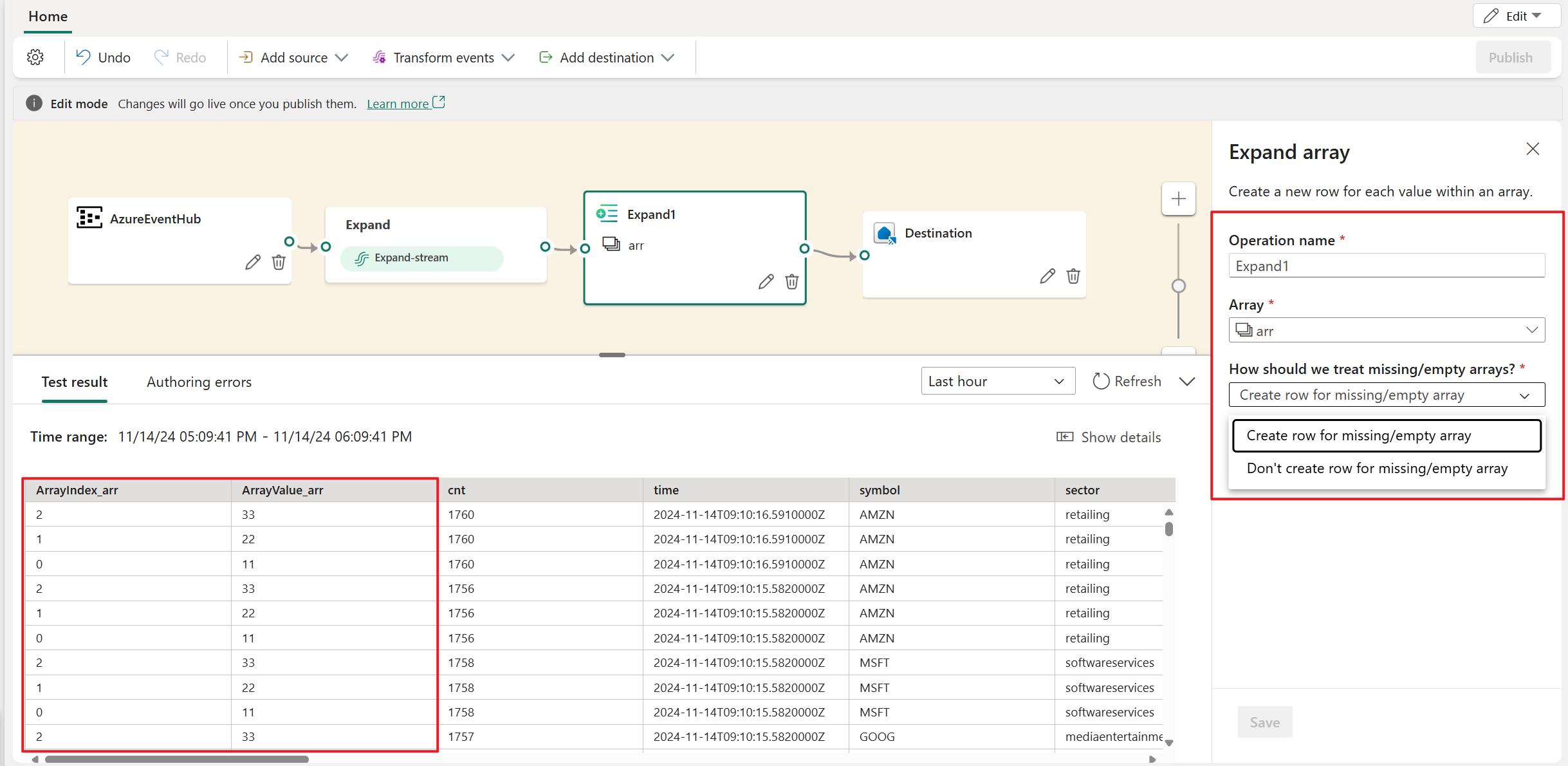
Filter
Verwenden Sie die Filter-Transformation, um Ereignisse basierend auf dem Wert eines Felds in der Eingabe zu filtern. Abhängig vom Datentyp (Zahl oder Text) werden bei der Transformation die Werte beibehalten, die der ausgewählten Bedingung entsprechen, wie ist null oder ist nicht null.
Gruppieren nach
Verwenden Sie die Gruppieren nach-Transformation, um Aggregationen für alle Ereignisse innerhalb eines bestimmten Zeitfensters zu berechnen. Sie können die Ansicht nach den Werten in einem oder mehreren Feldern gruppieren. Sie ähnelt der Aggregattransformation und lässt die Umbenennung der Spalten zu, bietet jedoch mehr Optionen für die Aggregation und enthält komplexere Optionen für Zeitfenster. Wie bei Aggregat können Sie pro Transformation mehrere Aggregationen hinzufügen.
Für die Transformation sind folgende Aggregationen verfügbar:
- Average
- Anzahl
- Maximum
- Mindestanforderungen
- Perzentil (kontinuierlich und diskret)
- Standardabweichung
- Sum
- Variance
Bei Szenarien mit „Time Streaming“ ist das Durchführen von Vorgängen für die Daten in temporalen Fenstern ein häufiges Muster. Der Ereignisprozessor unterstützt Fensterfunktionen, die in den Operator Gruppieren nach integriert sind. Sie können sie in den Einstellungen dieses Operators definieren.

Verwalten von Feldern
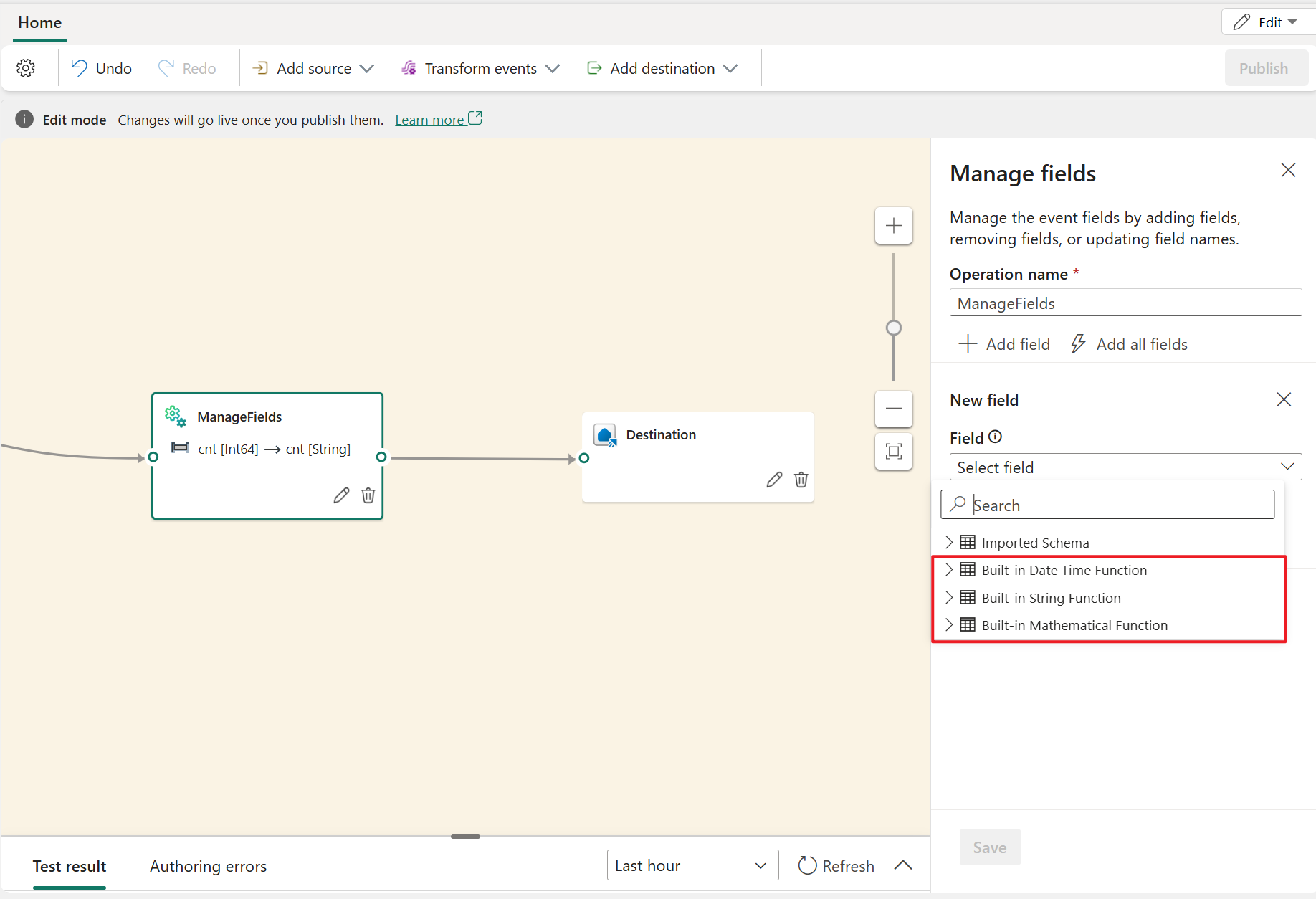
Mit der Transformation Verwalten von Feldern können Sie Felder, die aus einer Eingabe oder einer anderen Transformation stammen, hinzufügen, entfernen oder umbenennen oder den Datentyp ändern. In den Einstellungen im Seitenbereich haben Sie die Möglichkeit, durch Auswahl von Feld hinzufügen mehrere neue Felder oder alle Felder zugleich hinzuzufügen.
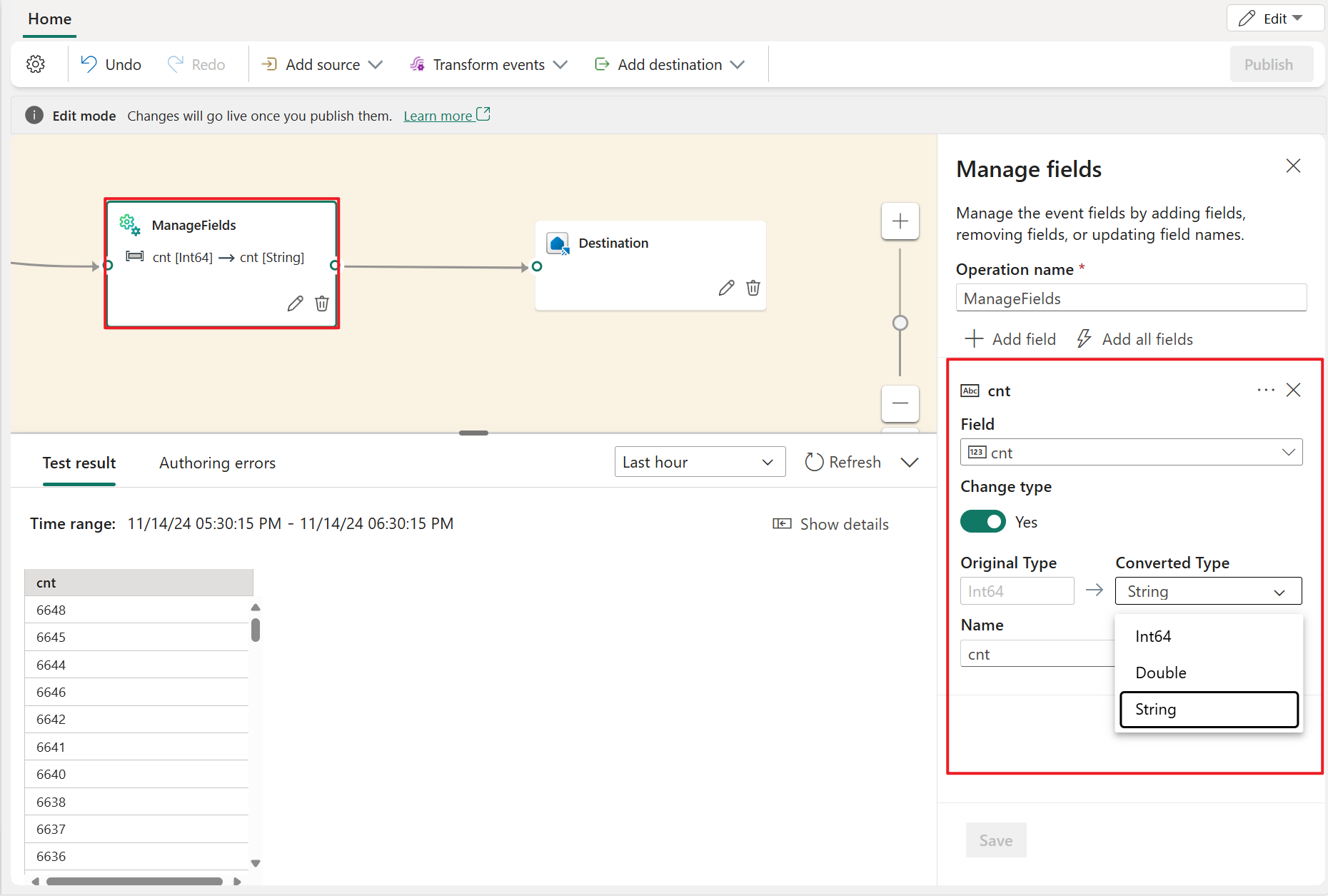
Außerdem können Sie mit den integrierten Funktionen ein neues Feld hinzufügen, um die Daten aus dem Upstream zu aggregieren. (Derzeit unterstützen wir einige integrierte Funktionen aus Zeichenfolgenfunktionen, Datums- und Uhrzeitfunktionen und Mathematische Funktionen. Suchen Sie nach „integriert“, um sie zu ermitteln.)
Die folgende Tabelle zeigt die Ergebnisse der Änderung des Datentyps durch Verwalten von Feldern. Die Spalten stellen den ursprünglichen Datentyp und die Zeilen den Zieldatentyp dar.
- Eine ✔️ in der Zelle bedeutet, dass sie direkt konvertiert werden kann, und die Option für den Zieldatentyp wird in der Dropdownliste angezeigt.
- Eine ❌ in der Zelle bedeutet, dass sie nicht konvertiert werden kann, und die Option für den Zieldatentyp wird in der Dropdownliste nicht angezeigt.
- Ein ⚠ in der Zelle bedeutet, dass sie konvertiert werden kann, dass aber bestimmte Bedingungen erfüllt werden müssen, z. B. dass das Zeichenkettenformat den Anforderungen des Zieldatentyps entsprechen muss. Bei der Konvertierung von Zeichenkette in int muss die Zeichenkette beispielsweise eine gültige ganzzahlige Form haben, wie z.B.
123und nichtabc.
| Int64 | Double | Zeichenfolge | Datetime | Datensatz | Array | |
|---|---|---|---|---|---|---|
| Int64 | ✔️ | ✔️ | ✔️ | ❌ | ❌ | ❌ |
| Double | ✔️ | ✔️ | ✔️ | ❌ | ❌ | ❌ |
| Zeichenfolge | ⚠️ | ⚠️ | ✔️ | ⚠️ | ❌ | ❌ |
| DateTime | ❌ | ❌ | ✔️ | ✔️ | ❌ | ❌ |
| Datensatz | ❌ | ❌ | ✔️ | ❌ | ✔️ | ❌ |
| Array | ❌ | ❌ | ✔️ | ❌ | ❌ | ✔️ |
Union
Mithilfe von Union-Transformationen können Sie zwei oder mehr Knoten verbinden und Ereignisse mit gemeinsamen Feldern (mit dem gleichen Namen und Datentyp) in eine Tabelle einfügen. Felder, die nicht übereinstimmen, werden verworfen und sind nicht in der Ausgabe enthalten.
Join
Verwenden Sie die Join-Transformation, um Ereignisse aus zwei Eingaben basierend auf den von Ihnen ausgewählten Feldpaaren zu kombinieren. Wenn Sie kein Feldpaar auswählen, basiert der Join standardmäßig auf der Zeit. Standardmäßig unterscheidet sich diese Transformation von einer Batch-Transformation.
Wie bei regulären Joins haben Sie Optionen für Ihre Verknüpfungslogik:
- Innerer Join: Enthält nur Datensätze aus beiden Tabellen, in denen das Paar übereinstimmt.
- Linker äußerer Join: Eingeschlossen sind alle Datensätze aus der linken (ersten) Tabelle und nur die Datensätze aus der zweiten, die dem Feldpaar entsprechen. Wenn keine Übereinstimmung besteht, sind die Felder aus der zweiten Eingabe leer.