Transformieren von Daten mit Apache Spark und Abfragen mit SQL
In diesem Leitfaden werden Sie:
Hochladen von Daten in OneLake mit dem OneLake-Datei-Explorer.
Verwenden eines Fabric-Notebooks, um Daten auf OneLake zu lesen und als Delta-Tabelle zurückzuschreiben.
Analysieren und Transformieren von Daten mit Spark mithilfe eines Fabric-Notebooks
Abfragen einer Kopie von Daten in OneLake mit SQL
Voraussetzungen
Führen Sie zur Vorbereitung folgende Schritte aus:
Laden Sie den OneLake-Datei-Explorer herunter, und installieren Sie ihn.
Erstellen eines Arbeitsbereichs mit einem Lakehouse-Element.
Herunterladen des WideWorldImportersDW-Datasets. Sie können Azure Storage-Explorer verwenden, um eine Verbindung mit
https://fabrictutorialdata.blob.core.windows.net/sampledata/WideWorldImportersDW/csv/full/dimension_cityherzustellen und die CSV-Dateien herunterzuladen. Oder Sie können eigene CSV-Daten verwenden und die Details nach Bedarf aktualisieren.
Hinweis
Erstellen, laden oder erstellen Sie eine Verknüpfung mit Delta-Parquet Daten immer direkt im Abschnitt Tabellen von Lakehouse. Verschachteln Sie Ihre Tabellen nicht in Unterordnern unter dem Abschnitt Tabellen, da Lakehouse sie sonst nicht als Tabelle erkennt und sie als „Nicht identifiziert“ kennzeichnet.
Hochladen, Lesen, Analysieren und Abfragen von Daten
Navigieren Sie im OneLake-Datei-Explorer zu Ihrem Lakehouse, und erstellen Sie unter dem Verzeichnis
/Filesein Unterverzeichnis mit dem Namendimension_city.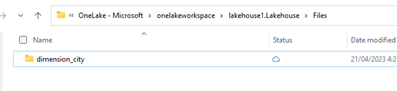
Kopieren Sie Ihre Beispiel-CSV-Dateien mithilfe des OneLake-Datei-Explorers in das OneLake-Verzeichnis
/Files/dimension_city.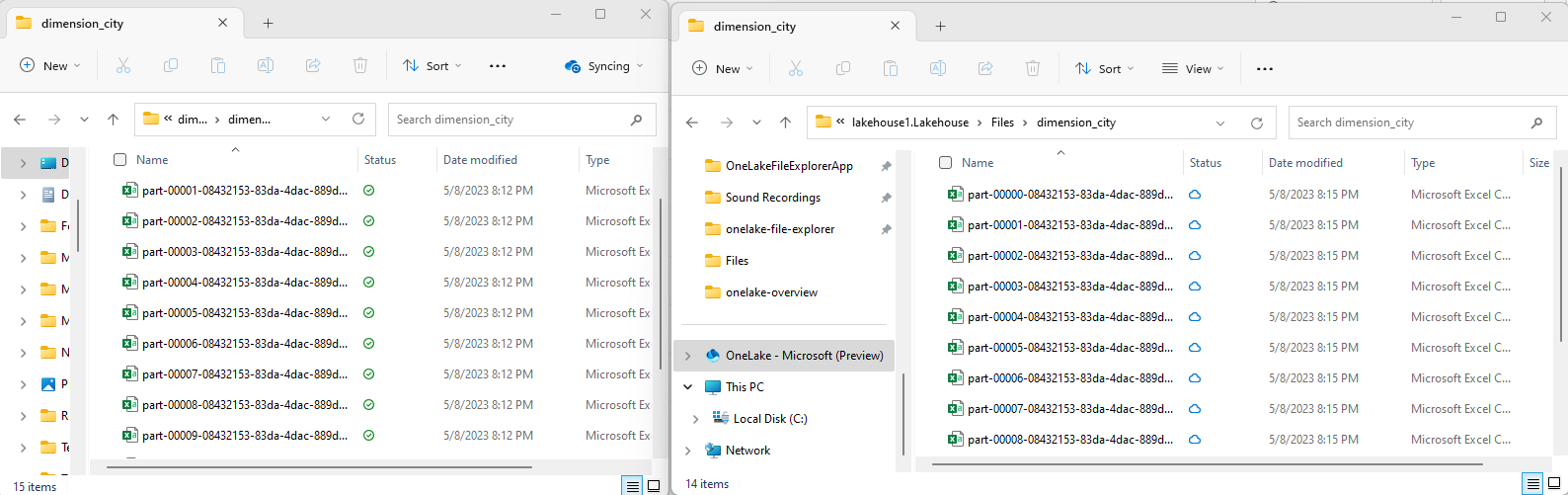
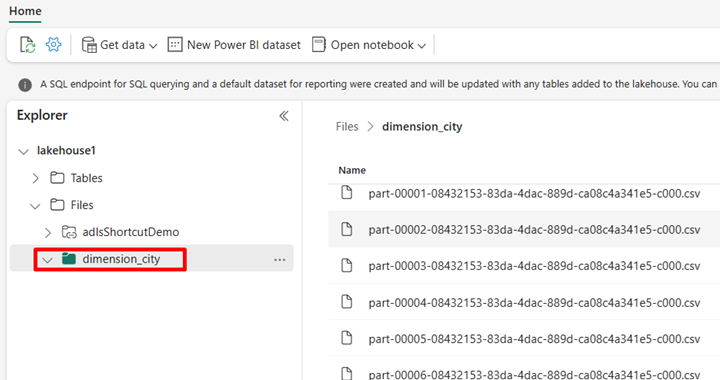
Navigieren Sie im Power BI-Dienst zu Ihrem Lakehouse, und zeigen Sie Ihre Dateien an.
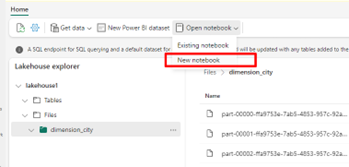
Wählen Sie Notebook öffnen und dann Neues Notebook aus, um ein Notebook zu erstellen.
Konvertieren Sie die CSV-Dateien mithilfe des Fabric-Notebooks in das Delta-Format. Der folgende Codeschnipsel liest Daten aus dem von Ihnen erstellten Verzeichnis
/Files/dimension_cityund konvertiert sie in die Delta-Tabelledim_city.import os from pyspark.sql.types import * for filename in os.listdir("/lakehouse/default/Files/<replace with your folder path>"): df=spark.read.format('csv').options(header="true",inferSchema="true").load("abfss://<replace with workspace name>@onelake.dfs.fabric.microsoft.com/<replace with item name>.Lakehouse/Files/<folder name>/"+filename,on_bad_lines="skip") df.write.mode("overwrite").format("delta").save("Tables/<name of delta table>")Um Ihre neue Tabelle anzuzeigen, aktualisieren Sie Ihre Ansicht des Verzeichnisses
/Tables.
Fragen Sie Ihre Tabelle mit SparkSQL im selben Fabric-Notebook ab.
%%sql SELECT * from <replace with item name>.dim_city LIMIT 10;Ändern Sie die Delta-Tabelle, indem Sie eine neue Spalte mit dem Namen newColumn und dem Datentyp „integer” hinzufügen. Legen Sie den Wert „9” für alle Datensätze für diese neu hinzugefügte Spalte fest.
%%sql ALTER TABLE <replace with item name>.dim_city ADD COLUMN newColumn int; UPDATE <replace with item name>.dim_city SET newColumn = 9; SELECT City,newColumn FROM <replace with item name>.dim_city LIMIT 10;Sie können auch über einen SQL-Analyseendpunkt auf jede Delta-Tabelle in OneLake zugreifen. Ein SQL-Analyseendpunkt verweist auf dieselbe physische Kopie der Delta-Tabelle in OneLake und bietet die T-SQL-Benutzeroberfläche. Wählen Sie den SQL-Analyseendpunkt für lakehouse1 und dann Neue SQL-Abfrage aus, um die Tabelle mithilfe von T-SQL abzufragen.
SELECT TOP (100) * FROM [<replace with item name>].[dbo].[dim_city];
