Erstellen eines Seehauses für Direct Lake
In diesem Artikel wird beschrieben, wie Sie ein Seehaus erstellen, einen Delta-Tisch im Seehaus erstellen und dann ein grundlegendes semantisches Modell für das Lakehouse in einem Microsoft Fabric-Arbeitsbereich erstellen.
Bevor Sie mit dem Erstellen eines Lakehouse für Direct Lake beginnen, lesen Sie unbedingt die Direct Lake-Übersicht.
Erstellen eines Seehauses
Wählen Sie in Ihrem Microsoft Fabric-Arbeitsbereich Neu>Weitere Optionen aus, und wählen Sie dann in Datentechnik die Kachel Lakehouse aus.
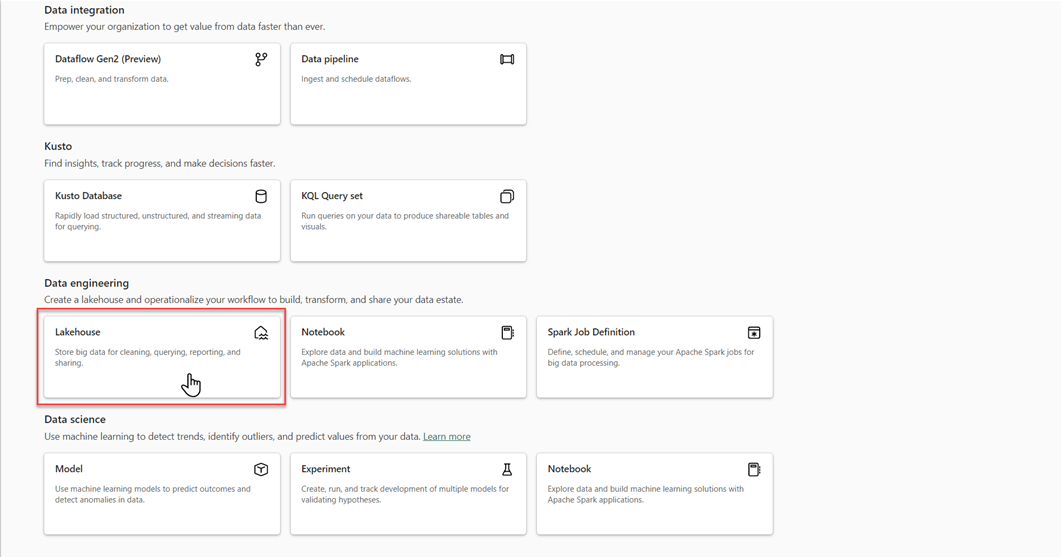
Geben Sie im Dialogfeld Neues Lakehouse einen Namen ein, und wählen Sie dann Erstellen aus. Der Name darf nur alphanumerische Zeichen und Unterstriche enthalten.
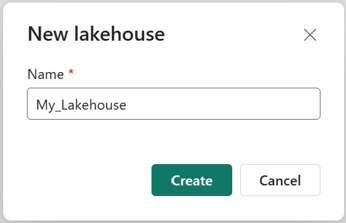
Überprüfen Sie, ob das neue Seehaus erstellt und erfolgreich geöffnet wird.
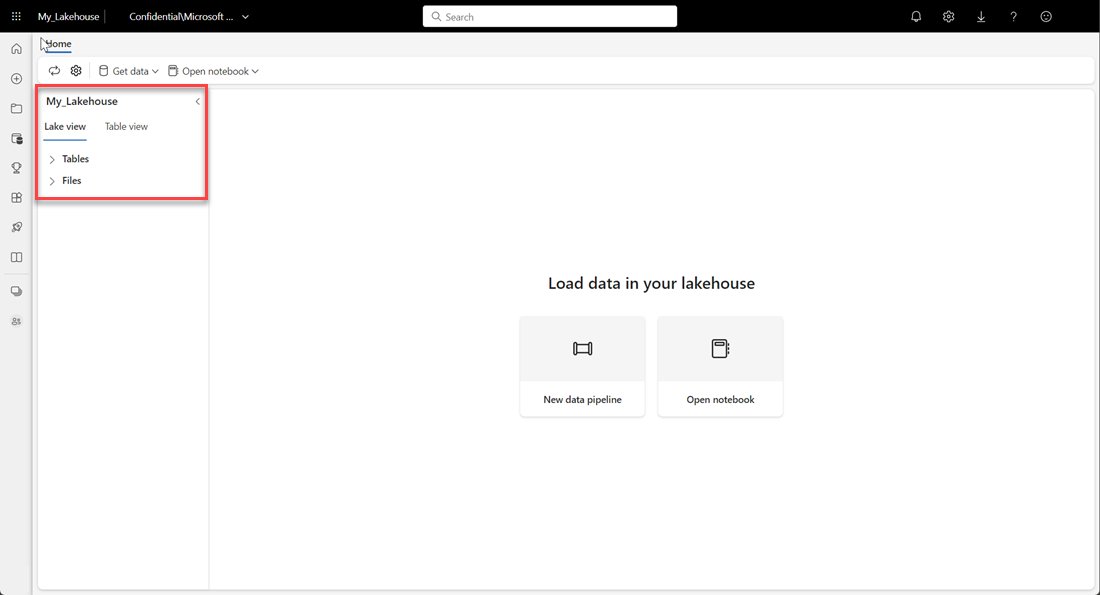
Erstellen einer Delta-Tabelle im Seehaus
Nachdem Sie ein neues Lakehouse erstellt haben, müssen Sie dann mindestens eine Delta-Tabelle erstellen, damit Direct Lake auf einige Daten zugreifen kann. Direct Lake kann parkettformatierte Dateien lesen, aber für die beste Leistung ist es am besten, die Daten mithilfe der VORDER-Komprimierungsmethode zu komprimieren. VORDER komprimiert die Daten mithilfe des systemeigenen Komprimierungsalgorithmus des Power BI-Moduls. Auf diese Weise kann das Modul die Daten so schnell wie möglich in den Arbeitsspeicher laden.
Es gibt mehrere Optionen, um Daten in ein Lakehouse zu laden, einschließlich Datenpipelines und Skripts. Die folgenden Schritte verwenden PySpark, um einem Lakehouse basierend auf einem Azure Open Dataset eine Delta-Tabelle hinzuzufügen:
Wählen Sie im neu erstellten Lakehouse die Option Notebook öffnen und dann Neues Notebook aus.
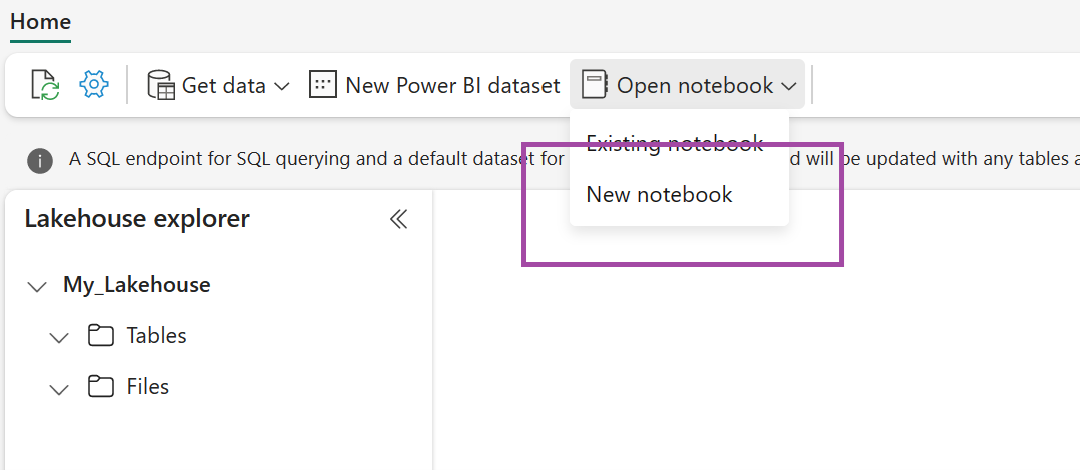
Kopieren Sie den folgenden Codeausschnitt, und fügen Sie ihn in die erste Codezelle ein, damit SPARK auf das geöffnete Modell zugreifen kann, und drücken Sie dann UMSCHALT+EINGABETASTE, um den Code auszuführen.
# Azure storage access info blob_account_name = "azureopendatastorage" blob_container_name = "holidaydatacontainer" blob_relative_path = "Processed" blob_sas_token = r"" # Allow SPARK to read from Blob remotely wasbs_path = 'wasbs://%s@%s.blob.core.windows.net/%s' % (blob_container_name, blob_account_name, blob_relative_path) spark.conf.set( 'fs.azure.sas.%s.%s.blob.core.windows.net' % (blob_container_name, blob_account_name), blob_sas_token) print('Remote blob path: ' + wasbs_path)Überprüfen Sie, ob der Code erfolgreich einen Remote-BLOB-Pfad ausgibt.
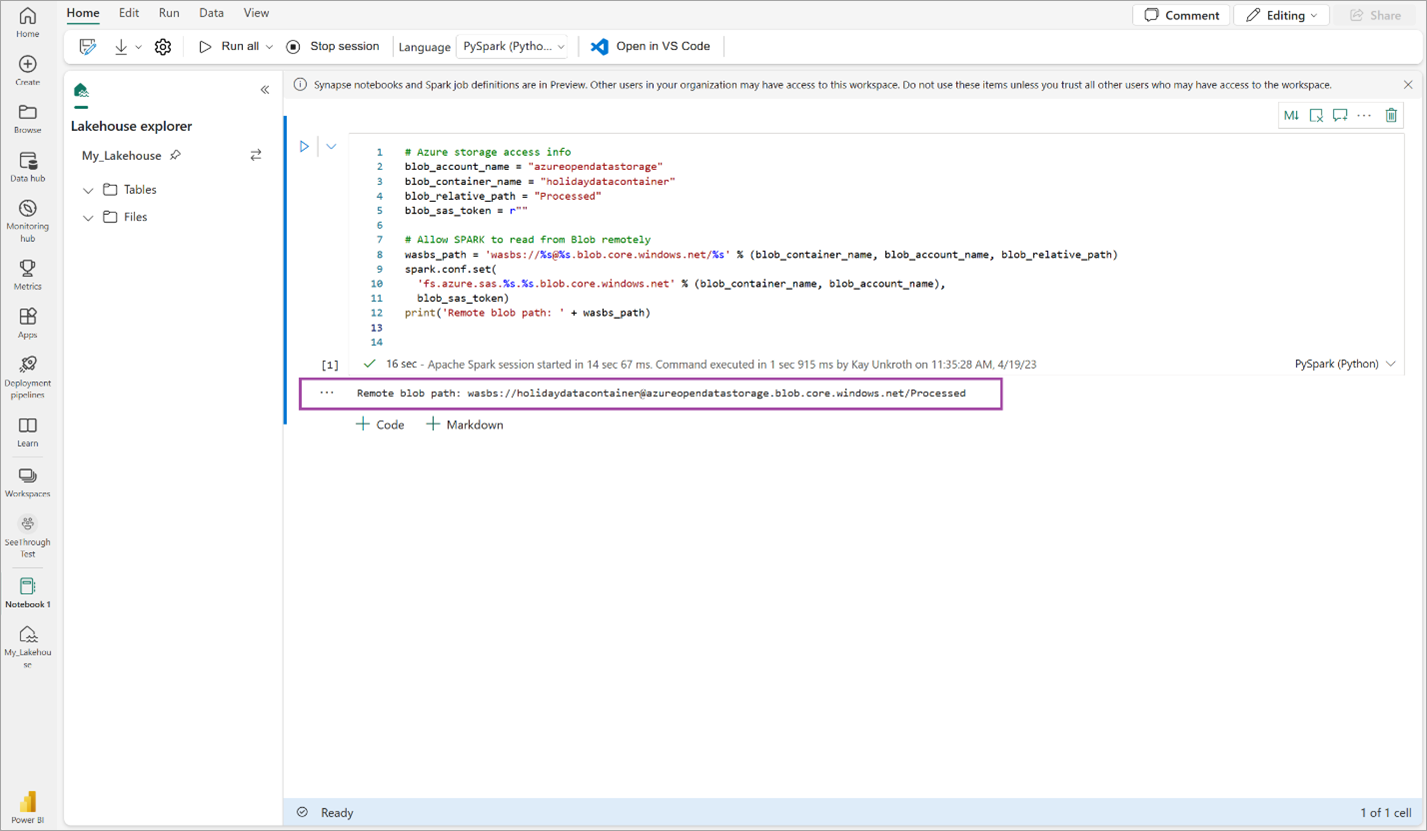
Kopieren Sie den folgenden Code, fügen Sie ihn in die nächste Zelle ein, und drücken Sie dann UMSCHALT+EINGABE.
# Read Parquet file into a DataFrame. df = spark.read.parquet(wasbs_path) print(df.printSchema())Überprüfen Sie, ob der Code erfolgreich das DataFrame-Schema ausgibt.
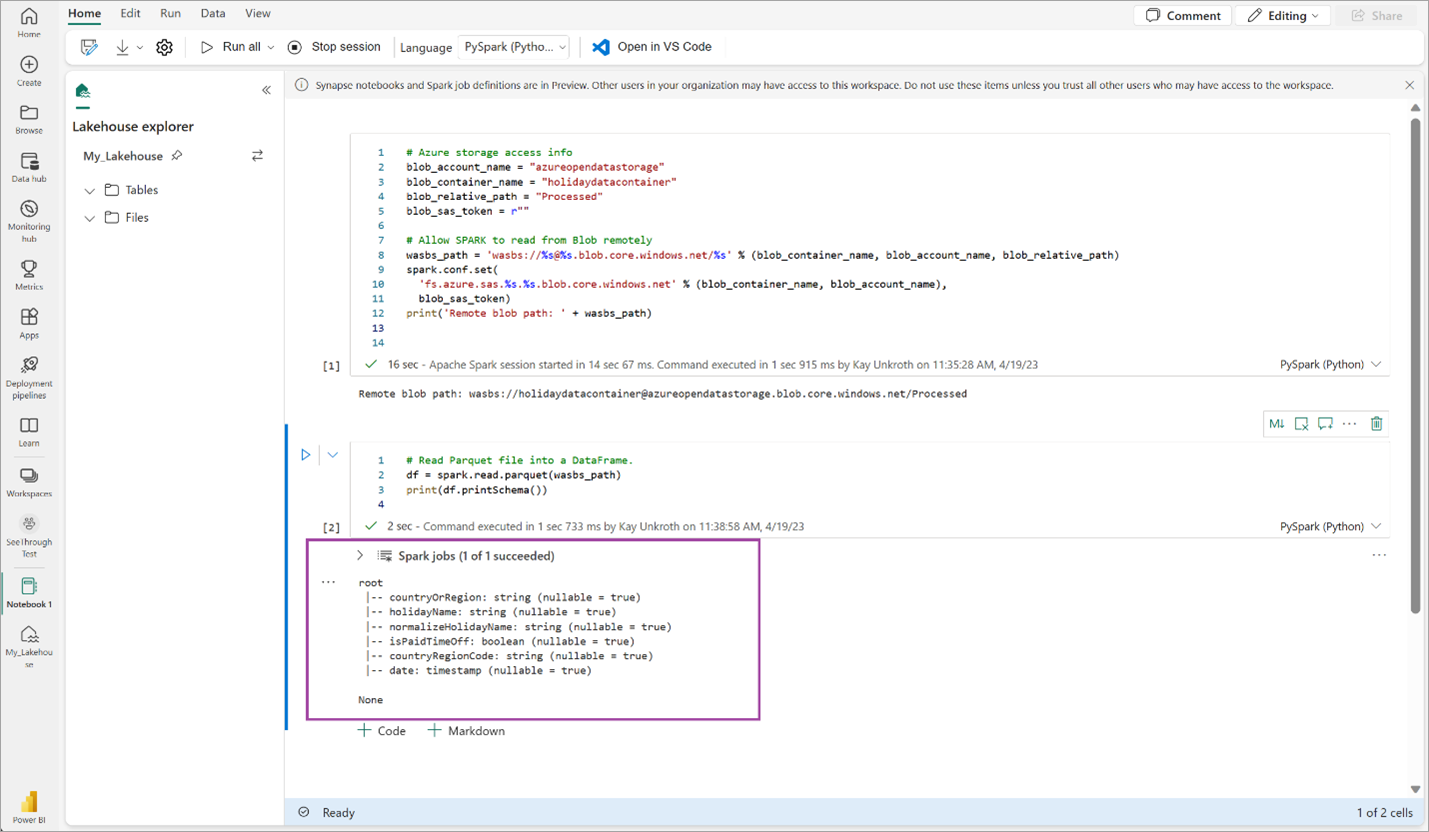
Kopieren Sie die folgenden Zeilen, fügen Sie sie in die nächste Zelle ein, und drücken Sie dann UMSCHALT+EINGABE. Die erste Anweisung ermöglicht die VORDER-Komprimierungsmethode, und die nächste Anweisung speichert den DataFrame als Delta-Tabelle im Seehaus.
# Save as delta table spark.conf.set("spark.sql.parquet.vorder.enabled", "true") df.write.format("delta").saveAsTable("holidays")Überprüfen Sie, ob alle SPARK-Aufträge erfolgreich abgeschlossen wurden. Erweitern Sie die SPARK-Auftragsliste, um weitere Details anzuzeigen.
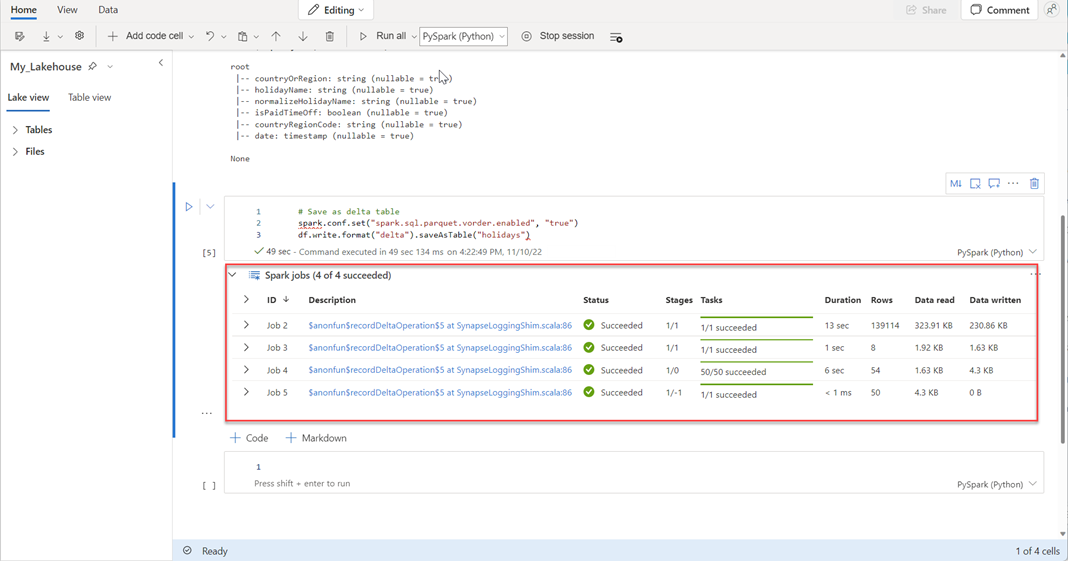
Um zu überprüfen, ob eine Tabelle erfolgreich erstellt wurde, wählen Sie im oberen linken Bereich neben Tabellen die Auslassungspunkte (…) aus, wählen Sie dann Aktualisieren aus, und erweitern Sie dann den Knoten Tabellen.
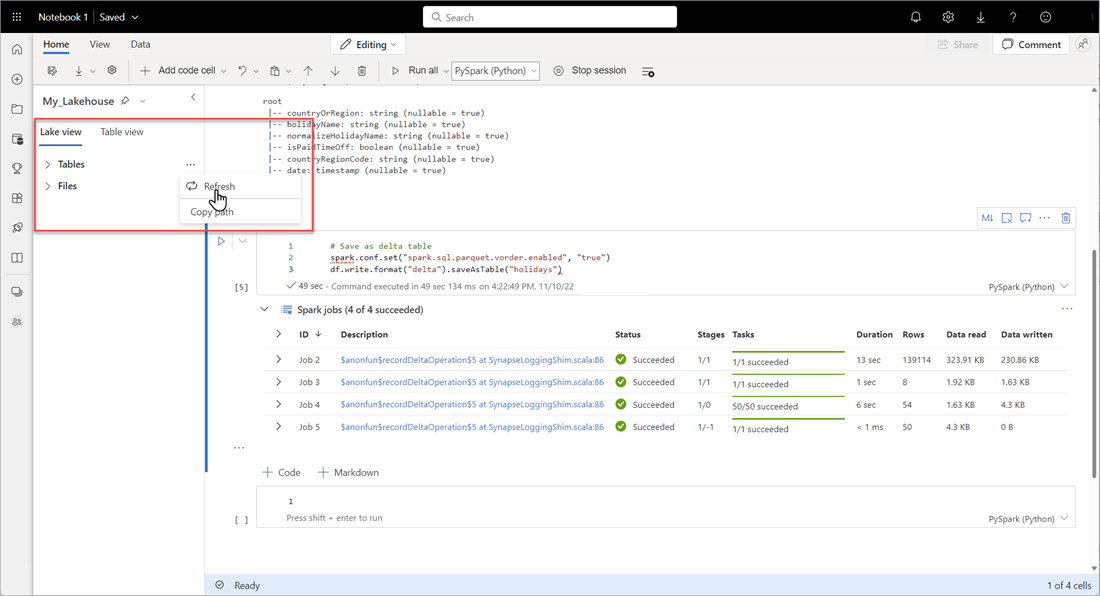
Verwenden Sie entweder dieselbe Methode wie oben oder andere unterstützte Methoden, um weitere Delta-Tabellen für die zu analysierenden Daten hinzuzufügen.
Erstellen eines einfachen Direct Lake-Modells für Ihr Seehaus
Wählen Sie in Ihrem Seehaus Neues Semantikmodellaus, und wählen Sie dann im Dialogfeld Tabellen aus, die einbezogen werden sollen.
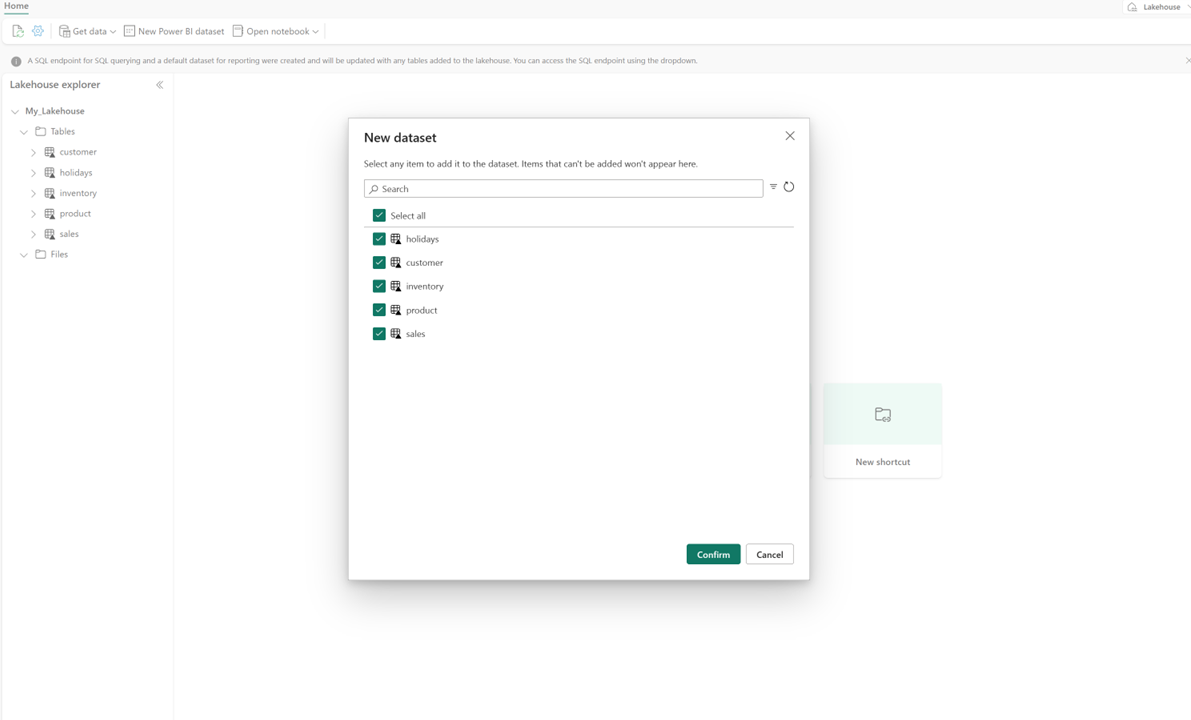
Wählen Sie Bestätigen sie aus, um das Direct Lake-Modell zu generieren. Das Modell wird basierend auf dem Namen Ihres Lakehouse automatisch im Arbeitsbereich gespeichert und öffnet dann das Modell.
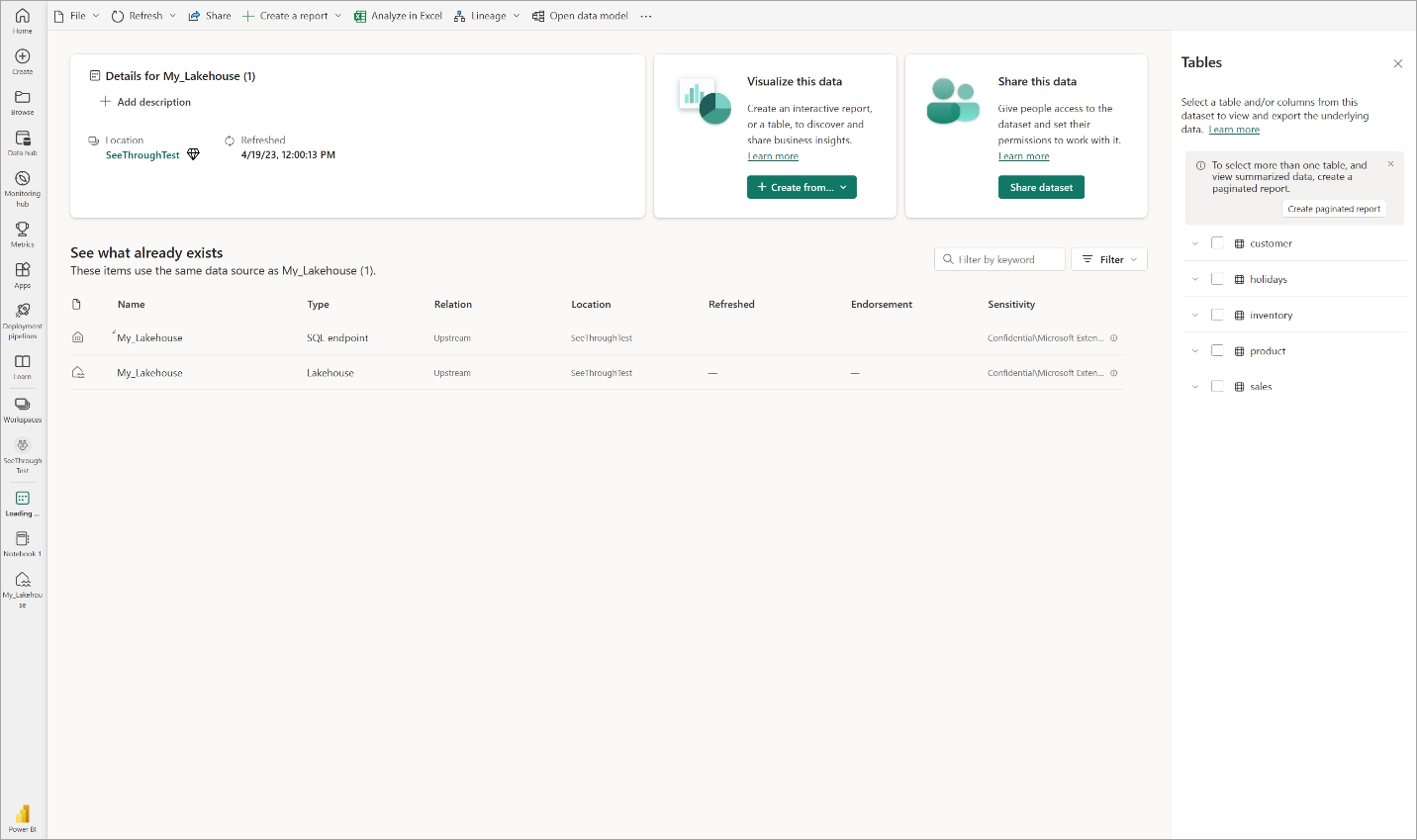
Wählen Sie Open Data Model aus, um die Webmodellierung zu öffnen, in der Sie Tabellenbeziehungen und DAX-Measures hinzufügen können.
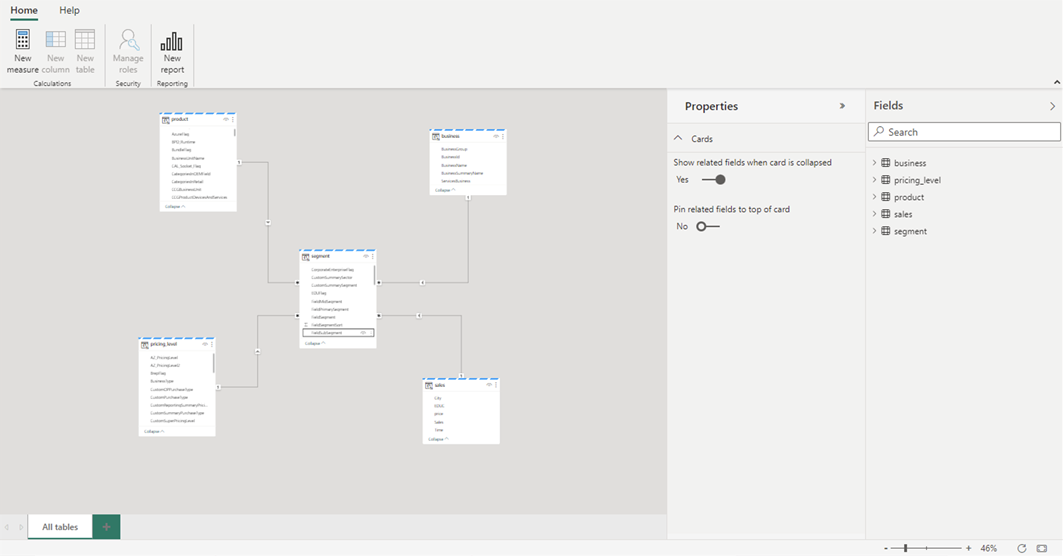
Wenn Sie mit dem Hinzufügen von Beziehungen und DAX-Measures fertig sind, können Sie Berichte erstellen, ein zusammengesetztes Modell erstellen und das Modell über XMLA-Endpunkte auf die gleiche Weise wie jedes andere Modell abfragen.