Informationen zum Zugriff auf gespiegelte Azure Cosmos DB-Daten in Lakehouse und Notebooks von Microsoft Fabric (Vorschau)
In dieser Anleitung erfahren Sie, wie Sie auf gespiegelte Azure Cosmos DB-Daten in Lakehouse und Notebooks von Microsoft Fabric (Preview) zugreifen.
Wichtig
Die Spiegelung für Azure Cosmos DB befindet sich derzeit in der Vorschau. Produktionsworkloads werden in der Vorschauversion nicht unterstützt. Derzeit werden nur Azure Cosmos DB for NoSQL-Konten unterstützt.
Voraussetzungen
- Ein vorhandenes Azure Cosmos DB for NoSQL-Konto.
- Wenn Sie kein Azure-Abonnement besitzen, testen Sie Azure Cosmos DB for NoSQL kostenlos.
- Wenn Sie über ein Azure-Abonnement verfügen, erstellen Sie einen neuen Azure Cosmos DB for NoSQL-Cluster.
- Eine vorhandene Fabric-Kapazität. Wenn Sie noch keine Kapazität haben, starten Sie einen Fabric-Test.
- Das Azure Cosmos DB for NoSQL-Konto muss für die Fabric-Spiegelung konfiguriert sein. Weitere Informationen finden Sie unter Kontoanforderungen.
Tipp
Es wird empfohlen, während der öffentlichen Vorschau eine Test- oder Entwicklungskopie Ihrer bestehenden Azure Cosmos DB-Daten zu verwenden, die schnell aus einem Backup wiederhergestellt werden kann.
Einrichten der Spiegelung und Voraussetzungen
Konfigurieren Sie die Spiegelung für die Azure Cosmos DB for NoSQL-Datenbank. Wenn Sie sich nicht sicher sind, wie Sie die Spiegelung konfigurieren, lesen Sie die Anleitung zur Konfiguration gespiegelter Datenbanken.
Navigieren Sie zum Fabric-Portal.
Erstellen Sie eine neue Verbindung und eine gespiegelte Datenbank mit den Anmeldedaten Ihres Azure Cosmos DB-Kontos.
Warten Sie, bis die Replikation die Anfangsmomentaufnahme der Daten abgeschlossen hat.
Zugriff auf gespiegelte Daten in Lakehouse und Notebooks
Verwenden Sie Lakehouse, um die Anzahl der Tools, die Sie für die Analyse Ihrer gespiegelten Azure Cosmos DB for NoSQL-Daten verwenden können, weiter zu erhöhen. Hier verwenden Sie Lakehouse, um ein Spark-Notebook zur Abfrage Ihrer Daten zu erstellen.
Navigieren Sie zurück zur Fabric-Portal-Startseite.
Wählen Sie im Navigationsmenü Erstellen.
Wählen Sie Erstellen, suchen Sie den Abschnitt Datentechnik und wählen Sie dann Lakehouse.
Geben Sie einen Namen für das Lakehouse ein und wählen Sie dann Erstellen.
Wählen Sie nun Daten abrufen und dann Neue Verknüpfung. Wählen Sie aus der Liste der Verknüpfungsoptionen Microsoft OneLake.
Wählen Sie die gespiegelte Azure Cosmos DB for NoSQL-Datenbank aus der Liste der gespiegelten Datenbanken in Ihrem Fabric-Arbeitsbereich. Wählen Sie die Tabellen aus, die Sie mit Lakehouse verwenden möchten, klicken Sie auf Weiter und dann auf Erstellen.
Öffnen Sie das Kontextmenü für die Tabelle in Lakehouse und wählen Sie Neues oder bestehendes Notebook.
Dadurch wird automatisch ein neues Notebook geöffnet und ein DataFrame mit Datenrahmen mit
SELECT LIMIT 1000geladen.Führen Sie Abfragen wie
SELECT *mit Spark aus.df = spark.sql("SELECT * FROM Lakehouse.OrdersDB_customers LIMIT 1000") display(df)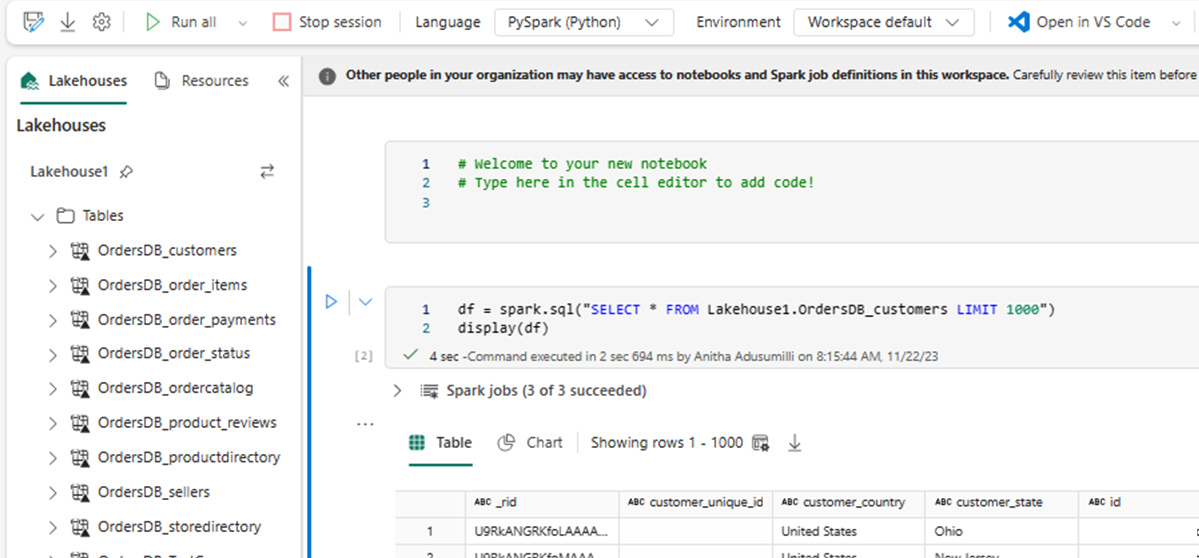
Hinweis
In diesem Beispiel wird der Name der Tabelle vorausgesetzt. Verwenden Sie beim Schreiben ihrer Spark-Abfrage Ihre eigene Tabelle.

Rückschreiben mithilfe von Spark
Schließlich können Sie Spark- und Python-Code verwenden, um Daten aus Notebooks in Fabric zurück in Ihr Azure Cosmos DB-Quellkonto zu schreiben. Vielleicht möchten Sie dies tun, um Analyseergebnisse in Cosmos DB rückzuschreiben, was dann als Bereitstellungsebene für OLTP-Anwendungen verwendet werden kann.
Erstellen Sie vier Codezellen in Ihrem Notebook.
Fragen Sie zunächst Ihre gespiegelten Daten ab.
fMirror = spark.sql("SELECT * FROM Lakehouse1.OrdersDB_ordercatalog")Tipp
Die Tabellennamen in diesen Beispielcodeblöcken setzen ein bestimmtes Datenschema voraus. Sie können diese durch Ihre eigenen Tabellen- und Spaltennamen ersetzen.
Transformieren und aggregieren Sie nun die Daten.
dfCDB = dfMirror.filter(dfMirror.categoryId.isNotNull()).groupBy("categoryId").agg(max("price").alias("max_price"), max("id").alias("id"))Als nächstes konfigurieren Sie Spark so, dass es unter Verwendung Ihrer Anmeldeinformationen, des Datenbanknamens und des Containernamens in Ihr Azure Cosmos DB for NoSQL-Konto zurückschreibt.
writeConfig = { "spark.cosmos.accountEndpoint" : "https://xxxx.documents.azure.com:443/", "spark.cosmos.accountKey" : "xxxx", "spark.cosmos.database" : "xxxx", "spark.cosmos.container" : "xxxx" }Verwenden Sie schließlich Spark, um zurück in die Quelldatenbank zu schreiben.
dfCDB.write.mode("APPEND").format("cosmos.oltp").options(**writeConfig).save()Führen Sie alle Codezellen aus.
Wichtig
Schreibvorgänge in Azure Cosmos DB verbrauchen Anforderungseinheiten (Request Units, RUs).