Bewertung von Machine Learning-Modellen mit PREDICT in Microsoft Fabric
Microsoft Fabric ermöglicht es Benutzern, Machine-Learning-Modelle mit der skalierbaren Funktion PREDICT zu operationalisieren. Diese Funktion unterstützt die Batchbewertung in jeder Compute-Engine. Benutzer können Batchvorhersagen direkt über ein Microsoft Fabric-Notebook oder die Elementseite eines bestimmten ML-Modells generieren.
In diesem Artikel wird erläutert, wie Sie PREDICT anwenden können, indem Sie Code selbst schreiben oder eine Benutzeroberfläche mit Anleitung verwenden, die Batchbewertung für Sie verarbeitet.
Voraussetzungen
Erwerben Sie ein Microsoft Fabric-Abonnement. Registrieren Sie sich alternativ für eine kostenlose Microsoft Fabric-Testversion.
Melden Sie sich bei Microsoft Fabric an.
Wechseln Sie zur Synapse-Data Science-Benutzeroberfläche, indem Sie den Umschalter für die Benutzeroberfläche auf der linken Seite Ihrer Homepage verwenden.

Begrenzungen
- Die PREDICT-Funktion wird derzeit für diese begrenzte Anzahl von ML-Modellvarianten unterstützt:
- CatBoost
- Keras
- LightGBM
- ONNX
- Prophet
- PyTorch
- Sklearn
- Spark
- Statsmodels
- TensorFlow
- XGBoost
- PREDICT erfordert, dass Sie ML-Modelle im MLflow-Format mit aufgefüllten Signaturen speichern.
- PREDICT unterstützt keine ML-Modelle mit MultiTensor-Eingängen oder -Ausgängen.
Aufrufen von PREDICT über ein Notebook
PREDICT unterstützt MLflow-gepackte Modelle in der Microsoft Fabric-Registrierung. Wenn sich in Ihrem Arbeitsbereich bereits ein trainiertes und registriertes ML-Modell befindet, können Sie mit Schritt 2 fortfahren. Andernfalls enthält Schritt 1 Beispielcode, der Sie durch das Trainieren eines logistischen Regressionsmodells führt. Sie können dieses Modell verwenden, um Batchvorhersagen am Ende der Prozedur zu generieren.
Trainieren und Registrieren eines ML-Modells bei MLflow. Im nächsten Codebeispiel wird die MLflow-API verwendet, um ein Machine Learning-Experiment zu erstellen und dann eine MLflow-Ausführung für ein logistisches scikit-learn-Regressionsmodell zu starten. Die Modellversion wird dann gespeichert und in der Microsoft Fabric-Registrierung registriert. Besuchen Sie die Ressource Trainieren von Modellen mit scikit-learn, um weitere Informationen zum Trainieren von Modellen und Nachzuverfolgen Ihrer eigenen Experimente zu erhalten.
import mlflow import numpy as np from sklearn.linear_model import LogisticRegression from sklearn.datasets import load_diabetes from mlflow.models.signature import infer_signature mlflow.set_experiment("diabetes-demo") with mlflow.start_run() as run: lr = LogisticRegression() data = load_diabetes(as_frame=True) lr.fit(data.data, data.target) signature = infer_signature(data.data, data.target) mlflow.sklearn.log_model( lr, "diabetes-model", signature=signature, registered_model_name="diabetes-model" )Laden von Testdaten als Spark-Dataframe: Um Batchvorhersagen mit dem im vorherigen Schritt trainierten ML-Modell zu generieren, benötigen Sie Testdaten in Form eines Spark-Dataframe. Ersetzen Sie im folgenden Code den Wert für die
test-Variable durch Ihre eigenen Daten.# You can substitute "test" below with your own data test = spark.createDataFrame(data.frame.drop(['target'], axis=1))Erstellen eines
MLFlowTransformer-Objekts zum Laden des ML-Modells für Rückschlüsse. Um einMLFlowTransformer-Objekt zum Generieren von Batchvorhersagen zu erstellen, müssen Sie diese Aktionen ausführen:- Angeben der
test-DataFrame-Spalten, die Sie als Modelleingaben benötigen (in diesem Fall alle) - Auswählen eines Namens für die neue Ausgabespalte (in diesem Fall
predictions) - Angeben des richtigen Modellnamens und der richtigen Modellversion zum Generieren dieser Vorhersagen
Wenn Sie Ihr eigenes ML-Modell verwenden, ersetzen Sie die Werte für die Eingabespalten, den Namen der Ausgabespalte, den Modellnamen und die Modellversion.
from synapse.ml.predict import MLFlowTransformer # You can substitute values below for your own input columns, # output column name, model name, and model version model = MLFlowTransformer( inputCols=test.columns, outputCol='predictions', modelName='diabetes-model', modelVersion=1 )- Angeben der
Generieren von Vorhersagen mithilfe der PREDICT-Funktion: Zum Aufrufen der PREDICT-Funktion können Sie die Transformer-API, die Spark SQL-API oder eine benutzerdefinierte PySpark-Funktion (User-defined Function, UDF) verwenden. In den folgenden Abschnitten wird gezeigt, wie mithilfe der verschiedenen Methoden zum Aufrufen der PREDICT-Funktion Batchvorhersagen mit den in den vorherigen Schritten definierten Testdaten und dem ML-Modell generiert werden.
PREDICT mit der Transformer-API
Dieser Code ruft die PREDICT-Funktion mit der Transformer-API auf. Wenn Sie Ihr eigenes ML-Modell verwenden, ersetzen Sie die Werte für das Modell und die Testdaten.
# You can substitute "model" and "test" below with values
# for your own model and test data
model.transform(test).show()
PREDICT mit der Spark-SQL-API
Dieser Code ruft die PREDICT-Funktion mit der Spark-SQL-API auf. Wenn Sie Ihr eigenes ML-Modell verwenden, ersetzen Sie die Werte für model_name, model_version und features durch den Modellnamen, die Modellversion und die Featurespalten.
Hinweis
Die Verwendung der Spark SQL-API für die Vorhersage erfordert weiterhin die Erstellung eines MLFlowTransformer-Objekts (wie in Schritt 3 dargestellt).
from pyspark.ml.feature import SQLTransformer
# You can substitute "model_name," "model_version," and "features"
# with values for your own model name, model version, and feature columns
model_name = 'diabetes-model'
model_version = 1
features = test.columns
sqlt = SQLTransformer().setStatement(
f"SELECT PREDICT('{model_name}/{model_version}', {','.join(features)}) as predictions FROM __THIS__")
# You can substitute "test" below with your own test data
sqlt.transform(test).show()
PREDICT mit einer benutzerdefinierten Funktion
Dieser Code ruft die PREDICT-Funktion mit einem benutzerdefinierten PySpark-UDF auf. Wenn Sie Ihr eigenes ML-Modell verwenden, ersetzen Sie die Werte für das Modell und die Features.
from pyspark.sql.functions import col, pandas_udf, udf, lit
# You can substitute "model" and "features" below with your own values
my_udf = model.to_udf()
features = test.columns
test.withColumn("PREDICT", my_udf(*[col(f) for f in features])).show()
Generieren von PREDICT-Code über die Elementseite eines ML-Modells
Auf der Elementseite eines beliebigen ML-Modells können Sie eine der folgenden Optionen auswählen, um die Generierung von Batchvorhersagen für eine bestimmte Modellversion mit der PREDICT-Funktion zu starten:
- Kopieren einer Codevorlage in ein Notebook und Anpassen der Parameter
- Verwenden einer Benutzeroberfläche mit Anleitung zum Generieren von PREDICT-Code
Verwenden einer Benutzeroberfläche mit Anleitung
Die geführte Benutzeroberfläche führt Sie durch diese Schritte:
- Auswählen der Quelldaten für die Bewertung
- Zuordnen der Daten zu den Eingaben Ihres ML-Modells
- Angeben des Ziels für die Ausgaben Ihres Modells
- Ein Notebook erstellen, das PREDICT verwendet, um Vorhersageergebnisse zu erzeugen und zu speichern
Gehen Sie wie folgt vor, um die Benutzeroberfläche mit Anleitung zu nutzen:
Navigieren Sie zur Elementseite für eine bestimmte ML-Modellversion.
Wählen Sie in der Dropdownliste Diese Version anwenden die Option Dieses Modell im Assistenten anwenden aus.

Im Schritt „Eingabetabelle auswählen” wird das Fenster „ML-Modellvorhersagen anwenden” geöffnet.
Wählen Sie eine Eingabetabelle aus einem Lakehouse in Ihrem aktuellen Arbeitsbereich aus.
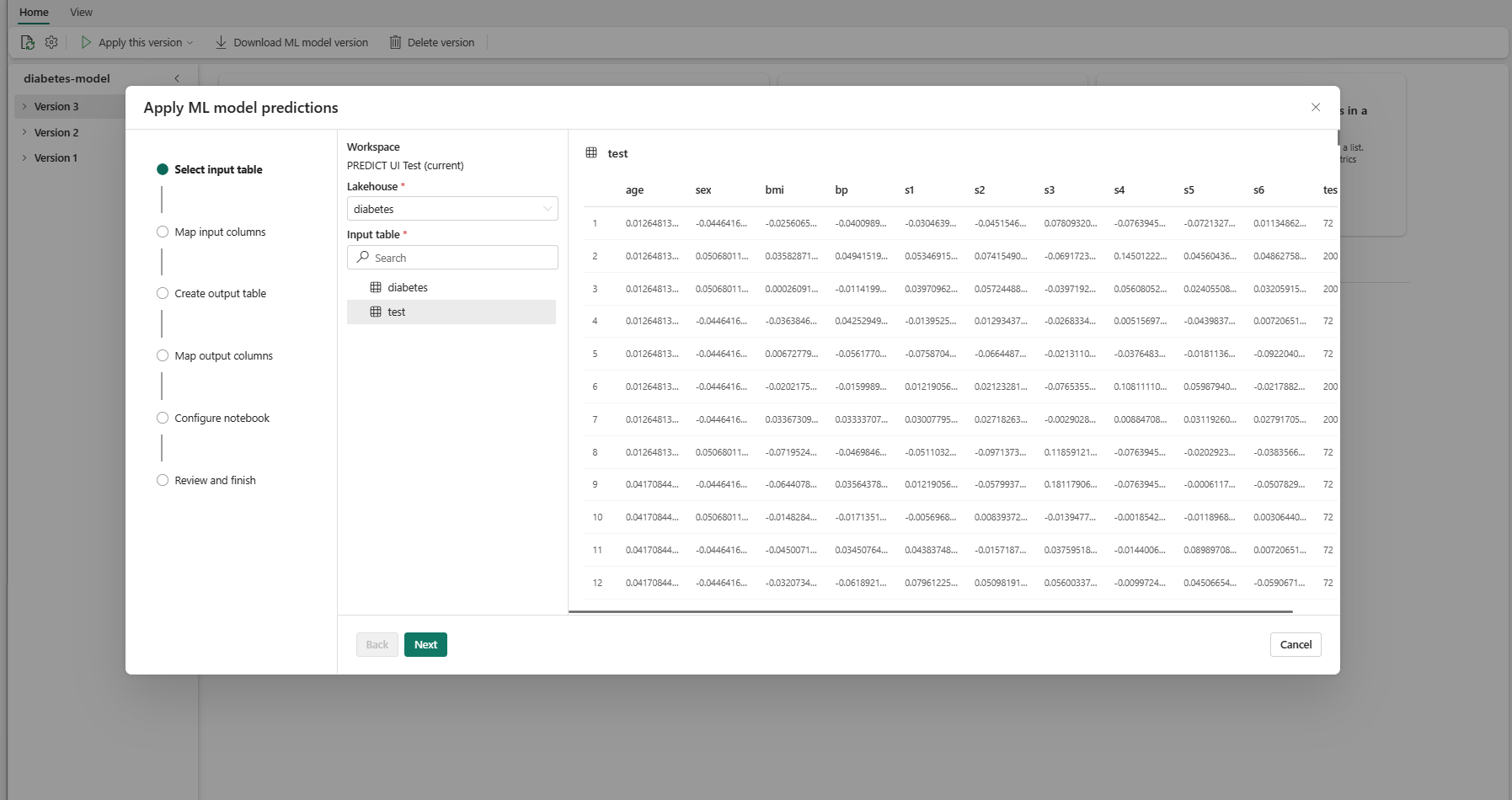
Klicken Sie auf Weiter, um zum Schritt „Eingabespalten zuordnen“ zu wechseln.
Ordnen Sie Spaltennamen aus der Quelltabelle den Eingabefeldern des ML-Modells zu, die aus der Signatur des Modells abgerufen wurden. Sie müssen eine Eingabespalte für alle erforderlichen Felder des Modells bereitstellen. Außerdem hinaus müssen die Datentypen der Quellspalte den erwarteten Datentypen des Modells entsprechen.
Tipp
Der Assistent füllt diese Zuordnung vorab auf, wenn die Spaltennamen der Eingabetabelle mit den Spaltennamen übereinstimmen, die in der ML-Modellsignatur protokolliert wurden.
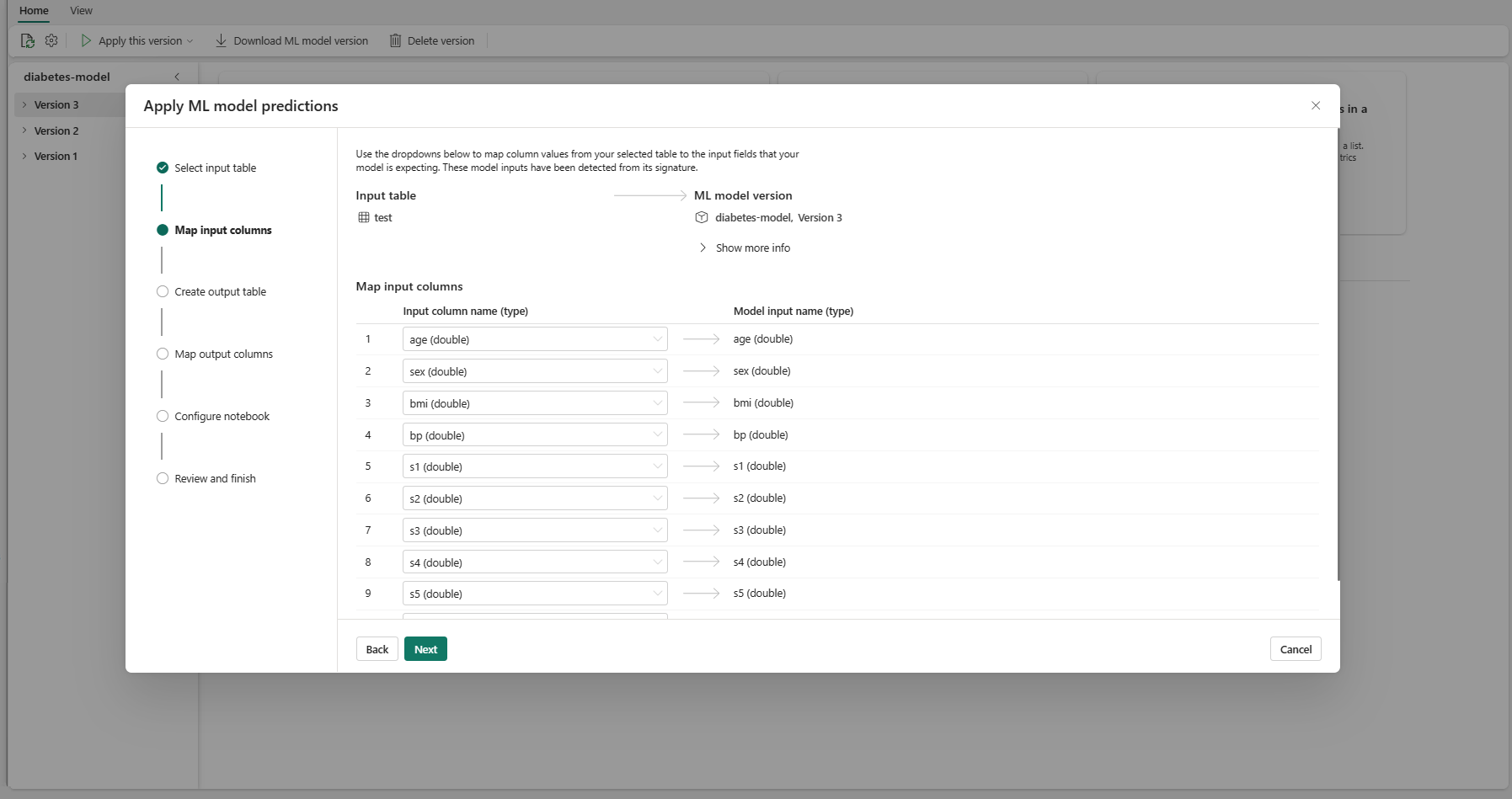
Klicken Sie auf Weiter, um zum Schritt „Ausgabetabelle erstellen“ zu wechseln.
Geben Sie einen Namen für eine neue Tabelle im ausgewählten Lakehouse Ihres aktuellen Arbeitsbereichs an. Diese Ausgabetabelle speichert die Eingabewerte Ihres ML-Modells und fügt die Vorhersagewerte an diese Tabelle an. Standardmäßig wird die Ausgabetabelle im selben Lakehouse wie die Eingabetabelle erstellt. Sie können das Ziel-Lakehouse ändern.

Klicken Sie auf Weiter, um zum Schritt „Ausgabespalten zuordnen“ zu wechseln.
Verwenden Sie die bereitgestellten Textfelder, um die Spalten in der Ausgabetabelle zu benennen, in der die Vorhersagen des ML-Modells gespeichert werden.
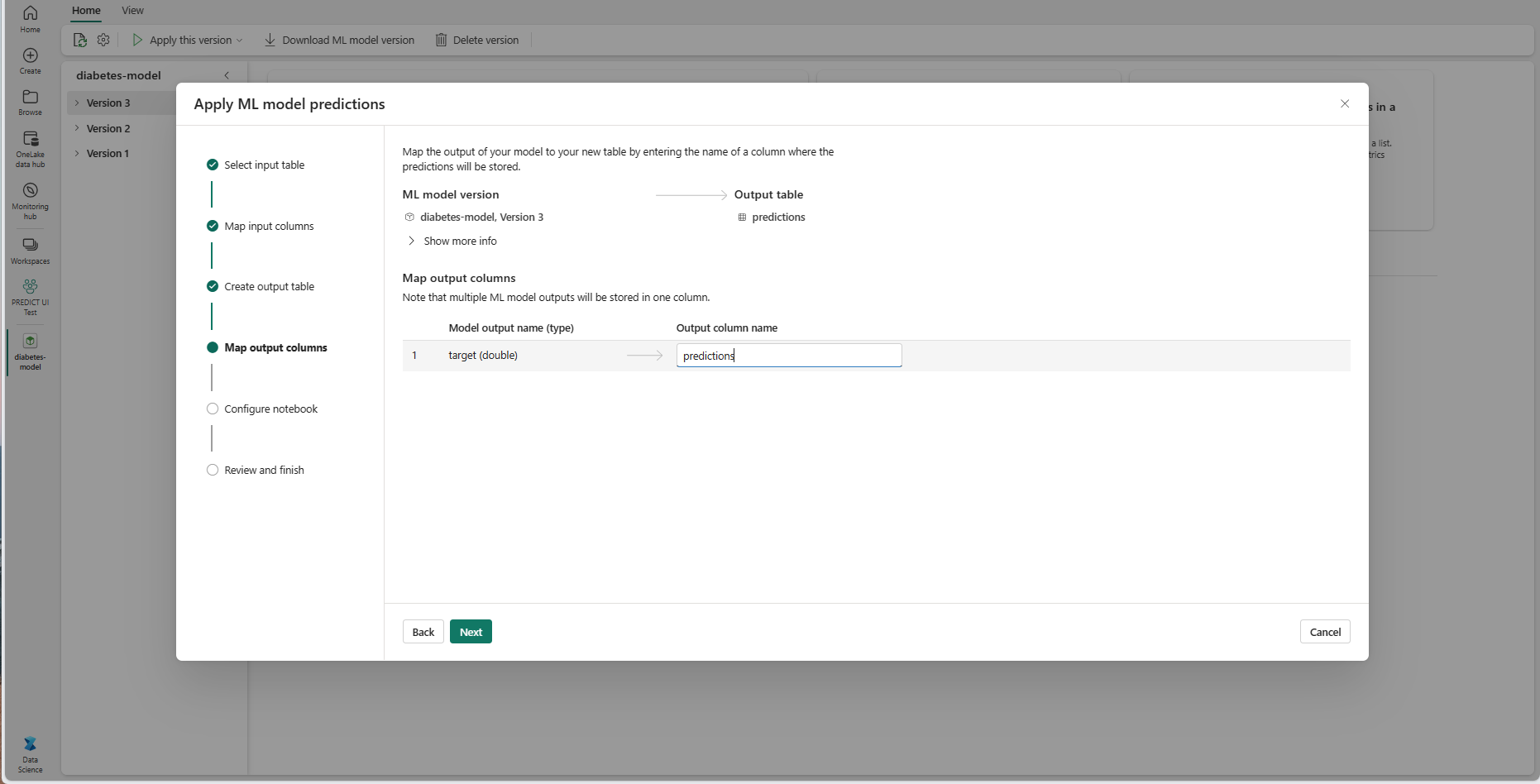
Klicken Sie auf Weiter, um zum Schritt „Notebook konfigurieren“ zu wechseln.
Geben Sie einen Namen für ein neues Notebook an, in dem der generierte PREDICT-Code ausgeführt wird. Der Assistent zeigt in diesem Schritt eine Vorschau des generierten Codes an. Sie können den Code in Ihre Zwischenablage kopieren und ihn bei Bedarf in ein vorhandenes Notebook einfügen.

Klicken Sie auf Weiter, um zum Schritt „Überprüfen und abschließen“ zu wechseln.
Überprüfen Sie die Details auf der Zusammenfassungsseite, und wählen Sie Notebook erstellen aus, um Ihrem Arbeitsbereich das neue Notebook mit dem generierten Code hinzuzufügen. Sie werden direkt zu diesem Notebook weitergeleitet, wo Sie den Code ausführen können, um Vorhersagen zu generieren und zu speichern.








Verwenden einer anpassbaren Codevorlage
Gehen Sie wie folgt vor, um eine Codevorlage zum Generieren von Batchvorhersagen zu verwenden:
- Navigieren Sie zur Elementseite für eine bestimmte ML-Modellversion.
- Wählen Sie in der Dropdownliste Diese Version anwenden die Option Code zum Anwenden kopieren aus. Durch die Auswahl können Sie eine anpassbare Codevorlage kopieren.
Sie können diese Codevorlage in ein Notebook einfügen, um Batchvorhersagen mit Ihrem ML-Modell zu generieren. Um die Codevorlage erfolgreich auszuführen, müssen Sie die folgenden Werte manuell ersetzen:
<INPUT_TABLE>: Dies ist der Dateipfad für die Tabelle, die Eingaben für das ML-Modell bereitstellt<INPUT_COLS>: Dies ist ein Array von Spaltennamen aus der Eingabetabelle, das in das ML-Modell eingefügt wird<OUTPUT_COLS>: Dies ist ein Name für eine neue Spalte in der Ausgabetabelle, in der Vorhersagen gespeichert werden<MODEL_NAME>: Dies ist der Name des ML-Modells, das zum Generieren von Vorhersagen verwendet werden soll<MODEL_VERSION>: Dies ist die Version des ML-Modells, das zum Generieren von Vorhersagen verwendet werden soll<OUTPUT_TABLE>: Dies ist der Dateipfad für die Tabelle, in der die Vorhersagen gespeichert werden

import mlflow
from synapse.ml.predict import MLFlowTransformer
df = spark.read.format("delta").load(
<INPUT_TABLE> # Your input table filepath here
)
model = MLFlowTransformer(
inputCols=<INPUT_COLS>, # Your input columns here
outputCol=<OUTPUT_COLS>, # Your new column name here
modelName=<MODEL_NAME>, # Your ML model name here
modelVersion=<MODEL_VERSION> # Your ML model version here
)
df = model.transform(df)
df.write.format('delta').mode("overwrite").save(
<OUTPUT_TABLE> # Your output table filepath here
)