Umfassendes Szenario für Data Factory: Einführung und Architektur
Dieses Tutorial hilft Ihnen, den Auswertungsprozess für Data Factory in Microsoft Fabric zu beschleunigen, indem eine Schritt-für-Schritt-Anleitung bereitgestellt wird, das ein vollständiges Datenintegrationsszenario innerhalb einer Stunde ermöglicht. Am Ende dieses Tutorials verstehen Sie den Nutzen und die wichtigsten Funktionen von Data Factory und wissen, wie Sie eine umfassendes allgemeines Datenintegrationsszenario durchführen.
Übersicht: Warum Data Factory in Microsoft Fabric?
In diesem Abschnitt erfahren Sie mehr über die Rolle von Fabric im Allgemeinen und die Rolle, die Data Factory darin spielt.
Verstehen des Nutzens von Microsoft Fabric
Microsoft Fabric bietet eine zentrale Anlaufstelle für alle analytischen Anforderungen für jedes Unternehmen. Microsoft Fabric deckt ein vollständiges Spektrum von Diensten ab, einschließlich Datenverschiebung, Data Lake, Datentechnik, Datenintegration und Data Science, Echtzeitanalysen und Business Intelligence. Mit Fabric ist es nicht erforderlich, verschiedene Dienste von mehreren Anbietern zusammenzufügen. Stattdessen genießen Ihre Benutzer*innen ein komplettes, hoch integriertes, alleinstehendes und umfassendes Produkt, das leicht zu verstehen, zu integrieren, zu erstellen und zu betreiben ist.
Verstehen des Werts von Data Factory in Microsoft Fabric
Data Factory in Fabric kombiniert die Benutzerfreundlichkeit von Power Query mit dem Umfang und der Leistungsfähigkeit von Azure Data Factory. Data Factory vereint das Beste aus beiden Produkten zu einer einheitlichen Lösung. Das Ziel besteht darin, sicherzustellen, dass die Datenintegration in Factory sowohl für Citizen Developer als auch für professionelle Datenentwickler*innen gut funktioniert. Data Factory in Fabric bietet KI-fähige Low-Code-Datenaufbereitungs- und -Transformationsumgebungen, Transformation im Petabytemaßstab sowie Hunderte von Connectors mit Hybrid- und Multi-Cloud-Konnektivität. Purview bietet Governance, und der Dienst bietet Verpflichtungen für Daten und Vorgänge auf Unternehmensniveau, CI/CD, Anwendungslebenszyklusverwaltung und Überwachung.
Einführung: Grundlegendes zu drei wichtigen Features von Data Factory
- Datenerfassung: Mit der Copy-Aktivität in Pipelines können Sie Daten im Petabytemaßstab aus Hunderten von Datenquellen zur weiteren Verarbeitung in Ihr Data Lakehouse verschieben.
- Datentransformation und -aufbereitung: Dataflow Gen2 bietet eine Low-Code-Schnittstelle zum Transformieren Ihrer Daten mithilfe von mehr als 300 Datentransformationen, mit der Möglichkeit, die transformierten Ergebnisse in mehrere Ziele wie Azure SQL-Datenbanken, Lakehouse usw. zu laden.
- Automatisierung des umfassenden Integrationsablaufs: Pipelines ermöglichen die Orchestrierung von Aktivitäten, die beispielsweise Kopier-, Dataflow- und Notebookaktivitäten umfassen. Auf diese Weise können Sie Aktivitäten an einem zentralen Ort verwalten. Aktivitäten in einer Pipeline können miteinander verkettet und sequenziell durchgeführt oder unabhängig voneinander parallel durchgeführt werden.
In diesem Anwendungsfall für die umfassende Datenintegration behandeln Sie Folgendes:
- Erfassen von Daten mithilfe des Assistenten zum Kopieren in einer Pipeline
- Transformieren der Daten mithilfe eines No-Code-Dataflows oder durch Schreiben Ihres eigenen Codes zum Verarbeiten der Daten mit einer Skript- oder Notebookaktivität
- Automatisierungsprozess des umfassenden Datenintegrationsablaufs mithilfe einer Pipeline mit Triggern und flexiblen Ablaufsteuerungsaktivitäten
Aufbau
In den nächsten 50 Minuten müssen Sie ein umfassendes Datenintegrationsszenario abschließen. Darin enthalten sind das Erfassen von Rohdaten aus einem Quellspeicher in die Bronze-Tabelle eines Lakehouse, die Verarbeitung aller Daten, das Verschieben in die Gold-Tabelle des Data Lakehouse, das Senden einer E-Mail, um Sie zu benachrichtigen, sobald alle Aufträge abgeschlossen sind, und schließlich die Einrichtung des gesamten Ablaufs für die geplante Ausführung.
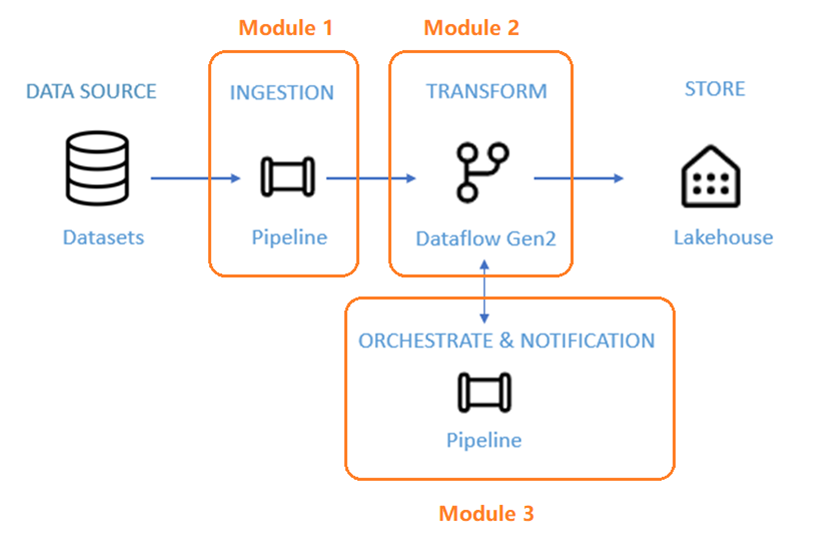
Das Szenario ist in drei Module unterteilt:
- Modul 1: Erstellen einer Pipeline mit Data Factory: Erfassen von Rohdaten aus einem Blobspeicher in einer Bronze-Tabelle in einem Data Lakehouse
- Modul 2: Transformieren von Daten mit einem Dataflow in Data Factory: Verarbeiten der Rohdaten aus Ihrer Bronze-Tabelle und Verschieben der Daten in eine Gold-Tabelle im Data Lakehouse
- Modul 3: Abschließen der ersten Datenintegrationsjourney: Sie erhalten eine E-Mail, sobald alle Aufträge abgeschlossen wurde. Schließlich können Sie den gesamten Flow für einen festgelegten Zeitplan einrichten.
Sie verwenden das Beispieldataset NYC-Taxi als Datenquelle für das Tutorial. Sobald Sie fertig sind, erhalten Sie mit Data Factory in Microsoft Fabric einen Einblick in die täglichen Rabatte auf Taxitarife für einen bestimmten Zeitraum.
Zugehöriger Inhalt
In dieser Einführung in unserem umfassenden Tutorial für Ihre erste Datenintegration mit Data Factory in Microsoft Fabric haben Sie Folgendes gelernt:
- Den Nutzen und die Rolle von Microsoft Fabric
- Den Nutzen und die Rolle von Data Factory in Fabric
- Wichtige Features von Data Factory
- Zusammenfassung der Lernziele in diesem Tutorial
Fahren Sie jetzt mit dem nächsten Abschnitt fort, um Ihre Datenpipeline zu erstellen.