Inkrementelle Aktualisierung in Dataflow Gen2 (Vorschau)
In diesem Artikel führen wir die inkrementelle Datenaktualisierung in Dataflow Gen2 für die Data Factory von Microsoft Fabric ein. Wenn Sie Datenflüsse für die Erfassung und Transformation von Daten verwenden, gibt es Szenarien, in denen Sie nur neue oder aktualisierte Daten aktualisieren müssen – insbesondere, wenn Ihre Daten weiter wachsen. Die inkrementelle Aktualisierungsfunktion behebt diesen Bedarf, indem Sie die Aktualisierungszeiten reduziert, die Zuverlässigkeit durch die Vermeidung lang ausgeführter Vorgänge verbessert und die Ressourcenauslastung minimiert.
Voraussetzungen
Um die inkrementelle Aktualisierung in Dataflow Gen2 zu verwenden, müssen Sie die folgenden Voraussetzungen erfüllen:
- Sie müssen über eine Fabric-Kapazität verfügen.
- Ihre Datenquelle unterstützt Folding (empfohlen) und muss eine Date/DateTime-Spalte enthalten, die zum Filtern der Daten verwendet werden kann.
- Sie sollten über ein Datenziel verfügen, das die inkrementelle Aktualisierung unterstützt. Weitere Informationen hierzu können Sie unter Zielsupport aufrufen.
- Bevor Sie beginnen, stellen Sie sicher, dass Sie die Einschränkungen der inkrementellen Aktualisierung überprüft haben. Weitere Informationen hierzu finden Sie unter Einschränkungen.
Zielunterstützung
Die folgenden Datenziele werden für die inkrementelle Aktualisierung unterstützt:
- Fabric Warehouse
- Azure SQL-Datenbank
- Azure Synapse Analytics
Andere Ziele wie Lakehouse können in Kombination mit der inkrementellen Aktualisierung mithilfe einer zweiten Abfrage verwendet werden, die auf die bereitgestellten Daten verweist, um das Datenziel zu aktualisieren. Auf diese Weise können Sie die inkrementelle Aktualisierung weiterhin verwenden, um die Datenmenge zu reduzieren, die verarbeitet und aus dem Quellsystem abgerufen werden muss. Sie müssen jedoch eine vollständige Aktualisierung von den bereitgestellten Daten zum Datenziel durchführen.
Verwenden der inkrementellen Aktualisierung
Erstellen Sie einen neuen Dataflow Gen2 oder öffnen Sie einen vorhandenen Dataflow Gen2.
Erstellen Sie im Datenflusseditor eine neue Abfrage, welche die Daten abruft, die Sie inkrementell aktualisieren möchten.
Überprüfen Sie die Datenvorschau, um sicherzustellen, dass die Abfrage Daten zurückgibt, die eine Spalte „DateTime“, „Date“ oder „DateTimeZone“ enthalten, die Sie zum Filtern der Daten verwenden können.
Stellen Sie sicher, dass die Abfrage vollständig Folding unterstützt, was bedeutet, dass die Abfrage vollständig im Quellsystem ausgeführt wird. Wenn die Abfrage nicht vollständig gefaltet wird, müssen Sie die Abfrage so ändern, dass sie vollständig gefaltet wird. Sie können sicherstellen, dass die Abfrage vollständig gefaltet wird, indem Sie die Abfrageschritte im Abfrageeditor überprüfen.
Klicken Sie mit der rechten Maustaste auf die Abfrage und wählen Sie inkrementelle Aktualisierung aus.
Geben Sie die erforderlichen Einstellungen für die inkrementelle Aktualisierung an.
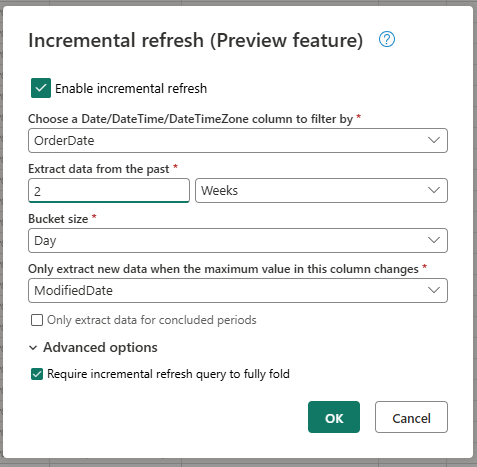
- Wählen Sie eine DateTime-Spalte aus, nach der gefiltert werden soll.
- Extrahieren Sie Daten aus der Vergangenheit.
- Bucketgröße.
- Extrahieren Sie nur neue Daten, wenn sich der Maximalwert in dieser Spalte ändert.
Konfigurieren Sie bei Bedarf die erweiterten Einstellungen.
- Inkrementelle Aktualisierungsabfragen sind erforderlich um Folding vollständig zu unterstützen.
Wählen Sie OK, um die Einstellungen zu speichern.
Wenn Sie möchten, können Sie jetzt ein Datenziel für die Abfrage einrichten. Stellen Sie sicher, dass Sie diese Einrichtung vor der ersten inkrementellen Aktualisierung durchführen, da ihr Datenziel sonst nur die inkrementell geänderten Daten seit der letzten Aktualisierung enthält.
Veröffentlichen Sie den Dataflow Gen2.
Nachdem Sie die inkrementelle Aktualisierung konfiguriert haben, aktualisiert der Datenfluss die Daten basierend auf den von Ihnen bereitgestellten Einstellungen automatisch inkrementell. Der Datenfluss ruft nur die Daten ab, die seit der letzten Aktualisierung geändert wurden. Der Datenfluss wird also schneller ausgeführt und verbraucht weniger Ressourcen.
Funktionsweise der inkrementellen Aktualisierung im Hintergrund
Die inkrementelle Aktualisierung funktioniert, indem die Daten basierend auf der DateTime-Spalte in Buckets aufgeteilt werden. Jeder Bucket enthält die Daten, die seit der letzten Aktualisierung geändert wurden. Der Datenfluss weiß, was geändert wurde, indem der Maximalwert in der von Ihnen angegebenen Spalte überprüft wird. Wenn sich der Maximalwert für diesen Bucket geändert hat, ruft der Dataflow den gesamten Bucket ab und ersetzt die Daten im Ziel. Wenn sich der Maximalwert nicht geändert hat, ruft der Datenfluss keine Daten ab. Die folgenden Abschnitte enthalten eine allgemeine Übersicht darüber, wie die inkrementelle Aktualisierung schrittweise funktioniert.
Erster Schritt: Auswerten der Änderungen
Wenn der Datenfluss ausgeführt wird, wertet er zuerst die Änderungen in der Datenquelle aus. Diese Auswertung erfolgt, indem der Maximalwert in der DateTime-Spalte mit dem Maximalwert in der vorherigen Aktualisierung verglichen wird. Wenn sich der Maximalwert geändert hat oder wenn es sich um die erste Aktualisierung handelt, markiert der Datenfluss den Bucket als geändert und listet ihn zur Verarbeitung auf. Wenn sich der Maximalwert nicht geändert hat, überspringt der Datenfluss den Bucket und verarbeitet ihn nicht.
Zweiter Schritt: Abrufen der Daten
Jetzt ist der Datenfluss bereit die Daten abzurufen. Er ruft die Daten für jeden geänderten Bucket ab. Der Datenfluss führt diesen Abruf parallel aus, um die Leistung zu verbessern. Der Datenfluss ruft die Daten aus dem Quellsystem ab und lädt sie in den Stagingbereich. Der Datenfluss ruft nur die Daten ab, die sich im Bucketbereich befinden. Mit anderen Worten, der Datenfluss ruft nur die Daten ab, die seit der letzten Aktualisierung geändert wurden.
Letzter Schritt: Ersetzen der Daten im Datenziel
Der Datenfluss ersetzt die Daten im Ziel durch die neuen Daten. Der Datenfluss verwendet die replace-Methode, um die Daten im Ziel zu ersetzen. Das heißt, der Datenfluss löscht zuerst die Daten im Ziel für diesen Bucket und fügt dann die neuen Daten ein. Der Datenfluss wirkt sich nicht auf die Daten aus, die sich außerhalb des Bucketbereichs befinden. Wenn Sie also Daten im Ziel haben, die älter als der erste Bucket sind, hat die inkrementelle Aktualisierung keine Auswirkungen auf diese Daten.
Inkrementelle Aktualisierungseinstellungen erläutert
Zum Konfigurieren der inkrementellen Aktualisierung müssen Sie die folgenden Einstellungen angeben.
Allgemeine Einstellungen
Die allgemeinen Einstellungen sind erforderlich und geben die grundlegende Konfiguration für die inkrementelle Aktualisierung an.
Wählen Sie eine DateTime-Spalte aus, nach der gefiltert werden soll
Diese Einstellung ist erforderlich und gibt die Spalte an, die Datenflüsse zum Filtern der Daten verwenden. Diese Spalte sollte entweder eine DateTime-, Date- oder DateTimeZone-Spalte sein. Der Datenfluss verwendet diese Spalte, um die Daten zu filtern und ruft nur die Daten ab, die seit der letzten Aktualisierung geändert wurden.
Extrahieren von Daten aus der Vergangenheit
Diese Einstellung ist erforderlich und gibt an, wie weit zurück der Datenfluss Daten extrahieren soll. Diese Einstellung wird verwendet, um den anfänglichen Datenladevorgang abzurufen. Der Datenfluss ruft alle Daten aus dem Quellsystem ab, die sich innerhalb des angegebenen Zeitraums befinden. Dabei sind folgende Werte möglich:
- x Tage
- x Wochen
- x Monate
- x Quartale
- x Jahre
Wenn Sie beispielsweise 1 Monat angeben, ruft der Datenfluss alle neuen Daten aus dem Quellsystem ab, die sich innerhalb des letzten Monats befinden.
Bucketgröße
Diese Einstellung ist erforderlich und gibt die Größe der Buckets an, die der Datenfluss zum Filtern der Daten verwendet. Der Datenfluss teilt die Daten in Buckets basierend auf der DateTime-Spalte auf. Jeder Bucket enthält die Daten, die seit der letzten Aktualisierung geändert wurden. Die Bucketgröße bestimmt, wie viele Daten in jeder Iteration verarbeitet werden. Eine kleinere Bucketgröße bedeutet, dass der Datenfluss weniger Daten in jeder Iteration verarbeitet, aber es bedeutet auch, dass mehr Iterationen erforderlich sind, um alle Daten zu verarbeiten. Eine größere Bucketgröße bedeutet, dass der Datenfluss in jeder Iteration mehr Daten verarbeitet, bedeutet aber auch, dass weniger Iterationen erforderlich sind, um alle Daten zu verarbeiten.
Nur neue Daten extrahieren, wenn sich der Maximalwert in dieser Spalte ändert
Diese Einstellung ist erforderlich und gibt die Spalte an, die der Datenfluss verwendet, um zu bestimmen, ob die Daten geändert wurden. Der Datenfluss vergleicht den Maximalwert in dieser Spalte mit dem Maximalwert in der vorherigen Aktualisierung. Wenn der Maximalwert geändert wird, ruft der Datenfluss die seit der letzten Aktualisierung geänderten Daten ab. Wenn der Maximalwert nicht geändert wird, ruft der Datenfluss keine Daten ab.
Daten nur für abgeschlossene Zeiträume extrahieren
Diese Einstellung ist optional und gibt an, ob der Datenfluss nur Daten für abgeschlossene Zeiträume extrahieren soll. Wenn diese Einstellung aktiviert ist, extrahiert der Datenfluss nur Daten für Zeiträume, die abgeschlossen wurden. Der Datenfluss extrahiert also nur Daten für Zeiträume, die abgeschlossen sind und keine zukünftigen Daten enthalten. Wenn diese Einstellung deaktiviert ist, extrahiert der Datenfluss Daten für alle Zeiträume, einschließlich Perioden, die nicht abgeschlossen sind und zukünftige Daten enthalten.
Wenn Sie beispielsweise über eine DateTime-Spalte verfügen, die das Datum der Transaktion enthält und Sie nur die vollständigen Monate aktualisieren möchten, können Sie diese Einstellung in Kombinationen mit der Bucketgröße von month aktivieren. Daher extrahiert der Datenfluss nur Daten für vollständige Monate und extrahiert keine Daten für unvollständige Monate.
Erweiterte Einstellungen
Einige Einstellungen gelten als erweitert und sind für die meisten Szenarien nicht erforderlich.
Inkrementelle Aktualisierungsabfragen erfordern um Folding vollständig zu unterstützen
Diese Einstellung ist optional und gibt an, ob auf die auf die inkrementelle Aktualisierung verwendete Abfrage vollständig Folding angewendet werden muss. Wenn diese Einstellung aktiviert ist, muss auf die für die inkrementelle Aktualisierung verwendete Abfrage vollständig Folding angewendet werden. Mit anderen Worten, die Abfrage muss vollständig auf dem Quellsystem durchgeführt werden. Wenn diese Einstellung deaktiviert ist, muss die für die inkrementelle Aktualisierung verwendete Abfrage nicht vollständig Folding unterstützen. In diesem Fall kann die Abfrage teilweise an das Quellsystem übertragen werden. Es wird dringend empfohlen, diese Einstellung zu aktivieren, um die Leistung zu verbessern, um unnötige und ungefilterte Daten zu vermeiden.
Begrenzungen
Es werden nur SQL-basierte Datenziele unterstützt
Derzeit werden nur SQL-basierte Datenziele für die inkrementelle Aktualisierung unterstützt. Sie können also nur Fabric Warehouse, Azure SQL-Datenbank oder Azure Synapse Analytics als Datenziel für die inkrementelle Aktualisierung verwenden. Der Grund für diese Einschränkung besteht darin, dass diese Datenziele die SQL-basierten Vorgänge unterstützen, die für die inkrementelle Aktualisierung erforderlich sind. Wir verwenden Vorgänge zum Löschen und Einfügen, um die Daten im Datenziel zu ersetzen, die nicht parallel zu anderen Datenzielen ausgeführt werden können.
Das Datenziel muss auf ein festes Schema festgelegt werden
Das Datenziel muss auf ein festes Schema festgelegt werden. Das bedeutet, dass das Schema der Tabelle im Datenziel fest sein muss und sich nicht ändern kann. Wenn das Schema der Tabelle im Datenziel auf ein dynamisches Schema festgelegt ist, müssen Sie es in ein festes Schema ändern, bevor Sie die inkrementelle Aktualisierung konfigurieren.
Die einzige unterstützte Aktualisierungsmethode im Datenziel ist replace
Die einzige unterstützte Aktualisierungsmethode im Datenziel ist replace, was bedeutet, dass der Datenfluss die Daten für jeden Bucket im Datenziel durch die neuen Daten ersetzt. Daten, die sich außerhalb des Bucketbereichs befinden, sind jedoch nicht betroffen. Wenn Sie also Daten im Datenziel haben, die älter als der erste Bucket sind, hat die inkrementelle Aktualisierung keine Auswirkungen auf diese Daten.
Die maximale Anzahl von Buckets beträgt 50 für eine einzelne Abfrage und 150 für den gesamten Datenfluss
Die maximale Anzahl von Buckets pro Abfrage, die der Datenfluss unterstützt, beträgt 50. Wenn Sie mehr als 50 Buckets haben, müssen Sie die Bucketgröße erhöhen oder den Bucketbereich reduzieren, um die Anzahl der Buckets zu senken. Für den gesamten Datenfluss beträgt die maximale Anzahl von Buckets 150. Wenn Sie mehr als 150 Buckets im Datenfluss haben, müssen Sie die Anzahl der inkrementellen Aktualisierungsabfragen verringern oder die Bucketgröße erhöhen, um die Anzahl der Buckets zu verringern.
Unterschiede zwischen der inkrementellen Aktualisierung in Dataflow Gen1 und Dataflow Gen2
Zwischen Dataflow Gen1 und Dataflow Gen2 gibt es einige Unterschiede bei der Funktionsweise der inkrementellen Aktualisierung. In der folgenden Liste werden die Hauptunterschiede zwischen der inkrementellen Aktualisierung in Dataflow Gen1 und Dataflow Gen2 erläutert.
- Die inkrementelle Aktualisierung ist jetzt ein erstklassiges Feature in Dataflow Gen2. In Dataflow Gen1 mussten Sie die inkrementelle Aktualisierung konfigurieren, nachdem Sie den Datenfluss veröffentlicht haben. In Dataflow Gen2 ist die inkrementelle Aktualisierung jetzt ein erstklassiges Feature, das Sie direkt im Datenflusseditor konfigurieren können. Dieses Feature erleichtert das Konfigurieren der inkrementellen Aktualisierung und verringert das Risiko von Fehlern.
- In Dataflow Gen1 mussten Sie den Verlaufsdatenbereich angeben, wenn Sie die inkrementelle Aktualisierung konfiguriert haben. In Dataflow Gen2 müssen Sie nicht den historischen Datenbereich angeben. Der Datenfluss entfernt keine Daten aus dem Ziel, das sich außerhalb des Bucketbereichs befindet. Wenn Sie also Daten im Ziel haben, die älter als der erste Bucket sind, hat die inkrementelle Aktualisierung keine Auswirkungen auf diese Daten.
- In Dataflow Gen1 mussten Sie beim Konfigurieren der inkrementellen Aktualisierung die Parameter für die inkrementelle Aktualisierung angeben. In Dataflow Gen2 müssen Sie die Parameter für die inkrementelle Aktualisierung nicht angeben. Der Datenfluss fügt die Filter und Parameter automatisch als letzten Schritt in der Abfrage hinzu. Daher müssen Sie die Parameter für die inkrementelle Aktualisierung nicht manuell angeben.
Häufig gestellte Fragen
Ich habe eine Warnung erhalten, dass ich dieselbe Spalte zum Erkennen von Änderungen und Filtern verwendet habe. Was bedeutet das?
Wenn Sie eine Warnung erhalten, dass Sie dieselbe Spalte zum Erkennen von Änderungen und Filtern verwendet haben, bedeutet dies, dass die Spalte, die Sie zum Erkennen von Änderungen angegeben haben, auch zum Filtern der Daten verwendet wird. Wir empfehlen diese Verwendung nicht, da sie zu unerwarteten Ergebnissen führen kann. Stattdessen wird empfohlen, unterschiedliche Spalten zum Erkennen von Änderungen und Filtern der Daten zu verwenden. Wenn sich die Daten zwischen Buckets verschieben, kann der Datenfluss die Änderungen möglicherweise nicht richtig erkennen und möglicherweise duplizierte Daten in Ihrem Ziel erstellen. Sie können diese Warnung beheben, indem Sie eine andere Spalte verwenden, um Änderungen zu erkennen und die Daten zu filtern. Sie können die Warnung auch ignorieren, wenn Sie sicher sind, dass sich die Daten nicht zwischen Aktualisierungen für die von Ihnen angegebene Spalte ändern.
Ich möchte eine inkrementelle Aktualisierung mit einem Datenziel verwenden, das nicht unterstützt wird. Was kann ich tun?
Wenn Sie die inkrementelle Aktualisierung mit einem nicht unterstützten Datenziel verwenden möchten, können Sie die inkrementelle Aktualisierung für Ihre Abfrage aktivieren und eine zweite Abfrage verwenden, die auf die bereitgestellten Daten verweist, um das Datenziel zu aktualisieren. Auf diese Weise können Sie die inkrementelle Aktualisierung weiterhin verwenden, um die Datenmenge zu reduzieren, die verarbeitet und aus dem Quellsystem abgerufen werden muss. Sie müssen jedoch eine vollständige Aktualisierung der bereitgestellten Daten zum Datenziel durchführen. Stellen Sie sicher, dass Sie die Fenster- und Bucketgröße korrekt einrichten, da wir nicht garantieren, dass die Daten im Staging außerhalb des Bucketbereichs aufbewahrt werden.
Wie kann ich feststellen, ob meine Abfrage die inkrementelle Aktualisierung aktiviert hat?
Sie können sehen, ob ihre Abfrage die inkrementelle Aktualisierung aktiviert hat, indem Sie das Symbol neben der Abfrage im Datenflusseditor überprüfen. Wenn das Symbol ein blaues Dreieck enthält, ist die inkrementelle Aktualisierung aktiviert. Wenn das Symbol kein blaues Dreieck enthält, ist die inkrementelle Aktualisierung nicht aktiviert.
Meine Quelle erhält zu viele Anforderungen, wenn ich die inkrementelle Aktualisierung verwende. Was kann ich tun?
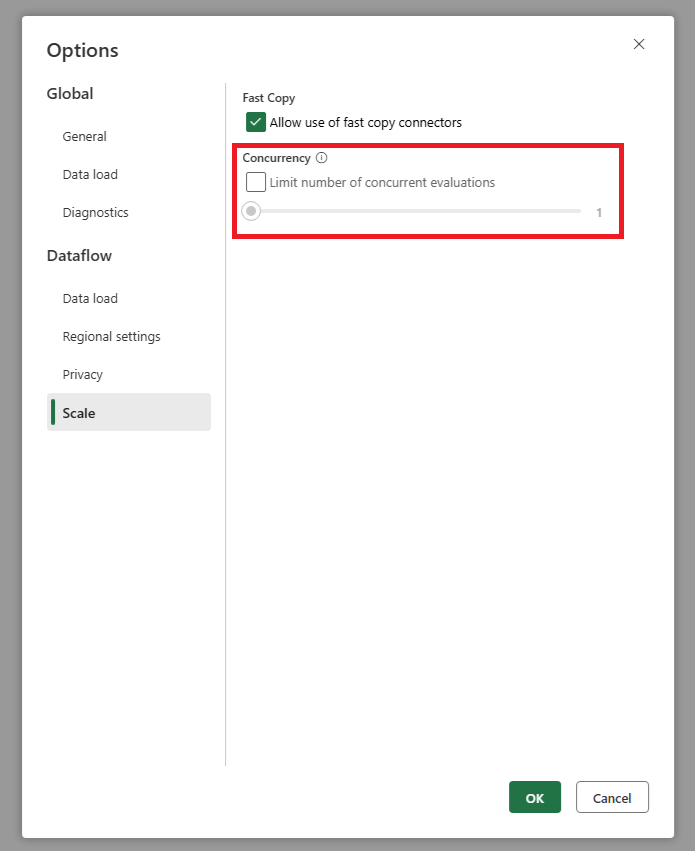
Wir haben eine Einstellung hinzugefügt, mit der Sie die maximale Anzahl paralleler Abfrageauswertungen festlegen können. Diese Einstellung finden Sie in den globalen Einstellungen des Datenflusses. Indem Sie diesen Wert auf eine niedrigere Zahl festlegen, können Sie die Anzahl der an das Quellsystem gesendeten Anforderungen verringern. Diese Einstellung kann dazu beitragen, die Anzahl gleichzeitiger Anforderungen zu verringern und die Leistung des Quellsystems zu verbessern. Um die maximale Anzahl paralleler Abfrageausführungen festzulegen, wechseln Sie zu den globalen Einstellungen des Datenflusses, navigieren Sie zur Registerkarte Skalierung und legen Sie die maximale Anzahl paralleler Abfrageauswertungen fest. Es wird empfohlen, diesen Grenzwert nur zu aktivieren, wenn Probleme mit dem Quellsystem auftreten.
Ich möchte die inkrementelle Aktualisierung verwenden, aber ich stelle fest, dass der Datenfluss nach der Aktivierung länger zur Aktualisierung braucht. Was kann ich tun?
Die inkrementelle Aktualisierung, wie in diesem Artikel beschrieben, dient dazu, die Datenmenge zu reduzieren, die verarbeitet und aus dem Quellsystem abgerufen werden muss. Wenn der Datenfluss nach dem Aktivieren der inkrementellen Aktualisierung jedoch länger dauert, könnte dies daran liegen, dass der zusätzliche Mehraufwand für die Überprüfung, ob Daten geändert wurden, und die Verarbeitung der Buckets höher ist als die Zeitersparnis durch das Verarbeiten geringerer Datenmengen. In diesem Fall wird empfohlen, die Einstellungen für die inkrementelle Aktualisierung zu überprüfen und sie an Ihr Szenario anzupassen. Sie können beispielsweise die Bucketgröße erhöhen, um die Anzahl der Buckets und den Mehraufwand für deren Verarbeitung zu verringern. Oder Sie können die Anzahl der Buckets reduzieren, indem Sie die Bucketgröße erhöhen. Wenn nach dem Anpassen der Einstellungen weiterhin eine geringe Leistung auftritt, können Sie die inkrementelle Aktualisierung deaktivieren und stattdessen eine vollständige Aktualisierung verwenden, da dies in Ihrem Szenario möglicherweise effizienter ist.