Ziele und verwaltete Einstellungen für Dataflow Gen2
Nachdem Sie Ihre Daten mit Dataflow Gen2 bereinigt und vorbereitet haben, möchten Sie Ihre Daten an einem Zielort ablegen. Dazu können Sie die Datenzielfunktionen in Dataflow Gen2 verwenden. Mit dieser Funktion können Sie unter verschiedenen Zielen wählen, wie z. B. Azure SQL, Fabric Lakehouse und viele mehr. Dataflow Gen2 überträgt Ihre Daten dann an das Ziel, und von dort aus können Sie Ihre Daten für weitere Analysen und Berichte verwenden.
Die folgende Liste enthält die unterstützten Datenziele.
- Azure SQL-Datenbanken
- Azure Data Explorer (Kusto)
- Fabric-Lakehouse
- Fabric Warehouse
- Fabric-KQL-Datenbank
- Fabric SQL-Datenbank
Einstiegspunkte
Jede Datenabfrage in Ihrem Dataflow Gen2 kann ein Datenziel haben. Funktionen und Listen werden nicht unterstützt; Sie können sie nur auf tabellarischen Abfragen anwenden. Sie können das Datenziel für jede Abfrage einzeln angeben und mehrere verschiedene Ziele innerhalb des Datenflusses verwenden.
Es gibt drei Standard Einstiegspunkte, um das Datenziel anzugeben:
Über das obere Menüband.
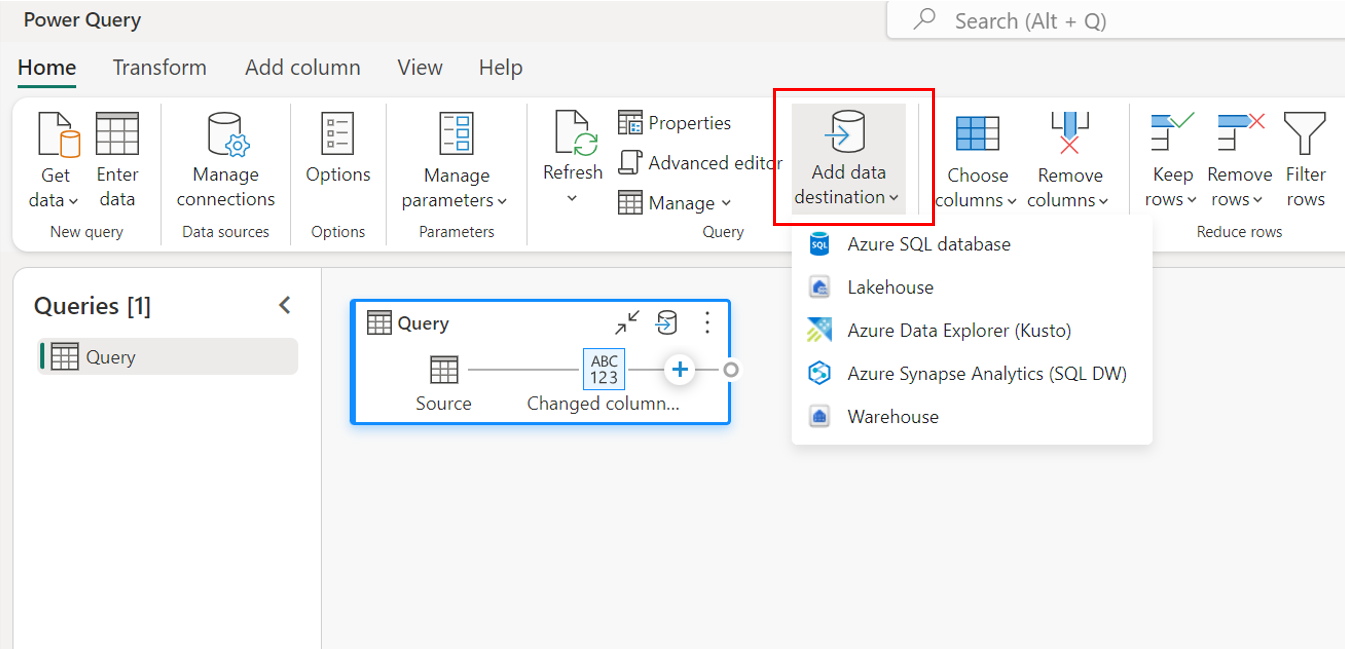
Über Abfrageeinstellungen.
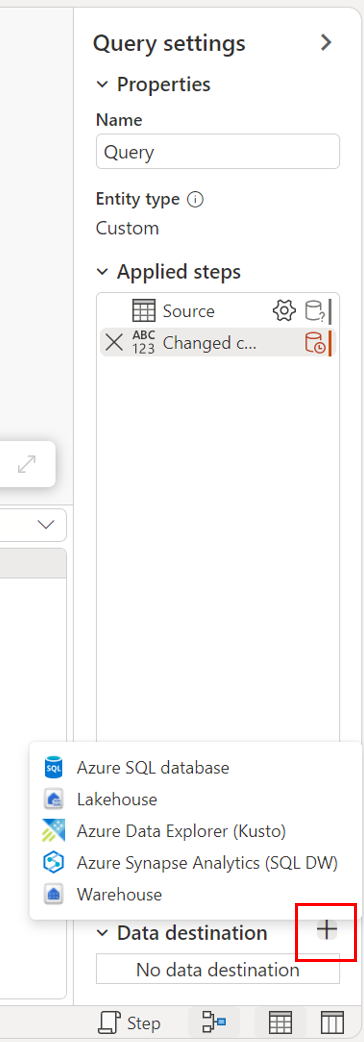
Über die Diagrammansicht.
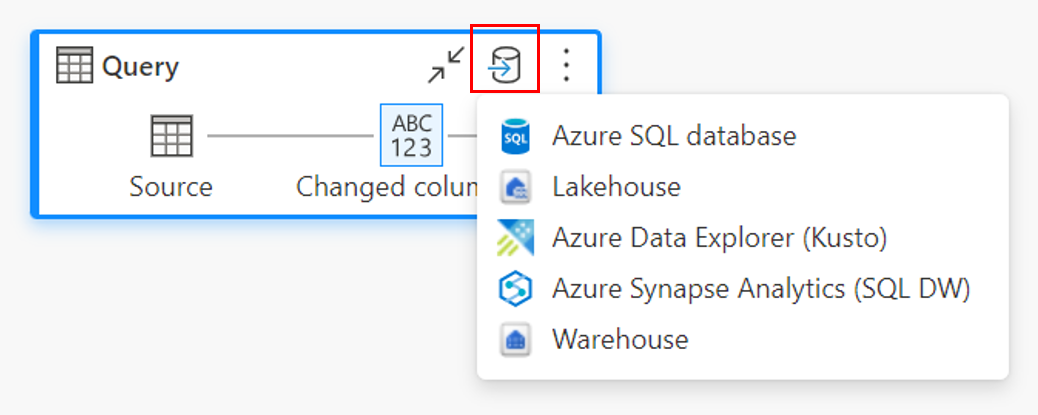
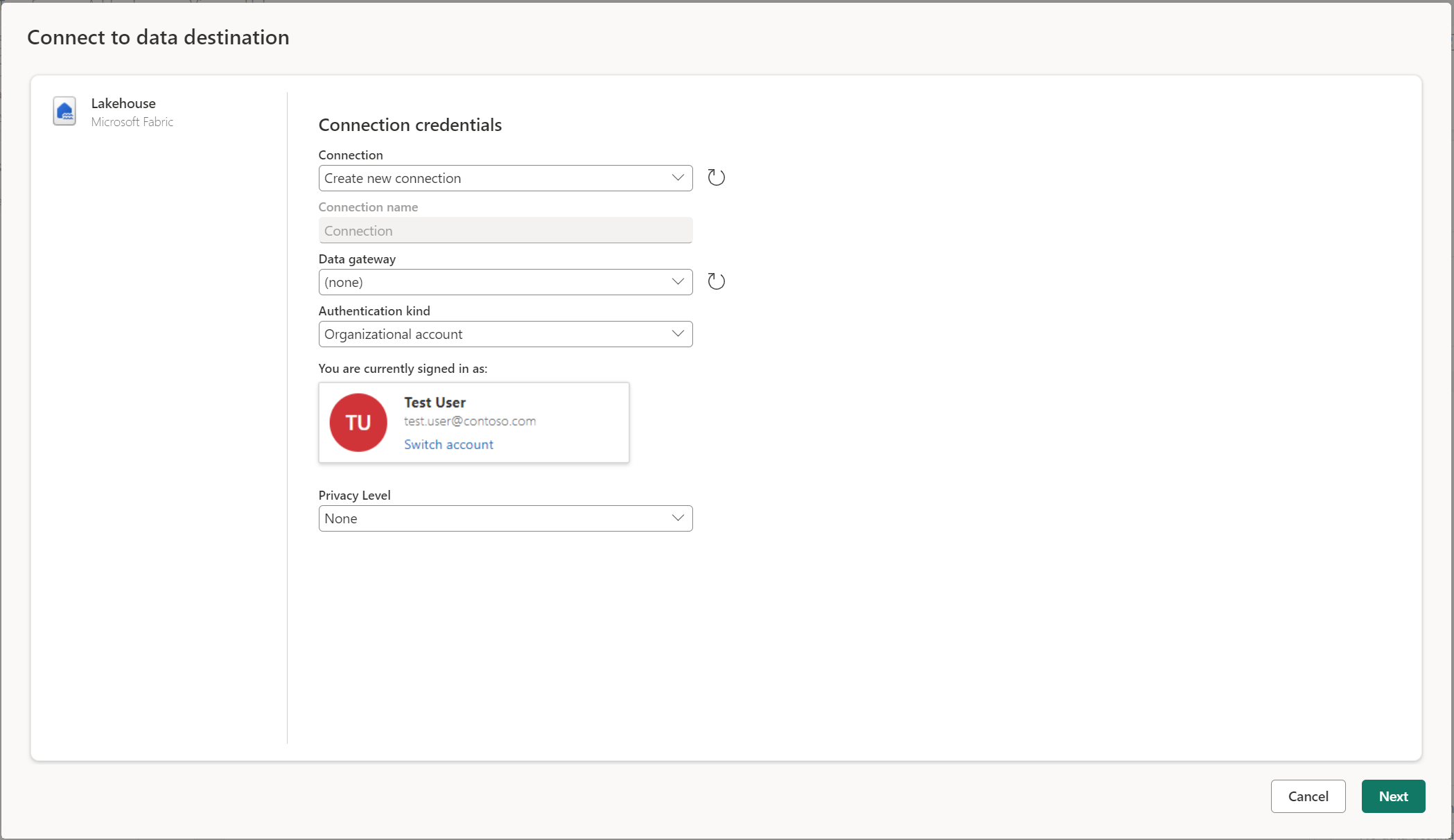
Verbindung mit dem Datenziel
Die Verbindung zum Datenziel ist ähnlich wie die Verbindung zu einer Datenquelle. Verbindungen können sowohl zum Lesen als auch zum Schreiben Ihrer Daten verwendet werden, da Sie über die richtigen Berechtigungen für die Datenquelle verfügen. Sie müssen eine neue Verbindung erstellen oder eine vorhandene Verbindung auswählen und dann "Weiter" auswählen.
Erstellen Sie eine neue Tabelle oder wählen Sie eine vorhandene Tabelle
Beim Laden in Ihr Datenziel können Sie entweder eine neue Tabelle erstellen oder eine vorhandene Tabelle auswählen.
Erstellen einer neuen Tabelle
Wenn Sie sich für die Erstellung einer neuen Tabelle entscheiden, wird während der Dataflow Gen2-Aktualisierung eine neue Tabelle in Ihrem Datenziel erstellt. Wenn die Tabelle in Zukunft gelöscht wird, indem sie manuell in das Ziel verschoben wird, erstellt der Datenfluss die Tabelle während der nächsten Datenfluss-Aktualisierung neu.
Standardmäßig hat der Tabellenname denselben Namen wie der Abfrage-Name. Wenn in Ihrem Tabellennamen ungültige Zeichen vorhanden sind, die das Ziel nicht unterstützt, wird der Tabellenname automatisch angepasst. Viele Ziele unterstützen z. B. keine Leerzeichen oder Sonderzeichen.
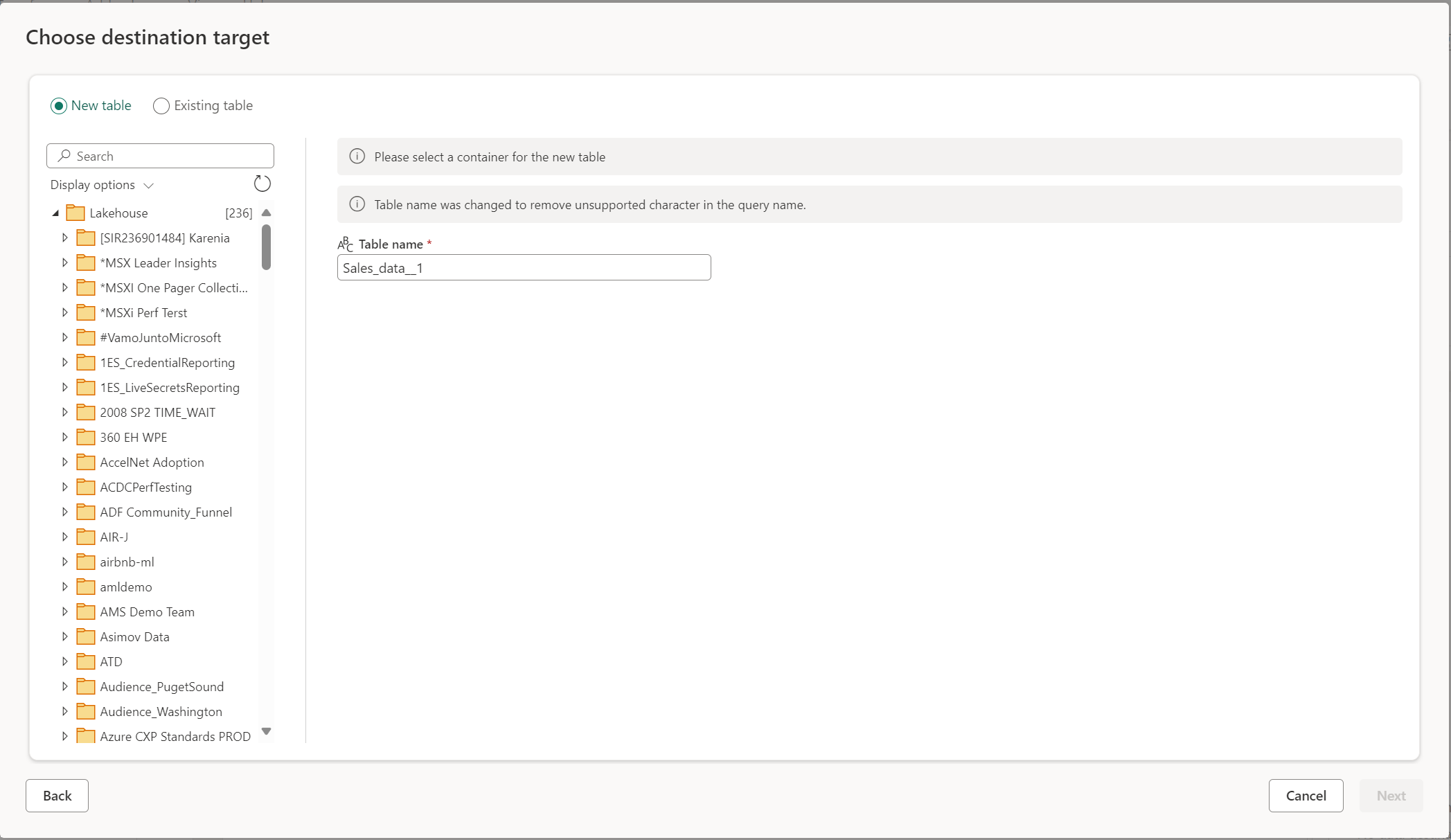
Als Nächstes müssen Sie den Zielordner auswählen. Wenn Sie eines der Fabric-Datenziele gewählt haben, können Sie mit dem Navigator das Fabric-Artefakt auswählen, in das Sie Ihre Daten laden möchten. Bei Azure-Zielen können Sie die Datenbank entweder während der Herstellung der Verbindung angeben oder die Datenbank über den Navigator auswählen.
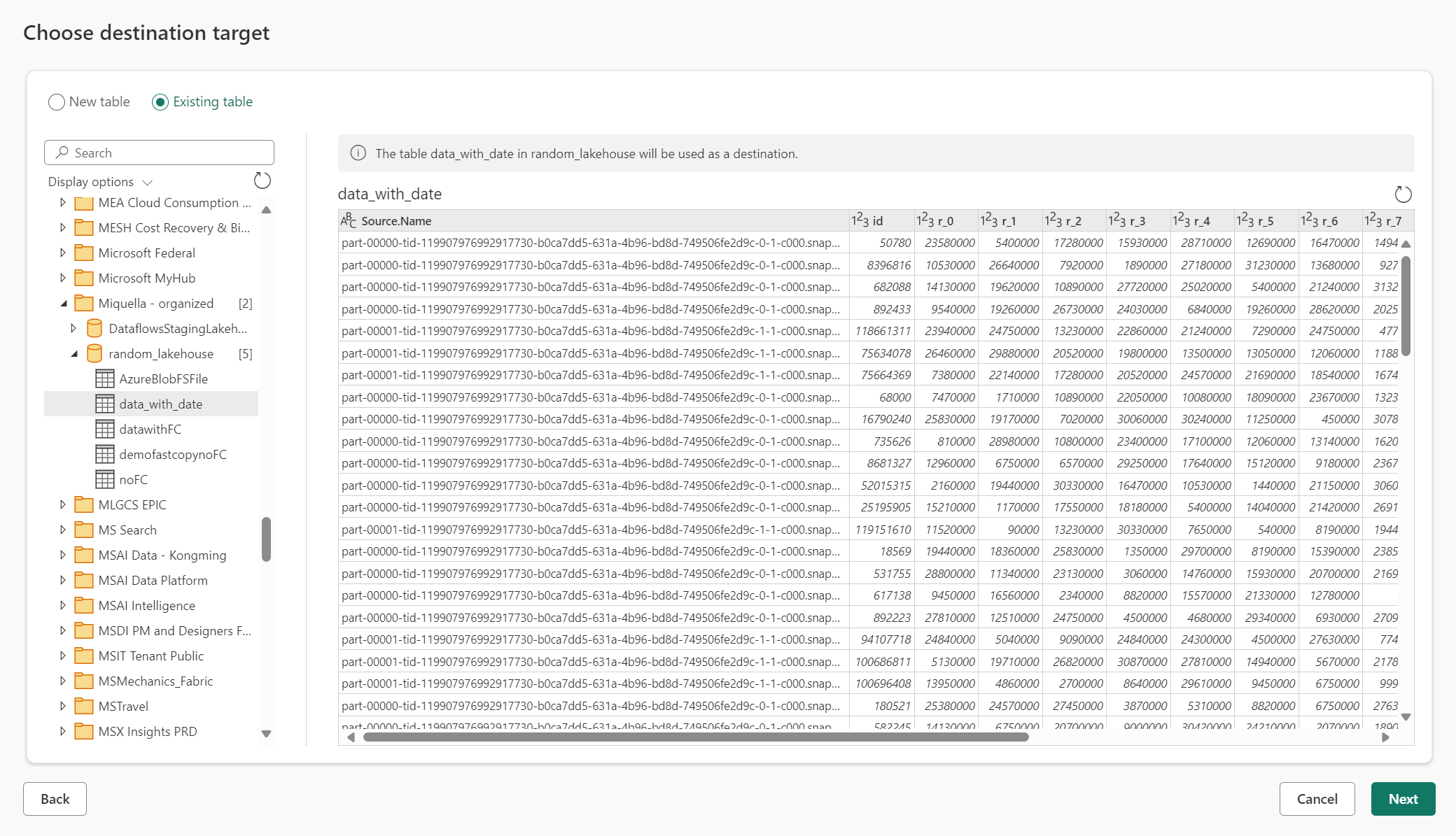
Vorhandene Tabelle verwenden
Um eine vorhandene Tabelle auszuwählen, verwenden Sie die Umschaltfunktion oben im Navigator. Beim Auswählen einer vorhandenen Tabelle müssen Sie sowohl das Fabric-Artefakt/die Fabric-Datenbank als auch die Tabelle mithilfe des Navigators auswählen.
Wenn Sie eine vorhandene Tabelle verwenden, kann die Tabelle in keinem Szenario neu erstellt werden. Wenn Sie die Tabelle manuell aus dem Datenziel löschen, erstellt Dataflow Gen2 die Tabelle bei der nächsten Aktualisierung nicht neu.
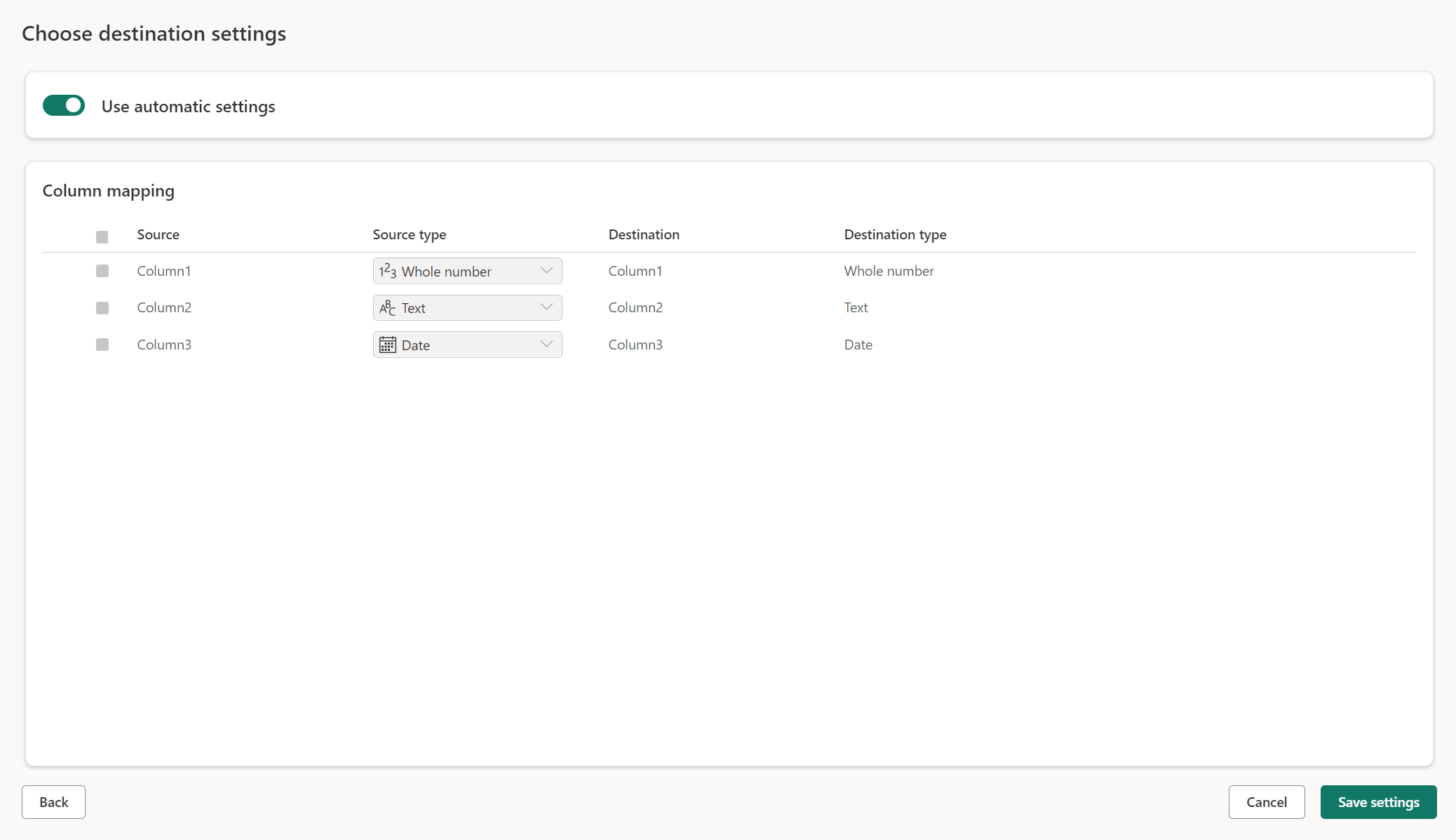
Verwaltete Einstellungen für neue Tabellen
Wenn Sie in eine neue Tabelle laden, sind die automatischen Einstellungen standardmäßig aktiviert. Wenn Sie die automatischen Einstellungen verwenden, verwaltet Dataflow Gen2 die Zuordnung für Sie. Die automatischen Einstellungen bieten das folgende Verhalten:
Update-Methode ersetzen: Daten werden bei jeder Aktualisierung des Datenflusses ersetzt. Alle Daten im Ziel werden entfernt. Die Daten im Ziel werden durch die Ausgabedaten des Datenflusses ersetzt.
Verwaltete Zuordnung: Die Zuordnung wird für Sie verwaltet. Wenn Sie Änderungen an Ihren Daten/Abfragen vornehmen müssen, um eine andere Spalte hinzuzufügen oder einen Datentyp zu ändern, wird die Zuordnung automatisch für diese Änderung angepasst, wenn Sie den Datenfluss erneut veröffentlichen. Sie müssen nicht jedes Mal, wenn Sie Änderungen an Ihrem Datenfluss vornehmen, in die Datenzielumgebung wechseln, so dass Änderungen am Schema bei der erneuten Veröffentlichung des Datenflusses problemlos möglich sind.
Tabelle verwerfen und neu erstellen: Um diese Änderungen des Schemas zu berücksichtigen, wird die Tabelle bei jeder Aktualisierung des Datenflusses verworfen und neu erstellt. Die Aktualisierung des Datenflusses kann dazu führen, dass Beziehungen oder Measures, die zuvor zu Ihrer Tabelle hinzugefügt wurden, entfernt werden.
Hinweis
Derzeit werden automatische Einstellungen nur für Lakehouse- und Azure SQL-Datenbank als Datenziel unterstützt.
Manuelle Einstellungen
Wenn Sie die Option Automatische Einstellungen verwenden deaktivieren, erhalten Sie die volle Kontrolle darüber, wie Ihre Daten in das Datenziel geladen werden. Sie können Änderungen an der Spaltenzuordnung vornehmen, indem Sie den Quelltyp ändern oder jede Spalte ausschließen, die Sie in Ihrem Datenziel nicht benötigen.
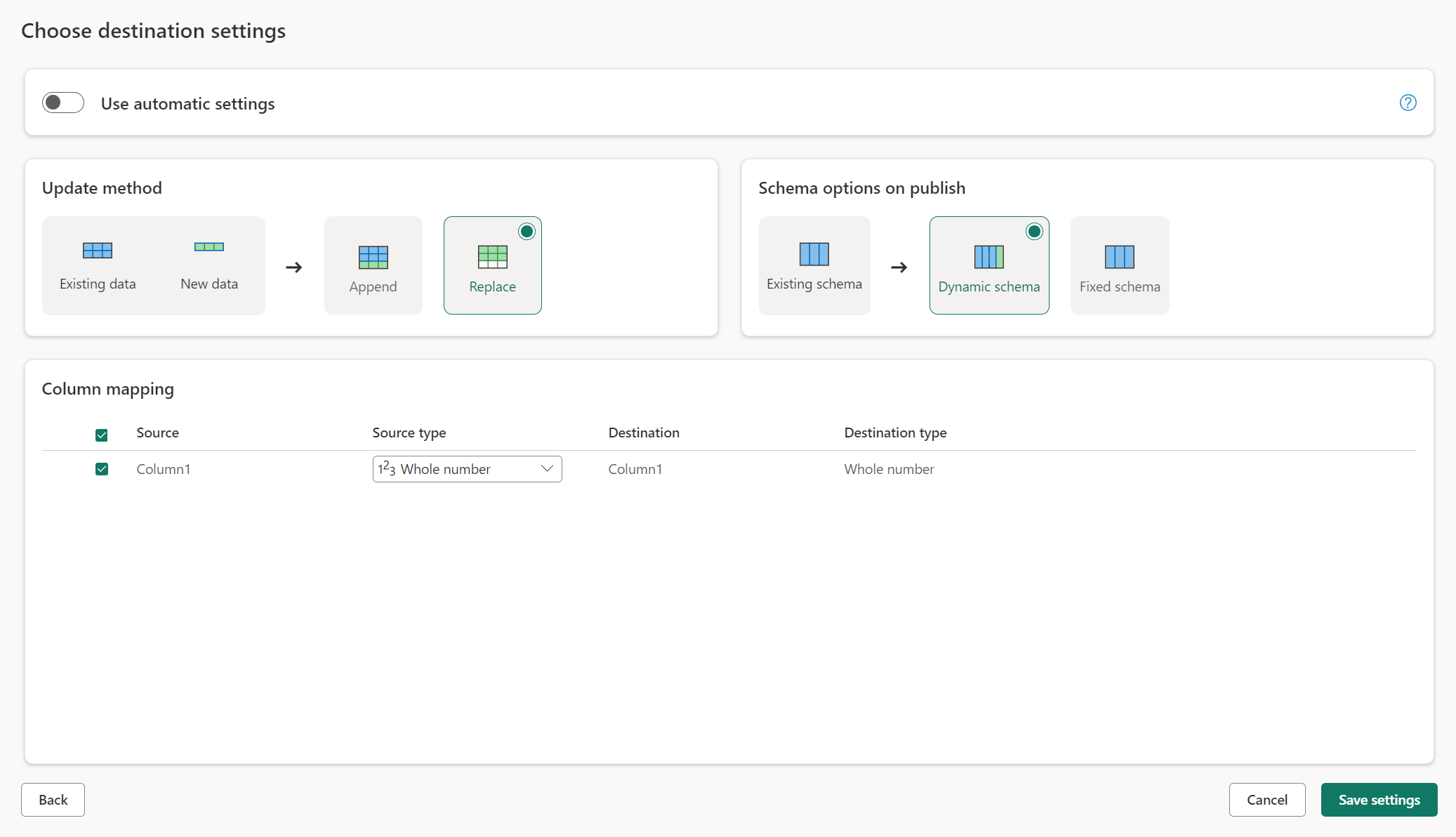
Aktualisierungsmethoden
Die meisten Ziele unterstützen sowohl anfügen als auch ersetzen als Aktualisierungsmethoden. Fabric KQL-Datenbanken und Azure Data Explorer unterstützen jedoch keine Ersetzungen als Aktualisierungsmethode.
Ersetzen: Bei jeder Datenflussaktualisierung werden Ihre Daten am Zielort gelöscht und durch die Ausgabedaten des Datenflusses ersetzt.
Anfügen: Bei jeder Aktualisierung des Datenflusses werden die Ausgabedaten des Datenflusses an die vorhandenen Daten in der Datenzieltabelle angehängt..
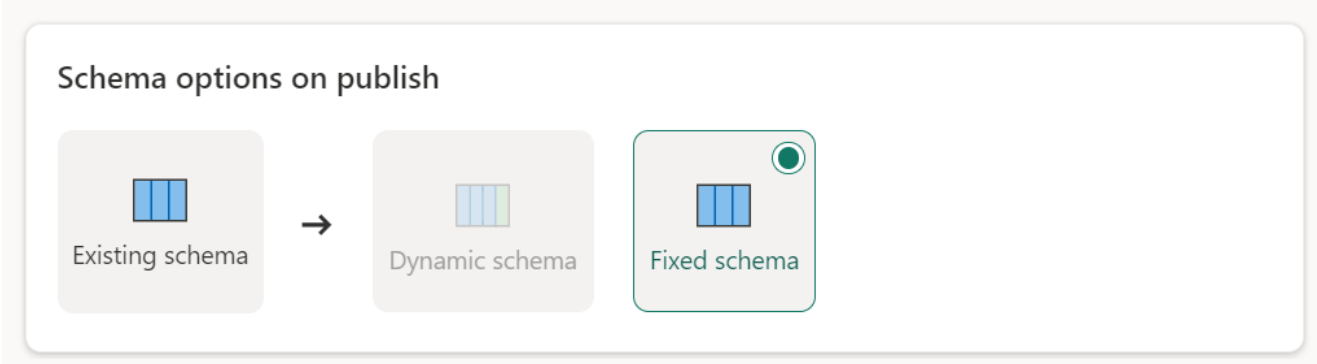
Schema-Optionen beim Veröffentlichen
Schema-Optionen für die Veröffentlichung gelten nur, wenn die Aktualisierungsmethode ersetzt wird. Wenn Sie Daten anfügen, sind Änderungen am Schema nicht möglich.
Dynamisches Schema: Beim Auswählen eines dynamischen Schemas können Sie beim erneuten Veröffentlichen des Datenflusses Änderungen des Schemas am Datenziel zulassen. Da Sie keine verwaltete Zuordnung verwenden, müssen Sie dennoch die Spaltenzuordnung im Ziel-Datenfluss aktualisieren, wenn Sie Änderungen an Ihrer Abfrage vornehmen. Wenn der Datenfluss aktualisiert wird, wird die Tabelle verworfen und neu erstellt. Die Aktualisierung des Datenflusses kann dazu führen, dass Beziehungen oder Measures, die zuvor zu Ihrer Tabelle hinzugefügt wurden, entfernt werden.
Festes Schema: Wenn Sie ein festes Schema auswählen, sind Änderungen des Schemas nicht möglich. Wenn der Datenfluss aktualisiert wird, werden nur die Zeilen in der Tabelle verworfen und durch die Ausgabedaten aus dem Datenfluss ersetzt. Alle Beziehungen oder Kennzahlen in der Tabelle bleiben erhalten. Wenn Sie Änderungen an Ihrer Abfrage im Datenfluss vornehmen, schlägt die Veröffentlichung des Datenflusses fehl, wenn erkannt wird, dass das Abfrageschema nicht mit dem Schema des Datenziels übereinstimmt. Verwenden Sie diese Einstellung, wenn Sie nicht beabsichtigen, das Schema zu ändern und Beziehungen oder Kennzahlen zur Zieltabelle hinzuzufügen.
Hinweis
Beim Laden von Daten in den Speicherort werden nur feste Schemas unterstützt.
Unterstützte Quell- und Zieltypen
| Unterstützte Datentypen pro Speicherort | DataflowStagingLakehouse | Ausgabe von Azure DB (SQL) | Ausgabe von Azure Data Explorer | Ausgabe von Fabric Lakehouse (LH) | Ausgabe von Fabric Warehouse (WH) | Ausgabe der Fabric SQL-Datenbank (SQL) |
|---|---|---|---|---|---|---|
| Aktion | No | Nr. | Nr. | Nr. | Nr. | Nein |
| Any | Nein | Nr. | Nr. | Nr. | Nr. | No |
| Binär | No | Nr. | Nr. | Nr. | Nr. | Nein |
| Währung | Ja | Ja | Ja | Ja | Keine | Ja |
| DatumZeitzone (DateTimeZone) | Ja | Ja | Ja | Nr. | Nein | Ja |
| Duration | No | Nein | Ja | Nr. | Nr. | No |
| Funktion | No | Nr. | Nr. | Nr. | Nr. | Nein |
| Keine | Nein | Nr. | Nr. | Nr. | Nr. | No |
| Null | No | Nr. | Nr. | Nr. | Nr. | Nein |
| Zeit | Ja | Ja | Nr. | Nr. | Nein | Ja |
| Type | No | Nr. | Nr. | Nr. | Nr. | No |
| Strukturiert (Liste, Datensatz, Tabelle) | No | Nr. | Nr. | Nr. | Nr. | No |
Weiterführende Themen
Verwendung von Staging vor dem Laden an einen Zielort
Um die Leistung der Abfrageverarbeitung zu verbessern, kann das Staging in Dataflows Gen2 verwendet werden, um Fabric-Compute zum Ausführen Ihrer Abfragen zu verwenden.
Wenn Staging für Ihre Abfragen aktiviert ist (das Standardverhalten), werden Ihre Daten in den Staging-Speicher geladen, der ein internes Lakehouse ist, auf das nur Datenflüsse selbst Zugriff haben.
Die Verwendung von Staging-Speicherorten kann in einigen Fällen die Leistung verbessern, in denen das Falten der Abfrage an den SQL-Analyseendpunkt schneller ist als bei der Speicherverarbeitung.
Wenn Sie Daten in das Lakehouse oder andere Nicht-Warehouse-Ziele laden, deaktivieren wir standardmäßig das Staging-Feature, um die Leistung zu verbessern. Wenn Sie Daten in das Datenziel laden, werden die Daten direkt in das Datenziel geschrieben, ohne Staging zu verwenden. Wenn Sie Staging für Ihre Abfrage verwenden möchten, können Sie eine erneute Aktivierung vornehmen.
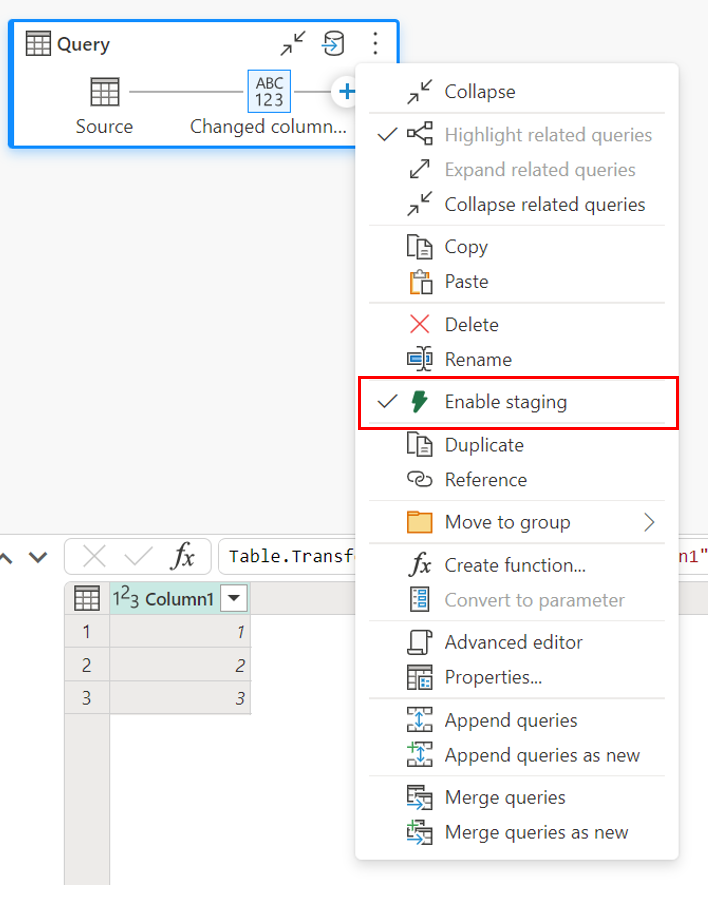
Klicken Sie zum Aktivieren des Stagings mit der rechten Maustaste auf die Abfrage, und aktivieren Sie die Staging-Schaltfläche, indem Sie die Taste Staging aktivieren auswählen. Ihre Abfrage wird dann blau.
Laden Sie Daten in den Speicherort
Wenn Sie Daten in den Speicherort laden, ist Staging erforderlich, bevor der Schreibvorgang im Datenziel erfolgt. Diese Anforderung verbessert die Leistung. Derzeit wird nur das Laden in denselben Arbeitsbereich wie der eigentliche Datenfluss unterstützt. Stellen Sie sicher, dass das Staging für alle Abfragen aktiviert ist, die in den Speicherort geladen werden.
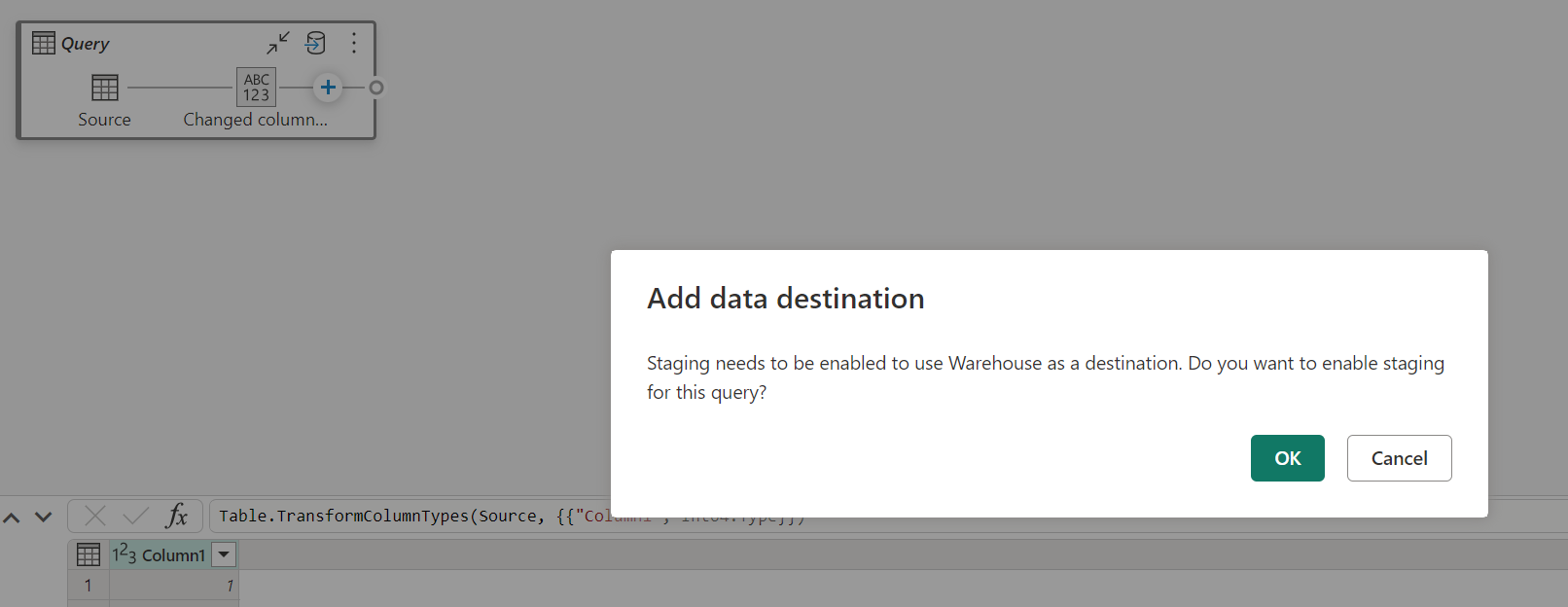
Wenn das Staging deaktiviert ist und Sie "Speicherort" als Ausgabeziel auswählen, erhalten Sie eine Warnung, dass erst das Staging aktiviert werden muss, bevor Sie das Datenziel konfigurieren können.
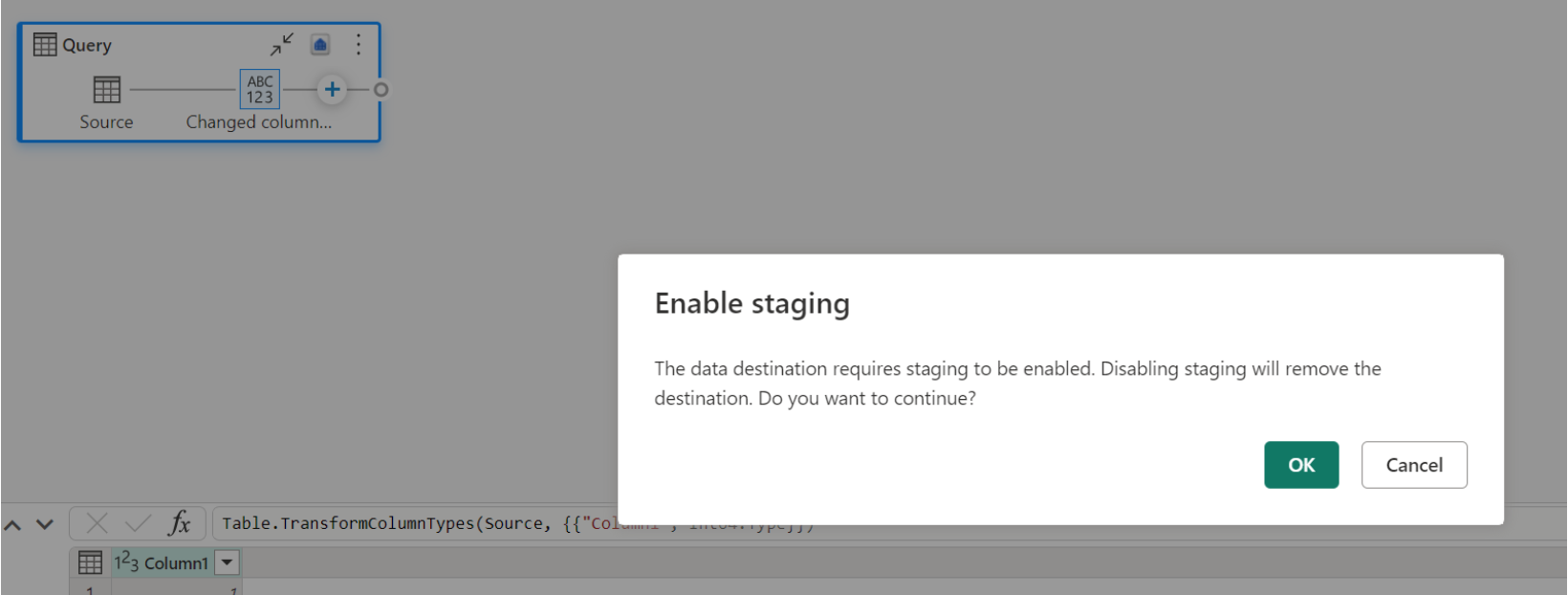
Wenn Sie bereits über einen Speicherort als Ziel verfügen und versuchen, das Staging zu deaktivieren, wird eine Warnung angezeigt. Sie können den Speicherort entweder als Ziel entfernen oder die Stagingaktion schließen.
Bereinigen Ihres Lakehouse-Datenziels
Bei Verwendung von Lakehouse als Ziel für Dataflow Gen2 in Microsoft Fabric ist es entscheidend, regelmäßige Wartungen durchzuführen, um eine optimale Leistung und effiziente Speicherverwaltung sicherzustellen. Eine wesentliche Wartungsaufgabe ist das Bereinigen Ihres Datenziels. Dieser Prozess hilft, alte Dateien zu entfernen, auf die nicht mehr im Delta-Tabellenprotokoll verwiesen wird, wodurch die Speicherkosten optimiert und die Integrität Ihrer Daten beibehalten wird.
Warum Bereinigen wichtig ist
- Speicheroptimierung: Im Laufe der Zeit sammeln Delta-Tabellen alte Dateien, die nicht mehr benötigt werden. Das Bereinigen hilft, diese Dateien zu bereinigen, Speicherplatz freizugeben und Kosten zu senken.
- Leistungsverbesserung: Das Entfernen unnötiger Dateien kann die Abfrageleistung verbessern, indem die Anzahl der Dateien reduziert wird, die während Lesevorgängen gescannt werden müssen.
- Datenintegrität: Die Sicherstellung, dass nur relevante Dateien aufbewahrt werden, trägt dazu bei, die Integrität Ihrer Daten aufrechtzuerhalten, wodurch potenzielle Probleme mit nicht ausgelassenen Dateien verhindert werden, die zu Lesefehlern oder Tabellenbeschädigungen führen können.
So bereinigen Sie Ihr Datenziel
Führen Sie die folgenden Schritte aus, um Ihre Delta-Tabellen in Lakehouse zu bereinigen:
- Navigieren Sie zu Ihrem Lakehouse: Wechseln Sie von Ihrem Microsoft Fabric-Konto zum gewünschten Lakehouse.
- Wartung von Access-Tabellen: Klicken Sie im Lakehouse-Explorer mit der rechten Maustaste auf die Tabelle, die Sie verwalten möchten, oder verwenden Sie die Auslassungspunkte, um auf das Kontextmenü zuzugreifen.
- Wählen Sie Wartungsoptionen aus: Wählen Sie den Menüeintrag Wartung und dann die Option Bereinigen aus.
- Führen Sie den Bereinigungsbefehl aus: Legen Sie den Aufbewahrungsschwellenwert fest (Standard ist sieben Tage) und führen Sie den Bereinigungsbefehl aus, indem Sie Jetzt ausführen auswählen.
Bewährte Methoden
- Aufbewahrungszeitraum: Legen Sie ein Aufbewahrungsintervall von mindestens sieben Tagen fest, um sicherzustellen, dass alte Momentaufnahmen und nicht ausgelassene Dateien nicht vorzeitig entfernt werden, was gleichzeitige Tabellenleser und Autoren stören könnte.
- Regelmäßige Wartung: Planen Sie die regelmäßige Bereinigung als Teil Ihrer Datenwartungsroutine, um Ihre Delta-Tabellen optimiert und für Analysen bereit zu halten.
Durch die Einbeziehung der Bereinigung in Ihre Datenwartungsstrategie können Sie sicherstellen, dass Ihr Lakehouse-Ziel effizient, kostengünstig und zuverlässig für Ihre Datenflussvorgänge bleibt.
Ausführlichere Informationen zur Tabellenwartung in Lakehouse finden Sie in der Dokumentation zur Wartung der Delta-Tabelle.
NULL zulassen
In einigen Fällen, wenn Sie eine Spalte mit Nullen haben, wird sie von Power Query als keine Nullwerte zulassend erkannt, und wenn Sie in das Datenziel schreiben, lässt der Spaltentyp keine Nullwerte zu. Während der Aktualisierung tritt der folgende Fehler auf:
E104100 Couldn't refresh entity because of an issue with the mashup document MashupException.Error: DataFormat.Error: Error in replacing table's content with new data in a version: #{0}., InnerException: We can't insert null data into a non-nullable column., Underlying error: We can't insert null data into a non-nullable column. Details: Reason = DataFormat.Error;Message = We can't insert null data into a non-nullable column.; Message.Format = we can't insert null data into a non-nullable column.
Um Nullwerte zulassende Spalten zu erzwingen, können Sie die folgenden Schritte ausführen:
Löschen Sie die Tabelle aus dem Datenziel.
Entfernen Sie das Datenziel aus dem Datenfluss.
Wechseln Sie zum Datenfluss, und aktualisieren Sie die Datentypen mithilfe des folgenden Power Query-Codes:
Table.TransformColumnTypes( #"PREVIOUS STEP", { {"COLLUMNNAME1", type nullable text}, {"COLLUMNNAME2", type nullable Int64.Type} } )Fügen Sie das Datenziel hinzu.
Datentypkonvertierung und Upscaling
In einigen Fällen unterscheidet sich der Datentyp innerhalb des Dataflows von dem, was unterstützt wird. Im Datenziel unten finden sich einige Standardkonvertierungen, die wir eingerichtet haben, um sicherzustellen, dass Sie Ihre Daten weiterhin im Datenziel abrufen können:
| Destination | Datentyp „Dataflow“ | Zieldatentyp |
|---|---|---|
| Fabric Warehouse | Int8.Type | Int16.Type |