Konfigurieren von Data Warehouse in einer Copy-Aktivität
In diesem Artikel wird beschrieben, wie Sie die Copy-Aktivität in einer Datenpipeline verwenden, um Daten aus einem und in ein Data Warehouse zu kopieren.
Unterstützte Konfiguration
Die Konfiguration der einzelnen Registerkarten unter der Kopieraktivität finden Sie in den folgenden Abschnitten.
Allgemein
Wechseln Sie für die Konfiguration der Registerkarte Allgemein zu Allgemein.
Quelle
Die folgenden Eigenschaften werden für ein Data Warehouse als Quelle in einer Copy-Aktivität unterstützt.
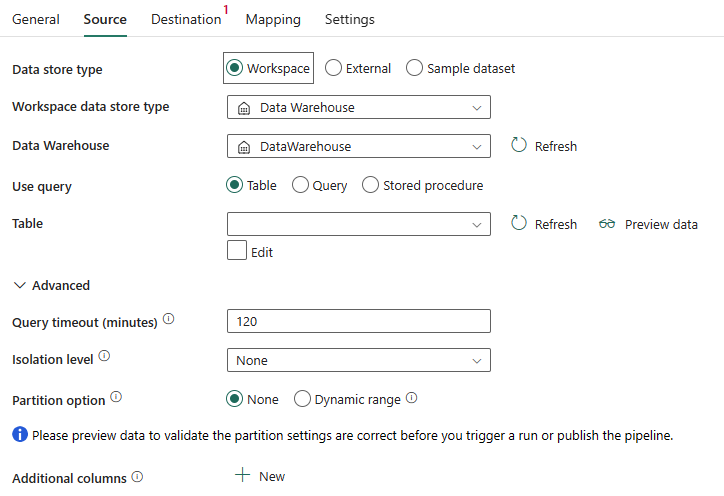
Die folgenden Eigenschaften sind erforderlich:
Datenspeichertyp: Wählen Sie Arbeitsbereich aus.
Datenspeichertyp des Arbeitsbereichs: Wählen Sie in der Liste der Datenspeichertypen Data Warehouse aus.
Data Warehouse: Wählen Sie ein vorhandenes Data Warehouse im Arbeitsbereich aus.
Abfrage verwenden: Wählen Sie Tabelle, Abfrage oder Gespeicherte Prozedur aus.
Wenn Sie Tabelle auswählen, wählen Sie in der Tabellenliste eine vorhandene Tabelle aus, oder geben Sie manuell einen Tabellennamen an, indem Sie das Feld Bearbeiten auswählen.

Wenn Sie Abfrage auswählen, verwenden Sie den Editor für benutzerdefinierte SQL-Abfragen, um eine SQL-Abfrage für das Abrufen der Quelldaten zu schreiben.

Wenn Sie Gespeicherte Prozedur auswählen, wählen Sie in der Dropdownliste eine vorhandene gespeicherte Prozedur aus, oder geben Sie den Namen einer gespeicherten Prozedur als Quelle an, indem Sie das Feld Bearbeiten auswählen.

Unter Erweitert können Sie die folgenden Felder angeben:
Abfragetimeout (Minuten): Timeout für die Ausführung von Abfragebefehlen mit einem Standardwert von 120 Minuten. Wenn diese Eigenschaft festgelegt ist, haben die zulässigen Werte das Format einer Zeitspanne, z. B. „02:00:00“ (120 Minuten).
Isolationsstufe: Geben Sie das Sperrverhalten für Transaktionen für die SQL-Quelle an.
Partitionsoption: Geben Sie die Datenpartitionierungsoptionen für das Laden von Daten aus dem Data Warehouse an. Sie können Keine oder Dynamischer Bereich auswählen.
Wenn Sie Dynamischer Bereich auswählen, ist der Bereichspartitionsparameter (
?AdfDynamicRangePartitionCondition) erforderlich, wenn eine Abfrage mit aktivierter Parallelität verwendet wird. Beispielabfrage:SELECT * FROM <TableName> WHERE ?AdfDynamicRangePartitionCondition.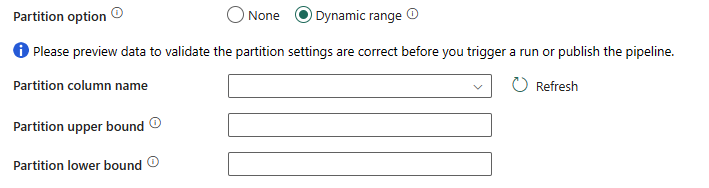
- Partitionsspaltenname: Geben Sie den Namen der Quellspalte als „integer“ oder „date/datetime“ (
int,smallint,bigint,date,smalldatetime,datetime,datetime2oderdatetimeoffset) an, der bei der Bereichspartitionierung für das parallele Kopieren verwendet wird. Ohne Angabe wird der Index oder der Primärschlüssel der Tabelle automatisch erkannt und als Partitionsspalte verwendet. - Partitionsobergrenze: Der maximale Wert der Partitionsspalte für das Teilen des Partitionsbereichs. Dieser Wert wird zur Entscheidung über den Partitionssprung verwendet, nicht zum Filtern der Zeilen in der Tabelle. Alle Zeilen in der Tabelle oder im Abfrageergebnis werden partitioniert und kopiert.
- Partitionsuntergrenze: Der Mindestwert der Partitionsspalte für das Teilen des Partitionsbereichs. Dieser Wert wird zur Entscheidung über den Partitionssprung verwendet, nicht zum Filtern der Zeilen in der Tabelle. Alle Zeilen in der Tabelle oder im Abfrageergebnis werden partitioniert und kopiert.
- Partitionsspaltenname: Geben Sie den Namen der Quellspalte als „integer“ oder „date/datetime“ (
Zusätzliche Spalten: Fügen Sie zusätzliche Datenspalten hinzu, um den relativen Pfad oder statischen Wert der Quelldateien zu speichern. Für Letzteres wird ein Ausdruck unterstützt.


Destination
Die folgenden Eigenschaften werden für ein Data Warehouse als Ziel in einer Copy-Aktivität unterstützt.
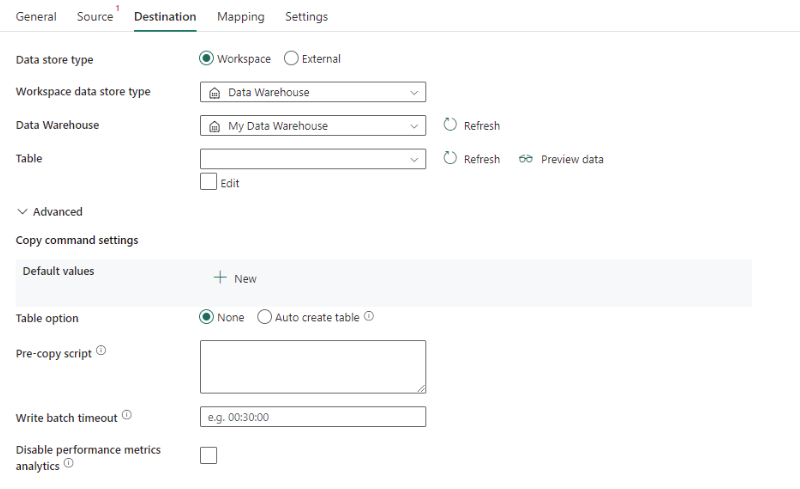
Die folgenden Eigenschaften sind erforderlich:
- Datenspeichertyp: Wählen Sie Arbeitsbereich aus.
- Datenspeichertyp des Arbeitsbereichs: Wählen Sie in der Liste der Datenspeichertypen Data Warehouse aus.
- Data Warehouse: Wählen Sie ein vorhandenes Data Warehouse im Arbeitsbereich aus.
- Tabelle: Wählen Sie in der Tabellenliste eine vorhandene Tabelle aus, oder geben Sie einen Tabellennamen als Ziel an.
Unter Erweitert können Sie die folgenden Felder angeben:
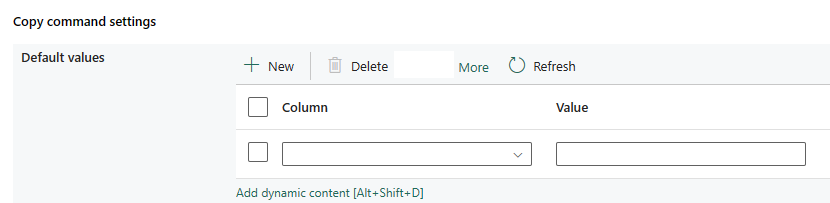
Kopierbefehlseinstellungen: Geben Sie die Eigenschaften des Kopierbefehls an.
Tabellenoptionen: Geben Sie an, ob die Zieltabelle auf Basis des Quellschemas automatisch erstellt werden soll, wenn sie nicht vorhanden ist. Sie können Keine oder Tabelle automatisch erstellen auswählen.
Skript vor Kopiervorgang: Geben Sie eine SQL-Abfrage an, die bei jeder Ausführung vor dem Schreiben von Daten in das Data Warehouse ausgeführt werden soll. Sie können diese Eigenschaft nutzen, um vorab geladene Daten zu bereinigen.
Zeitlimit für Batchschreibvorgang: Die Wartezeit beim Batcheinfügevorgang, bevor ein Timeout auftritt. Die zulässigen Werte haben das Format einer Zeitspanne. Der Standardwert lautet „00:30:00“ (30 Minuten).
Analyse von Leistungsmetriken deaktivieren: Der Dienst sammelt Metriken für die Optimierung der Kopierleistung und für Empfehlungen. Wenn dieses Feature problematisch sein könnte, deaktivieren Sie es.
Direkte Kopie
Die COPY-Anweisung ist die primäre Methode zum Erfassen von Daten in Warehousetabellen. Der COPY-Befehl für Data Warehouses unterstützt Azure Blob Storage und Azure Data Lake Storage Gen2 direkt als Quelldatenspeicher. Wenn Ihre Quelldaten die in diesem Abschnitt beschriebenen Kriterien erfüllen, können Sie mit dem COPY-Befehl direkt aus dem Quelldatenspeicher in ein Data Warehouse kopieren.
Quelldaten und -format enthalten die folgenden Typen und Authentifizierungsmethoden:
Unterstützter Quelldatenspeicher-Typ Unterstütztes Format Unterstützter Quellauthentifizierungstyp Azure Blob Storage Text mit Trennzeichen
ParquetAnonyme Authentifizierung
Kontoschlüsselauthentifizierung
SAS-Authentifizierung (Shared Access Signature)Azure Data Lake Storage Gen2 Text mit Trennzeichen
ParquetKontoschlüsselauthentifizierung
SAS-Authentifizierung (Shared Access Signature)Die folgenden Formateinstellungen können festgelegt werden:
- Für Parquet: Der Komprimierungstyp kann None, snappy oder gzip sein.
- Für DelimitedText:
- Zeilentrennzeichen: Geben Sie beim Kopieren von durch Trennzeichen getrennten Text in ein Data Warehouse über den direkten COPY-Befehl das Zeilentrennzeichen explizit an („\r“ „\n“ oder „\r\n“). Nur wenn das Zeilentrennzeichen der Quelldatei „\r\n“ ist, funktioniert der Standardwert („\r“, „\n“ oder „\r\n“). Aktivieren Sie andernfalls das Staging für Ihr Szenario.
- Sie können den Standardwert NULL-Wert übernehmen oder Leere Zeichenfolge („“) festlegen.
- Für die Codierung können Sie den Standardwert übernehmen oder UTF-8 bzw. UTF-16 festlegen.
- Für die Anzahl übersprungener Zeilen können Sie den Standardwert beibehalten oder 0 (null) festlegen.
- Der Komprimierungstyp kann None oder gzip sein.
Wenn Ihre Quelle ein Ordner ist, müssen Sie das Kontrollkästchen Rekursiv aktivieren.
Startzeit (UTC) und Endzeit (UTC) in Nach letzter Änderung filtern, Präfix, Partitionsermittlung aktivieren und Zusätzliche Spalten werden nicht angegeben.
Informationen zum Erfassen von Daten in Ihrem Data Warehouse mithilfe des COPY-Befehls finden Sie in diesem Artikel.
Wenn der Speicher und das Format der Quelldaten vom COPY-Befehl ursprünglich nicht unterstützt werden, können Sie stattdessen das Feature „Gestaffeltes Kopieren“ mit dem COPY-Befehl verwenden. Es konvertiert die Daten automatisch in ein für den COPY-Befehl kompatibles Format und ruft dann einen COPY-Befehl auf, um Daten in das Data Warehouse zu laden.
gestaffeltem Kopieren
Wenn Ihre Quelldaten nicht nativ mit dem COPY-Befehl kompatibel sind, aktivieren Sie das Kopieren von Daten über einen Stagingspeicher für die Zwischenspeicherung. In diesem Fall konvertiert der Dienst die Daten automatisch, damit das Datenformat den Anforderungen des COPY-Befehls entspricht. Dann wird der COPY-Befehl aufgerufen, um die Daten in Data Warehouse zu laden. Abschließend werden Sie die temporären Daten im Speicher bereinigt.
Gehen Sie zur Registerkarte Einstellungen und wählen Sie Staging aktivieren aus, um gestaffeltes Kopieren zu verwenden. Sie können Arbeitsbereich auswählen, um in Fabric automatisch erstellten Stagingspeicher zu verwenden. Für Extern werden Azure Blob Storage und Azure Data Lake Storage Gen2 als externe Stagingspeicher unterstützt. Sie müssen zuerst eine Verbindung mit Azure Blob Storage oder Azure Data Lake Storage Gen2 herstellen und dann die Verbindung aus der Einblendliste auswählen, um den Stagingspeicher zu verwenden.
Bitte beachten Sie, dass Sie sicherstellen müssen, dass der IP-Bereich des Data Warehouse vom Stagingspeicher korrekt zugelassen wurde.
Zuordnung
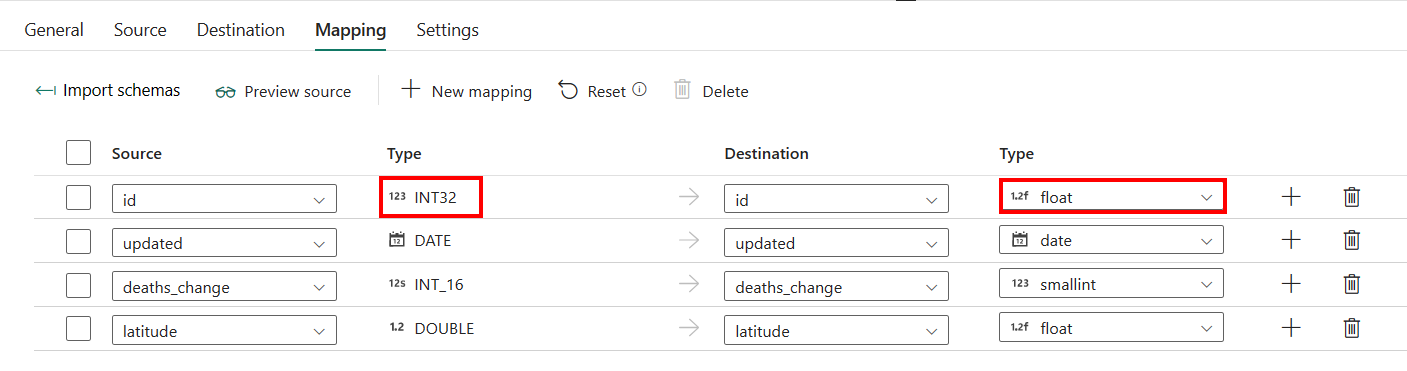
Wenn Sie für die Konfiguration der Registerkarte Zuordnung nicht Data Warehouse mit sich automatisch erstellender Tabelle als Ziel verwenden, wechseln Sie zu Zuordnung.
Wenn Sie nicht Data Warehouse mit sich automatisch erstelelnder Tabelle als Ziel verwenden, können Sie mit Ausnahme der Konfiguration in Zuordnung den Typ für Ihre Zielspalten bearbeiten. Nach dem Auswählen von Importschemas können Sie den Spaltentyp in Ihrem Ziel angeben.
Der Typ für die Spalte ID in der Quelle ist z. B. „int“, und Sie können ihn beim Zuordnen zur Zielspalte in den Typ „Float“ ändern.
Einstellungen
Wechseln Sie für die Konfiguration der Registerkarte Einstellungen zu Einstellungen.
Tabellenzusammenfassung
Die folgenden Tabellen enthalten weitere Informationen zur Copy-Aktivität in Data Warehouse.
Quellinformationen
| Name | Beschreibung | Wert | Erforderlich | JSON-Skripteigenschaft |
|---|---|---|---|---|
| Datenspeichertyp | Ihr Datenspeichertyp | Arbeitsbereich | Ja | / |
| Datenspeichertyp des Arbeitsbereichs | In diesem Abschnitt wählen Sie den Datenspeichertyp des Arbeitsbereichs aus. | Data Warehouse | Ja | Typ |
| Data Warehouse | Das Data Warehouse, das Sie verwenden möchten. | <Ihr Data Warehouse> | Ja | endpoint artifactId |
| Abfrage verwenden | Das Verfahren zum Lesen von Daten aus dem Data Warehouse. | • Tabellen • Abfrage • Gespeicherte Prozedur |
Nein | (unter typeProperties>source)• typeProperties: schema table • sqlReaderQuery • sqlReaderStoredProcedureName |
| Abfragetimeout (Minuten) | Timeout für die Ausführung von Abfragebefehlen mit einem Standardwert von 120 Minuten. Wenn diese Eigenschaft festgelegt ist, haben die zulässigen Werte das Format einer Zeitspanne, z. B. „02:00:00“ (120 Minuten). | Zeitraum | Nein | queryTimeout |
| Isolationsstufe | Das Sperrverhalten für Transaktionen für die Quelle. | • Keine • Snapshot |
Nein | isolationLevel |
| Partitionsoption | Die Datenpartitionierungsoptionen, mit denen Daten aus dem Data Warehouse geladen werden. | • Keine • Dynamischer Bereich |
Nein | partitionOption |
| Partitionsspaltenname | Der Name der Quellspalte als „integer“ oder „date/datetime“ (int, smallint, bigint, date, smalldatetime, datetime, datetime2 oder datetimeoffset), der von der Bereichspartitionierung für das parallele Kopieren verwendet wird. Ohne Angabe wird der Index oder der Primärschlüssel der Tabelle automatisch erkannt und als Partitionsspalte verwendet. |
<Partitionsspaltenname> | Nein | partitionColumnName |
| Partitionsobergrenze | Der maximale Wert der Partitionsspalte für das Teilen des Partitionsbereichs. Dieser Wert wird zur Entscheidung über den Partitionssprung verwendet, nicht zum Filtern der Zeilen in der Tabelle. Alle Zeilen in der Tabelle oder im Abfrageergebnis werden partitioniert und kopiert. | <Partitionsobergrenze> | Nein | partitionUpperBound |
| Partitionsuntergrenze | Der minimale Wert der Partitionsspalte für das Teilen des Partitionsbereichs. Dieser Wert wird zur Entscheidung über den Partitionssprung verwendet, nicht zum Filtern der Zeilen in der Tabelle. Alle Zeilen in der Tabelle oder im Abfrageergebnis werden partitioniert und kopiert. | <Partitionsuntergrenze> | Nein | partitionLowerBound |
| Zusätzliche Spalten | Fügen Sie zusätzliche Datenspalten hinzu, um den relativen Pfad oder statischen Wert der Quelldateien zu speichern. | • Name • Wert |
Nein | additionalColumns: • Name • Wert |
Zielinformationen
| Name | Beschreibung | Wert | Erforderlich | JSON-Skripteigenschaft |
|---|---|---|---|---|
| Datenspeichertyp | Ihr Datenspeichertyp | Arbeitsbereich | Ja | / |
| Datenspeichertyp des Arbeitsbereichs | In diesem Abschnitt wählen Sie den Datenspeichertyp des Arbeitsbereichs aus. | Data Warehouse | Ja | Typ |
| Data Warehouse | Das Data Warehouse, das Sie verwenden möchten. | <Ihr Data Warehouse> | Ja | endpoint artifactId |
| Tabelle | Die Zieltabelle für das Schreiben von Daten. | <Name Ihrer Zieltabelle> | Ja | schema table |
| Kopierbefehlseinstellungen | Die Einstellungen für Eigenschaften des Kopierbefehls. Umfasst die Einstellungen für Standardwerte. | Standardwert: • Spalte • Wert |
Nein | copyCommandSettings: defaultValues: • columnName • defaultValue |
| Tabellenoption | Gibt an, ob die Zieltabelle auf Basis des Quellschemas automatisch erstellt werden soll, wenn sie nicht vorhanden ist. | • Keine • Tabelle automatisch erstellen |
Nein | tableOption: • autoCreate |
| Skript vor Kopiervorgang | Eine SQL-Abfrage, die bei jeder Ausführung vor dem Schreiben von Daten in das Data Warehouse ausgeführt werden soll. Sie können diese Eigenschaft nutzen, um vorab geladene Daten zu bereinigen. | <Skript vor Kopiervorgang> | Nein | preCopyScript |
| Zeitlimit für Batchschreibvorgang | Die Wartezeit beim Batcheinfügevorgang, bevor ein Timeout auftritt. Die zulässigen Werte haben das Format einer Zeitspanne. Der Standardwert lautet „00:30:00“ (30 Minuten). | Zeitraum | Nein | writeBatchTimeout |
| Analyse von Leistungsmetriken deaktivieren | Der Dienst sammelt Metriken für die Leistungsoptimierung von Kopiervorgängen und für Empfehlungen, wodurch zusätzlicher Zugriff auf die Masterdatenbank ermöglicht wird. | Aktivieren oder deaktivieren | Nein | disableMetricsCollection: true oder false |