Konfigurieren von Amazon RDS für SQL Server in Copy-Aktivitäten
In diesem Artikel wird beschrieben, wie Sie die Copy-Aktivität in einer Datenpipeline verwenden, um Daten von Amazon RDS für SQL Server zu kopieren.
Unterstützte Konfiguration
Die Konfiguration der einzelnen Registerkarten unter der Kopieraktivität finden Sie in den folgenden Abschnitten.
Allgemein
Informationen zum Konfigurieren der Registerkarte Allgemein finden Sie unter Allgemeine Einstellungen.
Quelle
Die folgenden Eigenschaften werden für Amazon RDS für SQL Server auf der Registerkarte Quelle einer Copy-Aktivität unterstützt.
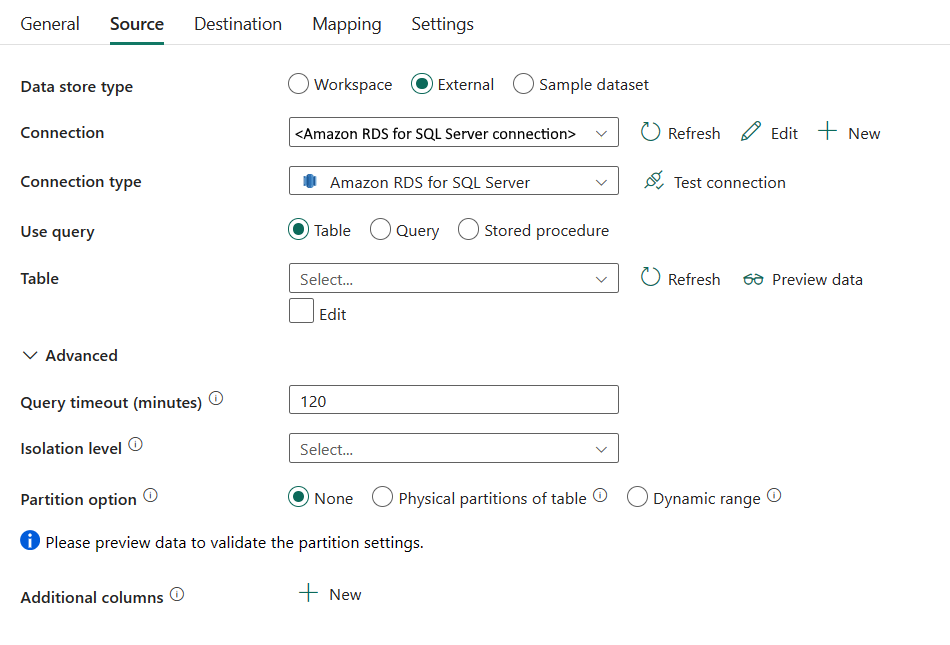
Die folgenden Eigenschaften sind erforderlich:
Datenspeichertyp: Wählen Sie Extern aus.
Verbindung: Wählen Sie in der Verbindungsliste eine Amazon RDS SQL Server-Verbindung aus. Falls die Verbindung nicht vorhanden ist, erstellen Sie eine neue Amazon RDS für SQL Server-Verbindung, indem Sie Neu auswählen.
Verbindungstyp: Wählen Sie Amazon RDS für SQL Server aus.
Abfrage verwenden: Geben Sie die Methode zum Lesen von Daten an. Sie können Tabelle, Abfrage oder Gespeicherte Prozedur auswählen. In der folgenden Liste wird die Konfiguration der einzelnen Einstellungen beschrieben:
Tabelle: Liest Daten aus der angegebenen Tabelle. Wählen Sie in der Dropdownliste Ihre Quelltabelle aus, oder wählen Sie Bearbeiten aus, um sie manuell einzugeben.
Abfrage: Geben Sie die benutzerdefinierte SQL-Abfrage zum Lesen der Daten an. z. B.
select * from MyTable. Oder wählen Sie das Stiftsymbol aus, das im Code-Editor bearbeitet werden soll.
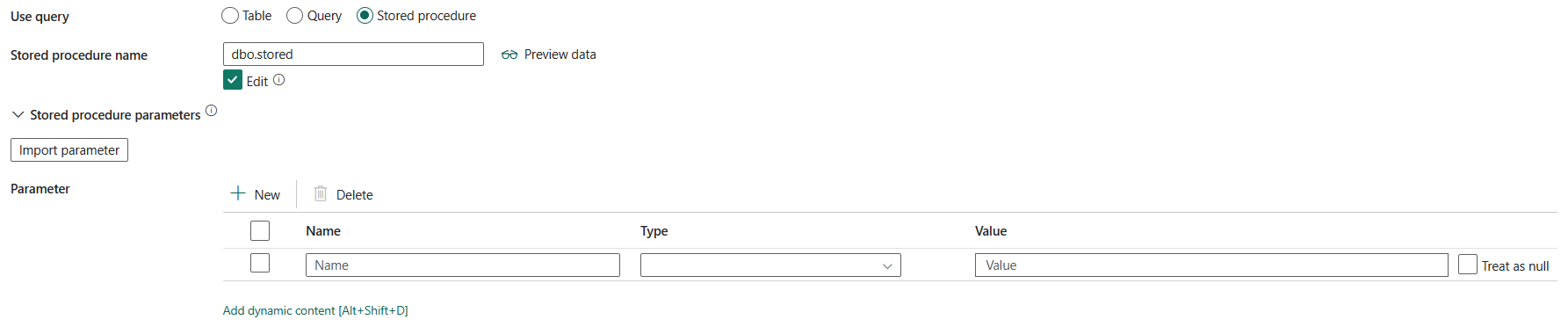
Gespeicherte Prozedur: Verwenden Sie die gespeicherte Prozedur, die Daten aus der Quelltabelle liest. Die letzte SQL-Anweisung muss eine SELECT-Anweisung in der gespeicherten Prozedur sein.
Name der gespeicherten Prozedur: Wählen Sie die gespeicherte Prozedur aus, oder geben Sie den Namen der gespeicherten Prozedur manuell an, wenn Sie Bearbeiten auswählen, um Daten aus der Quelltabelle zu lesen.
Parameter für gespeicherte Prozeduren: Geben Sie Werte für die Parameter der gespeicherten Prozedur an. Zulässige Werte sind Namen oder Name-Wert-Paare. Die Namen und die Groß-/Kleinschreibung von Parametern müssen den Namen und der Groß-/Kleinschreibung der Parameter der gespeicherten Prozedur entsprechen. Sie können Parameter importieren auswählen, um die Parameter Ihrer gespeicherten Prozedur abzurufen.
Unter Erweitert können Sie die folgenden Felder angeben:
Abfragetimeout (Minuten): Geben Sie den Timeout für die Ausführung von Abfragebefehlen an, der Standardwert ist 120 Minuten. Wenn für diese Eigenschaft ein Parameter festgelegt wird, sind Timespan-Werte zulässig, z. B. „02:00:00“ (120 Minuten).
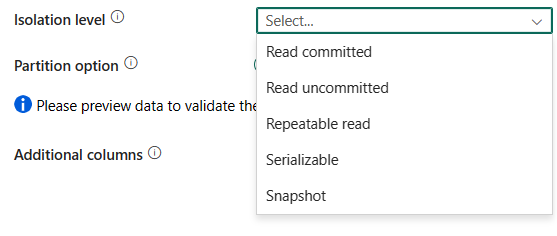
Isolationsstufe: Gibt das Sperrverhalten für Transaktionen für die SQL-Quelle an. Zulässige Werte sind: Read committed, Read uncommitted, Repeatable read, Serializable oder Snapshot. Ohne Angabe wird die Standardisolationsstufe der Datenbank verwendet. Weitere Informationen finden Sie unter IsolationLevel-Enumeration.
Partitionsoption: Geben Sie die Datenpartitionierungsoptionen für das Laden von Daten aus Amazon RDS für SQL Server an. Zulässige Werte sind: Keine (Standard), Physische Partitionen der Tabelle und Dynamischer Bereich. Wenn eine Partitionierungsoption aktiviert ist (d. h. nicht Keine), wird der Parallelitätsgrad für das gleichzeitige Laden von Daten aus Amazon RDS für SQL Server durch die Einstellung Parallelitätsgrad für Kopiervorgänge auf der Registerkarte mit den Einstellungen der Copy-Aktivität gesteuert.
Keine: Wählen Sie diese Einstellung aus, um keine Partition zu verwenden.
Physische Partitionen der Tabelle: Wenn Sie eine physische Partition verwenden, werden die Partitionsspalte und der Mechanismus automatisch auf der Grundlage Ihrer physischen Tabellendefinition bestimmt.
Dynamischer Bereich: Bei Verwendung der Abfrage mit aktivierter Parallelität wird der Parameter für die Bereichspartition (
?DfDynamicRangePartitionCondition) benötigt. Beispielabfrage:SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition.Partitionsspaltenname: Geben Sie den Namen der Quellspalte als „integer“ oder „date/datetime“ (
int,smallint,bigint,date,smalldatetime,datetime,datetime2oderdatetimeoffset) an, der bei der Bereichspartitionierung für das parallele Kopieren verwendet wird. Ohne Angabe wird der Index oder der Primärschlüssel der Tabelle automatisch erkannt und als Partitionsspalte verwendet.Wenn Sie die Quelldaten mithilfe einer Abfrage abrufen, integrieren Sie
?DfDynamicRangePartitionConditionin die WHERE-Klausel. Ein Beispiel finden Sie im Abschnitt Paralleles Kopieren aus SQL-Datenbank.Partitionsobergrenze: ‚Geben Sie den maximalen Wert der Partitionsspalte für das Teilen des Partitionsbereichs an. Dieser Wert wird zur Entscheidung über den Partitionssprung verwendet, nicht zum Filtern der Zeilen in der Tabelle. Alle Zeilen in der Tabelle oder im Abfrageergebnis werden partitioniert und kopiert. Wenn nicht angegeben, wird der Wert für die Kopieraktivität automatisch erkannt. Ein Beispiel finden Sie im Abschnitt Paralleles Kopieren aus SQL-Datenbank.
Partitionsuntergrenze: Geben Sie den Mindestwert der Partitionsspalte für das Teilen des Partitionsbereichs an. Dieser Wert wird zur Entscheidung über den Partitionssprung verwendet, nicht zum Filtern der Zeilen in der Tabelle. Alle Zeilen in der Tabelle oder im Abfrageergebnis werden partitioniert und kopiert. Wenn nicht angegeben, wird der Wert für die Kopieraktivität automatisch erkannt. Ein Beispiel finden Sie im Abschnitt Paralleles Kopieren aus SQL-Datenbank.
Zusätzliche Spalten: Fügen Sie zusätzliche Datenspalten hinzu, um den relativen Pfad oder statischen Wert der Quelldateien zu speichern. Für Letzteres wird ein Ausdruck unterstützt.
Beachten Sie folgende Punkte:
- Wenn als Quelle Abfrage angegeben ist, führt die Copy-Aktivität diese Abfrage für die Amazon RDS für SQL Server-Quelle aus, um die Daten abzurufen. Sie können auch eine gespeicherte Prozedur festlegen, indem Sie Name der gespeicherten Prozedur und Parameter der gespeicherten Prozedur angeben, sofern die gespeicherte Prozedur Parameter akzeptiert.
- Wenn Sie zum Abrufen von Daten eine gespeicherte Prozedur in der Quelle verwenden und die gespeicherte Prozedur beim Übergeben eines anderen Parameterwerts ein anderes Schema zurückgibt, kommt es möglicherweise beim Importieren eines Schemas über die Benutzeroberfläche oder beim Kopieren von Daten in eine SQL-Datenbank zu einem Fehler oder einem unerwarteten Ergebnis.
Zuordnung
Wechseln Sie für die Konfiguration der Registerkarte Zuordnung zu Konfigurieren der Zuordnungen auf der Registerkarte „Zuordnung“.
Einstellungen
Wechseln Sie für die Konfiguration der Registerkarte Einstellungen zu Konfigurieren der anderen Einstellungen auf der Registerkarte „Einstellungen“.
Paralleles Kopieren aus SQL-Datenbank
Der Amazon RDS for SQL Server-Connector in der Copy-Aktivität verfügt über eine integrierte Datenpartitionierung zum parallelen Kopieren von Daten. Die Datenpartitionierungsoptionen befinden sich auf der Registerkarte Quelle der Kopieraktivität.
Wenn Sie partitioniertes Kopieren aktivieren, führt die Copy-Aktivität parallele Abfragen für Ihre Amazon RDS for SQL Server-Quelle aus, um Daten partitionsweise zu laden. Der Parallelitätsgrad wird über die Einstellung Parallelitätsgrad für Kopiervorgänge auf der Registerkarte mit den Einstellungen der Copy-Aktivität gesteuert. Wenn Sie Parallelitätsgrad für Kopiervorgänge z. B. auf 4 festlegen, generiert der Dienst basierend auf der von Ihnen angegebenen Partitionsoption und Ihren Einstellungen gleichzeitig vier Abfragen und führt sie aus. Dabei ruft jede Abfrage einen Teil der Daten von Amazon RDS für SQL Server ab.
Es wird empfohlen, das parallele Kopieren mit Datenpartitionierung vor allem dann zu aktivieren, wenn Sie große Datenmengen aus Amazon RDS for SQL Server laden. Im Anschluss finden Sie empfohlene Konfigurationen für verschiedene Szenarien. Beim Kopieren von Daten in einen dateibasierten Datenspeicher wird empfohlen, mehrere Dateien in einen Ordner zu schreiben (nur den Ordnernamen anzugeben). In diesem Fall ist die Leistung besser als beim Schreiben in eine einzelne Datei.
| Szenario | Empfohlene Einstellungen |
|---|---|
| Vollständiges Laden aus einer großen Tabelle mit physischen Partitionen | Partitionsoption: Physische Partitionen der Tabelle. Während der Ausführung erkennt der Dienst automatisch die physischen Partitionen und kopiert Daten nach Partitionen. Um zu überprüfen, ob Ihre Tabelle eine physische Partition besitzt oder nicht, können Sie auf diese Abfrage verweisen. |
| Vollständiges Laden aus einer großen Tabelle ohne physische Partitionen, aber mit einer integer- oder datetime-Spalte für die Datenpartitionierung. | Partitionsoptionen: Dynamische Bereichspartitionierung Partitionsspalte (optional): Geben Sie die Spalte für die Datenpartitionierung an. Ohne Angabe wird die Primärschlüsselspalte verwendet. Obergrenze der Partition und Untergrenze der Partition (optional): Geben Sie an, ob Sie den Partitionssprung bestimmen möchten. Dies dient nicht zum Filtern der Zeilen in der Tabelle; alle Zeilen in der Tabelle werden partitioniert und kopiert. Wenn keine Angabe erfolgt, erkennt die Copy-Aktivität die Werte automatisch und kann je nach MIN- und MAX-Werten lange dauern. Es wird empfohlen, Ober- und Untergrenzen anzugeben. Wenn Ihre Partitionsspalte "ID" beispielsweise einen Wertebereich von 1 bis 100 hat und Sie die untere Grenze auf 20 und die obere Grenze auf 80 und die Parallelkopie auf 4 setzen, ruft der Dienst Daten nach 4 Partitionen ab - IDs im Bereich <=20, [21, 50], [51, 80] bzw. >=81. |
| Laden einer großen Datenmenge unter Verwendung einer benutzerdefinierten Abfrage ohne physische Partitionen, aber mit einer integer- oder date/datetime-Spalte für die Datenpartitionierung. | Partitionsoptionen: Dynamische Bereichspartitionierung Abfrage: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>Partitionsspalte: Geben Sie die Spalte für die Datenpartitionierung an. Obergrenze der Partition und Untergrenze der Partition (optional): Geben Sie an, ob Sie den Partitionssprung bestimmen möchten. Dies dient nicht zum Filtern der Zeilen in der Tabelle; alle Zeilen im Abfrageergebnis werden partitioniert und kopiert. Wenn nicht angegeben, wird der Wert für die Kopieraktivität automatisch erkannt. Wenn Ihre Partitionsspalte „ID“ beispielsweise einen Wertebereich von 1 bis 100 hat und Sie die untere Grenze auf 20, die obere Grenze auf 80 und die Parallelkopie auf 4 festlegen, ruft der Dienst Daten nach 4 Partitionen ab – IDs im Bereich <=20, [21, 50], [51, 80] bzw. >=81. Hier finden Sie weitere Beispiele für verschiedene Szenarien: • Abfrage der gesamten Tabelle: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition• Abfrage aus einer Tabelle mit Spaltenauswahl und zusätzlichen Where-Klausel-Filtern: SELECT <column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>• Abfragen mit Unterabfragen: SELECT <column_list> FROM (<your_sub_query>) AS T WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>• Abfrage mit Partition in Unterabfrage: SELECT <column_list> FROM (SELECT <your_sub_query_column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition) AS T |
Bewährte Methoden zum Laden von Daten mit Partitionierungsoption:
- Wählen Sie eine aussagekräftige Spalte als Partitionsspalte (wie Primärschlüssel oder eindeutiger Schlüssel), um Datenabweichungen zu vermeiden.
- Wenn die Tabelle eine integrierte Partition aufweist, verwenden Sie die Partitionsoption Physische Partitionen der Tabelle, um eine bessere Leistung zu erzielen.
Beispielabfrage zur Überprüfung der physischen Partition
SELECT DISTINCT s.name AS SchemaName, t.name AS TableName, pf.name AS PartitionFunctionName, c.name AS ColumnName, iif(pf.name is null, 'no', 'yes') AS HasPartition
FROM sys.tables AS t
LEFT JOIN sys.objects AS o ON t.object_id = o.object_id
LEFT JOIN sys.schemas AS s ON o.schema_id = s.schema_id
LEFT JOIN sys.indexes AS i ON t.object_id = i.object_id
LEFT JOIN sys.index_columns AS ic ON ic.partition_ordinal > 0 AND ic.index_id = i.index_id AND ic.object_id = t.object_id
LEFT JOIN sys.columns AS c ON c.object_id = ic.object_id AND c.column_id = ic.column_id
LEFT JOIN sys.partition_schemes ps ON i.data_space_id = ps.data_space_id
LEFT JOIN sys.partition_functions pf ON pf.function_id = ps.function_id
WHERE s.name='[your schema]' AND t.name = '[your table name]'
Wenn die Tabelle eine physische Partition besitzt, würde „HasPartition“ wie folgt als „Yes“ (Ja) angezeigt werden.

Tabellenzusammenfassung
Eine Zusammenfassung und weitere Informationen zur Amazon RDS für SQL Server-Copy-Aktivität finden Sie in der folgenden Tabelle.
Quellinformationen
| Name | Beschreibung | Wert | Erforderlich | JSON-Skripteigenschaft |
|---|---|---|---|---|
| Datenspeichertyp | Ihr Datenspeichertyp | Extern | Ja | / |
| Verbindung | Ihre Verbindung mit dem Quelldatenspeicher | < Ihre Verbindung > | Ja | Verbindung |
| Verbindungstyp | Ihr Verbindungstyp. Wählen Sie Amazon RDS für SQL Server aus. | Amazon RDS für SQL Server | Ja | / |
| Verwendungsabfrage | Die benutzerdefinierte SQL-Abfrage zum Lesen von Daten. | • Tabelle • Abfrage • Gespeicherte Prozedur |
Ja | / |
| Tabelle | Ihre Quelldatentabelle. | < Name Ihrer Zieltabelle > | No | schema table |
| Abfrage | Die benutzerdefinierte SQL-Abfrage zum Lesen von Daten. | <Abfrage> | Nein | sqlReaderQuery |
| Name der gespeicherten Prozedur | Diese Eigenschaft ist der Name der gespeicherten Prozedur, die Daten aus der Quelltabelle liest. Die letzte SQL-Anweisung muss eine SELECT-Anweisung in der gespeicherten Prozedur sein. | <Name der gespeicherten Prozedur> | Nein | sqlReaderStoredProcedureName |
| Parameter der gespeicherten Prozedur | Diese Parameter werden für die gespeicherte Prozedur verwendet. Zulässige Werte sind Namen oder Name-Wert-Paare. Die Namen und die Groß-/Kleinschreibung von Parametern müssen den Namen und der Groß-/Kleinschreibung der Parameter der gespeicherten Prozedur entsprechen. | <Name- oder Wert-Paare> | Nein | storedProcedureParameters |
| Abfragetimeout | Das Timeout für die Ausführung des Abfragebefehls. | Zeitraum (Die Standardeinstellung ist 120 Minuten.) |
Nein | queryTimeout |
| Isolationsstufe | Gibt das Sperrverhalten für Transaktionen für die SQL-Quelle an. | • Lesen zugesichert • Lesen nicht zugesichert • Wiederholbarer Lesevorgang • Serializable • Snapshot |
Nein | isolationLevel: • ReadCommitted • ReadUncommitted • RepeatableRead • Serializable • Snapshot |
| Partitionsoption | Die Datenpartitionierungsoptionen, die zum Laden von Daten aus Amazon RDS for SQL Server verwendet werden. | • Keine (Standard) • Physische Partitionen der Tabelle • Dynamischer Bereich |
Nein | partitionOption: • Keine (Standard) • PhysicalPartitionsOfTable • DynamicRange |
| Partitionsspaltenname | Der Name der Quellspalte mit dem Typ „integer“ oder „date/datetime“ (int, smallint, bigint, date, smalldatetime, datetime, datetime2 oder datetimeoffset), der von der Bereichspartitionierung für das parallele Kopieren verwendet wird. Ohne Angabe wird der Index oder der Primärschlüssel der Tabelle automatisch erkannt und als Partitionsspalte verwendet. Wenn Sie die Quelldaten mithilfe einer Abfrage abrufen, integrieren Sie ?DfDynamicRangePartitionCondition in die WHERE-Klausel. |
<Namen Ihrer Partitionsspalten> | Nein | partitionColumnName |
| Partitionsobergrenze | Der maximale Wert der Partitionsspalte für das Teilen des Partitionsbereichs. Dieser Wert wird zur Entscheidung über den Partitionssprung verwendet, nicht zum Filtern der Zeilen in der Tabelle. Alle Zeilen in der Tabelle oder im Abfrageergebnis werden partitioniert und kopiert. Wenn nicht angegeben, wird der Wert für die Kopieraktivität automatisch erkannt. | <Ihre Partitionsobergrenze> | Nein | partitionUpperBound |
| Partitionsuntergrenze | Der minimale Wert der Partitionsspalte für das Teilen des Partitionsbereichs. Dieser Wert wird zur Entscheidung über den Partitionssprung verwendet, nicht zum Filtern der Zeilen in der Tabelle. Alle Zeilen in der Tabelle oder im Abfrageergebnis werden partitioniert und kopiert. Wenn nicht angegeben, wird der Wert für die Kopieraktivität automatisch erkannt. | <Ihre Partitionsuntergrenze> | Nein | partitionLowerBound |
| Zusätzliche Spalten | Fügen Sie zusätzliche Datenspalten hinzu, um den relativen Pfad oder statischen Wert der Quelldateien zu speichern. Für Letzteres wird ein Ausdruck unterstützt. | • Name • Wert |
Nein | additionalColumns: • Name • Wert |