Umwandeln von Daten mithilfe von dbt
Hinweis
Ein Apache Airflow-Auftrag wird von Apache Airflow unterstützt.
dbt(Data Build Tool) ist eine Open-Source-Befehlszeilenschnittstelle (CLI), die Datentransformation und -modellierung in Data Warehouses vereinfacht, indem komplexer SQL-Code auf strukturierte und verwendbare Weise verwaltet wird. Es ermöglicht Datenteams, zuverlässige, testbare Transformationen im Kern ihrer analytischen Pipelines zu erstellen.
In Kombination mit Apache Airflow werden die Transformationsfunktionen von Dbt durch die Funktionen für Planung, Orchestrierung und Aufgabenverwaltung von Airflow verbessert. Dieser kombinierte Ansatz, der die Transformationskompetenz von dbt zusammen mit der Workflowverwaltung von Airflow nutzt, liefert effiziente und robuste Datenpipelinen, was letztendlich zu schnelleren und aussagekräftigeren datengesteuerten Entscheidungen führt.
In diesem Tutorial wird veranschaulicht, wie Sie einen Apache Airflow DAG erstellen, der dbt zum Transformieren von Daten verwendet, die im Microsoft Fabric Data Warehouse gespeichert sind.
Voraussetzungen
Um zu beginnen, müssen die folgenden Voraussetzungen erfüllt sein:
Aktivieren Sie den Apache Airflow-Auftrag in Ihrem Mandanten.
Hinweis
Da sich der Apache Airflow-Auftrag in der Vorschau befindet, müssen Sie ihn über Ihren Mandantenadministrator aktivieren. Wenn der Apache Airflow-Auftrag bereits angezeigt wird, hat Ihr Mandantenadministrator ihn möglicherweise bereits aktiviert.
Gehen Sie zum Verwaltungsportal –> Mandanteneinstellungen –> Erweitern Sie unter Microsoft Fabric –> den Abschnitt „Benutzer können Apache Airflow-Aufträge erstellen und verwenden (Vorschau)“.
Wählen Sie Übernehmen.

Erstellen Sie den Dienstprinzipal. Fügen Sie den Dienstprinzipal als
Contributorin den Arbeitsbereich ein, in dem Sie das Data Warehouse erstellen.Erstellen Sie ein Fabric-Warehouse, sofern Sie noch keins haben. Laden Sie die Beispieldaten mithilfe der Datenpipeline in das Warehouse ein. Für dieses Lernprogramm verwenden wir das NYC Taxi-Green-Beispiel.

Transformation der in Fabric Warehouse gespeicherten Daten mit dbt
In diesem Abschnitt werden die folgenden Schritte behandelt:
- Geben Sie die Anforderungen an.
- Erstellen Sie ein dbt-Projekt im vom Apache Airflow-Auftragbereitgestellten fabric-verwalteten Speicher.
- Erstellen eines Apache Airflow DAG zum Koordinieren von dbt-Jobs
Angeben der Anforderungen
Erstellen Sie eine Datei requirements.txt im Ordner dags. Fügen Sie die folgenden Pakete als Apache Airflow-Anforderungen hinzu.
astronomer-cosmos: Dieses Paket wird verwendet, um Ihre dbt-Kernprojekte als Apache-Airflow-Dags und Aufgabengruppen auszuführen.
dbt-fabric: Dieses Paket wird verwendet, um dbt-Projekt zu erstellen, das dann in einem Fabric Data Warehouse bereitgestellt werden kann.
astronomer-cosmos==1.0.3 dbt-fabric==1.5.0
Erstellen Sie ein dbt-Projekt im vom Apache Airflow-Auftrag bereitgestellten fabric-verwalteten Speicher.
In diesem Abschnitt erstellen wir ein Dbt-Beispielprojekt im Apache Airflow Job für das Dataset
nyc_taxi_greenmit der folgenden Verzeichnisstruktur.dags |-- my_cosmos_dag.py |-- nyc_taxi_green | |-- profiles.yml | |-- dbt_project.yml | |-- models | | |-- nyc_trip_count.sql | |-- targetErstellen Sie im Ordner
dagsden Ordnernyc_taxi_greenmit der Dateiprofiles.yml. Dieser Ordner enthält alle für das dbt-Projekt erforderlichen Dateien.
Kopieren Sie den folgenden Inhalt in den
profiles.yml. Diese Konfigurationsdatei enthält Datenbankverbindungsdetails und Profile, die von dbt verwendet werden. Aktualisieren Sie die Platzhalterwerte und speichern Sie die Datei.config: partial_parse: true nyc_taxi_green: target: fabric-dev outputs: fabric-dev: type: fabric driver: "ODBC Driver 18 for SQL Server" server: <sql connection string of your data warehouse> port: 1433 database: "<name of the database>" schema: dbo threads: 4 authentication: ServicePrincipal tenant_id: <Tenant ID of your service principal> client_id: <Client ID of your service principal> client_secret: <Client Secret of your service principal>Erstellen Sie die Datei
dbt_project.ymlund kopieren Sie den folgenden Inhalt. Diese Datei gibt die Konfiguration auf Projektebene an.name: "nyc_taxi_green" config-version: 2 version: "0.1" profile: "nyc_taxi_green" model-paths: ["models"] seed-paths: ["seeds"] test-paths: ["tests"] analysis-paths: ["analysis"] macro-paths: ["macros"] target-path: "target" clean-targets: - "target" - "dbt_modules" - "logs" require-dbt-version: [">=1.0.0", "<2.0.0"] models: nyc_taxi_green: materialized: tableErstellen Sie im Ordner
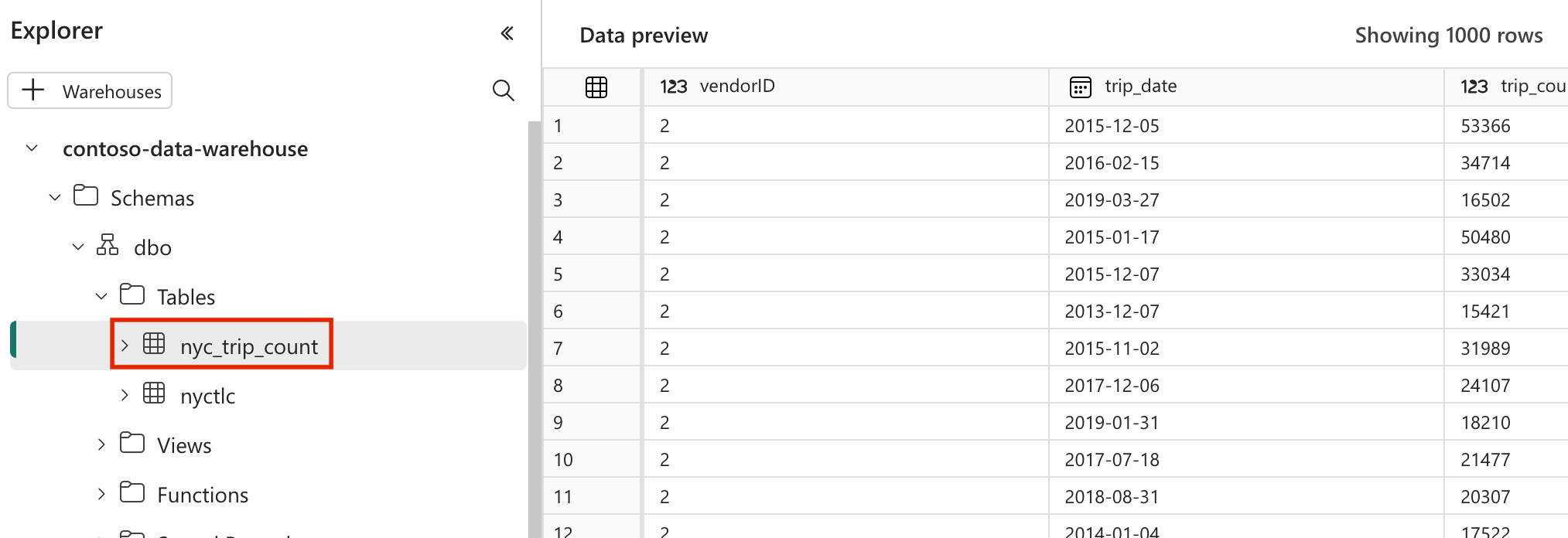
nyc_taxi_greenden Ordnermodels. Für dieses Lernprogramm erstellen wir das Beispielmodell in der Dateinyc_trip_count.sql, die die Tabelle mit der Anzahl der Fahrten pro Tag und Lieferant erstellt. Kopieren Sie den folgenden Inhalt in die Datei.with new_york_taxis as ( select * from nyctlc ), final as ( SELECT vendorID, CAST(lpepPickupDatetime AS DATE) AS trip_date, COUNT(*) AS trip_count FROM [contoso-data-warehouse].[dbo].[nyctlc] GROUP BY vendorID, CAST(lpepPickupDatetime AS DATE) ORDER BY vendorID, trip_date; ) select * from final


Erstellen eines Apache Airflow DAG zum Koordinieren von dbt-Jobs
Erstellen Sie die im Ordner benannte
my_cosmos_dag.pydagsDatei, und fügen Sie den folgenden Inhalt darin ein.import os from pathlib import Path from datetime import datetime from cosmos import DbtDag, ProjectConfig, ProfileConfig, ExecutionConfig DEFAULT_DBT_ROOT_PATH = Path(__file__).parent.parent / "dags" / "nyc_taxi_green" DBT_ROOT_PATH = Path(os.getenv("DBT_ROOT_PATH", DEFAULT_DBT_ROOT_PATH)) profile_config = ProfileConfig( profile_name="nyc_taxi_green", target_name="fabric-dev", profiles_yml_filepath=DBT_ROOT_PATH / "profiles.yml", ) dbt_fabric_dag = DbtDag( project_config=ProjectConfig(DBT_ROOT_PATH,), operator_args={"install_deps": True}, profile_config=profile_config, schedule_interval="@daily", start_date=datetime(2023, 9, 10), catchup=False, dag_id="dbt_fabric_dag", )
Ausführen Ihres gerichteten azyklischen Graphs (DAG)
Führen Sie die DAG im Apache Airflow-Auftrag aus.

Klicken Sie auf
Monitor in Apache Airflow.
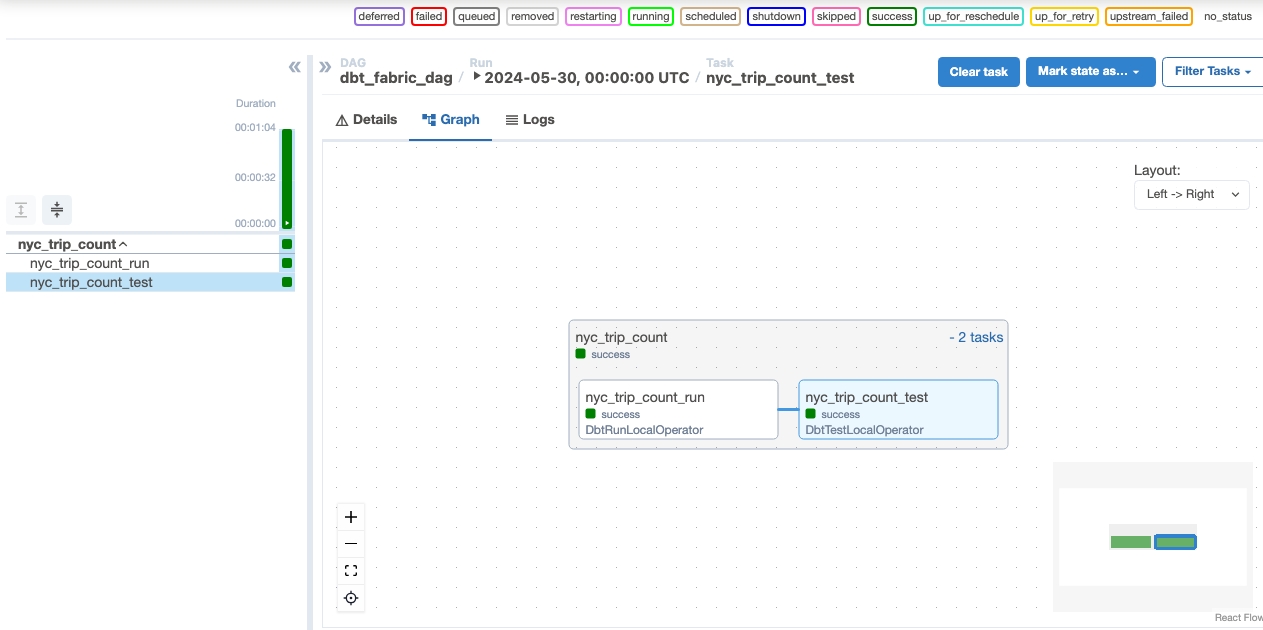 , um Ihren geladenen Tag in der Apache Airflow-Benutzeroberfläche zu sehen
, um Ihren geladenen Tag in der Apache Airflow-Benutzeroberfläche zu sehen



Validieren Sie Ihre Daten
- Nach einer erfolgreichen Ausführung zur Validierung Ihrer Daten können Sie die neue Tabelle mit dem Namen „nyc_trip_count.sql“ sehen, die in Ihrem Fabric Data Warehouse erstellt wurde.