Notebookvisualisierung in Microsoft Fabric
Microsoft Fabric ist ein integrierter Analysedienst zur schnelleren Gewinnung von Erkenntnissen aus Data Warehouses und Big Data-Analysesystemen. Die Datenvisualisierung in Notebooks ist eine Schlüsselkomponente, um Erkenntnisse über Ihre Daten gewinnen zu können. Es erleichtert den Menschen, große und kleine Daten zu verstehen. Sie erleichtert auch die Erkennung von Mustern, Trends und Ausreißern in Datengruppen.
Wenn Sie Apache Spark in Fabric verwenden, stehen verschiedene integrierte Optionen zur Verfügung, mit denen Sie Ihre Daten visualisieren können, einschließlich Fabric-Notebookdiagrammoptionen und Zugriff auf beliebte Open-Source-Bibliotheken.
Wenn Sie ein Fabric-Notebook verwenden, können Sie Ihre tabellarische Ergebnisansicht mithilfe von Diagrammoptionen in ein angepasstes Diagramm umwandeln. Hier können Sie Ihre Daten visualisieren, ohne Code schreiben zu müssen.
Integrierter Visualisierungsbefehl: display()-Funktion
Mit der integrierten Fabric-Visualisierungsfunktion können Sie Apache Spark DataFrames, Pandas DataFrames und SQL-Abfrageergebnisse in umfangreiche Formatdatenvisualisierungen umwandeln.
Sie können die Funktion display in Datenrahmen verwenden, die in PySpark und Scala für Spark DataFrames oder RDD-Funktionen (Resilient Distributed Datasets) erstellt wurden, um die umfassende DataFrame-Tabellenansicht und -Diagrammansicht zu erzeugen.
Sie können die Zeilenanzahl des gerenderten Datenrahmens angeben. Der Standardwert ist 1000. Das Notebook-Ausgabe-Widget display unterstützt die Anzeige und Profilerstellung von maximal 10.000 Zeilen eines Datenrahmens.

Sie können die Filterfunktion auf der globalen Symbolleiste verwenden, um die Daten zu filtern, die mit Ihrer angepassten Regel effizient zugeordnet werden, die Bedingung wird auf die angegebene Spalte angewendet, und das Filterergebnis wird sowohl in der Tabellenansicht als auch in der Diagrammansicht widergespiegelt.

Die Ausgabe der SQL-Anweisung übernimmt standardmäßig das gleiche Ausgabe-Widget mit display().
Umfangreiche Dataframe-Tabellenansicht
Unterstützung für freie Auswahl in der Tabellenansicht
Die Tabellenansicht wird bei Verwendung des Befehls display() standardmäßig gerendert. Die umfangreiche Datenrahmenvorschau im Notebook bietet eine kostenlose Auswahlfunktion, die die Datenanalyse durch flexible und intuitive Auswahloptionen verbessert. Mit dieser Funktion können Benutzer effizienter mit Datenframes interagieren und tiefere Einblicke gewinnen.
Spaltenauswahl
- Einzelne Spalte: Klicken Sie auf die Spaltenüberschrift, um die gesamte Spalte auszuwählen.
- Mehrere Spalten: Nachdem Sie eine einzelne Spalte ausgewählt haben, halten Sie die UMSCHALTTASTE gedrückt und klicken dann auf eine weitere Spaltenüberschrift, um mehrere Spalten auszuwählen.
Zeilenauswahl
- Einzelzeile: Klicken Sie auf eine Zeilenüberschrift, um die gesamte Zeile auszuwählen.
- Mehrere Zeilen: Nachdem Sie eine einzelne Zeile ausgewählt haben, halten Sie die 'Shift'-Taste gedrückt, und klicken Sie dann auf einen weiteren Zeilenkopf, um mehrere Zeilen auszuwählen.
Zelleninhaltsvorschau: Zeigen Sie den Inhalt einzelner Zellen in der Vorschau an, um einen schnellen und detaillierten Blick auf die Daten zu erhalten, ohne zusätzlichen Code schreiben zu müssen.
Spaltenzusammenfassung: Holen Sie sich eine Zusammenfassung der einzelnen Spalten, einschließlich Datenverteilung und Schlüsselstatistiken, um die Merkmale der Daten schnell zu verstehen.
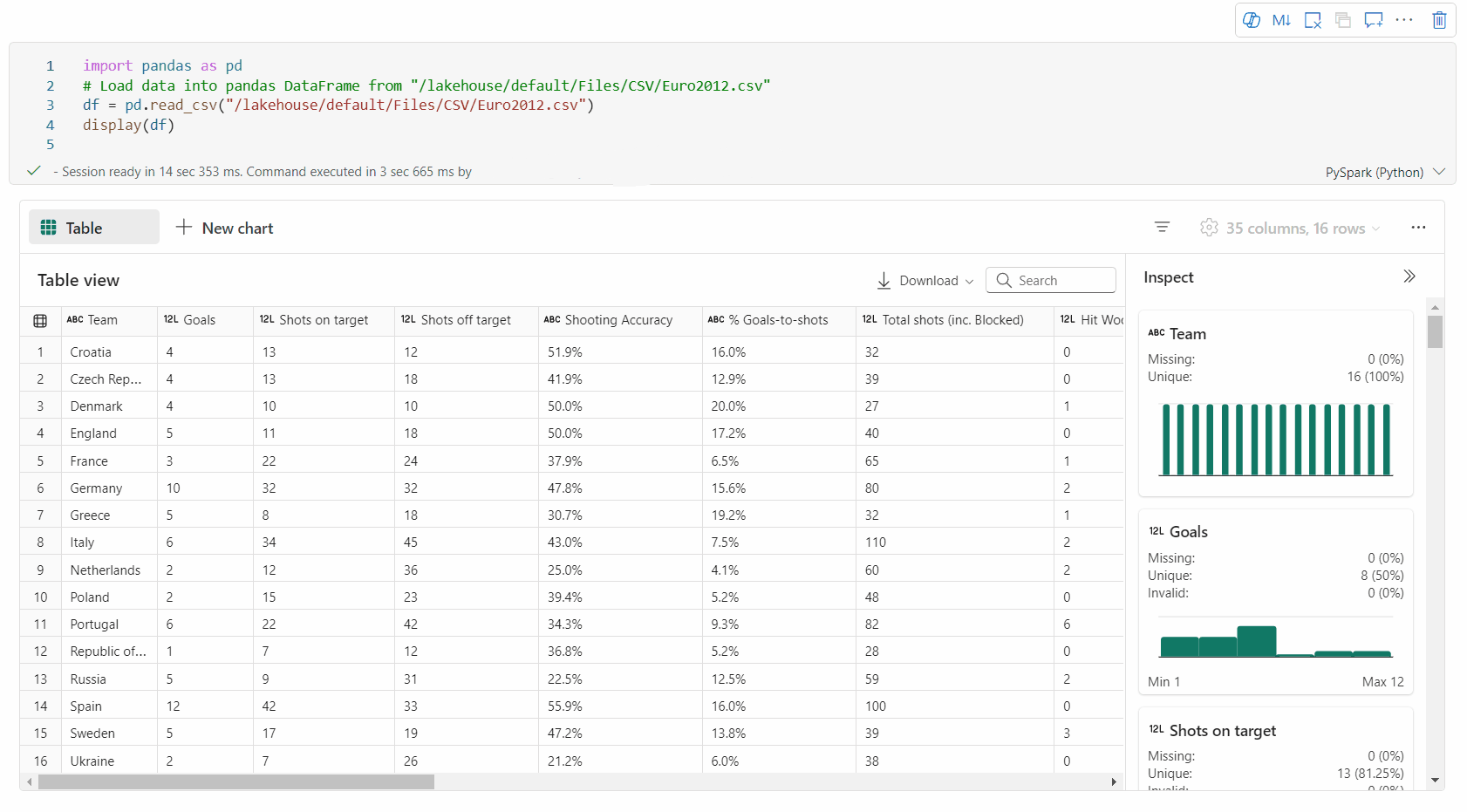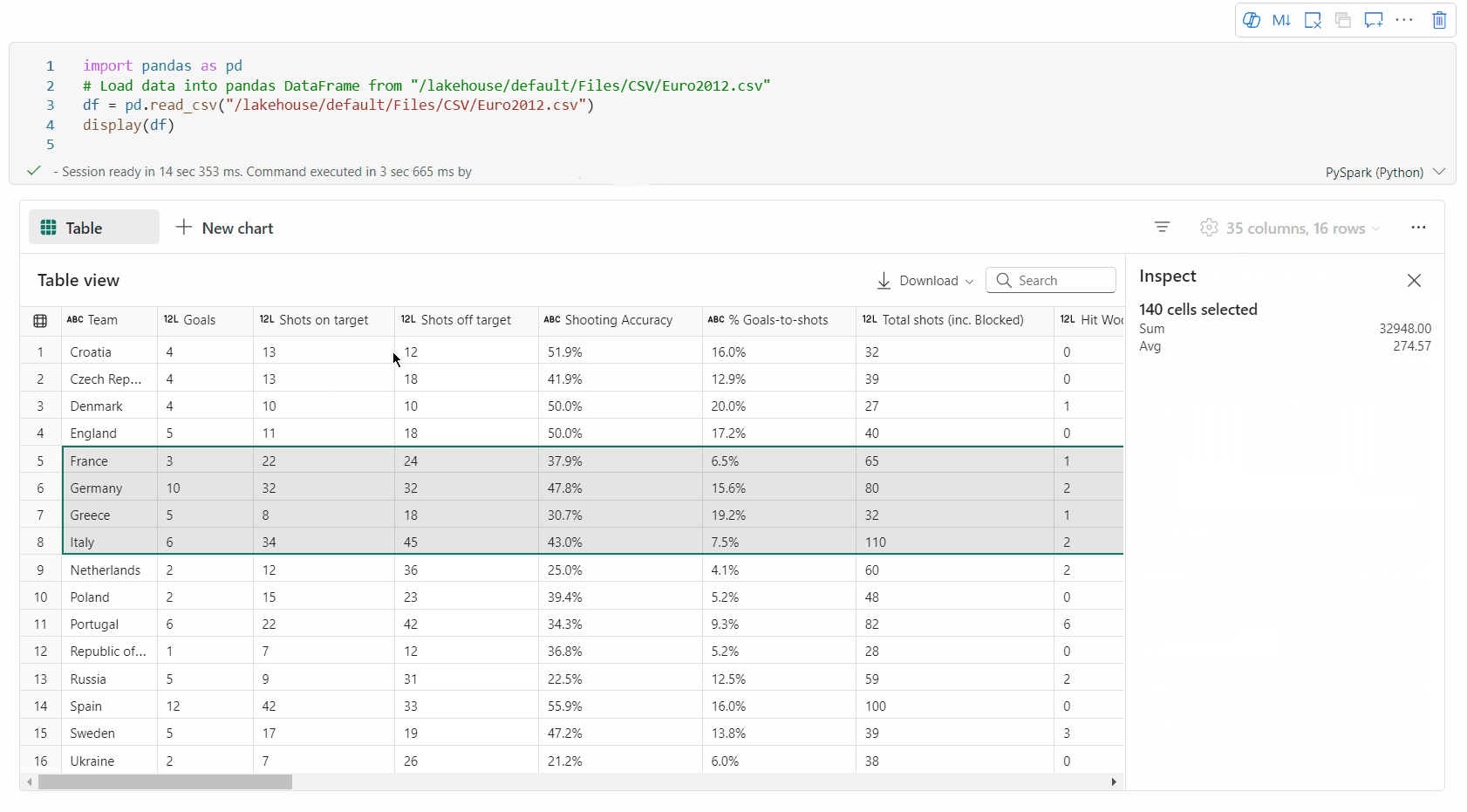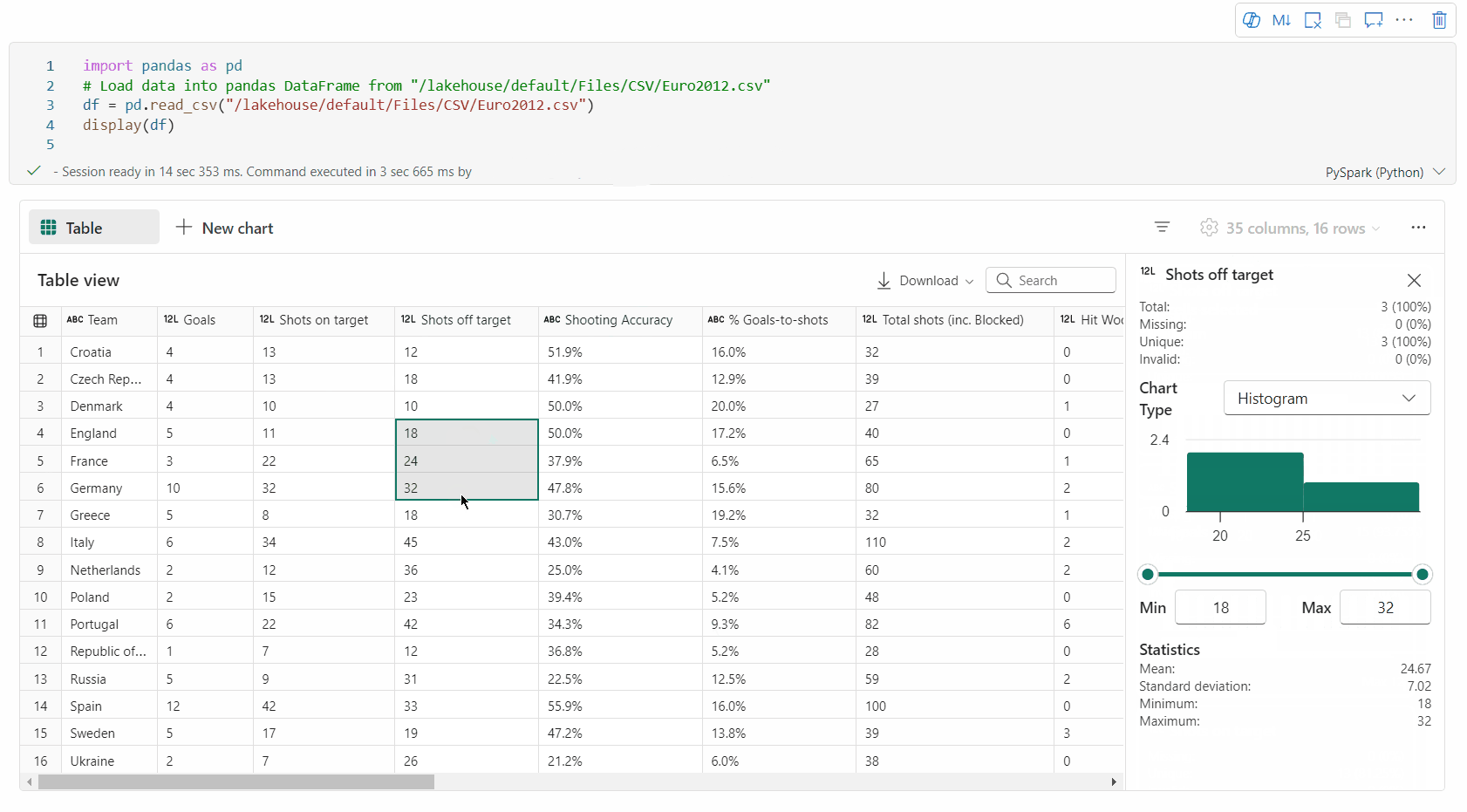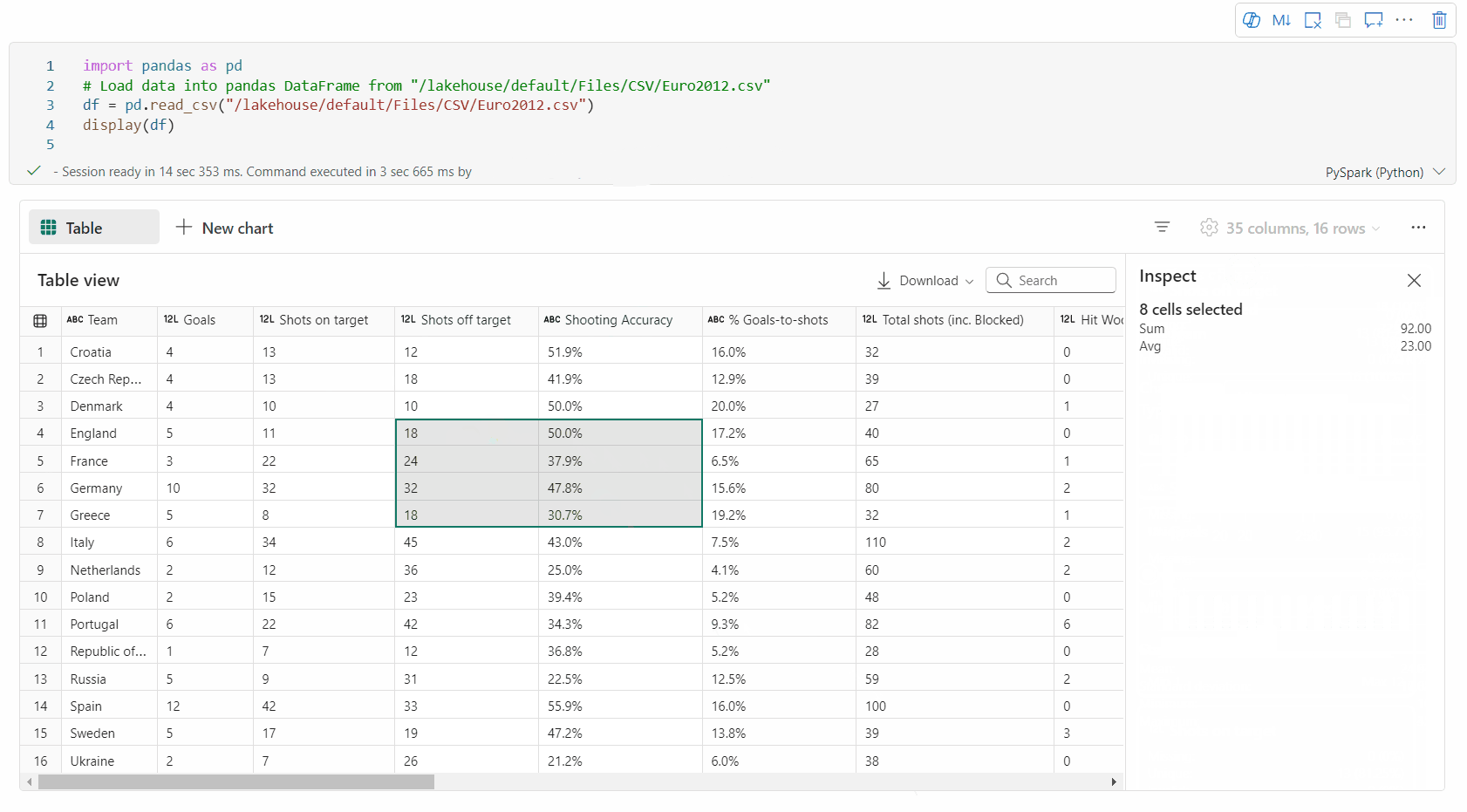
Auswahl des freien Bereichs: Wählen Sie ein beliebiges fortlaufendes Segment der Tabelle aus, um einen Überblick über die ausgewählten Gesamtzellen und die numerischen Werte im ausgewählten Bereich zu erhalten.
Kopieren ausgewählter Inhalte: In allen Auswahlfällen können Sie den ausgewählten Inhalt schnell mit der Tastenkombination "STRG+C" kopieren. Die ausgewählten Daten werden im CSV-Format kopiert und erleichtern die Verarbeitung in anderen Anwendungen.
Unterstützung der Datenprofilerstellung über den Bereich „Überprüfen“
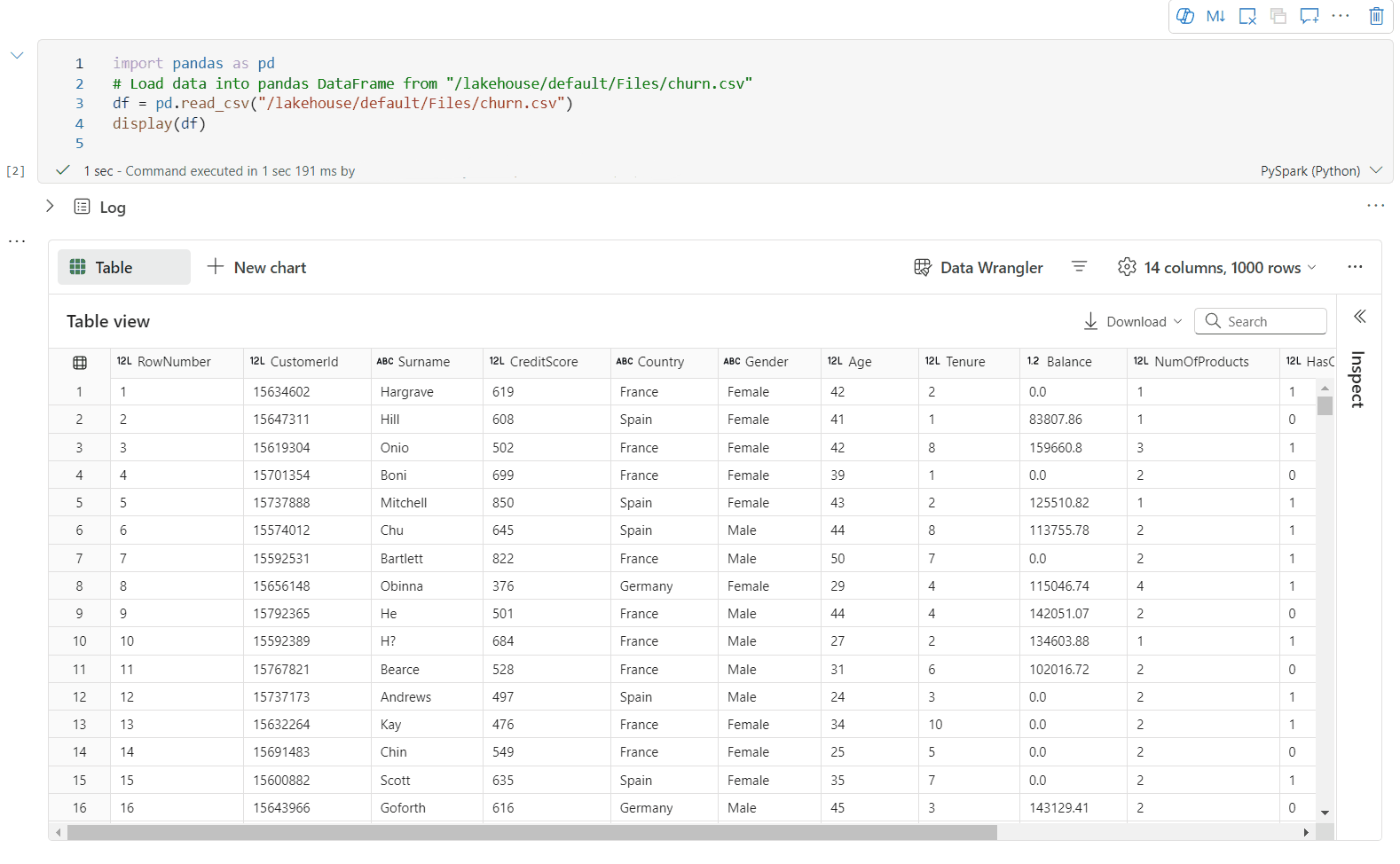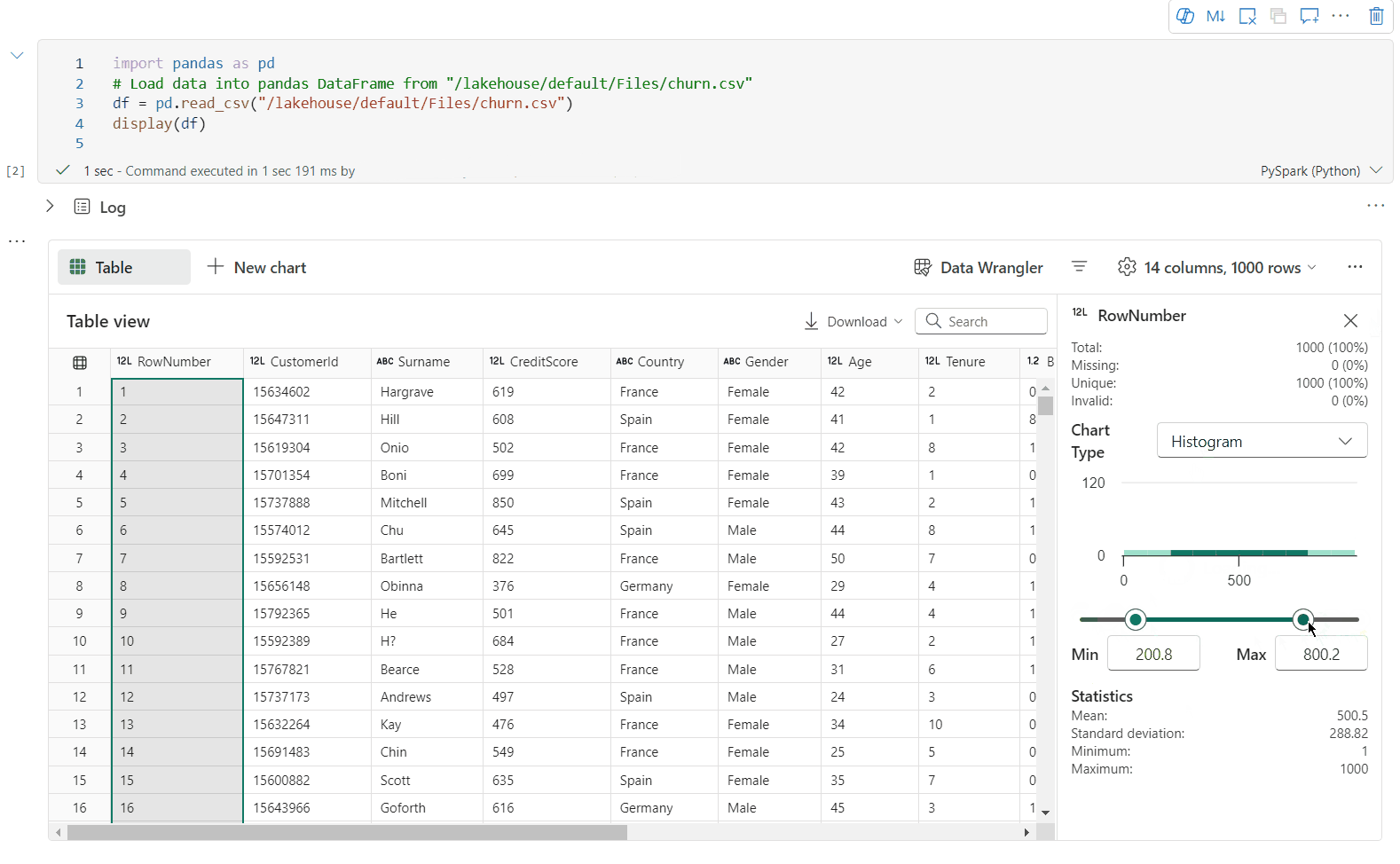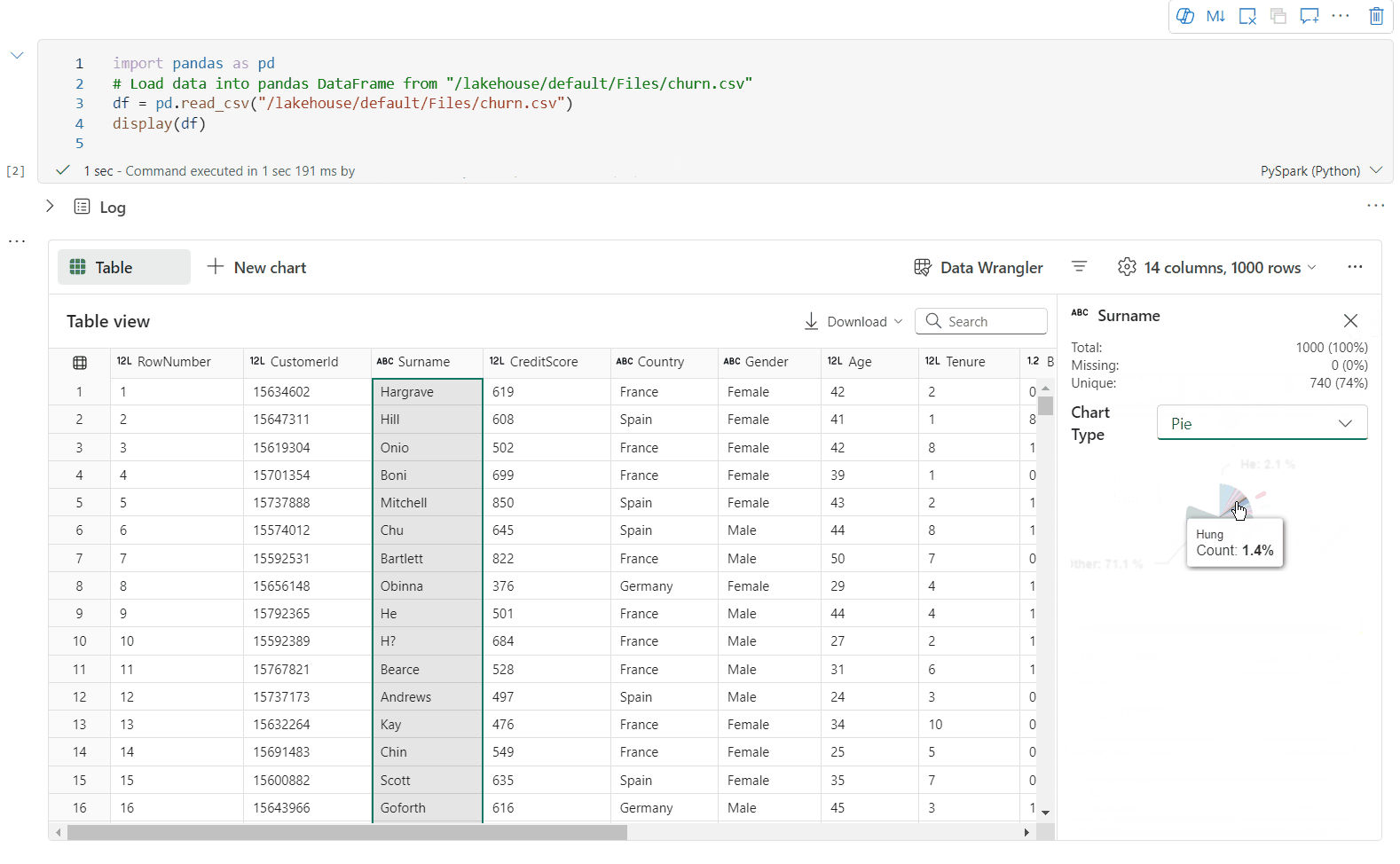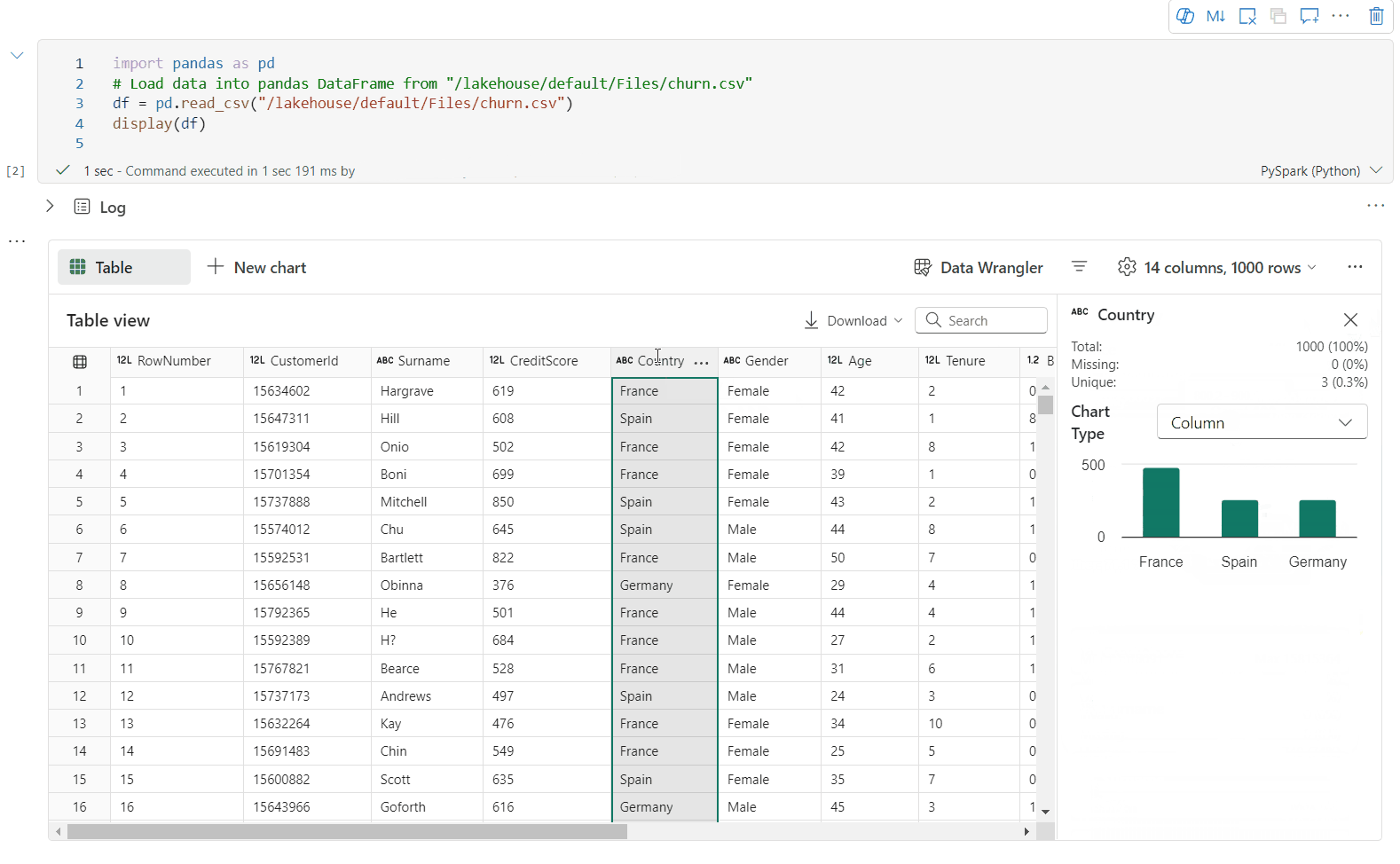
Sie können Ihren DataFrame profilieren, indem Sie auf die SchaltflächeInspizieren klicken. Sie stellt die zusammengefasste Datenverteilung bereit und zeigt Statistiken zu jeder Spalte an.
Jede Karte im Seitenbereich „Inspizieren“ ist einer Spalte des DataFrame zugeordnet. Sie können weitere Details anzeigen, indem Sie auf die Karte klicken oder eine Spalte in der Tabelle auswählen.
Sie können die Zelldetails anzeigen, indem Sie auf die Zelle der Tabelle klicken. Dieses Feature ist nützlich, wenn der Dataframe lange Zeichenketteninhalte enthält.
Neue Rich Dataframe-Diagrammansicht
Hinweis
Dieses Feature befindet sich derzeit in der Vorschauphase.
Die verbesserte Diagrammansicht mit dem display()-Befehl verfügbar. Sie bietet eine intuitivere und leistungsfähigere Benutzeroberfläche für die Visualisierung Ihrer Daten mithilfe des Befehls display().
Jetzt können Sie bis zu 5 Diagramme in einem display()-Ausgabe-Widget hinzufügen, indem Sie auf Neues Diagramm klicken, sodass Sie mehrere Diagramme basierend auf unterschiedlichen Spalten erstellen und Diagramme problemlos vergleichen können.
Sie können eine Liste von Diagrammempfehlungen basierend auf dem Zieldatenrahmen abrufen, wenn Sie neue Diagramme erstellen. Sie können ein empfohlenes Diagramm bearbeiten oder ein eigenes Diagramm von Grund auf neu erstellen.
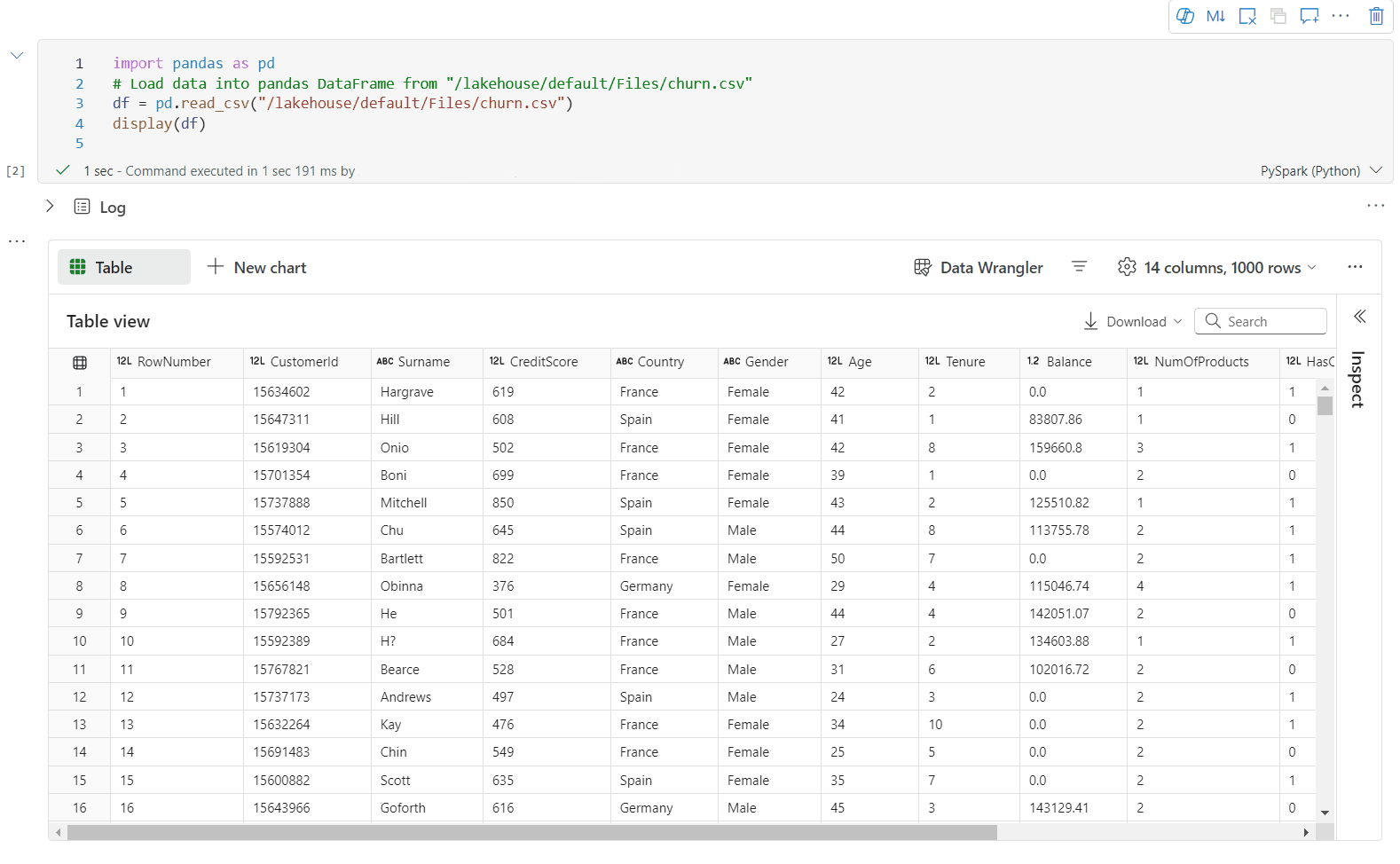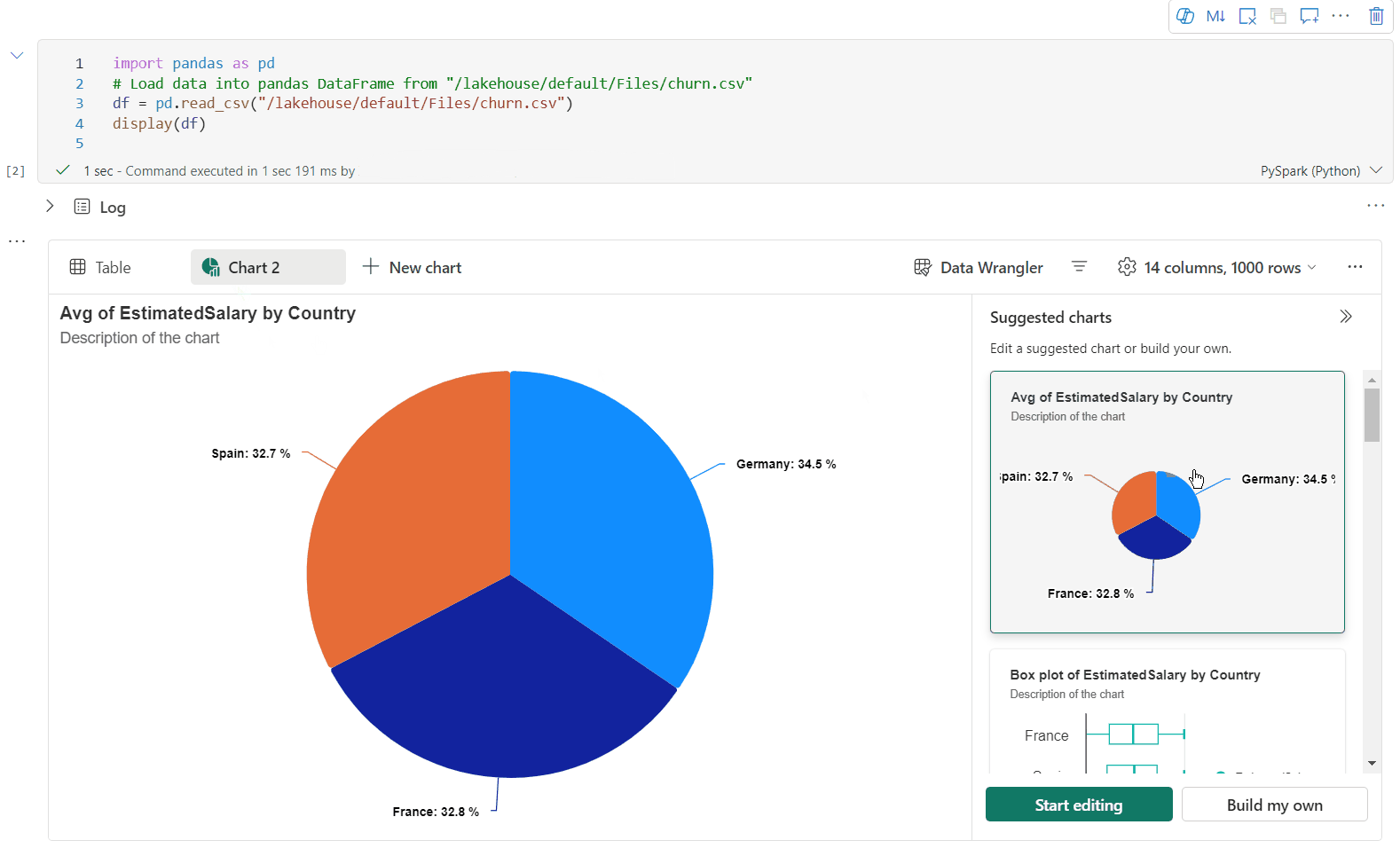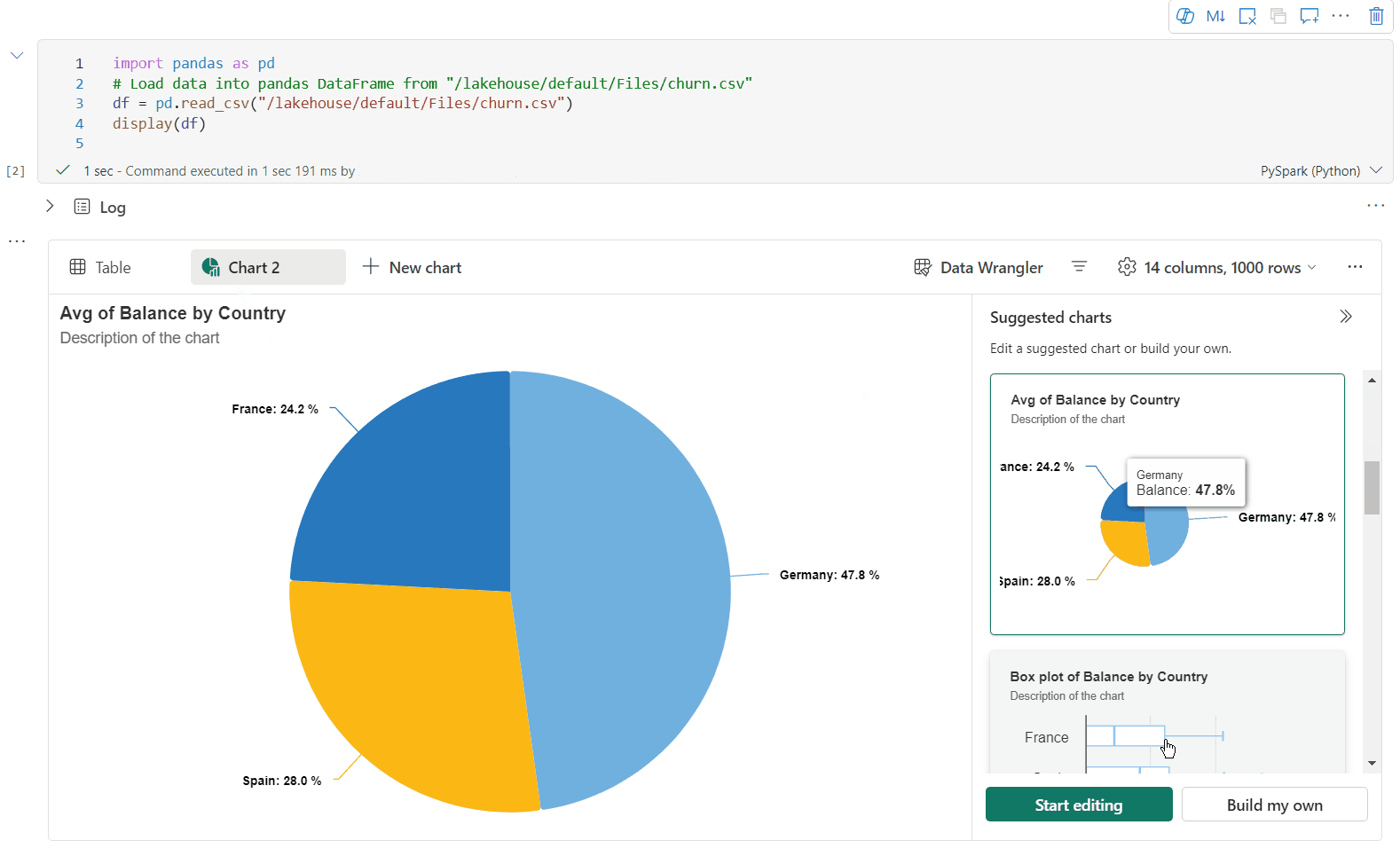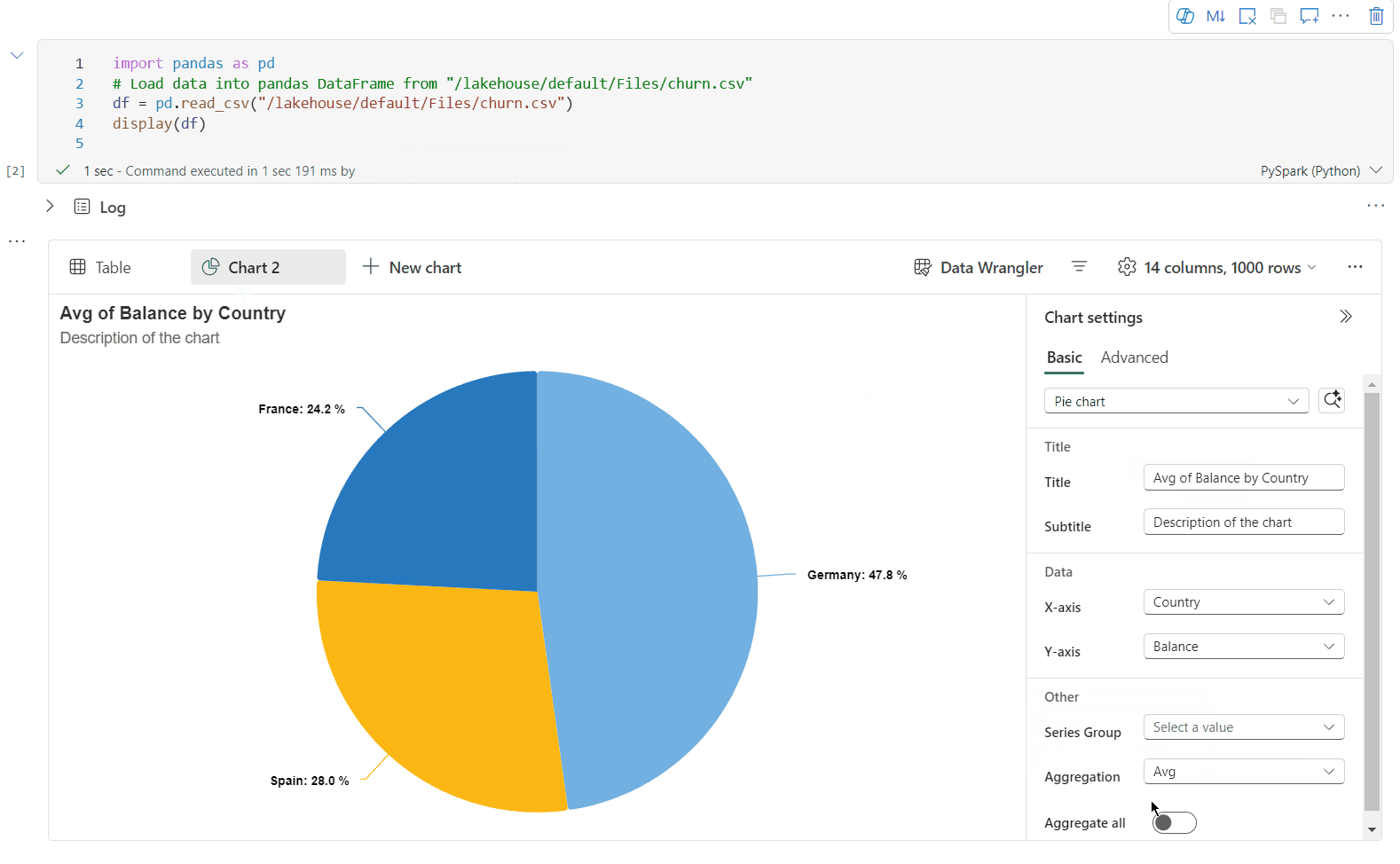
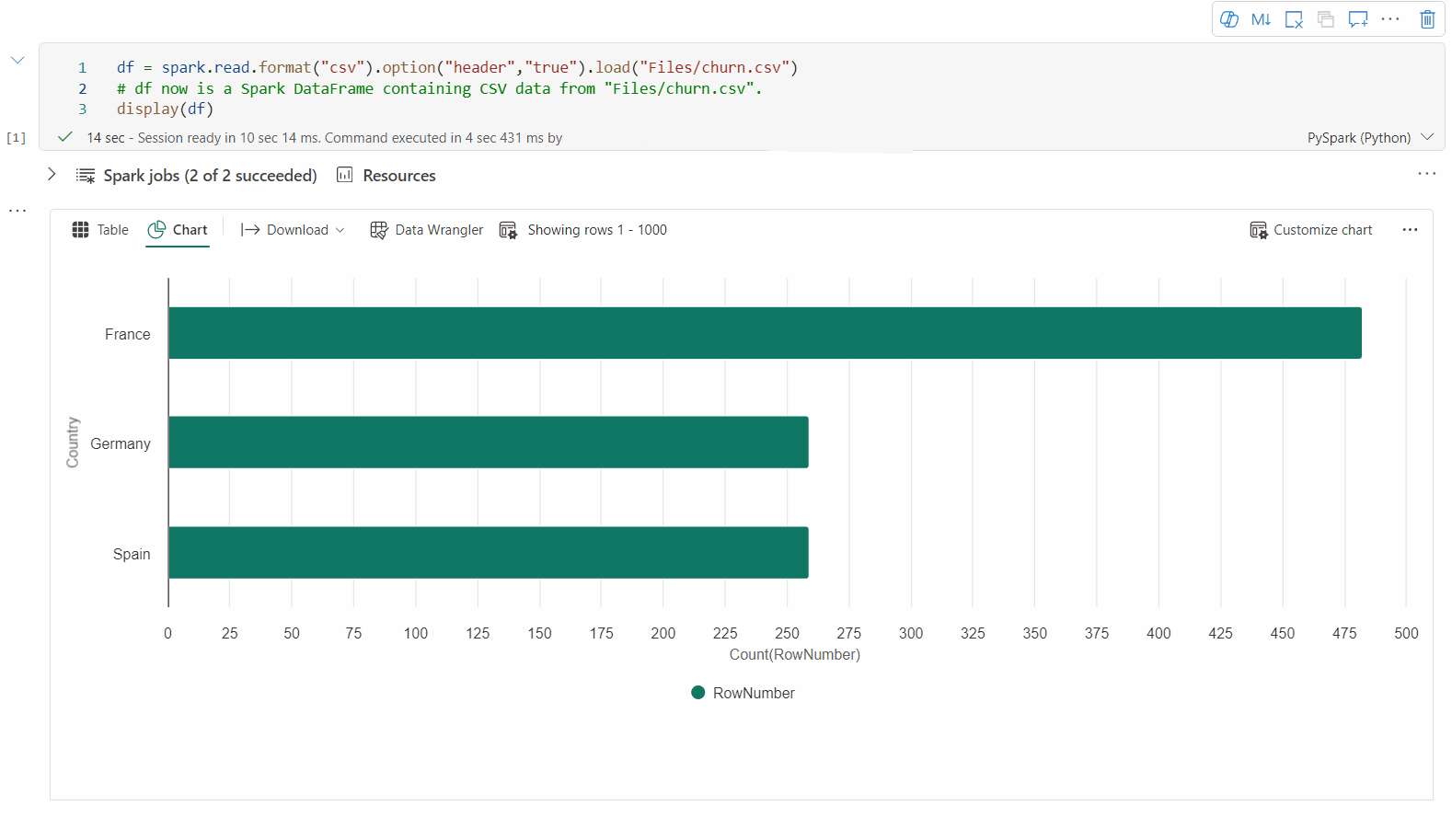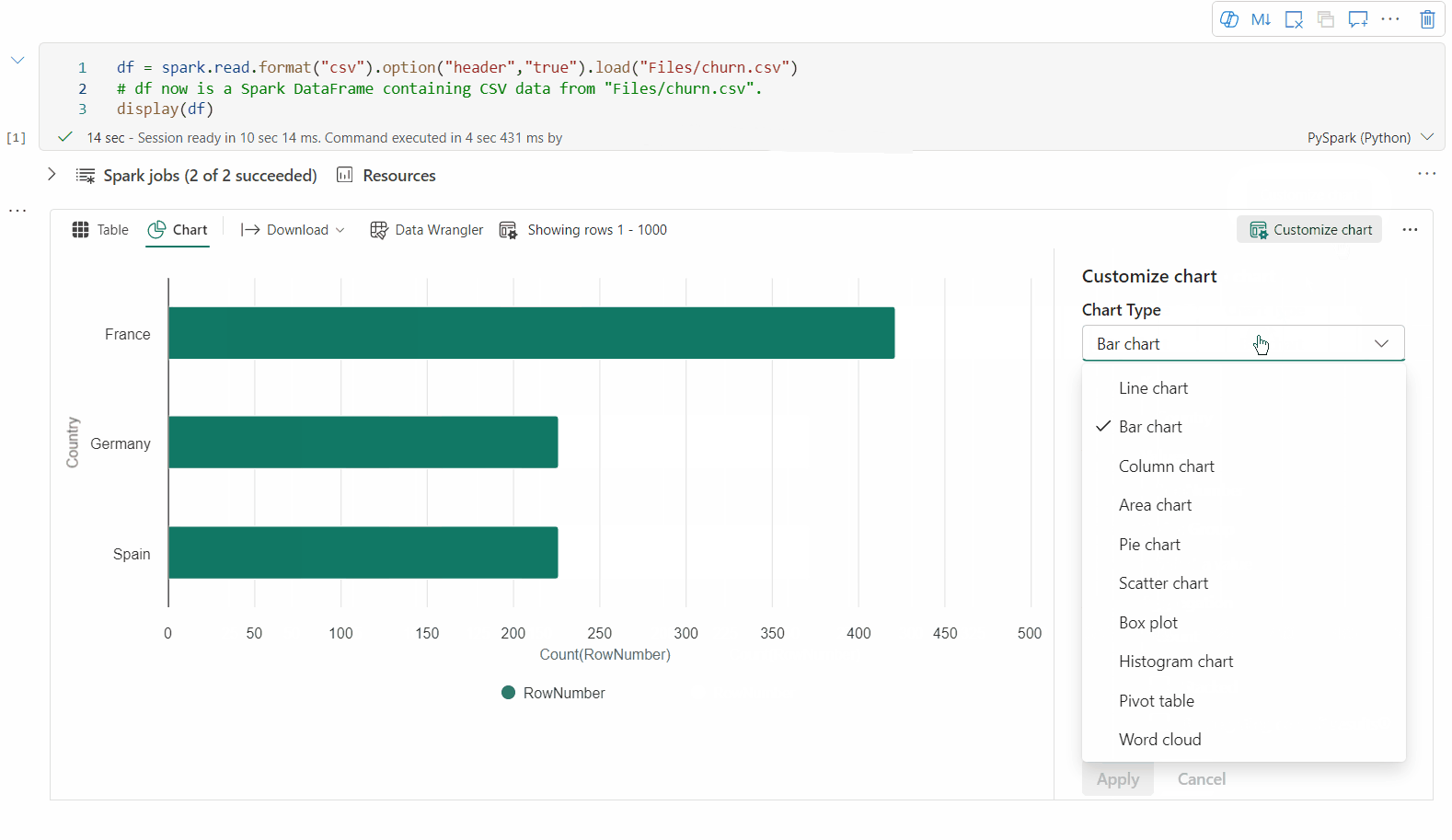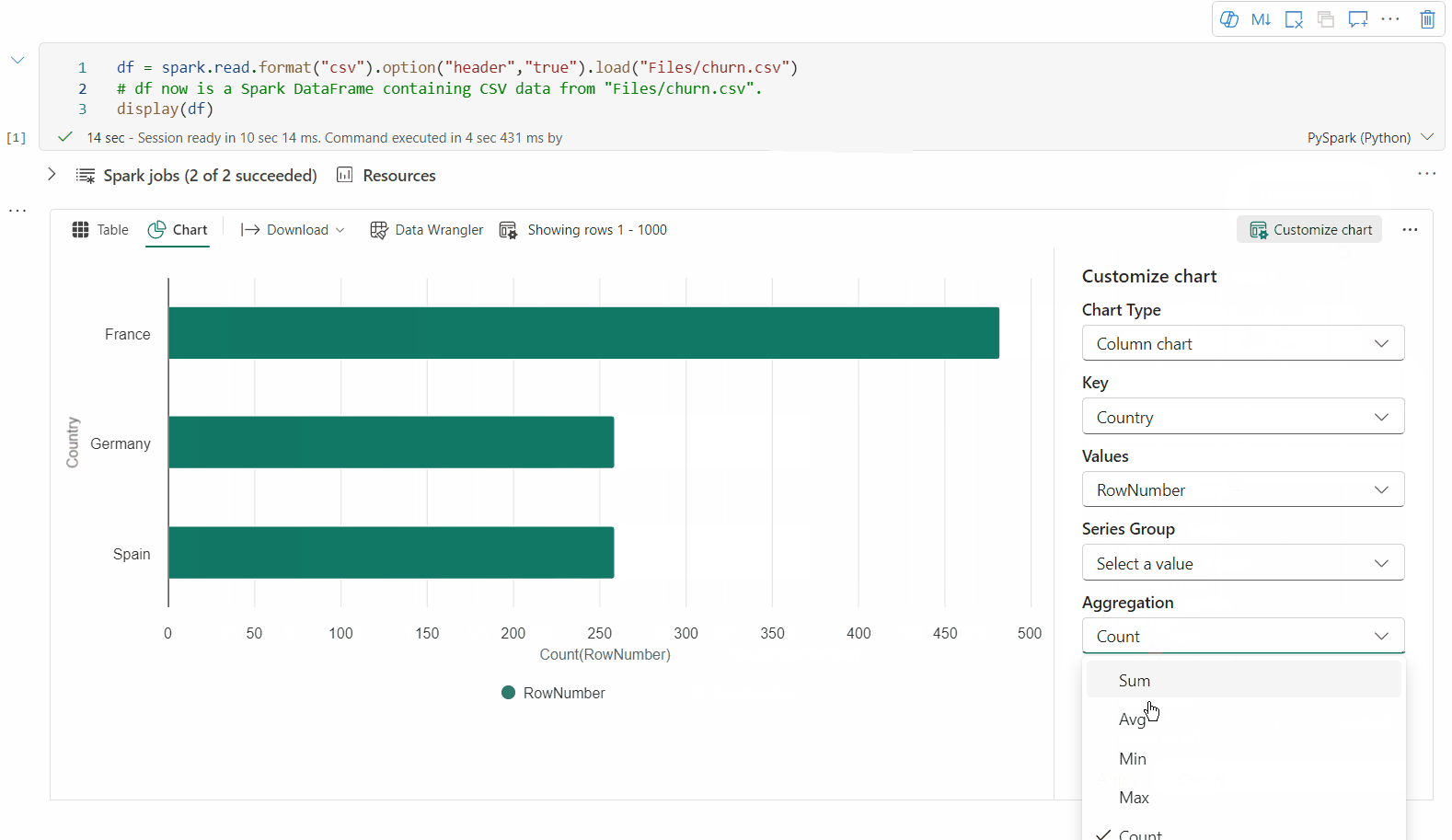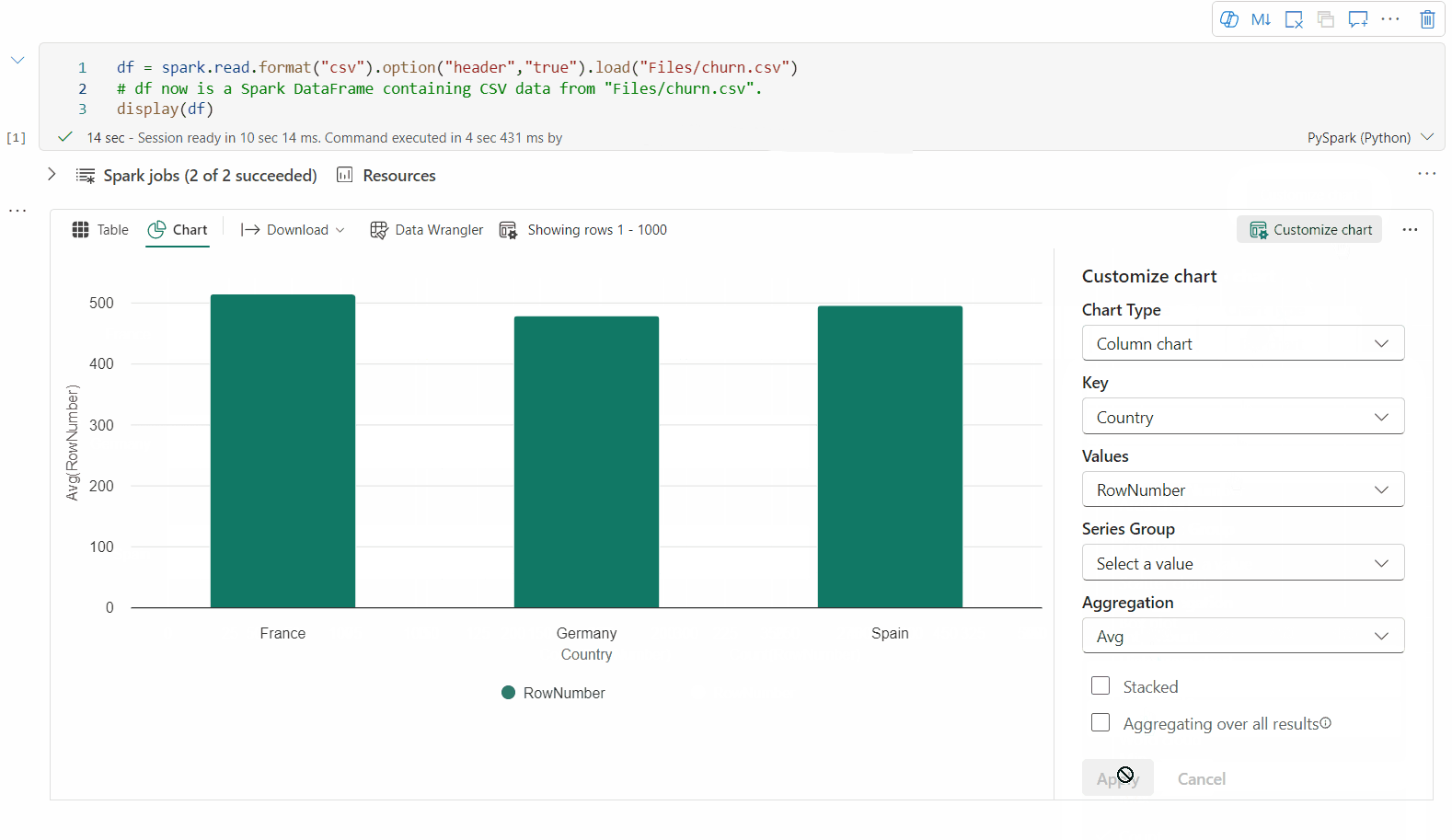
Sie können ihre Visualisierung jetzt anpassen, indem Sie die folgenden Einstellungen angeben. Die Einstellungsoptionen können sich je nach ausgewähltem Diagrammtyp ändern:
Kategorie Grundlegende Einstellungen Beschreibung Diagrammtyp Die display-Funktion unterstützt eine breite Palette von Diagrammtypen, einschließlich Balkendiagrammen, Punktdiagrammen, Liniendiagrammen, Pivottabellen und weiteren. Titel Titel Der Titel des Diagramms. Titel Untertitel Der Untertitel des Diagramms mit weiteren Beschreibungen. Daten X-Achse Geben Sie den Schlüssel des Diagramms an. Daten Y-Achse Geben Sie die Werte des Diagramms an. Legende Legende anzeigen Aktivieren/Deaktivieren sie die Legende. Legende Position Passen Sie die Position der Legende an. Andere Reihengruppe Verwenden Sie diese Konfiguration, um die Gruppen für die Aggregation zu bestimmen. Andere Aggregation Verwenden Sie diese Methode zum Aggregieren von Daten in der Visualisierung. Andere Gestapelt Konfigurieren Sie das Anzeigeformat des Ergebnisses. Hinweis
Standardmäßig verwendet die display(df) Funktion nur die ersten 1.000 Zeilen der Daten, um die Diagramme zu rendern. Wählen Sie Gesamtergebnisse der Aggregation und dann Anwenden aus, um die Diagrammgenerierung auf das gesamte Dataframe anzuwenden. Ein Spark-Auftrag wird ausgelöst, wenn sich die Diagrammeinstellung ändert. Es kann mehrere Minuten dauern, bis die Berechnung abgeschlossen und das Diagramm gerendert wird.
Kategorie Erweiterte Einstellungen Beschreibung Color Thema Definieren Sie den Designfarbensatz des Diagramms. X-Achse Label Geben Sie eine Beschriftung für die X-Achse an. X-Achse Skalieren Geben Sie die Skalierungsfunktion der X-Achse an. X-Achse Bereich Geben Sie die X-Achse des Wertbereichs an. Y-Achse Label Geben Sie eine Beschriftung für die Y-Achse an. Y-Achse Skalieren Geben Sie die Skalierungsfunktion der Y-Achse an. Y-Achse Bereich Geben Sie den Wertbereich Y-Achse an. Anzeige Bezeichnungen anzeigen Blenden Sie die Ergebnisbeschriftungen im Diagramm ein/aus. Die Änderungen der Konfigurationen werden sofort wirksam, und alle Konfigurationen werden automatisch in Notizbuchinhalten gespeichert.
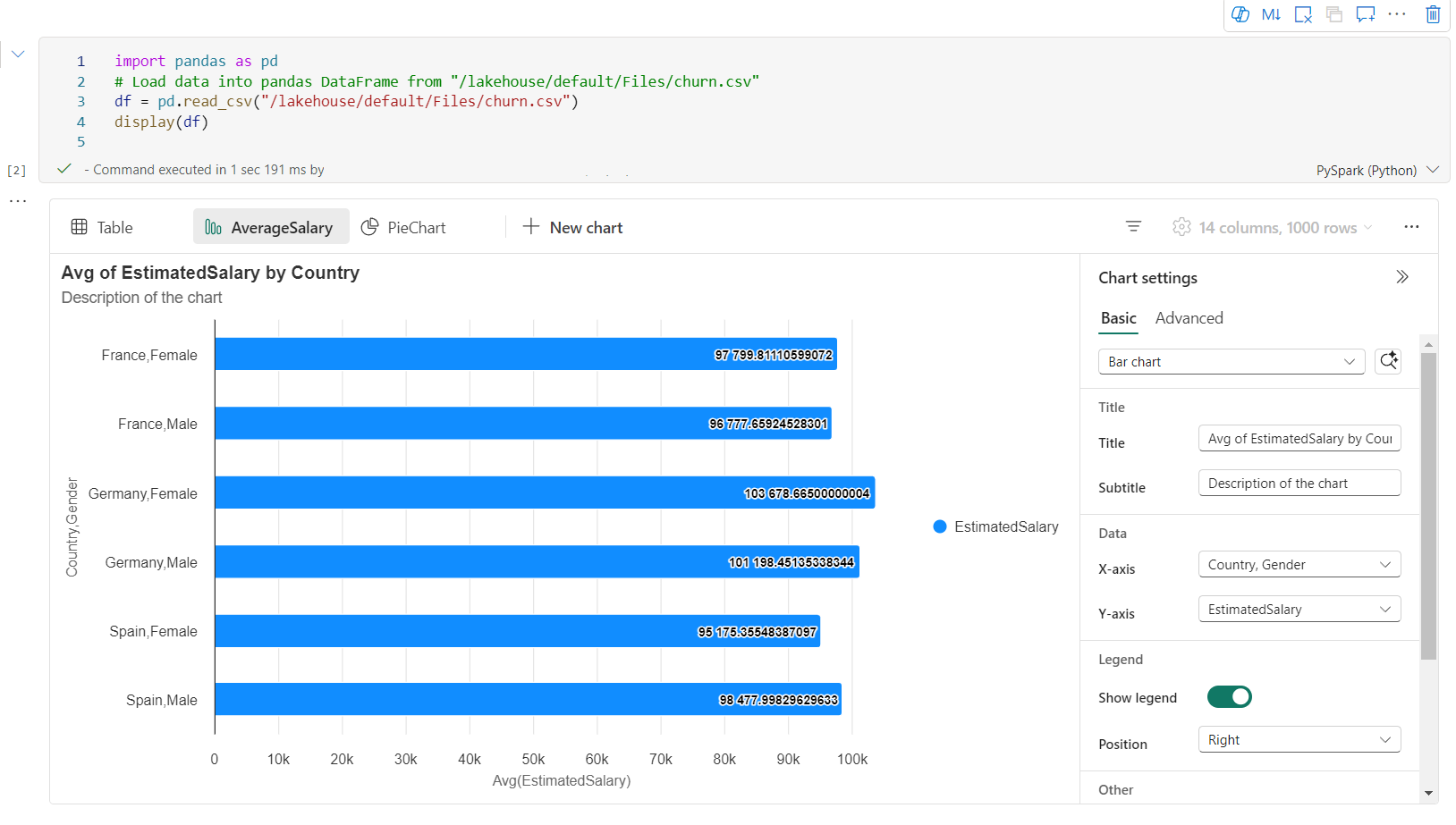
Sie können ganz einfach Diagramme im Menü „Diagrammregisterkarten“ umbenennen, duplizieren oder löschen.
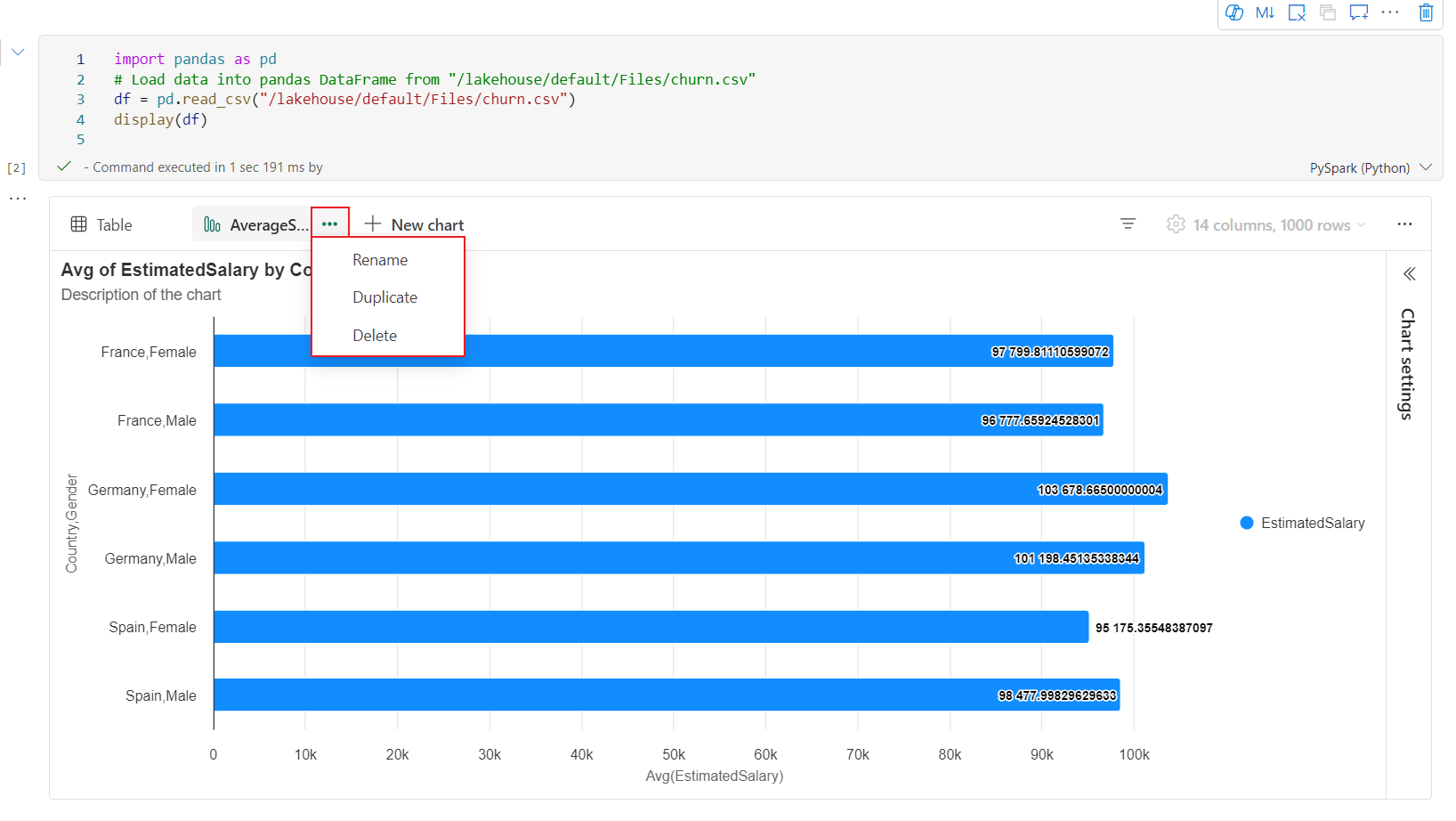
Eine interaktive Symbolleiste ist in der neuen Diagrammoberfläche verfügbar, wenn der Benutzer auf ein Diagramm zeigt. Unterstützen von Vorgängen wie Vergrößern, Verkleinern, Auswählen zum Vergrößern, Zurücksetzen, Schwenken usw.
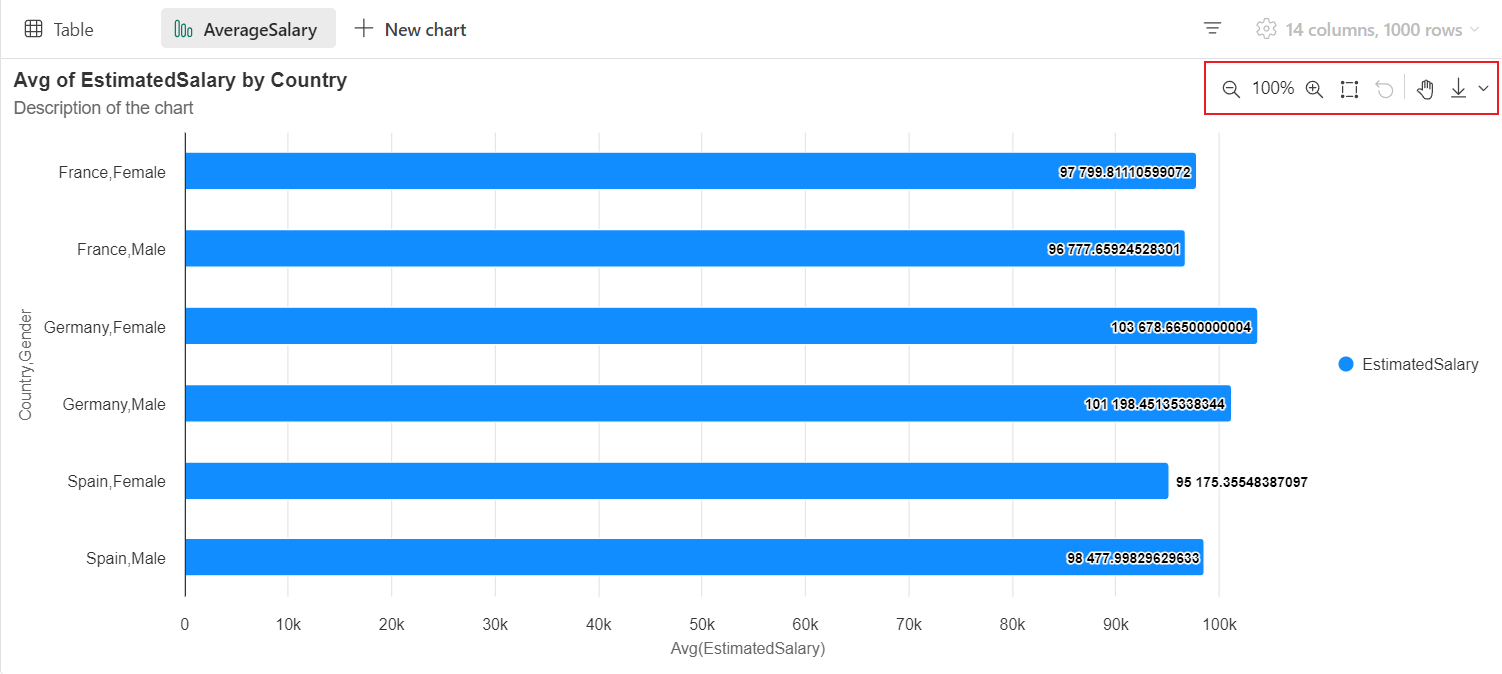



Legacydiagrammansicht
Hinweis
Die ältere Diagrammansicht wird eingestellt, nachdem die neue Diagrammansicht die Vorschau durchlaufen hat.
Sie können zurück zur älteren Diagrammansicht wechseln, indem Sie „Neue Visualisierung“ ausschalten. Die neue Oberfläche ist standardmäßig aktiviert.
Sobald Sie über eine gerenderte Tabellenansicht verfügen, wechseln Sie zur Diagrammansicht.
Das Fabric-Notebook empfiehlt Diagramme basierend auf dem Zieldatenrahmen automatisch, um das Diagramm mit Datenerkenntnissen aussagekräftig zu gestalten.
Sie können Ihre Visualisierung jetzt anpassen, indem Sie die folgenden Werte angeben:
Configuration Beschreibung Diagrammtyp Die Ansichtsfunktion (display) unterstützt eine breite Palette von Diagrammtypen, einschließlich Balkendiagrammen, Punktdiagrammen, Liniendiagrammen und weiteren. Schlüssel Geben Sie den Wertebereich für die X-Achse an. Wert Geben Sie den Wertebereich für die Y-Achse an. Reihengruppe Verwenden Sie diese Konfiguration, um die Gruppen für die Aggregation zu bestimmen. Aggregation Verwenden Sie diese Methode zum Aggregieren von Daten in der Visualisierung. Die Konfigurationen werden automatisch im Ausgabeinhalt des Notebooks gespeichert.
Hinweis
Standardmäßig verwendet die display(df) Funktion nur die ersten 1.000 Zeilen der Daten, um die Diagramme zu rendern. Wählen Sie Gesamtergebnisse der Aggregation und dann Anwenden aus, um die Diagrammgenerierung auf das gesamte Dataframe anzuwenden. Ein Spark-Auftrag wird ausgelöst, wenn sich die Diagrammeinstellung ändert. Es kann mehrere Minuten dauern, bis die Berechnung abgeschlossen und das Diagramm gerendert wird.
Nach Abschluss des Auftrags können Sie Ihre endgültige Visualisierung anzeigen und mit ihr interagieren.

Zusammenfassungsansicht von display()
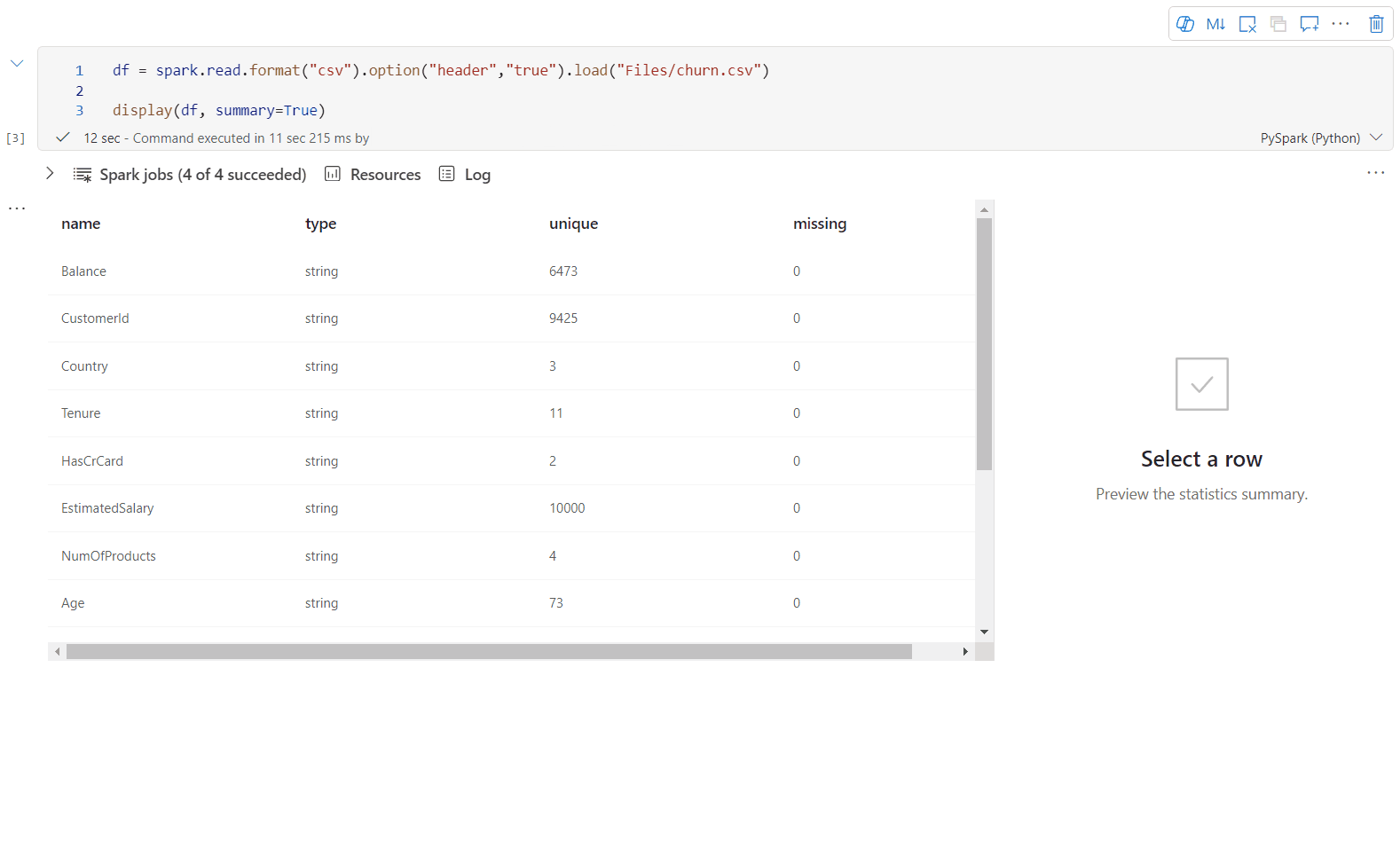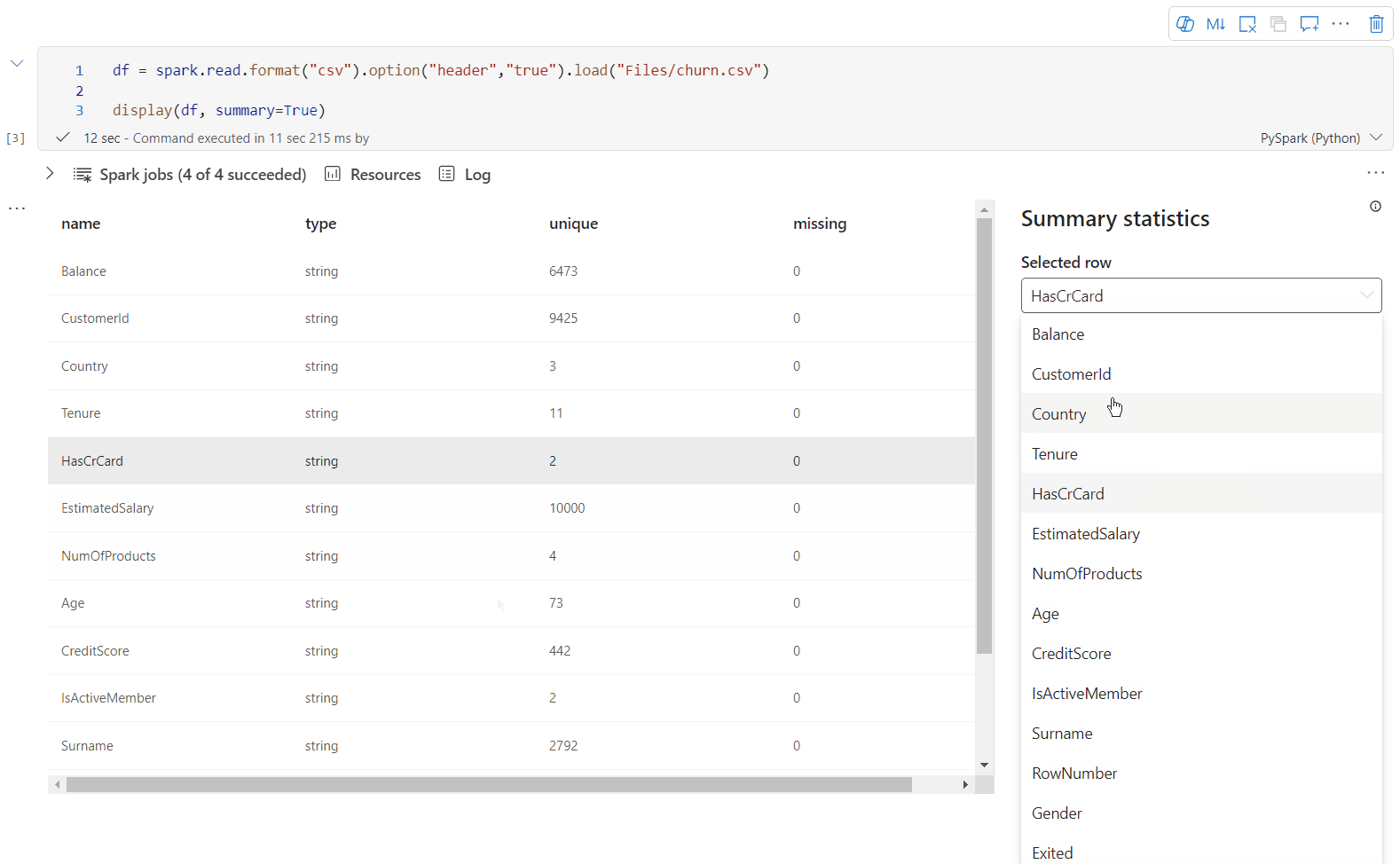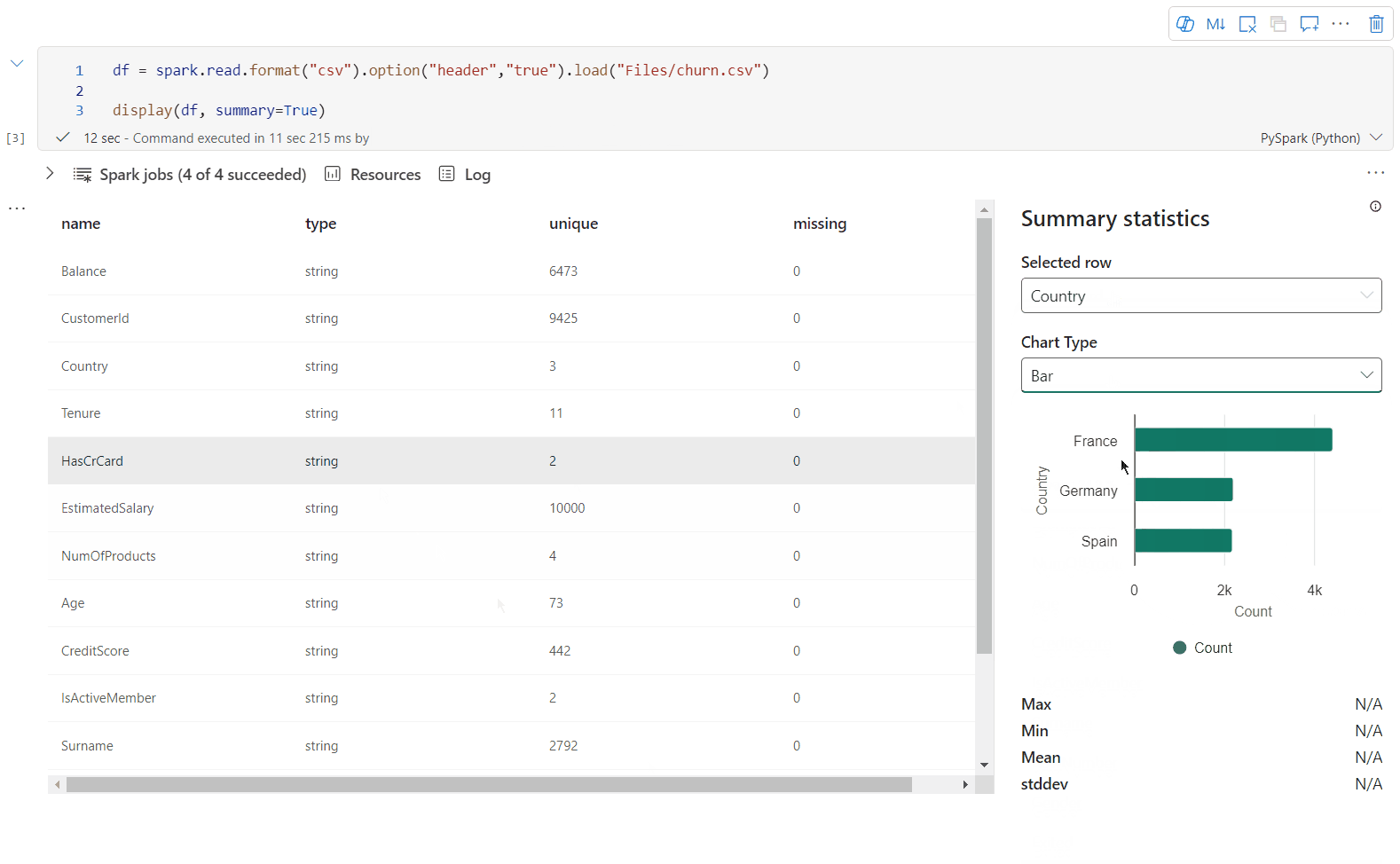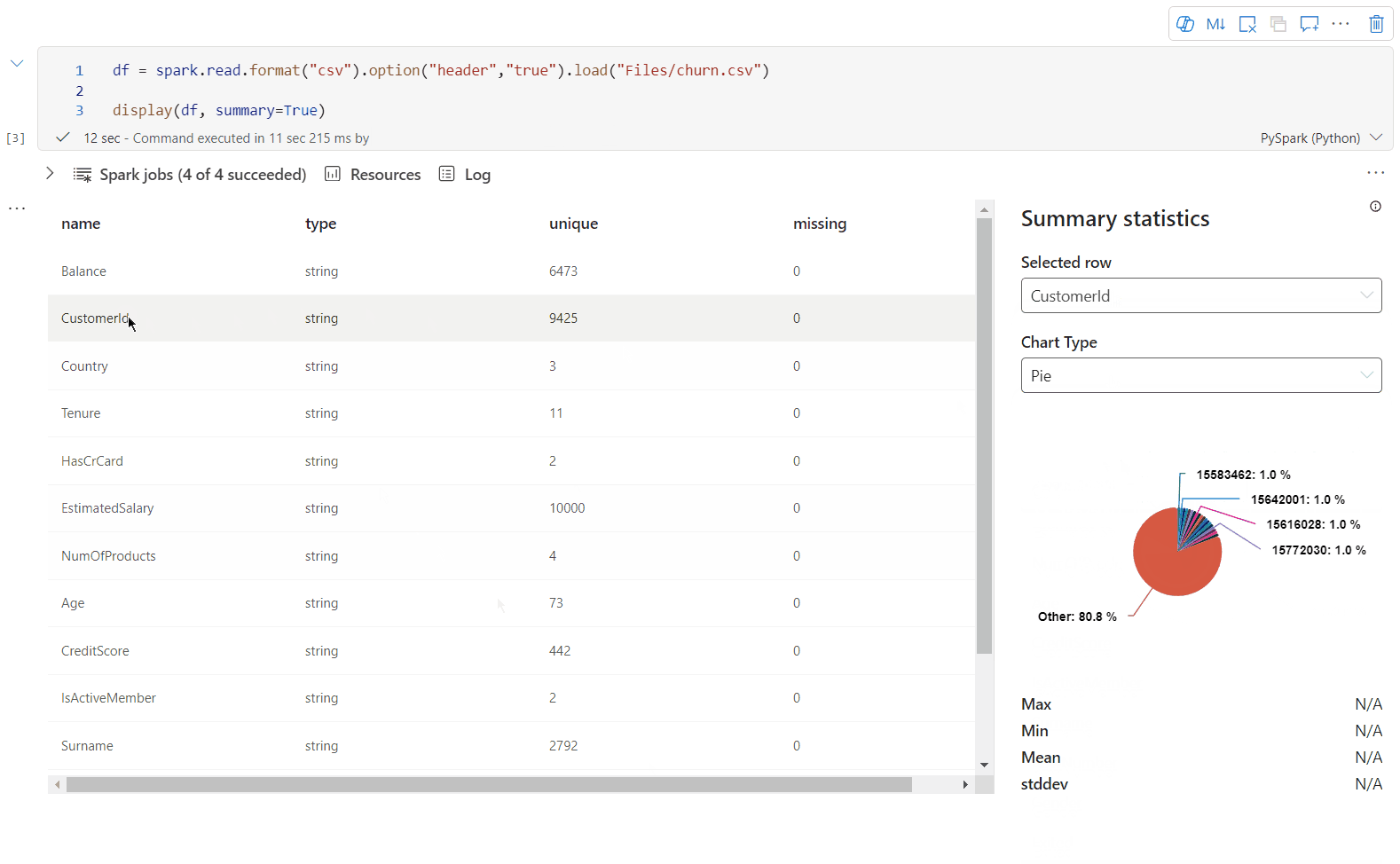
Verwenden Sie display(df, summary = true), um die Statistikzusammenfassung eines bestimmten Apache Spark-Datenrahmens zu überprüfen. Die Zusammenfassung enthält den Spaltennamen, den Spaltentyp, eindeutige Werte und fehlende Werte für jede Spalte. Ferner können Sie eine bestimmte Spalte auswählen, um ihren Mindestwert, Höchstwert, Durchschnittswert und die Standardabweichung anzuzeigen.
displayHTML(): Option
Fabric-Notebooks unterstützen HTML-Grafiken über die Funktion displayHTML.
Die folgende Abbildung ist ein Beispiel für das Erstellen von Visualisierungen mithilfe von D3.js.

Führen Sie den folgenden Code aus, um diese Visualisierung zu erstellen.
displayHTML("""<!DOCTYPE html>
<meta charset="utf-8">
<!-- Load d3.js -->
<script src="https://d3js.org/d3.v4.js"></script>
<!-- Create a div where the graph will take place -->
<div id="my_dataviz"></div>
<script>
// set the dimensions and margins of the graph
var margin = {top: 10, right: 30, bottom: 30, left: 40},
width = 400 - margin.left - margin.right,
height = 400 - margin.top - margin.bottom;
// append the svg object to the body of the page
var svg = d3.select("#my_dataviz")
.append("svg")
.attr("width", width + margin.left + margin.right)
.attr("height", height + margin.top + margin.bottom)
.append("g")
.attr("transform",
"translate(" + margin.left + "," + margin.top + ")");
// Create Data
var data = [12,19,11,13,12,22,13,4,15,16,18,19,20,12,11,9]
// Compute summary statistics used for the box:
var data_sorted = data.sort(d3.ascending)
var q1 = d3.quantile(data_sorted, .25)
var median = d3.quantile(data_sorted, .5)
var q3 = d3.quantile(data_sorted, .75)
var interQuantileRange = q3 - q1
var min = q1 - 1.5 * interQuantileRange
var max = q1 + 1.5 * interQuantileRange
// Show the Y scale
var y = d3.scaleLinear()
.domain([0,24])
.range([height, 0]);
svg.call(d3.axisLeft(y))
// a few features for the box
var center = 200
var width = 100
// Show the main vertical line
svg
.append("line")
.attr("x1", center)
.attr("x2", center)
.attr("y1", y(min) )
.attr("y2", y(max) )
.attr("stroke", "black")
// Show the box
svg
.append("rect")
.attr("x", center - width/2)
.attr("y", y(q3) )
.attr("height", (y(q1)-y(q3)) )
.attr("width", width )
.attr("stroke", "black")
.style("fill", "#69b3a2")
// show median, min and max horizontal lines
svg
.selectAll("toto")
.data([min, median, max])
.enter()
.append("line")
.attr("x1", center-width/2)
.attr("x2", center+width/2)
.attr("y1", function(d){ return(y(d))} )
.attr("y2", function(d){ return(y(d))} )
.attr("stroke", "black")
</script>
"""
)
Einbetten eines Power BI-Berichts in ein Notebook
Wichtig
Dieses Feature befindet sich derzeit in der VORSCHAU. Diese Informationen beziehen sich auf ein Vorabversionsprodukt, das erheblich geändert werden kann, bevor es allgemein verfügbar ist. Microsoft übernimmt keine Garantie, weder ausdrücklich noch stillschweigend, für die hier bereitgestellten Informationen.
Das Python-Paket powerbiclient wird jetzt nativ in Fabric-Notebooks unterstützt. Es ist kein zusätzliches Setup (z. B. eines Authentifizierungsprozesses) für die Spark-Runtime 3.4 für Fabric-Notebooks erforderlich. Importieren Sie einfach powerbiclient, und fahren Sie dann mit Ihrer Erkundung fort. Weitere Informationen zur Verwendung des Pakets „powerbiclient“ finden Sie in der Dokumentation zu „powerbiclient“.
„powerbiclient“ unterstützt folgende wichtige Features:
Rendern eines vorhandenen Power BI-Berichts
Sie können Power BI-Berichte ganz einfach und mit nur wenigen Codezeilen in Ihre Notebooks einbetten und mit ihnen interagieren.
Die folgende Abbildung zeigt ein Beispiel für das Rendern eines vorhandenen Power BI-Berichts:

Führen Sie den folgenden Code aus, um einen vorhandenen Power BI-Bericht zu rendern:
from powerbiclient import Report
report_id="Your report id"
report = Report(group_id=None, report_id=report_id)
report
Erstellen von Berichtsvisualisierungen auf der Grundlage eines Spark-Datenrahmens
Sie können einen Spark-Datenrahmen in Ihrem Notebook verwenden, um schnell aussagekräftige Visualisierungen zu generieren. Sie können in dem eingebetteten Bericht auch Speichern auswählen, um ein Berichtselement in einem Zielarbeitsbereich zu erstellen.
Das folgende Bild ist ein QuickVisualize()-Beispiel auf der Grundlage eines Spark-Datenrahmens:

Führen Sie den folgenden Code aus, um einen Bericht auf der Grundlage eines Spark-Datenrahmens zu rendern:
# Create a spark dataframe from a Lakehouse parquet table
sdf = spark.sql("SELECT * FROM testlakehouse.table LIMIT 1000")
# Create a Power BI report object from spark data frame
from powerbiclient import QuickVisualize, get_dataset_config
PBI_visualize = QuickVisualize(get_dataset_config(sdf))
# Render new report
PBI_visualize
Erstellen von Berichtsvisualisierungen auf der Grundlage eines Pandas-Datenrahmens
Sie können im Notebook auch Berichte basierend auf einem Pandas-Datenrahmen erstellen.
Das folgende Bild ist ein QuickVisualize()-Beispiel auf der Grundlage eines Pandas-Datenrahmens:

Führen Sie den folgenden Code aus, um einen Bericht auf der Grundlage eines Spark-Datenrahmens zu rendern:
import pandas as pd
# Create a pandas dataframe from a URL
df = pd.read_csv("https://raw.githubusercontent.com/plotly/datasets/master/fips-unemp-16.csv")
# Create a pandas dataframe from a Lakehouse csv file
from powerbiclient import QuickVisualize, get_dataset_config
# Create a Power BI report object from your data
PBI_visualize = QuickVisualize(get_dataset_config(df))
# Render new report
PBI_visualize
Beliebte Bibliotheken
Wenn es um Datenvisualisierung geht, bietet Python mehrere Grafikbibliotheken, die über viele verschiedene Features verfügen. Standardmäßig enthält jeder Apache Spark-Pool in Fabric mehrere kuratierte und beliebte Open-Source-Bibliotheken.
Matplotlib
Sie können standardmäßige Zeichnungsbibliotheken wie Matplotlib mithilfe der integrierten Renderingfunktionen für die einzelnen Bibliotheken rendern.
Die folgende Abbildung ist ein Beispiel für die Erstellung eines Balkendiagramms mithilfe von Matplotlib.


Führen Sie den folgenden Beispielcode aus, um dieses Balkendiagramm zu zeichnen.
# Bar chart
import matplotlib.pyplot as plt
x1 = [1, 3, 4, 5, 6, 7, 9]
y1 = [4, 7, 2, 4, 7, 8, 3]
x2 = [2, 4, 6, 8, 10]
y2 = [5, 6, 2, 6, 2]
plt.bar(x1, y1, label="Blue Bar", color='b')
plt.bar(x2, y2, label="Green Bar", color='g')
plt.plot()
plt.xlabel("bar number")
plt.ylabel("bar height")
plt.title("Bar Chart Example")
plt.legend()
plt.show()
Bokeh
Sie können HTML- oder interaktive Bibliotheken wie bokeh mithilfe von displayHTML(df) rendern.
Das folgende Bild ist ein Beispiel für das Zeichnen von Glyphen auf einer Karte mithilfe von bokeh.

Führen Sie den folgenden Beispielcode aus, um dieses Bild zu zeichnen:
from bokeh.plotting import figure, output_file
from bokeh.tile_providers import get_provider, Vendors
from bokeh.embed import file_html
from bokeh.resources import CDN
from bokeh.models import ColumnDataSource
tile_provider = get_provider(Vendors.CARTODBPOSITRON)
# range bounds supplied in web mercator coordinates
p = figure(x_range=(-9000000,-8000000), y_range=(4000000,5000000),
x_axis_type="mercator", y_axis_type="mercator")
p.add_tile(tile_provider)
# plot datapoints on the map
source = ColumnDataSource(
data=dict(x=[ -8800000, -8500000 , -8800000],
y=[4200000, 4500000, 4900000])
)
p.circle(x="x", y="y", size=15, fill_color="blue", fill_alpha=0.8, source=source)
# create an html document that embeds the Bokeh plot
html = file_html(p, CDN, "my plot1")
# display this html
displayHTML(html)
Plotly
Sie können HTML-oder interaktive Bibliotheken wie Plotly mithilfe von displayHTML() rendern.
Führen Sie den folgenden Beispielcode aus, um dieses Bild zu zeichnen:

from urllib.request import urlopen
import json
with urlopen('https://raw.githubusercontent.com/plotly/datasets/master/geojson-counties-fips.json') as response:
counties = json.load(response)
import pandas as pd
df = pd.read_csv("https://raw.githubusercontent.com/plotly/datasets/master/fips-unemp-16.csv",
dtype={"fips": str})
import plotly
import plotly.express as px
fig = px.choropleth(df, geojson=counties, locations='fips', color='unemp',
color_continuous_scale="Viridis",
range_color=(0, 12),
scope="usa",
labels={'unemp':'unemployment rate'}
)
fig.update_layout(margin={"r":0,"t":0,"l":0,"b":0})
# create an html document that embeds the Plotly plot
h = plotly.offline.plot(fig, output_type='div')
# display this html
displayHTML(h)
Pandas
Sie können die HTML-Ausgabe von Pandas-Datenrahmen als Standardausgabe anzeigen. Fabric-Notebooks zeigen automatisch den formatierten HTML-Inhalt an.

import pandas as pd
import numpy as np
df = pd.DataFrame([[38.0, 2.0, 18.0, 22.0, 21, np.nan],[19, 439, 6, 452, 226,232]],
index=pd.Index(['Tumour (Positive)', 'Non-Tumour (Negative)'], name='Actual Label:'),
columns=pd.MultiIndex.from_product([['Decision Tree', 'Regression', 'Random'],['Tumour', 'Non-Tumour']], names=['Model:', 'Predicted:']))
df