Was ist Autotune für Apache Spark-Konfigurationen in Fabric?
Autotune passt automatisch die Apache Spark-Konfigurationen an, um die Ausführungszeit der Workload-Ausführung zu beschleunigen und die Leistung zu optimieren. Im Vergleich zur manuellen Optimierung, die viel Aufwand, Ressourcen, Zeit und Experimente erfordert, spart Autotune Zeit und Ressourcen. Autotune verwendet historische Ausführungsdaten Ihrer Workloads, um iterativ die effektivsten Konfigurationen für einen bestimmten Workload zu ermitteln und anzuwenden.
Hinweis
Das Autotune-Abfrage-Optimierungs-Feature in Microsoft Fabric befindet sich derzeit in der Vorschau. Autotune ist in allen Produktionsregionen verfügbar, ist aber standardmäßig deaktiviert. Sie können es über die Spark-Konfigurationseinstellung innerhalb der Umgebung oder innerhalb einer einzelnen Sitzung aktivieren, indem Sie die jeweilige Spark-Einstellung in Ihr Spark-Notizbuch oder den Spark-Auftragsdefinition-Code einschließen.
Abfrageoptimierung
Autotune konfiguriert für die einzelnen Abfragen jeweils drei Apache Spark-Einstellungen:
spark.sql.shuffle.partitions- Legt die Partitionsanzahl für die unsortierten Daten während Verknüpfungen oder Aggregationen fest. Der Standardwert ist 200.spark.sql.autoBroadcastJoinThreshold: - Legt die maximale Tabellengröße in Bytes fest, die bei der Ausführung der Join-Operation an alle Workerknoten gesendet wird. Der Standardwert ist 10 MB.spark.sql.files.maxPartitionBytes: Definiert die maximale Anzahl von Bytes, die beim Lesen von Dateien in eine einzelne Partition gepackt werden. Funktioniert für dateibasierte Parquet-, JSON- und ORC-Quellen. Der Standardwert ist 128 MB.
Tipp
Die Autotune-Abfrageoptimierung untersucht einzelne Abfragen und erstellt ein eigenes ML-Modell für jede Abfrage. Sie zielt speziell auf:
- Wiederholte Abfragen
- Lange laufende Abfragen (solche mit mehr als 15 Sekunden Ausführung)
- Apache Spark SQL-API-Abfragen (mit Ausnahme derjenigen, die in der RDD-API geschrieben wurden, die sehr selten sind), aber wir optimieren alle Abfragen unabhängig von der Sprache (Scala, PySpark, R, Spark SQL)
Dieses Feature ist mit Notebooks, Apache Spark Auftragsdefinitionen und Pipelines kompatibel. Die Vorteile hängen von der Komplexität der Abfrage, den verwendeten Methoden und der Struktur ab. Ausführliche Tests haben gezeigt, dass die größten Vorteile bei Abfragen im Zusammenhang mit der explorativen Datenanalyse erzielt werden, z. B. beim Lesen von Daten, bei der Ausführung von Joins, Aggregationen und Sortierungen.
KI-basierte Intuition hinter dem Autotune
Das Autotune-Feature verwendet einen iterativen Prozess, um die Abfrageleistung zu optimieren. Es beginnt mit einer Standardkonfiguration und verwendet ein Machine Learning-Modell, um die Effektivität zu bewerten. Wenn ein Benutzer eine Abfrage sendet, ruft das System die gespeicherten Modelle basierend auf den vorherigen Interaktionen ab. Es generiert potenzielle Konfigurationen um eine Standardeinstellung mit dem Namen Centroid. Der beste Kandidat, der vom Modell vorhergesagt wird, wird angewendet. Nach der Ausführung der Abfrage werden die Leistungsdaten zurück an das System gesendet, um das Modell zu verfeinern.
Die Feedbackschleife verschiebt den Schwerpunkt schrittweise in Richtung optimaler Einstellungen. Die Leistung wird im Laufe der Zeit optimiert, während das Risiko einer Regression minimiert wird. Kontinuierliche Updates basierend auf Benutzerabfragen ermöglichen die Einschränkung von Leistungs-Benchmarks. Darüber hinaus aktualisiert der Prozess die Centroid-Konfigurationen, um sicherzustellen, dass das Modell inkrementell zu effizienteren Einstellungen wechselt. Dies wird erreicht, indem frühere Leistungen bewertet und verwendet werden, um zukünftige Anpassungen zu leiten. Er verwendet alle Datenpunkte, um die Auswirkungen von Anomalien zu verringern.
Aus verantwortungsvoller KI-Perspektive umfasst das Autotune-Feature Transparenz-Mechanismen, die Sie über Ihre Datennutzung und Ihre Vorteile auf dem Laufenden halten sollen. Die Sicherheit und der Datenschutz entsprechen den Standards von Microsoft. Die kontinuierliche Überwachung gewährleistet die Leistung und Systemintegrität auch nach dem Start.
Aktivierung von Autotune
Autotune ist in allen Produktionsregionen verfügbar, ist aber standardmäßig deaktiviert. Sie können es über die Spark-Konfigurationseinstellung innerhalb der Umgebung aktivieren. Um Autotune zu aktivieren, erstellen Sie entweder eine neue Umgebung, oder legen Sie für die vorhandene Umgebung die Spark-Eigenschaft „spark.ms.autotune.enabled = true“ fest, wie im folgenden Screenshot gezeigt. Diese Einstellung wird dann an alle Notebooks und Aufträge, die in dieser Umgebung laufen, vererbt, so dass sie automatisch angepasst werden.

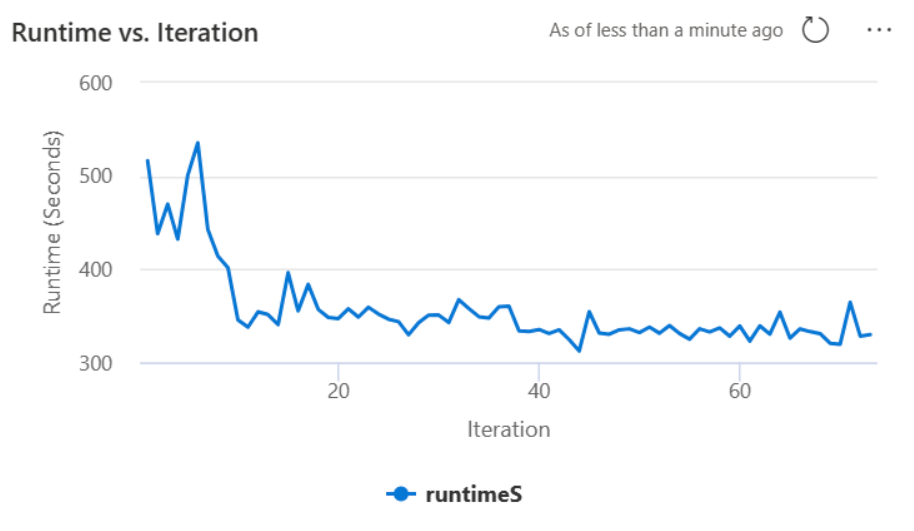
Autotune enthält einen eingebauten Mechanismus zur Leistungsüberwachung und zur Erkennung von Leistungsregressionen. Wenn eine Abfrage zum Beispiel eine ungewöhnlich große Datenmenge verarbeitet, wird Autotune automatisch deaktiviert. In der Regel sind 20 bis 25 Iterationen erforderlich, um die optimale Konfiguration zu erlernen und zu identifizieren.
Hinweis
Das Autotune ist mit Fabric Runtime 1.1 und Runtime 1.2 kompatibel. Autotune funktioniert nicht, wenn der Modus für hohe Parallelität oder der private Endpunkt aktiviert ist. Autotune lässt sich jedoch unabhängig von seiner Konfiguration nahtlos in die automatische Skalierung integrieren.
Sie können Autotune innerhalb einer einzelnen Sitzung aktivieren, indem Sie die jeweilige Spark-Einstellung in Ihr Spark-Notizbuch oder den Spark-Auftragsdefinition-Code einschließen.
%%sql
SET spark.ms.autotune.enabled=TRUE
Sie können Autotune über die Spark-Einstellungen für Ihr jeweiliges Spark-Notebook oder den Spark Auftragsdefinitions-Code steuern. Um Autotune zu deaktivieren, führen Sie die folgenden Befehle als erste Zelle (Notebook) oder Zeile des Codes (SJD) aus.
%%sql
SET spark.ms.autotune.enabled=FALSE
Fallstudie
Wenn Sie eine Apache Spark-Abfrage ausführen, erstellt Autotune ein angepasstes ML-Modell, das zur Optimierung der Ausführung der Abfrage dient. Es analysiert Abfragemuster und Ressourcenanforderungen. Erwägen Sie eine anfängliche Abfrage, die ein DataSet basierend auf einem bestimmten Attribut filtert, wie z. B. einem Land. Während in diesem Beispiel der geografische Filter verwendet wird, gilt das Prinzip universell für alle Attribute oder Vorgänge innerhalb der Abfrage:
%%pyspark
df.filter(df.country == "country-A")
Autotune lernt aus dieser Abfrage und optimiert nachfolgende Ausführungen. Wenn sich die Abfrage beispielsweise ändert, indem der Filterwert geändert oder eine andere Daten-Transformation angewendet wird, ist das strukturelle Wesen der Abfrage häufig wieder konsistent:
%%pyspark
df.filter(df.country == "country-B")
Trotz Änderungen identifiziert Autotune die grundlegende Struktur der neuen Abfrage, wobei zuvor gelernte Optimierungen implementiert werden. Diese Funktionalität stellt eine nachhaltige hohe Effizienz sicher, ohne dass für jede neue Abfrage-Iteration eine manuelle Neukonfiguration erforderlich ist.
Protokolle
Für jede Ihrer Abfragen bestimmt Autotune die optimalen Einstellungen für drei Spark-Konfigurationen. Sie können die vorgeschlagenen Einstellungen anzeigen, indem Sie zu den Protokollen navigieren. Die von Autotune empfohlenen Konfigurationen befinden sich in den Treiberprotokollen, insbesondere in den Einträgen, die mit [Autotune] beginnen.

Sie finden verschiedene Arten von Einträgen in Ihren Protokollen. Im Folgenden finden Sie die wichtigsten davon:
| Status | Beschreibung |
|---|---|
| AUTOTUNE_DISABLED | Übersprungen. Autotune ist deaktiviert und verhindert den Abruf von Telemetriedaten und die Optimierung von Abfragen. Aktivieren Sie Autotune, um ihre Funktionen vollständig zu nutzen, während sie den Datenschutz des Kunden respektieren.". |
| QUERY_TUNING_DISABLED | Übersprungen. Die Autotune-Abfrageoptimierung ist deaktiviert. Aktivieren Sie sie, um Einstellungen für Ihre Spark SQL-Abfragen zu optimieren. |
| QUERY_PATTERN_NOT_MATCH | Übersprungen. Abfragemuster stimmen nicht überein. Autotune ist für schreibgeschützte Abfragen wirksam. |
| QUERY_DURATION_TOO_SHORT | Übersprungen. Die Abfragedauer ist zu kurz, um sie zu optimieren. Autotune erfordert längere Abfragen für eine effektive Optimierung. Abfragen sollten mindestens 15 Sekunden lang ausgeführt werden. |
| QUERY_TUNING_SUCCEED | Erfolg. Die Abfrageoptimierung wurde abgeschlossen. Optimale Spark-Einstellungen angewendet. |
Transparenzhinweis
In Übereinstimmung mit dem verantwortungsvollen KI-Standard zielt dieser Abschnitt darauf ab, die Verwendung und Validierung des Autotune-Features zu klären, Transparenz zu fördern und fundierte Entscheidungsfindung zu ermöglichen.
Zweck von Autotune
Autotune wird entwickelt, um die Effizienz des Apache Spark-Workload zu verbessern, in erster Linie für Datenexperten. Zu den wichtigsten Funktionen gehören:
- Automatisierung der Apache Spark-Konfigurationsoptimierung, um die Ausführungszeiten zu reduzieren.
- Minimierung des manuellen Optimierungsaufwands.
- Verwendung von historischen Workload-Daten zum iterativen Verfeinern von Konfigurationen.
Validierung von Autotune
Autotune hat umfangreiche Tests durchlaufen, um die Wirksamkeit und Sicherheit zu gewährleisten:
- Strenge Tests mit verschiedenen Spark-Workloads zur Überprüfung der Effizienz des Optimierungsalgorithmus.
- Benchmarking mit standardmäßigen Spark-Optimierungsmethoden zur Veranschaulichung von Leistungsvorteilen.
- Praxisbezogene Fallstudien, die den praktischen Wert von Autotune hervorheben.
- Einhaltung strenger Sicherheits- und Datenschutzstandards zum Schutz von Benutzerdaten.
Benutzerdaten werden ausschließlich verwendet, um die Leistung Ihrer Workload mit robusten Schutzmaßnahmen zu verbessern, um Missbrauch oder Offenlegung vertraulicher Informationen zu verhindern.