Verwenden des erweiterten Apache Spark-Verlaufsservers zum Debuggen und Diagnostizieren von Apache Spark-Anwendungen
Dieser Artikel enthält Anleitungen zur Verwendung des erweiterten Apache Spark-Verlaufsservers zum Debuggen und Diagnostizieren abgeschlossener und aktiver Apache Spark-Anwendungen.
Zugreifen auf den Apache Spark-Verlaufsserver
Der Apache Spark-Verlaufsserver ist die Webbenutzeroberfläche für abgeschlossene und ausgeführte Spark-Anwendungen. Sie können die Apache Spark-Webbenutzeroberfläche (UI) über das Notebook zur Statusanzeige oder die Detailseite der Apache Spark-Anwendung öffnen.
Öffnen der Spark-Webbenutzeroberfläche über das Notebook zur Statusanzeige
Wenn ein Apache Spark-Auftrag ausgelöst wird, befindet sich die Schaltfläche zum Öffnen der Spark-Webbenutzeroberfläche in der Statusanzeige unter Weitere Aktionen. Wählen Sie Spark-Webbenutzeroberfläche aus, und warten Sie einige Sekunden. Dann wird die Seite „Spark-Benutzeroberfläche“ angezeigt.

Öffnen der Spark-Webbenutzeroberfläche über die Anwendungsdetailseite von Apache Spark
Die Spark-Webbenutzeroberfläche kann auch über die Anwendungsdetailseite von Apache Spark geöffnet werden. Wählen Sie links auf der Seite Überwachungshub und dann eine Apache Spark-Anwendung aus. Die Detailseite der Anwendung wird angezeigt.

Für eine Apache Spark-Anwendung, die derzeit ausgeführt wird, zeigt die Schaltfläche Spark-Benutzeroberfläche an. Wählen Sie Spark-Benutzeroberfläche aus, damit die Seite „Spark-Benutzeroberfläche“ geöffnet wird.

Für eine Apache Spark-Anwendung, deren Ausführung beendet ist, kann der Status Beendet, Fehler, Abgebrochen oder Abgeschlossen lauten. Die Schaltfläche zeigt Spark-Verlaufsserver an. Wählen Sie Spark-Verlaufsserver aus, damit die Seite „Spark-Benutzeroberfläche“ geöffnet wird.

Registerkarte „Graph“ im Apache Spark-Verlaufsserver
Wählen Sie die Auftrags-ID für den Auftrag aus, den Sie anzeigen möchten. Wählen Sie dann im Menü „Extras“ auf Graph aus, um die Auftragsdiagrammansicht aufzurufen.
Übersicht
Sie sehen eine Übersicht Ihres Auftrags in dem generierten Auftragsdiagramm. Standardmäßig werden in dem Diagramm alle Aufträge angezeigt. Sie können diese Ansicht anhand der Auftrags-ID filtern.

Anzeige
Standardmäßig ist die Anzeige Status ausgewählt. Sie können den Datenfluss überprüfen, indem Sie Read (Gelesen) oder Written (Geschrieben) in der Dropdownliste Anzeige auswählen.

In der Diagrammknotenanzeige werden die Farben gemäß der Legende des Wärmebilds angezeigt.

Wiedergabe
Wählen Sie Wiedergabe aus, um den Auftrag wiederzugeben. Sie können jederzeit Stopp auswählen, um die Wiedergabe zu beenden. Die Auftragsfarben zeigen bei der Wiedergabe verschiedene Status an:
| Color | Bedeutung |
|---|---|
| Grün | Succeeded (Erfolgreich): die abgeschlossen wurden. |
| Orange | Wiederholt: Instanzen fehlerhafter Aufgaben, die jedoch keine Auswirkungen auf das Endergebnis des Auftrags haben. Diese Aufträge enthielten doppelte oder wiederholte Instanzen, werden später aber möglicherweise erfolgreich ausgeführt. |
| Blau | Running (Wird ausgeführt): die gerade ausgeführt werden. |
| White | Wartend oder übersprungen: deren Ausführung noch ansteht oder bei denen eine Phase übersprungen wurde. |
| Red | Fehler: fehlgeschlagene Aufträge. |
In der folgenden Abbildung sind die Statusfarben Grün, Orange und Blau zu sehen.

In der folgenden Abbildung sind die Statusfarben Grün und Weiß zu sehen.

In der folgenden Abbildung sind die Statusfarben Rot und Grün zu sehen.

Hinweis
Der Apache Spark-Verlaufsserver ermöglicht die Wiedergabe für jeden abgeschlossenen Auftrag (jedoch nicht für unvollständige Aufträge).
Zoom
Scrollen Sie mit Ihrem Mausrad, um in das Auftragsdiagramm hinein- oder herauszuzoomen, oder wählen Sie Mit Zoom anpassen aus, um das Diagramm an die Anzeige anzupassen.

QuickInfos
Zeigen Sie mit der Maus auf den Diagrammknoten, um bei fehlgeschlagenen Aufträgen die QuickInfo anzuzeigen, und wählen Sie eine Phase aus, um die Seite zu dieser Phase zu öffnen.

Auf der Registerkarte „Auftragsdiagramm“ wird eine QuickInfo und ein kleines Symbol angezeigt, wenn es Aufträge gibt, die die folgenden Bedingungen erfüllen:
| Bedingung | Beschreibung |
|---|---|
| Datenschiefe | Größe der gelesenen Daten > durchschnittliche Größe der gelesenen Daten aller Aufträge innerhalb dieser Phase × 2 und Größe der gelesenen Daten > 10 MB |
| Zeitabweichung | Ausführungszeit > durchschnittliche Ausführungszeit aller Tasks in dieser Phase × 2 und Ausführungszeit > 2 Minuten |
![]()
Diagrammknotenbeschreibung
Der Auftragsdiagrammknoten zeigt die folgenden Informationen zu den einzelnen Phasen an:
- ID
- Name oder Beschreibung
- Anzahl der Aufgaben insgesamt
- Gelesene Daten: die Summe der Eingabegröße und der Shuffle-Lesegröße
- Geschriebene Daten: die Summe der Ausgabegröße und Größe der Shuffleschreibvorgänge
- Ausführungszeit: die Zeit zwischen der Startzeit des ersten Versuchs und der Endzeit des letzten Versuchs
- Zeilenanzahl: die Summe der Eingabe- und Ausgabedatensätze sowie die Datensätze der Shufflelese- und -schreibvorgänge
- Status
Hinweis
Standardmäßig zeigt der Auftragsdiagrammknoten Informationen zum letzten Versuch der einzelnen Phasen an (mit Ausnahme der Phase „Ausführungszeit“). Während der Wiedergabe zeigt der Diagrammknoten jedoch Informationen zu jedem Versuch an.
Für die Datengröße des Lese-und Schreibvorgangs gilt: 1 MB = 1000 KB = 1000 × 1000 Bytes.
Feedback geben
Senden Sie Feedback mit Problemen, indem Sie Provide us feedback (Feedback abgeben) auswählen.

Beschränkung der Phasenanzahl
Aus Leistungsgründen ist das Diagramm standardmäßig nur verfügbar, wenn die Spark-Anwendung weniger als 500 Phasen aufweist. Wenn zu viele Phasen vorhanden sind, tritt ein Fehler wie dieser auf:
The number of stages in this application exceeds limit (500), graph page is disabled in this case.
Wenden Sie als Problemumgehung vor dem Starten einer Spark-Anwendung diese Spark-Konfiguration an, um den Grenzwert zu erhöhen:
spark.ui.enhancement.maxGraphStages 1000
Beachten Sie jedoch, dass dies zu einer schlechten Leistung der Seite und der API führen kann, weil der Inhalt so groß sein kann, dass er vom Browser nicht abgerufen und gerendert werden kann.
Erkunden der Registerkarte „Diagnose“ im Apache Spark-Verlaufsserver
Um auf die Registerkarte Diagnose zuzugreifen, wählen Sie eine Auftrags-ID aus. Wählen Sie dann im Menü „Extras“ Diagnose aus, um die Auftragsdiagnoseansicht aufzurufen. Die Registerkarte „Diagnosis“ (Diagnose) umfasst die folgenden weiteren Registerkarten: Data Skew (Datenschiefe), Time Skew (Zeitabweichung) und Executor Usage Analysis (Analyse zur Executorauslastung).
Überprüfen Sie die Datenschiefe, Zeitabweichung und Executor-Nutzungsanalyse, indem Sie die entsprechenden Registerkarten auswählen.

Datenschiefe
Wenn Sie die Registerkarte Datenschiefe auswählen, werden die entsprechenden Aufgaben mit Abweichungen basierend auf den angegebenen Parametern angezeigt.
Parameter festlegen: Im ersten Abschnitt werden die Parameter angezeigt, die zum Erkennen von Datenschiefe verwendet werden. Standardregel: Die gelesenen Taskdaten sind dreimal so groß wie die durchschnittlichen gelesenen Taskdaten, und die gelesenen Taskdaten sind größer als 10 MB. Wenn Sie Ihre eigene Regel für Aufgaben mit Abweichungen definieren möchten, können Sie die Parameter selbst festlegen. Die Abschnitte Schiefe Phase und Skew Chart (Diagramm zur Datenschiefe) werden entsprechend aktualisiert.
Phase mit Datenschiefe: Im zweiten Abschnitt werden die Phasen angezeigt, die Tasks mit Abweichungen entsprechend den oben angegebenen Kriterien enthalten. Wenn in einer Phase mehrere Tasks mit Abweichungen vorhanden sind, wird in der Tabelle der schiefen Phasen nur der Task mit der größten Abweichung angezeigt (z. B. mit dem größten Wert der Datenschiefe).
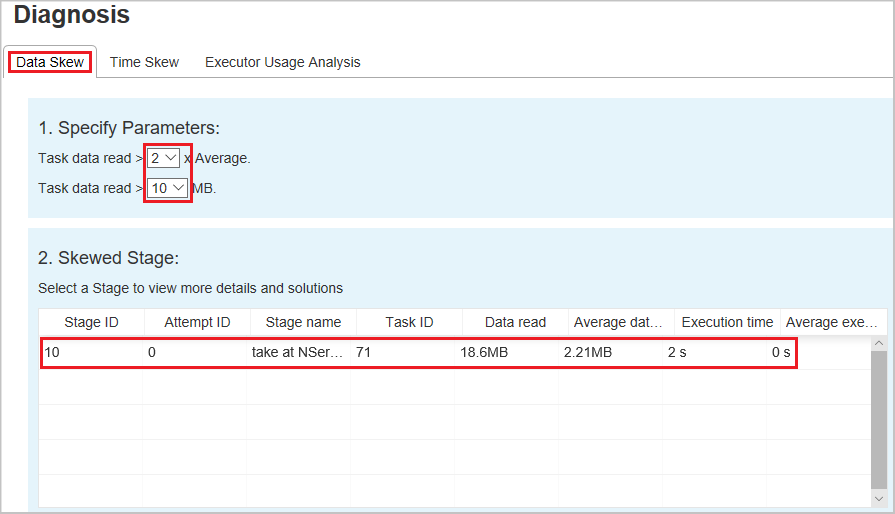
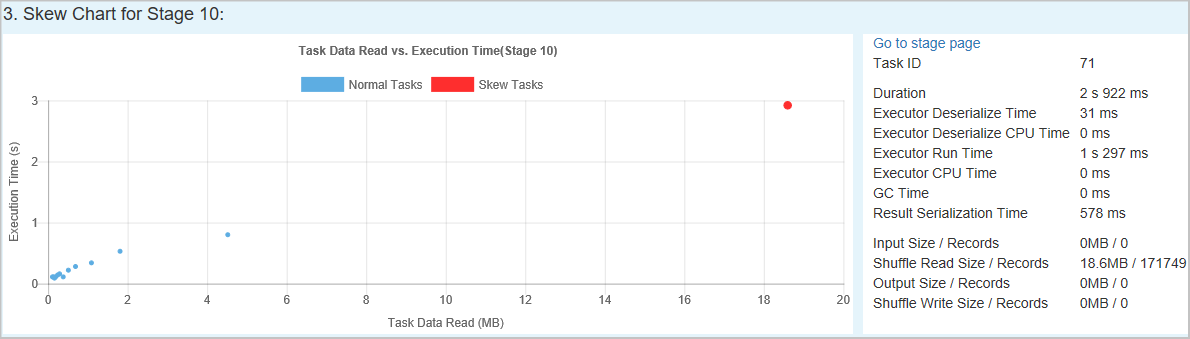
Diagramm zur Datenschiefe: Wenn eine Zeile in der Tabelle zu den Phasen mit Datenschiefe ausgewählt ist, werden im Diagramm zur Datenschiefe basierend auf den gelesenen Daten und der Ausführungszeit weitere Details zur Taskverteilung angezeigt. Die schiefen Aufträge sind rot und die normalen Aufträge sind blau markiert. In dem Diagramm werden bis zu 100 Beispielaufgaben angezeigt, außerdem werden die Aufgabendetails im unteren Bereich auf der rechten Seite angezeigt.


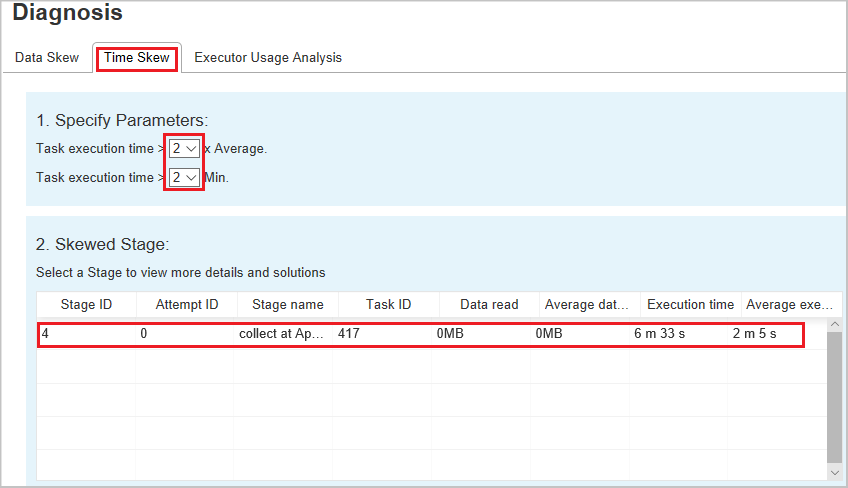
Zeitabweichung
Auf der Registerkarte Time Skew (Zeitabweichung) werden schiefe Aufträge basierend auf ihrer Ausführungszeit angezeigt.
Parameter festlegen: Im ersten Abschnitt werden die Parameter angezeigt, die zum Erkennen der Zeitabweichung verwendet werden. Die Standardkriterien zum Erkennen von Zeitabweichungen sind: Ausführungszeit der Aufgabe > 3-mal durchschnittliche Ausführungszeit und Ausführungszeit der Aufgabe > 30 Sekunden. Sie können die Parameter Ihren Anforderungen entsprechend anpassen. Unter Phase mit Datenschiefe und Diagramm zur Datenschiefe werden wie auf der obenstehenden Registerkarte Datenschiefe die Informationen zu den einzelnen Phasen und Aufträgen angezeigt.
Wenn Sie Zeitabweichung auswählen, wird das gefilterte Ergebnis im Abschnitt Schiefe Phase entsprechend den im Abschnitt Parameter festlegen angegebenen Parametern angezeigt. Wenn Sie ein Element im Abschnitt Phase mit Datenschiefe auswählen, wird das entsprechende Diagramm in Abschnitt 3 entworfen, und die Taskdetails werden im rechten unteren Bereich angezeigt.

Analyse zur Executorauslastung
Diese Funktion wurde in Fabric jetzt eingestellt. Wenn Sie dies dennoch als Problemumgehung verwenden möchten, greifen Sie bitte auf die Seite zu, indem Sie in der URL hinter dem Pfad „/diagnostic“ explizit „/executorusage“ hinzufügen, etwa so:
