Leistungsüberlegungen für EF 4, 5 und 6
Von David Obando, Eric Dettinger und anderen
Veröffentlichung: April 2012
Letzte Aktualisierung: Mai 2014
1. Einführung
Objekt-Relationale Zuordnungsframeworks sind eine bequeme Möglichkeit, eine Abstraktion für den Datenzugriff in einer objektorientierten Anwendung bereitzustellen. Für .NET-Anwendungen ist Entity Framework das von Microsoft empfohlene O/RM. Bei jeder Abstraktion kann jedoch die Leistung ein Problem werden.
Dieses Whitepaper wurde geschrieben, um die Leistungsüberlegungen beim Entwickeln von Anwendungen mithilfe von Entity Framework zu zeigen, um Entwicklern eine Vorstellung von den internen Algorithmen von Entity Framework zu geben, welche sich auf die Leistung auswirken können, und Tipps zur Untersuchung und Verbesserung der Leistung in ihren Anwendungen bereitzustellen, die Entity Framework verwenden. Es gibt bereits eine Reihe guter Themen zum Thema Leistung, die im Web verfügbar sind, und wir haben auch versucht, nach Möglichkeit auf diese Ressourcen hinzuweisen.
Die Leistung ist ein heikles Thema. Dieses Whitepaper ist als Ressource gedacht, die Ihnen helfen soll, leistungsbezogene Entscheidungen für Ihre Anwendungen zu treffen, die Entity Framework verwenden. Wir haben einige Testmetriken zum Veranschaulichen der Leistung eingeschlossen, aber diese Metriken sind nicht als absolute Indikatoren für die Leistung gedacht, die Sie in Ihrer Anwendung sehen werden.
Für praktische Zwecke wird in diesem Dokument davon ausgegangen, dass Entity Framework 4 unter .NET 4.0 und Entity Framework 5 und 6 unter .NET 4.5 ausgeführt werden. Viele der Leistungsverbesserungen für Entity Framework 5 befinden sich innerhalb der Kernkomponenten, die mit .NET 4.5 ausgeliefert werden.
Entity Framework 6 ist eine Out-of-Band-Version und hängt nicht von den Entity Framework-Komponenten ab, die mit .NET ausgeliefert werden. Entity Framework 6 funktioniert sowohl mit .NET 4.0 als auch mit .NET 4.5 und bietet einen großen Leistungsvorteil für diejenigen, die kein Upgrade von .NET 4.0 durchgeführt haben, aber die neuesten Entity Framework-Teile in ihrer Anwendung benötigen. Wenn dieses Dokument Entity Framework 6 erwähnt, bezieht es sich auf die neueste Version, die zum Zeitpunkt der Erstellung dieses Dokuments verfügbar war: Version 6.1.0.
2. Kalte vs. Warme Abfrageausführung
Wenn eine Abfrage zum allerersten Mal für ein bestimmtes Modell ausgeführt wird, leistet das Entity Framework im Hintergrund eine Menge Arbeit, um das Modell zu laden und zu überprüfen. Diese erste Abfrage wird häufig als eine „kalte“ Abfrage bezeichnet. Weitere Abfragen für bereits geladene Modelle werden als „warme“ Abfragen bezeichnet und sind viel schneller.
Lassen Sie uns einen Überblick darüber gewinnen, wo Zeit bei der Ausführung einer Abfrage mit Entity Framework verwendet wird, und sehen, wo sich die Dinge in Entity Framework 6 verbessern.
Erste Abfrageausführung – kalte Abfrage
| Vom Benutzer geschriebener Code | Aktion | EF4-Leistungsauswirkung | EF5-Leistungsauswirkung | EF6-Leistungsauswirkung |
|---|---|---|---|---|
using(var db = new MyContext()) { |
Erstellen von Kontext | Mittel | Medium | Niedrig |
var q1 = from c in db.Customers where c.Id == id1 select c; |
Erstellen eines Abfrageausdrucks | Niedrig | Niedrig | Niedrig |
var c1 = q1.First(); |
LINQ-Abfrageausführung | – Laden von Metadaten: Hoch, aber zwischengespeichert – Ansichtsgenerierung: Potenziell sehr hoch, aber zwischengespeichert – Parameterauswertung: Mittel – Abfrageübersetzung: Mittel – Materialisierer-Generierung: Mittel, aber zwischengespeichert – Ausführung von Datenbankabfragen: Potenziell hoch + Connection.Open + Command.ExecuteReader + DataReader.Read Objektmaterialisierung: Mittel – Identitätssuche: Mittel |
– Laden von Metadaten: Hoch, aber zwischengespeichert – Ansichtsgenerierung: Potenziell sehr hoch, aber zwischengespeichert – Parameterauswertung: Niedrig – Abfrageübersetzung: Mittel, aber zwischengespeichert – Materialisierer-Generierung: Mittel, aber zwischengespeichert – Ausführung von Datenbankabfragen: Potenziell hoch (bessere Abfragen in einigen Situationen) + Connection.Open + Command.ExecuteReader + DataReader.Read Objektmaterialisierung: Mittel – Identitätssuche: Mittel |
– Laden von Metadaten: Hoch, aber zwischengespeichert – Ansichtsgenerierung: Mittel, aber zwischengespeichert – Parameterauswertung: Niedrig – Abfrageübersetzung: Mittel, aber zwischengespeichert – Materialisierer-Generierung: Mittel, aber zwischengespeichert – Ausführung von Datenbankabfragen: Potenziell hoch (bessere Abfragen in einigen Situationen) + Connection.Open + Command.ExecuteReader + DataReader.Read Objektmaterialisierung: Mittel (Schneller als EF5) – Identitätssuche: Mittel |
} |
Connection.Close | Niedrig | Niedrig | Niedrig |
Zweite Abfrageausführung – warme Abfrage
| Vom Benutzer geschriebener Code | Aktion | EF4-Leistungsauswirkung | EF5-Leistungsauswirkung | EF6-Leistungsauswirkung |
|---|---|---|---|---|
using(var db = new MyContext()) { |
Erstellen von Kontext | Mittel | Medium | Niedrig |
var q1 = from c in db.Customers where c.Id == id1 select c; |
Erstellen eines Abfrageausdrucks | Niedrig | Niedrig | Niedrig |
var c1 = q1.First(); |
LINQ-Abfrageausführung | – Metadaten- – Ansichts- – Parameterauswertung: Mittel – Abfrage- – Materialisierer- – Ausführung von Datenbankabfragen: Potenziell hoch + Connection.Open + Command.ExecuteReader + DataReader.Read Objektmaterialisierung: Mittel – Identitätssuche: Mittel |
– Metadaten- – Ansichts- – Parameterauswertung: Niedrig – Abfrage- – Materialisierer- – Ausführung von Datenbankabfragen: Potenziell hoch (bessere Abfragen in einigen Situationen) + Connection.Open + Command.ExecuteReader + DataReader.Read Objektmaterialisierung: Mittel – Identitätssuche: Mittel |
– Metadaten- – Ansichts- – Parameterauswertung: Niedrig – Abfrage- – Materialisierer- – Ausführung von Datenbankabfragen: Potenziell hoch (bessere Abfragen in einigen Situationen) + Connection.Open + Command.ExecuteReader + DataReader.Read Objektmaterialisierung: Mittel (Schneller als EF5) – Identitätssuche: Mittel |
} |
Connection.Close | Niedrig | Niedrig | Niedrig |
Es gibt mehrere Möglichkeiten, die Leistungskosten sowohl von kalten als auch warmen Abfragen zu reduzieren, und wir sehen uns diese im folgenden Abschnitt an. Insbesondere werden wir uns mit der Verringerung der Kosten für das Laden von Modellen in kalten Abfragen befassen, indem wir vorgenerierte Ansichten verwenden, was dazu beitragen sollte, die Leistungsprobleme bei der Ansichtsgenerierung zu verringern. Bei warmen Abfragen werden wir das Zwischenspeichern von Abfrageplänen, Abfragen ohne Nachverfolgung und verschiedene Abfrageausführungsoptionen behandeln.
2.1 Was ist die Ansichtsgenerierung?
Um zu verstehen, was die Ansichtsgenerierung ist, müssen wir zunächst verstehen, was „Zuordnungsansichten“ sind. Zuordnungsansichten sind ausführbare Darstellungen der Transformationen, die in der Zuordnung für jede Entitätenmenge und jede Zuordnung angegeben sind. Intern nehmen diese Zuordnungsansichten die Form von CQTs (Canonical Query Trees, kanonische Abfragestrukturen) ein. Es gibt zwei Arten von Zuordnungsansichten:
- Abfrageansichten: Diese stellen die Transformation dar, die erforderlich ist, um vom Datenbankschema zum konzeptionellen Modell zu gelangen.
- Aktualisierungsansichten: Diese stellen die Transformation dar, die erforderlich ist, um vom konzeptionellen Modell zum Datenbankschema zu gelangen.
Beachten Sie, dass sich das konzeptionelle Modell auf verschiedene Weise vom Datenbankschema unterscheiden kann. So kann beispielsweise eine einzige Tabelle verwendet werden, um die Daten für zwei verschiedene Entitätstypen zu speichern. Vererbung und nicht-triviale Zuordnungen spielen eine Rolle bei der Komplexität der Zuordnungsansichten.
Der Prozess der Berechnung dieser Ansichten auf der Grundlage der Spezifikation der Zuordnung ist das, was wir als „Ansichtsgenerierung“ bezeichnen. Die Ansichtsgenerierung kann entweder dynamisch beim Laden eines Modells erfolgen, oder zur Erstellungszeit mithilfe von „vorgenerierten Ansichten". Letztere werden in Form von Entity SQL-Anweisungen in eine C#- oder VB-Datei serialisiert.
Wenn Ansichten generiert werden, werden sie ebenfalls überprüft. Vom Leistungsstandpunkt aus gesehen liegt der größte Teil der Kosten für die Ansichtsgenerierung tatsächlich in der Überprüfung der Ansichten, was sicherstellt, dass die Verbindungen zwischen den Entitäten sinnvoll sind und die richtige Kardinalität für alle unterstützten Vorgänge haben.
Wenn eine Abfrage über eine Entitätenmenge ausgeführt wird, wird die Abfrage mit der entsprechenden Abfrageansicht kombiniert, und das Ergebnis dieser Komposition durchläuft den Plancompiler, um die Darstellung der Abfrage zu erstellen, die der Sicherungsspeicher verstehen kann. Für SQL Server ist das endgültige Ergebnis dieser Kompilierung eine T-SQL SELECT-Anweisung. Bei der ersten Aktualisierung einer Entitätenmenge durchläuft die Aktualisierungsansicht einen ähnlichen Prozess, um sie in DML-Anweisungen für die Zieldatenbank umzuwandeln.
2.2 Faktoren, welche die Leistung der Ansichtsgenerierung beeinflussen
Die Leistung des Schrittes zur Ansichtsgenerierung hängt nicht nur von der Größe Ihres Modells ab, sondern auch davon, wie vernetzt das Modell ist. Wenn zwei Entitäten über eine Vererbungskette oder eine Zuordnung verbunden sind, werden sie als „verbunden“ bezeichnet. Wenn zwei Tabellen über einen Fremdschlüssel verbunden sind, gelten sie ebenfalls als „verbunden“. Wenn sich die Anzahl der verbundenen Entitäten und Tabellen in Ihren Schemas erhöht, erhöht sich die Kosten der Ansichtsgenerierung.
Der Algorithmus, den wir zum Generieren und Überprüfen von Ansichten verwenden, ist im schlimmsten Fall exponentiell, obwohl wir einige Optimierungen verwenden, um dies zu verbessern. Die wichtigsten Faktoren, die sich negativ auf die Leistung auswirken, sind Folgende:
- Die Modellgröße, die sich auf die Anzahl der Entitäten und die Menge der Zuordnungen zwischen diesen Entitäten bezieht.
- Die Modellkomplexität, insbesondere die Vererbung mit einer großen Anzahl von Typen.
- Das Verwenden von unabhängigen Zuordnungen anstelle von Fremdschlüsselzuordnungen.
Für kleine, einfache Modelle sind die Kosten möglicherweise klein genug, um sich nicht mit vorgenerierten Modellen befassen zu müssen. Wenn sich die Größe und die Komplexität eines Modells erhöhen, stehen mehrere Optionen zur Verfügung, um die Kosten für die Generierung und Überprüfung der Ansichten zu reduzieren.
2.3 Verwenden von vorgenerierten Ansichten zum Verringern der Modellladezeit
Ausführliche Informationen zur Verwendung von vorgenerierten Ansichten in Entity Framework 6 finden Sie unter Vorgenerierte Zuordnungsansichten
2.3.1 Vorgenerierte Ansichten mit der Power Tools-Communityedition von Entity Framework
Sie können die Power Tools-Communityedition von Entity Framework 6 verwenden, um Ansichten von EDMX- und Code First-Modellen zu generieren, indem Sie mit der rechten Maustaste auf die Modellklassendatei klicken und das Entity Framework-Menü verwenden, um „Ansichten generieren“ auszuwählen. Die Power Tools-Communityedition von Entity Framework funktioniert nur für von DbContext abgeleitete Kontexte.
2.3.2 Verwenden von vorgenerierten Ansichten mit einem Modell, das von EDMGen erstellt wurde
EDMGen ist ein Hilfsprogramm, das mit .NET ausgeliefert wird und mit Entity Framework 4 und 5 funktioniert, aber nicht mit Entity Framework 6. Mit EDMGen können Sie eine Modelldatei, die Objektebene und die Ansichten über die Befehlszeile generieren. Eine der Ausgaben wird eine „Ansichten“-Datei in Ihrer gewünschten Sprache sein, VB oder C#. Dies ist eine Codedatei mit Entity SQL-Codeschnipseln für jede Entitätenmenge. Um vorgenerierte Ansichten zu aktivieren, fügen Sie einfach die Datei in Ihr Projekt ein.
Wenn Sie die Schemadateien für das Modell manuell bearbeiten, müssen Sie die Ansichtendatei erneut generieren. Dazu können Sie EDMGen mit dem Flag /mode:ViewGeneration ausführen.
2.3.3 Verwenden von vorgenerierten Ansichten mit einer EDMX-Datei
Sie können auch EDMGen verwenden, um Ansichten für eine EDMX-Datei zu generieren – in dem bereits erwähnten MSDN-Thema wird beschrieben, wie man ein Vorabbuildereignis hinzufügt, um dies zu tun – aber dies ist kompliziert und es gibt einige Fälle, in denen dies nicht möglich ist. Im Allgemeinen ist es einfacher, eine T4-Vorlage zu verwenden, um die Ansichten zu generieren, wenn sich Ihr Modell in einer EDMX-Datei befindet.
Der ADO.NET-Teamblog enthält einen Beitrag, der beschreibt, wie eine T4-Vorlage für die Ansichtsgenerierung ( <https://learn.microsoft.com/archive/blogs/adonet/how-to-use-a-t4-template-for-view-generation>) verwendet wird. Dieser Beitrag enthält eine Vorlage, die heruntergeladen und Ihrem Projekt hinzugefügt werden kann. Die Vorlage wurde für die erste Version von Entity Framework geschrieben, so dass nicht garantiert werden kann, dass sie mit den neuesten Versionen von Entity Framework funktioniert. Sie können jedoch einen aktuelleren Satz von Vorlagen für die Ansichtsgenerierung für Entity Framework 4 und 5 aus dem Visual Studio-Katalog herunterladen:
- VB.NET: <http://visualstudiogallery.msdn.microsoft.com/118b44f2-1b91-4de2-a584-7a680418941d>
- C#: <http://visualstudiogallery.msdn.microsoft.com/ae7730ce-ddab-470f-8456-1b313cd2c44d>
Wenn Sie Entity Framework 6 verwenden, können Sie die T4-Vorlagen für die Ansichtsgenerierung aus dem Visual Studio-Katalog unter <http://visualstudiogallery.msdn.microsoft.com/18a7db90-6705-4d19-9dd1-0a6c23d0751f> abrufen.
2.4 Reduzierung der Kosten der Ansichtsgenerierung
Durch die Verwendung von vorgenerierten Ansichten werden die Kosten der Ansichtsgenerierung von der Modellladezeit (Laufzeit) in die Entwurfszeit verschoben. Dies verbessert zwar die Startleistung zur Laufzeit, aber Sie werden immer noch die Probleme der Ansichtsgenerierung während der Entwicklung erleben. Es gibt mehrere zusätzliche Tricks, mit denen die Kosten der Ansichtsgenerierung sowohl zur Kompilierzeit als auch zur Laufzeit reduziert werden können.
2.4.1 Verwendung von Fremdschlüsselzuordnungen zur Reduzierung der Kosten für die Generierung von Ansichten
Wir haben eine Reihe von Fällen gesehen, in denen der Wechsel der Zuordnungen im Modell von der unabhängigen Zuordnung zur Fremdschlüsselzuordnung die Zeit für die Generierung von Ansichten drastisch verkürzt hat.
Um diese Verbesserung zu veranschaulichen, haben wir zwei Versionen des Navision-Modells mithilfe von EDMGen generiert. Hinweis: Eine Beschreibung des Navision-Modells finden Sie in Anhang C. Das Navision-Modell ist für diese Übung interessant, da es eine sehr große Anzahl von Entitäten und Beziehungen zwischen ihnen enthält.
Eine Version dieses sehr großen Modells wurde mit Fremdschlüsselzuordnungen generiert, und die andere wurde mit unabhängigen Zuordnungen generiert. Dann haben wir gemessen, wie lange die Generierung der Ansichten für jedes Modell dauerte. Der Entity Framework 5-Test hat die GenerateViews()-Methode aus der Klasse EntityViewGenerator verwendet, um die Ansichten zu generieren, während der Entity Framework 6-Test die GenerateViews()-Methode aus der Klasse StorageMappingItemCollection verwendet hat. Dies aufgrund von Codeumstrukturierungen, die in der Entity Framework 6-Codebasis vorgenommen wurden.
Bei Verwendung von Entity Framework 5 dauerte die Ansichtsgenerierung für das Modell mit Fremdschlüsseln 65 Minuten auf einem Laborcomputer. Es ist unbekannt, wie lange es gedauert hätte, um die Ansichten für das Modell zu generieren, das unabhängige Zuordnungen verwendete. Wir ließen den Test über einen Monat lang laufen, bevor der Computer in unserem Labor neu gestartet wurde, um monatliche Updates zu installieren.
Bei Verwendung von Entity Framework 6 dauerte die Ansichtsgenerierung für das Modell mit Fremdschlüsseln 28 Sekunden auf dem gleichen Laborcomputer. Die Ansichtsgenerierung für das Modell, das unabhängige Zuordnungen verwendet, dauerte 58 Sekunden. Die in Entity Framework 6 vorgenommenen Verbesserungen am Code zur Generierung von Ansichten bedeuten, dass viele Projekte keine vorgenerierten Ansichten benötigen, um schnellere Startzeiten zu erreichen.
Es ist wichtig zu beachten, dass das Vorgenerieren von Ansichten in Entity Framework 4 und 5 mit EDMGen oder den Entity Framework-Power Tools erfolgen kann. Für Entity Framework 6 kann die Ansichtsgenerierung über die Entity Framework-Power Tools oder programmgesteuert erfolgen, wie in vorgenerierte Zuordnungsansichtenbeschrieben.
2.4.1.1 Verwendung von Fremdschlüsseln anstelle unabhängiger Zuordnungen
Wenn Sie EDMGen oder den Entity Designer in Visual Studio verwenden, erhalten Sie standardmäßig Fremdschlüssel,und es ist nur ein einziges Kontrollkästchen oder ein Flag in der Befehlszeile erforderlich, um zwischen Fremdschlüsseln und unabhängigen Zuordnungen zu wechseln.
Wenn Sie über ein großes Code First-Modell verfügen, hat die Verwendung unabhängiger Zuordnungen dieselbe Auswirkung auf die Ansichtsgenerierung. Sie können diese Auswirkungen vermeiden, indem Sie Fremdschlüsseleigenschaften für die Klassen für ihre abhängigen Objekte einschließen, obwohl einige Entwickler dies als Verunreinigung ihres Objektmodell betrachten. Weitere Informationen zu diesem Thema finden Sie unter <http://blog.oneunicorn.com/2011/12/11/whats-the-deal-with-mapping-foreign-keys-using-the-entity-framework/>.
| Bei Verwendung von | Aktion |
|---|---|
| Entity Designer | Stellen Sie nach dem Hinzufügen einer Zuordnung zwischen zwei Entitäten sicher, dass Sie über eine referenzielle Einschränkung verfügen. Referentielle Einschränkungen weisen Entity Framework an, Fremdschlüssel anstelle von unabhängigen Zuordnungen zu verwenden. Weitere Details finden Sie unter <https://learn.microsoft.com/archive/blogs/efdesign/foreign-keys-in-the-entity-framework>. |
| EDMGen | Wenn Sie EDMGen verwenden, um Ihre Dateien aus der Datenbank zu generieren, werden Ihre Fremdschlüssel beachtet und dem Modell als solche hinzugefügt. Weitere Informationen zu den verschiedenen Optionen, die von EDMGen verfügbar gemacht werden, finden Sie unter http://msdn.microsoft.com/library/bb387165.aspx. |
| Code First | Im Abschnitt „Beziehungskonvention“ des Themas Code First-Konventionen finden Sie Informationen dazu, wie Fremdschlüsseleigenschaften für abhängige Objekte bei Verwendung von Code First eingeschlossen werden. |
2.4.2 Verschieben des Modells auf eine separate Assembly
Wenn Ihr Modell direkt im Projekt Ihrer Anwendung enthalten ist und Sie Ansichten über ein Vorabbuildereignis oder eine T4-Vorlage generieren, wird die Generierung und Überprüfung der Ansicht dann erfolgen, wenn das Projekt neu erstellt wird, auch wenn das Modell nicht geändert wurde. Wenn Sie das Modell in eine separate Assembly verschieben und es vom Projekt der Anwendung referenzieren, können Sie andere Änderungen an Ihrer Anwendung vornehmen, ohne das Projekt, welches das Modell enthält, neu erstellen zu müssen.
Hinweis: Beim Verschieben Ihres Modells in separate Assemblys denken Sie daran, die Verbindungszeichenfolgen für das Modell in die Anwendungskonfigurationsdatei des Clientprojekts zu kopieren.
2.4.3 Deaktivieren der Überprüfung eines EDMX-basierten Modells
EDMX-Modelle werden zur Kompilierzeit überprüft, auch wenn das Modell unverändert ist. Wenn Ihr Modell bereits überprüft wurde, können Sie die Überprüfung zur Kompilierzeit unterdrücken, indem Sie die Eigenschaft „Beim Build überprüfen“ im Eigenschaftenfenster auf FALSCH festlegen. Wenn Sie Ihre Zuordnung oder Ihr Modell ändern, können Sie die Überprüfung vorübergehend erneut aktivieren, um Ihre Änderungen zu überprüfen.
Beachten Sie, dass die Leistungsverbesserungen am Entity Framework-Designer für Entity Framework 6 vorgenommen wurden, und die Kosten für „Beim Build überprüfen“ viel niedriger sind als in früheren Versionen des Designers.
3 Zwischenspeichern im Entity Framework
Entity Framework verfügt über die folgenden Formen des integrierten Zwischenspeicherns:
- Objektzwischenspeichern – der in eine ObjectContext-Instanz integrierte ObjectStateManager verfolgt den Arbeitsspeicher der Objekte, die mithilfe dieser Instanz abgerufen wurden. Dies wird auch als Cache der ersten Ebene bezeichnet.
- Zwischenspeichern des Abfrageplans – Erneutes Verwenden des generierten Speicherbefehls, wenn eine Abfrage mehr als einmal ausgeführt wird.
- Zwischenspeichern von Metadaten – Freigeben der Metadaten für ein Modell über verschiedene Verbindungen mit demselben Model.
Neben den Caches, die EF sofort bereitstellt, kann auch eine spezielle Art von ADO.NET-Datenanbieter, der als Umbruchanbieter bezeichnet wird, verwendet werden, um Entity Framework mit einem Cache für die Ergebnisse zu erweitern, die aus der Datenbank abgerufen wurden, auch als Zwischenspeichern auf zweiter Ebene bezeichnet.
3.1 Objektzwischenspeichern
Wenn eine Entität in den Ergebnissen einer Abfrage zurückgegeben wird, überprüft der ObjectContext standardmäßig, ob eine Entität mit demselben Schlüssel bereits in den ObjectStateManager geladen wurde, kurz bevor EF sie materialisiert. Wenn eine Entität mit den gleichen Schlüsseln bereits vorhanden ist, wird EF sie in die Ergebnisse der Abfrage aufnehmen. Obwohl EF immer noch die Abfrage an die Datenbank stellt, kann durch dieses Verhalten ein Großteil der Kosten für die mehrfache Materialisierung der Entität umgangen werden.
3.1.1 Abrufen von Entitäten aus dem Objektcache mithilfe der DbContext Find
Im Gegensatz zu einer regulären Abfrage führt die Find-Methode in DbSet (APIs, die zum ersten Mal in EF 4.1 enthalten sind) eine Suche im Arbeitsspeicher aus, noch bevor die Abfrage für die Datenbank gestellt wird. Es ist wichtig zu beachten, dass zwei verschiedene ObjectContext-Instanzen zwei verschiedene ObjectStateManager-Instanzen haben werden, was bedeutet, dass sie separate Objektcaches haben.
Find verwendet den Primärschlüsselwert beim Versuch, eine Entität zu finden, die vom Kontext nachverfolgt wird. Wenn sich die Entität nicht im Kontext befindet, wird eine Abfrage für die Datenbank ausgeführt und ausgewertet, und NULL wird zurückgegeben, wenn die Entität nicht im Kontext oder in der Datenbank gefunden wird. Beachten Sie, dass Find auch Entitäten zurückgibt, die zum Kontext hinzugefügt, jedoch noch nicht in der Datenbank gespeichert wurden.
Bei der Verwendung von Find ist eine Leistungsüberlegung zu berücksichtigen. Aufrufe an diese Methode lösen standardmäßig eine Überprüfung des Objektcaches aus, um Änderungen zu erkennen, die noch einen ausstehenden Commit zur Datenbank haben. Dieser Vorgang kann sehr teuer sein, wenn es eine sehr große Anzahl von Objekten im Objektcache gibt, oder in einem großen Objektgraph, der dem Objektcache hinzugefügt wird, aber der Vorgang kann auch deaktiviert werden. In bestimmten Fällen können Sie beim Aufrufen der Find-Methode einen Unterschied von mehr als einer Größenordnung wahrnehmen, wenn Sie die automatische Erkennung von Änderungen deaktivieren. Eine zweite Größenordnung wird jedoch wahrgenommen, wenn sich das Objekt tatsächlich im Cache befindet, im Vergleich mit dem Zeitpunkt, wenn das Objekt aus der Datenbank abgerufen werden muss. Hier ist ein Beispielgraph mit Messungen, die mit einigen unserer Mikrobenchmarks durchgeführt wurden, ausgedrückt in Millisekunden, mit einer Last von 5000 Entitäten:

Beispiel für Find mit deaktivierter automatischer Erkennung von Änderungen:
context.Configuration.AutoDetectChangesEnabled = false;
var product = context.Products.Find(productId);
context.Configuration.AutoDetectChangesEnabled = true;
...
Was Sie bei der Verwendung der Find-Methode berücksichtigen müssen, ist Folgendes:
- Wenn sich das Objekt nicht im Cache befindet, werden die Nutzen von Find negiert, aber die Syntax ist immer noch einfacher als eine Abfrage nach Schlüssel.
- Wenn die automatischen Erkennung von Änderungen aktiviert ist, können die Kosten der Find-Methode um eine Größenordnung oder sogar mehr erhöht werden, je nach Komplexität Ihres Modells und der Anzahl der Entitäten im Objektcache.
Denken Sie außerdem daran, dass Find nur die von Ihnen gesuchte Entität zurückgibt und deren zugeordneten Entitäten nicht automatisch laden wird, wenn sie sich nicht bereits im Objektcache befinden. Wenn Sie zugeordnete Entitäten abrufen müssen, können Sie eine Abfrage nach Schlüssel mit Eager Loading verwenden. Weitere Informationen finden Sie unter 8.1 Lazy Loading vs. Eager Loading.
3.1.2 Leistungsprobleme, wenn der Objektcache über viele Entitäten verfügt
Der Objektcache trägt dazu bei, die Gesamtreaktionsfähigkeit von Entity Framework zu erhöhen. Wenn der Objektcache jedoch eine sehr große Menge von Entitäten geladen hat, kann es sich auf bestimmte Vorgänge wie Add, Remove, Find, Entry, SaveChanges und mehr auswirken. Insbesondere werden Vorgänge, die einen Aufruf von DetectChanges auslösen, von sehr großen Objektcaches negativ beeinflusst. DetectChanges synchronisiert den Objektgraph mit dem Objektzustandsmanager, und seine Leistung wird direkt durch die Größe des Objektgraphs bestimmt. Weitere Informationen zu DetectChanges finden Sie unter Nachverfolgen von Änderungen in POCO-Entitäten.
Wenn Sie Entity Framework 6 verwenden, können Entwickler AddRange und RemoveRange direkt für ein DbSet aufrufen, anstatt eine Sammlung zu durchlaufen und „Einmal pro Instanz hinzufügen“ aufzurufen. Der Vorteil der Verwendung der Bereichsmethoden besteht darin, dass die Kosten von DetectChanges nur einmal für die gesamte Gruppe von Entitäten anfallen und nicht für jede hinzugefügte Entität.
3.2 Zwischenspeichern von Abfrageplänen
Wenn eine Abfrage zum ersten Mal ausgeführt wird, durchläuft sie den internen Plancompiler, um die konzeptionelle Abfrage in den Speicherbefehl zu übersetzen (z. B. der T-SQL, der beim Ausführen gegen die SQL Server-Instanz ausgeführt wird). Wenn das Zwischenspeichern von Abfrageplänen aktiviert ist, wird der Speicherbefehl beim nächsten Ausführen der Abfrage direkt aus dem Abfrageplancache für die Ausführung abgerufen, und der Plancompiler wird umgangen.
Der Abfrageplancache wird für ObjectContext-Instanzen innerhalb derselben AppDomain gemeinsam genutzt. Sie müssen nicht an einer ObjectContext-Instanz festhalten, um vom Zwischenspeichern des Abfrageplans zu profitieren.
3.2.1 Einige Hinweise zum Zwischenspeichern von Abfrageplänen
- Der Abfrageplancache wird für alle Abfragetypen gemeinsam genutzt: Entity SQL, LINQ to Entities und CompiledQuery-Objekte.
- Standardmäßig ist das Zwischenspeichern von Abfrageplänen für Entity SQL-Abfragen aktiviert, unabhängig davon, ob sie über einen EntityCommand oder über eine ObjectQuery ausgeführt werden. Es ist auch standardmäßig für LINQ to Entities-Abfragen in Entity Framework unter .NET 4.5 und in Entity Framework 6 aktiviert
- Das Zwischenspeichern von Abfrageplänen kann deaktiviert werden, indem die EnablePlanCaching-Eigenschaft (in EntityCommand oder ObjectQuery) auf FALSCH festgelegt wird. Beispiel:
var query = from customer in context.Customer
where customer.CustomerId == id
select new
{
customer.CustomerId,
customer.Name
};
ObjectQuery oQuery = query as ObjectQuery;
oQuery.EnablePlanCaching = false;
- Bei parametrisierten Abfragen wirkt sich eine Änderung des Parameterwerts immer noch auf die zwischengespeicherte Abfrage aus. Das Ändern der Facette eines Parameters (z. B. Größe, Genauigkeit oder Skalierung) wirkt sich jedoch auf einen anderen Eintrag im Cache aus.
- Bei Verwendung von Entity SQL ist die Abfragezeichenfolge ein Teil des Schlüssels. Jegliches Ändern der Abfrage führt zu unterschiedlichen Cacheeinträgen, auch wenn die Abfragen funktionell gleichwertig sind. Dazu gehören Änderungen an Groß-/Kleinschreibung oder Leerzeichen.
- Bei Verwendung von LINQ wird die Abfrage verarbeitet, um einen Teil des Schlüssels zu generieren. Das Ändern des LINQ-Ausdrucks wird daher einen unterschiedlichen Schlüssel generieren.
- Andere technische Einschränkungen können gelten. Weitere Details finden Sie unter „automatisch kompilierte Abfragen“.
3.2.2 Algorithmus zur Cacheauslagerung
Wenn Sie verstehen, wie der interne Algorithmus funktioniert, können Sie herausfinden, wann sie das Zwischenspeichern von Abfrageplänen aktivieren oder deaktivieren sollten. Der Bereinigungsalgorithmus lautet wie folgt:
- Sobald der Cache eine festgelegte Anzahl von Einträgen (800) enthält, wird ein Timer gestartet, der den Cache regelmäßig aufräumt (einmal pro Minute).
- Während dem Aufräumen des Caches werden Einträge auf einer LFRU-Basis (am wenigsten häufig – zuletzt verwendet) aus dem Cache entfernt. Dieser Algorithmus berücksichtigt sowohl die Trefferanzahl als auch das Alter bei der Entscheidung, welche Einträge ausgeworfen werden.
- Am Ende jedes Aufräumens des Caches enthält der Cache erneut 800 Einträge.
Alle Cacheeinträge werden gleich behandelt, wenn ermittelt wird, welche Einträge ausgelagert werden sollen. Dies bedeutet, dass der Speicherbefehl für eine CompiledQuery die gleiche Chance auf Auslagerung hat wie der Speicherbefehl für eine Entity SQL-Abfrage.
Beachten Sie, dass der Timer für die Cacheauslagerung ausgelöst wird, wenn 800 Entitäten im Cache vorhanden sind, der Cache jedoch erst 60 Sekunden nach dem Start dieses Timers aufgeräumt wird. Das bedeutet, dass Ihr Cache für bis zu 60 Sekunden sehr groß werden kann.
3.2.3 Testmetriken, welche die Leistung des Zwischenspeicherns von Abfrageplänen demonstrieren
Um die Auswirkung des Zwischenspeicherns von Abfrageplänen auf die Leistung Ihrer Anwendung zu veranschaulichen, haben wir einen Test durchgeführt, bei dem eine Reihe von Entity SQL-Abfragen gegen das Navision-Modell ausgeführt wurde. Eine Beschreibung des Navision-Modells und der Typen der ausgeführten Abfragen finden Sie im Anhang. In diesem Test durchlaufen wir zunächst die Liste der Abfragen und führen jede einmal aus, um sie dem Cache hinzuzufügen (wenn das Zwischenspeichern aktiviert ist). Dieser Schritt wird zeitlich nicht gemessen. Als Nächstes wird der Hauptthread für mehr als 60 Sekunden in den Ruhezustand versetzt, damit das Aufräumen des Caches stattfinden kann. Schließlich durchlaufen wir die Liste ein 2. Mal, um die zwischengespeicherten Abfragen auszuführen. Außerdem wird der SQL Server-Plancache geleert, bevor jede Gruppe von Abfragen ausgeführt wird, so dass die Zeiten, die wir erhalten, genau den Nutzen des Abfrageplancaches widerspiegeln.
3.2.3.1 Testergebnisse
| Test | EF5 kein Cache | EF5 zwischengespeichert | EF6 kein Cache | EF6 zwischengespeichert |
|---|---|---|---|---|
| Aufzählen aller 18 723 Abfragen | 124 | 125,4 | 124,3 | 125,3 |
| Vermeiden des Aufräumens (nur die ersten 800 Abfragen, unabhängig von der Komplexität) | 41,7 | 5.5 | 40,5 | 5.4 |
| Nur die AggregatingSubtotals-Abfragen (178 Gesamtsumme – wodurch ein Aufräumen vermieden wird) | 39,5 | 4.5 | 38,1 | 4.6 |
Alle Zeiten in Sekunden.
Moral – Beim Ausführen einer Vielzahl unterschiedlicher Abfragen (z. B. dynamisch erstellte Abfragen) hilft das Zwischenspeichern nicht und das resultierende Leeren des Caches kann dazu führen, dass die Abfragen, die am meisten vom Planzwischenspeichern profitieren würden, es nicht nutzen können.
Die AggregatingSubtotals-Abfragen sind die komplexesten Abfragen, mit denen wir getestet haben. Je komplexer die Abfrage ist, desto mehr profitieren Sie erwartungsgemäß vom Zwischenspeichern des Abfrageplans.
Da eine CompiledQuery tatsächlich eine LINQ-Abfrage mit zwischengespeichertem Plan ist, sollte der Vergleich einer CompiledQuery mit einer gleichwertigen Entity SQL-Abfrage ähnliche Ergebnisse liefern. Wenn eine App über viele dynamische Entity SQL-Abfragen verfügt, führt das Füllen des Caches mit Abfragen auch effektiv dazu, CompiledQueries zu „dekompilieren“, wenn sie aus dem Cache geleert werden. In diesem Szenario kann die Leistung verbessert werden, indem das Zwischenspeichern für die dynamischen Abfragen deaktiviert wird, um die CompiledQueries zu priorisieren. Noch besser wäre es natürlich, die App erneut zu generieren, um parametrisierte Abfragen anstelle dynamischer Abfragen zu verwenden.
3.3 Verwenden von CompiledQuery zur Verbesserung der Leistung mit LINQ-Abfragen
Unsere Tests deuten darauf hin, dass die Verwendung von CompiledQuery einen Vorteil von 7 % gegenüber automatisch kompilierten LINQ-Abfragen bieten kann. Dies bedeutet, dass Sie 7 % weniger Zeit damit verbringen, Code aus dem Entity Framework-Stapel auszuführen. Es bedeutet nicht, dass Ihre Anwendung 7 % schneller ist. Im Allgemeinen sind die Kosten für das Schreiben und Warten von CompiledQuery-Objekten in EF 5.0 im Vergleich zu den Nutzen möglicherweise nicht der Mühe wert. Der von Ihnen benötigte Aufwand kann unterschiedlich sein, also nutzen Sie diese Option, wenn Ihr Projekt einen zusätzlichen Schub erfordert. Beachten Sie, dass CompiledQueries nur mit von ObjectContext abgeleiteten Modellen kompatibel sind und nicht mit von DbContext abgeleiteten Modellen.
Weitere Informationen zum Erstellen und Aufrufen einer CompiledQuery finden Sie unter Kompilierte Abfragen (LINQ to Entities).
Es gibt zwei Überlegungen, die Sie bei der Verwendung einer CompiledQuery berücksichtigen müssen, nämlich die Anforderung, statische Instanzen zu verwenden und die Probleme, die sie mit der Zusammensetzbarkeit haben. Hier folgt eine ausführliche Erläuterung dieser beiden Überlegungen.
3.3.1 Verwenden statischer CompiledQuery-Instanzen
Da das Kompilieren einer LINQ-Abfrage ein zeitaufwendiger Prozess ist, möchten wir es nicht jedes Mal tun, wenn wir Daten aus der Datenbank abrufen müssen. CompiledQuery-Instanzen ermöglichen es Ihnen, einmal zu kompilieren und mehrmals auszuführen, aber Sie müssen vorsichtig sein und dafür sorgen, dass die gleiche CompiledQuery-Instanz jedes Mal wieder verwendet wird, anstatt sie immer wieder zu kompilieren. Die Verwendung statischer Members zum Speichern der CompiledQuery-Instanzen wird notwendig, anderenfalls werden Sie keinen Nutzen sehen.
Nehmen wir beispielsweise an, Ihre Seite weist den folgenden Methodenkörper auf, um die Anzeige der Produkte für die ausgewählte Kategorie zu verarbeiten:
// Warning: this is the wrong way of using CompiledQuery
using (NorthwindEntities context = new NorthwindEntities())
{
string selectedCategory = this.categoriesList.SelectedValue;
var productsForCategory = CompiledQuery.Compile<NorthwindEntities, string, IQueryable<Product>>(
(NorthwindEntities nwnd, string category) =>
nwnd.Products.Where(p => p.Category.CategoryName == category)
);
this.productsGrid.DataSource = productsForCategory.Invoke(context, selectedCategory).ToList();
this.productsGrid.DataBind();
}
this.productsGrid.Visible = true;
In diesem Fall werden Sie bei jedem Aufruf der Methode im laufenden Betrieb eine neue CompiledQuery-Instanz erstellen. Anstatt Leistungsvorteile zu sehen, indem der Speicherbefehl aus dem Abfrageplancache abgerufen wird, durchläuft die CompiledQuery den Plancompiler jedes Mal, wenn eine neue Instanz erstellt wird. Tatsächlich werden Sie Ihren Abfrageplancache bei jedem Aufruf der Methode mit einem neuen CompiledQuery-Eintrag verunreinigen.
Stattdessen möchten Sie eine statische Instanz der kompilierten Abfrage erstellen, sodass Sie bei jedem Aufruf der Methode dieselbe kompilierte Abfrage aufrufen. Eine Möglichkeit hierfür ist das Hinzufügen der CompiledQuery-Instanz als Member Ihres Objektkontexts. Sie können die Dinge dann etwas übersichtlicher gestalten, indem Sie über eine Hilfsprogrammmethode auf die CompiledQuery zugreifen:
public partial class NorthwindEntities : ObjectContext
{
private static readonly Func<NorthwindEntities, string, IEnumerable<Product>> productsForCategoryCQ = CompiledQuery.Compile(
(NorthwindEntities context, string categoryName) =>
context.Products.Where(p => p.Category.CategoryName == categoryName)
);
public IEnumerable<Product> GetProductsForCategory(string categoryName)
{
return productsForCategoryCQ.Invoke(this, categoryName).ToList();
}
Diese Hilfsprogrammmethode würde wie folgt aufgerufen:
this.productsGrid.DataSource = context.GetProductsForCategory(selectedCategory);
3.3.2 Verfassen über eine CompiledQuery
Die Möglichkeit zum Verfassen über eine LINQ-Abfrage ist äußerst nützlich; Dazu rufen Sie einfach eine Methode nach der IQueryable-Methode auf, z. B. Skip() oder Count(). Dadurch wird jedoch im Wesentlichen ein neues IQueryable-Objekt zurückgegeben. Es gibt zwar nichts, was Sie technisch daran hindern kann, eine CompiledQuery zusammenzustellen, aber dadurch wird ein neues IQueryable-Objekt generiert, das erneut den Plancompiler durchlaufen muss.
Einige Komponenten werden zusammengesetzte IQueryable-Objekte nutzen, um erweiterte Funktionen zu ermöglichen. Beispielsweise kann die GridView von ASP.NET über die SelectMethod-Eigenschaft über Daten an ein IQueryable-Objekt gebunden werden. Die GridView wird dann über dieses IQueryable-Objekt zusammensetzen, um das Sortieren und Pagen über das Datenmodell zu ermöglichen. Wie Sie sehen können, würde sich die Verwendung einer CompiledQuery für die GridView nicht auf die kompilierte Abfrage auswirken, sondern eine neue automatisch kompilierte Abfrage generieren.
Ein Ort, an dem Sie auf dieses Problem stoßen können, ist das Hinzufügen von progressiven Filtern zu einer Abfrage. Nehmen wir beispielsweise an, Sie hatten eine Seite „Kunden“ mit mehreren Dropdownlisten für optionale Filter (z. B. „Land“ und „OrdersCount“). Sie können diese Filter über die IQueryable-Ergebnisse eines CompiledQuery zusammenstellen, dies führt aber dazu, dass die neue Abfrage bei jeder Ausführung den Plancompiler durchläuft.
using (NorthwindEntities context = new NorthwindEntities())
{
IQueryable<Customer> myCustomers = context.InvokeCustomersForEmployee();
if (this.orderCountFilterList.SelectedItem.Value != defaultFilterText)
{
int orderCount = int.Parse(orderCountFilterList.SelectedValue);
myCustomers = myCustomers.Where(c => c.Orders.Count > orderCount);
}
if (this.countryFilterList.SelectedItem.Value != defaultFilterText)
{
myCustomers = myCustomers.Where(c => c.Address.Country == countryFilterList.SelectedValue);
}
this.customersGrid.DataSource = myCustomers;
this.customersGrid.DataBind();
}
Um diese erneute Kompilierung zu vermeiden, können Sie die CompiledQuery umschreiben, um die möglichen Filter zu berücksichtigen:
private static readonly Func<NorthwindEntities, int, int?, string, IQueryable<Customer>> customersForEmployeeWithFiltersCQ = CompiledQuery.Compile(
(NorthwindEntities context, int empId, int? countFilter, string countryFilter) =>
context.Customers.Where(c => c.Orders.Any(o => o.EmployeeID == empId))
.Where(c => countFilter.HasValue == false || c.Orders.Count > countFilter)
.Where(c => countryFilter == null || c.Address.Country == countryFilter)
);
Dies würde in der Benutzeroberfläche wie folgt aufgerufen werden:
using (NorthwindEntities context = new NorthwindEntities())
{
int? countFilter = (this.orderCountFilterList.SelectedIndex == 0) ?
(int?)null :
int.Parse(this.orderCountFilterList.SelectedValue);
string countryFilter = (this.countryFilterList.SelectedIndex == 0) ?
null :
this.countryFilterList.SelectedValue;
IQueryable<Customer> myCustomers = context.InvokeCustomersForEmployeeWithFilters(
countFilter, countryFilter);
this.customersGrid.DataSource = myCustomers;
this.customersGrid.DataBind();
}
Ein Nachteil dabei ist, dass der generierte Speicherbefehl immer die Filter mit den NULL-Prüfungen enthalten wird, aber diese sollten für den Datenbankserver recht einfach zu optimieren sein:
...
WHERE ((0 = (CASE WHEN (@p__linq__1 IS NOT NULL) THEN cast(1 as bit) WHEN (@p__linq__1 IS NULL) THEN cast(0 as bit) END)) OR ([Project3].[C2] > @p__linq__2)) AND (@p__linq__3 IS NULL OR [Project3].[Country] = @p__linq__4)
3.4 Zwischenspeichern von Metadaten
Das Entity Framework unterstützt auch das Zwischenspeichern von Metadaten. Dies ist im Wesentlichen das Zwischenspeichern von Typinformationen und Typ-zu-Datenbank-Zuordnungsinformationen über verschiedene Verbindungen zu demselben Modell. Der Metadatencache ist pro AppDomain eindeutig.
3.4.1 Algorithmus für das Zwischenspeichern von Metadaten
Metadateninformationen für ein Modell werden in einer ItemCollection für jede EntityConnection gespeichert.
- Nebenbei bemerkt gibt es verschiedene ItemCollection-Objekte für verschiedene Teile des Modells. Beispielsweise enthält StoreItemCollections die Informationen zum Datenbankmodell, ObjectItemCollection enthält Informationen zum Datenmodell, EdmItemCollection enthält Informationen zum konzeptionellen Modell.
Wenn zwei Verbindungen dieselbe Verbindungszeichenfolge verwenden, werden sie dieselbe ItemCollection-Instanz teilen.
Funktionell gleichwertige, aber inhaltlich unterschiedliche Verbindungszeichenfolgen können zu unterschiedlichen Metadatencaches führen. Wir versehen Verbindungszeichenfolgen mit Token, sodass eine einfache Änderung der Reihenfolge der Token zu gemeinsamen Metadaten führen sollte. Aber zwei Verbindungszeichenfolgen, die funktional gleich erscheinen, werden nach der Tokenisierung möglicherweise nicht als identisch ausgewertet.
Die ItemCollection wird in regelmäßigen Abständen auf Verwendung überprüft. Wenn festgestellt wird, dass auf einen Arbeitsbereich in letzter Zeit nicht zugegriffen wurde, wird er beim nächsten Aufräumen des Caches zur Bereinigung markiert.
Das bloße Erstellen einer EntityConnection führt dazu, dass ein Metadatencache erstellt wird (die darin enthaltenen Element-Sammlungen werden jedoch erst initialisiert, wenn die Verbindung geöffnet wird). Dieser Arbeitsbereich bleibt im Arbeitsspeicher, bis der Al für das Zwischenspeichern feststellt, dass er nicht „in Gebrauch“ ist.
Das Kundenberatungsteam hat einen Blogbeitrag geschrieben, in dem beschrieben wird, wie man einen Verweis auf eine ItemCollection hält, um bei der Verwendung großer Modelle eine „Veralterung“ zu vermeiden: <https://learn.microsoft.com/archive/blogs/appfabriccat/holding-a-reference-to-the-ef-metadataworkspace-for-wcf-services>.
3.4.2 Die Beziehung zwischen dem Zwischenspeichern von Metadaten und dem Zwischenspeichern des Abfrageplans
Die Cache-Instanz des Abfrageplans befindet sich in der ItemCollection von Speichertypen des MetadataWorkspace. Dies bedeutet, dass zwischengespeicherte Speicherbefehle für Abfragen gegen jeden Kontext verwendet werden, der mithilfe eines bestimmten MetadataWorkspace instanziiert wird. Dies bedeutet auch, dass Sie bei zwei Verbindungszeichenfolgen, die geringfügig unterschiedlich sind und nach der Tokenisierung nicht übereinstimmen, unterschiedliche Cache-Instanzen des Abfrageplans haben werden.
3.5 Zwischenspeichern von Ergebnissen
Beim Zwischenspeichern von Ergebnissen (auch als „Zwischenspeichern auf zweiter Ebene“ bezeichnet) behalten Sie die Ergebnisse von Abfragen in einem lokalen Cache bei. Beim Ausgeben einer Abfrage sehen Sie zuerst, ob die Ergebnisse lokal verfügbar sind, bevor Sie eine Abfrage gegen den Speicher durchführen. Obwohl das Zwischenspeichern von Ergebnissen nicht direkt von Entity Framework unterstützt wird, ist es möglich, einen Cache der zweiten Ebene mithilfe eines Umbruchanbieters hinzuzufügen. Ein Beispiel für den Umbruchanbieter mit einem Cache der zweiten Ebene ist der Entity Framework-Cache der zweiten Ebene von Alachisoft basierend auf NCache.
Diese Implementierung des Zwischenspeicherns auf zweiter Ebene ist eine eingefügte Funktionalität, die ausgeführt wird, nachdem der LINQ-Ausdruck ausgewertet (und funktionsfähig gemacht) wurde und der Abfrageausführungsplan berechnet oder aus dem Cache der ersten Ebene abgerufen wird. Der Cache der zweiter Ebene speichert dann nur die Rohdatenbankergebnisse, sodass die Materialisierungspipeline auch danach noch ausgeführt wird.
3.5.1 Zusätzliche Verweise zum Zwischenspeichern von Ergebnissen mit dem Umbruchanbieter
- Julie Lerman hat einen MSDN-Artikel „Zwischenspeichern auf zweiter Ebene in Entity Framework und Windows Azure“ geschrieben, in dem beschrieben wird, wie der Beispielumbruchanbieter aktualisiert werden kann, um das Windows Server AppFabric-Zwischenspeichern zu verwenden: https://msdn.microsoft.com/magazine/hh394143.aspx
- Wenn Sie mit Entity Framework 5 arbeiten, finden Sie im Teamblog einen Beitrag, der beschreibt, wie Sie mit dem Zwischenspeichernanbieter für Entity Framework 5 arbeiten können: <https://learn.microsoft.com/archive/blogs/adonet/ef-caching-with-jarek-kowalskis-provider>. Er enthält auch eine T4-Vorlage, mit der das Hinzufügen des Zwischenspeicherns auf zweiter Ebene zu Ihrem Projekt automatisiert werden kann.
4 Automatisch kompilierte Abfragen
Wenn eine Abfrage mittels Entity Framework gegen eine Datenbank ausgestellt wird, muss sie eine Reihe von Schritten durchlaufen, bevor die Ergebnisse tatsächlich materialisiert werden. Ein solcher Schritt ist die Abfragekompilierung. Entity SQL-Abfragen waren für gute Leistung bekannt, da sie automatisch zwischengespeichert werden, sodass beim zweiten oder dritten Ausführen derselben Abfrage der Plancompiler übersprungen und stattdessen der zwischengespeicherte Plan verwendet werden kann.
Entity Framework 5 führte auch das automatische Zwischenspeichern für LINQ to Entities-Abfragen ein. In früheren Editionen von Entity Framework war das Erstellen einer CompiledQuery zur Beschleunigung der Leistung eine gängige Methode, da dadurch Ihre LINQ to Entities-Abfrage zwischenspeicherbar würde. Da das Zwischenspeichern jetzt automatisch ohne Verwendung einer CompiledQuery erfolgt, wird dieses Feature als „automatisch kompilierte Abfragen“ bezeichnet. Weitere Informationen zum Abfrageplancache und seine Mechanismen finden Sie unter „Zwischenspeichern von Abfrageplänen“.
Entity Framework erkennt, wann eine Abfrage neu kompiliert werden muss, und tut dies, wenn die Abfrage aufgerufen wird, auch wenn sie zuvor bereits kompiliert wurde. Häufige Bedingungen, die dazu führen, dass die Abfrage neu kompiliert wird, sind:
- Ändern der MergeOption, die Ihrer Abfrage zugeordnet ist. Die zwischengespeicherte Abfrage wird nicht verwendet, stattdessen wird der Plancompiler erneut ausgeführt, und der neu erstellte Plan wird zwischengespeichert.
- Ändern des Werts von ContextOptions.UseCSharpNullComparisonBehavior. Sie erhalten den gleichen Effekt wie beim Ändern der MergeOption.
Andere Bedingungen können verhindern, dass Ihre Abfrage den Cache verwendet. Typische Beispiele:
- Verwenden von IEnumerable<T>.Contains<>(T-Wert).
- Verwenden von Funktionen, die Abfragen mit Konstanten erzeugen.
- Verwenden der Eigenschaften eines nicht zugeordneten Objekts.
- Verknüpfen Ihrer Abfrage mit einer anderen Abfrage, die neu kompiliert werden muss.
4.1 Verwendung von IEnumerable<T>.Contains<T>(T-Wert)
Entity Framework speichert keine Abfragen zwischen, die IEnumerable<T>.Contains<T>(T-Wert) gegen eine Arbeitsspeicherauflistung aufrufen, da die Werte der Auflistung als veränderlich betrachtet werden. Die folgende Beispielabfrage wird nicht zwischengespeichert, sodass sie immer vom Plancompiler verarbeitet wird:
int[] ids = new int[10000];
...
using (var context = new MyContext())
{
var query = context.MyEntities
.Where(entity => ids.Contains(entity.Id));
var results = query.ToList();
...
}
Beachten Sie, dass die Größe von IEnumerable, gegen den „Contains“ ausgeführt wird, bestimmt, wie schnell oder wie langsam Ihre Abfrage kompiliert wird. Die Leistung kann bei Verwendung großer Auflistungen wie der im obigen Beispiel gezeigten erheblich beeinträchtigt leiden.
Entity Framework 6 enthält Optimierungen für die Art und Weise, wie IEnumerable<T>.Contains<T>(T-Wert) funktioniert, wenn Abfragen ausgeführt werden. Der generierte SQL-Code ist viel schneller zu produzieren und lesbarer, und in den meisten Fällen wird er auf dem Server auch schneller ausgeführt.
4.2 Verwenden von Funktionen, die Abfragen mit Konstanten erzeugen
Die LINQ-Operatoren Skip(), Take(), Contains() und DefautIfEmpty() erzeugen keine SQL-Abfragen mit Parametern, sondern platzieren stattdessen die an sie übergebenen Werte als Konstanten. Aus diesem Grund verunreinigen Abfragen, die ansonsten identisch sein könnten, den Abfrageplancache, sowohl auf dem EF-Stapel als auch auf dem Datenbankserver, und werden nicht wiederverwendet, es sei denn, dieselben Konstanten werden in einer nachfolgenden Abfrageausführung verwendet. Beispiel:
var id = 10;
...
using (var context = new MyContext())
{
var query = context.MyEntities.Select(entity => entity.Id).Contains(id);
var results = query.ToList();
...
}
In diesem Beispiel wird die Abfrage jedes Mal, wenn sie mit einem anderen Wert für die ID ausgeführt wird, in einen neuen Plan kompiliert.
Achten Sie insbesondere auf die Verwendung von „Skip“ und „Take“ beim Pagen. In EF6 verfügen diese Methoden über ein Überladen der Lambdafunktion, die den zwischengespeicherten Abfrageplan effektiv wiederverwendbar macht, da EF die an diese Methoden übergebenen Variablen erfassen und in SQL-Parameter übersetzen kann. Dies hilft auch, den Cache sauberer zu halten, da sonst jede Abfrage mit einer unterschiedlichen Konstante für „Skip“ und „Take“ einen eigenen Eintrag im Abfrageplancache erhalten würde.
Betrachten Sie den folgenden Code, der suboptimal ist, aber nur als Beispiel für diese Klasse von Abfragen dienen soll:
var customers = context.Customers.OrderBy(c => c.LastName);
for (var i = 0; i < count; ++i)
{
var currentCustomer = customers.Skip(i).FirstOrDefault();
ProcessCustomer(currentCustomer);
}
Eine schnellere Version des gleichen Codes würde das Aufrufen von Skip mit einer Lambdafunktion umfassen:
var customers = context.Customers.OrderBy(c => c.LastName);
for (var i = 0; i < count; ++i)
{
var currentCustomer = customers.Skip(() => i).FirstOrDefault();
ProcessCustomer(currentCustomer);
}
Der zweite Codeausschnitt kann bis zu 11 % schneller ausgeführt werden, da der gleiche Abfrageplan bei jeder Ausführung der Abfrage verwendet wird, wodurch CPU-Zeit gespart wird und das Verunreinigen des Abfragecaches vermieden wird. Da sich der Parameter zum Überspringen in einem Einschluss befindet, könnte der Code jetzt auch so aussehen:
var i = 0;
var skippyCustomers = context.Customers.OrderBy(c => c.LastName).Skip(() => i);
for (; i < count; ++i)
{
var currentCustomer = skippyCustomers.FirstOrDefault();
ProcessCustomer(currentCustomer);
}
4.3 Verwenden der Eigenschaften eines nicht zugeordneten Objekts
Wenn eine Abfrage die Eigenschaften eines nicht zugeordneten Objekttyps als Parameter verwendet, wird die Abfrage nicht zwischengespeichert. Beispiel:
using (var context = new MyContext())
{
var myObject = new NonMappedType();
var query = from entity in context.MyEntities
where entity.Name.StartsWith(myObject.MyProperty)
select entity;
var results = query.ToList();
...
}
Gehen Sie in diesem Beispiel davon aus, dass die Klasse NonMappedType nicht Teil des Entity-Modells ist. Diese Abfrage kann ganz einfach geändert werden, um keinen nicht zugeordneten Typ zu verwenden und stattdessen eine lokale Variable als Parameter für die Abfrage zu verwenden:
using (var context = new MyContext())
{
var myObject = new NonMappedType();
var myValue = myObject.MyProperty;
var query = from entity in context.MyEntities
where entity.Name.StartsWith(myValue)
select entity;
var results = query.ToList();
...
}
In diesem Fall kann die Abfrage zwischengespeichert werden und profitiert vom Abfrageplancache.
4.4 Verknüpfen mit Abfragen, die eine erneute Kompilierung erfordern
Wenn Sie dem gleichen Beispiel wie oben folgen und eine zweite Abfrage haben, die auf einer Abfrage basiert, die neu kompiliert werden muss, wird auch die gesamte zweite Abfrage neu kompiliert. Hier ist ein Beispiel, um dieses Szenario zu veranschaulichen:
int[] ids = new int[10000];
...
using (var context = new MyContext())
{
var firstQuery = from entity in context.MyEntities
where ids.Contains(entity.Id)
select entity;
var secondQuery = from entity in context.MyEntities
where firstQuery.Any(otherEntity => otherEntity.Id == entity.Id)
select entity;
var results = secondQuery.ToList();
...
}
Das Beispiel ist generisch, veranschaulicht jedoch, wie die Verknüpfung mit firstQuery dazu führt, dass secondQuery nicht zwischengespeichert werden kann. Wäre firstQuery keine Abfrage gewesen, die eine Neukompilierung erfordert, wäre secondQuery zwischengespeichert worden.
5 NoTracking-Abfragen
5.1 Deaktivieren der Änderungsnachverfolgung, um den Aufwand für die Zustandsverwaltung zu verringern
Wenn Sie sich in einem schreibgeschützten Szenario befinden und den Aufwand des Ladens der Objekte in den ObjectStateManager vermeiden möchten, können Sie „No Tracking“-Abfragen (Abfragen ohne Nachverfolgung) ausgeben. Die Änderungsnachverfolgung kann auf Abfrageebene deaktiviert werden.
Beachten Sie jedoch, dass Sie durch Deaktivieren der Änderungsnachverfolgung den Objektcache effektiv deaktivieren. Wenn Sie eine Entität abfragen, können wir die Materialisierung nicht überspringen, indem die zuvor materialisierten Abfrageergebnisse aus dem ObjectStateManager gepullt werden. Wenn Sie wiederholt nach denselben Entitäten im selben Kontext abfragen, können Sie durch die Aktivierung der Änderungsverfolgung sogar einen Leistungsvorteil erzielen.
Beim Abfragen mithilfe von ObjectContext werden sich ObjectQuery- und ObjectSet-Instanzen eine einmal festgelegte MergeOption merken, und Abfragen, die auf ihnen aufgebaut sind, erben die effektive MergeOption der übergeordneten Abfrage. Bei Verwendung von DbContext kann die Nachverfolgung durch Aufrufen des AsNoTracking()-Modifizierers für DbSet deaktiviert werden.
5.1.1 Deaktivieren der Änderungsnachverfolgung für eine Abfrage bei Verwendung von DbContext
Sie können den Modus einer Abfrage in NoTracking wechseln, indem Sie einen Aufruf der Methode AsNoTracking() in der Abfrage verketten. Im Gegensatz zu ObjectQuery verfügen die DbSet- und DbQuery-Klassen in der DbContext-API nicht über eine veränderbare Eigenschaft für die MergeOption.
var productsForCategory = from p in context.Products.AsNoTracking()
where p.Category.CategoryName == selectedCategory
select p;
5.1.2 Deaktivieren der Änderungsnachverfolgung auf Abfrageebene mithilfe von ObjectContext
var productsForCategory = from p in context.Products
where p.Category.CategoryName == selectedCategory
select p;
((ObjectQuery)productsForCategory).MergeOption = MergeOption.NoTracking;
5.1.3 Deaktivieren der Änderungsnachverfolgung für eine gesamten Entitätenmenge mithilfe von ObjectContext
context.Products.MergeOption = MergeOption.NoTracking;
var productsForCategory = from p in context.Products
where p.Category.CategoryName == selectedCategory
select p;
5.2 Testmetriken, die den Leistungsvorteil von NoTracking-Abfragen demonstrieren
In diesem Test sehen wir uns die Kosten für das Ausfüllen des ObjectStateManager durch Vergleich von Tracking- mit NoTracking-Abfragen für das Navision-Modell an. Eine Beschreibung des Navision-Modells und der Typen der ausgeführten Abfragen finden Sie im Anhang. In diesem Test durchlaufen wir die Liste der Abfragen und führen jede einmal aus. Wir haben zwei Varianten des Tests ausgeführt, einmal mit NoTracking-Abfragen und einmal mit der Standardzusammenführungsoption „AppendOnly“. Wir haben jede Variation 3 Mal ausgeführt und nehmen den Mittelwert der Ausführungen. Zwischen den Tests löschen wir den Abfragecache auf der SQL Server-Instanz und verkleinern die temporäre Datenbank (tempdb), indem wir die folgenden Befehle ausführen:
- DBCC DROPCLEANBUFFERS
- DBCC FREEPROCCACHE
- DBCC SHRINKDATABASE (tempdb, 0)
Testergebnisse, Median über 3 Ausführungen:
| KEINE NACHVERFOLGUNG – ARBEITSSATZ | KEINE NACHVERFOLGUNG – ZEIT | NUR ANFÜGEN – ARBEITSSATZ | NUR ANFÜGEN – ZEIT | |
|---|---|---|---|---|
| Entity Framework 5 | 460361728 | 1163536 ms | 596545536 | 1273042 ms |
| Entity Framework 6 | 647127040 | 190228 ms | 832798720 | 195521 ms |
Entity Framework 5 wird am Ende der Ausführung einen kleineren Speicherbedarf als Entity Framework 6 aufweisen. Der von Entity Framework 6 verbrauchte zusätzliche Arbeitsspeicher ist das Ergebnis zusätzlicher Speicherstrukturen und Code, die neue Features und eine bessere Leistung ermöglichen.
Bei Verwendung des ObjectStateManager gibt es auch einen deutlichen Unterschied beim Speicherbedarf. Entity Framework 5 hat seinen Speicherbedarf um 30 % erhöht, wenn alle Entitäten, die wir aus der Datenbank materialisiert haben, nachverfolgt werden. Entity Framework 6 hat seinen Fußabdruck dabei um 28 % erhöht.
In Bezug auf die Zeit übertrifft Entity Framework 6 das Entity Framework 5 in diesem Test bei weitem. Entity Framework 6 hat den Test in etwa 16 % der von Entity Framework 5 verbrauchten Zeit abgeschlossen. Darüber hinaus benötigt Entity Framework 5 9 % mehr Zeit für die Fertigstellung, wenn der ObjectStateManager verwendet wird. Im Vergleich dazu verwendet Entity Framework 6 bei Verwendung des ObjectStateManager 3 % mehr Zeit.
6 Abfrageausführungsoptionen
Entity Framework bietet mehrere verschiedene Möglichkeiten zum Abfragen. Wir werden uns die folgenden Optionen ansehen, die Vor- und Nachteile der einzelnen Optionen vergleichen und ihre Leistungsmerkmale untersuchen:
- LINQ to Entities:
- LINQ to Entities ohne Nachverfolgung.
- Entity SQL über eine ObjectQuery.
- Entity SQL über einen EntityCommand.
- ExecuteStoreQuery.
- SqlQuery.
- CompiledQuery.
6.1 LINQ to Entities-Abfragen
var q = context.Products.Where(p => p.Category.CategoryName == "Beverages");
Vorteile
- Geeignet für CUD-Vorgänge.
- Vollständig materialisierte Objekte.
- Am einfachsten zu schreiben mit der in die Programmiersprache integrierten Syntax.
- Gute Leistung.
Nachteile
- Bestimmte technische Einschränkungen, z. B.:
- Muster, die DefaultIfEmpty für OUTER JOIN-Abfragen verwenden, führen zu komplexeren Abfragen als einfache OUTER JOIN-Anweisungen in Entity SQL.
- Sie können LIKE immer noch nicht mit allgemeinem Musterabgleich verwenden.
6.2 LINQ to Entities-Abfragen ohne Nachverfolgung
Wenn der Kontext ObjectContext ableitet:
context.Products.MergeOption = MergeOption.NoTracking;
var q = context.Products.Where(p => p.Category.CategoryName == "Beverages");
Wenn der Kontext DbContext ableitet:
var q = context.Products.AsNoTracking()
.Where(p => p.Category.CategoryName == "Beverages");
Vorteile
- Verbesserte Leistung gegenüber regulären LINQ-Abfragen.
- Vollständig materialisierte Objekte.
- Am einfachsten zu schreiben mit der in die Programmiersprache integrierten Syntax.
Nachteile
- Nicht geeignet für CUD-Vorgänge.
- Bestimmte technische Einschränkungen, z. B.:
- Muster, die DefaultIfEmpty für OUTER JOIN-Abfragen verwenden, führen zu komplexeren Abfragen als einfache OUTER JOIN-Anweisungen in Entity SQL.
- Sie können LIKE immer noch nicht mit allgemeinem Musterabgleich verwenden.
Beachten Sie, dass Abfragen, die skalare Eigenschaften projizieren, nicht nachverfolgt werden, auch wenn NoTracking nicht angegeben ist. Beispiel:
var q = context.Products.Where(p => p.Category.CategoryName == "Beverages").Select(p => new { p.ProductName });
Diese spezielle Abfrage gibt nicht explizit an, NoTracking zu sein, aber da sie keinen Typ materialisiert, der dem Objektzustandsmanager bekannt ist, wird das materialisierte Ergebnis nicht nachverfolgt.
6.3 Entity SQL über eine ObjectQuery
ObjectQuery<Product> products = context.Products.Where("it.Category.CategoryName = 'Beverages'");
Vorteile
- Geeignet für CUD-Vorgänge.
- Vollständig materialisierte Objekte.
- Unterstützt das Zwischenspeichern von Abfrageplänen.
Nachteile
- Beinhaltet Textabfragezeichenfolgen, die anfälliger für Benutzerfehler sind als die in die Sprache integrierten Abfragekonstrukte.
6.4 Entity SQL über einen Entity-Befehl
EntityCommand cmd = eConn.CreateCommand();
cmd.CommandText = "Select p From NorthwindEntities.Products As p Where p.Category.CategoryName = 'Beverages'";
using (EntityDataReader reader = cmd.ExecuteReader(CommandBehavior.SequentialAccess))
{
while (reader.Read())
{
// manually 'materialize' the product
}
}
Vorteile
- Unterstützt das Zwischenspeichern von Abfrageplänen in .NET 4.0 (Planzwischenspeichern wird von allen anderen Abfragetypen in .NET 4.5 unterstützt).
Nachteile
- Beinhaltet Textabfragezeichenfolgen, die anfälliger für Benutzerfehler sind als die in die Sprache integrierten Abfragekonstrukte.
- Nicht geeignet für CUD-Vorgänge.
- Ergebnisse werden nicht automatisch materialisiert und müssen aus dem Datenleser gelesen werden.
6.5 SqlQuery und ExecuteStoreQuery
SqlQuery für Datenbank:
// use this to obtain entities and not track them
var q1 = context.Database.SqlQuery<Product>("select * from products");
SqlQuery für DbSet:
// use this to obtain entities and have them tracked
var q2 = context.Products.SqlQuery("select * from products");
ExecuteStoreQuery:
var beverages = context.ExecuteStoreQuery<Product>(
@" SELECT P.ProductID, P.ProductName, P.SupplierID, P.CategoryID, P.QuantityPerUnit, P.UnitPrice, P.UnitsInStock, P.UnitsOnOrder, P.ReorderLevel, P.Discontinued, P.DiscontinuedDate
FROM Products AS P INNER JOIN Categories AS C ON P.CategoryID = C.CategoryID
WHERE (C.CategoryName = 'Beverages')"
);
Vorteile
- In der Regel die schnellste Leistung, da der Plancompiler umgangen wird.
- Vollständig materialisierte Objekte.
- Geeignet für CUD-Vorgänge, wenn sie aus dem DbSet verwendet werden.
Nachteile
- Die Abfrage ist textbasiert und fehleranfällig.
- Die Abfrage ist an ein bestimmtes Back-End gebunden, indem Speichersemantik anstelle von konzeptioneller Semantik verwendet wird.
- Wenn die Vererbung vorhanden ist, muss eine von Hand erstellte Abfrage Zuordnungsbedingungen für den angeforderten Typ berücksichtigen.
6.6 CompiledQuery
private static readonly Func<NorthwindEntities, string, IQueryable<Product>> productsForCategoryCQ = CompiledQuery.Compile(
(NorthwindEntities context, string categoryName) =>
context.Products.Where(p => p.Category.CategoryName == categoryName)
);
…
var q = context.InvokeProductsForCategoryCQ("Beverages");
Vorteile
- Bietet bis zu 7 % Leistungsverbesserung gegenüber regulären LINQ-Abfragen.
- Vollständig materialisierte Objekte.
- Geeignet für CUD-Vorgänge.
Nachteile
- Erhöhte Komplexität und erhöhter Programmieraufwand.
- Die Leistungsverbesserung geht beim Zusammenstellen über eine kompilierte Abfrage verloren.
- Einige LINQ-Abfragen können nicht als CompiledQuery geschrieben werden, beispielsweise Projektionen anonymer Typen.
6.7 Leistungsvergleich verschiedener Abfrageoptionen
Einfache Mikrobenchmarks, bei denen die Kontexterstellung zeitlich nicht gemessen wurde, wurden getestet. Wir haben eine Abfrageausführung 5000 Mal für eine Reihe nicht zwischengespeicherter Entitäten in einer kontrollierten Umgebung gemessen. Diese Zahlen sind mit einer Warnung zu betrachten: Sie spiegeln nicht die tatsächlichen Zahlen wider, die von einer Anwendung erzeugt werden, sondern sie sind eine sehr genaue Messung des Leistungsunterschieds, wenn verschiedene Abfrageoptionen direkt miteinander verglichen werden, unter Ausschluss der Kosten für die Erstellung eines neuen Kontexts.
| EF | Test | Zeit (ms) | Arbeitsspeicher |
|---|---|---|---|
| EF5 | ObjectContext ESQL | 2414 | 38801408 |
| EF5 | ObjectContext LINQ-Abfrage | 2692 | 38277120 |
| EF5 | DbContext LINQ-Abfrage ohne Nachverfolgung | 2818 | 41840640 |
| EF5 | DbContext LINQ-Abfrage | 2930 | 41771008 |
| EF5 | ObjectContext LINQ-Abfrage ohne Nachverfolgung | 3013 | 38412288 |
| EF6 | ObjectContext ESQL | 2059 | 46039040 |
| EF6 | ObjectContext LINQ-Abfrage | 3074 | 45248512 |
| EF6 | DbContext LINQ-Abfrage ohne Nachverfolgung | 3125 | 47575040 |
| EF6 | DbContext LINQ-Abfrage | 3420 | 47652864 |
| EF6 | ObjectContext LINQ-Abfrage ohne Nachverfolgung | 3593 | 45260800 |
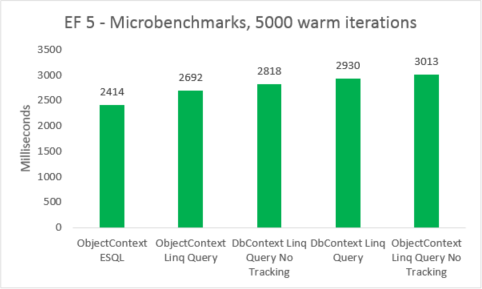
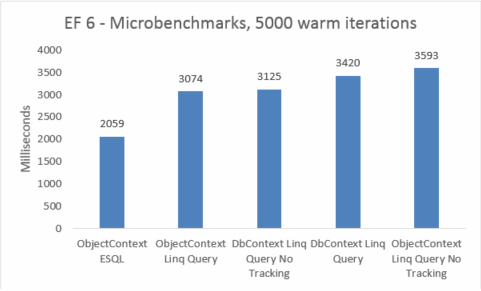
Mikrobenchmarks sind sehr sensibel bezüglich kleinen Änderungen im Code. In diesem Fall ist die Differenz zwischen den Kosten von Entity Framework 5 und Entity Framework 6 auf das Hinzufügen von Abfangen und Transaktionsverbesserungen zurückzuführen. Diese Mikrobenchmarkzahlen sind jedoch ein erweiterter Blick auf ein sehr kleines Fragment dessen, was Entity Framework leistet. Reale Szenarien warmer Abfragen sollten beim Upgrade von Entity Framework 5 auf Entity Framework 6 keine Leistungseinbußen sehen.
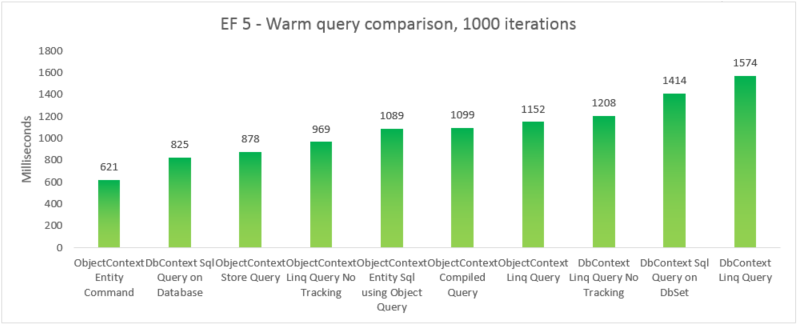
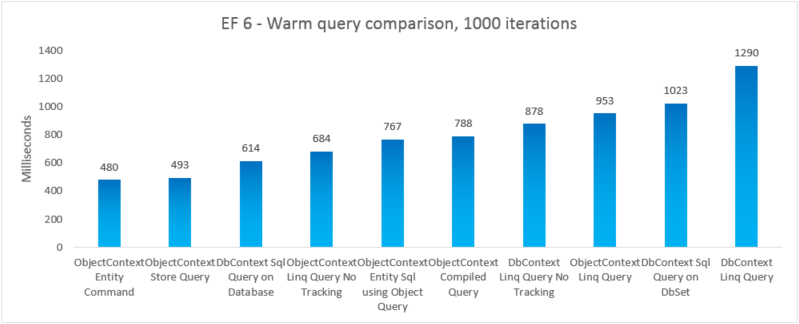
Um die reale Leistung der verschiedenen Abfrageoptionen zu vergleichen, haben wir fünf separate Testvariationen erstellt, bei denen wir eine andere Abfrageoption verwenden, um alle Produkte auszuwählen, deren Kategoriename „Getränke“ lautet. Jede Iteration umfasst die Kosten für die Erstellung des Kontexts und die Kosten für die Materialisierung aller zurückgegebenen Entitäten. 10 Iterationen werden ohne Zeitmessung ausgeführt, bevor die Summe von 1000 zeitlich gemessenen Iterationen berücksichtigt wird. Bei den Ergebnissen handelt es sich um den Mittelwert von 5 Ausführungen jedes Tests. Weitere Informationen finden Sie in Anhang B, welcher den Code für den Test enthält.
| EF | Test | Zeit (ms) | Arbeitsspeicher |
|---|---|---|---|
| EF5 | ObjectContext Entity-Befehl | 621 | 39350272 |
| EF5 | DbContext SQL-Abfrage für Datenbank | 825 | 37519360 |
| EF5 | ObjectContext-Speicherabfrage | 878 | 39460864 |
| EF5 | ObjectContext LINQ-Abfrage ohne Nachverfolgung | 969 | 38293504 |
| EF5 | ObjectContext Entity SQL mit Objektabfrage | 1089 | 38981632 |
| EF5 | Kompilierte ObjectContext-Abfrage | 1099 | 38682624 |
| EF5 | ObjectContext LINQ-Abfrage | 1152 | 38178816 |
| EF5 | DbContext LINQ-Abfrage ohne Nachverfolgung | 1208 | 41803776 |
| EF5 | DbContext SQL-Abfrage für DbSet | 1414 | 37982208 |
| EF5 | DbContext LINQ-Abfrage | 1574 | 41738240 |
| EF6 | ObjectContext Entity-Befehl | 480 | 47247360 |
| EF6 | ObjectContext-Speicherabfrage | 493 | 46739456 |
| EF6 | DbContext SQL-Abfrage für Datenbank | 614 | 41607168 |
| EF6 | ObjectContext LINQ-Abfrage ohne Nachverfolgung | 684 | 46333952 |
| EF6 | ObjectContext Entity SQL mit Objektabfrage | 767 | 48865280 |
| EF6 | Kompilierte ObjectContext-Abfrage | 788 | 48467968 |
| EF6 | DbContext LINQ-Abfrage ohne Nachverfolgung | 878 | 47554560 |
| EF6 | ObjectContext LINQ-Abfrage | 953 | 47632384 |
| EF6 | DbContext SQL-Abfrage für DbSet | 1023 | 41992192 |
| EF6 | DbContext LINQ-Abfrage | 1290 | 47529984 |
Hinweis
Der Vollständigkeit halber haben wir eine Variante eingefügt, bei der wir eine Entity SQL-Abfrage für einen EntityCommand ausführen. Da die Ergebnisse für solche Abfragen jedoch nicht materialisiert sind, ist der Vergleich nicht unbedingt äquivalent. Der Test umfasst eine enge Annäherung an die Materialisierung, um zu versuchen, den Vergleich fairer zu gestalten.
In diesem End-to-End-Fall übertrifft Entity Framework 6 die Leistung von Entity Framework 5 aufgrund von Leistungsverbesserungen in mehreren Teilen des Stapels, einschließlich einer viel leichteren DbContext-Initialisierung und schnelleren MetadataCollection<T>-Nachschlagevorgängen.
7 Leistungsüberlegungen zur Entwurfszeit
7.1 Vererbungsstrategien
Eine weitere Leistungsüberlegung bei der Verwendung von Entity Framework ist die von Ihnen verwendete Vererbungsstrategie. Entity Framework unterstützt drei grundlegende Vererbungstypen und ihre Kombinationen:
- Tabelle pro Hierarchie (TPH) – hier ist jeder Vererbungssatz einer Tabelle mit einer Diskriminatorspalte zugeordnet, um anzugeben, welcher bestimmte Typ in der Hierarchie in der Zeile dargestellt wird.
- Tabelle pro Typ (TPT) – hier verfügt jeder Typ über seine eigene Tabelle in der Datenbank. Die untergeordneten Tabellen definieren nur diejenigen Spalten, welche die übergeordnete Tabelle nicht enthält.
- Tabelle pro Klasse (TPC) – hier verfügt jeder Typ über seine eigene vollständige Tabelle in der Datenbank. Die untergeordneten Tabellen definieren alle Felder, einschließlich der Felder, die in übergeordneten Typen definiert sind.
Wenn Ihr Modell TPT-Vererbung verwendet, werden die generierten Abfragen komplexer sein als diejenigen, die mit den anderen Vererbungsstrategien generiert werden, was zu längeren Ausführungszeiten im Speicher führen kann. Es dauert in der Regel länger, Abfragen über ein TPT-Modell zu generieren und die resultierenden Objekte zu materialisieren.
Weitere Informationen finden Sie im MSDN-Blogbeitrag „Leistungsüberlegungen bei Verwendung von TPT (Tabelle pro Typ) im Entity Framework“: <https://learn.microsoft.com/archive/blogs/adonet/performance-considerations-when-using-tpt-table-per-type-inheritance-in-the-entity-framework>.
7.1.1 Vermeiden von TPT in „Model First“- oder „Code First“-Anwendung
Wenn Sie ein Modell über eine vorhandene Datenbank erstellen, die über ein TPT-Schema verfügt, haben Sie nicht viele Optionen. Wenn Sie jedoch eine Anwendung mit Model First oder Code First erstellen, sollten Sie aus Leistungsgründen die TPT-Vererbung vermeiden.
Wenn Sie Model First im Entity Designer-Assistenten verwenden, erhalten Sie TPT für jede Vererbung in Ihrem Modell. Wenn Sie mit Model First zu einer TPH-Vererbungsstrategie wechseln möchten, können Sie das „Entity Designer Database Generation Power Pack“ (Power Pack für die Datenbankgenerierung in Entity Designer) verwenden, das im Visual Studio-Katalog ( <http://visualstudiogallery.msdn.microsoft.com/df3541c3-d833-4b65-b942-989e7ec74c87/>) verfügbar ist.
Wenn Sie Code First zum Konfigurieren der Zuordnung eines Modells mit Vererbung verwenden, wird EF standardmäßig TPH verwenden, daher werden alle Entitäten in der Vererbungshierarchie der gleichen Tabelle zugeordnet werden. Weitere Informationen finden Sie im Abschnitt „Zuordnung mit der Fluent-API“ des Artikels „Code First in Entity Framework 4.1“ im MSDN Magazine ( http://msdn.microsoft.com/magazine/hh126815.aspx).
7.2 Upgrade von EF4 zur Verbesserung der Modellgenerierungszeit
Eine SQL Server-spezifische Verbesserung des Algorithmus, der die Speicherschicht (SSDL) des Modells generiert, ist in Entity Framework 5 und 6 verfügbar, sowie als Update auf Entity Framework 4, wenn Visual Studio 2010 SP1 installiert ist. Die folgenden Testergebnisse zeigen die Verbesserung beim Generieren eines sehr großen Modells, in diesem Fall das Navision-Modell. Weitere Informationen hierzu finden Sie in Anhang C.
Das Modell enthält 1005 Sätze in der Entitätenmenge und 4227 Zuordnungssätze.
| Konfiguration | Aufschlüsselung der verbrauchten Zeit |
|---|---|
| Visual Studio 2010, Entity Framework 4 | SSDL-Generierung: 2 Std. 27 Min. Zuordnungsgenerierung: 1 Sekunde CSDL-Generierung: 1 Sekunde ObjectLayer-Generierung: 1 Sekunde Ansichtsgenerierung: 2 Std. 14 Min. |
| Visual Studio 2010 SP1, Entity Framework 4 | SSDL-Generierung: 1 Sekunde Zuordnungsgenerierung: 1 Sekunde CSDL-Generierung: 1 Sekunde ObjectLayer-Generierung: 1 Sekunde Ansichtsgenerierung: 1 Std. 53 Min. |
| Visual Studio 2013, Entity Framework 5 | SSDL-Generierung: 1 Sekunde Zuordnungsgenerierung: 1 Sekunde CSDL-Generierung: 1 Sekunde ObjectLayer-Generierung: 1 Sekunde Ansichtsgenerierung: 65 Minuten |
| Visual Studio 2013, Entity Framework 6 | SSDL-Generierung: 1 Sekunde Zuordnungsgenerierung: 1 Sekunde CSDL-Generierung: 1 Sekunde ObjectLayer-Generierung: 1 Sekunde Ansichtsgenerierung: 28 Sekunden. |
Es ist erwähnenswert, dass beim Generieren der SSDL die Last fast vollständig auf der SQL Server-Instanz liegt, während der Cliententwicklungscomputer im Leerlauf auf Ergebnisse wartet, die vom Server zurückgegeben werden. Die DBAs sollten diese Verbesserung besonders schätzen. Es ist auch erwähnenswert, dass im Wesentlichen die gesamten Kosten der Modellgenerierung jetzt in der Ansichtsgenerierung auftreten.
7.3 Aufteilen großer Modelle mit Database First und Model First
Wenn die Modellgröße zunimmt, wird die Designeroberfläche unübersichtlich und schwierig zu verwenden. In der Regel betrachten wir ein Modell mit mehr als 300 Entitäten als zu groß, um den Designer effektiv zu verwenden. Der folgende Blogbeitrag beschreibt mehrere Optionen zum Aufteilen großer Modelle: <https://learn.microsoft.com/archive/blogs/adonet/working-with-large-models-in-entity-framework-part-2>.
Der Beitrag wurde für die erste Version von Entity Framework geschrieben, aber die Schritte gelten weiterhin.
7.4 Leistungsüberlegungen mit dem Entity-Datenquellensteuerelement
Wir haben Fälle in Multithread-Leistungs- und Stresstests gesehen, bei denen sich die Leistung einer Webanwendung mit dem EntityDataSource-Steuerelement erheblich verschlechtert. Die zugrunde liegende Ursache besteht darin, dass EntityDataSource wiederholt MetadataWorkspace.LoadFromAssembly für die Assemblys aufruft, auf die von der Webanwendung verwiesen wird, um die Typen zu ermitteln, die als Entitäten verwendet werden sollen.
Die Lösung besteht darin, den ContextTypeName der EntityDataSource auf den Typnamen der abgeleiteten ObjectContext-Klasse festzulegen. Dadurch wird der Mechanismus deaktiviert, der alle referenzierten Assemblys auf Entitätstypen scannt.
Das Festlegen des ContextTypeName-Felds verhindert auch ein funktionales Problem, bei dem die EntityDataSource in .NET 4.0 eine ReflectionTypeLoadException auslöst, wenn ein Typ nicht über Reflexion aus einer Assembly geladen werden kann. Dieses Problem wurde in .NET 4.5 behoben.
7.5 POCO-Entitäten und Änderungsnachverfolgungsproxys
Entity Framework ermöglicht es Ihnen, benutzerdefinierte Datenklassen zusammen mit Ihrem Datenmodell zu verwenden, ohne Änderungen an den Datenklassen selbst vornehmen zu müssen. Dies bedeutet, dass Sie POCO-Objekte (Plain-old CLR objects), z. B. vorhandene Domänenobjekte, mit dem Datenmodell verwenden können. Diese POCO-Datenklassen (auch persistenzignorante Objekte genannt), die Entitäten zugeordnet werden, die in einem Datenmodell definiert werden, unterstützen die meisten der gleichen Abfrage-, Einfüge-, Aktualisierungs- und Löschverhaltensweisen wie die Entitätstypen, die von Entity Data Model-Tools generiert werden.
Entity Framework kann auch von Ihren POCO-Typen abgeleitete Proxyklassen erstellen, die verwendet werden, wenn Sie Features wie Lazy Loading und automatische Änderungsnachverfolgung für POCO-Entitäten aktivieren wollen. Ihre POCO-Klassen müssen bestimmte Anforderungen erfüllen, damit Entity Framework Proxys verwenden kann, wie hier beschrieben: http://msdn.microsoft.com/library/dd468057.aspx.
Zufallsverfolgungsproxys benachrichtigen den Objektzustandsmanager jedes Mal, wenn sich die Eigenschaften Ihrer Entitäten geändert haben, sodass Entity Framework den tatsächlichen Zustand Ihrer Entitäten immer kennt. Dies geschieht durch das Hinzufügen von Benachrichtigungsereignissen in den Textkörper der Setter-Methoden Ihrer Eigenschaften und durch die Verarbeitung solcher Ereignisse durch den Objektzustandsmanager. Beachten Sie, dass das Erstellen einer Proxyentität in der Regel teurer sein wird als das Erstellen einer NICHT-Proxy-POCO-Entität, da Entity Framework eine Reihe von zusätzlichen Ereignissen erzeugt.
Wenn eine POCO-Entität keinen Proxy für die Änderungsnachverfolgung aufweist, werden Änderungen gefunden, indem die Inhalte Ihrer Entitäten mit einer Kopie eines vorherigen gespeicherten Zustands verglichen werden. Dieser umfassende Vergleich wird zu einem langwierigen Prozess, wenn Sie viele Entitäten in Ihrem Kontext haben, oder wenn Ihre Entitäten eine sehr große Anzahl von Eigenschaften haben, selbst wenn sich keine von ihnen seit dem letzten Vergleich geändert hat.
Zusammenfassung: Sie bezahlen beim Erstellen des Proxy für die Änderungsnachverfolgung mit einer Leistungseinbuße, aber die Änderungsnachverfolgung hilft Ihnen, den Änderungserkennungsprozess zu beschleunigen, wenn Ihre Entitäten über viele Eigenschaften verfügen, oder wenn Sie viele Entitäten in Ihrem Modell haben. Für Entitäten mit einer kleinen Anzahl von Eigenschaften, bei denen die Anzahl der Entitäten nicht zu stark anwächst, wird der Proxy für die Änderungsnachverfolgung wahrscheinlich nicht von großem Nutzen sein.
8 Laden zugehöriger Entitäten
8.1 Lazy Loading vs. Eager Loading
Entity Framework bietet verschiedene Möglichkeiten, die Entitäten zu laden, die mit Ihrer Zielentität verbunden sind. Wenn Sie z. B. nach Produkten abfragen, gibt es verschiedene Möglichkeiten, wie die zugehörigen Bestellungen in den Objektzustandsmanager geladen werden. Vom Leistungsstandpunkt aus gesehen ist die wichtigste Frage beim Laden verwandter Entitäten, ob Lazy Loading oder Eager Loading verwendet werden soll.
Bei Verwendung von Eager Loading werden die zugehörigen Entitäten zusammen mit der Zielentitätenmenge geladen. Sie verwenden eine Include-Anweisung in Ihrer Abfrage, um anzugeben, welche verwandten Entitäten Sie einbeziehen möchten.
Bei Verwendung von Lazy Loading wird Ihre anfängliche Abfrage nur die Zielentitätenmenge einbeziehen. Wenn Sie jedoch auf eine Navigationseigenschaft zugreifen, wird eine weitere Abfrage für den Speicher ausgegeben, um die zugehörige Entität zu laden.
Sobald eine Entität geladen wurde, werden alle weiteren Abfragen für die Entität direkt aus dem Objektzustandsmanager geladen, unabhängig davon, ob Sie Lazy Loading oder Eager Loading verwenden.
8.2 Wählen zwischen Lazy Loading und Eager Loading
Es ist wichtig, dass Sie den Unterschied zwischen Lazy Loading und Eager Loading verstehen, damit Sie die richtige Wahl für Ihre Anwendung treffen können. Dies wird Ihnen helfen, den Kompromiss zwischen mehreren Anforderungen an die Datenbank gegenüber einer einzigen Anorderung, die möglicherweise viele Nutzdaten enthält, zu bewerten. Es kann sinnvoll sein, Eager Loading in einigen Teilen Ihrer Anwendung und Lazy Loading in anderen Teilen zu verwenden.
Hier ein Beispiel, was im Hintergrund passiert: Angenommen, Sie möchten die im Vereinigten Königreich lebenden Kunden und die Anzahl ihrer Bestellungen abfragen.
Verwenden des Eager Loading
using (NorthwindEntities context = new NorthwindEntities())
{
var ukCustomers = context.Customers.Include(c => c.Orders).Where(c => c.Address.Country == "UK");
var chosenCustomer = AskUserToPickCustomer(ukCustomers);
Console.WriteLine("Customer Id: {0} has {1} orders", customer.CustomerID, customer.Orders.Count);
}
Verwenden des Lazy Loading
using (NorthwindEntities context = new NorthwindEntities())
{
context.ContextOptions.LazyLoadingEnabled = true;
//Notice that the Include method call is missing in the query
var ukCustomers = context.Customers.Where(c => c.Address.Country == "UK");
var chosenCustomer = AskUserToPickCustomer(ukCustomers);
Console.WriteLine("Customer Id: {0} has {1} orders", customer.CustomerID, customer.Orders.Count);
}
Wenn Sie Eager Loading verwenden, geben Sie eine einzelne Abfrage aus, die alle Kunden und alle Bestellungen zurückgibt. Der Speicherbefehl sieht wie folgt aus:
SELECT
[Project1].[C1] AS [C1],
[Project1].[CustomerID] AS [CustomerID],
[Project1].[CompanyName] AS [CompanyName],
[Project1].[ContactName] AS [ContactName],
[Project1].[ContactTitle] AS [ContactTitle],
[Project1].[Address] AS [Address],
[Project1].[City] AS [City],
[Project1].[Region] AS [Region],
[Project1].[PostalCode] AS [PostalCode],
[Project1].[Country] AS [Country],
[Project1].[Phone] AS [Phone],
[Project1].[Fax] AS [Fax],
[Project1].[C2] AS [C2],
[Project1].[OrderID] AS [OrderID],
[Project1].[CustomerID1] AS [CustomerID1],
[Project1].[EmployeeID] AS [EmployeeID],
[Project1].[OrderDate] AS [OrderDate],
[Project1].[RequiredDate] AS [RequiredDate],
[Project1].[ShippedDate] AS [ShippedDate],
[Project1].[ShipVia] AS [ShipVia],
[Project1].[Freight] AS [Freight],
[Project1].[ShipName] AS [ShipName],
[Project1].[ShipAddress] AS [ShipAddress],
[Project1].[ShipCity] AS [ShipCity],
[Project1].[ShipRegion] AS [ShipRegion],
[Project1].[ShipPostalCode] AS [ShipPostalCode],
[Project1].[ShipCountry] AS [ShipCountry]
FROM ( SELECT
[Extent1].[CustomerID] AS [CustomerID],
[Extent1].[CompanyName] AS [CompanyName],
[Extent1].[ContactName] AS [ContactName],
[Extent1].[ContactTitle] AS [ContactTitle],
[Extent1].[Address] AS [Address],
[Extent1].[City] AS [City],
[Extent1].[Region] AS [Region],
[Extent1].[PostalCode] AS [PostalCode],
[Extent1].[Country] AS [Country],
[Extent1].[Phone] AS [Phone],
[Extent1].[Fax] AS [Fax],
1 AS [C1],
[Extent2].[OrderID] AS [OrderID],
[Extent2].[CustomerID] AS [CustomerID1],
[Extent2].[EmployeeID] AS [EmployeeID],
[Extent2].[OrderDate] AS [OrderDate],
[Extent2].[RequiredDate] AS [RequiredDate],
[Extent2].[ShippedDate] AS [ShippedDate],
[Extent2].[ShipVia] AS [ShipVia],
[Extent2].[Freight] AS [Freight],
[Extent2].[ShipName] AS [ShipName],
[Extent2].[ShipAddress] AS [ShipAddress],
[Extent2].[ShipCity] AS [ShipCity],
[Extent2].[ShipRegion] AS [ShipRegion],
[Extent2].[ShipPostalCode] AS [ShipPostalCode],
[Extent2].[ShipCountry] AS [ShipCountry],
CASE WHEN ([Extent2].[OrderID] IS NULL) THEN CAST(NULL AS int) ELSE 1 END AS [C2]
FROM [dbo].[Customers] AS [Extent1]
LEFT OUTER JOIN [dbo].[Orders] AS [Extent2] ON [Extent1].[CustomerID] = [Extent2].[CustomerID]
WHERE N'UK' = [Extent1].[Country]
) AS [Project1]
ORDER BY [Project1].[CustomerID] ASC, [Project1].[C2] ASC
Wenn Sie Lazy Loading verwenden, geben Sie anfänglich t die folgende Abfrage aus:
SELECT
[Extent1].[CustomerID] AS [CustomerID],
[Extent1].[CompanyName] AS [CompanyName],
[Extent1].[ContactName] AS [ContactName],
[Extent1].[ContactTitle] AS [ContactTitle],
[Extent1].[Address] AS [Address],
[Extent1].[City] AS [City],
[Extent1].[Region] AS [Region],
[Extent1].[PostalCode] AS [PostalCode],
[Extent1].[Country] AS [Country],
[Extent1].[Phone] AS [Phone],
[Extent1].[Fax] AS [Fax]
FROM [dbo].[Customers] AS [Extent1]
WHERE N'UK' = [Extent1].[Country]
Und jedes Mal, wenn Sie auf die Navigationseigenschaft „Bestellungen“ eines Kunden zugreifen, wird eine andere Abfrage wie die folgende für den Speicher ausgegeben:
exec sp_executesql N'SELECT
[Extent1].[OrderID] AS [OrderID],
[Extent1].[CustomerID] AS [CustomerID],
[Extent1].[EmployeeID] AS [EmployeeID],
[Extent1].[OrderDate] AS [OrderDate],
[Extent1].[RequiredDate] AS [RequiredDate],
[Extent1].[ShippedDate] AS [ShippedDate],
[Extent1].[ShipVia] AS [ShipVia],
[Extent1].[Freight] AS [Freight],
[Extent1].[ShipName] AS [ShipName],
[Extent1].[ShipAddress] AS [ShipAddress],
[Extent1].[ShipCity] AS [ShipCity],
[Extent1].[ShipRegion] AS [ShipRegion],
[Extent1].[ShipPostalCode] AS [ShipPostalCode],
[Extent1].[ShipCountry] AS [ShipCountry]
FROM [dbo].[Orders] AS [Extent1]
WHERE [Extent1].[CustomerID] = @EntityKeyValue1',N'@EntityKeyValue1 nchar(5)',@EntityKeyValue1=N'AROUT'
Weitere Informationen finden Sie unter Laden von verknüpften Objekten.
8.2.1 Lazy Loading versus Eager Loading – Spickzettel
Es gibt kein Patentrezept für die Entscheidung zwischen Eager Loading und Lazy Loading. Versuchen Sie zunächst, die Unterschiede zwischen den beiden Strategien zu verstehen, damit Sie eine fundierte Entscheidung treffen können. Überlegen Sie außerdem, ob Ihr Code zu einem der folgenden Szenarien passt:
| Szenario | Unser Vorschlag |
|---|---|
| Müssen Sie auf viele Navigationseigenschaften der abgerufenen Entitäten zugreifen? | Nein – Beide Optionen sind wahrscheinlich geeignet. Wenn die Ihrer Abfrage bereitgestellten Nutzdaten jedoch nicht zu groß sind, können Leistungsvorteile auftreten, indem Sie Eager Loading verwenden, da weniger Netzwerk-Roundtrips erforderlich sind, um Ihre Objekte zu materialisieren. Ja – Wenn Sie auf viele Navigationseigenschaften aus den Entitäten zugreifen müssen, würden Sie dies tun, indem Sie mehrere „Include“-Anweisungen mit Eager Loading in Ihrer Abfrage verwenden. Je mehr Entitäten Sie einbeziehen, desto größer werden die Nutzdaten, die Ihre Abfrage zurückgeben wird. Sobald Sie drei oder mehr Entitäten in Ihre Abfrage einbeziehen, sollten Sie in Betracht ziehen, zum Lazy Loading zu wechseln. |
| Wissen Sie genau, welche Daten zur Laufzeit benötigt werden? | Nein – Lazy Loading wird für Sie besser geeignet sein. Andernfalls kann es passieren, dass Sie Daten abfragen, die Sie nicht benötigen werden. Ja – Eager Loading ist wahrscheinlich Ihre beste Wahl, denn dadurch können ganze Sätze schneller geladen werden. Wenn ihre Abfrage erfordert, eine sehr große Datenmenge abzurufen und dies zu langsam wird, versuchen Sie stattdessen Lazy Loading. |
| Wird Ihr Code weit weg von Ihrer Datenbank ausgeführt? (erhöhte Netzwerkwartezeit) | Nein – Wenn die Netzwerkwartezeit kein Problem ist, kann die Verwendung von Lazy Loading Ihren Code vereinfachen. Denken Sie daran, dass sich die Topologie Ihrer Anwendung ändern kann, nehmen Sie also die Nähe zur Datenbank nicht als gegeben hin. Ja – Wenn das Netzwerk ein Problem darstellt, können nur Sie entscheiden, was für Ihr Szenario besser geeignet ist. Normalerweise ist Eager Loading besser geeignet, da weniger Roundtrips erforderlich sind. |
8.2.2 Leistungsprobleme mit mehreren Includes
Wenn wir Fragen zur Leistung hören, die Antwortzeitprobleme von Servern beinhalten, liegt die Ursache des Problems häufig in Abfragen mit mehreren Include-Anweisungen. Die Einbeziehung verwandter Entitäten in eine Abfrage ist zwar leistungsstark, aber es ist wichtig zu verstehen, was hinter den Kulissen geschieht.
Es dauert relativ lange, bis eine Abfrage mit mehreren Include-Anweisungen unseren internen Plancompiler durchlaufen hat, um den Speicherbefehl zu erstellen. Der Großteil dieser Zeit wird aufgewendet, um die resultierende Abfrage zu optimieren. Der generierte Speicherbefehl wird je nach Ihrer Zuordnung eine äußere Verknüpfung oder Union für jeden Include enthalten. Abfragen wie diese werden große verbundene Diagramme aus Ihrer Datenbank in eine einzige Payload bringen, was Bandbreitenprobleme verschärfen wird, insbesondere wenn die Nutzdaten sehr redundant sind (z. B. wenn mehrere Ebenen von „Include“ verwendet werden, um Zuordnungen in 1:n-Richtung zu durchlaufen).
Sie können Fälle prüfen, in denen Ihre Abfragen übermäßig große Nutzdaten zurückgeben, indem Sie mithilfe von ToTraceString auf die zugrunde liegende TSQL für die Abfrage zugreifen und den Speicherbefehl in SQL Server Management Studio ausführen, um die Nutzdatengröße anzuzeigen. In solchen Fällen können Sie versuchen, die Anzahl der Include-Anweisungen in Ihrer Abfrage zu reduzieren, um nur die benötigten Daten einzuschließen. Oder Sie können Ihre Abfrage möglicherweise in eine kleinere Abfolge von Unterabfragen aufteilen, beispielsweise:
Vor dem Unterbrechen der Abfrage:
using (NorthwindEntities context = new NorthwindEntities())
{
var customers = from c in context.Customers.Include(c => c.Orders)
where c.LastName.StartsWith(lastNameParameter)
select c;
foreach (Customer customer in customers)
{
...
}
}
Nach dem Unterbrechen der Abfrage:
using (NorthwindEntities context = new NorthwindEntities())
{
var orders = from o in context.Orders
where o.Customer.LastName.StartsWith(lastNameParameter)
select o;
orders.Load();
var customers = from c in context.Customers
where c.LastName.StartsWith(lastNameParameter)
select c;
foreach (Customer customer in customers)
{
...
}
}
Dies wird nur bei nachverfolgten Abfragen funktionieren, da wir die Fähigkeit des Kontexts nutzen, Identitätsauflösung und Zuordnungskorrekturen automatisch durchzuführen.
Wie beim Lazy Loading wird der Kompromiss darin bestehen, dass es mehr Abfragen für kleinere Nutzdaten gibt. Sie können auch Projektionen einzelner Eigenschaften verwenden, um explizit nur die Daten auszuwählen, die Sie aus jeder Entität benötigen, aber in diesem Fall werden keine Entitäten geladen, und Updates werden nicht unterstützt.
8.2.3 Problemumgehung zum Lazy Loading von Eigenschaften
Entity Framework unterstützt derzeit kein Lazy Loading von skalaren oder komplexen Eigenschaften. Wenn Sie jedoch über eine Tabelle verfügen, die ein großes Objekt wie z. B. ein BLOB enthält, können Sie die Tabellenaufteilung verwenden, um die großen Eigenschaften in eine separate Entität zu trennen. Nehmen wir zum Beispiel an, Sie haben eine Produkttabelle, die eine Fotospalte vom Typ „varbinary“ enthält. Wenn Sie in Ihren Abfragen nicht häufig auf diese Eigenschaft zugreifen müssen, können Sie die Tabellenaufteilung verwenden, um nur die Teile der Entität einzubinden, die Sie normalerweise benötigen. Die Entität, die das Produktfoto darstellt, wird nur geladen werden, wenn Sie es explizit benötigen.
Eine gute Ressource, die zeigt, wie die Tabellenaufteilung aktiviert wird, ist der Blogbeitrag „Tabellenaufteilung in Entity Framework“ von Gil Fink: <http://blogs.microsoft.co.il/blogs/gilf/archive/2009/10/13/table-splitting-in-entity-framework.aspx>.
9 Andere Überlegungen
9.1 Garbage Collection für Server
Bei einigen Benutzern tritt möglicherweise ein Ressourcenkonflikt auf, der die von ihnen erwartete Parallelität begrenzt, wenn der Garbage Collector nicht ordnungsgemäß konfiguriert ist. Wenn EF in einem Multithread-Szenario oder in einer Anwendung verwendet wird, die einem serverseitigen System ähnelt, müssen Sie sicherstellen, dass Garbage Collection für Server aktiviert ist. Dies erfolgt über eine einfache Einstellung in Ihrer Anwendungskonfigurationsdatei:
<?xmlversion="1.0" encoding="utf-8" ?>
<configuration>
<runtime>
<gcServer enabled="true" />
</runtime>
</configuration>
Dies sollte Ihre Thread-Konkurrenz verringern und Ihren Durchsatz in Szenarien mit gesättigter CPU um bis zu 30 % erhöhen. Generell sollten Sie immer testen, wie sich Ihre Anwendung mit der klassischen Garbage Collection (die besser für Benutzeroberflächen- und clientseitige Szenarien optimiert ist) und der Garbage Collection für Server verhält.
9.2 AutoDetectChanges
Wie bereits früher erwähnt, zeigt Entity Framework möglicherweise Leistungsprobleme an, wenn der Objektcache über viele Entitäten verfügt. Bestimmte Vorgänge, z. B. Add, Remove, Find, Entry und SaveChanges, lösen Aufrufe von DetectChanges aus, die je nach Größe des Objektcaches möglicherweise eine große CPU-Menge verbrauchen. Der Grund dafür ist, dass der Objektcache und der Objektzustandsmanager versuchen, für jeden Vorgang, der in einem Kontext ausgeführt wird, so synchronisiert wie möglich zu bleiben, damit die erzeugten Daten garantiert unter einer Vielzahl von Szenarien korrekt sind.
Generell ist es eine gute Praxis, die automatische Änderungserkennung von Entity Framework für die gesamte Lebensdauer Ihrer Anwendung aktiviert zu lassen. Wenn Ihr Szenario durch eine hohe CPU-Auslastung negativ beeinträchtigt wird und Ihre Profile darauf hindeuten, dass der Aufruf von DetectChanges daran schuld ist, sollten Sie erwägen, AutoDetectChanges im sensiblen Teil Ihres Codes vorübergehend zu deaktivieren:
try
{
context.Configuration.AutoDetectChangesEnabled = false;
var product = context.Products.Find(productId);
...
}
finally
{
context.Configuration.AutoDetectChangesEnabled = true;
}
Bevor Sie AutoDetectChanges deaktivieren, sollten Sie sich darüber im Klaren sein, dass Entity Framework dadurch möglicherweise die Fähigkeit verliert, bestimmte Informationen über die an den Entitäten vorgenommenen Änderungen zu verfolgen. Bei unsachgemäßer Handhabung kann dies zu Dateninkonsistenzen in Ihrer Anwendung führen. Weitere Informationen zum Deaktivieren von AutoDetectChanges finden Sie unter <http://blog.oneunicorn.com/2012/03/12/secrets-of-detectchanges-part-3-switching-off-automatic-detectchanges/>.
9.3 Kontext pro Anforderung
Die Kontexte von Entity Framework sollen als kurzlebige Instanzen verwendet werden, um die optimale Leistungserfahrung zu bieten. Es wird erwartet, dass Kontexte kurzlebig und verworfen werden. Daher wurden sie so implementiert, dass sie möglichst einfach sind und Metadaten wann immer möglich wiederverwenden. In Webszenarien ist es wichtig, dies zu berücksichtigen und einen Kontext nicht länger als für die Dauer einer einzigen Anforderung zu verwenden. Ebenso sollte der Kontext in Nicht-Web-Szenarien basierend auf Ihrem Verständnis der verschiedenen Ebenen des Zwischenspeicherns im Entity Framework verworfen werden. Ganz generell sollte man es vermeiden, während der gesamten Lebensdauer der Anwendung eine Kontextinstanz zu haben, ebenso wie Kontexte pro Thread und statische Kontexte.
9.4 Datenbank-NULL-Semantik
Entity Framework wird standardmäßig SQL-Code mit C#-NULL-Vergleichssemantik generieren. Betrachten Sie die folgende Beispielabfrage:
int? categoryId = 7;
int? supplierId = 8;
decimal? unitPrice = 0;
short? unitsInStock = 100;
short? unitsOnOrder = 20;
short? reorderLevel = null;
var q = from p incontext.Products
where p.Category.CategoryName == "Beverages"
|| (p.CategoryID == categoryId
|| p.SupplierID == supplierId
|| p.UnitPrice == unitPrice
|| p.UnitsInStock == unitsInStock
|| p.UnitsOnOrder == unitsOnOrder
|| p.ReorderLevel == reorderLevel)
select p;
var r = q.ToList();
In diesem Beispiel vergleichen wir eine Reihe von Nullwerte zulassenden Variablen mit Nullwerte zulassenden Eigenschaften für die Entität, z. B. SupplierID und UnitPrice. Die generierte SQL für diese Abfrage wird abfragen, ob der Parameterwert mit dem Spaltenwert identisch ist oder ob sowohl die Parameter- als auch die Spaltenwerte NULL sind. Dadurch wird die Art und Weise ausgeblendet, wie der Datenbankserver NULL-Werten umgeht, und es wird eine konsistente C#-NULL-Erfahrung für verschiedene Datenbankanbieter ermöglicht. Andererseits ist der generierte Code etwas unübersichtlich und möglicherweise nicht leistungsfähig, wenn die Menge der Vergleiche in der WHERE-Anweisung der Abfrage zu groß wird.
Eine Möglichkeit zum Umgang mit dieser Situation ist die Verwendung der Datenbank-NULL-Semantik. Beachten Sie, dass sich dies möglicherweise anders verhält als die C#-NULL-Semantik, da Entity Framework jetzt einfachere SQL generiert, welche die Art und Weise verfügbar macht, wie das Datenbankmodul NULL-Werte verarbeitet. Die Datenbank-NULL-Semantik kann pro Kontext mit einer einzigen Konfigurationszeile für die Kontextkonfiguration aktiviert werden:
context.Configuration.UseDatabaseNullSemantics = true;
Bei kleinen bis mittelgroßen Abfragen wird die Leistungsverbesserung bei Verwendung der Datenbank-NULL-Semantik nicht spürbar sein, bei Abfragen mit einer großen Anzahl potenzieller NULL-Vergleiche wird der Unterschied jedoch deutlicher.
In der obigen Beispielabfrage lag der Leistungsunterschied in einer Mikrobenchmark, die in einer kontrollierten Umgebung ausgeführt wurde, bei weniger als 2 %.
9.5 Asynchron
Mit Entity Framework 6 wurde der Support für asynchrone Vorgänge eingeführt, wenn sie auf .NET 4.5 oder höher ausgeführt werden. In den meisten Fällen profitieren Anwendungen mit IO-bezogenen Konflikten am meisten von der Verwendung asynchroner Abfrage- und Speichervorgänge. Wenn Ihre Anwendung nicht unter IO-Konflikten leidet, wird die Verwendung von asynchron im besten Fall synchron ausgeführt und das Ergebnis in der gleichen Zeit zurückgegeben wie ein synchroner Aufruf, oder im schlimmsten Fall wird die Ausführung einfach auf eine asynchrone Aufgabe verschoben und wird zusätzliche Zeit für die Fertigstellung Ihres Szenarios benötigen.
Informationen zur Funktionsweise der asynchronen Programmierung, die Ihnen bei der Entscheidung helfen, ob asynchron die Leistung Ihrer Anwendung verbessern wird, finden Sie unter Asynchrone Programmierung mit „Async“ und „Await“. Weitere Informationen zur Verwendung von asynchronen Vorgängen in Entity Framework finden Sie unter Asynchrone Abfrage und Speichern.
9.6 NGEN
Entity Framework 6 ist nicht in der Standardinstallation von .NET-Framework enthalten. Daher sind die Entity Framework-Assemblys nicht standardmäßig als NGEN verarbeitet, was bedeutet, dass der gesamte Entity Framework-Code den gleichen Just-In-Time-Verarbeitungskosten wie jede andere MSIL-Assembly unterliegt. Dies kann die F5-Erfahrung während der Entwicklung und auch den Kaltstart Ihrer Anwendung in den Produktionsumgebungen beeinträchtigen. Um die CPU- und Speicherkosten der Just-In-Time-Verarbeitung zu reduzieren, ist es ratsam, die Entity Framework-Images nach Bedarf als NGEN zu verarbeiten. Weitere Informationen zur Verbesserung der Startleistung von Entity Framework 6 mit NGEN finden Sie unter Verbessern der Startleistung mit NGen.
9.7 Code First im Vergleich zu EDMX
Entity Framework löst das Impedanzdiskrepanzproblem zwischen objektorientierter Programmierung und relationalen Datenbanken, indem es eine arbeitsspeicherinterne Darstellung des konzeptionellen Modells (der Objekte), des Speicherschemas (der Datenbank) und eine Zuordnung zwischen beiden bietet. Diese Metadaten werden kurz als Entity Data Model oder kurz EDM bezeichnet. Aus diesem EDM wird Entity Framework die Ansichten ableiten, um Daten aus den Objekten im Arbeitsspeicher in die Datenbank und zurück zu transportieren.
Wenn Entity Framework mit einer EDMX-Datei verwendet wird, die formell das konzeptionelle Modell, das Speicherschema und die Zuordnung angibt, muss die Ladephase des Modells nur überprüfen, ob EDM korrekt ist (beispielsweise sicherstellen, dass keine Zuordnungen fehlen), dann die Ansichten generieren und validieren und diese Metadaten zur Verwendung bereitstellen. Erst dann kann eine Abfrage ausgeführt oder neue Daten im Datenspeicher gespeichert werden.
Der Code First-Ansatz ist im Kern ein hoch entwickelter Entity Data Model-Generator. Das Entity Framework muss einen EDM aus dem bereitgestellten Code erstellen. Dies geschieht, indem es die Klassen analysiert, die am Modell beteiligt sind, Konventionen anwendet und das Modell über die Fluent-API konfiguriert. Nachdem das EDM erstellt wurde, verhält sich das Entity Framework im Wesentlichen genauso, als wäre eine EDMX-Datei im Projekt vorhanden gewesen. Daher fügt das Erstellen des Modells aus Code First zusätzliche Komplexität hinzu, die sich im Vergleich zu einem EDMX in einer langsameren Startzeit für das Entity Framework niederschlägt. Die Kosten hängen vollständig von der Größe und Komplexität des Modells ab, das erstellt wird.
Bei der Wahl, EDMX anstelle von Code First zu verwenden, ist es wichtig zu wissen, dass die von Code First eingeführte Flexibilität die Kosten für die erstmalige Erstellung des Modells Mal erhöht. Wenn Ihre Anwendung die Kosten für diese erstmalige Last verkraften kann, ist Code First in der Regel die bessere Wahl.
10 Untersuchung der Leistung
10.1 Verwenden des Visual Studio-Profilers
Wenn Sie Leistungsprobleme mit dem Entity Framework haben, können Sie einen Profiler wie den in Visual Studio integrierten Profiler verwenden, um zu sehen, wo Ihre Anwendung ihre Zeit verbringt. Dies ist das Tool, mit dem wir die Kreisdiagramme im Blogbeitrag „Untersuchen der Leistung des ADO.NET-Entity Framework – Teil 1" ( <https://learn.microsoft.com/archive/blogs/adonet/exploring-the-performance-of-the-ado-net-entity-framework-part-1>) generiert haben, die zeigen, wo Entity Framework seine Zeit bei kalten und warmen Abfragen verbringt.
Der Blogbeitrag „Profilerstellung für das Entity Framework mithilfe des Visual Studio 2010-Profilers“, der vom Team „Data and Modeling Customer Advisory“ geschrieben wurde, zeigt ein reales Beispiel für die Verwendung des Profilers zur Untersuchung eines Leistungsproblems. <https://learn.microsoft.com/archive/blogs/dmcat/profiling-entity-framework-using-the-visual-studio-2010-profiler>. Dieser Beitrag wurde für eine Windows-Anwendung geschrieben. Wenn Sie eine Webanwendung profilieren müssen, funktionieren die Tools Windows-Leistungsaufzeichnung (Windows Performance Recorder, WPR) und Windows-Leistungsanalyse (Windows Performance Analyzer, WPA) möglicherweise besser als das Arbeiten mit Visual Studio. WPR und WPA sind Teil des Windows Performance Toolkit, das im Windows ADK (Assessment and Deployment Kit) enthalten ist.
10.2 Anwendungs-/Datenbankprofilerstellung
Tools wie der in Visual Studio integrierte Profiler teilen Ihnen mit, wo Ihre Anwendung Zeit verbringt. Eine andere Art von Profiler ist verfügbar, der eine dynamische Analyse Ihrer laufenden Anwendung ausführt, je nach Bedarf entweder in der Produktion oder der Vorproduktion, und nach häufigen Fallstricken und Antimustern des Datenbankzugriffs sucht.
Zwei kommerziell verfügbare Profiler sind der Entity Framework-Profiler ( <http://efprof.com>) und der ORMProfiler ( <http://ormprofiler.com>).
Wenn Ihre Anwendung eine MVC-Anwendung mit Code First ist, können Sie den MiniProfiler von StackExchange verwenden. Scott Hanselman beschreibt dieses Tool in seinem Blog unter: <http://www.hanselman.com/blog/NuGetPackageOfTheWeek9ASPNETMiniProfilerFromStackExchangeRocksYourWorld.aspx>.
Weitere Informationen zur Profilerstellung der Datenbankaktivitäten Ihrer Anwendung finden Sie im MSDN Magazine-Artikel von Julie Lerman mit dem Titel Profilerstellung der Datenbankaktivitäten im Entity Framework.
10.3 Datenbankprotokollierung
Wenn Sie Entity Framework 6 verwenden, sollten Sie auch die integrierte Protokollierungsfunktion verwenden. Die Datenbankeigenschaft des Kontexts kann über eine einfache einzeilige Konfiguration angewiesen werden, ihre Aktivitäten zu protokollieren:
using (var context = newQueryComparison.DbC.NorthwindEntities())
{
context.Database.Log = Console.WriteLine;
var q = context.Products.Where(p => p.Category.CategoryName == "Beverages");
q.ToList();
}
In diesem Beispiel wird die Datenbankaktivität in der Konsole protokolliert, aber die Protokolleigenschaft kann so konfiguriert werden, dass ein beliebiger Aktions-<Zeichenfolge>-Delegat aufgerufen wird.
Wenn Sie die Datenbankprotokollierung ohne erneute Kompilierung aktivieren möchten und Entity Framework 6.1 oder höher verwenden, können Sie dies tun, indem Sie einen Interceptor in der Datei „web.config“ oder „app.config“ Ihrer Anwendung hinzufügen.
<interceptors>
<interceptor type="System.Data.Entity.Infrastructure.Interception.DatabaseLogger, EntityFramework">
<parameters>
<parameter value="C:\Path\To\My\LogOutput.txt"/>
</parameters>
</interceptor>
</interceptors>
Weitere Informationen zum Hinzufügen der Protokollierung ohne erneutes Kompilieren finden Sie unter <http://blog.oneunicorn.com/2014/02/09/ef-6-1-turning-on-logging-without-recompiling/>.
11 Anhang
11.1 A. Testumgebung
Diese Umgebung verwendet ein 2-Computer-Setup mit der Datenbank auf einem von der Clientanwendung separaten Computer. Computer befinden sich im gleichen Rack, sodass die Netzwerkwartezeit relativ niedrig ist, aber realistischer als in einer Einzelcomputerumgebung.
11.1.1 App-Server
11.1.1.1 Softwareumgebung
- Entity Framework 4-Softwareumgebung
- Betriebssystemname: Windows Server 2008 R2 Enterprise SP1.
- Visual Studio 2010 – Ultimate.
- Visual Studio 2010 SP1 (nur für einige Vergleiche).
- Entity Framework 5- und 6-Softwareumgebung
- Betriebssystemname: Windows 8.1 Enterprise
- Visual Studio 2013 – Ultimate.
11.1.1.2 Hardwareumgebung
- Dualer Prozessor: Intel(R) Xeon(R) CPU L5520 W3530 @ 2.27GHz, 2261 Mhz8 GHz, 4 Kern(e), 84 Logische(r) Prozessor(en).
- 2412 GB RAM.
- 136 GB SCSI250GB SATA 7200 rpm 3GB/s-Laufwerk aufgeteilt in 4 Partitionen.
11.1.2 DB-Server
11.1.2.1 Softwareumgebung
- Betriebssystemname: Windows Server 2008 R28.1 Enterprise SP1.
- SQL Server 2008 R2 2012.
11.1.2.2 Hardwareumgebung
- Einzelprozessor: Intel(R) Xeon(R) CPU L5520 @ 2.27GHz, 2261 MhzES-1620 0 @ 3.60GHz, 4 Kern(e), 8 Logische(r) Prozessor(en).
- 824 GB RAM.
- 465 GB ATA500GB SATA 7200 rpm 6GB/s-Laufwerk aufgeteilt in 4 Partitionen.
11.2 B. Vergleichstests zur Abfrageleistung
Das Northwind-Modell wurde verwendet, um diese Tests auszuführen. Es wurde mithilfe des Entity Framework-Designers aus der Datenbank generiert. Dann wurde der folgende Code verwendet, um die Leistung der Abfrageausführungsoptionen zu vergleichen:
using System;
using System.Collections.Generic;
using System.Data;
using System.Data.Common;
using System.Data.Entity.Infrastructure;
using System.Data.EntityClient;
using System.Data.Objects;
using System.Linq;
namespace QueryComparison
{
public partial class NorthwindEntities : ObjectContext
{
private static readonly Func<NorthwindEntities, string, IQueryable<Product>> productsForCategoryCQ = CompiledQuery.Compile(
(NorthwindEntities context, string categoryName) =>
context.Products.Where(p => p.Category.CategoryName == categoryName)
);
public IQueryable<Product> InvokeProductsForCategoryCQ(string categoryName)
{
return productsForCategoryCQ(this, categoryName);
}
}
public class QueryTypePerfComparison
{
private static string entityConnectionStr = @"metadata=res://*/Northwind.csdl|res://*/Northwind.ssdl|res://*/Northwind.msl;provider=System.Data.SqlClient;provider connection string='data source=.;initial catalog=Northwind;integrated security=True;multipleactiveresultsets=True;App=EntityFramework'";
public void LINQIncludingContextCreation()
{
using (NorthwindEntities context = new NorthwindEntities())
{
var q = context.Products.Where(p => p.Category.CategoryName == "Beverages");
q.ToList();
}
}
public void LINQNoTracking()
{
using (NorthwindEntities context = new NorthwindEntities())
{
context.Products.MergeOption = MergeOption.NoTracking;
var q = context.Products.Where(p => p.Category.CategoryName == "Beverages");
q.ToList();
}
}
public void CompiledQuery()
{
using (NorthwindEntities context = new NorthwindEntities())
{
var q = context.InvokeProductsForCategoryCQ("Beverages");
q.ToList();
}
}
public void ObjectQuery()
{
using (NorthwindEntities context = new NorthwindEntities())
{
ObjectQuery<Product> products = context.Products.Where("it.Category.CategoryName = 'Beverages'");
products.ToList();
}
}
public void EntityCommand()
{
using (EntityConnection eConn = new EntityConnection(entityConnectionStr))
{
eConn.Open();
EntityCommand cmd = eConn.CreateCommand();
cmd.CommandText = "Select p From NorthwindEntities.Products As p Where p.Category.CategoryName = 'Beverages'";
using (EntityDataReader reader = cmd.ExecuteReader(CommandBehavior.SequentialAccess))
{
List<Product> productsList = new List<Product>();
while (reader.Read())
{
DbDataRecord record = (DbDataRecord)reader.GetValue(0);
// 'materialize' the product by accessing each field and value. Because we are materializing products, we won't have any nested data readers or records.
int fieldCount = record.FieldCount;
// Treat all products as Product, even if they are the subtype DiscontinuedProduct.
Product product = new Product();
product.ProductID = record.GetInt32(0);
product.ProductName = record.GetString(1);
product.SupplierID = record.GetInt32(2);
product.CategoryID = record.GetInt32(3);
product.QuantityPerUnit = record.GetString(4);
product.UnitPrice = record.GetDecimal(5);
product.UnitsInStock = record.GetInt16(6);
product.UnitsOnOrder = record.GetInt16(7);
product.ReorderLevel = record.GetInt16(8);
product.Discontinued = record.GetBoolean(9);
productsList.Add(product);
}
}
}
}
public void ExecuteStoreQuery()
{
using (NorthwindEntities context = new NorthwindEntities())
{
ObjectResult<Product> beverages = context.ExecuteStoreQuery<Product>(
@" SELECT P.ProductID, P.ProductName, P.SupplierID, P.CategoryID, P.QuantityPerUnit, P.UnitPrice, P.UnitsInStock, P.UnitsOnOrder, P.ReorderLevel, P.Discontinued
FROM Products AS P INNER JOIN Categories AS C ON P.CategoryID = C.CategoryID
WHERE (C.CategoryName = 'Beverages')"
);
beverages.ToList();
}
}
public void ExecuteStoreQueryDbContext()
{
using (var context = new QueryComparison.DbC.NorthwindEntities())
{
var beverages = context.Database.SqlQuery\<QueryComparison.DbC.Product>(
@" SELECT P.ProductID, P.ProductName, P.SupplierID, P.CategoryID, P.QuantityPerUnit, P.UnitPrice, P.UnitsInStock, P.UnitsOnOrder, P.ReorderLevel, P.Discontinued
FROM Products AS P INNER JOIN Categories AS C ON P.CategoryID = C.CategoryID
WHERE (C.CategoryName = 'Beverages')"
);
beverages.ToList();
}
}
public void ExecuteStoreQueryDbSet()
{
using (var context = new QueryComparison.DbC.NorthwindEntities())
{
var beverages = context.Products.SqlQuery(
@" SELECT P.ProductID, P.ProductName, P.SupplierID, P.CategoryID, P.QuantityPerUnit, P.UnitPrice, P.UnitsInStock, P.UnitsOnOrder, P.ReorderLevel, P.Discontinued
FROM Products AS P INNER JOIN Categories AS C ON P.CategoryID = C.CategoryID
WHERE (C.CategoryName = 'Beverages')"
);
beverages.ToList();
}
}
public void LINQIncludingContextCreationDbContext()
{
using (var context = new QueryComparison.DbC.NorthwindEntities())
{
var q = context.Products.Where(p => p.Category.CategoryName == "Beverages");
q.ToList();
}
}
public void LINQNoTrackingDbContext()
{
using (var context = new QueryComparison.DbC.NorthwindEntities())
{
var q = context.Products.AsNoTracking().Where(p => p.Category.CategoryName == "Beverages");
q.ToList();
}
}
}
}
11.3 C. Navision-Modell
Die Navision-Datenbank ist eine große Datenbank, die zur Demonstration von Microsoft Dynamics – NAV verwendet wird. Das generierte konzeptionelle Modell enthält 1005 Sätze in der Entitätenmenge und 4227 Zuordnungssätze. Das im Test verwendete Modell ist „flach“ – es wurde keine Vererbung hinzugefügt.
11.3.1 Für Navision-Tests verwendete Abfragen
Die mit dem Navision-Modell verwendete Abfrageliste enthält drei Kategorien von Entity SQL-Abfragen:
11.3.1.1 Nachschlagevorgang
Eine einfache Nachschlageabfrage ohne Aggregationen
- Anzahl: 16 232
- Beispiel:
<Query complexity="Lookup">
<CommandText>Select value distinct top(4) e.Idle_Time From NavisionFKContext.Session as e</CommandText>
</Query>
11.3.1.2 SingleAggregating
Eine normale BI-Abfrage mit mehreren Aggregationen, aber keine Teilergebnisse (einzelne Abfrage)
- Anzahl: 2313
- Beispiel:
<Query complexity="SingleAggregating">
<CommandText>NavisionFK.MDF_SessionLogin_Time_Max()</CommandText>
</Query>
Dabei wird MDF_SessionLogin_Time_Max() im Modell wie folgt definiert:
<Function Name="MDF_SessionLogin_Time_Max" ReturnType="Collection(DateTime)">
<DefiningExpression>SELECT VALUE Edm.Min(E.Login_Time) FROM NavisionFKContext.Session as E</DefiningExpression>
</Function>
11.3.1.3 AggregatingSubtotals
Eine BI-Abfrage mit Aggregationen und Teilergebnissen (über „union all“)
- Anzahl: 178
- Beispiel:
<Query complexity="AggregatingSubtotals">
<CommandText>
using NavisionFK;
function AmountConsumed(entities Collection([CRONUS_International_Ltd__Zone])) as
(
Edm.Sum(select value N.Block_Movement FROM entities as E, E.CRONUS_International_Ltd__Bin as N)
)
function AmountConsumed(P1 Edm.Int32) as
(
AmountConsumed(select value e from NavisionFKContext.CRONUS_International_Ltd__Zone as e where e.Zone_Ranking = P1)
)
----------------------------------------------------------------------------------------------------------------------
(
select top(10) Zone_Ranking, Cross_Dock_Bin_Zone, AmountConsumed(GroupPartition(E))
from NavisionFKContext.CRONUS_International_Ltd__Zone as E
where AmountConsumed(E.Zone_Ranking) > @MinAmountConsumed
group by E.Zone_Ranking, E.Cross_Dock_Bin_Zone
)
union all
(
select top(10) Zone_Ranking, Cast(null as Edm.Byte) as P2, AmountConsumed(GroupPartition(E))
from NavisionFKContext.CRONUS_International_Ltd__Zone as E
where AmountConsumed(E.Zone_Ranking) > @MinAmountConsumed
group by E.Zone_Ranking
)
union all
{
Row(Cast(null as Edm.Int32) as P1, Cast(null as Edm.Byte) as P2, AmountConsumed(select value E
from NavisionFKContext.CRONUS_International_Ltd__Zone as E
where AmountConsumed(E.Zone_Ranking) > @MinAmountConsumed))
}</CommandText>
<Parameters>
<Parameter Name="MinAmountConsumed" DbType="Int32" Value="10000" />
</Parameters>
</Query>