Ähnliche Kunden mit KI finden (Vorschauversion)
[Dieser Artikel ist Teil der Dokumentation zur Vorabversion und kann geändert werden.]
Finden Sie mithilfe künstlicher Intelligenz ähnliche Kunden in Ihrem Kundenstamm. Sie müssen mindestens ein Segment erstellt haben, um diese Funktion nutzen zu können. Durch Erweitern der Kriterien eines vorhandenen Segments können Sie Kunden finden, die diesem Segment ähnlich sind.
Notiz
Finden Sie ähnliche Kunden verwendet automatisierte Mittel, um Daten auszuwerten und auf der Grundlage dieser Daten Vorhersagen zu treffen. Daher kann es als Methode zur Profilerstellung verwendet werden, da dieser Begriff in verschiedenen Datenschutzgesetzen und -bestimmungen definiert ist. Die Verwendung dieses Features zur Verarbeitung von Daten durch die Kundschaft unterliegt möglicherweise diesen Gesetzen oder Bestimmungen. Sie sind dafür verantwortlich, dass Ihre Dynamics 365 Customer Insights - Data-Nutzung, einschließlich der Vorhersagen, allen geltenden Gesetzen und Vorschriften entspricht, einschließlich Gesetzen in Bezug auf Privatsphäre, personenbezogene Daten, biometrische Daten, Datenschutz und Vertraulichkeit der Kommunikation.
Ähnliche Kunden finden
Gehen Sie zu Erkenntnisse>Segmente und wählen Sie das Segment aus, auf das Sie Ihr neues Segment stützen möchten. Das ist Ihr Quellensegment.
Ähnliche Kunden finden auswählen
Überprüfen Sie den vorgeschlagenen Namen für Ihr neues Segment und ändern Sie ihn gegebenenfalls.
Fügen Sie optional Tags zum neuen Segment hinzu.
Überprüfen Sie die Felder, die Ihr neues Segment definieren. Diese Felder definieren die Basis, auf der das System versucht, ähnliche Kunden wie Ihr Quellsegment zu finden. Das System wählt standardmäßig empfohlene Felder aus. Fügen Sie bei Bedarf weitere Felder hinzu. Felder, die die Modellleistung erheblich reduzieren können, werden automatisch ausgeschlossen:
- Felder mit den folgenden Datentypen: StringType, BooleanType, CharType, LongType, IntType, DoubleType, FloatType, ShortType
- Felder mit einer Kardinalität (Anzahl der Elemente in einem Feld) von weniger als 2 oder mehr als 30
Wählen Sie aus, ob Sie Alle Kunden einschließen möchten ausschließlich der Quellsegmente oder nur Kunden in einem Anderes Segment in Ihrem neuen Segment.
Standardmäßig schlägt das System vor, nur 20 % der Zielgruppe in Ihre Ausgabe aufzunehmen. Bearbeiten Sie diesen Schwellenwert nach Bedarf. Durch Erhöhen des Schwellenwerts wird die Genauigkeit verringert.
Beziehen Sie Kunden in Ihr Quellensegment ein, indem Sie das Kontrollkästchen Mitglieder aus dem Quellsegment zusätzlich zu Kunden mit ähnlichen Attributen einbeziehen auswählen.
Wählen Sie Ausführen am Ende der Seite, um eine binäre Klassifizierungsaufgabe (eine Methode von Maschinellem Lernen) zu starten, die das Datenset analysiert.
Sehen Sie sich das ähnliche Segment an
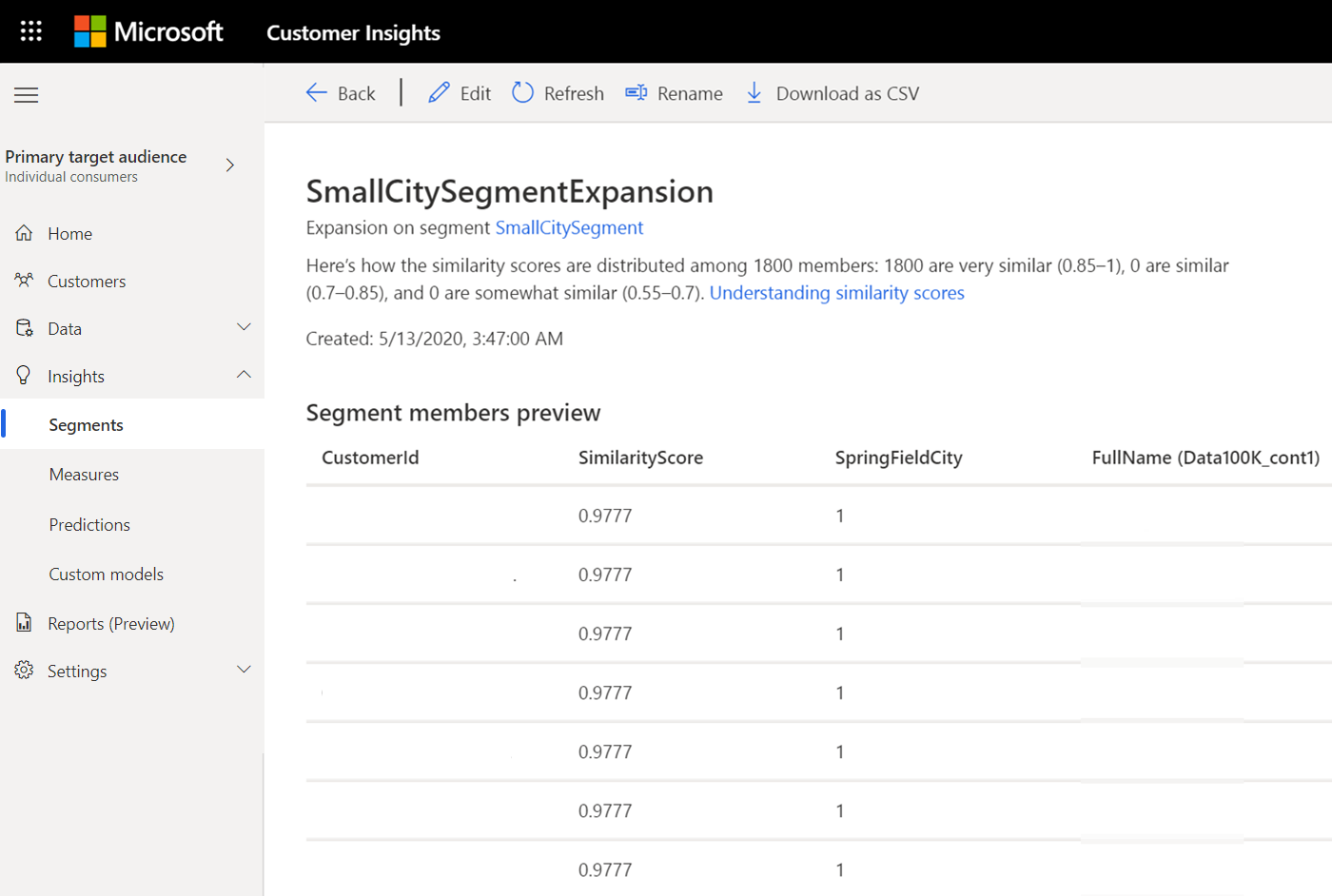
Nach der Verarbeitung des ähnlichen Segments finden Sie das neue Segment auf der Seite Erkenntnisse>Segmente mit dem Typ Erweiterung.
Wählen Sie Ansicht aus. um die Ergebnisverteilung über Ähnlichkeitsbewertung und Ähnlichkeitswert unter Vorschau der Segmentmitglieder anzuzeigen.
Ein ähnliches Segment verwalten
Mit der Ausgabe eines ähnlichen Segments arbeiten und dieses verwalten, wie Sie es mit anderen Segmenten tun. Exportieren Sie beispielsweise das Segment oder erstellen Sie eine Kennzahl.
Bearbeiten, aktualisieren, umbenennen, herunterladen und löschen eines ähnlichen Segments. Durch Bearbeiten eines ähnlichen Segments werden Ihre Daten erneut verarbeitet. Das zuvor erstellte Segment wird mit aktualisierten Daten aktualisiert.
Über die Ähnlichkeitsbewertung
Das Modell der binären Klassifizierung Maschinelles Lernen weist Kunden im ähnlichen Segment eine Bewertung zu. Die Bewertung basiert auf der Ähnlichkeit mit Kunden im Quellensegment.
- Ähnlichkeitswerte unter 0,55 sind Kunden, die das System klassifiziert als nicht ähnlich an Kunden im Quellensegment
- Ähnlichkeitswerte zwischen 0,55 und 0,7 werden klassifiziert als etwas ähnlich
- Ähnlichkeitswerte zwischen 0,7 und 0,85 werden klassifiziert als ähnlich
- Ähnlichkeitswerte zwischen 0,85 – 1 sind Kunden, die das System klassifiziert als sehr ähnlich
Kunden mit Ähnlichkeitswerten unter 0,4 werden nicht in die Modellausgabe einbezogen. Das System betrachtet sie nicht als ähnlich genug für das Quellensegment.