Bewährte Methoden für die Datenvereinheitlichung
Berücksichtigen Sie beim Festlegen von Regeln zur Vereinheitlichung Ihrer Daten in einem Kundenprofil die folgenden Best Practices:
Wägen Sie die Zeit für die Vereinheitlichung und die vollständige Übereinstimmung ab. Der Versuch, jede mögliche Übereinstimmung zu erfassen, führt dazu, dass viele Regeln und die Vereinheitlichung viel Zeit in Anspruch nehmen.
Fügen Sie nach und nach Regeln hinzu, und verfolgen Sie die Ergebnisse. Entfernen Sie Regeln, die das Übereinstimmungsergebnis nicht verbessern.
Deduplizieren Sie jede Tabelle, sodass jeder Kunde in einer einzigen Zeile dargestellt wird.
Nutzen Sie die Normalisierung, um Variationen dahingehend zu standardisieren, wie Daten eingegeben wurden, wie z. B. Street vs. St vs. St. vs. st.
Verwenden Sie die Fuzzyübereinstimmung strategisch, um Tippfehler und Fehler wie bob@contoso.com und bob@contoso.cm zu korrigieren. Die Ausführung von Fuzzy-Übereinstimmungen dauert länger als die Ausführung exakter Übereinstimmungen. Testen Sie immer, ob die zusätzliche Zeit, die für die Fuzzyübereinstimmung aufgewendet wird, die zusätzliche Übereinstimmungsrate wert ist.
Schränken Sie den Umfang der Übereinstimmungen mit exakter Übereinstimmung ein. Stellen Sie sicher, dass jede Regel mit Fuzzy-Bedingungen mindestens eine exakte Vergleichsbedingung hat.
Stimmen Sie keine Spalten ab, die häufig wiederholte Daten enthalten. Stellen Sie sicher, dass sich die Werte in Spalten mit Fuzzy-Übereinstimmung nicht häufig wiederholen, z. B. der Standardwert „Vorname“ eines Formulars.
Vereinheitlichungsleistung
Die Ausführung jeder Regel nimmt Zeit in Anspruch. Muster wie der Vergleich jeder Tabelle mit jeder anderen Tabelle oder der Versuch, jede mögliche Datensatzübereinstimmung zu erfassen, können zu langen Verarbeitungszeiten für die Vereinheitlichung führen. Außerdem werden nur wenige oder gar keine Übereinstimmungen mehr in einem Plan zurückgegeben, der jede Tabelle mit einer Basistabelle vergleicht.
Der beste Ansatz besteht darin, mit einem grundlegenden Satz von Regeln zu beginnen, von denen Sie wissen, dass sie benötigt werden, z. B. indem Sie jede Tabelle mit Ihrer primären Tabelle vergleichen. Ihre primäre Tabelle muss die Tabelle mit den vollständigsten und genauesten Daten sein. Diese Tabelle sollte im Schritt der Vereinheitlichung der Übereinstimmungsregeln oben angeordnet werden.
Fügen Sie nach und nach mehrere Regeln hinzu und prüfen Sie, wie lange die Ausführung der Änderungen dauert und ob sich Ihre Ergebnisse verbessern. Gehen Sie zu Einstellungen>System>Status, und wählen Sie Abgleichen aus, um zu sehen, wie lange die Deduplizierung und der Abgleich für jeden Vereinheitlichungslauf gedauert haben.
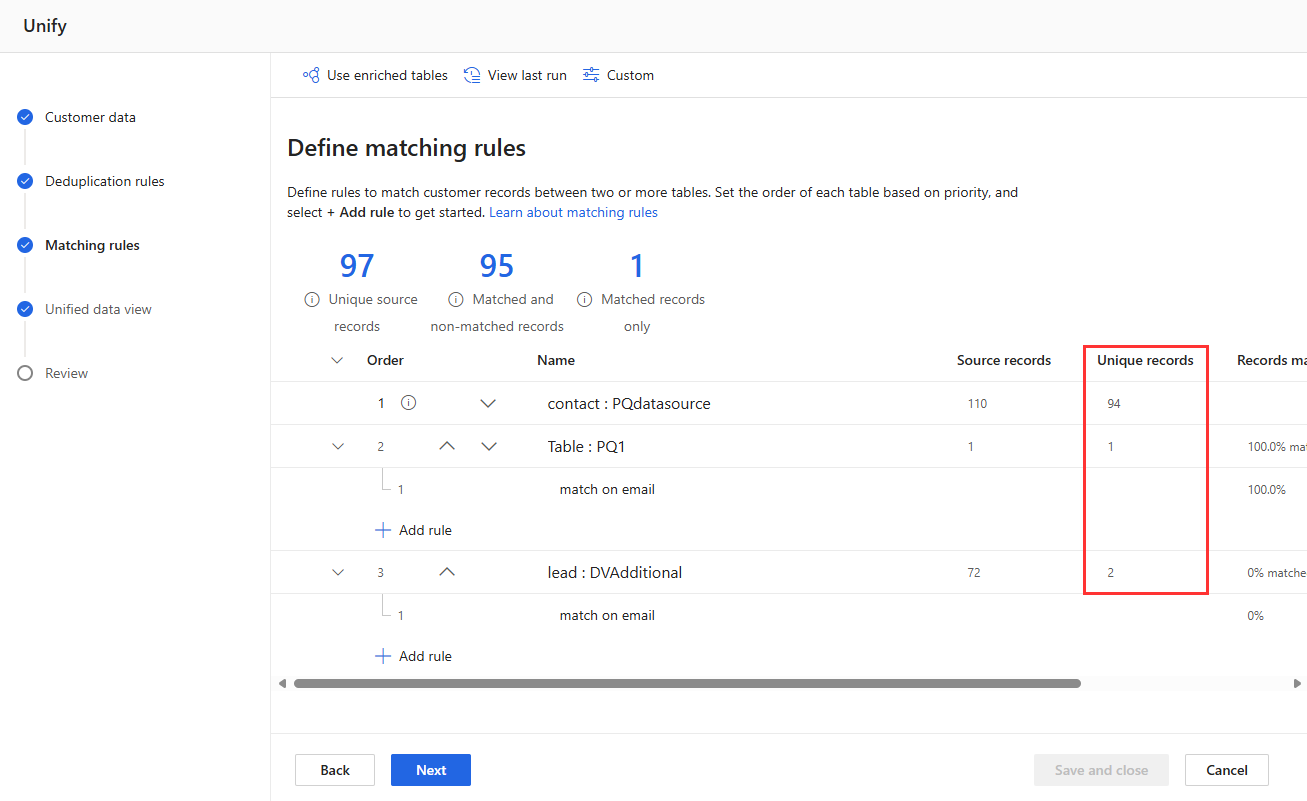
Zeigen Sie die Regelstatistiken auf den Seiten Deduplizierungsregeln und Übereinstimmungsregeln an, um festzustellen, ob sich die Anzahl der eindeutigen Datensätze ändert. Wenn eine neue Regel mit einigen Datensätzen übereinstimmt und sich die eindeutige Datensatzanzahl nicht ändert, werden diese Übereinstimmungen durch eine vorherige Regel identifiziert.
Deduplizierung
Verwenden Sie Deduplizierungsregeln, um doppelte Kundendatensätze in einer Tabelle zu entfernen, sodass eine einzelne Zeile in jeder Tabelle jeden Kunden repräsentiert. Eine gute Regel identifiziert einen eindeutigen Kunden bzw. eine eindeutige Kundin.
In diesem einfachen Beispiel haben die Datensätze 1, 2 und 3 entweder eine gemeinsame E-Mail- oder Telefonnummer und repräsentieren dieselbe Person.
| Kennung | Name des Dataflows | Telefon | E‑Mail |
|---|---|---|---|
| 1 | Person 1 | (425) 555-1111 | AAA@A.com |
| 2 | Person 1 | (425) 555-1111 | BBB@B.com |
| 3 | Person 1 | (425) 555-2222 | BBB@B.com |
| 4 | Person 2 | (206) 555-9999 | Person2@contoso.com |
Wir möchten nicht nur nach Namen suchen, da dies dazu führen würde, dass verschiedene Personen denselben Namen haben.
Erstellen Sie Regel 1 mit Name und Telefonnummer, die mit den Datensätzen 1 und 2 übereinstimmt.
Erstellen Sie Regel 2 mit Name und E-Mail-Adresse, die mit Datensätzen 2 und 3 übereinstimmen.
Durch die Kombination von Regel 1 und Regel 2 entsteht eine einzige Übereinstimmungsgruppe, da sie Datensatz 2 gemeinsam nutzen.
Sie bestimmen die Anzahl der Regeln und Bedingungen, die Ihre Kunden eindeutig identifizieren. Die genauen Regeln hängen davon ab, welche Daten Ihnen zum Abgleich zur Verfügung stehen, wie gut Ihre Daten sind und wie umfassend der Deduplizierungsprozess sein soll.
Normalisierung
Verwenden Sie die Normalisierung, um Daten für eine bessere Übereinstimmung zu standardisieren. Die Normalisierung funktioniert gut bei großen Datenmengen.
Die normalisierten Daten werden nur zu Vergleichszwecken verwendet, um Kundendatensätze effektiver abzugleichen. Die Daten in der endgültigen Ausgabe des vereinheitlichten Kundenprofils werden dadurch nicht geändert.
Genaue Übereinstimmung
Verwenden Sie Präzision, um zu bestimmen, wie nah zwei Zeichenfolgen sein sollten, um als Übereinstimmung zu gelten. Die Standardeinstellung für die Genauigkeit erfordert eine genaue Übereinstimmung. Jeder andere Wert ermöglicht die Fuzzyübereinstimmung für diese Bedingung.
Die Präzision kann auf niedrig (30 % Übereinstimmung), mittel (60 % Übereinstimmung) und hoch (80 % Übereinstimmung) eingestellt werden. Oder Sie können die Genauigkeit anpassen und in Schritten von 1 % festlegen.
Genaue Vergleichsbedingungen
Die exakten Vergleichsbedingungen werden zuerst ausgeführt, um einen kleineren Satz von Werten für Fuzzyübereinstimmungen zu erhalten. Um effektiv zu sein, sollten die genauen Vergleichsbedingung einen angemessenen Grad an Eindeutigkeit aufweisen. Wenn beispielsweise alle Ihre Kunden im selben Land/in derselben Region leben, würde eine genaue Übereinstimmung mit dem Land/der Region nicht helfen, den Umfang einzugrenzen.
Spalten wie die Felder „Vollständiger Name“, „E-Mail“, „Telefon“ oder „Adresse“ weisen eine gute Eindeutigkeit auf und eignen sich hervorragend als exakte Übereinstimmung.
Stellen Sie sicher, dass die Spalte, die Sie für eine exakte Vergleichsbedingung verwenden, keine Werte enthält, die häufig wiederholt werden, z. B. den Standardwert „Firstname“, der von einem Formular erfasst wird. Customer Insights kann Datenspalten profilieren, um Einblicke in die am häufigsten wiederkehrenden Werte zu erhalten. Sie können die Datenprofilerstellung für Azure Data Lake-Verbindungen (mit Common Data Model oder Delta-Format) und Synapse aktivieren. Das Datenprofil wird ausgeführt, wenn die Datenquelle das nächste Mal aktualisiert wird. Weitere Informationen finden Sie unter Datenprofilerstellung.
Fuzzy-Übereinstimmung
Verwenden Sie die Fuzzyübereinstimmung, um Zeichenfolgen abzugleichen, die nahe beieinander liegen, aber aufgrund von Tippfehlern oder anderen kleinen Variationen nicht genau sind. Verwenden Sie die Fuzzyübereinstimmung strategisch, da sie langsamer ist als exakte Übereinstimmungen. Stellen Sie sicher, dass in jeder Regel mit Fuzzy-Bedingungen mindestens eine genaue Vergleichsbedingung vorhanden ist.
Die Fuzzyübereinstimmung ist nicht dazu gedacht, Namensvariationen wie Suzzie und Suzanne zu erfassen. Diese Variationen lassen sich besser mit dem Normalisierungsmuster Typ: Name oder dem benutzerdefinierten Aliasabgleich erfassen, bei dem Kunden ihre Liste der Namensvariationen eingeben können, die sie als Übereinstimmungen in Betracht ziehen möchten.
Sie können einer Regel Bedingungen hinzufügen, z. B. den Abgleich von „FirstName“ und „Telefon“. Bedingungen innerhalb einer gegebenen Regel sind „UND“-Bedingungen. Alle Bedingungen müssen übereinstimmen, damit die Zeilen übereinstimmen. Separate Regeln sind „ODER“-Bedingungen. Wenn Regel 1 nicht mit den Zeilen übereinstimmt, werden die Zeilen mit Regel 2 verglichen.
Anmerkung
Nur Spalten vom Datentyp „Zeichenfolge“ können die Fuzzyübereinstimmung verwenden. Bei Spalten mit anderen Datentypen, z. B. „Integer“, „Double“ oder „DateTime“, ist das Genauigkeitsfeld schreibgeschützt und auf die genaue Übereinstimmung festgelegt.
Fuzzyübereinstimmungs-Berechnungen
Fuzzy-Übereinstimmungen werden ermittelt, indem der Bearbeitungsabstandswert zwischen zwei Zeichenfolgen berechnet wird. Wenn der Score den Genauigkeitsschwellenwert erreicht oder überschreitet, gelten die Zeichenfolgen als Übereinstimmung.
Der Bearbeitungsabstand ist die Anzahl der Bearbeitungen, die erforderlich sind, um eine Zeichenfolge in eine andere umzuwandeln, indem ein Zeichen hinzugefügt, gelöscht oder geändert wird.
Zum Beispiel haben die Zeichenfolgen „robert2020@hotmail.com“ und „robrt2020@hotmail.cm“ eine Bearbeitungsdistanz von zwei, wenn wir die Zeichen e und o entfernen. Um das Bearbeitungsabstandsergebnis zu berechnen, verwenden Sie diese Formel: (Basis-Zeichenfolgenlänge – Bearbeitungsabstand) / Basis-Zeichenfolgenlänge.
| Basis-Zeichenfolge | Vergleichszeichenfolge | Ergebnis |
|---|---|---|
| robert2020@hotmail.com | robrt2020@hotmail.cm | (20 - 2)/20 = 0,9 |