System.IO.Pipelines in .NET
System.IO.Pipelines ist eine Bibliothek, die entwickelt wurde, um die Ausführung von Hochleistungs-E/A in .NET zu erleichtern. Dabei handelt es sich um eine Bibliothek für .NET Standard, die mit allen .NET-Implementierungen kompatibel ist.
Die Bibliothek ist im Nuget-Paket System.IO.Pipelines verfügbar.
Von System.IO.Pipelines gelöste Probleme
Apps, die Streamingdaten analysieren, bestehen aus Codebausteinen, die über viele spezialisierte und ungewöhnliche Codeflows verfügen. Die Codebausteine und der Sonderfallcode sind komplex und schwer zu verwalten.
System.IO.Pipelines soll Folgendes ermöglichen:
- Hochleistungsanalyse von Streamingdaten.
- Verringern der Komplexität von Code.
Der folgende Code ist typisch für einen TCP-Server, der durch Zeilen getrennte Nachrichten (getrennt durch '\n') von einem Client empfängt:
async Task ProcessLinesAsync(NetworkStream stream)
{
var buffer = new byte[1024];
await stream.ReadAsync(buffer, 0, buffer.Length);
// Process a single line from the buffer
ProcessLine(buffer);
}
Der vorstehende Code weist mehrere Probleme auf:
- Die gesamte Nachricht (Zeilenende) wird möglicherweise nicht in einem einzigen Aufruf von
ReadAsyncempfangen. - Das Ergebnis von
stream.ReadAsyncwird ignoriert.stream.ReadAsyncgibt zurück, wie viele Daten gelesen wurden. - Der Fall, in dem mehrere Zeilen in einem einzigen Aufruf von
ReadAsyncgelesen werden, wird nicht verarbeitet. - Es wird bei jedem Lesevorgang ein
byte-Array zugeordnet.
Um die oben beschriebenen Probleme zu beheben, sind die folgenden Änderungen erforderlich:
Puffern der eingehenden Daten, bis eine neue Zeile gefunden wird.
Analysieren aller zurückgegebenen Zeilen im Puffer.
Es ist möglich, dass die Zeile größer als 1 KB (1.024 Bytes) ist. Der Code muss die Größe des Eingabepuffers ändern, bis das Trennzeichen gefunden wird, damit die gesamte Zeile in den Puffer passt.
- Wenn die Größe des Puffers geändert wird, werden mehr Pufferkopien erstellt, weil in der Eingabe längere Zeilen vorhanden sind.
- Um unnötigen Speicherplatz zu sparen, komprimieren Sie den Puffer, der zum Lesen von Zeilen verwendet wird.
Verwenden Sie ggf. Pufferpools, um zu vermeiden, dass wiederholt Speicher zugeteilt wird.
Der folgende Code behandelt einige dieser Probleme:
async Task ProcessLinesAsync(NetworkStream stream)
{
byte[] buffer = ArrayPool<byte>.Shared.Rent(1024);
var bytesBuffered = 0;
var bytesConsumed = 0;
while (true)
{
// Calculate the amount of bytes remaining in the buffer.
var bytesRemaining = buffer.Length - bytesBuffered;
if (bytesRemaining == 0)
{
// Double the buffer size and copy the previously buffered data into the new buffer.
var newBuffer = ArrayPool<byte>.Shared.Rent(buffer.Length * 2);
Buffer.BlockCopy(buffer, 0, newBuffer, 0, buffer.Length);
// Return the old buffer to the pool.
ArrayPool<byte>.Shared.Return(buffer);
buffer = newBuffer;
bytesRemaining = buffer.Length - bytesBuffered;
}
var bytesRead = await stream.ReadAsync(buffer, bytesBuffered, bytesRemaining);
if (bytesRead == 0)
{
// EOF
break;
}
// Keep track of the amount of buffered bytes.
bytesBuffered += bytesRead;
var linePosition = -1;
do
{
// Look for a EOL in the buffered data.
linePosition = Array.IndexOf(buffer, (byte)'\n', bytesConsumed,
bytesBuffered - bytesConsumed);
if (linePosition >= 0)
{
// Calculate the length of the line based on the offset.
var lineLength = linePosition - bytesConsumed;
// Process the line.
ProcessLine(buffer, bytesConsumed, lineLength);
// Move the bytesConsumed to skip past the line consumed (including \n).
bytesConsumed += lineLength + 1;
}
}
while (linePosition >= 0);
}
}
Der oben gezeigte Code ist komplex und behandelt nicht alle identifizierten Probleme. Hochleistungsnetzwerke bedeuten in der Regel das Schreiben von komplexem Code, um die Leistung zu maximieren. System.IO.Pipelines wurde entworfen, um das Schreiben dieser Art von Code zu vereinfachen.
Pipe
Die Pipe-Klasse kann verwendet werden, um ein PipeWriter/PipeReader-Paar zu erstellen. Alle Daten, die in PipeWriter geschrieben werden, sind in PipeReader verfügbar:
var pipe = new Pipe();
PipeReader reader = pipe.Reader;
PipeWriter writer = pipe.Writer;
Grundlegende Verwendung von Pipe
async Task ProcessLinesAsync(Socket socket)
{
var pipe = new Pipe();
Task writing = FillPipeAsync(socket, pipe.Writer);
Task reading = ReadPipeAsync(pipe.Reader);
await Task.WhenAll(reading, writing);
}
async Task FillPipeAsync(Socket socket, PipeWriter writer)
{
const int minimumBufferSize = 512;
while (true)
{
// Allocate at least 512 bytes from the PipeWriter.
Memory<byte> memory = writer.GetMemory(minimumBufferSize);
try
{
int bytesRead = await socket.ReceiveAsync(memory, SocketFlags.None);
if (bytesRead == 0)
{
break;
}
// Tell the PipeWriter how much was read from the Socket.
writer.Advance(bytesRead);
}
catch (Exception ex)
{
LogError(ex);
break;
}
// Make the data available to the PipeReader.
FlushResult result = await writer.FlushAsync();
if (result.IsCompleted)
{
break;
}
}
// By completing PipeWriter, tell the PipeReader that there's no more data coming.
await writer.CompleteAsync();
}
async Task ReadPipeAsync(PipeReader reader)
{
while (true)
{
ReadResult result = await reader.ReadAsync();
ReadOnlySequence<byte> buffer = result.Buffer;
while (TryReadLine(ref buffer, out ReadOnlySequence<byte> line))
{
// Process the line.
ProcessLine(line);
}
// Tell the PipeReader how much of the buffer has been consumed.
reader.AdvanceTo(buffer.Start, buffer.End);
// Stop reading if there's no more data coming.
if (result.IsCompleted)
{
break;
}
}
// Mark the PipeReader as complete.
await reader.CompleteAsync();
}
bool TryReadLine(ref ReadOnlySequence<byte> buffer, out ReadOnlySequence<byte> line)
{
// Look for a EOL in the buffer.
SequencePosition? position = buffer.PositionOf((byte)'\n');
if (position == null)
{
line = default;
return false;
}
// Skip the line + the \n.
line = buffer.Slice(0, position.Value);
buffer = buffer.Slice(buffer.GetPosition(1, position.Value));
return true;
}
Es gibt zwei Schleifen:
FillPipeAsyncliest ausSocketund schreibt inPipeWriter.ReadPipeAsyncliest ausPipeReaderund analysiert eingehende Zeilen.
Es sind keine expliziten Puffer zugeordnet. Die gesamte Pufferverwaltung wird an die PipeReader- und PipeWriter-Implementierungen delegiert. Durch die Delegierung der Pufferverwaltung ist es für Daten verarbeitenden Code einfacher, sich ausschließlich auf die Geschäftslogik zu konzentrieren.
In der ersten Schleife geschieht Folgendes:
- PipeWriter.GetMemory(Int32) wird aufgerufen, um Speicher vom zugrunde liegenden Writer abzurufen.
- PipeWriter.Advance(Int32) wird aufgerufen, um
PipeWritermitzuteilen, wie viele Daten in den Puffer geschrieben wurden. - PipeWriter.FlushAsync wird aufgerufen, um die Daten für
PipeReaderverfügbar zu machen.
In der zweiten Schleife verarbeitet PipeReader die von PipeWriter geschriebenen Puffer. Die Puffer stammen aus dem Socket. Für den Aufruf von PipeReader.ReadAsync gilt Folgendes:
Er gibt ein ReadResult zurück, das zwei wichtige Informationen enthält:
- Die gelesenen Daten in Form von
ReadOnlySequence<byte>. - Einen boolescher Wert
IsCompleted, der angibt, ob das Ende der Daten (EOF) erreicht wurde.
- Die gelesenen Daten in Form von
Nachdem das Zeilenende-Trennzeichen (EOL) gefunden und die Zeile analysiert wurde, geschieht Folgendes:
- Die Logik verarbeitet den Puffer, um die Daten zu überspringen, die bereits verarbeitet wurden.
PipeReader.AdvanceTowird aufgerufen, umPipeReadermitzuteilen, wie viele Daten verarbeitet und untersucht wurden.
Die Reader- und Writerschleifen werden durch den Aufruf von Complete beendet. Complete ermöglicht der zugrunde liegenden Pipe, den zugeordneten Arbeitsspeicher freizugeben.
Rückstau und Flusssteuerung
Im Idealfall arbeiten die Lese- und Analysevorgänge zusammen:
- Der lesende Thread nutzt Daten aus dem Netzwerk und speichert sie in Puffern.
- Der analysierende Thread ist für das Erstellen der entsprechenden Datenstrukturen verantwortlich.
In der Regel nimmt die Analyse mehr Zeit als das Kopieren von Datenblöcken aus dem Netzwerk in Anspruch:
- Der lesende Thread überholt den analysierenden Thread.
- Der lesende Thread muss entweder langsamer werden oder mehr Speicher zuteilen, um die Daten für den analysierenden Thread zu speichern.
Für optimale Leistung ist ein Gleichgewicht zwischen häufigen Pausen und der Zuteilung von mehr Speicherplatz vorhanden.
Zum Beheben des oben beschriebenen Problems hat Pipe zwei Einstellungen, um den Datenfluss zu steuern:
- PauseWriterThreshold: Bestimmt, wie viele Daten gepuffert werden sollen, bevor für Aufrufe von FlushAsync eine Pause eingelegt wird.
- ResumeWriterThreshold: Bestimmt, wie viele Daten der Reader untersuchen muss, bevor die Aufrufe von
PipeWriter.FlushAsyncfortgesetzt werden.
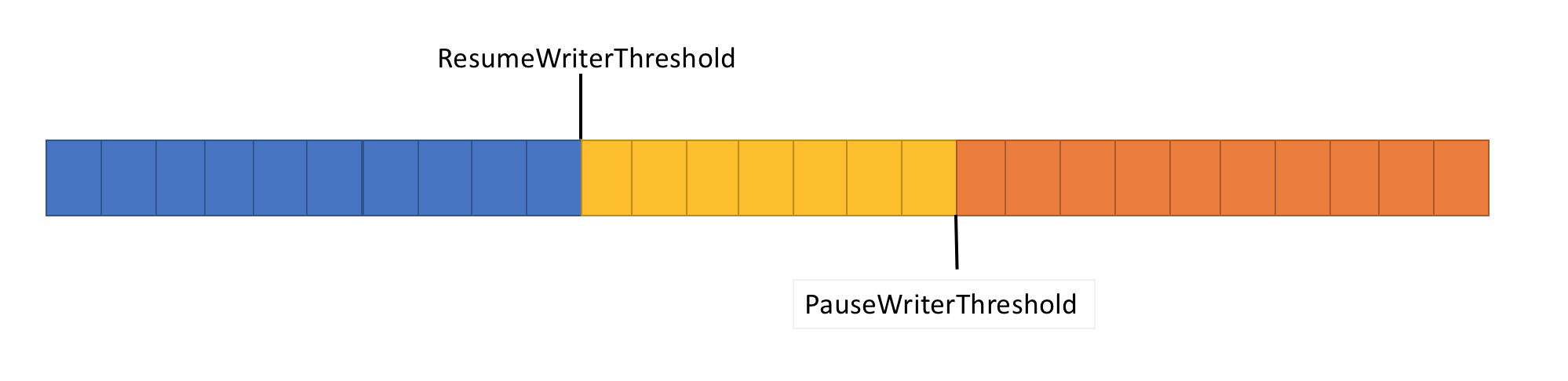
- Gibt ein unvollständiges
ValueTask<FlushResult>zurück, wenn die Datenmenge inPipePauseWriterThresholderreicht. - Schließt
ValueTask<FlushResult>ab, wenn der Wert kleiner alsResumeWriterThresholdwird.
Es werden zwei Werte verwendet, um einen schnellen Zyklus zu verhindern, der bei Verwendung nur eines Werts auftreten kann.
Beispiele
// The Pipe will start returning incomplete tasks from FlushAsync until
// the reader examines at least 5 bytes.
var options = new PipeOptions(pauseWriterThreshold: 10, resumeWriterThreshold: 5);
var pipe = new Pipe(options);
PipeScheduler
In der Regel wird der asynchrone Code bei Verwendung von async und await entweder für einen TaskScheduler oder den aktuellen SynchronizationContext fortgesetzt.
Wenn E/A-Vorgänge durchgeführt werden, ist es wichtig, genau zu steuern, wo die E/A-Vorgänge durchgeführt werden. Diese Steuerung ermöglicht die effektive Nutzung von CPU-Caches. Effiziente Zwischenspeicherung ist für Hochleistungs-Apps wie Webserver von entscheidender Bedeutung. PipeScheduler bietet die Kontrolle darüber, wo asynchrone Rückrufe ausgeführt werden. Standardmäßig:
- Der aktuelle SynchronizationContext wird verwendet.
- Wenn kein
SynchronizationContextvorhanden ist, wird der Threadpool verwendet, um Rückrufe auszuführen.
public static void Main(string[] args)
{
var writeScheduler = new SingleThreadPipeScheduler();
var readScheduler = new SingleThreadPipeScheduler();
// Tell the Pipe what schedulers to use and disable the SynchronizationContext.
var options = new PipeOptions(readerScheduler: readScheduler,
writerScheduler: writeScheduler,
useSynchronizationContext: false);
var pipe = new Pipe(options);
}
// This is a sample scheduler that async callbacks on a single dedicated thread.
public class SingleThreadPipeScheduler : PipeScheduler
{
private readonly BlockingCollection<(Action<object> Action, object State)> _queue =
new BlockingCollection<(Action<object> Action, object State)>();
private readonly Thread _thread;
public SingleThreadPipeScheduler()
{
_thread = new Thread(DoWork);
_thread.Start();
}
private void DoWork()
{
foreach (var item in _queue.GetConsumingEnumerable())
{
item.Action(item.State);
}
}
public override void Schedule(Action<object?> action, object? state)
{
if (state is not null)
{
_queue.Add((action, state));
}
// else log the fact that _queue.Add was not called.
}
}
PipeScheduler.ThreadPool ist die PipeScheduler-Implementierung, die Rückrufe des Threadpools der Warteschlange hinzufügt. PipeScheduler.ThreadPool ist die Standardeinstellung und in der Regel die beste Wahl. Pipescheduler.Inline kann unbeabsichtigte Folgen verursachen, z.B. Deadlocks.
Pipezurücksetzung
Es ist häufig effizient, das Pipe-Objekt wiederzuverwenden. Zum Zurücksetzen der Pipe rufen Sie PipeReader Reset auf, wenn PipeReader sowie PipeWriter abgeschlossen ist.
PipeReader
PipeReader verwaltet den Arbeitsspeicher im Auftrag des Aufrufers. Rufen Sie immer PipeReader.AdvanceTo auf, nachdem PipeReader.ReadAsync aufgerufen wurde. Dadurch kann PipeReader erkennen, wenn der Aufrufer Vorgänge im Arbeitsspeicher abgeschlossen hat, damit sie nachverfolgt werden können. Das PipeReader.ReadAsync, das von ReadOnlySequence<byte> zurückgegeben wird, ist nur bis zum Aufruf von PipeReader.AdvanceTo gültig. Es ist unzulässig, ReadOnlySequence<byte> nach dem Aufruf von PipeReader.AdvanceTo zu verwenden.
PipeReader.AdvanceTo nimmt zwei SequencePosition-Argumente an.
- Das erste Argument bestimmt, wie viel Arbeitsspeicher verbraucht wurde.
- Das zweite Argument bestimmt, in welchem Umfang der Puffer untersucht wurde.
Das Markieren von Daten als verarbeitet bedeutet, dass die Pipe den Arbeitsspeicher an den zugrunde liegenden Pufferpool zurückgeben kann. Durch das Markieren von Daten als untersucht wird gesteuert, welche Aktion der nächste Aufruf von PipeReader.ReadAsync ausführt. Wenn alle Daten als untersucht markiert sind, bedeutet dies, dass der nächste Aufruf von PipeReader.ReadAsync erst dann eine Rückgabe liefert, wenn weitere Daten in die Pipe geschrieben werden. Jeder andere Wert führt dazu, dass der nächste Aufruf von PipeReader.ReadAsync sofort die untersuchten und die nicht untersuchten Daten zurückgibt. Es handelt sich jedoch nicht um bereits verarbeitete Daten.
Szenarien für das Lesen von Streamingdaten
Beim Versuch, Streamingdaten zu lesen, gibt es einige typische Muster:
- Analysieren einer einzelnen Nachricht in einem angegebenen Datenstrom.
- Analysieren aller Nachrichten in einem angegebenen Datenstrom.
In den folgenden Beispielen wird die TryParseLines-Methode zum Analysieren von Nachrichten aus ReadOnlySequence<byte> verwendet. TryParseLines analysiert eine einzelne Nachricht und aktualisiert den Eingabepuffer, um die analysierte Nachricht aus dem Puffer zu kürzen. TryParseLines ist nicht Bestandteil von .NET, sondern eine vom Benutzer erstellte Methode, die in den folgenden Abschnitten verwendet wird.
bool TryParseLines(ref ReadOnlySequence<byte> buffer, out Message message);
Lesen einer einzelnen Nachricht
Der folgende Code liest eine einzelne Nachricht aus PipeReader und gibt sie an den Aufrufer zurück.
async ValueTask<Message?> ReadSingleMessageAsync(PipeReader reader,
CancellationToken cancellationToken = default)
{
while (true)
{
ReadResult result = await reader.ReadAsync(cancellationToken);
ReadOnlySequence<byte> buffer = result.Buffer;
// In the event that no message is parsed successfully, mark consumed
// as nothing and examined as the entire buffer.
SequencePosition consumed = buffer.Start;
SequencePosition examined = buffer.End;
try
{
if (TryParseLines(ref buffer, out Message message))
{
// A single message was successfully parsed so mark the start of the
// parsed buffer as consumed. TryParseLines trims the buffer to
// point to the data after the message was parsed.
consumed = buffer.Start;
// Examined is marked the same as consumed here, so the next call
// to ReadSingleMessageAsync will process the next message if there's
// one.
examined = consumed;
return message;
}
// There's no more data to be processed.
if (result.IsCompleted)
{
if (buffer.Length > 0)
{
// The message is incomplete and there's no more data to process.
throw new InvalidDataException("Incomplete message.");
}
break;
}
}
finally
{
reader.AdvanceTo(consumed, examined);
}
}
return null;
}
Der vorangehende Code:
- Analysiert eine einzelne Nachricht.
- Aktualisiert die verarbeitete
SequencePositionund die untersuchteSequencePosition, um auf den Anfang des gekürzten Eingabepuffers zu verweisen.
Die beiden SequencePosition-Argumente werden aktualisiert, weil TryParseLines die analysierte Nachricht aus dem Eingabepuffer entfernt. Wenn eine einzelne Nachricht aus dem Puffer analysiert wird, sollte die untersuchte Position im Allgemeinen eine der folgenden Positionen sein:
- Das Ende der Nachricht.
- Das Ende des empfangenen Puffers, wenn keine Nachricht gefunden wurde.
Das Szenario mit einer einzelnen Nachricht weist das größte Fehlerpotenzial auf. Wenn Sie die falschen Werte an examined (untersucht) übergeben, kann dies zu einer Ausnahme des Typs „Nicht genügend Arbeitsspeicher“ oder einer Endlosschleife führen. Weitere Informationen finden Sie im Abschnitt Allgemeine PipeReader-Probleme in diesem Artikel.
Lesen mehrerer Nachrichten
Der folgende Code liest alle Nachrichten aus einem PipeReader und ruft für jede Nachricht ProcessMessageAsync auf.
async Task ProcessMessagesAsync(PipeReader reader, CancellationToken cancellationToken = default)
{
try
{
while (true)
{
ReadResult result = await reader.ReadAsync(cancellationToken);
ReadOnlySequence<byte> buffer = result.Buffer;
try
{
// Process all messages from the buffer, modifying the input buffer on each
// iteration.
while (TryParseLines(ref buffer, out Message message))
{
await ProcessMessageAsync(message);
}
// There's no more data to be processed.
if (result.IsCompleted)
{
if (buffer.Length > 0)
{
// The message is incomplete and there's no more data to process.
throw new InvalidDataException("Incomplete message.");
}
break;
}
}
finally
{
// Since all messages in the buffer are being processed, you can use the
// remaining buffer's Start and End position to determine consumed and examined.
reader.AdvanceTo(buffer.Start, buffer.End);
}
}
}
finally
{
await reader.CompleteAsync();
}
}
Abbruch
PipeReader.ReadAsync:
- Unterstützt das Übergeben eines CancellationToken-Elements.
- Löst eine OperationCanceledException aus, wenn
CancellationTokenabgebrochen wird, während ein Lesevorgang aussteht. - Unterstützt die Möglichkeit, den aktuellen Lesevorgang über PipeReader.CancelPendingRead abzubrechen, wodurch das Auslösen einer Ausnahme vermieden wird. Das Aufrufen von
PipeReader.CancelPendingReadbewirkt, dass der aktuelle oder nächste Aufruf vonPipeReader.ReadAsyncein ReadResult zurückgibt, wobeiIsCanceledauftruefestgelegt ist. Dies kann nützlich sein, um die vorhandene Leseschleife auf nicht destruktive Weise und ohne Auslösen einer Ausnahme anzuhalten.
private PipeReader reader;
public MyConnection(PipeReader reader)
{
this.reader = reader;
}
public void Abort()
{
// Cancel the pending read so the process loop ends without an exception.
reader.CancelPendingRead();
}
public async Task ProcessMessagesAsync()
{
try
{
while (true)
{
ReadResult result = await reader.ReadAsync();
ReadOnlySequence<byte> buffer = result.Buffer;
try
{
if (result.IsCanceled)
{
// The read was canceled. You can quit without reading the existing data.
break;
}
// Process all messages from the buffer, modifying the input buffer on each
// iteration.
while (TryParseLines(ref buffer, out Message message))
{
await ProcessMessageAsync(message);
}
// There's no more data to be processed.
if (result.IsCompleted)
{
break;
}
}
finally
{
// Since all messages in the buffer are being processed, you can use the
// remaining buffer's Start and End position to determine consumed and examined.
reader.AdvanceTo(buffer.Start, buffer.End);
}
}
}
finally
{
await reader.CompleteAsync();
}
}
Allgemeine PipeReader-Probleme
Wenn die falschen Werte an
consumedoderexaminedübergeben werden, können bereits gelesene Daten erneut gelesen werden.Wenn Sie
buffer.Endals untersucht übergeben, kann dies zu folgenden Ergebnissen führen:- Angehaltene Daten.
- Möglicherweise wird eine Ausnahme aufgrund von nicht genügend Arbeitsspeicher (Out of Memory, OOM) ausgelöst, wenn keine Daten verarbeitet werden. Beispielsweise
PipeReader.AdvanceTo(position, buffer.End), wenn jeweils eine einzelne Nachricht aus dem Puffer verarbeitet wird.
Wenn die falschen Werte an
consumedoderexaminedübergeben werden, kann dies zu einer Endlosschleife führen.PipeReader.AdvanceTo(buffer.Start), wenn sichbuffer.Startnicht geändert hat, bewirkt beispielsweise, dass der nächste Aufruf vonPipeReader.ReadAsyncsofort vor dem Eintreffen neuer Daten zurückgegeben wird.Wenn die falschen Werte an
consumedoderexaminedübergeben werden, kann dies zu einer Endlospufferung führen (möglicherweise OOM).Wenn Sie
ReadOnlySequence<byte>nach dem Aufruf vonPipeReader.AdvanceToverwenden, kann dies zu einer Beschädigung des Arbeitsspeichers führen (Verwendung nach dem Freigeben).Wenn
PipeReader.Complete/CompleteAsyncnicht aufgerufen wird, kann dies zu einem Arbeitsspeicherverlust führen.Das Überprüfen von ReadResult.IsCompleted und das Beenden der Leselogik vor dem Verarbeiten der Pufferergebnisse führt zu Datenverlusten. Die Beendigungsbedingung der Schleife sollte auf
ReadResult.Buffer.IsEmptyundReadResult.IsCompletedbasieren. Wenn dieser Vorgang nicht ordnungsgemäß erfolgt, kann dies zu einer Endlosschleife führen.
Problematischer Code
❌Datenverlust
ReadResult kann das finale Datensegment zurückgeben, wenn IsCompleted auf true festgelegt ist. Das Nichtlesen dieser Daten vor dem Beenden der Leseschleife führt zu Datenverlusten.
Warnung
Verwenden Sie NICHT den folgenden Code. Das Verwenden dieses Beispiels führt zu Datenverlusten, nicht reagierenden Apps, Sicherheitsproblemen und sollte NICHT kopiert werden. Das folgende Beispiel wird bereitgestellt, um häufige PipeReader-Probleme zu verdeutlichen.
Environment.FailFast("This code is terrible, don't use it!");
while (true)
{
ReadResult result = await reader.ReadAsync(cancellationToken);
ReadOnlySequence<byte> dataLossBuffer = result.Buffer;
if (result.IsCompleted)
break;
Process(ref dataLossBuffer, out Message message);
reader.AdvanceTo(dataLossBuffer.Start, dataLossBuffer.End);
}
Warnung
Verwenden Sie den oben gezeigten Code NICHT. Das Verwenden dieses Beispiels führt zu Datenverlusten, nicht reagierenden Apps, Sicherheitsproblemen und sollte NICHT kopiert werden. Das Beispiel oben wird bereitgestellt, um häufige PipeReader-Probleme zu verdeutlichen.
❌Endlosschleife
Die folgende Logik kann zu einer Endlosschleife führen, wenn Result.IsCompleted true ist, im Puffer aber niemals eine vollständige Nachricht vorhanden ist.
Warnung
Verwenden Sie NICHT den folgenden Code. Das Verwenden dieses Beispiels führt zu Datenverlusten, nicht reagierenden Apps, Sicherheitsproblemen und sollte NICHT kopiert werden. Das folgende Beispiel wird bereitgestellt, um häufige PipeReader-Probleme zu verdeutlichen.
Environment.FailFast("This code is terrible, don't use it!");
while (true)
{
ReadResult result = await reader.ReadAsync(cancellationToken);
ReadOnlySequence<byte> infiniteLoopBuffer = result.Buffer;
if (result.IsCompleted && infiniteLoopBuffer.IsEmpty)
break;
Process(ref infiniteLoopBuffer, out Message message);
reader.AdvanceTo(infiniteLoopBuffer.Start, infiniteLoopBuffer.End);
}
Warnung
Verwenden Sie den oben gezeigten Code NICHT. Das Verwenden dieses Beispiels führt zu Datenverlusten, nicht reagierenden Apps, Sicherheitsproblemen und sollte NICHT kopiert werden. Das Beispiel oben wird bereitgestellt, um häufige PipeReader-Probleme zu verdeutlichen.
Im Folgenden finden Sie einen weiteren Codeausschnitt mit dem gleichen Problem. Der Code überprüft, ob ein nicht leerer Puffer vorhanden ist, bevor ReadResult.IsCompleted überprüft wird. Da dies in einer else if-Anweisung stattfindet, ist das Ergebnis eine Endlosschleife, wenn im Puffer niemals eine vollständige Nachricht vorhanden ist.
Warnung
Verwenden Sie NICHT den folgenden Code. Das Verwenden dieses Beispiels führt zu Datenverlusten, nicht reagierenden Apps, Sicherheitsproblemen und sollte NICHT kopiert werden. Das folgende Beispiel wird bereitgestellt, um häufige PipeReader-Probleme zu verdeutlichen.
Environment.FailFast("This code is terrible, don't use it!");
while (true)
{
ReadResult result = await reader.ReadAsync(cancellationToken);
ReadOnlySequence<byte> infiniteLoopBuffer = result.Buffer;
if (!infiniteLoopBuffer.IsEmpty)
Process(ref infiniteLoopBuffer, out Message message);
else if (result.IsCompleted)
break;
reader.AdvanceTo(infiniteLoopBuffer.Start, infiniteLoopBuffer.End);
}
Warnung
Verwenden Sie den oben gezeigten Code NICHT. Das Verwenden dieses Beispiels führt zu Datenverlusten, nicht reagierenden Apps, Sicherheitsproblemen und sollte NICHT kopiert werden. Das Beispiel oben wird bereitgestellt, um häufige PipeReader-Probleme zu verdeutlichen.
❌Anwendung reagiert nicht
Der Aufruf von PipeReader.AdvanceTo mit buffer.End an der examined-Position ohne Bedingungen kann beim Analysieren einer einzelnen Nachricht dazu führen, dass die Anwendung nicht mehr reagiert. Der nächste Aufruf von PipeReader.AdvanceTo liefert erst eine Rückgabe, wenn:
- Weitere Daten in die Pipe geschrieben werden.
- Und die neuen Daten zuvor nicht untersucht wurden.
Warnung
Verwenden Sie NICHT den folgenden Code. Das Verwenden dieses Beispiels führt zu Datenverlusten, nicht reagierenden Apps, Sicherheitsproblemen und sollte NICHT kopiert werden. Das folgende Beispiel wird bereitgestellt, um häufige PipeReader-Probleme zu verdeutlichen.
Environment.FailFast("This code is terrible, don't use it!");
while (true)
{
ReadResult result = await reader.ReadAsync(cancellationToken);
ReadOnlySequence<byte> hangBuffer = result.Buffer;
Process(ref hangBuffer, out Message message);
if (result.IsCompleted)
break;
reader.AdvanceTo(hangBuffer.Start, hangBuffer.End);
if (message != null)
return message;
}
Warnung
Verwenden Sie den oben gezeigten Code NICHT. Das Verwenden dieses Beispiels führt zu Datenverlusten, nicht reagierenden Apps, Sicherheitsproblemen und sollte NICHT kopiert werden. Das Beispiel oben wird bereitgestellt, um häufige PipeReader-Probleme zu verdeutlichen.
❌Nicht genügend Arbeitsspeicher (Out of Memory, OOM)
Mit den folgenden Bedingungen behält der folgende Code die Pufferung bei, bis eine OutOfMemoryException auftritt:
- Es gibt keine maximale Nachrichtengröße.
- Die von
PipeReaderzurückgegebenen Daten bilden keine vollständige Nachricht. Beispielsweise ergibt sich keine vollständige Nachricht, weil die andere Seite eine große Nachricht schreibt (z.B. eine Nachricht mit 4 GB).
Warnung
Verwenden Sie NICHT den folgenden Code. Das Verwenden dieses Beispiels führt zu Datenverlusten, nicht reagierenden Apps, Sicherheitsproblemen und sollte NICHT kopiert werden. Das folgende Beispiel wird bereitgestellt, um häufige PipeReader-Probleme zu verdeutlichen.
Environment.FailFast("This code is terrible, don't use it!");
while (true)
{
ReadResult result = await reader.ReadAsync(cancellationToken);
ReadOnlySequence<byte> thisCouldOutOfMemory = result.Buffer;
Process(ref thisCouldOutOfMemory, out Message message);
if (result.IsCompleted)
break;
reader.AdvanceTo(thisCouldOutOfMemory.Start, thisCouldOutOfMemory.End);
if (message != null)
return message;
}
Warnung
Verwenden Sie den oben gezeigten Code NICHT. Das Verwenden dieses Beispiels führt zu Datenverlusten, nicht reagierenden Apps, Sicherheitsproblemen und sollte NICHT kopiert werden. Das Beispiel oben wird bereitgestellt, um häufige PipeReader-Probleme zu verdeutlichen.
❌Speicherbeschädigung
Beim Schreiben von Hilfsprogrammen, die den Puffer lesen, sollte jede zurückgegebene Nutzlast kopiert werden, bevor Advance aufgerufen wird. Im folgenden Beispiel wird der Arbeitsspeicher zurückgegeben, der von Pipe verworfen wurde. Er kann für den nächsten Vorgang (Lese-/Schreibzugriff) wiederverwendet werden.
Warnung
Verwenden Sie NICHT den folgenden Code. Das Verwenden dieses Beispiels führt zu Datenverlusten, nicht reagierenden Apps, Sicherheitsproblemen und sollte NICHT kopiert werden. Das folgende Beispiel wird bereitgestellt, um häufige PipeReader-Probleme zu verdeutlichen.
public class Message
{
public ReadOnlySequence<byte> CorruptedPayload { get; set; }
}
Environment.FailFast("This code is terrible, don't use it!");
Message message = null;
while (true)
{
ReadResult result = await reader.ReadAsync(cancellationToken);
ReadOnlySequence<byte> buffer = result.Buffer;
ReadHeader(ref buffer, out int length);
if (length <= buffer.Length)
{
message = new Message
{
// Slice the payload from the existing buffer
CorruptedPayload = buffer.Slice(0, length)
};
buffer = buffer.Slice(length);
}
if (result.IsCompleted)
break;
reader.AdvanceTo(buffer.Start, buffer.End);
if (message != null)
{
// This code is broken since reader.AdvanceTo() was called with a position *after* the buffer
// was captured.
break;
}
}
return message;
}
Warnung
Verwenden Sie den oben gezeigten Code NICHT. Das Verwenden dieses Beispiels führt zu Datenverlusten, nicht reagierenden Apps, Sicherheitsproblemen und sollte NICHT kopiert werden. Das Beispiel oben wird bereitgestellt, um häufige PipeReader-Probleme zu verdeutlichen.
PipeWriter
PipeWriter verwaltet Puffer zum Schreiben im Auftrag des Aufrufers. PipeWriter implementiert IBufferWriter<byte>. IBufferWriter<byte> ermöglicht es, Zugriff auf Puffer zu erhalten, um Schreibvorgänge ohne zusätzliche Pufferkopien auszuführen.
async Task WriteHelloAsync(PipeWriter writer, CancellationToken cancellationToken = default)
{
// Request at least 5 bytes from the PipeWriter.
Memory<byte> memory = writer.GetMemory(5);
// Write directly into the buffer.
int written = Encoding.ASCII.GetBytes("Hello".AsSpan(), memory.Span);
// Tell the writer how many bytes were written.
writer.Advance(written);
await writer.FlushAsync(cancellationToken);
}
Der vorherige Code:
- Fordert einen Puffer mit mindestens 5 Bytes von
PipeWriterunter Verwendung von GetMemory an. - Schreibt Bytes für die ASCII-Zeichenfolge
"Hello"in das zurückgegebeneMemory<byte>-Element. - Ruft Advance auf, um anzugeben, wie viele Bytes in den Puffer geschrieben wurden.
- Leert das
PipeWriter-Element, das die Bytes an das zugrunde liegende Gerät sendet.
Die vorherige Methode zum Schreiben verwendet die Puffer, die von PipeWriter bereitgestellt werden. Es hätte auch PipeWriter.WriteAsync verwendet werden können, das:
- Kopiert den vorhandenen Puffer in
PipeWriter. - Ruft
GetSpan,Advancenach Bedarf auf und ruft dann FlushAsync auf.
async Task WriteHelloAsync(PipeWriter writer, CancellationToken cancellationToken = default)
{
byte[] helloBytes = Encoding.ASCII.GetBytes("Hello");
// Write helloBytes to the writer, there's no need to call Advance here
// (Write does that).
await writer.WriteAsync(helloBytes, cancellationToken);
}
Abbruch
FlushAsync unterstützt das Übergeben eines CancellationToken-Elements. Das Übergeben eines CancellationToken führt zu einer OperationCanceledException, wenn das Token abgebrochen wird, während ein Leerungsvorgang aussteht. PipeWriter.FlushAsync unterstützt die Möglichkeit, den aktuellen Leerungsvorgang über PipeWriter.CancelPendingFlush abzubrechen, ohne eine Ausnahme auszulösen. Der Aufruf von PipeWriter.CancelPendingFlush bewirkt, dass der aktuelle oder nächste Aufruf von PipeWriter.FlushAsync oder PipeWriter.WriteAsync ein FlushResult zurückgibt, wobei IsCanceled auf true festgelegt ist. Dies kann nützlich sein, um die sich ergebende Leerung auf nicht destruktive Weise und ohne Auslösen einer Ausnahme anzuhalten.
Allgemeine PipeWriter-Probleme
- GetSpan und GetMemory geben einen Puffer mit mindestens der angeforderten Menge an Arbeitsspeicher zurück. Gehen Sie nicht von genauen Puffergrößen aus.
- Es gibt keine Garantie, dass aufeinanderfolgende Aufrufe denselben Puffer oder dieselbe Puffergröße zurückgeben.
- Nach dem Aufrufen von Advance muss ein neuer Puffer angefordert werden, um das Schreiben weiterer Daten fortzusetzen. In den zuvor abgerufenen Puffer kann nicht geschrieben werden.
- Das Aufrufen von
GetMemoryoderGetSpanist während eines unvollständiger Aufrufs vonFlushAsyncnicht sicher. - Wenn Sie
CompleteoderCompleteAsyncaufrufen, während nicht geleerte Daten vorhanden sind, kann dies zu einer Speicherbeschädigung führen.
Tipps für die Verwendung von PipeReader und PipeWriter
Die folgenden Tipps helfen Ihnen bei der erfolgreichen Verwendung der System.IO.Pipelines-Klassen:
- Schließen Sie PipeReader und PipeWriter immer ab, einschließlich einer Ausnahme, falls zutreffend.
- Rufen Sie immer PipeReader.AdvanceTo auf, nachdem PipeReader.ReadAsync aufgerufen wurde.
- Regelmäßig während des Schreibens
awaitPipeWriter.FlushAsync, und überprüfen Sie immer FlushResult.IsCompleted. Abbrechen des Schreibens, wennIsCompletedisttrue, da dies angibt, dass der Reader abgeschlossen ist und nicht mehr überwacht, was geschrieben wird. - Rufen Sie PipeWriter.FlushAsync auf, nachdem Sie etwas geschrieben haben, auf das
PipeReaderZugriff haben soll. - Rufen Sie nicht auf
FlushAsync, wenn der Reader erst starten kann, wennFlushAsyncabgeschlossen ist, da dies zu einem Deadlock führen kann. - Stellen Sie sicher, dass nur ein Kontext einen
PipeReaderoderPipeWriter„besitzt“ oder auf sie zugreift. Diese Typen sind nicht threadsicher. - Greifen Sie nie auf einen ReadResult.Buffer zu, nachdem Sie
AdvanceToaufgerufen oderPipeReaderabgeschlossen haben.
IDuplexPipe
IDuplexPipe ist ein Vertrag für Typen, die sowohl Lese- als auch Schreibvorgänge unterstützen. Eine Netzwerkverbindung würde z.B. durch eine IDuplexPipe dargestellt werden.
Im Gegensatz zum Pipe-Element, das eine PipeReader- und eine PipeWriter-Klasse enthält, stellt IDuplexPipe nur eine Seite einer vollständigen Duplexverbindung dar. Dies bedeutet, dass die in PipeWriter geschriebenen Informationen von PipeReader gelesen werden.
Streams
Beim Lesen oder Schreiben von Streamdaten lesen Sie Daten in der Regel mithilfe eines Deserialisierers und schreiben Daten mit einem Serialisierer. Die meisten dieser APIs zum Lesen und Schreiben eines Datenstrom verfügen über einen Stream-Parameter. Um die Integration mit diesen vorhandenen APIs zu vereinfachen, machen PipeReader und PipeWriter eine AsStream-Methode verfügbar. AsStream gibt eine Stream-Implementierung um PipeReader oder PipeWriter zurück.
Streambeispiel
PipeReader- und PipeWriter-Instanzen können mithilfe der statischen Methode Create erstellt werden, sofern ein Stream-Objekt und optional entsprechende Erstellungsoptionen vorhanden sind.
Mit StreamPipeReaderOptions kann die Erstellung einer PipeReader-Instanz gesteuert werden, indem folgende Parameter verwendet werden:
- StreamPipeReaderOptions.BufferSize ist die minimale Puffergröße in Byte, die beim Leihen von Arbeitsspeicher aus dem Pool verwendet wird. Der Standardwert ist
4096. - Mit dem StreamPipeReaderOptions.LeaveOpen-Flag wird festgelegt, ob der zugrunde liegende Stream nach Abschluss von
PipeReadergeöffnet bleibt. Der Standardwert istfalse. - StreamPipeReaderOptions.MinimumReadSize stellt den Schwellenwert der im Puffer verbleibenden Bytes dar, bevor ein neuer Puffer zugeordnet wird. Der Standardwert ist
1024. - StreamPipeReaderOptions.Pool entspricht der beim Belegen von Arbeitsspeicher verwendeten
MemoryPool<byte>-Klasse. Der Standardwert istnull.
Mit StreamPipeWriterOptions kann die Erstellung einer PipeWriter-Instanz gesteuert werden, indem folgende Parameter verwendet werden:
- Mit dem StreamPipeWriterOptions.LeaveOpen-Flag wird festgelegt, ob der zugrunde liegende Stream nach Abschluss von
PipeWritergeöffnet bleibt. Der Standardwert istfalse. - StreamPipeWriterOptions.MinimumBufferSize ist die minimale Puffergröße, die beim Leihen von Arbeitsspeicher von
4096verwendet werden soll. Der Standardwert ist Pool. - StreamPipeWriterOptions.Pool entspricht der beim Belegen von Arbeitsspeicher verwendeten
MemoryPool<byte>-Klasse. Der Standardwert istnull.
Wichtig
Wenn Sie PipeReader- und PipeWriter-Instanzen mithilfe von Create-Methoden erstellen, müssen Sie die Lebensdauer des Stream-Objekts berücksichtigen. Wenn Sie Zugriff auf den Stream benötigen, nachdem der Reader oder Writer beendet wurde, müssen Sie das Flag in den Erstellungsoptionen LeaveOpen auf true festlegen. Andernfalls wird der Stream geschlossen.
Im folgenden Code wird die Erstellung von PipeReader- und PipeWriter-Instanzen mithilfe der Create-Methoden über einen Stream veranschaulicht.
using System.Buffers;
using System.IO.Pipelines;
using System.Text;
class Program
{
static async Task Main()
{
using var stream = File.OpenRead("lorem-ipsum.txt");
var reader = PipeReader.Create(stream);
var writer = PipeWriter.Create(
Console.OpenStandardOutput(),
new StreamPipeWriterOptions(leaveOpen: true));
WriteUserCancellationPrompt();
var processMessagesTask = ProcessMessagesAsync(reader, writer);
var userCanceled = false;
var cancelProcessingTask = Task.Run(() =>
{
while (char.ToUpperInvariant(Console.ReadKey().KeyChar) != 'C')
{
WriteUserCancellationPrompt();
}
userCanceled = true;
// No exceptions thrown
reader.CancelPendingRead();
writer.CancelPendingFlush();
});
await Task.WhenAny(cancelProcessingTask, processMessagesTask);
Console.WriteLine(
$"\n\nProcessing {(userCanceled ? "cancelled" : "completed")}.\n");
}
static void WriteUserCancellationPrompt() =>
Console.WriteLine("Press 'C' to cancel processing...\n");
static async Task ProcessMessagesAsync(
PipeReader reader,
PipeWriter writer)
{
try
{
while (true)
{
ReadResult readResult = await reader.ReadAsync();
ReadOnlySequence<byte> buffer = readResult.Buffer;
try
{
if (readResult.IsCanceled)
{
break;
}
if (TryParseLines(ref buffer, out string message))
{
FlushResult flushResult =
await WriteMessagesAsync(writer, message);
if (flushResult.IsCanceled || flushResult.IsCompleted)
{
break;
}
}
if (readResult.IsCompleted)
{
if (!buffer.IsEmpty)
{
throw new InvalidDataException("Incomplete message.");
}
break;
}
}
finally
{
reader.AdvanceTo(buffer.Start, buffer.End);
}
}
}
catch (Exception ex)
{
Console.Error.WriteLine(ex);
}
finally
{
await reader.CompleteAsync();
await writer.CompleteAsync();
}
}
static bool TryParseLines(
ref ReadOnlySequence<byte> buffer,
out string message)
{
SequencePosition? position;
StringBuilder outputMessage = new();
while(true)
{
position = buffer.PositionOf((byte)'\n');
if (!position.HasValue)
break;
outputMessage.Append(Encoding.ASCII.GetString(buffer.Slice(buffer.Start, position.Value)))
.AppendLine();
buffer = buffer.Slice(buffer.GetPosition(1, position.Value));
};
message = outputMessage.ToString();
return message.Length != 0;
}
static ValueTask<FlushResult> WriteMessagesAsync(
PipeWriter writer,
string message) =>
writer.WriteAsync(Encoding.ASCII.GetBytes(message));
}
Die Anwendung verwendet ein StreamReader an, um die lorem-ipsum.txt-Datei als Stream zu lesen, und sie muss mit einer leeren Zeile enden. FileStream wird an die PipeReader.Create-Methode übergeben, die ein PipeReader-Objekt instanziiert. Die Konsolenanwendung übergibt dann ihren Standardausgabestream an Console.OpenStandardOutput(). Sie verwendet hierzu PipeWriter.Create. In diesem Beispiel wird ein Abbruch unterstützt.