Behandeln von Ausnahmen und Fehlern
Mit Ausnahmen werden Fehlfunktionen lokal in der Dienst- oder der Clientimplementierung übermittelt. Fehler übermitteln hingegen Fehlfunktionen über die Grenzen eines Dienstes hinaus, z. B. vom Server zum Client und umgekehrt. Darüber hinaus verwenden Transportkanäle häufig transportspezifische Mechanismen, um Fehlfunktionen auf Transportebene zu übermitteln. Der HTTP-Transport verwendet z. B. Statuscodes wie 404 zur Übermittlung einer nicht vorhandenen Endpunkt-URL (es gibt keinen Endpunkt, an den der Fehler zurückgegeben werden kann). Dieses Dokument besteht aus drei Abschnitten mit Hinweisen für Autoren benutzerdefinierter Kanäle. Der erste Abschnitt enthält Hinweise dazu, wann und wie Ausnahmen definiert und ausgelöst werden. Der zweite Abschnitt enthält Hinweise zum Auslösen und Behandeln von Fehlern. Im dritten Abschnitt wird das Bereitstellen von Ablaufinformationen erklärt, mit deren Hilfe die Benutzer Ihres benutzerdefinierten Kanals Probleme in laufenden Anwendungen behandeln können.
Ausnahmen
Beim Auslösen einer Ausnahme müssen zwei Punkte beachtet werden: Erstens muss es sich dabei um einen Typ handeln, bei dem Benutzern den richtigen Code schreiben können, um auf die Ausnahme angemessen zu reagieren. Zweiten müssen dabei ausreichend Informationen angegeben werden, damit der Benutzer die Fehlerursache, die Auswirkung des Fehlers und dessen Behebung erkennen kann. Die folgenden Abschnitte enthalten Hinweise zu den Ausnahmetypen und Meldungen für WCF-Kanäle (Windows Communication Foundation). Allgemeine Hinweise zu Ausnahmen in .NET finden Sie außerdem in den Entwurfsrichtlinien für Ausnahmen.
Ausnahmetypen
Bei allen von Kanälen ausgelösten Ausnahmen muss es sich entweder um System.TimeoutException, System.ServiceModel.CommunicationException oder einen Typ handeln, der von CommunicationException abgeleitet wird. (Es können auch Ausnahmen wie ObjectDisposedException ausgelöst werden. Diese geben jedoch nur an, dass der aufrufende Code den Kanal falsch verwendet hat. Wenn ein Kanal ordnungsgemäß verwendet wird, darf er nur die angegebenen Ausnahmen auslösen.) WCF stellt sieben Ausnahmetypen bereit, die von CommunicationException abgeleitet werden und für die Verwendung von Kanälen bestimmt sind. Es gibt noch weitere von CommunicationException abgeleitete Ausnahmen, die der Verwendung durch andere Teile des Systems dienen. Dazu gehören die folgenden Ausnahmetypen:
| Ausnahmetyp | Bedeutung | Inhalt der internen Ausnahme | Wiederherstellungsstrategie |
|---|---|---|---|
| AddressAlreadyInUseException | Die zur Überwachung angegebene Endpunktadresse wird bereits verwendet. | Gibt, sofern vorhanden, weitere Details zum Transportfehler an, der diese Ausnahme verursacht hat. Beispiel: PipeException, HttpListenerException oder SocketException. | Versuchen Sie es mit einer anderen Adresse. |
| AddressAccessDeniedException | Der Prozess darf nicht auf die zur Überwachung angegebene Endpunktadresse zugreifen. | Gibt, sofern vorhanden, weitere Details zum Transportfehler an, der diese Ausnahme verursacht hat. Beispiel: PipeException oder HttpListenerException. | Versuchen Sie es mit anderen Anmeldeinformationen. |
| CommunicationObjectFaultedException | Das verwendete ICommunicationObject befindet sich im Fehlerstatus (weitere Informationen finden Sie unter Understanding State Changes (Informationen zu Statusänderungen)). Wenn ein Objekt mit mehreren ausstehenden Aufrufen in den Faulted-Status wechselt, löst nur ein Aufruf eine Ausnahme aus, die sich auf den Fehler bezieht. Die übrigen Aufrufe lösen CommunicationObjectFaultedException aus. Diese Ausnahme wird in der Regel ausgelöst, weil eine Anwendung eine Ausnahme übersieht und ein bereits fehlerhaftes Objekt verwenden will, möglicherweise in einem anderen Thread als dem, der die ursprüngliche Ausnahme abfing. | Gibt, sofern vorhanden, Details zur inneren Ausnahme an. | Erstellen Sie ein neues Objekt. Beachten Sie, dass je nachdem, was den Fehler von ICommunicationObject ursprünglich verursacht hat, weitere Maßnahmen zur Problembehandlung erforderlich sein können. |
| CommunicationObjectAbortedException | Das verwendete ICommunicationObject wurde abgebrochen (weitere Informationen finden Sie unter Understanding State Changes (Informationen zu Statusänderungen)). Ähnlich wie bei CommunicationObjectFaultedException gibt diese Ausnahme an, dass die Anwendung Abort für ein Objekt aufgerufen hat, das möglicherweise aus einem anderen Thread stammt und deshalb nicht mehr verwendet werden kann. | Gibt, sofern vorhanden, Details zur inneren Ausnahme an. | Erstellen Sie ein neues Objekt. Beachten Sie, dass je nachdem, was den Abbruch von ICommunicationObject ursprünglich verursacht hat, weitere Maßnahmen zur Problembehandlung erforderlich sein können. |
| EndpointNotFoundException | Der Remotezielendpunkt führt keine Überwachung aus. Möglicherweise ist ein Teil der Endpunktadresse falsch oder kann nicht ausgelöst werden, oder der Endpunkt ist deaktiviert. Beispiele hierfür sind DNS-Fehler, der Warteschlangen-Manager ist nicht verfügbar oder der Dienst wird nicht ausgeführt. | Die innere Ausnahme stellt Details bereit, in der Regel aus dem zugrunde liegenden Transport. | Versuchen Sie es mit einer anderen Adresse. Stattdessen kann der Absender auch eine Weile warten und es noch einmal versuchen, für den Fall, dass der Dienst ausgefallen war. |
| ProtocolException | Die Kommunikationsprotokolle, die von der Richtlinie des Endpunkts beschrieben werden, stimmen zwischen den Endpunkten nicht überein. Beispiele: Rahmeninhaltstypenkonflikt oder die maximale Nachrichtengröße wurde überschritten. | Gibt, sofern vorhanden, Informationen zum speziellen Protokollfehler an. Beispielsweise ist QuotaExceededException die innere Ausnahme, wenn die Fehlerursache eine Überschreitung von MaxReceivedMessageSize ist. | Wiederherstellung: Stellen sicher, dass die Einstellungen für das Absender- und das Empfängerprotokoll übereinstimmen. Eine Möglichkeit hierfür besteht darin, die Metadaten des Dienstendpunkts (Richtlinie) neu zu importieren und mit der generierten Bindung den Kanal neu zu erstellen. |
| ServerTooBusyException | Der Remoteendpunkt führt eine Überwachung aus, ist jedoch noch nicht zur Verarbeitung von Nachrichten bereit. | Sofern vorhanden, gibt die innere Ausnahme die Details des SOAP- oder Tansportfehlers an. | Wiederherstellung: Warten Sie, und wiederholen Sie den Vorgang später. |
| TimeoutException | Der Vorgang konnte innerhalb des angegebenen Timeouts nicht abgeschlossen werden. | Stellt möglicherweise Details über das Timeout bereit. | Warten Sie, und wiederholen Sie den Vorgang später. |
Definieren Sie nur dann einen neuen Ausnahmetyp, wenn dieser Typ einer bestimmten Wiederherstellungsstrategie entspricht, die sich von allen vorhandenen Ausnahmetypen unterscheidet. Wenn Sie einen neuen Ausnahmetyp definieren, muss er von CommunicationException oder einer der davon abgeleiteten Klassen abgeleitet werden.
Ausnahmemeldungen
Ausnahmemeldungen richten sich an den Benutzer, nicht an das Programm. Deshalb sollten sie ausreichend Informationen enthalten, mit denen der Benutzer das Problem verstehen und beheben kann. Eine gute Ausnahmemeldung besteht im Wesentlichen aus den folgenden drei Teilen:
Was ist passiert. Beschreiben Sie das Problem eindeutig, und verwenden Sie Begriffe, die den Benutzer*innen vertraut sind. Eine schlechte Ausnahmemeldung wäre z. B. "Ungültiger Konfigurationsabschnitt". Dabei bleibt der Benutzer im Unklaren, welcher Konfigurationsabschnitt falsch ist und warum er falsch ist. Eine bessere Meldung wäre „Ungültiger Konfigurationsabschnitt <customBinding>“. Und eine noch bessere Meldung wäre „Der Transport mit der Bezeichnung ,meinTransport‘ kann der Bindung ,meineBindung‘ nicht hinzugefügt werden, da die Bindung bereits einen Transport mit dem Namen ,meinTransport‘ besitzt“. Diese Meldung ist sehr genau und verwendet Begriffe und Namen, die Benutzer*innen schnell in der Konfigurationsdatei der Anwendung finden. Es fehlen jedoch noch immer einige entscheidende Komponenten.
Die Relevanz des Fehlers. Wenn die Meldung nicht klar angibt, was der Fehler bedeutet, weiß der Benutzer nicht, ob der Fehler schwerwiegend ist oder ignoriert werden kann. Im Allgemeinen sollten Fehlermeldungen mit der Bedeutung oder der Relevanz des Fehlers eingeleitet werden. Um das vorherige Beispiel zu verbessern, könnte die Meldung lauten "ServiceHost konnte aufgrund eines Konfigurationsfehlers nicht geöffnet werden: Der Transport mit der Bezeichnung meinTransport kann der Bindung meineBindung nicht hinzugefügt werden, da die Bindung bereits einen Transport mit dem Namen meinTransport besitzt".
Vorgehensweise zum Beheben des Problems. Der wichtigste Teil der Meldung besteht darin, dem Benutzer beim Beheben des Problem zu helfen. Die Meldung sollte einige Anweisungen und Hinweise enthalten, was zu überprüfen oder zu korrigieren ist. Beispiel: "ServiceHost konnte aufgrund eines Konfigurationsfehlers nicht geöffnet werden: Der Transport mit der Bezeichnung meinTransport kann der Bindung meineBindung nicht hinzugefügt werden, da die Bindung bereits einen Transport mit dem Namen meinTransport besitzt. Stellen Sie sicher, dass die Bindung nur einen Transport enthält.“
Übermitteln von Fehlern
SOAP 1.1 und SOAP 1.2 definieren jeweils eine spezielle Struktur für Fehler. Es gibt einige Unterschiede zwischen den beiden Spezifikationen. Im Allgemeinen werden jedoch die Typen Message und MessageFault zum Erstellen und Behandeln von Fehlern verwendet.
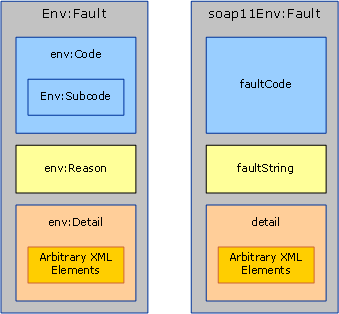
Fehler in SOAP 1.2 (links) und Fehler in SOAP 1.1 (rechts). In SOAP 1.1 ist nur das Fehlerelement namespacequalifiziert.
SOAP definiert eine Fehlermeldung als Meldung, die nur ein Fehlerelement (ein Element, dessen Name <env:Fault> enthält. Der Inhalt des Fehlerelements unterscheidet sich ein wenig zwischen SOAP 1.1 und SOAP 1.2 (siehe Abbildung 1). Die System.ServiceModel.Channels.MessageFault-Klasse normalisiert diese Unterschiede jedoch in ein Objektmodell:
public abstract class MessageFault
{
protected MessageFault();
public virtual string Actor { get; }
public virtual string Node { get; }
public static string DefaultAction { get; }
public abstract FaultCode Code { get; }
public abstract bool HasDetail { get; }
public abstract FaultReason Reason { get; }
public T GetDetail<T>();
public T GetDetail<T>( XmlObjectSerializer serializer);
public System.Xml.XmlDictionaryReader GetReaderAtDetailContents();
// other methods omitted
}
Die Code-Eigenschaft entspricht env:Code (oder faultCode in SOAP 1.1) und identifiziert den Typ des Fehlers. SOAP 1.2 definiert fünf zulässige Werte für faultCode (z. B. Sender und Receiver) und definiert ein Subcode-Element, das einen beliebigen Subcodewert enthalten kann. (Eine Liste der zulässigen Fehlercodes und deren Bedeutung finden Sie in der Spezifikation zu SOAP 1.2.) Der Mechanismus in SOAP 1.1 unterscheidet sich etwas: Er definiert vier faultCode-Werte (z. B. Client und Server), die erweitert werden können. Die Erweiterung kann entweder durch Definieren völlig neuer Werte erfolgen, oder indem mit der Punktnotation speziellere faultCodes erstellt werden (z. B. Client.Authentication).
Wenn Sie MessageFault zum Programmieren von Fehlern verwenden, wird FaultCode.Name und FaultCode.Namespace jeweils dem Namen und dem Namespace von env:Code in SOAP 1.2 oder faultCode in SOAP 1.1 zugeordnet. FaultCode.SubCode wird env:Subcode für SOAP 1.2 zugeordnet und ist für SOAP 1.1 NULL.
Erstellen Sie neue Fehlersubcodes (oder bei SOAP 1.1 neue Fehlercodes), wenn eine programmgesteuerte Unterscheidung eines Fehlers von Interesse ist. Diese Vorgehensweise entspricht dem Erstellen eines neuen Ausnahmetyps. Vermeiden Sie die Verwendung der Punktnotation mit SOAP 1.1-Fehlercodes. (Auch mit WS-I Basic Profile wird die Verwendung der Punktnotation nicht empfohlen.)
public class FaultCode
{
public FaultCode(string name);
public FaultCode(string name, FaultCode subCode);
public FaultCode(string name, string ns);
public FaultCode(string name, string ns, FaultCode subCode);
public bool IsPredefinedFault { get; }
public bool IsReceiverFault { get; }
public bool IsSenderFault { get; }
public string Name { get; }
public string Namespace { get; }
public FaultCode SubCode { get; }
// methods omitted
}
Die Reason-Eigenschaft entspricht env:Reason (oder faultString in SOAP 1.1), einer lesbaren Beschreibung der Fehlerbedingung analog zur Meldung einer Ausnahme. In der FaultReason-Klasse (und SOAP env:Reason/faultString) ist eine Unterstützung mehrerer Übersetzungen für Globalisierungszwecke integriert.
public class FaultReason
{
public FaultReason(FaultReasonText translation);
public FaultReason(IEnumerable<FaultReasonText> translations);
public FaultReason(string text);
public SynchronizedReadOnlyCollection<FaultReasonText> Translations
{
get;
}
}
Der Inhalt der Fehlerdetails wird für „MessageFault“ mit verschiedenen Methoden verfügbar gemacht, einschließlich GetDetail<T> und GetReaderAtDetailContents(). Das Fehlerdetail ist ein nicht transparentes Element zur Aufnahme zusätzlicher Fehlerdetails. Das ist nützlich, wenn Sie dem Fehler willkürlich strukturierte Details hinzufügen möchten.
Generieren von Fehlern
In diesem Abschnitt wird das Generieren eines Fehlers als Reaktion auf eine Fehlerbedingung erläutert, die in einem Kanal oder in einer von einem Kanal erstellten Nachrichteneigenschaft festgestellt wird. Ein typisches Beispiel ist die Rückgabe eines Fehlers als Antwort auf eine Anforderungsnachricht, die ungültige Daten enthält.
Beim Generieren eines Fehlers sollte der benutzerdefinierte Kanal den Fehler nicht direkt senden, sondern eine Ausnahme auslösen, um es der übergeordneten Ebene zu überlassen, ob diese Ausnahme in einen Fehler konvertiert wird und wie der Fehler zu senden ist. Als Hilfestellung bei dieser Konvertierung sollte der Kanal eine FaultConverter-Implementierung bereitstellen, die die vom benutzerdefinierten Kanal ausgelöste Ausnahme in den geeigneten Fehler konvertieren kann. FaultConverter wird folgendermaßen definiert:
public class FaultConverter
{
public static FaultConverter GetDefaultFaultConverter(
MessageVersion version);
protected abstract bool OnTryCreateFaultMessage(
Exception exception,
out Message message);
public bool TryCreateFaultMessage(
Exception exception,
out Message message);
}
Jeder Kanal, der benutzerdefinierte Fehler generiert, muss FaultConverter implementieren und nach einem Aufruf von GetProperty<FaultConverter> zurückgeben. Die benutzerdefinierte OnTryCreateFaultMessage-Implementierung muss die Ausnahme in einen Fehler konvertieren oder an den FaultConverter des inneren Kanals delegieren. Wenn es sich um einen Transportkanal handelt, muss der Kanal die Ausnahme konvertieren oder an den FaultConverter des Encoders oder den standardmäßigen FaultConverter von WCF delegieren. Der standardmäßige FaultConverter konvertiert Fehler entsprechend der in der WS-Adressierung und SOAP angegebenen Fehlermeldungen. Im Folgenden sehen Sie ein Beispiel für eine OnTryCreateFaultMessage-Implementierung.
public override bool OnTryCreateFaultMessage(Exception exception,
out Message message)
{
if (exception is ...)
{
message = ...;
return true;
}
#if IMPLEMENTING_TRANSPORT_CHANNEL
FaultConverter encoderConverter =
this.encoder.GetProperty<FaultConverter>();
if ((encoderConverter != null) &&
(encoderConverter.TryCreateFaultMessage(
exception, out message)))
{
return true;
}
FaultConverter defaultConverter =
FaultConverter.GetDefaultFaultConverter(
this.channel.messageVersion);
return defaultConverter.TryCreateFaultMessage(
exception,
out message);
#else
FaultConverter inner =
this.innerChannel.GetProperty<FaultConverter>();
if (inner != null)
{
return inner.TryCreateFaultMessage(exception, out message);
}
else
{
message = null;
return false;
}
#endif
}
Eine Folge dieses Musters ist, dass die zwischen Schichten für Fehlerbedingungen ausgelösten Ausnahmen, die Fehler erfordern, genügend Informationen enthalten müssen, damit der entsprechende Fehlergenerator den richtigen Fehler erstellen kann. Als Autor eines benutzerdefinierten Kanals definieren Sie möglicherweise Ausnahmetypen, die verschiedenen Fehlerbedingungen entsprechen, falls solche Ausnahmen nicht bereits vorhanden sind. Beachten Sie, dass Ausnahmen, die Kanalschichten durchlaufen, eher die Fehlerbedingung statt der nicht transparenten Fehlerdaten übermitteln sollten.
Fehlerkategorien
Es gibt im Allgemeinen drei Kategorien von Fehlern:
Fehler, die den ganzen Stapel durchdringen. Diese Fehler können in jeder Schicht des Kanalstapels auftreten, z. B. InvalidCardinalityAddressingException.
Fehler, die an jeder beliebigen Stelle über einer bestimmten Schicht im Stapel auftreten können. Hierzu gehören z. B. Fehler, die einen Transaktionsfluss oder Sicherheitsrollen betreffen.
Fehler, die sich auf eine einzelne Schicht im Stapel beziehen. Hierzu zählen z. B. Fehler wie WS-RM-Sequenznummernfehler.
Kategorie 1: Fehler sind im Allgemeinen WS-Adressierungs- und SOAP-Fehler. Die von WCF bereitgestellte FaultConverter-Basisklasse konvertiert Fehler, die mit den in WS-Addressing und SOAP angegebenen Fehlermeldungen übereinstimmen. Deshalb müssen Sie diese Ausnahmen nicht selbst konvertieren.
Kategorie 2: Fehler treten auf, wenn der Nachricht von einer Schicht eine Eigenschaft hinzugefügt wird und diese Eigenschaft Nachrichteninformationen, die diese Schicht betreffen, nicht vollständig behandelt. Fehler werden möglicherweise später erkannt, wenn eine höhere Schicht von der Eigenschaft eine weitere Verarbeitung von Nachrichteninformationen verlangt. Solche Kanäle sollten wie erwähnt GetProperty implementieren, um der höheren Schicht, die Rückgabe des richtigen Fehlers zu ermöglichen. TransactionMessageProperty ist hierfür ein Beispiel. Diese Eigenschaft wird der Nachricht hinzugefügt, ohne dass alle Daten im Header vollständig überprüft werden (dadurch wird möglicherweise eine Verbindung mit dem Distributed Transaction Coordinator (DTC) hergestellt).
Kategorie 3. Fehler werden nur von einer einzelnen Schicht im Prozessor generiert und gesendet. Deshalb sind alle Ausnahmen innerhalb der Schicht enthalten. Um die Einheitlichkeit zwischen den Kanälen zu verbessern und die Wartung zu erleichtern, sollte der benutzerdefinierte Kanal oben beschriebene Muster verwenden, um auch für interne Fehler Fehlermeldungen zu generieren.
Interpretieren empfangener Fehler
Dieser Abschnitt enthält Hinweise zum Generieren der richtigen Ausnahme beim Empfang einer Fehlermeldung. Die Entscheidungsstruktur zur Verarbeitung einer Meldung in den einzelnen Schichten eines Stapels lautet wie folgt:
Wenn die Meldung von der Schicht als ungültig angesehen wird, sollte sie diese als „ungültige Meldung“ verarbeiten. Diese Verarbeitung hängt von der jeweiligen Schicht ab, kann jedoch das Verwerfen der Meldung, eine Ablaufverfolgung oder das Auslösen einer Ausnahme beinhalten, die in einen Fehler konvertiert wird. Zu den Beispielen hierfür zählen, dass die Sicherheit eine nicht ordnungsgemäß gesicherte Nachricht erhält oder dass RM eine Nachricht mit einer falschen Sequenznummer empfängt.
Andernfalls sollte die Schicht die Fehlerbedingung behandeln, wenn sich die Meldung speziell auf die Schicht bezieht und außerhalb der Schicht keine Bedeutung hat. Ein Beispiel hierfür ist ein Fehler aufgrund einer abgelehnten RM-Sequenz. Dieser Fehler ist für die Schichten über dem RM-Kanal bedeutungslos und impliziert, dass der RM-Kanal einen Fehler ausgibt und ausstehende Vorgänge eine Ausnahme auslösen.
Andernfalls sollte die Meldung von Request() oder Receive() zurückgegeben werden. Dazu gehören Fälle, in denen die Schicht den Fehler erkennt, der Fehler jedoch nur angibt, dass eine Anforderung fehlgeschlagen ist. Dabei impliziert der Fehler nicht, dass der RM-Kanal einen Fehler ausgibt und ausstehende Vorgänge eine Ausnahme auslösen. Um die Verwendbarkeit in einem solchen Fall zu verbessern, sollte die Schicht
GetProperty<FaultConverter>implementieren und eine vonFaultConverterabgeleitete Klasse zurückgeben, die den Fehler durch Außerkraftsetzen vonOnTryCreateExceptionkonvertieren kann.
Das folgende Objektmodell unterstützt das Konvertieren von Meldungen in Ausnahmen:
public class FaultConverter
{
public static FaultConverter GetDefaultFaultConverter(
MessageVersion version);
protected abstract bool OnTryCreateException(
Message message,
MessageFault fault,
out Exception exception);
public bool TryCreateException(
Message message,
MessageFault fault,
out Exception exception);
}
Eine Kanalschicht kann GetProperty<FaultConverter> implementieren, um das Konvertieren von Fehlermeldungen in Ausnahmen zu unterstützen. Setzen Sie dazu OnTryCreateException außer Kraft, und überprüfen Sie die Fehlermeldung. Wenn sie erkannt wird, führen Sie die Konvertierung aus, überlassen Sie andernfalls den Kanal die Konvertierung. Transportkanäle sollten eine Delegierung an FaultConverter.GetDefaultFaultConverter ausführen, um den standardmäßigen FaultConverter der SOAP/WS-Adressierung abzurufen.
Eine typische Implementierung sieht folgendermaßen aus:
public override bool OnTryCreateException(
Message message,
MessageFault fault,
out Exception exception)
{
if (message.Action == "...")
{
exception = ...;
return true;
}
// OR
if ((fault.Code.Name == "...") && (fault.Code.Namespace == "..."))
{
exception = ...;
return true;
}
if (fault.IsMustUnderstand)
{
if (fault.WasHeaderNotUnderstood(
message.Headers, "...", "..."))
{
exception = new ProtocolException(...);
return true;
}
}
#if IMPLEMENTING_TRANSPORT_CHANNEL
FaultConverter encoderConverter =
this.encoder.GetProperty<FaultConverter>();
if ((encoderConverter != null) &&
(encoderConverter.TryCreateException(
message, fault, out exception)))
{
return true;
}
FaultConverter defaultConverter =
FaultConverter.GetDefaultFaultConverter(
this.channel.messageVersion);
return defaultConverter.TryCreateException(
message, fault, out exception);
#else
FaultConverter inner =
this.innerChannel.GetProperty<FaultConverter>();
if (inner != null)
{
return inner.TryCreateException(message, fault, out exception);
}
else
{
exception = null;
return false;
}
#endif
}
Definieren Sie gegebenenfalls für spezielle Fehlerbedingungen mit besonderen Wiederherstellungszenarien eine abgeleitete Klasse von ProtocolException.
Verarbeitung von MustUnderstand
SOAP definiert einen allgemeinen Fehler, wenn ein erforderlicher Header vom Empfänger nicht interpretiert werden konnte. Dieser Fehler wird mustUnderstand genannt. In WCF generieren benutzerdefinierte Kanäle keine mustUnderstand-Fehler. Stattdessen überprüft der WCF-Verteiler, der sich im WCF-Kommunikationsstapel ganz oben befindet, ob alle mit „MustUndestand=true“ gekennzeichneten Header vom zugrunde liegenden Stapel interpretiert werden konnten. Sind Header dabei, die nicht interpretiert werden konnten, wird an dieser Stelle ein mustUnderstand-Fehler generiert. (Benutzer*innen können diese mustUnderstand-Verarbeitung deaktivieren und die Anwendung alle Nachrichtenheader empfangen lassen. In diesem Fall wird die mustUnderstand-Verarbeitung der Anwendung überlassen.) Der generierte Fehler schließt einen NotUnderstood-Header ein, der die Namen aller nicht interpretierten Header mit „MustUnderstand=true“ enthält.
Wenn Ihr Protokollkanal einen benutzerdefinierten Header mit MustUnderstand=true sendet und einen mustUnderstand-Fehler empfängt, muss er überprüfen, ob dieser Fehler durch einen von ihm gesendeten Header verursacht wurde. Die MessageFault-Klasse besitzt zwei Member, die für diesen Zweck nützlich sind:
public class MessageFault
{
...
public bool IsMustUnderstandFault { get; }
public static bool WasHeaderNotUnderstood(MessageHeaders headers,
string name, string ns) { }
...
}
IsMustUnderstandFault gibt true zurück, wenn der Fehler ein mustUnderstand-Fehler ist. WasHeaderNotUnderstood gibt true zurück, wenn der Header mit dem angegebenen Namen und Namespace im Fehler als NotUnderstood-Header enthalten ist. Andernfalls wird falsezurückgegeben.
Wenn dieser Kanal einen Header ausgibt, der mit MustUnderstand = true gekennzeichnet ist, sollte diese Schicht auch das Exception Generation API-Muster implementieren. Außerdem sollte sie mustUnderstand-Fehler, die durch diesen Fehler verursacht wurden, wie weiter oben beschrieben in eine nützlichere Ausnahme konvertieren.
Ablaufverfolgung
.NET Framework stellt einen Mechanismus bereit, mit dem die Programmausführung verfolgt werden kann. Damit wird die Diagnose von Produktionsanwendungen oder von zeitweiligen Problemen unterstützt, bei denen es nicht möglich ist, einfach ein Debugger hinzuzufügen und den Code zu durchlaufen. Die folgenden Kernkomponenten dieses Mechanismus befinden sich im System.Diagnostics-Namespace:
System.Diagnostics.TraceSource stellt die Quelle der zu schreibenden Anlaufverfolgungsinformationen dar, System.Diagnostics.TraceListener, stellt die abstrakte Basisklasse für konkrete Listener dar, die zu verfolgende Informationen von TraceSource erhalten und an ein für die Listener spezifisches Ziel ausgeben. Beispielsweise gibt XmlWriterTraceListener Ablaufverfolgungsinformationen in eine XML-Datei aus. System.Diagnostics.TraceSwitch wird in der Konfiguration angegeben und ermöglicht dem Benutzer der Anwendung die Ausführlichkeit der Ablaufverfolgung zu steuern.
Neben den Kernkomponenten können Sie mit dem Service Trace Viewer-Tool (SvcTraceViewer.exe) WCF-Ablaufverfolgungen anzeigen und suchen. Das Tool wurde speziell für Ablaufverfolgungsdateien entwickelt, die in WCF generiert und mit XmlWriterTraceListener geschrieben werden. Die folgende Abbildung zeigt die verschiedenen Komponenten der Ablaufverfolgung.
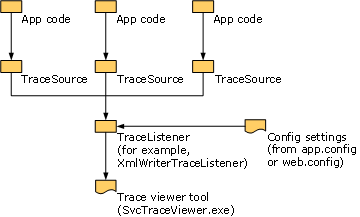
Ablaufverfolgung durch einen benutzerdefinierten Kanal
Als Hilfestellung bei der Diagnose von Problemen, bei denen es nicht möglich ist, der laufenden Anwendung einen Debugger hinzuzufügen, sollten benutzerdefinierte Kanäle Ablaufverfolgungsmeldungen ausgeben. Das schließt zwei komplexe Aufgaben ein: Instanziieren einer TraceSource und Aufrufen ihrer Methoden zu Schreiben von Ablaufverfolgungen.
Bei der Instanziierung einer TraceSource dient die von Ihnen angegebene Zeichenfolge als Name dieser Quelle. Mit diesem Namen wird die Ablaufverfolgungsquelle konfiguriert (Aktivieren/Deaktivieren/Festlegen der Ablaufverfolgungsebene). Der Name wird außerdem direkt in der Ausgabe der Ablaufverfolgung angegeben. Benutzerdefinierte Kanäle sollten einen eindeutigen Quellennamen verwenden, damit Leser der Ablaufverfolgungsausgabe erkennen können, woher die Ablaufverfolgungsinformationen stammen. Im Allgemeinen wird als Name der Ablaufverfolgungsquelle der Name der Assembly verwendet, die diese Informationen schreibt. Zum Beispiel verwendet WCF „System.ServiceModel“ als Ablaufverfolgungsquelle für Informationen, die von der System.ServiceModel-Assembly geschrieben werden.
Sobald eine Ablaufverfolgungsquelle vorhanden ist, rufen Sie ihre Methoden TraceDataTraceEvent oder TraceInformation auf, um Ablaufverfolgungseinträge für den Ablaufverfolgungslistener zu schreiben. Für jeden geschriebenen Ablaufverfolgungseintrag müssen Sie den Typ des Ereignisses als einen der in TraceEventType definierten Ereignistypen klassifizieren. Diese Klassifikation und die Einstellung der Ablaufverfolgungsebene in der Konfiguration bestimmen, ob der Ablaufverfolgungseintrag an den Listener ausgegeben wird. Wenn z. B. die Ablaufverfolgungsebene in der Konfiguration auf Warning festgelegt wird, können Warning- Error- und Critical-Ablaufverfolgungsereignisse geschrieben werden, Information- und Verbose-Einträge werden jedoch blockiert. Das folgende Beispiel veranschaulicht die Instanziierung einer Ablaufverfolgungsquelle und das Schreiben eines Eintrags auf Information-Ebene:
using System.Diagnostics;
//...
TraceSource udpSource = new TraceSource("Microsoft.Samples.Udp");
//...
udpsource.TraceInformation("UdpInputChannel received a message");
Wichtig
Geben Sie unbedingt einen Namen für die Ablaufverfolgungsquellen an, der in Ihren benutzerdefinierten Kanal eindeutig ist, damit Leser der Ablaufverfolgungsausgabe erkennen können, woher die Ausgabe stammt.
Integration des Ablaufverfolgungs-Viewers
Von Ihrem Kanal generierte Ablaufverfolgungen können in einem Format ausgegeben werden, das vom Service Trace Viewer-Tool (SvcTraceViewer.exe) gelesen werden kann, indem System.Diagnostics.XmlWriterTraceListener als Ablaufverfolgungslistener verwendet wird. Allerdings ist das kein Schritt, den Sie als Kanalentwickler vornehmen müssen. Dieser Ablaufverfolgungslistener muss eher von den Benutzer*innen der Anwendung (oder der Person, die Anwendungsprobleme behandelt) in der Konfigurationsdatei der Anwendung konfiguriert werden. Beispielsweise werden mit der folgenden Konfiguration Ablaufverfolgungsinformationen von System.ServiceModel und von Microsoft.Samples.Udp an die Datei TraceEventsFile.e2e ausgegeben:
<configuration>
<system.diagnostics>
<sources>
<!-- configure System.ServiceModel trace source -->
<source name="System.ServiceModel" switchValue="Verbose"
propagateActivity="true">
<listeners>
<add name="e2e" />
</listeners>
</source>
<!-- configure Microsoft.Samples.Udp trace source -->
<source name="Microsoft.Samples.Udp" switchValue="Verbose" >
<listeners>
<add name="e2e" />
</listeners>
</source>
</sources>
<!--
Define a shared trace listener that outputs to TraceFile.e2e
The listener name is e2e
-->
<sharedListeners>
<add name="e2e" type="System.Diagnostics.XmlWriterTraceListener"
initializeData=".\TraceFile.e2e"/>
</sharedListeners>
<trace autoflush="true" />
</system.diagnostics>
</configuration>
Verfolgen strukturierter Daten
System.Diagnostics.TraceSource besitzt eine TraceData-Methode, die ein oder mehrere Objekte in den Ablaufverfolgungseintrag aufnimmt. Im Allgemeinen wird die Object.ToString-Methode für jedes Objekt aufgerufen, und die resultierende Zeichenfolge wird als Teil des Ablaufverfolgungseintrags geschrieben. Wenn mit System.Diagnostics.XmlWriterTraceListener Ablaufverfolgungen ausgegeben werden, können Sie System.Xml.XPath.IXPathNavigable als Datenobjekt an TraceData übergeben. Der resultierende Ablaufverfolgungseintrag schließt die von System.Xml.XPath.XPathNavigator bereitgestellten XML-Daten ein. Der folgende Beispieleintrag enthält XML-Anwendungsdaten:
<E2ETraceEvent xmlns="http://schemas.microsoft.com/2004/06/E2ETraceEvent">
<System xmlns="...">
<EventID>12</EventID>
<Type>3</Type>
<SubType Name="Information">0</SubType>
<Level>8</Level>
<TimeCreated SystemTime="2006-01-13T22:58:03.0654832Z" />
<Source Name="Microsoft.ServiceModel.Samples.Udp" />
<Correlation ActivityID="{00000000-0000-0000-0000-000000000000}" />
<Execution ProcessName="UdpTestConsole"
ProcessID="3348" ThreadID="4" />
<Channel />
<Computer>COMPUTER-LT01</Computer>
</System>
<!-- XML application data -->
<ApplicationData>
<TraceData>
<DataItem>
<TraceRecord
Severity="Information"
xmlns="…">
<TraceIdentifier>some trace id</TraceIdentifier>
<Description>EndReceive called</Description>
<AppDomain>UdpTestConsole.exe</AppDomain>
<Source>UdpInputChannel</Source>
</TraceRecord>
</DataItem>
</TraceData>
</ApplicationData>
</E2ETraceEvent>
Der Trace Viewer in WCF erkennt das Schema des TraceRecord-Elements, extrahiert die Daten aus dessen untergeordneten Elementen und zeigt sie in einem Tabellenformat an. Ihr Kanal sollte beim Verfolgen strukturierter Anwendungsdaten dieses Schema verwenden, damit Benutzer von Svctraceviewer.exe die Daten lesen können.