Zustands- und Datenverwaltung in Docker-Anwendungen
Tipp
Diese Inhalte sind ein Auszug aus dem eBook „.NET Microservices Architecture for Containerized .NET Applications“, verfügbar unter .NET Docs oder als kostenlos herunterladbare PDF-Datei, die offline gelesen werden kann.

In den meisten Fällen können Sie sich einen Container als Instanz eines Prozesses vorstellen. Ein Prozess behält keinen persistenten Zustand bei. Während ein Container in den lokalen Speicher schreiben kann, gleicht die Annahme, dass eine Instanz auf unbestimmte Zeit vorhanden ist, der Annahme, dass ein Speicherort im Arbeitsspeicher dauerhaft ist. Sie müssen davon ausgehen, dass Containerimages ebenso wie Prozesse über mehrere Instanzen verfügen oder letztendlich gelöscht werden. Wenn sie mit einem Containerorchestrator verwaltet werden, müssen Sie davon ausgehen, dass sie zwischen Knoten oder virtuellen Computern verschoben werden.
Die folgenden Lösungen werden verwendet, um Daten in Docker-Anwendungen zu verwalten:
Über den Docker-Host als Docker-Volumes:
Volumes werden in einem Bereich des Hostdateisystems gespeichert, der von Docker verwaltet wird.
Einbindungen über „Bind“ können jedem Ordner im Hostdateisystem zugeordnet werden, sodass der Zugriff nicht vom Docker-Prozess gesteuert werden kann – dies wäre ein Sicherheitsrisiko, weil ein Container auf vertrauliche Betriebssystemordner zugreifen könnte.
Einbindungen über tmpfs sind ähnlich wie virtuelle Ordner, die nur im Arbeitsspeicher des Hosts vorhanden sind und nie in das Dateisystem geschrieben werden.
Über den Remotespeicher:
Azure Storage, das geografisch verteilbaren Speicher und eine geeignete Lösung für langfristige Persistenz für Container bereitstellt.
Relationale Remotedatenbanken wie die Azure SQL-Datenbank oder NoSQL-Datenbanken wie Azure Cosmos DB oder Zwischenspeicherdienste wie Redis.
Über den Docker-Container:
- Overlay File System. Dieses Docker-Feature implementiert ein Copy-on-Write-Task, der aktualisierte Informationen im Stammdateisystem des Containers speichert. Diese Information befindet sich „über“ dem ursprünglichen Image, auf dem der Container basiert. Wenn der Container aus dem System gelöscht wird, gehen diese Änderungen verloren. Aus diesem Grund ist es zwar möglich, den Zustand eines Containers in seinem lokalen Speicher zu speichern, doch das Entwerfen eines umgehenden Systems würde mit der Prämisse des Containerdesigns kollidieren, das standardmäßig zustandslos ist.
Allerdings stellt die Verwendung von Docker-Volumes mittlerweile das bevorzugte Verfahren zum Verwalten von lokalen Daten in Docker dar. Wenn Sie weitere Informationen zu Speichern in Container benötigen, lesen Sie Docker storage drivers (Docker-Speichertreiber) und About storage drivers (Über Speichertreiber).
Nachfolgend erhalten Sie weitere Details zu diesen Optionen:
Volumes sind Verzeichnisse, die vom Hostbetriebssystem den Verzeichnissen in Containern zugeordnet werden. Wenn Code im Container Zugriff auf das Verzeichnis hat, ist dies ein Zugriff auf ein Verzeichnis auf dem Hostbetriebssystem. Dieses Verzeichnis ist nicht an die Lebensdauer des Containers selbst gebunden, und es wird von Docker verwaltet und von der Kernfunktionalität des Hostcomputers isoliert. Deshalb sind diese Datenvolumes dazu entworfen, Daten unabhängig von der Lebensdauer des Containers beizubehalten. Wenn Sie einen Container oder ein Image aus dem Docker-Host löschen, werden die persistenten Daten im Datenvolume nicht gelöscht.
Volumes können benannt oder anonym sein (letzteres ist die Standardeinstellung). Benannte Volumes sind eine Weiterentwicklung von Datenvolumecontainern und vereinfachen die gemeinsame Nutzung von Daten durch Container. Volumes unterstützen auch Volumetreiber, mit denen Sie u.a. Daten auf Remotehosts speichern können.
Einbindungen über „Bind“ sind schon lange verfügbar und ermöglichen die Zuordnung jedes Ordners zu einem Bereitstellungspunkt in einem Container. Einbindungen über „Bind“ weisen mehr Einschränkungen als Volumes sowie einige erhebliche Sicherheitsprobleme auf, daher sind Volumes die empfohlene Option.
Einbindungen über tmpfs sind im Grunde virtuelle Ordner, die nur im Arbeitsspeicher des Hosts vorhanden sind und nie in das Dateisystem geschrieben werden. Sie sind schnell und sicher, verbrauchen aber Arbeitsspeicher und sind nur für temporäre, nicht persistente Daten vorgesehen.
Wie in Abbildung 4-5 gezeigt, können reguläre Docker-Volumes außerhalb der Container selbst aber innerhalb der physischen Grenzen des Hostservers oder der VM gespeichert werden. Docker-Container können jedoch nicht von einem Hostserver oder virtuellen Computer aus auf ein Volume auf einem anderen Hostserver oder virtuellen Computer zugreifen. Anders gesagt: Bei diesen Volumes ist es nicht möglich, Daten zu verwalten, die von auf verschiedenen Docker-Hosts ausgeführten Containern gemeinsam verwendet werden. Dieses Szenario ließe sich allerdings mit einem Volumetreiber umsetzen, der Remotehosts unterstützt.
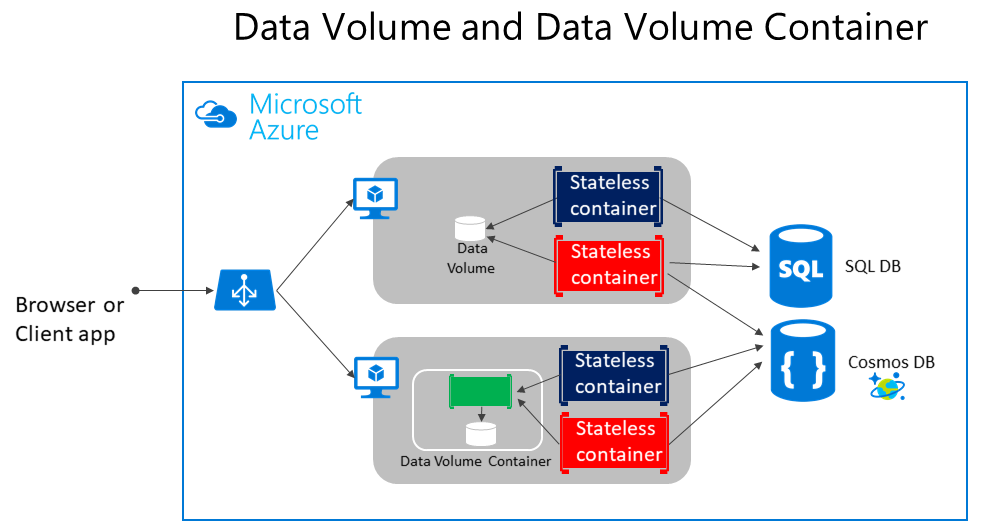
Abbildung 4-5. Volumes und externe Datenquellen für containerbasierte Anwendungen
Volumes können von Containern gemeinsam genutzt werden, allerdings nur auf demselben Host, es sei denn, Sie verwenden einen Remotetreiber, der Remotehosts unterstützt. Darüber hinaus können Docker-Container möglicherweise zwischen Hosts verschoben werden, wenn sie von einem Orchestrator verwaltet werden. Dies hängt von den vom Cluster durchgeführten Optimierungen ab. Aus diesem Grund wird nicht empfohlen, Datenvolumes für Geschäftsdaten zu verwenden. Dennoch sind sie ein guter Mechanismus zum Arbeiten mit Ablaufverfolgungsdateien, temporären Dateien oder ähnlichen Strukturen, die keine Auswirkung auf die Konsistenz von Geschäftsdaten haben.
Tools für Remotedatenquellen und -caches wie Azure SQL-Datenbank, Azure Cosmos DB oder ein Remotecache wie Redis können in Containeranwendungen auf die gleiche Weise verwendet werden wie bei der Entwicklung ohne Container. Dies ist eine bewährte Möglichkeit zum Speichern von Geschäftsanwendungsdaten.
„Azure Storage“. Geschäftsdaten müssen in der Regel in externen Ressourcen oder Datenbanken wie Azure Storage abgelegt werden. Azure Storage bietet konkret die folgenden Dienste in der Cloud:
Blob Storage dient zum Speichern unstrukturierter Objektdaten. Ein Blob kann jeder Text- oder Binärdatentyp sein, z.B. Dokumenten- oder Mediendaten (Bilder, Audio- und Videodateien). Blob Storage wird auch als Objektspeicher bezeichnet.
File Storage bietet freigegebenen Speicher für Legacyanwendungen mithilfe von SMB-Standardprotokollen. Azure Virtual Machines und Clouddienste können Dateidaten mithilfe bereitgestellter Freigaben für mehrere Anwendungskomponenten freigeben. Lokale Anwendungen können über die REST-API des Dateidiensts auf Dateidaten in einer Freigabe zugreifen.
Table Storage speichert strukturierte Datasets. File Storage ist ein NoSQL-Schlüsselattributdatenspeicher, der schnelle Entwicklung sowie den schnellen Zugriff auf große Datenmengen ermöglicht.
Relationale Datenbanken und NoSQL-Datenbanken. Es gibt viele Optionen für externe Datenbanken, z. B. relationale Datenbanken wie SQL Server, PostgreSQL, Oracle oder NoSQL-Datenbanken wie Azure Cosmos DB oder MongoDB. Diese Datenbanken werden in diesem Leitfaden nicht erläutert, da sie zu einem anderen Thema gehören.