Beobachtbarkeitsmuster
Tipp
Diese Inhalte sind ein Auszug aus dem E-Book „Architecting Cloud Native .NET Applications for Azure“, verfügbar in der .NET-Dokumentation oder als kostenlos herunterladbare PDF-Datei, die offline gelesen werden kann.

Ebenso wie Muster entwickelt wurden, um das Layout von Code in Anwendungen zu unterstützen, gibt es Muster für die Bedienung von Anwendungen auf zuverlässige Weise. Drei nützliche Muster bei der Verwaltung von Anwendungen sind entstanden: Protokollierung, Überwachung und Warnungen.
Empfohlene Verwendung der Protokollierung
Unabhängig davon, wie vorsichtig wir sind, verhalten sich Anwendungen fast immer auf unerwartete Weise in der Produktionsumgebung. Wenn Benutzer Probleme mit einer Anwendung melden, ist es hilfreich, sehen zu können, was in der App vor sich ging, als das Problem auftrat. Eine der bewährtesten Methoden zur Erfassung von Informationen darüber, wie eine Anwendung arbeitet, während sie ausgeführt wird, besteht darin, die Anwendung aufzeichnen zu lassen, was sie gerade unternimmt. Dieser Prozess wird als Protokollierung bezeichnet. Immer wenn in der Produktion Fehler oder Probleme auftreten, sollte das Ziel sein, die Bedingungen, unter denen die Fehler aufgetreten sind, in einer Nicht-Produktionsumgebung zu reproduzieren. Eine gute Protokollierung bietet Entwicklern eine Roadmap, die Sie befolgen können, um Probleme in einer Umgebung zu duplizieren, die getestet und ausprobiert werden kann.
Herausforderungen bei der Protokollierung mit cloudnativen Anwendungen
In herkömmlichen Anwendungen werden Protokolldateien in der Regel auf dem lokalen Computer gespeichert. Auf Unix-ähnlichen Betriebssystemen gibt es sogar eine Ordnerstruktur, in der alle Protokolle gespeichert werden, normalerweise unter /var/log.
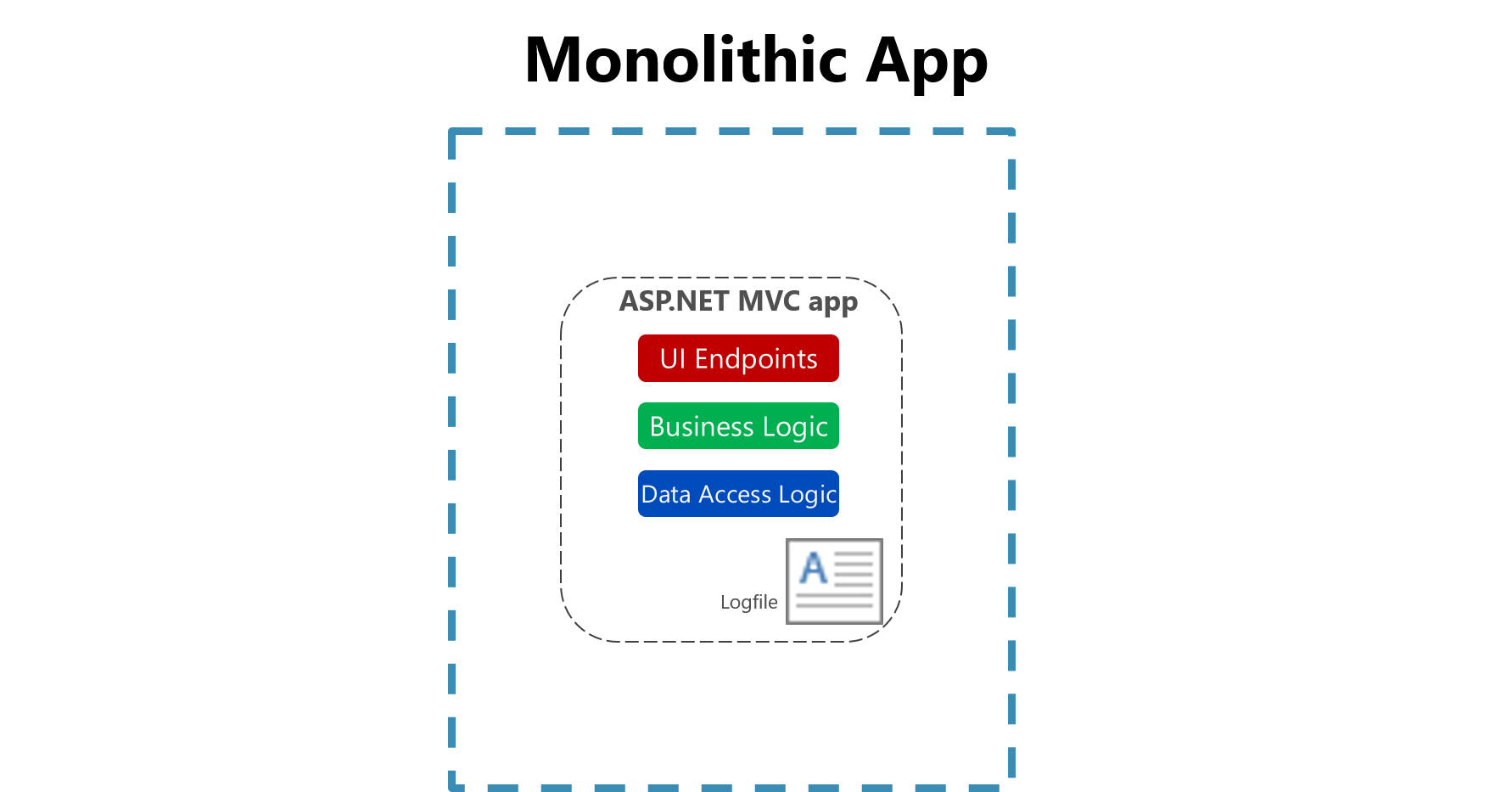 Abbildung 7-1. Protokollierung in eine Datei in einer monolithischen App.
Abbildung 7-1. Protokollierung in eine Datei in einer monolithischen App.
Die Nützlichkeit der Protokollierung in einer Flatfile auf einem einzelnen Computer wird in einer Cloudumgebung erheblich eingeschränkt. Anwendungen, die Protokolle produzieren, haben möglicherweise keinen Zugriff auf den lokalen Datenträger, oder der lokale Datenträger ist hochgradig transient (vorübergehend), da die Container auf verschiedenen physischen Computern verschoben werden. Selbst einfaches Hochskalieren von monolithischen Anwendungen über mehrere Knoten hinweg kann es schwierig gestalten, die entsprechende dateibasierte Protokolldatei zu finden.
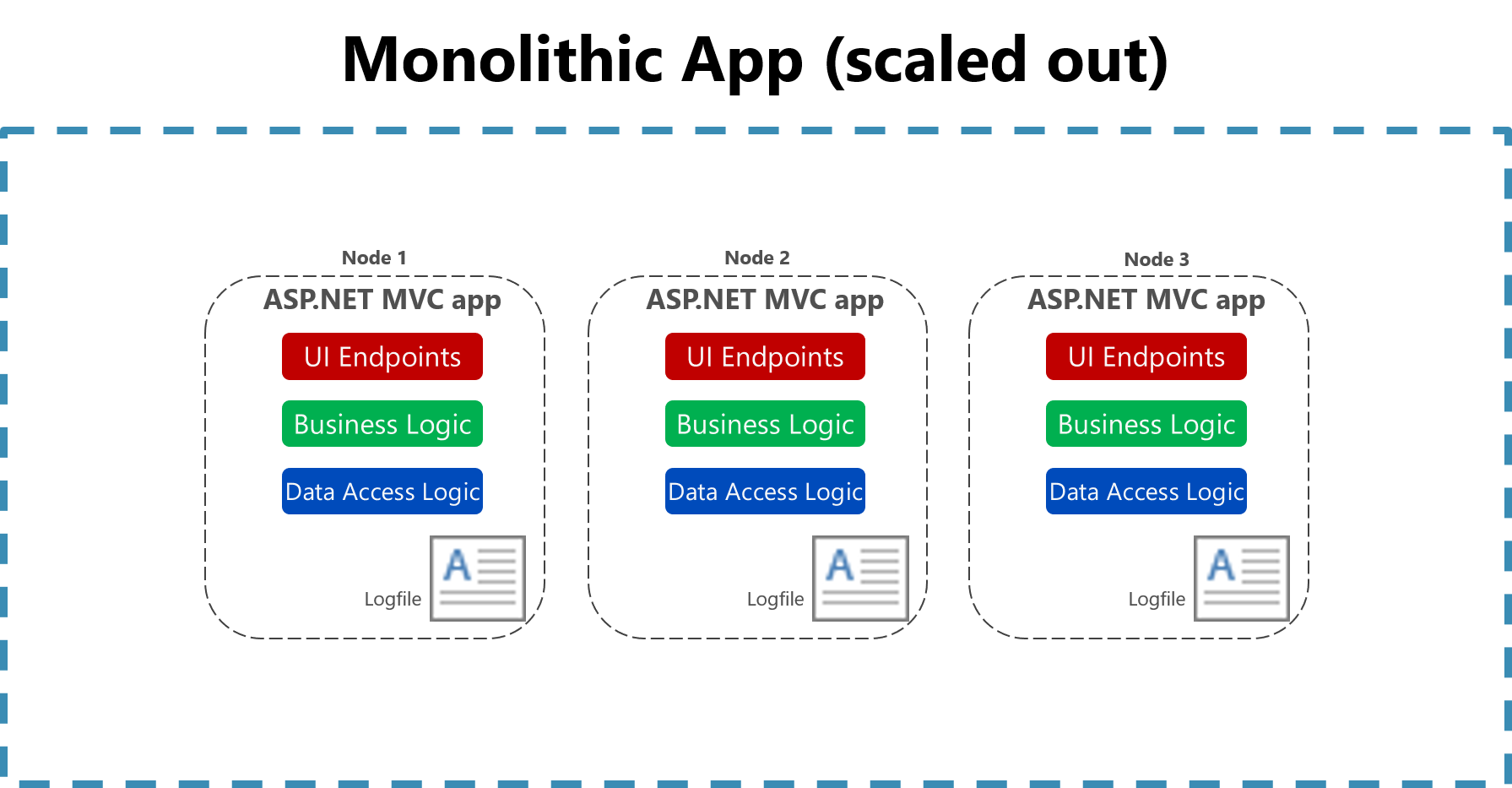 Abbildung 7-2. Protokollierung in Dateien in einer skalierten monolithischen App.
Abbildung 7-2. Protokollierung in Dateien in einer skalierten monolithischen App.
Cloudnative Anwendungen, die mit einer Microservices-Architektur entwickelt wurden, stellen auch einige Herausforderungen für dateibasierte Protokollierungen dar. Benutzeranforderungen können sich jetzt über mehrere Dienste erstrecken, die auf verschiedenen Computern ausgeführt werden, und können auch serverlose Funktionen ohne Zugriff auf ein lokales Dateisystem umfassen. Es wäre sehr schwierig, die Protokolle von einem Benutzer oder einer Sitzung über diese vielen Dienste und Computer hinweg zu korrelieren.
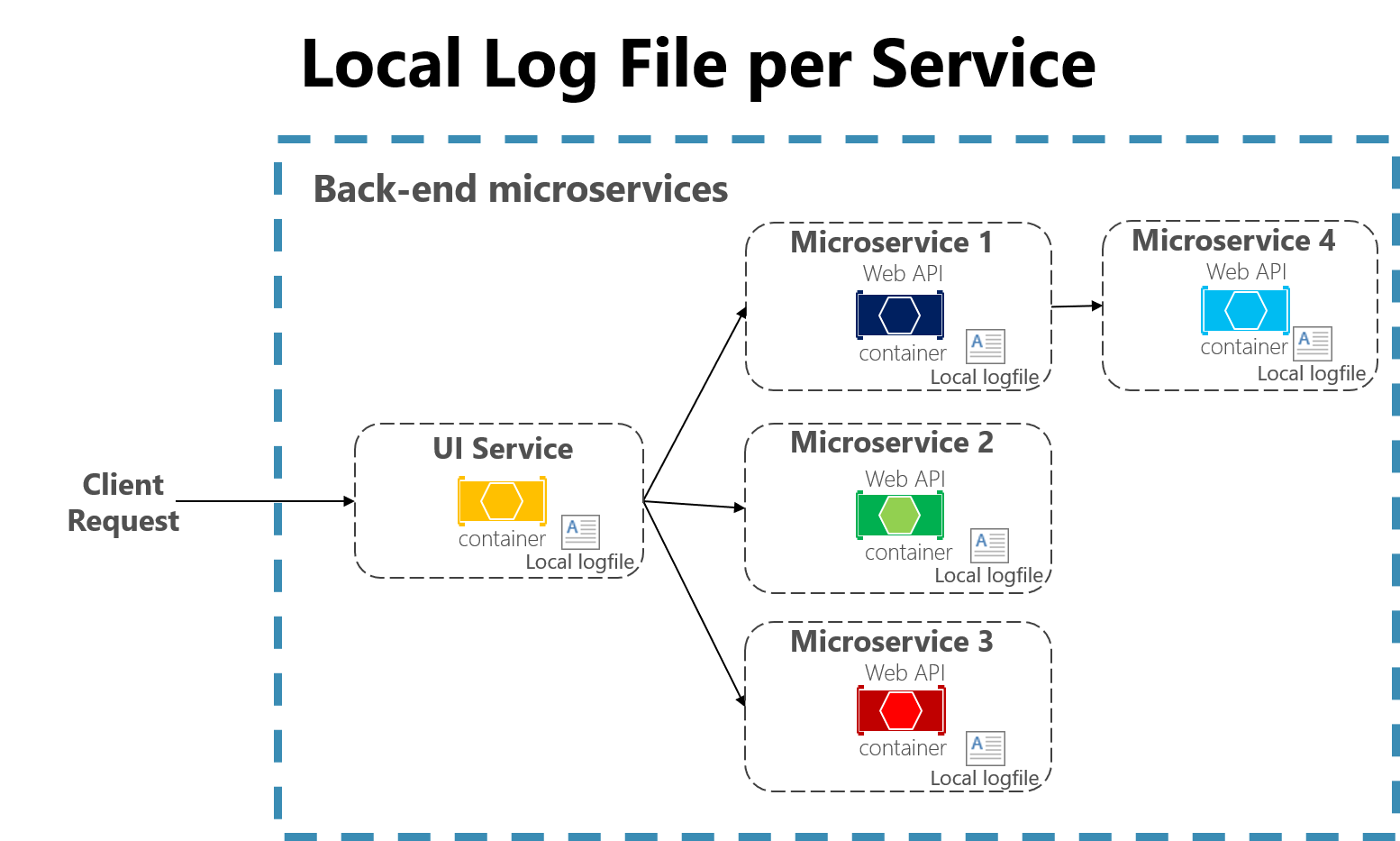 Abbildung 7-3. Protokollierung in lokalen Dateien in einer Microservices-App.
Abbildung 7-3. Protokollierung in lokalen Dateien in einer Microservices-App.
Schließlich ist die Anzahl der Benutzer in einigen cloudnativen Anwendungen hoch. Stellen Sie sich vor, jeder Benutzer generiert hundert Zeilen von Protokollnachrichten, wenn er sich bei einer Anwendung anmeldet. Für sich genommen ist das überschaubar, aber wird das mit 100.000 Benutzern multipliziert, wird das Volumen der Protokolle so groß, dass spezielle Tools benötigt werden, um die Protokolle effektiv zu verwenden.
Protokollierung in cloudnativen Anwendungen
Jede Programmiersprache verfügt über Tools, die das Schreiben von Protokollen zulassen, und in der Regel ist der Aufwand zum Schreiben dieser Protokolle gering. Viele der Protokollierungsbibliotheken bieten verschiedene Arten von Kritikalitäten, die zur Laufzeit optimiert werden können. Beispielsweise ist die Serilog-Bibliothek eine beliebte strukturierte Protokollierungsbibliothek für .NET, die die folgenden Protokollierungsebenen bereitstellt:
- Ausführlich
- Debuggen
- Information
- Warnung
- Fehler
- Schwerwiegend
Diese verschiedenen Protokollebenen bieten Granularität bei der Protokollierung. Wenn die Anwendung in der Produktion ordnungsgemäß funktioniert, kann sie so konfiguriert werden, dass nur wichtige Nachrichten protokolliert werden. Wenn die Anwendung nicht ordnungsgemäß funktioniert, kann die Protokollebene erhöht werden, sodass ausführlichere Protokolle gesammelt werden. Dies schafft ein Gleichgewicht zwischen Leistung und einfachem Debuggen.
Die hohe Leistung von Protokollierungstools und die Abstimmbarkeit der Ausführlichkeit sollten Entwickler zum häufigen Protokollieren ermutigen. Viele bevorzugen ein Muster, bei dem der Einstieg und Ausstieg jeder Methode protokolliert wird. Dieser Ansatz mag nach zu viel Aufwand klingen, aber es kommt selten vor, dass Entwickler eine weniger umfangreiche Protokollierung wünschen. In der Tat ist es nicht ungewöhnlich, dass eine Bereitstellung nur zu dem Zweck erfolgt, die Protokollierung zu einer problematischen Methode hinzuzufügen. Achten Sie darauf, dass Sie lieber zu viel und nicht zu wenig protokollieren. Einige Tools können verwendet werden, um diese Art von Protokollierung automatisch bereitzustellen.
Aufgrund der Herausforderungen, die mit der Verwendung dateibasierter Protokolle in cloudnativen Apps verbunden sind, werden zentralisierte Protokolle bevorzugt. Protokolle werden von den Anwendungen erfasst und an eine zentrale Protokollierungsanwendung weitergeleitet, die die Protokolle indiziert und speichert. Diese Klasse von Systemen kann täglich Dutzende von Gigabytes an Protokollen erfassen.
Es ist auch hilfreich, einige Standardpraktiken beim Erstellen von Protokollierungen zu befolgen, die viele Dienste umfassen. Durch das Generieren einer Korrelations-ID zu Beginn einer langen Interaktion und anschließendes Protokollieren in jeder Nachricht, die mit dieser Interaktion verknüpft ist, erleichtert dies die Suche nach allen zusammenhängenden Nachrichten. Sie brauchen nur eine einzelne Nachricht zu finden und die Korrelations-ID zu extrahieren, um alle zugehörigen Nachrichten zu finden. Ein weiteres Beispiel ist die Sicherstellung, dass das Protokollformat für jeden Dienst gleich ist, unabhängig von der verwendeten Sprache oder Protokollierungsbibliothek. Diese Standardisierung vereinfacht das Lesen von Protokollen erheblich. Abbildung 7-4 zeigt, wie eine Microservices-Architektur die zentralisierte Protokollierung als Teil des Workflows nutzen kann.
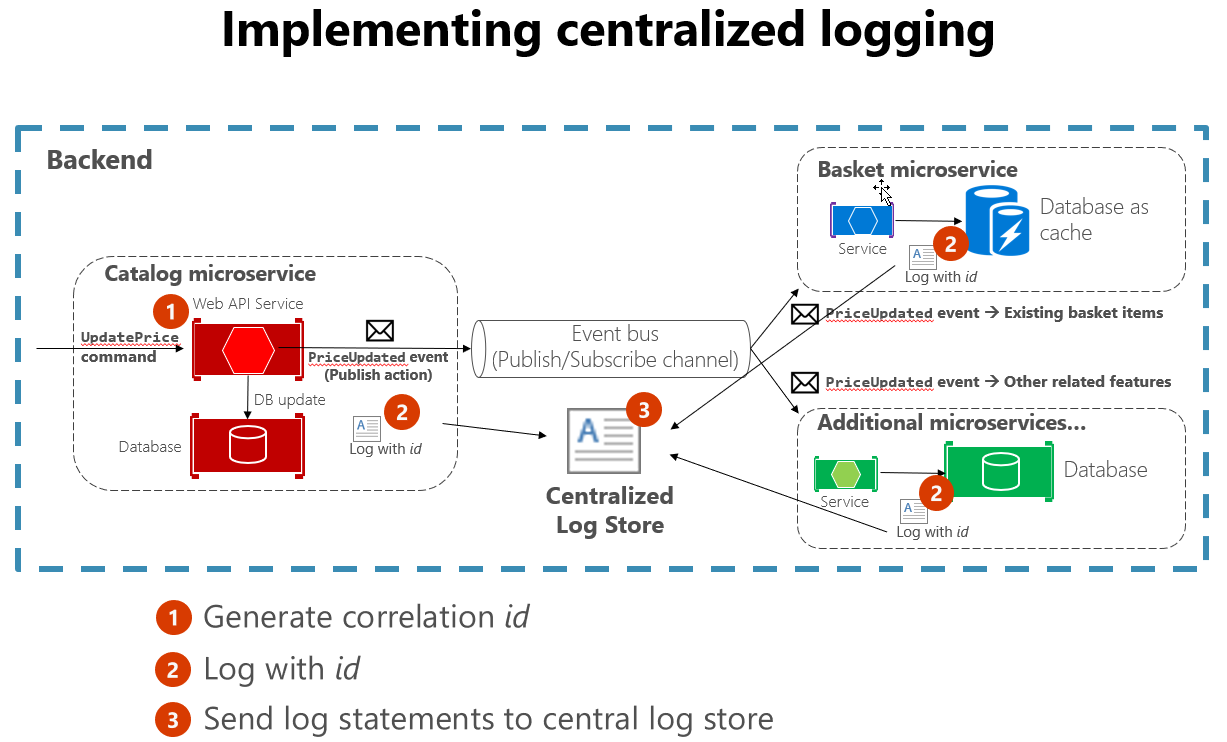 Abbildung 7-4. Protokolle aus verschiedenen Quellen werden in einen zentralen Protokollspeicher erfasst.
Abbildung 7-4. Protokolle aus verschiedenen Quellen werden in einen zentralen Protokollspeicher erfasst.
Herausforderungen beim Erkennen und Reagieren auf potenzielle App-Integritätsprobleme
Einige Anwendungen sind nicht unternehmenskritisch. Vielleicht werden sie nur intern verwendet, und wenn ein Problem auftritt, kann der Benutzer das zuständige Team kontaktieren und die Anwendung kann neu gestartet werden. Die Kunden haben jedoch oft höhere Erwartungen an die Anwendungen, die sie nutzen. Sie sollten wissen, wenn Probleme mit Ihrer Anwendung auftreten, bevor die Benutzer dies merken oder bevor die Benutzer Sie benachrichtigen. Andernfalls erfahren Sie vielleicht erst dann von einem Problem, wenn Sie eine Flut von Posts in den sozialen Medien bemerken, in denen Ihre Anwendung oder sogar Ihr Unternehmen verhöhnt wird.
Einige Szenarien, die Sie möglicherweise in Betracht ziehen müssen, sind:
- Ein Dienst in Ihrer Anwendung fällt immer wieder aus und wird neu gestartet, was zeitweiligen zu langsamen Antworten führt.
- Zu manchen Tageszeiten ist die Reaktionszeit Ihrer Anwendung langsam.
- Nach einer kürzlichen Bereitstellung hat sich die Auslastung der Datenbank verdreifacht.
Richtig implementiert, kann die Überwachung Sie über Zustände informieren, die zu Problemen führen, sodass Sie die zugrunde liegenden Bedingungen beheben können, bevor sie erhebliche Auswirkungen auf die Benutzer haben.
Überwachen cloudnativer Apps
Einige zentralisierte Protokollierungssysteme übernehmen neben den reinen Protokollen auch die Aufgabe, Telemetriedaten zu sammeln. Sie können Metriken sammeln, z. B. die Zeit zum Ausführen einer Datenbankabfrage, die durchschnittliche Antwortzeit eines Webservers und sogar die durchschnittliche CPU-Last und Arbeitsspeicherauslastung, wie sie vom Betriebssystem gemeldet wird. In Verbindung mit den Protokollen können diese Systeme einen ganzheitlichen Überblick über die Integrität der Knoten im System und der Anwendung als Ganzes geben.
Die Metrikerfassungsfunktionen der Überwachungstools können auch manuell aus der Anwendung heraus eingesetzt werden. Geschäftsabläufe, die von besonderem Interesse sind, z. B. die Anmeldung neuer Benutzer oder die Aufgabe von Bestellungen, können so instrumentiert werden, dass sie einen Zähler im zentralen Überwachungssystem inkrementieren. Dieser Aspekt entsperrt die Überwachungstools, um nicht nur die Integrität der Anwendung zu überwachen, sondern auch die Integrität des Unternehmens.
Abfragen können in den Protokollaggregationstools erstellt werden, um nach bestimmten Statistiken oder Mustern zu suchen, die dann in grafischer Form auf benutzerdefinierten Dashboards angezeigt werden können. Häufig investieren Teams in große, wandmontierte Displays, auf denen die verschiedenen Statistiken zu einer Anwendung angezeigt werden. Auf diese Weise ist es einfach, die Probleme zu sehen, während sie auftreten.
Cloudnative Überwachungstools bieten Echtzeittelemetrie und Einblicke in Apps, unabhängig davon, ob es sich um monolithische Anwendungen mit einem einzelnen Prozess oder um verteilte Microservice-Architekturen handelt. Sie umfassen Tools, mit denen Daten aus der App gesammelt werden können, sowie Tools zum Abfragen und Anzeigen von Informationen zur Integrität der App.
Herausforderungen beim Reagieren auf kritische Probleme in cloudnativen Apps
Wenn Sie auf Probleme mit Ihrer Anwendung reagieren müssen, brauchen Sie eine Möglichkeit, die richtigen Mitarbeiter zu benachrichtigen. Dies ist das dritte Beobachtungsmuster für cloudnative Anwendungen und hängt von der Protokollierung und Überwachung ab. Ihre Anwendung muss über eine Protokollierung verfügen, damit Probleme diagnostiziert werden können und in einigen Fällen in Überwachungstools einfließen können. Sie muss überwacht werden, um Metriken und Integritätsdaten von Anwendungen an einem Ort zu sammeln. Sobald dies eingerichtet wurde, können Regeln erstellt werden, die Warnungen auslösen, wenn bestimmte Metriken außerhalb der akzeptablen Werte liegen.
In der Regel werden Warnungen auf einer Ebene über die Überwachung gelegt, sodass bestimmte Bedingungen entsprechende Warnungen auslösen, um Teammitglieder über dringende Probleme zu informieren. Einige Szenarien, die Warnungen erfordern können, umfassen:
- Einer der Dienste Ihrer Anwendung reagiert nach einer Downtime von einer Minute nicht.
- Ihre Anwendung gibt erfolglose HTTP-Antworten auf mehr als 1 % der Anforderungen zurück.
- Die durchschnittliche Antwortzeit Ihrer Anwendung für wichtige Endpunkte überschreitet 2000 ms.
Warnungen in cloudnativen Apps
Sie können Abfragen für die Überwachungstools erstellen, um nach bekannten Fehlerbedingungen zu suchen. Beispielsweise könnten Abfragen die eingehenden Protokolle nach Hinweisen auf HTTP-Statuscode 500 durchsuchen, was auf ein Problem auf einem Webserver hinweist. Sobald einer dieser Fälle entdeckt wird, kann eine E-Mail oder eine SMS an den Besitzer des Diensts gesendet werden, der die Ermittlungen einleiten kann.
Normalerweise reicht jedoch ein einzelner 500-Fehler nicht aus, um festzustellen, dass ein Problem aufgetreten ist. Es könnte auch bedeuten, dass ein Benutzer sein Kennwort falsch oder einige nicht wohlgeformte Daten eingegeben hat. Die Warnungsabfragen können so gestaltet werden, dass sie nur ausgelöst werden, wenn eine überdurchschnittliche Anzahl von Fehlern vom Typ 500 erkannt wird.
Eines der schädlichsten Muster bei Warnungen besteht darin, zu viele Warnungen auszulösen, die von Mitarbeitern untersucht werden müssen. Besitzer von Diensten werden schnell desensibilisiert gegenüber Fehlern, die sie zuvor untersucht und für harmlos befunden haben. Wenn dann wirkliche Fehler auftreten, gehen sie im Durcheinander von Hunderten von False Positives unter. Das Gleichnis Der Junge, der „Wolf“ schrie wird Kindern häufig erzählt, um sie vor genau dieser Gefahr zu warnen. Es ist wichtig, sicherzustellen, dass die ausgelösten Warnungen auf ein echtes Problem hinweisen.