Überlegungen zur Anwendungsplattform für unternehmenskritische Workloads in Azure
Azure bietet viele Computedienste für das Hosten hoch verfügbarer Anwendungen. Die Dienste unterscheiden sich in der Funktion und Komplexität. Es wird empfohlen, dienste basierend auf:
- Nicht funktionale Anforderungen an Zuverlässigkeit, Verfügbarkeit, Leistung und Sicherheit.
- Entscheidungsfaktoren wie Skalierbarkeit, Kosten, Operierbarkeit und Komplexität.
Die Wahl einer Anwendungshostingplattform ist eine wichtige Entscheidung, die sich auf alle anderen Entwurfsbereiche auswirkt. Beispielsweise werden legacy- oder proprietäre Entwicklungssoftware möglicherweise nicht in PaaS-Diensten oder containerisierten Anwendungen ausgeführt. Diese Einschränkung würde ihre Wahl der Computeplattform beeinflussen.
Eine unternehmenskritische Anwendung kann mehrere Computedienste verwenden, um mehrere zusammengesetzte Workloads und Microservices mit unterschiedlichen Anforderungen zu unterstützen.
Dieser Entwurfsbereich enthält Empfehlungen im Zusammenhang mit der Berechnung von Auswahl-, Entwurfs- und Konfigurationsoptionen. Außerdem wird empfohlen, sich mit der Berechnungsentscheidungsstruktur vertraut zu machen.
Wichtig
Dieser Artikel ist Teil der Mission-Critical Workload-Reihe von Azure Well-Architected Framework. Wenn Sie mit dieser Reihe nicht vertraut sind, empfehlen wir Ihnen, mit "Was ist eine unternehmenskritische Workload?" zu beginnen.
Globale Verteilung von Plattformressourcen
Ein typisches Muster für eine unternehmenskritische Workload umfasst globale Ressourcen und regionale Ressourcen.
Azure-Dienste, die nicht auf eine bestimmte Azure-Region beschränkt sind, werden als globale Ressourcen bereitgestellt oder konfiguriert. Einige Anwendungsfälle umfassen das Verteilen von Datenverkehr über mehrere Regionen, das Speichern des dauerhaften Zustands für eine gesamte Anwendung und das Zwischenspeichern globaler statischer Daten. Wenn Sie sowohl eine Skalierungseinheitsarchitektur als auch eine globale Verteilung berücksichtigen müssen, überlegen Sie, wie Ressourcen optimal verteilt oder in Azure-Regionen repliziert werden.
Andere Ressourcen werden regional bereitgestellt. Diese Ressourcen, die als Teil eines Bereitstellungsstempels bereitgestellt werden, entsprechen in der Regel einer Skalierungseinheit. Eine Region kann jedoch mehrere Stempel aufweisen, und ein Stempel kann mehrere Einheiten aufweisen. Die Zuverlässigkeit regionaler Ressourcen ist von entscheidender Bedeutung, da sie für die Ausführung der Hauptarbeitsauslastung verantwortlich sind.
Die folgende Abbildung zeigt das allgemeine Design. Ein Benutzer greift über einen zentralen globalen Einstiegspunkt auf die Anwendung zu, der dann Anforderungen an einen geeigneten regionalen Bereitstellungsstempel umleitet:
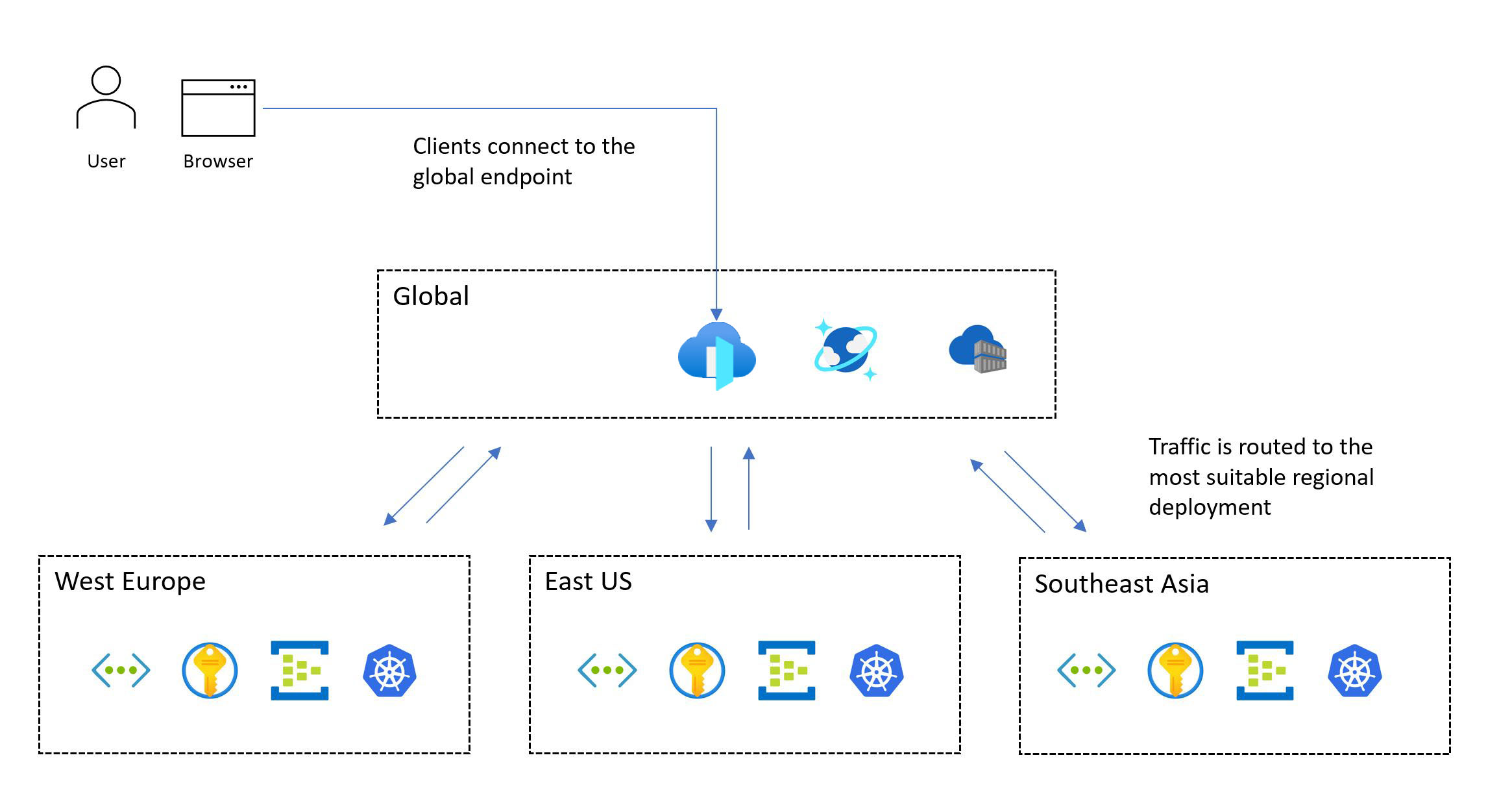
Die missionskritische Designmethodik erfordert eine Bereitstellung mit mehreren Regionen. Mit diesem Modell wird die regionale Fehlertoleranz sichergestellt, sodass die Anwendung auch dann verfügbar bleibt, wenn eine gesamte Region abläuft. Berücksichtigen Sie beim Entwerfen einer Multiregion-Anwendung verschiedene Bereitstellungsstrategien, z. B. aktiv/aktiv und aktiv/passiv, zusammen mit Anwendungsanforderungen, da für jeden Ansatz erhebliche Kompromisse bestehen. Für unternehmenskritische Workloads empfehlen wir dringend das aktive/aktive Modell.
Nicht jede Workload unterstützt oder erfordert gleichzeitiges Ausführen mehrerer Regionen. Sie sollten bestimmte Anwendungsanforderungen gegen Kompromisse abwägen, um eine optimale Designentscheidung zu bestimmen. Für bestimmte Anwendungsszenarien mit niedrigeren Zuverlässigkeitszielen können aktive/passive oder Sharding geeignete Alternativen sein.
Verfügbarkeitszonen können hoch verfügbare regionale Bereitstellungen in verschiedenen Rechenzentren innerhalb einer Region bereitstellen. Fast alle Azure-Dienste sind entweder in einer Zonenkonfiguration verfügbar, in der der Dienst an eine bestimmte Zone delegiert wird, oder eine zonenredundante Konfiguration, bei der die Plattform automatisch sicherstellt, dass sich der Dienst über Zonen erstreckt und einem Zonenausfall standhalten kann. Diese Konfigurationen bieten Fehlertoleranz bis zur Rechenzentrumsebene.
Überlegungen zum Entwurf
Regionale und zonale Fähigkeiten. Nicht alle Dienste und Funktionen sind in jeder Azure-Region verfügbar. Diese Überlegung könnte sich auf die von Ihnen ausgewählten Regionen auswirken. Außerdem sind Verfügbarkeitszonen nicht in jeder Region verfügbar.
Regionale Paare. Azure-Regionen werden in regionale Paare gruppiert, die aus zwei Regionen in einer einzelnen Geografie bestehen. Einige Azure-Dienste verwenden gekoppelte Regionen, um die Geschäftskontinuität zu gewährleisten und einen Schutz vor Datenverlust zu gewährleisten. Beispielsweise repliziert Azure Geo-redundanter Speicher (GRS) Daten automatisch in eine sekundäre gekoppelte Region, um sicherzustellen, dass Daten dauerhaft sind, wenn die primäre Region nicht wiederhergestellt werden kann. Wenn sich ein Ausfall auf mehrere Azure-Regionen auswirkt, wird mindestens eine Region in jedem Paar für die Wiederherstellung priorisiert.
Datenkonsistenz. Berücksichtigen Sie bei Konsistenzproblemen die Verwendung eines global verteilten Datenspeichers, einer gestempelten regionalen Architektur und einer teilweise aktiven/aktiven Bereitstellung. In einer Teilbereitstellung sind einige Komponenten in allen Regionen aktiv, während andere zentral in der primären Region liegen.
Sichere Bereitstellung. Das Azure Safe Deployment Practice (SDP)-Framework stellt sicher, dass alle Code- und Konfigurationsänderungen (geplante Wartung) an der Azure-Plattform einem phasenweisen Rollout unterzogen werden. Die Integrität wird während der Freigabe auf Beeinträchtigungen analysiert. Nachdem Canary- und Pilotphasen erfolgreich abgeschlossen wurden, werden Plattformupdates über regionale Paare serialisiert, sodass jeweils nur eine Region in jedem Paar aktualisiert wird.
Plattformkapazität. Wie jeder Cloudanbieter verfügt Azure über endliche Ressourcen. Die Nichtverfügbarkeit kann das Ergebnis von Kapazitätsbeschränkungen in Regionen sein. Wenn es einen regionalen Ausfall gibt, gibt es eine Zunahme der Nachfrage nach Ressourcen, da die Arbeitsauslastung versucht, innerhalb der gekoppelten Region wiederherzustellen. Der Ausfall kann zu einem Kapazitätsproblem führen, bei dem angebot vorübergehend die Nachfrage nicht erfüllt.
Entwurfsempfehlungen
Stellen Sie Ihre Lösung in mindestens zwei Azure-Regionen bereit, um vor regionalen Ausfällen zu schützen. Stellen Sie sie in Regionen bereit, die über die Funktionen und Merkmale verfügen, die von der Workload benötigt werden. Die Funktionen sollten Leistungs- und Verfügbarkeitsziele erfüllen und gleichzeitig die Anforderungen an die Datenaufbewahrung und -aufbewahrung erfüllen.
Beispielsweise können einige Datencomplianceanforderungen die Anzahl der verfügbaren Regionen einschränken und potenziell Entwurfskompromittierungen erzwingen. In solchen Fällen wird dringend empfohlen, zusätzliche Investitionen in betriebsbereite Wrapper hinzuzufügen, um Fehler vorherzusagen, zu erkennen und darauf zu reagieren. Angenommen, Sie sind auf eine Geografie mit zwei Regionen beschränkt, und nur eine dieser Regionen unterstützt Verfügbarkeitszonen (3 + 1 Rechenzentrumsmodell). Erstellen Sie ein sekundäres Bereitstellungsmuster mithilfe der Fehlerdomänenisolation, damit beide Regionen in einer aktiven Konfiguration bereitgestellt werden können, und stellen Sie sicher, dass die primäre Region mehrere Bereitstellungsstempel enthält.
Wenn geeignete Azure-Regionen nicht alle funktionen bieten, die Sie benötigen, sollten Sie darauf vorbereitet sein, die Konsistenz regionaler Bereitstellungsstempel zu kompromittieren, um die geografische Verteilung zu priorisieren und die Zuverlässigkeit zu maximieren. Wenn nur eine einzelne Azure-Region geeignet ist, stellen Sie mehrere Bereitstellungsstempel (regionale Skalierungseinheiten) in der ausgewählten Region bereit, um einige Risiken zu minimieren, und verwenden Sie Verfügbarkeitszonen, um Fehlertoleranz auf Rechenzentrumsebene bereitzustellen. Ein solcher erheblicher Kompromiss bei der geografischen Verteilung schränkt jedoch die erreichbare zusammengesetzte SLO und die Gesamtsicherheit erheblich ein.
Wichtig
Für Szenarien, die auf ein SLO abzielen, das größer oder gleich 99,99 % ist, empfehlen wir mindestens drei Bereitstellungsregionen. Berechnen Sie den zusammengesetzten SLO für alle Benutzerflüsse. Stellen Sie sicher, dass diese Ziele an Geschäftsziele ausgerichtet sind.
Entwerfen Sie für szenarien mit hoher Skalierung, die erhebliche Datenverkehrsmengen aufweisen, die Lösung so, dass sie in mehreren Regionen skaliert wird, um in potenziellen Kapazitätsbeschränkungen innerhalb einer einzelnen Region zu navigieren. Zusätzliche regionale Bereitstellungsstempel können einen höheren zusammengesetzten SLO erreichen. Weitere Informationen finden Sie unter Implementierung von Multiregionszielen.
Definieren und überprüfen Sie Ihre Wiederherstellungspunktziele (RPO) und Wiederherstellungszeitziele (Recovery Time Objectives, RTO).
Priorisieren Sie innerhalb einer einzelnen Geografie die Verwendung regionaler Paare, um von serialisierten SDP-Rollouts für geplante Wartung und regionale Priorisierung für ungeplante Wartungen zu profitieren.
Ordnen Sie Azure-Ressourcen geografisch mit Benutzern zusammen, um die Netzwerklatenz zu minimieren und die End-to-End-Leistung zu maximieren.
- Sie können auch Lösungen wie ein Content Delivery Network (CDN) oder Edgezwischenspeicherung verwenden, um eine optimale Netzwerklatenz für verteilte Benutzerbasen zu fördern. Weitere Informationen finden Sie unter "Globales Datenverkehrsrouting", "Anwendungsübermittlungsdienste" und "Zwischenspeichern" und "Statische Inhaltsübermittlung".
Richten Sie die aktuelle Dienstverfügbarkeit an Produktroadmaps aus, wenn Sie Bereitstellungsregionen auswählen. Einige Dienste sind möglicherweise nicht sofort in jeder Region verfügbar.
Containerisierung
Ein Container enthält Anwendungscode und die zugehörigen Konfigurationsdateien, Bibliotheken und Abhängigkeiten, die die Anwendung ausführen muss. Die Containerisierung stellt eine Abstraktionsebene für Anwendungscode und deren Abhängigkeiten bereit und erstellt eine Trennung von der zugrunde liegenden Hostingplattform. Das einzelne Softwarepaket ist sehr portierbar und kann konsistent auf verschiedenen Infrastrukturplattformen und Cloudanbietern ausgeführt werden. Entwickler müssen Code nicht neu schreiben und können Anwendungen schneller und zuverlässiger bereitstellen.
Wichtig
Es wird empfohlen, Container für unternehmenskritische Anwendungspakete zu verwenden. Sie verbessern die Infrastrukturnutzung, da Sie mehrere Container in derselben virtualisierten Infrastruktur hosten können. Da alle Software im Container enthalten ist, können Sie die Anwendung unabhängig von Laufzeiten oder Bibliotheksversionen auf verschiedene Betriebssysteme verschieben. Die Verwaltung ist auch mit Containern einfacher als bei herkömmlichem virtualisiertem Hosting.
Unternehmenskritische Anwendungen müssen schnell skaliert werden, um Leistungsengpässe zu vermeiden. Da Containerimages vorkonfiguriert sind, können Sie den Start nur während des Bootstrappings der Anwendung einschränken, was eine schnelle Skalierbarkeit bietet.
Überlegungen zum Entwurf
Überwachung: Die Überwachung von Diensten kann schwierig sein, auf Anwendungen zuzugreifen, die sich in Containern befinden. Normalerweise benötigen Sie Software von Drittanbietern, um Containerstatusindikatoren wie CPU- oder RAM-Nutzung zu sammeln und zu speichern.
Sicherheit: Der Hostplattform-Betriebssystemkernkern wird für mehrere Container freigegeben, wodurch ein einzelner Angriffspunkt entsteht. Das Risiko des Zugriffs auf virtuelle Hostcomputer (VM) ist jedoch eingeschränkt, da Container vom zugrunde liegenden Betriebssystem isoliert sind.
Zustand Obwohl es möglich ist, Daten im Dateisystem eines ausgeführten Containers zu speichern, bleiben die Daten beim erneuten Erstellen des Containers nicht erhalten. Speichern Sie stattdessen Daten, indem Sie externen Speicher einbinden oder eine externe Datenbank verwenden.
Entwurfsempfehlungen
Containerisieren sie alle Anwendungskomponenten. Verwenden Sie Containerimages als primäres Modell für Anwendungsbereitstellungspakete.
Priorisieren Sie linuxbasierte Containerlaufzeiten nach Möglichkeit. Die Images sind einfacher, und neue Features für Linux-Knoten/-Container werden häufig veröffentlicht.
Sorgen Sie dafür, dass Container unveränderlich und austauschbar sind, mit kurzen Lebenszyklus.
Achten Sie darauf, alle relevanten Protokolle und Metriken aus dem Container, containerhost und dem zugrunde liegenden Cluster zu sammeln. Senden Sie die gesammelten Protokolle und Metriken an eine einheitliche Datensenke zur weiteren Verarbeitung und Analyse.
Speichern Sie Containerimages in der Azure-Containerregistrierung. Verwenden Sie die Georeplikation , um Containerimages in allen Regionen zu replizieren. Aktivieren Sie Microsoft Defender für Containerregistrierungen , um Sicherheitsrisikoüberprüfungen für Containerimages bereitzustellen. Stellen Sie sicher, dass der Zugriff auf die Registrierung von Microsoft Entra ID verwaltet wird.
Containerhosting und -orchestrierung
Mehrere Azure-Anwendungsplattformen können Container effektiv hosten. Es gibt Vor- und Nachteile, die mit jeder dieser Plattformen verbunden sind. Vergleichen Sie die Optionen im Kontext Ihrer Geschäftlichen Anforderungen. Optimieren Sie jedoch immer Zuverlässigkeit, Skalierbarkeit und Leistung. Weitere Informationen finden Sie in folgenden Artikeln:
Wichtig
Azure Kubernetes Service (AKS) und Azure Container Apps sollten je nach Ihren Anforderungen zu Ihren ersten Optionen für die Containerverwaltung gehören. Obwohl Azure-App Service kein Orchestrator ist, ist er als Containerplattform mit geringer Reibung immer noch eine machbare Alternative zu AKS.
Designüberlegungen und Empfehlungen für Azure Kubernetes Service
AKS, ein verwalteter Kubernetes-Dienst, ermöglicht eine schnelle Clusterbereitstellung ohne komplexe Clusterverwaltungsaktivitäten und bietet einen Featuresatz, der erweiterte Netzwerk- und Identitätsfunktionen umfasst. Eine vollständige Reihe von Empfehlungen finden Sie unter Azure Well-Architected Framework Review – AKS.
Wichtig
Es gibt einige grundlegende Konfigurationsentscheidungen, die Sie nicht ändern können, ohne den AKS-Cluster erneut bereitzustellen. Beispiele hierfür sind die Wahl zwischen öffentlichen und privaten AKS-Clustern, das Aktivieren der Azure-Netzwerkrichtlinie, die Microsoft Entra-Integration und die Verwendung von verwalteten Identitäten für AKS anstelle von Dienstprinzipalen.
Zuverlässigkeit
AKS verwaltet die systemeigene Kubernetes-Steuerungsebene. Wenn die Steuerungsebene nicht verfügbar ist, kommt die Arbeitsauslastung zu Ausfallzeiten. Nutzen Sie die Zuverlässigkeitsfeatures von AKS:
Stellen Sie AKS-Cluster in verschiedenen Azure-Regionen als Skalierungseinheit bereit, um Zuverlässigkeit und Verfügbarkeit zu maximieren. Verwenden Sie Verfügbarkeitszonen , um die Resilienz innerhalb einer Azure-Region zu maximieren, indem Sie AKS-Steuerebene und Agentknoten über physisch getrennte Rechenzentren verteilen. Wenn die Colocation-Latenz jedoch ein Problem darstellt, können Sie die AKS-Bereitstellung innerhalb einer einzelnen Zone durchführen oder Näherungsgruppen verwenden, um die Internodelatenz zu minimieren.
Verwenden Sie die AKS Uptime SLA für Produktionscluster, um Kubernetes-API-Endpunktverfügbarkeitsgarantien zu maximieren.
Skalierbarkeit
Berücksichtigen Sie AKS-Skalierungsgrenzwerte, z. B. die Anzahl der Knoten, Knotenpools pro Cluster und Cluster pro Abonnement.
Wenn Skalierungsgrenzwerte eine Einschränkung sind, nutzen Sie die Skalierungseinheitsstrategie und stellen Sie weitere Einheiten mit Clustern bereit.
Aktivieren Sie die automatische Clusterskalierung, um die Anzahl von Agent-Knoten als Reaktion auf Ressourceneinschränkungen automatisch anzupassen.
Verwenden Sie die horizontale Pod-Autoskalierung , um die Anzahl der Pods in einer Bereitstellung basierend auf der CPU-Auslastung oder anderen Metriken anzupassen.
Für Szenarien mit hoher Skalierung und Platzierung sollten Sie virtuelle Knoten für umfangreiche und schnelle Skalierung verwenden.
Definieren sie Pod-Ressourcenanforderungen und -beschränkungen in Anwendungsbereitstellungsmanifesten. Wenn dies nicht der Derb ist, treten möglicherweise Leistungsprobleme auf.
Isolation
Verwalten Sie Grenzen zwischen der Infrastruktur, die von der Workload und den Systemtools verwendet wird. Die Freigabeinfrastruktur kann zu einer hohen Ressourcenauslastung und zu lauten Nachbarszenarien führen.
Verwenden Sie separate Knotenpools für System- und Workloaddienste. Dedizierte Knotenpools für Workloadkomponenten sollten auf Anforderungen für spezialisierte Infrastrukturressourcen wie GPU-VMs mit hohem Arbeitsspeicher basieren. Um unnötigen Verwaltungsaufwand zu reduzieren, vermeiden Sie die Bereitstellung großer Anzahl von Knotenpools.
Verwenden Sie Taints und Tolerationen , um dedizierte Knoten bereitzustellen und ressourcenintensive Anwendungen einzuschränken.
Bewerten Sie Anwendungsaffinitäts- und Antiaffinitätsanforderungen, und konfigurieren Sie die entsprechende Kolocation von Containern auf Knoten.
Sicherheit
Standard-Vanille Kubernetes erfordert eine erhebliche Konfiguration, um einen geeigneten Sicherheitsstatus für unternehmenskritische Szenarien zu gewährleisten. AKS behandelt verschiedene Sicherheitsrisiken aus der Box. Zu den Features gehören private Cluster, Überwachung und Anmeldung bei Log Analytics, gehärteten Knotenbildern und verwalteten Identitäten.
Wenden Sie Konfigurationsanleitungen an, die in der AKS-Sicherheitsbasislinie bereitgestellt werden.
Verwenden Sie AKS-Features zum Behandeln von Clusteridentitäts- und Zugriffsverwaltung, um den Betriebsaufwand zu reduzieren und konsistente Zugriffsverwaltung anzuwenden.
Verwenden Sie verwaltete Identitäten anstelle von Dienstprinzipalen, um die Verwaltung und Drehung von Anmeldeinformationen zu vermeiden. Sie können verwaltete Identitäten auf Clusterebene hinzufügen. Auf Podebene können Sie verwaltete Identitäten über die Microsoft Entra Workload-ID verwenden.
Verwenden Sie die Microsoft Entra-Integration für die zentrale Kontoverwaltung und Kennwörter, die Anwendungszugriffsverwaltung und den erweiterten Identitätsschutz. Verwenden Sie Kubernetes RBAC mit Microsoft Entra-ID für geringste Berechtigungen, und minimieren Sie die Gewährung von Administratorrechten, um den Konfigurations- und geheimen Zugriff zu schützen. Beschränken Sie außerdem den Zugriff auf die Kubernetes-Clusterkonfigurationsdatei mithilfe der rollenbasierten Zugriffssteuerung von Azure. Beschränken Sie den Zugriff auf Aktionen, die Container ausführen können, stellen Sie die geringste Anzahl von Berechtigungen bereit, und vermeiden Sie die Verwendung der Stammberechtigungseskalation.
Upgrades
Cluster und Knoten müssen regelmäßig aktualisiert werden. AKS unterstützt Kubernetes-Versionen in Übereinstimmung mit dem Releasezyklus nativer Kubernetes.
Abonnieren Sie die öffentlichen AKS-Roadmap und Versionshinweise auf GitHub, um über bevorstehende Änderungen, Verbesserungen und vor allem Kubernetes-Versionsversionen und -veraltete Versionen auf dem neuesten Stand zu bleiben.
Wenden Sie die anleitungen in der AKS-Checkliste an, um die Ausrichtung mit bewährten Methoden sicherzustellen.
Beachten Sie die verschiedenen Methoden, die von AKS zum Aktualisieren von Knoten und/oder Clustern unterstützt werden. Diese Methoden können manuell oder automatisiert werden. Sie können die geplante Wartung verwenden, um Wartungsfenster für diese Vorgänge zu definieren. Neue Bilder werden wöchentlich veröffentlicht. AKS unterstützt außerdem automatisch upgradekanäle für das automatische Upgrade von AKS-Clustern auf neuere Versionen von Kubernetes und/oder neueren Knotenimages, wenn sie verfügbar sind.
Netzwerk
Bewerten Sie die Netzwerk-Plug-Ins, die am besten zu Ihrem Anwendungsfall passen. Bestimmen Sie, ob Sie eine differenzierte Steuerung des Datenverkehrs zwischen Pods benötigen. Azure-Support s kubenet, Azure CNI, und bringen Sie Eigene CNI für bestimmte Anwendungsfälle mit.
Priorisieren Sie die Verwendung von Azure CNI nach der Bewertung der Netzwerkanforderungen und der Größe des Clusters. Azure CNI ermöglicht die Verwendung von Azure- oder Calico-Netzwerkrichtlinien zum Steuern des Datenverkehrs innerhalb des Clusters.
Überwachung
Ihre Überwachungstools sollten Protokolle und Metriken aus ausgeführten Pods erfassen können. Sie sollten auch Informationen aus der Kubernetes-Metrik-API sammeln, um den Status der ausgeführten Ressourcen und Workloads zu überwachen.
Verwenden Sie Azure Monitor und Application Insights , um Metriken, Protokolle und Diagnosen aus AKS-Ressourcen für die Problembehandlung zu sammeln.
Aktivieren und Überprüfen von Kubernetes-Ressourcenprotokollen.
Konfigurieren Sie Prometheus-Metriken in Azure Monitor. Containereinblicke in Monitor bieten Onboarding, ermöglichen Überwachungsfunktionen sofort und ermöglichen erweiterte Funktionen über integrierte Prometheus-Unterstützung.
Governance
Verwenden Sie Richtlinien, um zentrale Schutzmaßnahmen auf AKS-Cluster einheitlich anzuwenden. Wenden Sie Richtlinienzuweisungen auf Abonnementebene oder höher an, um die Konsistenz in Entwicklungsteams zu steigern.
Steuern Sie, welche Funktionen Pods gewährt werden und ob die Ausführung einer Richtlinie unter Verwendung der Azure-Richtlinie widerspricht. Dieser Zugriff wird durch integrierte Richtlinien definiert, die durch das Azure Policy-Add-On für AKS bereitgestellt werden.
Richten Sie einen konsistenten Zuverlässigkeits- und Sicherheitsgrundwert für AKS-Cluster- und Podkonfigurationen mithilfe von Azure-Richtlinien ein.
Verwenden Sie das Azure-Richtlinien-Add-On für AKS , um Pod-Funktionen wie Stammberechtigungen zu steuern und Pods zu verbieten, die nicht den Richtlinien entsprechen.
Hinweis
Wenn Sie eine Bereitstellung in einer Azure-Zielzone ausführen, sollten die Azure-Richtlinien, die Ihnen helfen, eine konsistente Zuverlässigkeit und Sicherheit sicherzustellen, von der Implementierung der Zielzone bereitgestellt werden.
Die unternehmenskritischen Referenzimplementierungen stellen eine Reihe von Basisrichtlinien bereit, um empfohlene Zuverlässigkeits- und Sicherheitskonfigurationen voranzutreiben.
Designüberlegungen und Empfehlungen für Azure-App Service
Für Web- und API-basierte Workloadszenarien kann App Service eine machbare Alternative zu AKS sein. Es bietet eine reibungsarme Containerplattform ohne die Komplexität von Kubernetes. Eine vollständige Reihe von Empfehlungen finden Sie unter Zuverlässigkeitsüberlegungen für App Service und Operative Exzellenz für App Service.
Zuverlässigkeit
Erwägen Sie die Verwendung von TCP- und SNAT-Ports. TCP-Verbindungen werden für alle ausgehenden Verbindungen verwendet. SNAT-Ports werden für ausgehende Verbindungen mit öffentlichen IP-Adressen verwendet. SNAT-Portausschöpfung ist ein häufiges Ausfallszenario. Sie sollten dieses Problem prädiktiv erkennen, indem Sie Tests laden, während Sie Azure-Diagnose verwenden, um Ports zu überwachen. Wenn SNAT-Fehler auftreten, müssen Sie entweder mehr oder größere Mitarbeiter skalieren oder Codierungsmethoden implementieren, um SNAT-Ports beizubehalten und wiederzuverwenden. Beispiele für Codierungsmethoden, die Sie verwenden können, sind Verbindungspooling und das faule Laden von Ressourcen.
Die Tcp-Portausschöpfung ist ein weiteres Fehlerszenario. Dies tritt auf, wenn die Summe ausgehender Verbindungen von einem bestimmten Worker die Kapazität überschreitet. Die Anzahl der verfügbaren TCP-Ports hängt von der Größe des Workers ab. Empfehlungen finden Sie unter TCP- und SNAT-Ports.
Skalierbarkeit
Planen Sie zukünftige Skalierbarkeitsanforderungen und Anwendungswachstum, damit Sie von Anfang an geeignete Empfehlungen anwenden können. Auf diese Weise können Sie technische Migrationsschulden vermeiden, wenn die Lösung wächst.
Aktivieren Sie die automatische Skalierung, um sicherzustellen, dass ausreichende Ressourcen für Serviceanfragen verfügbar sind. Bewerten sie die Skalierung pro App für das Hosting mit hoher Dichte im App-Dienst.
Beachten Sie, dass der App-Dienst über ein standardmäßiges, weiches Limit von Instanzen pro App Service-Plan verfügt.
Anwenden von Regeln für die automatische Skalierung. Ein App Service-Plan wird skaliert, wenn eine Regel innerhalb des Profils erfüllt ist, aber nur skaliert wird, wenn alle Regeln innerhalb des Profils erfüllt sind. Verwenden Sie eine Kombination aus skalierungs- und skalierungsbasierten Regeln, um sicherzustellen, dass die Autoskala Aktionen ausführen kann, um sowohl das Skalieren als auch das Skalieren zu ermöglichen. Grundlegendes zum Verhalten mehrerer Skalierungsregeln in einem einzelnen Profil.
Beachten Sie, dass Sie die Skalierung pro App auf der Ebene des App Service-Plans aktivieren können, damit eine Anwendung unabhängig vom App Service-Plan skaliert werden kann, der sie hostt. Apps werden verfügbaren Knoten über einen Best-Effort-Ansatz für eine gleichmäßige Verteilung zugewiesen. Obwohl eine gleichmäßige Verteilung nicht garantiert ist, stellt die Plattform sicher, dass zwei Instanzen derselben App nicht in derselben Instanz gehostet werden.
Überwachung
Überwachen Sie das Anwendungsverhalten, und erhalten Sie Zugriff auf relevante Protokolle und Metriken, um sicherzustellen, dass Ihre Anwendung erwartungsgemäß funktioniert.
Sie können die Diagnoseprotokollierung verwenden, um Protokolle auf Anwendungsebene und Plattformebene in Log Analytics, Azure Storage oder ein Drittanbietertool über Azure Event Hubs aufzunehmen.
Anwendungsleistungsüberwachung mit Application Insights bietet tiefe Einblicke in die Anwendungsleistung.
Unternehmenskritische Anwendungen müssen die Fähigkeit haben, sich selbst zu heilen, wenn Fehler auftreten. Aktivieren Sie auto Heal , um fehlerhafte Mitarbeiter automatisch wiederzuverwenden.
Sie müssen geeignete Integritätsprüfungen verwenden, um alle kritischen nachgeschalteten Abhängigkeiten zu bewerten, was dazu beiträgt, die Gesamtintegrität zu gewährleisten. Es wird dringend empfohlen, die Integritätsprüfung zu aktivieren, um nicht reaktionsfähige Mitarbeiter zu identifizieren.
Bereitstellung
Um den Standardgrenzwert von Instanzen pro App Service-Plan zu umgehen, stellen Sie App Service-Pläne in mehreren Skalierungseinheiten in einer einzelnen Region bereit. Stellen Sie App Service-Pläne in einer Verfügbarkeitszonenkonfiguration bereit, um sicherzustellen, dass Arbeitsknoten über Zonen innerhalb einer Region verteilt werden. Erwägen Sie, ein Supportticket zu öffnen, um die maximale Anzahl von Mitarbeitern auf zweimal die Anzahl der Instanzen zu erhöhen, die Sie für die normale Spitzenlast benötigen.
Containerregistrierung
Containerregistrierungen hosten Images, die in Containerlaufzeitumgebungen wie AKS bereitgestellt werden. Sie müssen Ihre Containerregistrierungen für unternehmenskritische Workloads sorgfältig konfigurieren. Ein Ausfall sollte nicht zu Verzögerungen beim Ziehen von Bildern führen, insbesondere bei Skalierungsvorgängen. Die folgenden Überlegungen und Empfehlungen konzentrieren sich auf die Azure-Containerregistrierung und untersuchen die Kompromisse, die mit zentralisierten und Verbundbereitstellungsmodellen verknüpft sind.
Überlegungen zum Entwurf
Format: Erwägen Sie die Verwendung einer Containerregistrierung, die auf dem von Docker bereitgestellten Format und den Standards für Push- und Pullvorgänge basiert. Diese Lösungen sind kompatibel und meist austauschbar.
Bereitstellungsmodell: Sie können die Containerregistrierung als zentralen Dienst bereitstellen, der von mehreren Anwendungen innerhalb Ihrer Organisation genutzt wird. Sie können sie auch als dedizierte Komponente für eine bestimmte Anwendungsworkloads bereitstellen.
Öffentliche Register. Containerimages werden in Docker Hub oder anderen öffentlichen Registrierungen gespeichert, die außerhalb von Azure und einem bestimmten virtuellen Netzwerk vorhanden sind. Dies ist nicht unbedingt ein Problem, kann aber zu verschiedenen Problemen führen, die mit der Dienstverfügbarkeit, Drosselung und Datenexfiltration zusammenhängen. Für einige Anwendungsszenarien müssen Sie öffentliche Containerimages in einer privaten Containerregistrierung replizieren, um den Datenverkehr einzuschränken, die Verfügbarkeit zu erhöhen oder potenzielle Drosselung zu vermeiden.
Entwurfsempfehlungen
Verwenden Sie Containerregistrierungsinstanzen, die der Anwendungsworkload zugeordnet sind. Vermeiden Sie das Erstellen einer Abhängigkeit von einem zentralisierten Dienst, es sei denn, die Anforderungen an die Verfügbarkeit und Zuverlässigkeit der Organisation sind vollständig an die Anwendung angepasst.
Im empfohlenen Kernarchitekturmuster sind Containerregistrierungen globale Ressourcen, die lange leben. Erwägen Sie die Verwendung einer einzelnen globalen Containerregistrierung pro Umgebung. Verwenden Sie beispielsweise eine globale Produktionsregistrierung.
Stellen Sie sicher, dass die SLA für die öffentliche Registrierung mit Ihren Zuverlässigkeits- und Sicherheitszielen übereinstimmt. Beachten Sie besondere Einschränkungen für Anwendungsfälle, die von Docker Hub abhängen.
Priorisieren Sie die Azure-Containerregistrierung für das Hosten von Containerimages.
Entwurfsüberlegungen und Empfehlungen für die Azure-Containerregistrierung
Dieser systemeigene Dienst bietet eine Reihe von Features, einschließlich Georeplikation, Microsoft Entra-Authentifizierung, automatisiertes Erstellen von Containern und Patching über Containerregistrierungsaufgaben.
Zuverlässigkeit
Konfigurieren Sie die Georeplikation für alle Bereitstellungsregionen, um regionale Abhängigkeiten zu entfernen und die Latenz zu optimieren. Containerregistrierung unterstützt hohe Verfügbarkeit durch Georeplikation auf mehrere konfigurierte Regionen, wodurch Resilienz gegenüber regionalen Ausfällen bereitgestellt wird. Wenn eine Region nicht verfügbar ist, werden die anderen Regionen weiterhin Bildanforderungen bedient. Wenn die Region wieder online ist, stellt die Containerregistrierung Änderungen wieder her und repliziert sie. Diese Funktion ermöglicht auch die Colocation der Registrierung in jeder konfigurierten Region, wodurch die Netzwerkwartezeit und die Kosten regionsübergreifender Datenübertragungen reduziert werden.
In Azure-Regionen, die Verfügbarkeitszonenunterstützung bereitstellen, unterstützt die Premium-Containerregistrierungsstufe Zonenredundanz , um Schutz vor Zonenfehlern zu bieten. Die Premium-Stufe unterstützt auch private Endpunkte , um unbefugten Zugriff auf die Registrierung zu verhindern, was zu Zuverlässigkeitsproblemen führen kann.
Hosten Sie Bilder in der Nähe der verbrauchenden Computeressourcen innerhalb derselben Azure-Regionen.
Bildsperrung
Bilder können aufgrund eines manuellen Fehlers gelöscht werden. Containerregistrierung unterstützt das Sperren einer Imageversion oder eines Repositorys , um Änderungen oder Löschungen zu verhindern. Wenn eine zuvor bereitgestellte Imageversion an Ort und Stelle geändert wird, können Bereitstellungen mit der gleichen Version vor und nach der Änderung unterschiedliche Ergebnisse liefern.
Wenn Sie die Containerregistrierungsinstanz vor dem Löschen schützen möchten, verwenden Sie Ressourcensperren.
Markierte Bilder
Tagged Container Registry images are defaultable, which means that the same tag can be used on multiple images pushed to the registry. In Produktionsszenarien kann dies zu unvorhersehbaren Verhaltensweisen führen, die sich auf die Betriebszeit der Anwendung auswirken könnten.
Identitäts- und Zugriffsverwaltung
Verwenden Sie die integrierte Microsoft Entra-Authentifizierung zum Pushen und Pullen von Images, anstatt mit Zugriffsschlüsseln zu arbeiten. Um die Sicherheit zu erhöhen, deaktivieren Sie die Verwendung des Administratorzugriffsschlüssels vollständig.
Serverloses Computing
Serverloses Computing bietet Ressourcen bei Bedarf und beseitigt die Notwendigkeit der Infrastrukturverwaltung. Der Cloudanbieter stellt automatisch bereit, skaliert und verwaltet die Ressourcen, die zum Ausführen des bereitgestellten Anwendungscodes erforderlich sind. Azure bietet mehrere serverlose Computeplattformen:
Azure Functions. Wenn Sie Azure Functions verwenden, wird anwendungslogik als unterschiedliche Codeblöcke oder Funktionen implementiert, die als Reaktion auf Ereignisse ausgeführt werden, z. B. eine HTTP-Anforderung oder Warteschlangennachricht. Jede Funktion wird nach Bedarf skaliert, um den Bedarf zu erfüllen.
Azur Logic Apps. Logik-Apps eignen sich am besten zum Erstellen und Ausführen automatisierter Workflows, die verschiedene Apps, Datenquellen, Dienste und Systeme integrieren. Wie Azure-Funktionen verwendet Logic Apps integrierte Trigger für die ereignisgesteuerte Verarbeitung. Anstatt jedoch Anwendungscode bereitzustellen, können Sie Logik-Apps mithilfe einer grafischen Benutzeroberfläche erstellen, die Codeblöcke wie Bedingte und Schleifen unterstützt.
Azure API Management: Sie können die API-Verwaltung verwenden, um erweiterte Sicherheits-APIs mithilfe der Nutzungsebene zu veröffentlichen, zu transformieren, zu verwalten und zu überwachen.
Power Apps und Power Automate. Diese Tools bieten eine Low-Code- oder No-Code-Entwicklungsumgebung mit einfacher Workflowlogik und Integrationen, die über Verbindungen in einer Benutzeroberfläche konfigurierbar sind.
Für unternehmenskritische Anwendungen bieten serverlose Technologien vereinfachte Entwicklungs- und Betriebsabläufe, die für einfache Geschäftsanwendungsfälle nützlich sein können. Diese Einfachheit kommt jedoch zu den Kosten der Flexibilität in Bezug auf Skalierbarkeit, Zuverlässigkeit und Leistung, und das ist für die meisten unternehmenskritischen Anwendungsszenarien nicht praktikabel.
Die folgenden Abschnitte enthalten Entwurfsüberlegungen und Empfehlungen für die Verwendung von Azure Functions und Logic Apps als alternative Plattformen für nicht kritische Workflowszenarien.
Designüberlegungen und Empfehlungen für Azure-Funktionen
Unternehmenskritische Workloads weisen kritische und nicht kritische Systemflüsse auf. Azure Functions ist eine praktikable Wahl für Flüsse, die nicht über die gleichen strengen Geschäftsanforderungen verfügen wie kritische Systemflüsse. Es eignet sich gut für ereignisgesteuerte Flüsse mit kurzlebigen Prozessen, da Funktionen unterschiedliche Vorgänge ausführen, die so schnell wie möglich ausgeführt werden.
Wählen Sie eine Azure Functions-Hostingoption aus, die für die Zuverlässigkeitsstufe der Anwendung geeignet ist. Wir empfehlen den Premium-Plan, da Sie die Berechnungsinstanzgröße konfigurieren können. Der dedizierte Plan ist die am wenigsten serverlose Option. Sie stellt die automatische Skalierung bereit, aber diese Skalierungsvorgänge sind langsamer als die der anderen Pläne. Es wird empfohlen, den Premium-Plan zu verwenden, um Zuverlässigkeit und Leistung zu maximieren.
Es gibt einige Sicherheitsaspekte. Wenn Sie einen HTTP-Trigger verwenden, um einen externen Endpunkt verfügbar zu machen, verwenden Sie eine Webanwendungsfirewall (WAF), um eine Schutzebene für den HTTP-Endpunkt vor allgemeinen externen Angriffsvektoren bereitzustellen.
Wir empfehlen die Verwendung privater Endpunkte zum Einschränken des Zugriffs auf private virtuelle Netzwerke. Sie können auch Datenexfiltrationsrisiken wie böswillige Administratorszenarien mindern.
Sie müssen Codescantools im Azure Functions-Code verwenden und diese Tools in CI/CD-Pipelines integrieren.
Designüberlegungen und Empfehlungen für Azure Logic Apps
Wie Azure-Funktionen verwendet Logic Apps integrierte Trigger für die ereignisgesteuerte Verarbeitung. Anstatt jedoch Anwendungscode bereitzustellen, können Sie Logik-Apps mithilfe einer grafischen Benutzeroberfläche erstellen, die Blöcke wie Bedingte, Schleifen und andere Konstrukte unterstützt.
Es stehen mehrere Bereitstellungsmodi zur Verfügung. Wir empfehlen den Standardmodus, um eine Bereitstellung mit einem einzelnen Mandanten sicherzustellen und laute Nachbarszenarien zu mindern. Dieser Modus verwendet die containerisierte Speicherlogik-Apps-Laufzeit, die auf Azure-Funktionen basiert. In diesem Modus kann die Logik-App mehrere zustands- und zustandslose Workflows aufweisen. Beachten Sie die Konfigurationsgrenzwerte.
Eingeschränkte Migrationen über IaaS
Viele Anwendungen mit vorhandenen lokalen Bereitstellungen verwenden Virtualisierungstechnologien und redundante Hardware, um unternehmenskritische Zuverlässigkeitsstufen bereitzustellen. Die Modernisierung wird häufig durch Geschäftseinschränkungen behindert, die eine vollständige Ausrichtung mit dem Cloud-nativen Basisplanmuster (North Star) verhindern, das für unternehmenskritische Workloads empfohlen wird. Aus diesem Grund setzen viele Anwendungen einen phasenweisen Ansatz ein, wobei erste Cloudbereitstellungen virtualisierungs- und Azure Virtual Machines als primäres Anwendungshostingmodell verwendet werden. Die Verwendung von Infrastruktur-as-a-Service-VMs (IaaS) kann in bestimmten Szenarien erforderlich sein:
- Verfügbare PaaS-Dienste bieten nicht die erforderliche Leistung oder Steuerungsebene.
- Die Workload erfordert Den Zugriff auf das Betriebssystem, bestimmte Treiber oder Netzwerk- und Systemkonfigurationen.
- Die Workload unterstützt die Ausführung in Containern nicht.
- Es gibt keine Anbieterunterstützung für Workloads von Drittanbietern.
Dieser Abschnitt konzentriert sich auf die besten Möglichkeiten, virtuelle Computer und zugehörige Dienste zu verwenden, um die Zuverlässigkeit der Anwendungsplattform zu maximieren. Es hebt wichtige Aspekte der unternehmenskritischen Designmethodik hervor, die Cloud-native und IaaS-Migrationsszenarien transponieren.
Überlegungen zum Entwurf
Die Betriebskosten bei der Verwendung von IaaS-VMs sind deutlich höher als die Kosten für die Nutzung von PaaS-Diensten aufgrund der Verwaltungsanforderungen der VMs und der Betriebssysteme. Die Verwaltung von VMs erfordert das häufige Rollout von Softwarepaketen und -updates.
Azure bietet Funktionen, um die Verfügbarkeit von virtuellen Computern zu erhöhen:
- Verfügbarkeitszonen können Ihnen helfen, noch höhere Zuverlässigkeitsstufen zu erreichen, indem sie virtuelle Computer über physisch getrennte Rechenzentren innerhalb einer Region verteilen.
- Skalierungssätze für virtuelle Azure-Computer bieten Funktionen zum automatischen Skalieren der Anzahl von virtuellen Computern in einer Gruppe. Sie bieten auch Funktionen zum Überwachen des Instanzstatus und zum automatischen Reparieren von fehlerhaften Instanzen.
- Skalierungssätze mit flexibler Orchestrierung können zum Schutz vor Netzwerk-, Datenträger- und Stromausfällen beitragen, indem virtuelle Computer automatisch über Fehlerdomänen verteilt werden.
Entwurfsempfehlungen
Wichtig
Verwenden Sie PaaS-Dienste und -Container, wenn möglich, um die Betriebskomplexität und die Kosten zu reduzieren. Verwenden Sie IaaS-VMs nur, wenn Sie dies benötigen.
SKU-Größen für virtuelle Computer mit der richtigen Größe, um eine effektive Ressourcenauslastung sicherzustellen.
Stellen Sie drei oder mehr virtuelle Computer über Verfügbarkeitszonen bereit, um fehlertoleranz auf Rechenzentrumsebene zu erzielen.
- Wenn Sie kommerzielle Off-the-Shelf-Software bereitstellen, wenden Sie sich an den Softwareanbieter, und testen Sie sie angemessen, bevor Sie die Software in der Produktion bereitstellen.
Verwenden Sie für Workloads, die Sie nicht über Verfügbarkeitszonen hinweg bereitstellen können, flexible Vm-Skalierungsgruppen , die drei oder mehr VMs enthalten. Weitere Informationen zum Konfigurieren der richtigen Anzahl von Fehlerdomänen finden Sie unter Verwalten von Fehlerdomänen in Skalierungssätzen.
Priorisieren Sie die Verwendung von Skalierungssätzen für virtuelle Computer für Skalierbarkeit und Zonenredundanz. Dieser Punkt ist besonders wichtig für Workloads, die unterschiedliche Lasten aufweisen. Wenn beispielsweise die Anzahl der aktiven Benutzer oder Anforderungen pro Sekunde eine unterschiedliche Last ist.
Greifen Sie nicht direkt auf einzelne virtuelle Computer zu. Verwenden Sie nach Möglichkeit Lastenausgleichsgeräte vor ihnen.
Um vor regionalen Ausfällen zu schützen, stellen Sie Anwendungs-VMs in mehreren Azure-Regionen bereit.
- Ausführliche Informationen zum optimalen Weiterleiten des Datenverkehrs zwischen aktiven Bereitstellungsregionen finden Sie im Entwurfsbereich "Netzwerk und Konnektivität".
Für Arbeitslasten, die keine aktiven/aktiven Bereitstellungen mit mehreren Regionen unterstützen, sollten Sie aktive/passive Bereitstellungen mithilfe von Hot/Warm Standby-VMs für regionales Failover implementieren.
Verwenden Sie Standardimages von Azure Marketplace anstelle von benutzerdefinierten Images, die verwaltet werden müssen.
Implementieren Sie automatisierte Prozesse zum Bereitstellen und Bereitstellen von Änderungen an virtuellen Computern, um manuelle Eingriffe zu vermeiden. Weitere Informationen finden Sie unter IaaS-Überlegungen im Entwurfsbereich " Operational procedures ".
Implementieren Sie Chaosexperimente, um Anwendungsfehler in VM-Komponenten einzufügen und die Risikominderung von Fehlern zu beobachten. Weitere Informationen finden Sie unter Fortlaufende Überprüfung und Tests.
Überwachen Sie virtuelle Computer, und stellen Sie sicher, dass Diagnoseprotokolle und Metriken in eine einheitliche Datensenke aufgenommen werden.
Implementieren Sie Sicherheitspraktiken für unternehmenskritische Anwendungsszenarien, falls zutreffend, und die bewährten Methoden für IaaS-Workloads in Azure.
Nächster Schritt
Überprüfen Sie die Überlegungen für die Datenplattform.