Einrichten der Zugriffssteuerung für synchronisierte Objekte in einem serverlosen SQL-Pool
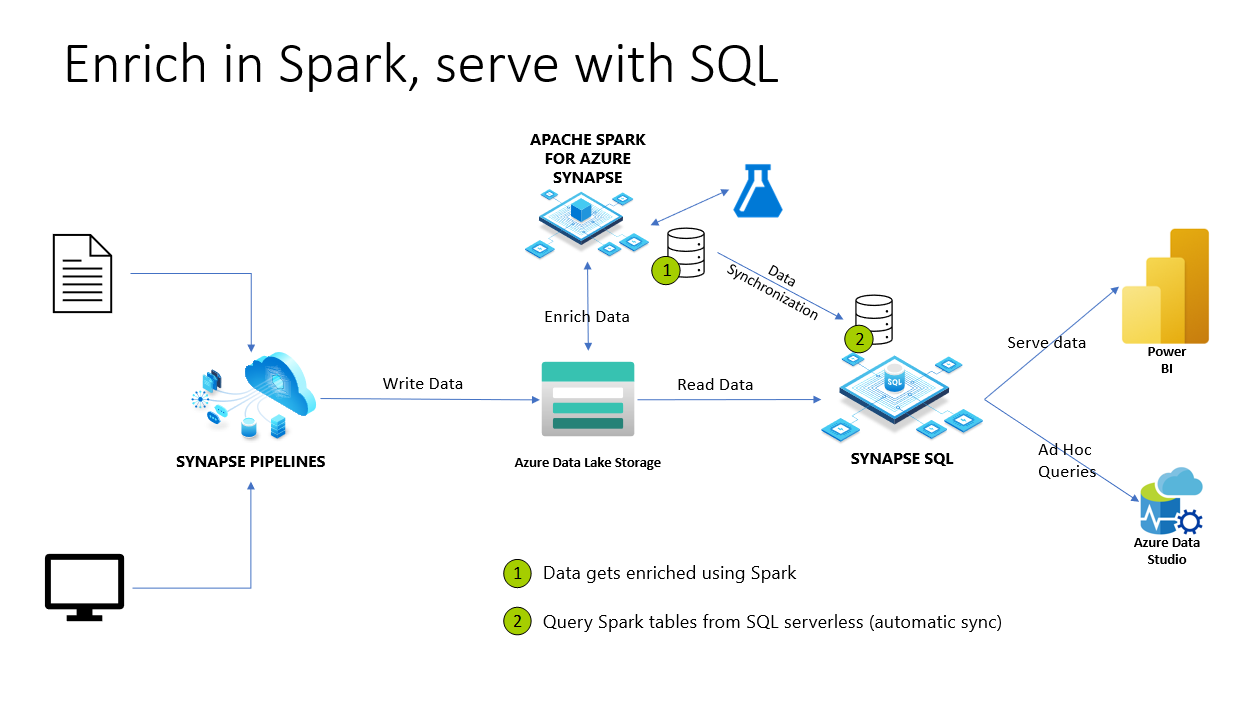
In Azure Synapse Analytics werden Spark-Datenbanken und -Tabellen für einen serverlosen SQL-Pool freigegeben. Lake-Datenbanken sowie Tabellen im Parquet- und CSV-Format, die mit Spark erstellt wurden, sind automatisch in einem serverlosen SQL-Pool verfügbar. Dieses Feature ermöglicht die Verwendung eines serverlosen SQL-Pools zum Untersuchen und Abfragen von Daten, die mithilfe von Spark-Pools vorbereitet wurden. Im folgenden Diagramm sehen Sie eine allgemeine Übersicht über die Architektur zur Nutzung dieses Features. Als Erstes verschieben Azure Synapse-Pipelines Daten aus lokalem (oder anderem) Speicher in Azure Data Lake Storage. Jetzt kann Spark die Daten anreichern und Datenbanken und Tabellen erstellen, die mit einer serverlosen Synapse SQL-Instanz synchronisiert werden. Später kann der Benutzer Ad-hoc-Abfragen auf der Grundlage der angereicherten Daten ausführen oder sie beispielsweise für Power BI bereitstellen.
Vollständiger Administratorzugriff (sysadmin)
Nachdem die Datenbanken und Tabellen aus Spark mit dem serverlosen SQL-Pool synchronisiert wurden, ist es möglich, über diese externen Tabellen im serverlosen SQL-Pool auf dieselben Daten zuzugreifen. Objekte im serverlosen SQL-Pool sind jedoch schreibgeschützt, um die Konsistenz mit den Objekten in Spark-Pools zu gewährleisten. Durch diese Einschränkung können nur Benutzer mit den Rollen „Synapse SQL-Administrator“ oder „Synapse-Administrator“ auf diese Objekte im serverlosen SQL-Pool zugreifen. Wenn Benutzer ohne Administratorrechte versuchen, eine Abfrage für die synchronisierte Datenbank/Tabelle auszuführen, erhalten sie in etwa folgende Fehlermeldung: External table '<table>' is not accessible because content of directory cannot be listed.. Dies geschieht, obwohl sie Zugriff auf Daten in den zugrunde liegenden Speicherkonten besitzen.
Da synchronisierte Datenbanken im serverlosen SQL-Pool schreibgeschützt sind, können sie nicht geändert werden. Ein Versuch zum Erstellen eines Benutzers oder zum Erteilen anderer Berechtigungen führt zu einem Fehler. Um synchronisierte Datenbanken zu lesen, müssen Sie über privilegierte Berechtigungen auf Serverebene verfügen (z. B. sysadmin). Diese Einschränkung gilt auch für externe Tabellen in serverlosen SQL-Pools, wenn Azure Synapse Link für Dataverse- und Lake-Datenbanktabellen verwendet werden.
Nicht-Administratorzugriff auf synchronisierte Datenbanken
Ein Benutzer, der Daten lesen und Berichte erstellen muss, verfügt in der Regel nicht über vollständigen Administratorzugriff (sysadmin). Dieser Benutzer ist in der Regel Datenanalyst und muss Daten anhand der vorhandenen Tabellen nur lesen und analysieren. Er muss keine neuen Objekte erstellen.
Ein Benutzer mit minimaler Berechtigung sollte folgende Aufgaben ausführen können:
- Herstellen einer Verbindung mit einer Datenbank, die aus Spark repliziert wird
- Auswählen von Daten über externe Tabellen und Zugreifen auf die zugrunde liegenden ADLS-Daten
Nach dem Ausführen des folgenden Codeskripts erhalten Benutzer ohne Administratorrechte Berechtigungen auf Serverebene, um eine Verbindung mit einer beliebigen Datenbank herzustellen. Außerdem können Benutzer Daten aus allen Objekten auf Schemaebene wie z. B. Tabellen oder Sichten anzeigen. Die Sicherheit des Datenzugriffs kann auf Speicherebene verwaltet werden.
-- Creating Azure AD login (same can be achieved for Azure AD app)
CREATE LOGIN [login@contoso.com] FROM EXTERNAL PROVIDER;
go;
GRANT CONNECT ANY DATABASE to [login@contoso.com];
GRANT SELECT ALL USER SECURABLES to [login@contoso.com];
GO;
Hinweis
Diese Anweisungen sollten in der Masterdatenbank ausgeführt werden, da dies alle Berechtigungen auf Serverebene sind.
Nach dem Erstellen eines Anmeldenamens und dem Erteilen von Berechtigungen können Benutzer Abfragen auf der Grundlage der synchronisierten externen Tabellen ausführen. Diese Entschärfung kann auch auf Microsoft Entra-Sicherheitsgruppen angewendet werden.
Mehr Sicherheit für die Objekte kann über bestimmte Schemas und durch die Beschränkung des Zugriffs auf ein bestimmtes Schema verwaltet werden. Zur Problemumgehung ist eine zusätzliche DDL erforderlich. In diesem Szenario können Sie neue serverlose Datenbanken, Schemas und Sichten erstellen, die auf die Spark-Tabellendaten in ADLS verweisen.
Der Zugriff auf die Daten im Speicherkonto kann über die Zugriffssteuerungsliste oder über reguläre Rollen für Storage-Blobdatenbesitzer/-leser und Mitwirkende für Microsoft Entra-Benutzer*innen und -Gruppen verwaltet werden. Stellen Sie für Dienstprinzipale (Microsoft Entra-Apps) sicher, dass Sie die ACL-Einrichtung verwenden.
Hinweis
- Wenn Sie die Verwendung von OPENROWSET auf Basis der Daten verbieten möchten, können Sie
DENY ADMINISTER BULK OPERATIONS to [login@contoso.com];verwenden. Weitere Informationen finden Sie unter DENY-Serverberechtigungen. - Wenn Sie die Verwendung bestimmter Schemas untersagen möchten, können Sie
DENY SELECT ON SCHEMA::[schema_name] TO [login@contoso.com];verwenden. Weitere Informationen finden Sie unter DENY-Schemaberechtigungen.
Nächste Schritte
Weitere Informationen finden Sie unter SQL-Authentifizierung.