Leistungsoptimierung mit materialisierten Sichten mithilfe des dedizierten SQL-Pools in Azure Synapse Analytics
Im dedizierten SQL-Pool bieten materialisierte Sichten eine Methode mit geringer Wartung für komplexe analytische Abfragen, um eine schnelle Leistung ohne Abfrageänderung zu erzielen. Dieser Artikel erläutert den allgemeinen Leitfaden zur Verwendung materialisierter Sichten.
Materialisierte Sichten im Vergleich zu Standardsichten
Der SQL-Pool unterstützt sowohl Standardsichten als auch materialisierte Sichten. Beides sind virtuelle Tabellen, die mit SELECT-Ausdrücken erstellt und Abfragen als logische Tabellen präsentiert werden. Sichten zeigen die Komplexität von allgemeiner Datenberechnung und fügen eine Abstraktionsebene zur Berechnung von Änderungen hinzu, sodass Abfragen nicht erneut generiert werden müssen.
Eine Standardsicht berechnet die zugehörigen Daten jedes Mal, wenn sie verwendet wird. Auf dem Datenträger sind keine Daten gespeichert. Normalerweise verwenden Benutzer Standardsichten als Tool, das sie beim Organisieren logischer Objekte und Abfragen in einer Datenbank unterstützt. Um eine Standardsicht verwenden zu können, muss eine Abfrage direkt darauf verweisen.
Eine materialisierte Sicht berechnet vorab, speichert und verwaltet die zugehörigen Daten im dedizierten SQL-Pool genauso wie eine Tabelle. Die Neuberechnung ist nicht jedes Mal erforderlich, wenn eine materialisierte Sicht verwendet wird. Deshalb können Abfragen, die alle Daten oder eine Teilmenge davon in materialisierten Sichten verwenden, eine schnellere Leistung erzielen. Noch besser: Weil Abfragen eine materialisierte Sicht verwenden können, ohne direkt darauf zu verweisen, muss der Anwendungscode nicht geändert werden.
Die meisten Anforderungen an eine Standardsicht gelten weiterhin für eine materialisierte Sicht. Ausführliche Informationen zur Syntax für materialisierte Sichten und andere Anforderungen finden Sie unter CREATE MATERIALIZED VIEW AS SELECT.
| Vergleich | Sicht | Materialisierte Sicht |
|---|---|---|
| Anzeigen der Definition | In Azure Data Warehouse gespeichert. | In Azure Data Warehouse gespeichert. |
| Inhalt der Sicht | Wird bei jeder Verwendung der Sicht generiert. | Wird während der Sichterstellung vorab verarbeitet und in Azure Data Warehouse gespeichert. Wird aktualisiert, wenn den zugrunde liegenden Tabellen Daten hinzugefügt werden. |
| Datenaktualisierung | Werden immer aktualisiert. | Werden immer aktualisiert. |
| Geschwindigkeit zum Abrufen von Sichtdaten aus komplexen Abfragen | Langsam | Schnell |
| Zusätzlicher Speicher | Nein | Ja |
| Syntax | CREATE VIEW | CREATE MATERIALIZED VIEW AS SELECT |
Vorteile von materialisierten Sichten
Eine ordnungsgemäß entworfene materialisierte Sicht bietet folgende Vorteile:
Verkürzte Ausführungszeit für komplexe Abfragen mit JOINs und Aggregatfunktionen. Je komplexer die Abfrage ist, desto höher ist das Potenzial für Einsparungen bei der Ausführungszeit. Der größte Vorteil wird erzielt, wenn die Berechnungskosten für eine Abfrage hoch sind und das sich ergebende Dataset klein ist.
Der Abfrageoptimierer im dedizierten SQL-Pool kann bereitgestellte materialisierte Sichten automatisch verwenden, um Abfrageausführungspläne zu verbessern. Dieser Prozess ist für Benutzer transparent, die eine schnellere Abfrageleistung bereitstellen, und es ist nicht erforderlich, dass Abfragen einen direkten Verweis auf die materialisierten Sichten erstellen.
Geringe Wartung für die Sichten erforderlich. Eine materialisierte Sicht speichert Daten an zwei Stellen: in einem gruppierten Columnstore-Index für die Anfangsdaten zum Zeitpunkt der Sichterstellung und in einem Deltaspeicher für die inkrementellen Datenänderungen. Alle Datenänderungen aus den Basistabellen werden dem Deltaspeicher automatisch synchron hinzugefügt. Ein Hintergrundprozess (Tupelverschiebungsvorgang) verschiebt die Daten in regelmäßigen Abständen aus dem Deltaspeicher in den Columnstore-Index der Sicht. Dieser Entwurf ermöglicht das Abfragen materialisierter Sichten, damit dieselben Daten wie beim direkten Abfragen der Basistabellen zurückgegeben werden.
Die Daten in einer materialisierten Sicht können aus den Basistabellen unterschiedlich verteilt werden.
Daten in materialisierten Sichten erhalten dieselben Vorteile an hoher Verfügbarkeit und Resilienz wie Daten in regulären Tabellen.
Im Vergleich zu anderen Data Warehouse-Anbietern bieten die im dedizierten SQL-Pool implementierten materialisierten Sichten die folgenden zusätzlichen Vorteile:
- Automatische und synchrone Datenaktualisierung bei Datenänderungen in Basistabellen. Es ist keine Benutzeraktion erforderlich.
- Umfassende Unterstützung von Aggregatfunktionen. Lesen Sie dazu CREATE MATERIALIZED VIEW AS SELECT (Transact-SQL).
- Die Unterstützung für abfragespezifische Empfehlungen von materialisierten Sichten. Lesen Sie dazu EXPLAIN (Transact-SQL).
Häufige Szenarios
Materialisierte Sichten werden normalerweise in folgenden Szenarios verwendet:
Die Leistung von komplexen analytischen Abfragen für große Datenmengen muss verbessert werden
Komplexe analytische Abfragen verwenden normalerweise mehr Aggregationsfunktionen und Tabellenverknüpfungen, was zu rechenintensiveren Vorgängen führt, z.B. Zufallswiedergaben und Verknüpfungen bei der Abfrageausführung. Deshalb dauert die Ausführung dieser Abfragen länger, besonders bei großen Tabellen.
Benutzer können materialisierte Sichten für die Daten erstellen, die aus den allgemeinen Berechnungen von Abfragen zurückgegeben werden, sodass keine Neuberechnung erforderlich ist, wenn diese Daten von Abfragen benötigt werden. Das ermöglicht niedrigere Computekosten und schnellere Abfrageantworten.
Eine schnellere Leistung ohne oder mit minimalen Abfrageänderungen ist erforderlich
Schema- und Abfrageänderungen in Data Warehouse-Instanzen werden normalerweise auf ein Minimum beschränkt, um reguläre ETL-Vorgänge und -Berichte zu unterstützen. Benutzer können materialisierte Sichten zur Optimierung der Abfrageleistung verwenden, wenn die durch die Sichten anfallenden Kosten durch den Gewinn bei der Abfrageleistung ausgeglichen werden können.
Im Vergleich zu anderen Optimierungsoptionen, z. B. Skalierung und Statistikverwaltung, ist dies eine Produktionsänderung mit viel geringeren Auswirkungen zur Erstellung und Wartung einer materialisierten Sicht, und der potenzielle Leistungsgewinn ist außerdem höher.
- Das Erstellen oder Warten von materialisierten Sichten hat keine Auswirkung auf die Abfragen, die für die Basistabellen ausgeführt werden.
- Der Abfrageoptimierer kann die bereitgestellten materialisierten Sichten ohne direkten Sichtverweis in einer Abfrage automatisch verwenden. Diese Funktion reduziert den Bedarf an Abfrageänderungen bei der Leistungsoptimierung.
Eine andere Datenverteilungsstrategie für eine schnellere Abfrageleistung ist erforderlich
Azure Data Warehouse ist ein verteiltes System mit paralleler Massenverarbeitung (Massively Parallel Processing, MPP).
Synapse SQL ist ein verteiltes Abfragesystem, das es Unternehmen ermöglicht, Data Warehousing- und Datenvirtualisierungsszenarien mithilfe standardmäßiger T-SQL-Umgebungen zu implementieren, mit denen Dateningenieure vertraut sind. Darüber hinaus erweitert es die Funktionen von SQL für Streaming- und Machine Learning-Szenarien. Daten in einer Data Warehouse-Tabelle werden mit einer von drei Verteilungsstrategien (hash, round_robin oder replicated) über 60 Knoten verteilt.
Die Datenverteilung wird zum Zeitpunkt der Tabellenerstellung angegeben und bleibt so lange unverändert, bis die Tabelle gelöscht wird. Da die materialisierte Sicht eine virtuelle Tabelle auf Datenträger ist, unterstützt sie die Datenverteilungen hash und round_robin. Benutzer können eine Datenverteilung wählen, die sich von den Basistabellen unterscheidet, aber optimal für die Leistung von Abfragen ist, die die Sichten regelmäßig verwenden.
Entwurfsleitfäden
Hier ist ein allgemeiner Leitfaden zur Verwendung von materialisierten Sichten, um die Abfrageleistung zu verbessern:
Entwurf für Ihren Workload
Bevor Sie mit dem Erstellen von materialisierten Sichten beginnen, ist es wichtig, dass Sie sich mit Ihrem Workload in Bezug auf Abfragemuster, Wichtigkeit, Häufigkeit und Größe der sich ergebenden Daten umfassend vertraut machen.
Benutzer*innen können EXPLAIN WITH_RECOMMENDATIONS <SQL-Anweisung> für die vom Abfrageoptimierer empfohlenen materialisierten Sichten ausführen. Da es sich hierbei um abfragespezifische Empfehlungen handelt, ist eine materialisierte Sicht, die eine einzelne Abfrage bietet, für andere Abfragen in demselben Workload möglicherweise nicht optimal geeignet.
Werten Sie diese Empfehlungen unter Berücksichtigung Ihrer Workloadanforderungen aus. Die idealen materialisierten Sichten sind solche, die die Leistung des Workloads nutzen.
Beachten Sie den Kompromiss zwischen schnelleren Abfragen und den Kosten
Bei jeder materialisierten Sicht gibt es Kosten für den Datenspeicher und Kosten für die Wartung der Sicht. Bei Datenänderungen in den Basistabellen nimmt die Größe der materialisierten Sicht zu, und die physische Struktur ändert sich ebenfalls.
Um eine Leistungsminderung bei der Abfrage zu vermeiden, wird jede materialisierte Sicht von der Data Warehouse-Engine separat gewartet, einschließlich dem Verschieben von Zeilen aus dem Deltaspeicher in die Columnstore-Indexsegmente und dem Konsolidieren von Datenänderungen.
Die Wartungsworkload steigt, wenn die Anzahl von materialisierten Sichten und Änderungen an der Basistabelle zunimmt. Benutzer sollten überprüfen, ob die aus allen materialisierten Sichten anfallenden Kosten durch den Abfrageleistungsgewinn ausgeglichen werden können.
Sie können diese Abfrage für die Liste von materialisierten Sichten in einer Datenbank ausführen:
SELECT V.name as materialized_view, V.object_id
FROM sys.views V
JOIN sys.indexes I ON V.object_id= I.object_id AND I.index_id < 2;
Optionen zum Verringern der Anzahl von materialisierten Sichten:
Identifizieren Sie allgemeine Datasets, die von den komplexen Abfragen in Ihrem Workload häufig verwendet werden. Erstellen Sie materialisierte Sichten zum Speichern dieser Datasets, damit der Optimierer sie als Bausteine beim Erstellen von Ausführungsplänen verwenden kann.
Löschen Sie die materialisierten Sichten, die wenig genutzt oder nicht mehr benötigt werden. Eine deaktivierte materialisierte Sicht wird nicht gewartet, doch es fallen dafür weiterhin Speicherkosten an.
Kombinieren Sie materialisierte Sichten, die in derselben Basistabelle oder ähnlichen Basistabellen erstellt wurden – auch wenn deren Daten sich nicht überschneiden. Eine Kombination materialisierter Sichten könnte zu einer größeren Sicht als die Summe der separaten Sichten führen. Allerdings sollten die Kosten für die Sichtwartung reduziert werden. Beispiel:
-- Query 1 would benefit from having a materialized view created with this SELECT statement
SELECT A, SUM(B)
FROM T
GROUP BY A
-- Query 2 would benefit from having a materialized view created with this SELECT statement
SELECT C, SUM(D)
FROM T
GROUP BY C
-- You could create a single materialized view of this form
SELECT A, C, SUM(B), SUM(D)
FROM T
GROUP BY A, C
Nicht die gesamte Leistungsoptimierung erfordert Abfrageänderungen
Der Data Warehouse-Optimierer kann bereitgestellte materialisierte Sichten automatisch zur Verbesserung der Abfrageleistung verwenden. Diese Unterstützung wird auf Abfragen transparent angewendet, die nicht auf die Sichten und Abfragen verweisen, die bei der Erstellung von materialisierten Sichten nicht unterstützte Aggregate verwenden. Es ist keine Abfrageänderung erforderlich. Sie können den geschätzten Ausführungsplan für eine Abfrage überprüfen, um sich zu vergewissern, dass eine materialisierte Sicht verwendet wird.
- Weitere Informationen zum Abrufen des tatsächlichen Ausführungsplans finden Sie unter Überwachen der Workload Ihres dedizierten SQL-Pools von Azure Synapse Analytics mit DMVs.
- Sie können einen geschätzten Ausführungsplan über SQL Server Management Studio (SSMS) oder SET SHOWPLAN_XML abrufen.
Überwachen von materialisierten Sichten
Eine materialisierte Sicht wird im Data Warehouse wie eine Tabelle mit gruppiertem Columnstore-Index (CCI) gespeichert. Das Lesen von Daten aus einer materialisierten Sicht besteht aus dem Überprüfen des Indexes und Anwenden von Änderungen aus dem Deltaspeicher. Wenn die Anzahl der Zeilen im Deltaspeicher zu hoch ist, kann die Auflösung einer Abfrage aus einer materialisierten Sicht länger dauern als das direkte Abfragen der Basistabellen.
Um eine Leistungsbeeinträchtigung bei der Abfrage zu vermeiden, empfiehlt es sich, DBCC PDW_SHOWMATERIALIZEDVIEWOVERHEAD zur Überwachung von „overhead_ratio (total_rows/base_view_row)“ der Sicht auszuführen. Wenn der Wert für „overhead_ratio“ zu hoch ist, sollten Sie die materialisierte Sicht neu erstellen, damit alle Zeilen im Deltaspeicher in den Columnstore-Index verschoben werden.
Materialisierte Sicht und Zwischenspeichern von Resultsets
Diese beiden Features werden im dedizierten SQL-Pool ungefähr zeitgleich zur Optimierung der Abfrageleistung eingeführt. Das Zwischenspeichern von Resultsets wird verwendet, um hohe Parallelität und schnelle Antwortzeiten aus sich wiederholenden Abfragen für statische Daten zu erzielen.
Um das zwischengespeicherte Ergebnis verwenden zu können, muss die Form des Caches, der die Abfrage anfordert, mit der Abfrage übereinstimmen, die den Cache erzeugt hat. Außerdem muss das zwischengespeicherte Ergebnis für die gesamte Abfrage gelten.
Materialisierte Sichten lassen Datenänderungen in den Basistabellen zu. Daten in materialisierten Sichten können auf einen Teil einer Abfrage angewendet werden. Diese Unterstützung ermöglicht es, dass dieselben materialisierten Sichten von unterschiedlichen Abfragen verwendet werden können, die einige Berechnungen für eine schnellere Leistung gemeinsam nutzen.
Beispiel
In diesem Beispiel wird eine TPCDS-ähnliche Abfrage verwendet, bei der Kunden gefunden werden, die über den Katalog mehr Geld aufwenden als in Geschäften. Außerdem werden die bevorzugten Kunden und deren Ursprungsland/-region ermittelt. Die Abfrage umfasst die Auswahl der TOP 100-Datensätze aus der Vereinigung (UNION) von drei untergeordneten SELECT-Anweisungen mit SUM () und GROUP BY.
WITH year_total AS (
SELECT c_customer_id customer_id
,c_first_name customer_first_name
,c_last_name customer_last_name
,c_preferred_cust_flag customer_preferred_cust_flag
,c_birth_country customer_birth_country
,c_login customer_login
,c_email_address customer_email_address
,d_year dyear
,sum(isnull(ss_ext_list_price-ss_ext_wholesale_cost-ss_ext_discount_amt+ss_ext_sales_price, 0)/2) year_total
,'s' sale_type
FROM customer
,store_sales
,date_dim
WHERE c_customer_sk = ss_customer_sk
AND ss_sold_date_sk = d_date_sk
GROUP BY c_customer_id
,c_first_name
,c_last_name
,c_preferred_cust_flag
,c_birth_country
,c_login
,c_email_address
,d_year
UNION ALL
SELECT c_customer_id customer_id
,c_first_name customer_first_name
,c_last_name customer_last_name
,c_preferred_cust_flag customer_preferred_cust_flag
,c_birth_country customer_birth_country
,c_login customer_login
,c_email_address customer_email_address
,d_year dyear
,sum(isnull(cs_ext_list_price-cs_ext_wholesale_cost-cs_ext_discount_amt+cs_ext_sales_price, 0)/2) year_total
,'c' sale_type
FROM customer
,catalog_sales
,date_dim
WHERE c_customer_sk = cs_bill_customer_sk
AND cs_sold_date_sk = d_date_sk
GROUP BY c_customer_id
,c_first_name
,c_last_name
,c_preferred_cust_flag
,c_birth_country
,c_login
,c_email_address
,d_year
UNION ALL
SELECT c_customer_id customer_id
,c_first_name customer_first_name
,c_last_name customer_last_name
,c_preferred_cust_flag customer_preferred_cust_flag
,c_birth_country customer_birth_country
,c_login customer_login
,c_email_address customer_email_address
,d_year dyear
,sum(isnull(ws_ext_list_price-ws_ext_wholesale_cost-ws_ext_discount_amt+ws_ext_sales_price, 0)/2) year_total
,'w' sale_type
FROM customer
,web_sales
,date_dim
WHERE c_customer_sk = ws_bill_customer_sk
AND ws_sold_date_sk = d_date_sk
GROUP BY c_customer_id
,c_first_name
,c_last_name
,c_preferred_cust_flag
,c_birth_country
,c_login
,c_email_address
,d_year
)
SELECT TOP 100
t_s_secyear.customer_id
,t_s_secyear.customer_first_name
,t_s_secyear.customer_last_name
,t_s_secyear.customer_birth_country
FROM year_total t_s_firstyear
,year_total t_s_secyear
,year_total t_c_firstyear
,year_total t_c_secyear
,year_total t_w_firstyear
,year_total t_w_secyear
WHERE t_s_secyear.customer_id = t_s_firstyear.customer_id
AND t_s_firstyear.customer_id = t_c_secyear.customer_id
AND t_s_firstyear.customer_id = t_c_firstyear.customer_id
AND t_s_firstyear.customer_id = t_w_firstyear.customer_id
AND t_s_firstyear.customer_id = t_w_secyear.customer_id
AND t_s_firstyear.sale_type = 's'
AND t_c_firstyear.sale_type = 'c'
AND t_w_firstyear.sale_type = 'w'
AND t_s_secyear.sale_type = 's'
AND t_c_secyear.sale_type = 'c'
AND t_w_secyear.sale_type = 'w'
AND t_s_firstyear.dyear+0 = 1999
AND t_s_secyear.dyear+0 = 1999+1
AND t_c_firstyear.dyear+0 = 1999
AND t_c_secyear.dyear+0 = 1999+1
AND t_w_firstyear.dyear+0 = 1999
AND t_w_secyear.dyear+0 = 1999+1
AND t_s_firstyear.year_total > 0
AND t_c_firstyear.year_total > 0
AND t_w_firstyear.year_total > 0
AND CASE WHEN t_c_firstyear.year_total > 0 THEN t_c_secyear.year_total / t_c_firstyear.year_total ELSE NULL END
> CASE WHEN t_s_firstyear.year_total > 0 THEN t_s_secyear.year_total / t_s_firstyear.year_total ELSE NULL END
AND CASE WHEN t_c_firstyear.year_total > 0 THEN t_c_secyear.year_total / t_c_firstyear.year_total ELSE NULL END
> CASE WHEN t_w_firstyear.year_total > 0 THEN t_w_secyear.year_total / t_w_firstyear.year_total ELSE NULL END
ORDER BY t_s_secyear.customer_id
,t_s_secyear.customer_first_name
,t_s_secyear.customer_last_name
,t_s_secyear.customer_birth_country
OPTION ( LABEL = 'Query04-af359846-253-3');
Überprüfen Sie den geschätzten Ausführungsplan der Abfrage. Es gibt 18 Zufallswiedergaben und 17 Verknüpfungsvorgänge, deren Ausführung mehr Zeit in Anspruch nimmt.
Lassen Sie uns nun eine materialisierte Sicht für jede der drei untergeordneten SELECT-Anweisungen erstellen.
CREATE materialized view nbViewSS WITH (DISTRIBUTION=HASH(customer_id)) AS
SELECT c_customer_id customer_id
,c_first_name customer_first_name
,c_last_name customer_last_name
,c_preferred_cust_flag customer_preferred_cust_flag
,c_birth_country customer_birth_country
,c_login customer_login
,c_email_address customer_email_address
,d_year dyear
,sum(isnull(ss_ext_list_price-ss_ext_wholesale_cost-ss_ext_discount_amt+ss_ext_sales_price, 0)/2) year_total
, count_big(*) AS cb
FROM dbo.customer
,dbo.store_sales
,dbo.date_dim
WHERE c_customer_sk = ss_customer_sk
AND ss_sold_date_sk = d_date_sk
GROUP BY c_customer_id
,c_first_name
,c_last_name
,c_preferred_cust_flag
,c_birth_country
,c_login
,c_email_address
,d_year
GO
CREATE materialized view nbViewCS WITH (DISTRIBUTION=HASH(customer_id)) AS
SELECT c_customer_id customer_id
,c_first_name customer_first_name
,c_last_name customer_last_name
,c_preferred_cust_flag customer_preferred_cust_flag
,c_birth_country customer_birth_country
,c_login customer_login
,c_email_address customer_email_address
,d_year dyear
,sum(isnull(cs_ext_list_price-cs_ext_wholesale_cost-cs_ext_discount_amt+cs_ext_sales_price, 0)/2) year_total
, count_big(*) as cb
FROM dbo.customer
,dbo.catalog_sales
,dbo.date_dim
WHERE c_customer_sk = cs_bill_customer_sk
AND cs_sold_date_sk = d_date_sk
GROUP BY c_customer_id
,c_first_name
,c_last_name
,c_preferred_cust_flag
,c_birth_country
,c_login
,c_email_address
,d_year
GO
CREATE materialized view nbViewWS WITH (DISTRIBUTION=HASH(customer_id)) AS
SELECT c_customer_id customer_id
,c_first_name customer_first_name
,c_last_name customer_last_name
,c_preferred_cust_flag customer_preferred_cust_flag
,c_birth_country customer_birth_country
,c_login customer_login
,c_email_address customer_email_address
,d_year dyear
,sum(isnull(ws_ext_list_price-ws_ext_wholesale_cost-ws_ext_discount_amt+ws_ext_sales_price, 0)/2) year_total
, count_big(*) AS cb
FROM dbo.customer
,dbo.web_sales
,dbo.date_dim
WHERE c_customer_sk = ws_bill_customer_sk
AND ws_sold_date_sk = d_date_sk
GROUP BY c_customer_id
,c_first_name
,c_last_name
,c_preferred_cust_flag
,c_birth_country
,c_login
,c_email_address
,d_year
Überprüfen Sie erneut den Ausführungsplan der ursprünglichen Abfrage. Nun wird die Anzahl der Verknüpfungen von 17 in 5 geändert, und es gibt keine Zufallswiedergabe mehr. Wählen Sie das Symbol für den Filtervorgang im Plan aus. In der Ausgabeliste wird angezeigt, dass die Daten aus den materialisierten Sichten anstatt aus Basistabellen gelesen werden.
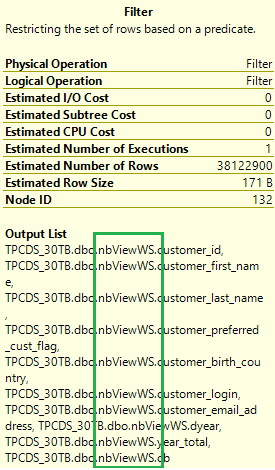
Bei materialisierten Sichten wird dieselbe Abfrage viel schneller ausgeführt, ohne dass Code geändert werden muss.
Nächste Schritte
Weitere Tipps zur Entwicklung finden Sie in der Entwicklungsübersicht für Synapse SQL.