Anleitung für das Verwenden replizierter Tabellen im Synapse SQL-Pool
Dieser Artikel enthält Empfehlungen für das Entwerfen replizierter Tabellen in Ihrem Synapse SQL-Poolschema. Nutzen Sie diese Empfehlungen, um die Abfrageleistung zu verbessern, indem Sie die Datenverschiebung und die Komplexität von Abfragen reduzieren.
Voraussetzungen
In diesem Artikel wird davon ausgegangen, dass Sie mit den Konzepten der Datenverteilung und -verschiebung im SQL-Pool vertraut sind. Weitere Informationen finden Sie im Artikel zur Architektur.
Für den Tabellenentwurf sollten Sie möglichst umfassende Kenntnisse zu Ihren Daten und über das Abfragen der Daten besitzen. Stellen Sie sich beispielsweise die folgenden Fragen:
- Wie groß ist die Tabelle?
- Wie oft wird die Tabelle aktualisiert?
- Gibt es in einem SQL-Pool Fakten- und Dimensionstabellen?
Was ist eine replizierte Tabelle?
Eine replizierte Tabelle verfügt über eine vollständige Kopie der Tabelle, auf die auf jedem Computeknoten zugegriffen werden kann. Durch das Replizieren einer Tabelle müssen Daten vor einem Join oder einer Aggregation nicht mehr auf Computeknoten übertragen werden. Da die Tabelle über mehrere Kopien verfügt, lässt sich mit replizierten Tabellen am besten arbeiten, wenn die komprimierte Tabelle kleiner als 2 GB ist. 2 GB ist keine harte Grenze. Wenn die Daten statisch sind und nicht geändert werden, können Sie größere Tabellen replizieren.
Im folgenden Diagramm wird eine replizierte Tabelle dargestellt, auf die auf jedem Computeknoten zugegriffen werden kann. In einem SQL-Pool wird die replizierte Tabelle auf jedem Serverknoten vollständig in eine Verteilungsdatenbank kopiert.

Replizierte Tabellen eignen sich gut für Dimensionstabellen in einem Sternschema. Dimensionstabellen werden in der Regel mit Faktentabellen verknüpft, die anders verteilt sind als die Dimensionstabelle. Dimensionen haben normalerweise eine Größe, die das Speichern und Verwalten mehrerer Kopien ermöglicht. In Dimensionen werden beschreibende Daten gespeichert, die sich selten ändern, z.B. Kundenname und -adresse sowie Produktdetails. Da sich die Daten nicht häufig ändern, muss die replizierte Tabelle seltener verwaltet werden.
Die Verwendung einer replizierten Tabelle kann sinnvoll sein, wenn folgende Bedingungen zutreffen:
- Die Tabellengröße auf dem Datenträger ist geringer als 2 GB, unabhängig von der Anzahl der Zeilen. Sie können die Größe der Tabelle mit dem DBCC PDW_SHOWSPACEUSED-Befehl ermitteln:
DBCC PDW_SHOWSPACEUSED('ReplTableCandidate'). - Die Tabelle wird in Joins verwendet, die andernfalls Datenverschiebung erfordern. Beim Verknüpfen von Tabellen, die nicht in derselben Spalte verteilt sind, z.B. einer Tabelle mit Hashverteilung mit einer Roundrobintabelle, ist die Datenverschiebung erforderlich, um die Abfrage abzuschließen. Wenn eine der Tabellen klein ist, empfiehlt sich möglicherweise eine replizierte Tabelle. In den meisten Fällen wird empfohlen, replizierte Tabellen statt Roundrobintabellen zu verwenden. Verwenden Sie sys.dm_pdw_request_steps, um Datenverschiebungen in Abfrageplänen anzuzeigen. BroadcastMoveOperation ist der typische Datenverschiebungsvorgang, der mithilfe einer replizierten Tabelle gelöscht werden kann.
Replizierte Tabellen liefern möglicherweise nicht die optimale Abfrageleistung, wenn folgende Bedingungen zutreffen:
- In der Tabelle erfolgen häufig Einfüge-, Aktualisierungs- und Löschvorgänge. Vorgänge der Datenbearbeitungssprache (Data Manipulation Language, DML) erfordern das erneute Erstellen der replizierten Tabelle. Ein häufiges Neuerstellen kann zu Leistungseinbußen führen.
- Der SQL-Pool wird häufig skaliert. Durch das Skalieren eines SQL-Pools wird die Anzahl der Serverknoten geändert. Dies führt zu einer Neuerstellung der replizierten Tabelle.
- Die Tabelle enthält eine große Anzahl von Spalten, die Datenvorgänge greifen jedoch in der Regel nur auf eine kleine Anzahl von Spalten zu. In diesem Szenario ist es möglicherweise effektiver, eine Verteilung der Tabelle und dann einen Index für die Spalten mit häufigem Zugriff zu erstellen, statt die gesamte Tabelle zu replizieren. Wenn eine Abfrage eine Datenverschiebung erfordert, verschiebt der SQL-Pool nur Daten für die angeforderten Spalten.
Tipp
Weitere Anleitungen zur Indizierung und replizierten Tabellen finden Sie unter Cheatsheet für dedizierte SQL-Pools (ehemals SQL DW) in Azure Synapse Analytics.
Verwenden Sie replizierte Tabellen mit einfachen Abfrageprädikaten
Bevor Sie sich für das Verteilen oder Replizieren einer Tabelle entscheiden, sollten Sie überlegen, welche Typen von Abfragen Sie für die Tabelle ausführen werden. Gehen Sie nach Möglichkeit wie folgt vor:
- Verwenden Sie replizierte Tabellen für Abfragen mit einfachen Abfrageprädikaten, z.B. Gleichheit oder Ungleichheit.
- Verwenden Sie verteile Tabellen für Abfragen mit komplexen Abfrageprädikaten, z.B. „LIKE“ oder „NOT LIKE“.
CPU-intensive Abfragen zeigen die beste Leistung, wenn die Verarbeitung auf alle Computeknoten verteilt ist. Beispielsweise bieten Abfragen, die Berechnungen für jede Zeile einer Tabelle ausführen, mit verteilten Tabellen eine bessere Leistung als mit replizierten Tabellen. Da eine replizierte Tabelle vollständig auf jedem Computeknoten gespeichert wird, wird eine CPU-intensive Abfrage einer replizierten Tabelle für die gesamte Tabelle auf jedem Computeknoten ausgeführt. Die zusätzliche Berechnung kann die Abfrageleistung beeinträchtigen.
Beispielsweise weist diese Abfrage ein komplexes Prädikat auf. Sie wird schneller ausgeführt, wenn sich die Daten in einer verteilten Tabelle anstatt in einer replizierten Tabelle befinden. In diesem Beispiel können die Daten mit Roundrobin verteilt werden.
SELECT EnglishProductName
FROM DimProduct
WHERE EnglishDescription LIKE '%frame%comfortable%';
Konvertieren Sie vorhandene Roundrobintabellen in replizierte Tabellen
Wenn Sie bereits über Roundrobintabellen verfügen, sollten Sie sie in replizierte Tabellen konvertieren, sofern sie die in diesem Artikel beschriebenen Kriterien erfüllen. Replizierte Tabellen bieten eine bessere Leistung als Roundrobintabellen, da sie nicht das Verschieben von Daten erfordern. Eine Roundrobintabelle erfordert für Joins immer Datenverschiebung.
In diesem Beispiel wird mithilfe von CTAS die Tabelle DimSalesTerritory in eine replizierte Tabelle geändert. Dieses Beispiel ist unabhängig davon gültig, ob DimSalesTerritory eine Tabelle mit Hashverteilung oder eine Roundrobintabelle ist.
CREATE TABLE [dbo].[DimSalesTerritory_REPLICATE]
WITH
(
HEAP,
DISTRIBUTION = REPLICATE
)
AS SELECT * FROM [dbo].[DimSalesTerritory]
OPTION (LABEL = 'CTAS : DimSalesTerritory_REPLICATE')
-- Switch table names
RENAME OBJECT [dbo].[DimSalesTerritory] to [DimSalesTerritory_old];
RENAME OBJECT [dbo].[DimSalesTerritory_REPLICATE] TO [DimSalesTerritory];
DROP TABLE [dbo].[DimSalesTerritory_old];
Beispiel für die Abfrageleistung bei Roundrobintabellen und replizierten Tabellen
Eine replizierte Tabelle erfordert für Joins keine Datenverschiebung, da die gesamte Tabelle bereits auf jedem Computeknoten vorhanden ist. Wenn die Dimensionstabellen nach dem Roundrobinprinzip verteilt sind, wird für einen Join die Dimensionstabelle vollständig auf jeden Computeknoten kopiert. Zum Verschieben der Daten enthält der Abfrageplan einen Vorgang mit dem Namen „BroadcastMoveOperation“. Dieser Typ von Datenverschiebungsvorgang verringert die Abfrageleistung und lässt sich durch die Verwendung replizierter Tabellen vermeiden. Verwenden Sie zum Anzeigen der Schritte von Abfrageplänen die Systemkatalogsicht sys.dm_pdw_request_steps.
Beispielsweise ist in der folgenden Abfrage des AdventureWorks-Schemas die Tabelle FactInternetSales eine Tabelle mit Hashverteilung. Die Tabellen DimDate und DimSalesTerritory sind kleinere Dimensionstabellen. Diese Abfrage gibt den Gesamtumsatz in Nordamerika für das Geschäftsjahr 2004 zurück:
SELECT [TotalSalesAmount] = SUM(SalesAmount)
FROM dbo.FactInternetSales s
INNER JOIN dbo.DimDate d
ON d.DateKey = s.OrderDateKey
INNER JOIN dbo.DimSalesTerritory t
ON t.SalesTerritoryKey = s.SalesTerritoryKey
WHERE d.FiscalYear = 2004
AND t.SalesTerritoryGroup = 'North America'
Wir haben DimDate und DimSalesTerritory als Roundrobintabellen neu erstellt. Deshalb wies die Abfrage den folgenden Abfrageplan auf, der mehrere Broadcastverschiebevorgänge enthält:
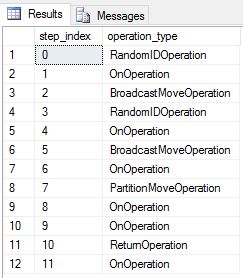
Wir haben DimDate und DimSalesTerritory als replizierte Tabellen neu erstellt und die Abfrage erneut ausgeführt. Der resultierende Abfrageplan ist sehr viel kürzer und enthält keine Broadcastverschiebungen.
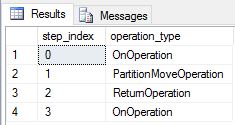
Überlegungen zur Leistung beim Ändern replizierter Tabellen
Der SQL-Pool implementiert eine replizierte Tabelle, indem eine Masterversion der Tabelle erhalten bleibt. Die Masterversion wird in die erste Verteilungsdatenbank auf jedem Computeknoten kopiert. Wenn eine Änderung eintritt, wird zunächst die Masterversion aktualisiert. Anschließend werden dann die Tabellen auf den einzelnen Serverknoten neu erstellt. Das Neuerstellen einer replizierten Tabelle umfasst das Kopieren der Tabelle auf jeden Serverknoten und das anschließende Erstellen der Indizes. Beispielsweise verfügt eine replizierte Tabelle auf einem DW2000c über fünf Kopien der Daten. Eine Masterkopie und eine vollständige Kopie auf jedem Serverknoten. Alle Daten werden in Verteilungsdatenbanken gespeichert. Der SQL-Pool unterstützt mit diesem Modell schnellere Datenänderungsanweisungen und flexible Skalierungsvorgänge.
Asynchrone Rebuilds werden von der ersten Abfrage der replizierten Tabelle ausgelöst:
- Daten werden geladen oder geändert.
- Die Synapse SQL-Instanz wird auf eine andere Ebene skaliert.
- Die Tabellendefinition wird aktualisiert.
Nach folgenden Vorgängen ist keine Neuerstellung erforderlich:
- Anhalten
- Fortsetzen
Die Neuerstellung erfolgt nicht unmittelbar nach dem Ändern der Daten. Stattdessen wird die Neuerstellung ausgelöst, wenn eine Abfrage zum ersten Mal etwas aus der Tabelle auswählt. Die Abfrage, die die Neuerstellung ausgelöst hat, liest sofort aus der Masterversion der Tabelle, während die Daten asynchron auf jeden Serverknoten kopiert werden. Solange das Kopieren der Daten noch nicht abgeschlossen ist, verwenden nachfolgende Abfragen weiterhin die Masterversion der Tabelle. Wenn eine Aktivität an der replizierten Tabelle ausgeführt wird, die eine weitere Neuerstellung erzwingt, wird das Kopieren der Daten für ungültig erklärt, und die nächste Select-Anweisung löst erneutes Kopieren der Daten aus.
Verwenden Sie Indizes zurückhaltend
Für replizierte Tabellen gelten Standardindizierungsverfahren. Der SQL-Pool erstellt während der Neuerstellung jeden replizierten Tabellenindex neu. Verwenden Sie Indizes nur, wenn der Leistungsgewinn die Kosten für die Neuerstellung der Indizes überwiegt.
Datenladevorgänge in Batches
Versuchen Sie beim Laden von Daten in replizierte Tabellen Neuerstellungen zu minimieren, indem Sie die Ladevorgänge in Batches zusammenfassen. Führen Sie alle in Batches zusammengefassten Ladevorgänge aus, bevor die SELECT-Anweisungen ausgeführt werden.
Beispielsweise werden in diesem Auslastungsmuster Daten aus vier Quellen geladen und vier Neuerstellungen aufgerufen.
- Laden aus Quelle 1.
- Eine SELECT-Anweisung löst Neuerstellung 1 aus.
- Laden aus Quelle 2.
- Eine SELECT-Anweisung löst Neuerstellung 2 aus.
- Laden aus Quelle 3.
- Eine SELECT-Anweisung löst Neuerstellung 3 aus.
- Laden aus Quelle 4.
- Eine SELECT-Anweisung löst Neuerstellung 4 aus.
Beispielsweise werden in diesem Auslastungsmuster Daten aus vier Quellen geladen, jedoch wird nur eine Neuerstellung aufgerufen.
- Laden aus Quelle 1.
- Laden aus Quelle 2.
- Laden aus Quelle 3.
- Laden aus Quelle 4.
- Eine SELECT-Anweisung löst die Neuerstellung aus.
Erstellen Sie nach jedem Batchladevorgang eine replizierte Tabelle neu
Um einheitliche Abfrageausführungszeiten sicherzustellen, erwägen Sie, nach jedem Batchladevorgang das Erstellen der replizierten Tabellen zu erzwingen. Andernfalls wird die erste Abfrage trotzdem eine Datenverschiebung durchführen, um die Abfrage abzuschließen.
Der Vorgang „Replizierten Tabellen-Cache erstellen“ kann bis zu zwei Vorgänge gleichzeitig ausführen. Wenn Sie beispielsweise versuchen, den Cache für fünf Tabellen neu zu erstellen, verwendet das System staticrc20 (kann nicht geändert werden), um zwei Tabellen gleichzeitig zu erstellen. Daher wird empfohlen, die Verwendung großer replizierter Tabellen mit einer Größe von mehr als 2 GB zu vermeiden, da dadurch die Cache-Neuerstellung über die Knoten hinweg verlangsamt und die Gesamtlaufzeit erhöht wird.
In dieser Abfrage wird die dynamische Verwaltungssicht sys.pdw_replicated_table_cache_state verwendet, um die replizierten Tabellen aufzulisten, die geändert, jedoch nicht neu erstellt wurden.
SELECT SchemaName = SCHEMA_NAME(t.schema_id)
, [ReplicatedTable] = t.[name]
, [RebuildStatement] = 'SELECT TOP 1 * FROM ' + '[' + SCHEMA_NAME(t.schema_id) + '].[' + t.[name] +']'
FROM sys.tables t
JOIN sys.pdw_replicated_table_cache_state c
ON c.object_id = t.object_id
JOIN sys.pdw_table_distribution_properties p
ON p.object_id = t.object_id
WHERE c.[state] = 'NotReady'
AND p.[distribution_policy_desc] = 'REPLICATE'
Um eine Neuerstellung auszulösen, führen Sie für jede Tabelle in der obigen Ausgabe die folgende Anweisung aus.
SELECT TOP 1 * FROM [ReplicatedTable]
Hinweis
Wenn Sie planen, die Statistiken der nicht zwischengespeicherten replizierten Tabelle neu zu erstellen, müssen Sie die Statistiken aktualisieren, bevor Sie den Cache auslösen. Durch das Aktualisieren von Statistiken wird der Cache ungültig, sodass die Sequenz wichtig ist.
Beispiel: Beginnen Sie mit UPDATE STATISTICS, und lösen Sie dann die Neuerstellung des Caches aus. In den folgenden Beispielen aktualisiert das richtige Beispiel die Statistiken und löst dann die Neuerstellung des Caches aus.
-- Incorrect sequence. Ensure that the rebuild operation is the last statement within the batch.
BEGIN
SELECT TOP 1 * FROM [ReplicatedTable]
UPDATE STATISTICS [ReplicatedTable]
END
-- Correct sequence. Ensure that the rebuild operation is the last statement within the batch.
BEGIN
UPDATE STATISTICS [ReplicatedTable]
SELECT TOP 1 * FROM [ReplicatedTable]
END
Um den Neuerstellungsprozess zu überwachen, können Sie sys.dm_pdw_exec_requests verwenden, wobei command mit "BuildReplicatedTableCache" beginnt. Beispiel:
-- Monitor Build Replicated Cache
SELECT *
FROM sys.dm_pdw_exec_requests
WHERE command like 'BuildReplicatedTableCache%'
Tipp
Tabellengrößenabfragen können verwendet werden, um zu überprüfen, welche Tabellen eine replizierte Verteilungsrichtlinie haben und welche größer als 2 GB sind.
Nächste Schritte
Verwenden Sie zum Erstellen einer replizierten Tabelle eine dieser Anweisungen:
Einen Überblick über verteilte Tabellen finden Sie unter Verteilen von Tabellen in SQL Data Warehouse.