Verwalten von Bibliotheken für Apache Spark-Pools in Azure Synapse Analytics
Nachdem Sie die Scala-, Java-, R- (Vorschau) oder Python-Pakete ermittelt haben, die Sie für Ihre Spark-Anwendung verwenden oder aktualisieren möchten, können Sie sie in einen Spark-Pool installieren oder daraus entfernen. Bibliotheken auf Poolebene sind für alle Notebooks und Aufträge verfügbar, die im Pool ausgeführt werden.
Es gibt zwei Hauptmethoden zum Installieren einer Bibliothek in einem Spark-Pool:
- Installieren Sie eine Arbeitsbereichsbibliothek, die als Arbeitsbereichspaket hochgeladen wurde.
- Stellen Sie zum Aktualisieren von Python-Bibliotheken eine Umgebungsspezifikationsdatei requirements.txt oder Conda environment.yml bereit, um Pakete aus Repositorys wie PyPI oder Conda-Forge zu installieren. Weitere Informationen finden Sie im Abschnitt Formate für Umgebungsspezifikationen.
Nachdem die Änderungen gespeichert wurden, wird die Installation durch einen Spark-Auftrag ausgeführt und die resultierende Umgebung zur späteren Wiederverwendung zwischengespeichert. Nachdem der Auftrag fertiggestellt wurde, werden bei neuen Spark-Aufträgen oder Notebooksitzungen die aktualisierten Poolbibliotheken verwendet.
Wichtig
- Wenn das zu installierende Paket groß ist oder seine Installation lange dauert, wirkt sich dies auf die Startdauer der Spark-Instanz aus.
- Das Ändern der Version von PySpark, Python, Scala/Java, .NET, R oder Spark wird nicht unterstützt.
- Das Installieren von Paketen aus externen Repositorys wie PyPI, Conda-Forge oder den Conda-Standardkanälen wird in Arbeitsbereichen mit DEP (Data Exfiltration Protection, Schutz vor Datenexfiltration) nicht unterstützt.
Verwalten von Paketen über Synapse Studio oder das Azure-Portal
Spark-Poolbibliotheken können entweder über Synapse Studio oder das Azure-Portal verwaltet werden.
Navigieren Sie im Azure-Portal zu Ihrem Azure Synapse Analytics-Arbeitsbereich.
Wählen Sie im Abschnitt Analytics-Pool die Registerkarte Apache Spark-Pools und dann einen Spark-Pool aus der Liste aus.
Wählen Sie im Abschnitt Einstellungen des Spark-Pools die Option Pakete aus.

Für Python-Feedbibliotheken laden Sie die Umgebungskonfigurationsdatei mithilfe der Dateiauswahl im Abschnitt Pakete auf der Seite hoch.
Sie können auch zusätzliche Arbeitsbereichspakete auswählen, um JAR-, Wheel- oder TAR.GZ-Dateien zu Ihrem Pool hinzuzufügen.
Sie können auch die veralteten Pakete aus dem Abschnitt Arbeitsbereichspakete entfernen. Ihr Pool wird diese Pakete dann nicht mehr anfügen.
Nachdem Sie Ihre Änderungen gespeichert haben, wird ein Systemauftrag ausgelöst, um die angegebenen Bibliotheken zu installieren und zwischenzuspeichern. Durch diesen Vorgang wird die Gesamtstartzeit der Sitzung reduziert.
Nachdem der Auftrag erfolgreich abgeschlossen wurde, übernehmen alle neuen Sitzungen die aktualisierten Poolbibliotheken.


Wichtig
Wenn Sie die Option Neue Einstellungen erzwingen aktivieren, beenden Sie damit alle aktuellen Sitzungen für den ausgewählten Spark-Pool. Nachdem die Sitzungen beendet wurden, müssen Sie warten, bis der Pool neu gestartet wurde.
Wenn diese Einstellung deaktiviert ist, müssen Sie warten, bis die aktuelle Spark-Sitzung beendet wurde, oder sie manuell beenden. Nachdem die Sitzung beendet wurde, müssen Sie warten, bist der Pool neu gestartet wurde.
Nachverfolgen des Installationsstatus
Bei jeder Aktualisierung eines Pools mit einem neuen Satz von Bibliotheken wird ein vom System reservierter Spark-Auftrag initiiert. Mit diesem Spark-Auftrag können Sie den Status der Bibliotheksinstallation überwachen. Wenn bei der Installation aufgrund von Bibliothekskonflikten oder anderen Problemen ein Fehler auftritt, wird der Spark-Pool auf den vorherigen oder den Standardzustand zurückgesetzt.
Darüber hinaus können Benutzende die Installationsprotokolle überprüfen, um Abhängigkeitskonflikte zu identifizieren oder zu ermitteln, welche Bibliotheken während des Poolupdates installiert wurden.
So zeigen Sie diese Protokolle an
Navigieren Sie in Synapse Studio auf der Registerkarte Überwachen zur Liste der Spark-Anwendungen.
Wählen Sie den Spark-Systemanwendungsauftrag aus, der Ihrem Poolupdate entspricht. Diese Systemaufträge werden unter dem Titel SystemReservedJob-LibraryManagement ausgeführt.
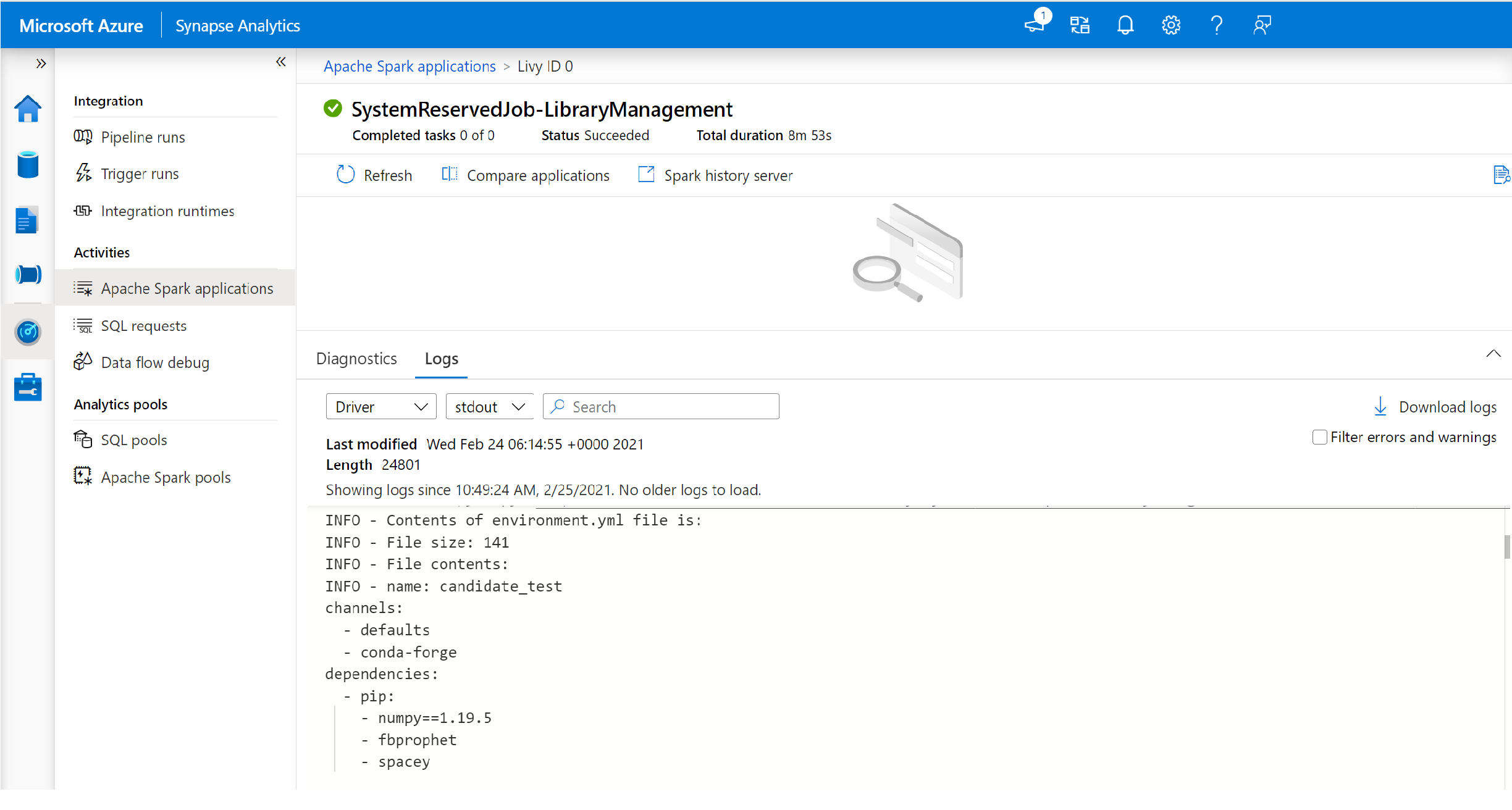
Wechseln Sie zur Anzeige der Protokolle driver und stdout.
Die Ergebnisse enthalten die Protokolle im Zusammenhang mit der Installation Ihrer Abhängigkeiten.


Formate für Umgebungsspezifikationen
PIP-Datei „requirements.txt“
Sie können eine Datei requirements.txt (Ausgabe des Befehls pip freeze) verwenden, um ein Upgrade der Umgebung durchzuführen. Bei der Aktualisierung eines Pools werden die in dieser Datei aufgeführten Pakete aus PyPI heruntergeladen. Die vollständigen Abhängigkeiten werden dann zwischengespeichert und zur späteren Wiederverwendung des Pools gespeichert.
Der folgende Codeausschnitt zeigt das Format für die Anforderungsdatei. Der Name des PyPI-Pakets wird zusammen mit einer exakten Version aufgeführt. Diese Datei hält das Format ein, das in der Referenzdokumentation zu pip freeze beschrieben wird.
Dieses Beispiel verwendet eine bestimmte Version.
absl-py==0.7.0
adal==1.2.1
alabaster==0.7.10
YML-Format
Darüber hinaus können Sie eine Datei environment.yml bereitstellen, um die Poolumgebung zu aktualisieren. Die in dieser Datei aufgeführten Pakete werden aus den Conda-Standardkanälen „Conda-Forge“ und „PyPI“ heruntergeladen. Mithilfe der Konfigurationsoptionen können Sie andere Kanäle angeben oder die Standardkanäle entfernen.
In diesem Beispiel werden die Kanäle und die Conda-/PyPI-Abhängigkeiten angegeben.
name: stats2
channels:
- defaults
dependencies:
- bokeh
- numpy
- pip:
- matplotlib
- koalas==1.7.0
Ausführliche Informationen zum Erstellen einer Umgebung aus dieser Datei environment.yml finden Sie unter Aktivieren einer Umgebung.