Tutorial: Erstellen einer Machine Learning-App mit Apache Spark MLlib und Azure Synapse Analytics
In diesem Artikel erfahren Sie, wie Sie mithilfe von Apache Spark MLlib eine Machine-Learning-Anwendung erstellt, die eine einfache Vorhersageanalyse für ein Azure Open Dataset ausführt. Spark bietet integrierte Machine Learning-Bibliotheken. In diesem Beispiel wird eine Klassifizierung mittels logistischer Regression verwendet.
SparkML und MLlib sind Spark-Kernbibliotheken, die viele praktische Hilfsprogramme für Machine Learning-Aufgaben wie die folgenden enthalten:
- Klassifizierung
- Regression
- Clustering
- Themenmodellierung
- Singulärwertzerlegung (Singular Value Decomposition, SVD) und Hauptkomponentenanalyse (Principal Component Analysis, PCA)
- Testen von Hypothesen und Berechnen von Beispielstatistiken
Grundlegendes zu Klassifizierung und logistischer Regression
Klassifizierung, eine Aufgabe im Bereich des Machine Learning, ist der Prozess, bei dem Eingabedaten in Kategorien sortiert werden. Der Klassifizierungsalgorithmus hat die Aufgabe, herauszufinden, wie Bezeichnungen den von Ihnen bereitgestellten Eingabedaten zugewiesen werden sollen. So kann ein Machine Learning-Algorithmus beispielsweise Börsendaten als Eingabe akzeptieren und die Daten in zwei Kategorien einteilen: Aktien, die Sie verkaufen sollten, und solche, die Sie behalten sollten.
Logistische Regression ist ein Algorithmus, den Sie für die Klassifizierung verwenden können. Die API für die logistische Regression von Spark ist nützlich für eine binäre Klassifizierungoder für die Klassifizierung der Eingabedaten in einer von zwei Gruppen. Weitere Informationen zur logistischen Regression finden Sie in Wikipedia.
Kurz gesagt: Der Prozess der logistischen Regression erzeugt eine logistische Funktion, die verwendet werden kann, um die Wahrscheinlichkeit vorherzusagen, dass ein Eingabevektor zu einer Gruppe gehört.
Beispiel für eine Vorhersageanalyse mit NYC-Taxidaten
In diesem Beispiel wird Spark verwendet, um einige Vorhersageanalysen zu Trinkgelddaten von Taxifahrten in New York durchzuführen. Die Daten sind über Azure Open Datasets verfügbar. Diese Teilmenge des Datasets enthält Informationen über Taxifahrten von Yellow Cabs, einschließlich Informationen zu jeder einzelnen Fahrt, den Start- und Endzeiten/-orten, den Kosten und andere interessante Attribute.
Wichtig
Es können zusätzliche Gebühren für das Abrufen dieser Daten aus ihrem Speicherort anfallen.
In den folgenden Schritten entwickeln Sie ein Modell, um vorherzusagen, ob eine bestimmte Fahrt ein Trinkgeld enthält oder nicht.
Erstellen eines Apache Spark-Machine Learning-Modells
Erstellen Sie ein Notebook unter Verwendung des PySpark-Kernels. Eine entsprechende Anleitung finden Sie unter Erstellen eines Notebooks.
Importieren Sie die Typen, die für diese Anwendung benötigt werden. Kopieren Sie den folgenden Code, fügen Sie ihn in eine leere Zelle ein, und drücken Sie UMSCHALT+EINGABE, oder führen Sie die Zelle mithilfe des blauen Wiedergabesymbols auf der linken Seite des Codes aus.
import matplotlib.pyplot as plt from datetime import datetime from dateutil import parser from pyspark.sql.functions import unix_timestamp, date_format, col, when from pyspark.ml import Pipeline from pyspark.ml import PipelineModel from pyspark.ml.feature import RFormula from pyspark.ml.feature import OneHotEncoder, StringIndexer, VectorIndexer from pyspark.ml.classification import LogisticRegression from pyspark.mllib.evaluation import BinaryClassificationMetrics from pyspark.ml.evaluation import BinaryClassificationEvaluatorDurch den PySpark-Kernel müssen Sie keine Kontexte explizit erstellen. Der Spark-Kontext wird automatisch für Sie erstellt, wenn Sie die erste Codezelle ausführen.
Erstellen des Eingabedatenrahmens
Da die Rohdaten im Parquet-Format vorliegen, können Sie den Spark-Kontext verwenden, um die Datei direkt als Datenrahmen in den Arbeitsspeicher zu lesen. Im Code für die folgenden Schritte werden zwar die Standardoptionen verwendet, bei Bedarf kann aber auch die Zuordnung von Datentypen und anderen Schemaattributen erzwungen werden.
Führen Sie die folgenden Zeilen zum Erstellen eines Spark-Datenrahmens aus, indem Sie den Code in eine neue Zelle einfügen. In diesem Schritt werden die Daten über die Open Datasets-API abgerufen. Das Abrufen aller dieser Daten generiert ungefähr 1,5 Milliarden Zeilen.
Je nach Größe Ihres serverlosen Apache Spark-Pools sind die Rohdaten möglicherweise zu umfangreich, oder ihre Verarbeitung dauert zu lang. Sie können diese Daten zu einer kleineren Menge filtern. Im folgenden Codebeispiel werden
start_dateundend_dateverwendet, um einen Filter anzuwenden, der Daten für einen einzelnen Monat zurückgibt.from azureml.opendatasets import NycTlcYellow from datetime import datetime from dateutil import parser end_date = parser.parse('2018-05-08 00:00:00') start_date = parser.parse('2018-05-01 00:00:00') nyc_tlc = NycTlcYellow(start_date=start_date, end_date=end_date) filtered_df = spark.createDataFrame(nyc_tlc.to_pandas_dataframe())Der Nachteil eines einfachen Filtervorgangs besteht darin, dass aus statistischer Sicht dadurch ein Trend in die Daten eingeführt werden kann. Ein anderer Ansatz besteht darin, die in Spark integrierte Stichprobenentnahme zu verwenden.
Durch den folgenden Code wird das Dataset auf etwa 2.000 Zeilen verkleinert, wenn er nach dem vorangehenden Code angewendet wird. Diese Stichprobenentnahme kann anstelle des einfachen Filters oder in Verbindung mit dem einfachen Filter verwendet werden.
# To make development easier, faster, and less expensive, downsample for now sampled_taxi_df = filtered_df.sample(True, 0.001, seed=1234)Nun können Sie sich die Daten ansehen, um herauszufinden, was gelesen wurde. Es empfiehlt sich in der Regel, Daten nicht anhand des gesamten Datasets, sondern anhand einer Teilmenge zu überprüfen. Das hängt jedoch von der Größe des Datasets ab.
Der folgende Code umfasst zwei Datenbetrachtungsmethoden. Die erste Methode ist rudimentär. Die zweite Methode bietet eine deutlich umfangreichere Rasterdarstellung sowie die Möglichkeit, die Daten grafisch zu visualisieren.
#sampled_taxi_df.show(5) display(sampled_taxi_df)Abhängig davon, wie groß das generierte Dataset ist und ob Sie damit experimentieren oder das Notebook mehrmals ausführen möchten, empfiehlt es sich gegebenenfalls, das Dataset lokal im Arbeitsbereich zwischenzuspeichern. Es gibt drei Methoden, um ein explizites Zwischenspeichern durchzuführen:
- Lokales Speichern des Datenrahmens als Datei
- Speichern des Datenrahmens als temporäre Tabelle oder Sicht
- Speichern des Datenrahmens als dauerhafte Tabelle
Die ersten beiden dieser Ansätze sind in den folgenden Codebeispielen enthalten.
Das Erstellen einer temporären Tabelle oder Sicht bietet unterschiedliche Zugriffspfade auf die Daten, ist aber auf die Dauer der Spark-Instanzsitzung beschränkt.
sampled_taxi_df.createOrReplaceTempView("nytaxi")
Vorbereiten der Daten
Die Daten im Rohformat sind häufig nicht für die direkte Übergabe an ein Modell geeignet. Für die Daten muss eine Reihe von Aktionen ausgeführt werden, um sie für das Modell nutzbar zu machen.
Im folgenden Code werden vier Arten von Vorgängen ausgeführt:
- Das Entfernen von Ausreißern oder falschen Werten durch Filtern.
- Das Entfernen von Spalten, die nicht benötigt werden.
- Das Erstellen neuer Spalten, die von den Rohdaten abgeleitet werden, um das Modell effektiver zu machen. Dieser Vorgang wird manchmal auch als Featurisierung bezeichnet.
- Bezeichnen („Labeln“). Da Sie eine binäre Klassifizierung vornehmen (gibt es bei einer bestimmten Fahrt Trinkgeld oder nicht), muss der Trinkgeldbetrag in 0 oder 1 konvertiert werden.
taxi_df = sampled_taxi_df.select('totalAmount', 'fareAmount', 'tipAmount', 'paymentType', 'rateCodeId', 'passengerCount'\
, 'tripDistance', 'tpepPickupDateTime', 'tpepDropoffDateTime'\
, date_format('tpepPickupDateTime', 'hh').alias('pickupHour')\
, date_format('tpepPickupDateTime', 'EEEE').alias('weekdayString')\
, (unix_timestamp(col('tpepDropoffDateTime')) - unix_timestamp(col('tpepPickupDateTime'))).alias('tripTimeSecs')\
, (when(col('tipAmount') > 0, 1).otherwise(0)).alias('tipped')
)\
.filter((sampled_taxi_df.passengerCount > 0) & (sampled_taxi_df.passengerCount < 8)\
& (sampled_taxi_df.tipAmount >= 0) & (sampled_taxi_df.tipAmount <= 25)\
& (sampled_taxi_df.fareAmount >= 1) & (sampled_taxi_df.fareAmount <= 250)\
& (sampled_taxi_df.tipAmount < sampled_taxi_df.fareAmount)\
& (sampled_taxi_df.tripDistance > 0) & (sampled_taxi_df.tripDistance <= 100)\
& (sampled_taxi_df.rateCodeId <= 5)
& (sampled_taxi_df.paymentType.isin({"1", "2"}))
)
In einem zweiten Durchlauf für die Daten werden dann die endgültigen Features hinzugefügt.
taxi_featurised_df = taxi_df.select('totalAmount', 'fareAmount', 'tipAmount', 'paymentType', 'passengerCount'\
, 'tripDistance', 'weekdayString', 'pickupHour','tripTimeSecs','tipped'\
, when((taxi_df.pickupHour <= 6) | (taxi_df.pickupHour >= 20),"Night")\
.when((taxi_df.pickupHour >= 7) & (taxi_df.pickupHour <= 10), "AMRush")\
.when((taxi_df.pickupHour >= 11) & (taxi_df.pickupHour <= 15), "Afternoon")\
.when((taxi_df.pickupHour >= 16) & (taxi_df.pickupHour <= 19), "PMRush")\
.otherwise(0).alias('trafficTimeBins')
)\
.filter((taxi_df.tripTimeSecs >= 30) & (taxi_df.tripTimeSecs <= 7200))
Erstellen eines logistischen Regressionsmodells
Die letzte Aufgabe besteht darin, die bezeichneten Daten in ein Format zu konvertieren, das mit der logistischen Regression analysiert werden kann. Die Eingabe für einen logistischen Regressionsalgorithmus muss eine Gruppe von Paaren aus Bezeichnung und Featurevektor sein, wobei der Featurevektor aus Zahlen besteht, die den Eingabepunkt darstellen.
Die Kategoriespalten müssen also in Zahlen konvertiert werden. Genauer gesagt, müssen die Spalten trafficTimeBins und weekdayString in ganzzahlige Darstellungen konvertiert werden. Die Konvertierung kann auf verschiedene Arten durchgeführt werden. Im folgenden Beispiel wird der gängige Ansatz OneHotEncoder verwendet.
# Because the sample uses an algorithm that works only with numeric features, convert them so they can be consumed
sI1 = StringIndexer(inputCol="trafficTimeBins", outputCol="trafficTimeBinsIndex")
en1 = OneHotEncoder(dropLast=False, inputCol="trafficTimeBinsIndex", outputCol="trafficTimeBinsVec")
sI2 = StringIndexer(inputCol="weekdayString", outputCol="weekdayIndex")
en2 = OneHotEncoder(dropLast=False, inputCol="weekdayIndex", outputCol="weekdayVec")
# Create a new DataFrame that has had the encodings applied
encoded_final_df = Pipeline(stages=[sI1, en1, sI2, en2]).fit(taxi_featurised_df).transform(taxi_featurised_df)
Diese Aktion führt zu einem neuen Datenrahmen mit allen Spalten im richtigen Format, um ein Modell zu trainieren.
Trainieren eines logistischen Regressionsmodells
Die erste Aufgabe besteht darin, das Dataset in ein Trainingsdataset und ein Test- oder Validierungsdataset aufzuteilen. Die Aufteilung ist hierbei beliebig. Experimentieren Sie mit verschiedenen Aufteilungseinstellungen, um zu sehen, ob sie sich auf das Modell auswirken.
# Decide on the split between training and testing data from the DataFrame
trainingFraction = 0.7
testingFraction = (1-trainingFraction)
seed = 1234
# Split the DataFrame into test and training DataFrames
train_data_df, test_data_df = encoded_final_df.randomSplit([trainingFraction, testingFraction], seed=seed)
Nachdem nun zwei Datenrahmen vorhanden sind, besteht die nächste Aufgabe darin, die Modellformel zu erstellen und für den Trainingsdatenrahmen auszuführen. Anschließend können Sie eine Überprüfung anhand des Testdatenrahmens ausführen. Experimentieren Sie mit verschiedenen Versionen der Modellformel, um die Auswirkungen verschiedener Kombinationen zu ermitteln.
Hinweis
Um das Modell zu speichern, weisen Sie dem Ressourcenbereich des Azure SQL-Datenbank-Servers die Rolle Mitwirkender an Storage-Blobdaten zu. Ausführliche Informationen finden Sie unter Zuweisen von Azure-Rollen über das Azure-Portal. Dieser Schritt kann nur von Mitgliedern mit Besitzerrechten ausgeführt werden.
## Create a new logistic regression object for the model
logReg = LogisticRegression(maxIter=10, regParam=0.3, labelCol = 'tipped')
## The formula for the model
classFormula = RFormula(formula="tipped ~ pickupHour + weekdayVec + passengerCount + tripTimeSecs + tripDistance + fareAmount + paymentType+ trafficTimeBinsVec")
## Undertake training and create a logistic regression model
lrModel = Pipeline(stages=[classFormula, logReg]).fit(train_data_df)
## Saving the model is optional, but it's another form of inter-session cache
datestamp = datetime.now().strftime('%m-%d-%Y-%s')
fileName = "lrModel_" + datestamp
logRegDirfilename = fileName
lrModel.save(logRegDirfilename)
## Predict tip 1/0 (yes/no) on the test dataset; evaluation using area under ROC
predictions = lrModel.transform(test_data_df)
predictionAndLabels = predictions.select("label","prediction").rdd
metrics = BinaryClassificationMetrics(predictionAndLabels)
print("Area under ROC = %s" % metrics.areaUnderROC)
Die Ausgabe dieser Zelle ist:
Area under ROC = 0.9779470729751403
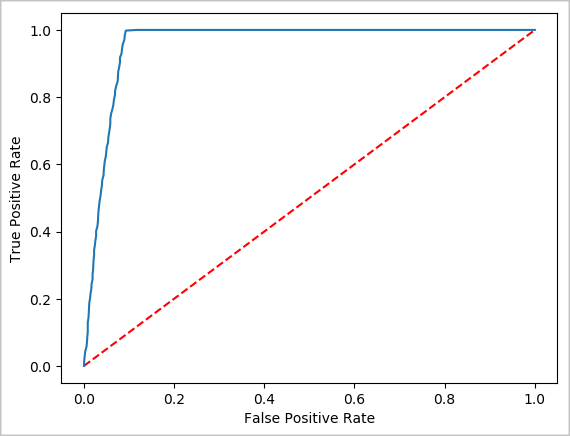
Erstellen einer visuellen Darstellung der Vorhersage
Nun können Sie eine endgültige Visualisierung erstellen, um sich mit den Ergebnissen dieses Tests auseinanderzusetzen. Eine ROC-Kurve ist eine Möglichkeit, um das Ergebnis zu überprüfen.
## Plot the ROC curve; no need for pandas, because this uses the modelSummary object
modelSummary = lrModel.stages[-1].summary
plt.plot([0, 1], [0, 1], 'r--')
plt.plot(modelSummary.roc.select('FPR').collect(),
modelSummary.roc.select('TPR').collect())
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.show()
Herunterfahren der Spark-Instanz
Nach dem Ausführen der Anwendung empfiehlt es sich, die Registerkarte zu schließen, um das Notebook herunterzufahren und die Ressourcen freizugeben. Alternativ können Sie auch im Statusbereich am unteren Rand des Notebooks die Option Sitzung beenden auswählen.