Sicherheit, Zugriff und Vorgänge für Netezza-Migrationen
Dieser Artikel ist Teil 3 einer siebenteiligen Reihe, die einen Leitfaden zum Migrieren von Netezza zu Azure Synapse Analytics bereitstellt. In diesem Artikel werden schwerpunktmäßig bewährte Methoden für Sicherheit, Zugriff und Vorgänge behandelt.
Sicherheitshinweise
In diesem Artikel werden Verbindungsmethoden für vorhandene Netezza-Legacyumgebungen erläutert, und Sie erfahren, wie Sie diese Umgebungen mit minimalen Risiken und Auswirkungen auf Benutzer zu Azure Synapse Analytics migrieren können.
In diesem Artikel wird davon ausgegangen, dass die vorhandenen Verbindungsmethoden und die vorhandene Benutzer-, Rollen- und Berechtigungsstruktur unverändert migriert werden müssen. Ansonsten verwenden Sie das Azure-Portal, um ein neues Sicherheitsschema zu erstellen und zu verwalten.
Weitere Informationen zu den Optionen für die Azure Synapse-Sicherheit finden Sie im Whitepaper zur Sicherheit.
Verbindung und Authentifizierung
Tipp
Sowohl in Netezza als auch in Azure Synapse kann die Authentifizierung datenbankintern oder über externe Methoden erfolgen.
Autorisierungsoptionen von Netezza
Das IBM Netezza-System bietet verschiedene Authentifizierungsmethoden für Netezza-Datenbankbenutzer:
Lokale Authentifizierung: Netezza-Administratoren definieren Datenbankbenutzer und ihre Kennwörter mit dem Befehl
CREATE USERoder über die Verwaltungsschnittstellen von Netezza. Bei der lokalen Authentifizierung verwenden Sie das Netezza-System zur Verwaltung von Datenbankkonten und Kennwörtern sowie zum Hinzufügen und Entfernen von Datenbankbenutzern aus dem System. Diese Methode ist die Standardauthentifizierungsmethode.LDAP-Authentifizierung: Verwenden Sie einen LDAP-Namensserver zur Authentifizierung von Datenbankbenutzern, zum Verwalten von Kennwörtern sowie zum Aktivieren und Deaktivieren von Datenbankkonten. Das Netezza-System verwendet ein Modul für die austauschbare Authentifizierung (Pluggable Authentication Module, PAM) zur Authentifizierung von Benutzern auf dem LDAP-Namensserver. Microsoft Active Directory entspricht dem LDAP-Protokoll, sodass es für die Zwecke der LDAP-Authentifizierung wie ein LDAP-Server behandelt werden kann.
Kerberos-Authentifizierung: Verwenden Sie einen Kerberos-Verteilungsserver zur Authentifizierung von Datenbankbenutzern, zum Verwalten von Kennwörtern sowie zum Aktivieren und Deaktivieren von Datenbankkonten.
Die Authentifizierung ist eine systemweite Einstellung. Benutzer müssen entweder lokal oder über die LDAP- oder Kerberos-Methode authentifiziert werden. Wenn Sie sich für die LDAP- oder Kerberos-Authentifizierung entscheiden, erstellen Sie Benutzer mit lokaler Authentifizierung auf Benutzerbasis. LDAP und Kerberos können nicht gleichzeitig verwendet werden, um Benutzer zu authentifizieren. Der Netezza-Host unterstützt die LDAP- oder Kerberos-Authentifizierung nur für die Anmeldung von Datenbankbenutzern, nicht für die Anmeldung am Betriebssystem des Hosts.
Autorisierungsoptionen von Azure Synapse
Azure Synapse unterstützt zwei grundlegende Optionen für die Verbindung und Autorisierung:
SQL-Authentifizierung: Die SQL-Authentifizierung erfolgt über eine Datenbankverbindung, die einen Datenbankbezeichner, eine Benutzer-ID und ein Kennwort sowie andere optionale Parameter umfasst. Dies entspricht funktionell den lokalen Verbindungen von Netezza.
Microsoft Entra-Authentifizierung: Mit der Microsoft Entra-Authentifizierung können Sie die Identitäten von Datenbankbenutzer*innen und anderen Microsoft-Diensten zentral an einem Ort verwalten. Die zentrale ID-Verwaltung ermöglicht eine einheitliche Verwaltung von Azure Synapse-Benutzern und vereinfacht die Berechtigungsverwaltung. Microsoft Entra ID kann auch Verbindungen mit LDAP- und Kerberos-Diensten unterstützen. Beispielsweise kann Microsoft Entra ID zum Herstellen einer Verbindung mit vorhandenen LDAP-Verzeichnissen verwendet werden, wenn diese nach der Migration der Datenbank beibehalten werden.
Benutzer, Rollen und Berechtigungen
Übersicht
Tipp
Für ein erfolgreiches Migrationsprojekt ist eine Planung auf hoher Ebene unerlässlich.
Sowohl Netezza als auch Azure Synapse implementieren die Zugriffssteuerung für Datenbanken über eine Kombination aus Benutzern, Rollen (Gruppen in Netezza) und Berechtigungen. Beide Systeme verwenden standardmäßige SQL-Anweisungen CREATE USER und CREATE ROLE/GROUP zum Definieren von Benutzern und Rollen sowie GRANT- und REVOKE-Anweisungen zum Zuweisen oder Entfernen von Berechtigungen für diese Benutzer und/oder Rollen.
Tipp
Die Automatisierung von Migrationsprozessen wird empfohlen, um den Zeitaufwand und die Wahrscheinlichkeit von Fehlern zu reduzieren.
Konzeptionell ähneln sich die beiden Datenbanken, und es kann möglich sein, die Migration vorhandener Benutzer-IDs, Gruppen und Berechtigungen zu einem gewissen Grad zu automatisieren. Migrieren Sie solche Daten, indem Sie die vorhandenen Informationen zu Benutzern und Gruppen aus den Netezza-Systemkatalogtabellen extrahieren und entsprechende CREATE USER- und CREATE ROLE-Anweisungen generieren, die in Azure Synapse ausgeführt werden, um die gleiche Benutzer-/Rollenhierarchie neu zu erstellen.
Generieren Sie nach der Datenextraktion mithilfe der Netezza-Systemkatalogtabellen entsprechende GRANT-Anweisungen zum Zuweisen von Berechtigungen (sofern ein Äquivalent vorhanden ist). Das folgende Diagramm zeigt, wie vorhandene Metadaten zum Generieren der erforderlichen SQL-Anweisungen verwendet werden können.
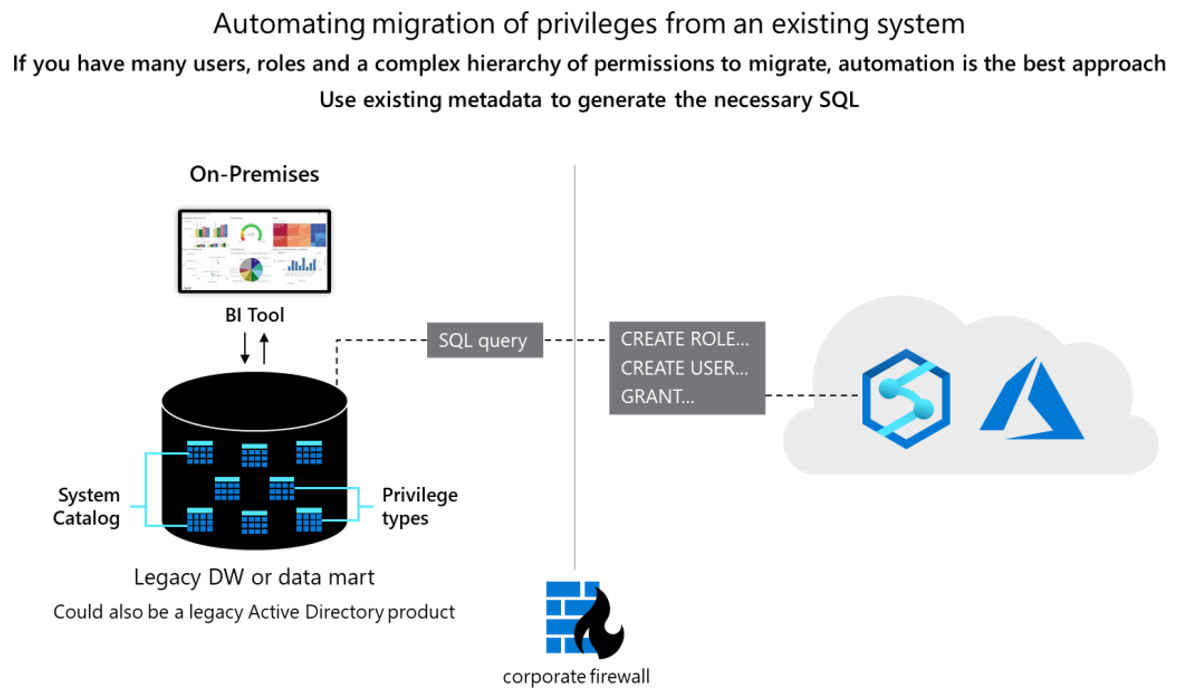
Die folgenden Abschnitte enthalten hierzu weitere Informationen.
Benutzer und Rollen
Tipp
Die Migration eines Data Warehouse erfordert mehr als nur Tabellen, Sichten und SQL-Anweisungen.
Die Informationen über die aktuellen Benutzer und Gruppen in einem Netezza-System werden in den Systemkatalogsichten _v_users und _v_groupusers gespeichert. Verwenden Sie das nzsql-Hilfsprogramm oder Tools wie Netezza Performance, NzAdmin und Netezza-Hilfsskripts, um Benutzerberechtigungen aufzulisten. Verwenden Sie zum Beispiel die Befehle dpu und dpgu in nzsql, um Benutzer oder Gruppen mit ihren Berechtigungen anzuzeigen.
Verwenden oder bearbeiten Sie die Hilfsskripts nz_get_users und nz_get_user_groups, um die gleichen Informationen im erforderlichen Format abzurufen.
Fragen Sie die Systemkatalogsichten direkt ab (wenn der Benutzer SELECT-Zugriff auf diese Sichten hat), um aktuelle Listen der im System definierten Benutzer und Rollen abzurufen. Beispiele zum Auflisten von Benutzern, Gruppen oder Benutzern und ihren zugeordneten Gruppen:
-- List of users
SELECT USERNAME FROM _V_USER;
--List of groups
SELECT DISTINCT(GROUPNAME) FROM _V_USERGROUPS;
--List of users and their associated groups
SELECT USERNAME, GROUPNAME FROM _V_GROUPUSERS;
Ändern Sie die Beispielanweisung SELECT, um ein Resultset zu erzeugen, das aus einer Reihe von CREATE USER- und CREATE GROUP-Anweisungen besteht, indem Sie den entsprechenden Text als Literal in die SELECT-Anweisung einfügen.
Das Abrufen vorhandener Kennwörter ist nicht möglich. Sie müssen daher ein Schema für die Zuordnung neuer anfänglicher Kennwörter in Azure Synapse implementieren.
Berechtigungen
Tipp
Für grundlegende Datenbankvorgänge wie Datenbearbeitungssprache (Data Manipulation Language, DML) und Datenbeschreibungssprache (Data Definition Language, DDL) sind entsprechende Azure Synapse-Berechtigungen verfügbar.
In einem Netezza-System enthält die Systemtabelle _t_usrobj_priv die Zugriffsrechte für Benutzer und Rollen. Fragen Sie diese Tabellen ab (wenn der Benutzer über SELECT-Zugriff auf diese Tabellen verfügt), um aktuelle Listen der im System definierten Zugriffsrechte abzurufen.
In Netezza werden die jeweiligen Berechtigungen als einzelne Bits im Feld „privileges“ oder „g_privileges“ dargestellt. Eine SQL-Beispielanweisung finden Sie unter Benutzer- und Gruppenberechtigungen.
Der einfachste Weg zum Abrufen eines DDL-Skripts, das die GRANT-Befehle zum Replizieren der aktuellen Berechtigungen für Benutzer und Gruppen enthält, ist die Verwendung der entsprechenden Netezza-Hilfsskripts:
--List of group privileges
nz_ddl_grant_group -usrobj dbname > output_file_dbname;
--List of user privileges
nz_ddl_grant_user -usrobj dbname > output_file_dbname;
Die Ausgabedatei kann geändert werden, um ein Skript zu erstellen, das eine Reihe von GRANT-Anweisungen für Azure Synapse enthält.
Netezza unterstützt zwei Klassen von Zugriffsrechten: „Admin“ und „Object“. Die folgende Tabelle enthält eine Liste der Netezza-Zugriffsrechte und ihrer Entsprechungen in Azure Synapse.
| Administratorberechtigung | BESCHREIBUNG | Azure Synapse-Äquivalent |
|---|---|---|
| Backup | Ermöglicht Benutzern das Erstellen von Sicherungen. Der Benutzer kann Sicherungen ausführen. Der Benutzer kann den Befehl nzbackup ausführen. |
1 |
| [Create] Aggregate | Ermöglicht dem Benutzer, benutzerdefinierte Aggregate (UDAs) zu erstellen. Die Berechtigung zum Arbeiten mit vorhandenen UDAs wird über Objektberechtigungen gesteuert. | CREATE FUNCTION 3 |
| [Create] Database | Ermöglicht dem Benutzer das Erstellen von Datenbanken. Die Berechtigung zum Arbeiten mit vorhandenen Datenbanken wird über Objektberechtigungen gesteuert. | CREATE DATABASE |
| [Create] External Table | Ermöglicht dem Benutzer das Erstellen externer Tabellen. Die Berechtigung zum Arbeiten mit vorhandenen Tabellen wird über Objektberechtigungen gesteuert. | CREATE TABLE |
| [Create] Function | Ermöglicht dem Benutzer, benutzerdefinierte Funktionen (UDFs) zu erstellen. Die Berechtigung zum Arbeiten mit vorhandenen UDFs wird über Objektberechtigungen gesteuert. | CREATE FUNCTION |
| [Create] Group | Ermöglicht dem Benutzer das Erstellen von Gruppen. Die Berechtigung zum Arbeiten mit vorhandenen Gruppen wird über Objektberechtigungen gesteuert. | CREATE ROLE |
| [Create] Index | Nur zur Verwendung durch das System. Benutzer können keine Indizes erstellen. | CREATE INDEX |
| [Create] Library | Ermöglicht dem Benutzer das Erstellen freigegebener Bibliotheken. Die Berechtigung zum Arbeiten mit vorhandenen freigegebenen Bibliotheken wird über Objektberechtigungen gesteuert. | 1 |
| [Create] Materialized View | Ermöglicht dem Benutzer, materialisierte Sichten zu erstellen. | CREATE VIEW |
| [Create] Procedure | Ermöglicht dem Benutzer, gespeicherte Prozeduren zu erstellen. Die Berechtigung zum Arbeiten mit vorhandenen gespeicherten Prozeduren wird über Objektberechtigungen gesteuert. | CREATE PROCEDURE |
| [Create] Schema | Ermöglicht dem Benutzer das Erstellen von Schemas. Die Berechtigung zum Arbeiten mit vorhandenen Schemas wird über Objektberechtigungen gesteuert. | CREATE SCHEMA |
| [Create] Sequence | Ermöglicht dem Benutzer das Erstellen von Datenbanksequenzen. | 1 |
| [Create] Synonym | Ermöglicht dem Benutzer das Erstellen von Synonymen. | CREATE SYNONYM |
| [Create] Table | Ermöglicht dem Benutzer das Erstellen von Tabellen. Die Berechtigung zum Arbeiten mit vorhandenen Tabellen wird über Objektberechtigungen gesteuert. | CREATE TABLE |
| [Create] Temp Table | Ermöglicht dem Benutzer das Erstellen von temporären Tabellen. Die Berechtigung zum Arbeiten mit vorhandenen Tabellen wird über Objektberechtigungen gesteuert. | CREATE TABLE |
| [Create] User | Ermöglicht dem Benutzer das Erstellen von Benutzern. Die Berechtigung zum Arbeiten mit vorhandenen Benutzern wird über Objektberechtigungen gesteuert. | CREATE USER |
| [Create] View | Ermöglicht dem Benutzer das Erstellen von Sichten. Die Berechtigung zum Arbeiten mit vorhandenen Sichten wird über Objektberechtigungen gesteuert. | CREATE VIEW |
| [Manage Hardware | Ermöglicht dem Benutzer, die folgenden hardwarebezogenen Vorgänge auszuführen: Anzeigen des Hardwarestatus, Verwalten von SPUs, Topologie und Spiegelung und Ausführen von Diagnosetests. Der Benutzer kann diese Befehle ausführen: nzhw, nzds. | 4 |
| [Manage Security | Ermöglicht dem Benutzer das Ausführen von Befehlen und Vorgängen, die sich auf die folgenden erweiterten Sicherheitsoptionen beziehen, darunter: Verwalten und Konfigurieren von Verlaufsdatenbanken, Verwalten von Sicherheitsobjekten auf mehreren Ebenen, Festlegen der Sicherheit für Benutzer und Gruppen, Verwalten von Datenbankschlüsselspeichern, Schlüsseln und Schlüsselspeichern für die digitale Signatur von Überwachungsdaten. | 4 |
| [Manage System | Ermöglicht dem Benutzer die folgenden Verwaltungsvorgänge: Starten/Beenden/Pausieren/Wiederaufnehmen des Systems, Abbrechen von Sitzungen, Anzeigen von Verteilungsübersicht, Systemstatistiken und Protokollen. Der Benutzer kann diese Befehle verwenden: nzsystem, nzstate, nzstats, nzsession. | 4 |
| Restore | Ermöglicht dem Benutzer das Wiederherstellen des Systems. Der Benutzer kann den Befehl „nzrestore“ ausführen. | 2 |
| Unfence | Ermöglicht dem Benutzer das Erstellen oder Ändern einer benutzerdefinierten Funktion oder eines Aggregats, das im Modus „Unfenced“ ausgeführt werden kann. | 1 |
| Objektberechtigung | BESCHREIBUNG | Azure Synapse-Äquivalent |
|---|---|---|
| Abbruch | Ermöglicht dem Benutzer das Abbrechen von Sitzungen. Gilt für Gruppen und Benutzer. | KILL DATABASE CONNECTION |
| Ändern | Ermöglicht dem Benutzer das Ändern von Objektattributen. Gilt für alle Objekte. | ALTER |
| Löschen | Ermöglicht dem Benutzer das Löschen von Tabellenzeilen. Gilt nur für Tabellen. | Delete |
| Verwerfen | Ermöglicht dem Benutzer das Ablegen von Objekten. Gilt für alle Objekttypen. | DROP |
| Execute | Ermöglicht dem Benutzer das Ausführen benutzerdefinierter Funktionen, benutzerdefinierte Aggregate oder gespeicherter Prozeduren. | Führen Sie |
| GenStats | Ermöglicht dem Benutzer, Statistiken für Tabellen oder Datenbanken zu generieren. Der Benutzer kann den Befehl GENERATE STATISTICS ausführen. | 2 |
| Groom | Ermöglicht es dem Benutzer, Speicherplatz für gelöschte oder veraltete Zeilen zurückzufordern und eine Tabelle nach den Organisationsschlüsseln neu anzuordnen oder Daten für Tabellen zu migrieren, für die mehrere Versionen gespeichert sind. | 2 |
| Einfügen | Ermöglicht dem Benutzer das Einfügen von Zeilen in eine Tabelle. Gilt nur für Tabellen. | INSERT |
| List | Ermöglicht dem Benutzer das Anzeigen eines Objektnamens, entweder in einer Liste oder auf andere Weise. Gilt für alle Objekte. | AUFLISTEN |
| Select | Ermöglicht dem Benutzer das Auswählen (oder Abfragen) von Zeilen in einer Tabelle. Gilt für Tabellen und Sichten. | SELECT |
| Truncate | Ermöglicht dem Benutzer das Löschen aller Zeilen aus einer Tabelle. Gilt nur für Tabellen. | TRUNCATE |
| Aktualisieren | Ermöglicht dem Benutzer das Ändern von Tabellenzeilen. Gilt nur für Tabellen. | UPDATE |
Anmerkungen zur Tabelle:
Es gibt keine direkte Entsprechung dieser Funktion in Azure Synapse.
Diese Netezza-Funktionen werden in Azure Synapse automatisch verarbeitet.
Das Azure Synapse-Feature
CREATE FUNCTIONumfasst die Aggregatfunktion von Netezza.Diese Features werden in Azure Synapse automatisch vom System oder über das Azure-Portal verwaltet. Weitere Informationen finden Sie im nächsten Abschnitt „Überlegungen zur Verwendung“, in dem betriebliche Überlegungen erläutert werden.
Siehe Azure Synapse Analytics-Sicherheitsberechtigungen.
Überlegungen zur Verwendung
Tipp
Für den effizienten Betrieb eines Data Warehouse müssen operative Aufgaben ausgeführt werden.
In diesem Abschnitt wird erläutert, wie Sie typische operative Netezza-Aufgaben mit minimalen Risiken und Auswirkungen auf Benutzer in Azure Synapse implementieren.
Wie bei allen Data Warehouse-Produkten sind bei der Verwendung in der Produktion laufende Verwaltungsaufgaben erforderlich, um den effizienten Betrieb des Systems aufrechtzuerhalten und Daten für die Überwachung und Überprüfung bereitzustellen. Die Ressourcenverwendung und Kapazitätsplanung für zukünftiges Wachstum fällt wie die Sicherung/Wiederherstellung von Daten ebenfalls in diese Kategorie.
Netezza-Verwaltungsaufgaben werden üblicherweise in zwei Kategorien eingeordnet:
Systemverwaltung: In diesen Bereich fallen die Verwaltung von Hardware, Konfigurationseinstellungen, Systemstatus, Zugriff, Speicherplatz, Nutzung, Upgrades und andere Aufgaben.
Datenbankverwaltung: In diesen Bereich fallen die Verwaltung von Benutzerdatenbanken und deren Inhalt, das Laden von Daten, das Sichern von Daten, das Wiederherstellen von Daten und die Kontrolle des Zugriffs auf Daten und Berechtigungen.
IBM Netezza bietet unterschiedliche Möglichkeiten bzw. Schnittstellen, mit denen Sie die verschiedenen System- und Datenbankverwaltungsaufgaben ausführen können:
Netezza-Befehle (
nz*-Befehle) werden im Verzeichnis/nz/kit/binauf dem Netezza-Host installiert. Für viele dernz*-Befehle müssen Sie sich beim Netezza-System anmelden, um auf die Befehle zugreifen und sie ausführen zu können. In den meisten Fällen melden sich die Benutzer mit dem standardmäßigennz-Benutzerkonto an, Sie können aber auch andere Linux-Benutzerkonten in Ihrem System erstellen. Bei einigen Befehlen müssen Sie ein Datenbankbenutzerkonto, ein Kennwort und eine Datenbank angeben, um sicherzustellen, dass Sie über die entsprechende Berechtigung zum Ausführen der Aufgabe verfügen.Die Netezza CLI-Client-Kits enthalten eine Teilmenge der
nz*-Befehle, die auf Windows- und UNIX-Clientsystemen ausgeführt werden können. Für die Clientbefehle müssen Sie möglicherweise zusätzlich ein Datenbankbenutzerkonto, ein Kennwort und eine Datenbank angeben, um sicherzustellen, dass Sie für die Datenbank über die erforderlichen Administrator- und Objektberechtigungen zum Ausführen der Aufgabe verfügen.Die SQL-Befehle unterstützen Verwaltungsaufgaben und Abfragen innerhalb einer SQL-Datenbanksitzung. Sie können die SQL-Befehle über den nzsql-Befehlsinterpreter von Netezza oder über SQL-APIs wie ODBC, JDBC und den OLE DB-Anbieter ausführen. Sie müssen über ein Datenbankbenutzerkonto verfügen, um die SQL-Befehle mit den entsprechenden Berechtigungen für die von Ihnen durchgeführten Abfragen und Aufgaben ausführen zu können.
Das NzAdmin-Tool ist eine Netezza-Schnittstelle, die auf Windows-Clientarbeitsstationen ausgeführt wird, um Netezza-Systeme zu verwalten.
Wenngleich sich die Verwaltungs- und Betriebsaufgaben für verschiedene Data Warehouses vom Konzept her ähneln, können sich die einzelnen Implementierungen unterscheiden. Moderne cloudbasierte Produkte wie Azure Synapse beruhen meist auf einem Ansatz mit umfassender Automatisierung und „systemseitiger Verwaltung“ (im Gegensatz zum eher manuellen Ansatz in Legacy-Data Warehouses wie Netezza).
In den folgenden Abschnitten werden die Netezza- und Azure Synapse-Optionen für verschiedene operative Aufgaben verglichen.
Housekeepingaufgaben
Tipp
Housekeepingaufgaben sorgen dafür, dass ein Data Warehouse in der Produktion effizient funktioniert, und optimieren die Verwendung von Ressourcen wie z. B. Speicher.
In den meisten Legacy-Data Warehouse-Umgebungen nehmen die regelmäßigen Housekeepingaufgaben viel Zeit in Anspruch. Geben Sie Speicherplatz auf dem Datenträger frei, indem Sie alte Versionen von aktualisierten oder gelöschten Zeilen entfernen oder Daten, Protokolldateien oder Indexblöcke zur Effizienzsteigerung reorganisieren (GROOM und VACUUM in Netezza). Auch das Erfassen von Statistiken ist eine potenziell zeitaufwändige Aufgabe, die nach dem Masseneinlesen von Daten erforderlich ist, um den Abfrageoptimierer mit aktuellen Daten zu versorgen, auf denen die Abfrageausführungspläne basieren.
Netezza empfiehlt, zum Erfassen von Statistiken wie folgt vorzugehen:
Erfassen Sie Statistiken für nicht aufgefüllte Tabellen, um das Intervallhistogramm einzurichten, das bei der internen Verarbeitung verwendet wird. Durch diese anfängliche Erfassung wird der Zeitaufwand für nachfolgende Statistikerfassungen reduziert. Stellen Sie sicher, dass nach dem Hinzufügen von Daten erneut Statistiken erfasst werden.
Erfassen Sie in der Prototypphase Statistiken für neu aufgefüllte Tabellen.
Erfassen Sie in der Produktionsphase Statistiken, nachdem eine signifikante prozentuale Änderung an der Tabelle oder Partition vorgenommen wurde (~10 % der Zeilen). Bei einer großen Anzahl nicht eindeutiger Werte (z. B. Datumsangaben oder Zeitstempel), kann es von Vorteil sein, bei 7 % erneut eine Sammlung durchzuführen.
Erfassen Sie Statistiken in der Produktionsphase, nachdem Sie Benutzer erstellt und realistische Abfragelasten für die Datenbank ausgeführt haben (Abfragen von bis zu drei Monaten).
Erfassen Sie Statistiken in den ersten Wochen nach einem Upgrade oder einer Migration in Zeiträumen mit geringer CPU-Auslastung.
Die Netezza-Datenbank enthält viele Protokolltabellen im Datenwörterbuch, die Daten automatisch oder nach dem Aktivieren bestimmter Features sammeln. Da Protokolldaten im Laufe der Zeit an Umfang zunehmen, sollten Sie ältere Informationen löschen, damit sie nicht permanent Speicherplatz belegen. Zum Automatisieren der Verwaltung dieser Protokolle stehen verschiedene Optionen zur Verfügung.
Tipp
Automatisieren und überwachen Sie Housekeepingaufgaben in Azure.
Azure Synapse bietet eine Option zum automatischen Erstellen von Statistiken, sodass diese bei Bedarf verfügbar sind. Führen Sie die Defragmentierung von Indizes und Datenblöcken manuell, nach einem Zeitplan oder automatisch aus. Durch die Nutzung nativer integrierter Azure-Funktionen kann der erforderliche Aufwand für eine Migration reduziert werden.
Überwachung und Überprüfung
Tipp
Netezza Performance Portal ist die empfohlene Methode zur Überwachung und Protokollierung für Netezza-Systeme.
Netezza stellt Netezza Performance Portal zur Verfügung, um verschiedene Aspekte eines oder mehrerer Netezza-Systeme zu überwachen, einschließlich Aktivität, Leistung, Warteschlangenverwendung und Ressourcenauslastung. Netezza Performance Portal ist eine interaktive grafische Benutzeroberfläche, in der Benutzer für jedes Diagramm einen Drilldown zum Anzeigen von untergeordneten Details ausführen können.
Tipp
Das Azure-Portal bietet eine Benutzeroberfläche zum Verwalten von Überwachungs- und Überprüfungsaufgaben für alle Azure-Daten und -Prozesse.
Für Azure Synapse ist im Azure-Portal eine vergleichbare Benutzeroberfläche mit umfassenden Funktionen für die Überwachung verfügbar, die Erkenntnisse zur Arbeitsauslastung Ihres Data Warehouse liefert. Das Azure-Portal ist das empfohlene Tool zum Überwachen Ihrer Data Warehouse-Instanz, weil es eine konfigurierbare Aufbewahrungsdauer, Warnungen, Empfehlungen und anpassbare Diagramme und Dashboards für Metriken und Protokolle bietet.
Das Portal ermöglicht außerdem die Integration weiterer Azure-Überwachungsdienste – z.B. Operations Management Suite (OMS) und Azure Monitor (Protokolle) –, um Ihnen nicht nur für das Data Warehouse, sondern für die gesamte Azure-Analyseplattform eine ganzheitliche und integrierte Überwachungsoberfläche bereitzustellen.
Tipp
Metriken auf niedriger Ebene und systemweite Metriken werden in Azure Synapse automatisch protokolliert.
Statistiken zur Ressourcenverwendung für Azure Synapse werden automatisch im System protokolliert. Die Metriken für die einzelnen Abfragen enthalten Verwendungsstatistiken für CPU, Arbeitsspeicher, Cache, E/A und temporäre Arbeitsbereiche sowie Verbindungsinformationen (z. B. Fehler bei Verbindungsversuchen).
Azure Synapse bietet eine Reihe von dynamischen Verwaltungssichten (Dynamic Management View, DMV). Diese Sichten sind nützlich für die aktive Problembehandlung und das Identifizieren von Leistungsengpässen in Ihrer Workload.
Weitere Informationen finden Sie unter Optionen für Vorgänge und die Verwaltung in Azure Synapse.
Hochverfügbarkeit und Notfallwiederherstellung
Netezza-Appliances sind redundante, fehlertolerante Systeme, und es stehen in einem Netezza-System verschiedene Optionen zur Verfügung, um Hochverfügbarkeit und Notfallwiederherstellung zu ermöglichen.
Das Hinzufügen von IBM Netezza Replication Services für die Notfallwiederherstellung verbessert die Fehlertoleranz durch eine Ausweitung der Redundanz über lokale Netzwerke und Fernnetze hinweg.
IBM Netezza Replication Services schützt vor Datenverlusten durch die Synchronisierung von Daten auf einem Primärsystem (dem primären Knoten) mit Daten auf einem oder mehreren Zielknoten (untergeordneten Knoten). Diese Knoten bilden eine Replikationsgruppe.
High-Availability Linux (auch als Linux-HA bezeichnet) stellt die Failoverfunktionen eines primären oder aktiven Netezza-Hosts auf einem sekundären oder Standby-Netezza-Host bereit. Der wichtigste Daemon zur Clusterverwaltung in der Linux-HA-Lösung heißt Heartbeat. Heartbeat überwacht die Hosts und verwaltet die Kommunikations- und Statusüberprüfungen von Diensten.
Jeder Dienst ist eine Ressource.
Netezza gruppiert die Netezza-spezifischen Dienste in der nps-Ressourcengruppe. Wenn Heartbeat Probleme feststellt, die auf einen Ausfall des Hosts oder eine Dienstunterbrechung für die Netezza-Benutzer hindeuten, kann Heartbeat ein Failover auf den Standbyhost einleiten.
Distributed Replicated Block Device (DRBD) ist ein Blockgerätetreiber, der den Inhalt von Blockgeräten (Festplatten, Partitionen und logische Volumes) zwischen den Hosts spiegelt. Netezza verwendet die DRBD-Replikation nur auf den Partitionen /nz und /export/home. Wenn neue Daten auf die Partition /nz und die Partition /export/home auf dem primären Host geschrieben werden, nimmt die DRBD-Software automatisch dieselben Änderungen auf den Partitionen /nz und /export/home des Standbyhosts vor.
Tipp
Azure Synapse erstellt automatisch Momentaufnahmen, um eine schnelle Wiederherstellung sicherzustellen.
Azure Synapse verwendet Datenbankmomentaufnahmen, um die Hochverfügbarkeit des Data Warehouse zu gewährleisten. Mit einer Data Warehouse-Momentaufnahme wird ein Wiederherstellungspunkt erstellt, mit dessen Hilfe ein vorheriger Zustand eines Data Warehouse wiederhergestellt oder kopiert werden kann. Da Azure Synapse ein verteiltes System ist, besteht eine Data Warehouse-Momentaufnahme aus zahlreichen Dateien, die in Azure Storage gespeichert sind. Momentaufnahmen erfassen inkrementelle Änderungen der Daten, die in Ihrem Data Warehouse gespeichert sind.
Tipp
Verwenden Sie benutzerdefinierte Momentaufnahmen, um vor wichtigen Updates einen Wiederherstellungspunkt zu definieren.
Tipp
Für die Notfallwiederherstellung bietet Microsoft Azure automatische Sicherungen an einem separaten geografischen Standort.
Azure Synapse erstellt im Lauf des Tages automatisch Momentaufnahmen, und die generierten Wiederherstellungspunkte sind für sieben Tage verfügbar. Sie können diesen Aufbewahrungszeitraum nicht ändern. Azure Synapse unterstützt eine Recovery Point Objective (RPO) von acht Stunden. Ein Data Warehouse kann in der primären Region anhand einer beliebigen Momentaufnahme wiederhergestellt werden, die in den vergangenen sieben Tagen erstellt wurde.
Es werden auch benutzerdefinierte Wiederherstellungspunkte unterstützt, sodass Momentaufnahmen manuell ausgelöst werden können, um Wiederherstellungspunkte eines Data Warehouse vor und nach großen Änderungen zu erstellen. Diese Funktion gewährleistet die logische Konsistenz von Wiederherstellungspunkten und sorgt somit bei Workloadunterbrechungen oder Benutzerfehlern für zusätzlichen Datenschutz und die gewünschte RPO von weniger als 8 Stunden.
Zusätzlich zu den oben beschriebenen Momentaufnahmen führt Azure Synapse auch standardmäßig einmal pro Tag eine Geosicherung in einem gekoppelten Rechenzentrum aus. Die RPO für eine Geowiederherstellung beträgt 24 Stunden. Sie können die Geosicherung auf einem Server in einer beliebigen anderen Region wiederherstellen, in der Azure Synapse unterstützt wird. Durch eine Geosicherung wird gewährleistet, dass ein Data Warehouse wiederhergestellt werden kann, falls die Wiederherstellungspunkte in der primären Region nicht verfügbar sind.
Verwalten von Arbeitsauslastungen
Tipp
In einem Data Warehouse, das in der Produktion eingesetzt wird, gibt es in der Regel gemischte Workloads mit unterschiedlichen Ressourcenverwendungseigenschaften, die parallel ausgeführt werden.
Netezza bietet verschiedene Features zum Verwalten von Workloads:
| Verfahren | Beschreibung |
|---|---|
| Scheduler-Regeln | Scheduler-Regeln beeinflussen die Planung von Plänen. Jede Scheduler-Regel gibt eine Bedingung oder einen Satz von Bedingungen an. Jedes Mal, wenn der Scheduler einen Plan empfängt, wertet er alle modifizierenden Scheduler-Regeln aus und führt die entsprechenden Aktionen aus. Jedes Mal, wenn der Scheduler einen Plan zur Ausführung auswählt, wertet er alle einschränkenden Scheduler-Regeln aus. Der Plan wird nur dann ausgeführt, wenn dadurch kein Limit überschritten wird, das durch eine einschränkende Scheduler-Regel vorgegeben ist. Andernfalls wartet der Plan. Damit erhalten Sie die Möglichkeit, Pläne so zu klassifizieren und zu bearbeiten, dass sie die weiteren Verfahren zur Workloadverwaltung (SQB, GRA und PQE) beeinflussen. |
| Garantierte Ressourcenzuordnung (GRA) | Sie können Entitäten, den sogenannten Ressourcengruppen, einen Mindestanteil und einen maximalen Prozentsatz der gesamten Systemressourcen zuordnen. Der Scheduler sorgt dafür, dass jede Ressourcengruppe Systemressourcen im Verhältnis zu ihrem Mindestanteil erhält. Eine Ressourcengruppe erhält einen größeren Anteil an Ressourcen, wenn andere Ressourcengruppen sich im Leerlauf befinden, aber nie mehr als ihren konfigurierten maximalen Prozentsatz. Jeder Plan ist einer Ressourcengruppe zugeordnet und die Einstellungen dieser Ressourcengruppe bestimmen, welcher Anteil der verfügbaren Systemressourcen für die Bearbeitung des Plans zur Verfügung gestellt werden soll. |
| Short Query Bias (SQB) | Ressourcen (d. h. Zeitfenster, Speicher und bevorzugte Warteschlangen) werden für kurze Abfragen reserviert. Eine kurze Abfrage ist eine Abfrage, bei der die Kostenschätzung unter einem bestimmten Maximalwert liegt (der Standardwert beträgt zwei Sekunden). Mit SQB können kurze Abfragen auch dann ausgeführt werden, wenn das System mit der Bearbeitung anderer, längerer Abfragen beschäftigt ist. |
| Priorisierte Abfrageausführung (PQE) | Basierend auf den Einstellungen, die Sie konfigurieren, weist das System jeder Abfrage eine Priorität zu – kritisch, hoch, normal oder niedrig. Die Priorität hängt von Faktoren wie dem Benutzer, der Gruppe oder der Sitzung ab, die der Abfrage zugeordnet ist. Anschließend kann das System die Priorität als Grundlage für die Zuordnung von Ressourcen verwenden. |
Azure Synapse protokolliert automatisch Ressourcennutzungsstatistiken. Zu den Metriken gehören Nutzungsstatistiken für CPU, Arbeitsspeicher, Cache, E/A und temporären Arbeitsbereich für jede Abfrage. Azure Synapse protokolliert auch Verbindungsinformationen, z. B. fehlgeschlagene Verbindungsversuche.
Tipp
Low-Level- und systemweite Metriken werden automatisch in Azure protokolliert.
In Azure Synapse sind Ressourcenklassen vorab festgelegte Ressourcenlimits, die die Computeressourcen und die Parallelität bei der Abfrageausführung regeln. Ressourcenklassen können Sie bei der Verwaltung Ihrer Workload unterstützen, da sie es Ihnen ermöglichen, Limits für die Anzahl gleichzeitig ausgeführter Abfragen und für Computeressourcen festzulegen, die den einzelnen Abfragen zugewiesen werden. Dabei erfolgt ein Ausgleich zwischen Speicher und Parallelität.
Azure Synapse unterstützt diese grundlegenden Workloadverwaltungskonzepte:
Workloadklassifizierung: Sie können eine Anforderung einer Workloadgruppe zuweisen, um Wichtigkeitsstufen festzulegen.
Workloadpriorität: Sie können die Reihenfolge beeinflussen, in der eine Anforderung Zugriff auf Ressourcen erhält. Standardmäßig werden Abfragen nach dem First-In-First-Out-Prinzip aus der Warteschlange freigegeben, wenn Ressourcen verfügbar werden. Die Workloadpriorität ermöglicht es Abfragen mit höherer Priorität, Ressourcen unabhängig von der Warteschlange sofort zu erhalten.
Workloadisolation: Sie können Ressourcen für eine Workloadgruppe reservieren, eine maximale und minimale Nutzung für unterschiedliche Ressourcen zuweisen, die Ressourcen begrenzen, die eine Gruppe von Anforderungen verbrauchen kann, und einen Zeitüberschreitungswert festlegen, um außer Kontrolle geratene Abfragen automatisch zu beenden.
Das Ausführen gemischter Workloads kann bei ausgelasteten Systemen zu Ressourcenproblemen führen. Mit einem erfolgreichen Schema Workloadverwaltung werden Ressourcen effektiv verwaltet, wird eine hochgradig effiziente Ressourcennutzung sichergestellt und die Rendite (ROI) maximiert. Die Workloadklassifizierung, die Workloadpriorität und die Workloadisolation bieten mehr Kontrolle darüber, wie die Workload Systemressourcen nutzt.
Im Workload Management Guide (Handbuch zur Workloadverwaltung) werden die Techniken zur Analyse der Workload, der Verwaltung und Überwachung der Workloadpriorität](../../sql-data-warehouse/sql-data-warehouse-how-to-manage-and-monitor-workload-importance.md) sowie die Schritte zum Konvertieren einer Ressourcenklasse in eine Workloadgruppe beschrieben. Verwenden Sie das Azure-Portal und T-SQL-Abfragen auf DMVs, um die Workload zu überwachen und sicherzustellen, dass die entsprechenden Ressourcen effizient genutzt werden. Azure Synapse stellt eine Reihe von dynamischen Verwaltungssichten (Dynamic Management Views, DMVs) bereit, um alle Aspekte der Workloadverwaltung zu überwachen. Diese Sichten sind nützlich für die aktive Problembehandlung und die Identifizierung von Leistungsengpässen in Ihrer Workload.
Diese Informationen können auch für die Kapazitätsplanung herangezogen werden, um die erforderlichen Ressourcen für zusätzliche Benutzer oder Anwendungsworkloads zu ermitteln. Dies gilt auch für die Planung des Hoch- und Herunterskalierens von Computeressourcen, um Workloads mit Auslastungsspitzen kosteneffizient zu unterstützen, z. B. Workloads mit temporären, intensiven Aktivitätsspitzen zwischen Zeiten mit geringer Aktivität.
Weitere Informationen zur Workloadverwaltung in Azure Synapse finden Sie unter Workloadverwaltung mit Ressourcenklassen.
Skalieren von Computeressourcen
Tipp
Ein großer Vorteil von Azure ist die Möglichkeit, Ressourcen nach Bedarf separat hoch- und herunterzuskalieren, um die Kosten für Workloads mit Auslastungsspitzen zu optimieren.
In der Architektur von Azure Synapse sind Speicher- und Computeressourcen voneinander getrennt, sodass sie unabhängig voneinander skaliert werden können. Dies ermöglicht die Skalierung von Computeressourcen, um Leistungsanforderungen unabhängig vom Datenspeicher zu erfüllen. Sie können Computeressourcen auch anhalten und fortsetzen. Ein logischer Vorteil dieser Architektur ist die separate Abrechnung für Compute- und Speicherressourcen. Wenn ein Data Warehouse nicht verwendet wird, können Sie Computekosten sparen, indem Sie Computeressourcen anhalten.
Computeressourcen können durch Anpassen der Einstellung für die Data Warehouse-Einheiten des Data Warehouse hoch- oder herunterskaliert werden. Die Lade- und Abfrageleistung nimmt linear zu, wenn Sie Data Warehouse-Einheiten hinzufügen.
Durch das Hinzufügen weiterer Computeknoten werden die Computeleistung und die Möglichkeiten zur Nutzung der Parallelverarbeitung erhöht. Mit zunehmender Anzahl von Computeknoten verringert sich die Anzahl von Verteilungen pro Computeknoten, sodass für Abfragen mehr Computeleistung und mehr Kapazität für die Parallelverarbeitung verfügbar ist. Entsprechend sinkt bei einer Verringerung der Data Warehouse-Einheiten die Anzahl von Computeknoten und in der Folge die Menge an Computeressourcen für Abfragen.
Nächste Schritte
Weitere Informationen zur Visualisierung und Berichterstellung finden Sie im nächsten Artikel dieser Reihe: Visualisierung und Berichterstellung für Netezza-Migrationen