Tutorial: Textanalyse mit Azure KI Services
In diesem Tutorial erfahren Sie, wie Sie die Textanalyse verwenden, um unstrukturierten Text mithilfe von Azure Synapse Analytics zu analysieren. Die Textanalyse ist ein Azure KI Services-Dienst, mit dem Sie Textmining und Textanalysen mit NLP-Features (Natural Language Processing, Verarbeitung natürlicher Sprache) durchführen können.
Dieses Tutorial veranschaulicht die Verwendung der Textanalyse mit SynapseML für Folgendes:
- Erkennen von Stimmungsbezeichnungen auf Satz- oder Dokumentebene
- Identifizieren der Sprache für eine bestimmte Texteingabe
- Erkennen von Entitäten in einem Text mit Links zu einer bekannten Wissensdatenbank
- Extrahieren von Schlüsselbegriffen aus Text
- Identifizieren verschiedener Entitäten im Text und Kategorisieren dieser in vordefinierte Klassen oder Typen
- Identifizieren und Ändern vertraulicher Entitäten in einem bestimmten Text
Wenn Sie kein Azure-Abonnement besitzen, können Sie ein kostenloses Konto erstellen, bevor Sie beginnen.
Voraussetzungen
- Azure Synapse Analytics-Arbeitsbereich mit einem als Standardspeicher konfigurierten Azure Data Lake Storage Gen2-Speicherkonto. Für das hier verwendete Data Lake Storage Gen2-Dateisystem müssen Sie über die Rolle Mitwirkender an Storage-Blobdaten verfügen.
- Spark-Pool in Ihrem Azure Synapse Analytics-Arbeitsbereich. Ausführliche Informationen finden Sie unter Erstellen eines Spark-Pools in Azure Synapse.
- Die Vorkonfigurationsschritte sind im Tutorial Konfigurieren von Azure KI Services in Azure Synapse beschrieben.
Erste Schritte
Öffnen Sie Synapse Studio, und erstellen Sie ein neues Notebook. Importieren Sie zunächst SynapseML.
import synapse.ml
from synapse.ml.services import *
from pyspark.sql.functions import col
Konfigurieren der Textanalyse
Verwenden Sie die verknüpfte Textanalyse, die Sie in den Vorbereitungsschritten konfiguriert haben.
linked_service_name = "<Your linked service for text analytics>"
Stimmung in Text
Die Stimmungsanalyse von Texten bietet eine Möglichkeit, Stimmungsbezeichnungen (z. B. „negativ“, „neutral“ und „positiv“) und Konfidenzbewertungen auf Satz- und Dokumentebene zu erkennen. Eine Liste der unterstützten Sprachen finden Sie unter Unterstützte Sprachen in der Textanalyse-API.
# Create a dataframe that's tied to it's column names
df = spark.createDataFrame([
("I am so happy today, it's sunny!", "en-US"),
("I am frustrated by this rush hour traffic", "en-US"),
("The Azure AI services on spark aint bad", "en-US"),
], ["text", "language"])
# Run the Text Analytics service with options
sentiment = (TextSentiment()
.setLinkedService(linked_service_name)
.setTextCol("text")
.setOutputCol("sentiment")
.setErrorCol("error")
.setLanguageCol("language"))
# Show the results of your text query in a table format
results = sentiment.transform(df)
display(results
.withColumn("sentiment", col("sentiment").getItem("document").getItem("sentences")[0].getItem("sentiment"))
.select("text", "sentiment"))
Erwartete Ergebnisse
| text | Stimmung |
|---|---|
| Ich bin heute so glücklich, die Sonne scheint! | Positiv |
| Ich bin frustriert über diesen Berufsverkehr. | Negativ |
| Azure KI Services in Spark sind gar nicht schlecht | Neutral |
Spracherkennung
Die Sprachenerkennung wertet Texteingaben aus und gibt für jedes Dokument Sprachen-IDs mit einer Bewertung zurück, die die Stärke der Analyse angibt. Diese Funktion ist hilfreich für Inhaltsspeicher, die willkürliche Texte mit unbekannter Sprache sammeln. Eine Liste der unterstützten Sprachen finden Sie unter Unterstützte Sprachen in der Textanalyse-API.
# Create a dataframe that's tied to it's column names
df = spark.createDataFrame([
("Hello World",),
("Bonjour tout le monde",),
("La carretera estaba atascada. Había mucho tráfico el día de ayer.",),
("你好",),
("こんにちは",),
(":) :( :D",)
], ["text",])
# Run the Text Analytics service with options
language = (LanguageDetector()
.setLinkedService(linked_service_name)
.setTextCol("text")
.setOutputCol("language")
.setErrorCol("error"))
# Show the results of your text query in a table format
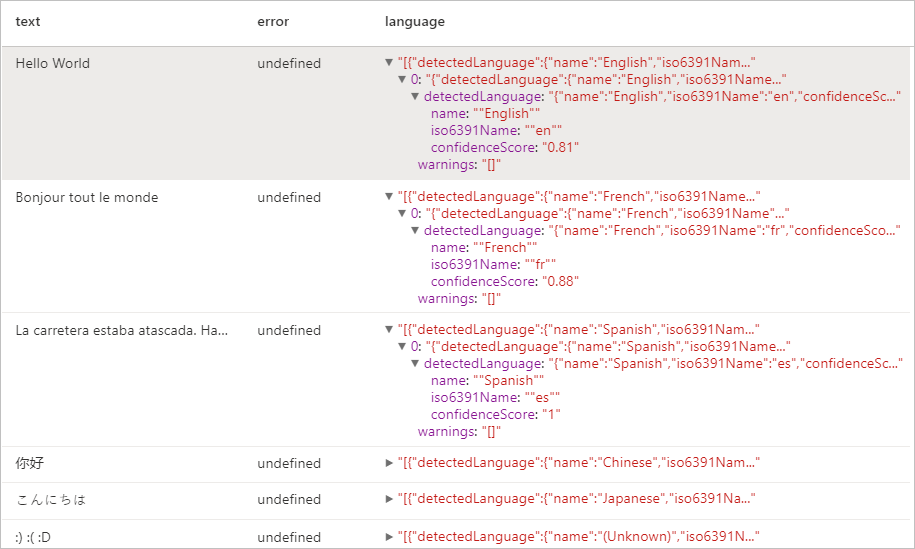
display(language.transform(df))
Erwartete Ergebnisse
Entitätserkennung
Die Entitätserkennung gibt eine Liste der erkannten Entitäten mit Links zu einer bekannten Wissensdatenbank zurück. Eine Liste der unterstützten Sprachen finden Sie unter Unterstützte Sprachen in der Textanalyse-API.
df = spark.createDataFrame([
("1", "Microsoft released Windows 10"),
("2", "In 1975, Bill Gates III and Paul Allen founded the company.")
], ["if", "text"])
entity = (EntityDetector()
.setLinkedService(linked_service_name)
.setLanguage("en")
.setOutputCol("replies")
.setErrorCol("error"))
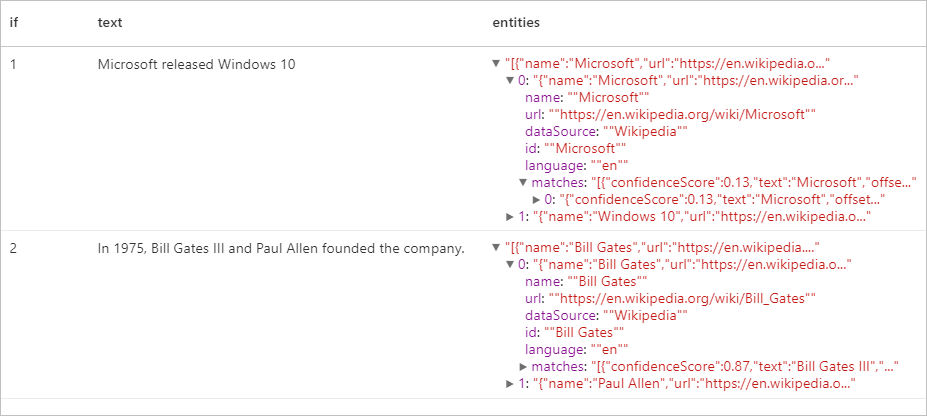
display(entity.transform(df).select("if", "text", col("replies").getItem("document").getItem("entities").alias("entities")))
Erwartete Ergebnisse
Schlüsselbegriffserkennung
Die Schlüsselbegriffserkennung bewertet unstrukturierten Text und gibt eine Liste mit Schlüsselbegriffen zurück. Diese Funktion ist nützlich, wenn Sie die wichtigsten Punkte in einer Sammlung von Dokumenten schnell identifizieren müssen. Eine Liste der unterstützten Sprachen finden Sie unter Unterstützte Sprachen in der Textanalyse-API.
df = spark.createDataFrame([
("en", "Hello world. This is some input text that I love."),
("fr", "Bonjour tout le monde"),
("es", "La carretera estaba atascada. Había mucho tráfico el día de ayer.")
], ["lang", "text"])
keyPhrase = (KeyPhraseExtractor()
.setLinkedService(linked_service_name)
.setLanguageCol("lang")
.setOutputCol("replies")
.setErrorCol("error"))
display(keyPhrase.transform(df).select("text", col("replies").getItem("document").getItem("keyPhrases").alias("keyPhrases")))
Erwartete Ergebnisse
| text | keyPhrases |
|---|---|
| Hello World. This is some input text that I love. | "["Hello world","input text"]" |
| Bonjour tout le monde | "["Bonjour","monde"]" |
| La carretera estaba atascada. Había mucho tráfico el día de ayer. | "["mucho tráfico","día","carretera","ayer"]" |
Erkennung benannter Entitäten (NER)
NER (Named Entity Recognition) ist die Möglichkeit, unterschiedliche Entitäten im Text zu identifizieren und sie in vordefinierte Klassen oder Typen zu kategorisieren wie z. B.: „Person“, „Standort“, „Ereignis“, „Produkt“ und „Organisation“. Eine Liste der unterstützten Sprachen finden Sie unter Unterstützte Sprachen in der Textanalyse-API.
df = spark.createDataFrame([
("1", "en", "I had a wonderful trip to Seattle last week."),
("2", "en", "I visited Space Needle 2 times.")
], ["id", "language", "text"])
ner = (NER()
.setLinkedService(linked_service_name)
.setLanguageCol("language")
.setOutputCol("replies")
.setErrorCol("error"))
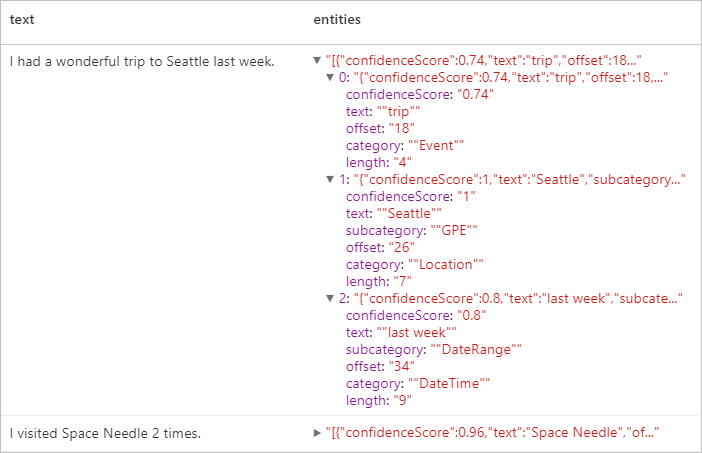
display(ner.transform(df).select("text", col("replies").getItem("document").getItem("entities").alias("entities")))
Erwartete Ergebnisse
Personenbezogene Informationen (Personally Identifiable Information, PII v3.1)
Das Feature PII ist ein Bestandteil von NER und kann vertrauliche Entitäten in Text identifizieren und bearbeiten, die einer einzelnen Person zugeordnet sind, wie z. B.: Telefonnummer, E-Mail-Adresse, Postanschrift, Reisepassnummer. Eine Liste der unterstützten Sprachen finden Sie unter Unterstützte Sprachen in der Textanalyse-API.
df = spark.createDataFrame([
("1", "en", "My SSN is 859-98-0987"),
("2", "en", "Your ABA number - 111000025 - is the first 9 digits in the lower left hand corner of your personal check."),
("3", "en", "Is 998.214.865-68 your Brazilian CPF number?")
], ["id", "language", "text"])
pii = (PII()
.setLinkedService(linked_service_name)
.setLanguageCol("language")
.setOutputCol("replies")
.setErrorCol("error"))
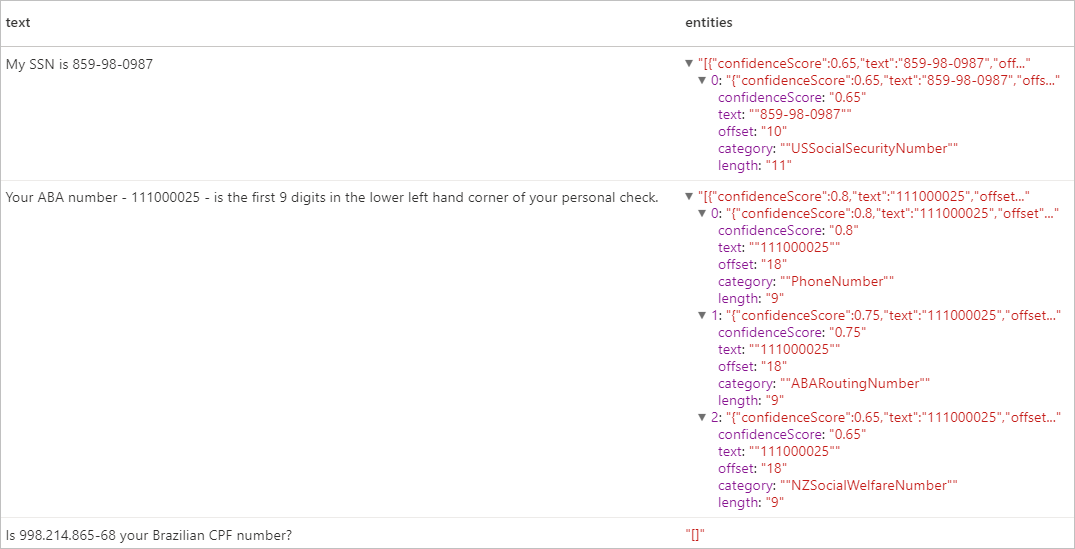
display(pii.transform(df).select("text", col("replies").getItem("document").getItem("entities").alias("entities")))
Erwartete Ergebnisse
Bereinigen von Ressourcen
Beenden Sie alle verbundenen Sitzungen (Notebooks), um sicherzustellen, dass die Spark-Instanz heruntergefahren wird. Der Pool wird heruntergefahren, wenn die im Apache Spark-Pool angegebene Leerlaufzeit erreicht wird. Sie können auch auf der Statusleiste am oberen Rand des Notebooks die Option Sitzung beenden auswählen.
