Anomalieerkennung in Azure Stream Analytics
Azure Stream Analytics ist sowohl in der Cloud als auch in Azure IoT Edge verfügbar und bietet integrierte Anomalieerkennungsfunktionen auf Machine Learning-Basis, die zum Überwachen der beiden am häufigsten auftretenden Anomalien verwendet werden können: temporäre und permanente. Mit den Funktionen AnomalyDetection_SpikeAndDip und AnomalyDetection_ChangePoint können Sie die Erkennung von Anomalien direkt in Ihrem Stream Analytics-Auftrag ausführen.
Die Machine Learning-Modelle setzen einheitlich als Stichprobe entnommene Zeitreihen voraus. Wenn die Zeitreihe nicht einheitlich ist, können Sie vor dem Aufrufen der Anomalieerkennung einen Aggregationsschritt mit einem Stürzenfenster einfügen.
Die Machine Learning-Vorgänge unterstützen derzeit keine saisonalen Trends oder Korrelationen mit mehreren Varianten.
Anomalieerkennung unter Verwendung von Machine Learning in Azure Stream Analytics
Das folgende Video veranschaulicht, wie eine Anomalie in Echtzeit mithilfe von Machine Learning-Funktionen in Azure Stream Analytics erkannt wird.
Modellverhalten
In der Regel wird die Genauigkeit des Modells besser, je mehr Daten das gleitende Fenster enthält. Die Daten im angegebenen gleitenden Fenster werden als Teil des normalen Wertebereichs für diesen Zeitrahmen behandelt. Das Modell berücksichtigt nur den Ereignisverlauf im gleitenden Fenster, um zu überprüfen, ob das aktuelle Ereignis anomal ist. Wenn das gleitende Fenster verschoben wird, werden die alten Werte des Trainings des Modells entfernt.
Die Funktionen legen basierend auf dem bisher Beobachteten einen bestimmten Normalwert fest. Ausreißer werden durch Vergleich mit dem festgelegten Normalwert innerhalb des Zuverlässigkeitsgrads identifiziert. Die Größe des Fensters sollte auf der Anzahl von Ereignissen basieren, die mindestens erforderlich sind, um das Modell für das normale Verhalten zu trainieren, sodass es eine Anomalie erkennen kann, sobald sie auftritt.
Die Antwortzeit des Modells nimmt mit der Größe des Verlaufs zu, da eine höhere Anzahl vergangener Ereignisse verglichen werden muss. Es wird empfohlen, nur die erforderliche Anzahl von Ereignissen für eine bessere Leistung einzubeziehen.
Lücken in der Zeitreihe können darauf zurückzuführen sein, dass das Modell zu bestimmten Zeitpunkten keine Ereignisse empfangen hat. Diese Situation wird von Stream Analytics mit Annahmelogik behandelt. Für das gleiche gleitende Fenster wird die Größe des Verlaufs ebenso wie die Dauer zum Berechnen der durchschnittlichen Rate verwendet, mit der Ereignisse auftreten.
Mit einem hier verfügbaren Anomalie-Generator können Sie für einen IoT-Hub Daten mit verschiedenen Anomaliemustern bereitstellen. Ein Azure Stream Analytics-Auftrag kann mit diesen Anomalieerkennungsfunktionen eingerichtet werden, um aus diesem Iot Hub zu lesen und Anomalien zu erkennen.
Spitzen und Senken
Temporäre Anomalien im Ereignisdatenstrom einer Zeitreihe werden als Spitzen und Senken bezeichnet. Spitzen und Senken können mithilfe des auf Machine Learning basierenden AnomalyDetection_SpikeAndDip-Operators überwacht werden.
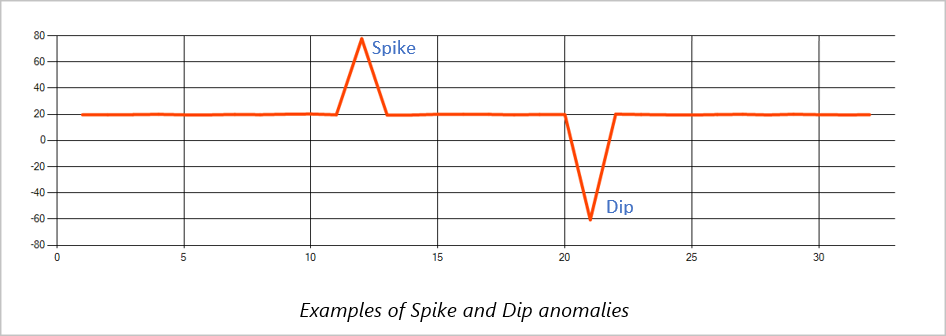
Wenn im gleichen gleitenden Fenster eine zweite Spitze kleiner ist als die erste, ist das berechnete Ergebnis für die kleinere Spitze wahrscheinlich nicht signifikant genug im Vergleich zum Ergebnis für die erste Spitze innerhalb des angegebenen Zuverlässigkeitsgrads. Sie können den Zuverlässigkeitsgrad des Modells verringern, um solche Anomalien zu erkennen. Sollten Sie jedoch zu viele Warnungen erhalten, können Sie ein höheres Konfidenzintervall verwenden.
Die folgende Beispielabfrage setzt eine einheitliche Eingangsrate von einem Ereignis pro Sekunde in einem zweiminütigen gleitenden Fenster mit einer Verlaufsgröße von 120 Ereignissen voraus. Mit einem Zuverlässigkeitsgrad von 95% extrahiert die letzte SELECT-Anweisung Ergebnis und Anomalienstatus und gibt sie aus.
WITH AnomalyDetectionStep AS
(
SELECT
EVENTENQUEUEDUTCTIME AS time,
CAST(temperature AS float) AS temp,
AnomalyDetection_SpikeAndDip(CAST(temperature AS float), 95, 120, 'spikesanddips')
OVER(LIMIT DURATION(second, 120)) AS SpikeAndDipScores
FROM input
)
SELECT
time,
temp,
CAST(GetRecordPropertyValue(SpikeAndDipScores, 'Score') AS float) AS
SpikeAndDipScore,
CAST(GetRecordPropertyValue(SpikeAndDipScores, 'IsAnomaly') AS bigint) AS
IsSpikeAndDipAnomaly
INTO output
FROM AnomalyDetectionStep
Änderungspunkt
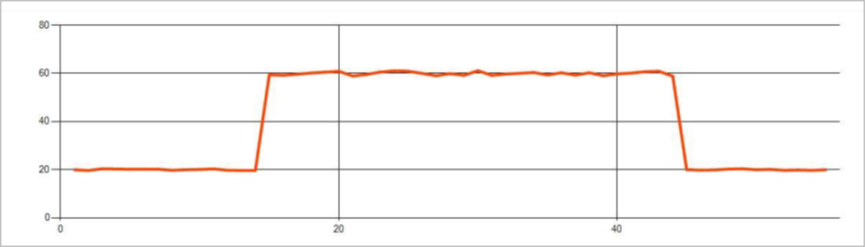
Permanente Anomalien im Ereignisdatenstrom einer Zeitreihe sind Änderungen bei der Verteilung der Werte im Ereignisdatenstrom, wie Änderungen des Zuverlässigkeitsgrads und Trends. In Stream Analytics werden diese Anomalien mithilfe des auf Machine Learning basierenden AnomalyDetection_ChangePoint-Operators erkannt.
Anhaltende Veränderungen dauern viel länger als Spitzen und Dips und könnten katastrophale Ereignisse zeigen. Permanente Änderungen sind in der Regel mit bloßem Auge nicht sichtbar, können aber mit dem AnomalyDetection_ChangePoint-Operator erkannt werden.
Die folgende Abbildung ist ein Beispiel für die Änderung des Zuverlässigkeitsgrads:
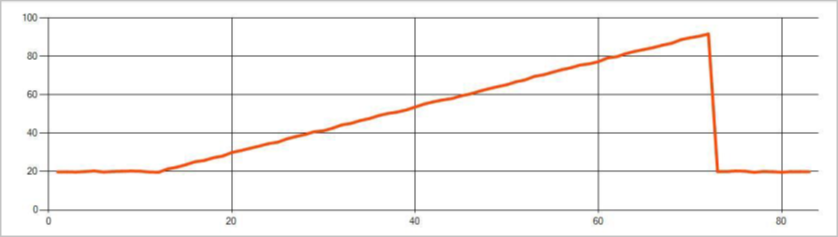
Die folgende Abbildung ist ein Beispiel für eine Trendänderung:
Die folgende Beispielabfrage geht von einer einheitlichen Eingaberate eines Ereignisses pro Sekunde in einem 20-minütigen Gleitfenster mit einer Verlaufsgröße von 1.200 Ereignissen aus. Mit einem Zuverlässigkeitsgrad von 80% extrahiert die letzte SELECT-Anweisung Ergebnis und Anomalienstatus und gibt sie aus.
WITH AnomalyDetectionStep AS
(
SELECT
EVENTENQUEUEDUTCTIME AS time,
CAST(temperature AS float) AS temp,
AnomalyDetection_ChangePoint(CAST(temperature AS float), 80, 1200)
OVER(LIMIT DURATION(minute, 20)) AS ChangePointScores
FROM input
)
SELECT
time,
temp,
CAST(GetRecordPropertyValue(ChangePointScores, 'Score') AS float) AS
ChangePointScore,
CAST(GetRecordPropertyValue(ChangePointScores, 'IsAnomaly') AS bigint) AS
IsChangePointAnomaly
INTO output
FROM AnomalyDetectionStep
Leistungsmerkmale
Die Leistungsfähigkeit dieser Modelle hängt von der Verlaufsgröße, der Fensterdauer, der Ereignislast und davon ab, ob die Partitionierung auf Funktionsebene verwendet wird. In diesem Abschnitt werden diese Konfigurationen erläutert und Beispiele für die Erhaltung der Aufnahmeraten von 1 K-, 5-K- und 10K-Ereignissen pro Sekunde bereitgestellt.
- Verlaufsgröße – Die Modellleistung verhält sich linear zur Verlaufsgröße. Je länger die Verlaufsgröße, umso mehr Zeit benötigen die Modelle, um ein neues Ereignis zu bewerten. Dies liegt daran, dass die Modelle das neue Ereignis mit jedem der vergangenen Ereignisse im Verlaufspuffer vergleichen.
- Fensterdauer – Die Fensterdauer sollte widerspiegeln, wie lange die Erfassung der Anzahl von Ereignissen dauert, die durch die Verlaufsgröße angegeben ist. Wenn diese Anzahl von Ereignisse im Fenster nicht erreicht wird, werden die fehlenden Werte von Azure Stream Analytics vervollständigt. Daher besteht eine direkte Beziehung zwischen der CPU-Auslastung und der Verlaufsgröße.
- Ereignislast – Je größer die Ereignislast, desto mehr Arbeit müssen die Modelle leisten, was sich wiederum auf die CPU-Auslastung auswirkt. Der Auftrag kann durch eine extreme Parallelverarbeitung horizontal skaliert werden. Dabei muss die Verwendung zusätzlicher Eingabepartitionen für die Geschäftslogik jedoch sinnvoll sein.
- Bei der Partitionierung auf Funktionsebene - Partitionierung auf Funktionsebene wird
PARTITION BYinnerhalb des Funktionsaufrufs der Anomalieerkennung verwendet. Durch diese Partitionierung entsteht ein Mehraufwand, da der Zustand für mehrere Modelle gleichzeitig aufrechterhalten werden muss. Die Partitionierung auf Funktionsebene wird in Szenarien wie der Partitionierung auf Geräteebene verwendet.
Relationship
Zwischen der Verlaufsgröße, der Fensterdauer und der Gesamtereignislast besteht folgende Beziehung:
windowDuration (in ms) = 1000 · historySize/(Eingabeereignisse gesamt [s]/Anzahl der Eingabepartitionen)
Wenn Sie die Funktion nach „deviceId“ partitionieren, fügen Sie dem Funktionsaufruf der Anomalieerkennung „PARTITION BY deviceId“ hinzu.
Beobachtungen
Die folgende Tabelle enthält die Durchsatzbeobachtungen für einen einzelnen Knoten (sechs SU) für den nicht partitionierten Fall:
| Verlaufsgröße (Ereignisse) | Fensterdauer (ms) | Eingabeereignisse gesamt/s |
|---|---|---|
| 60 | 55 | 2\.200 |
| 600 | 728 | 1.650 |
| 6\.000 | 10.910 | 1.100 |
Die folgende Tabelle enthält die Durchsatzbeobachtungen für einen einzelnen Knoten (sechs SU) für den partitionierten Fall:
| Verlaufsgröße (Ereignisse) | Fensterdauer (ms) | Eingabeereignisse gesamt/s | Geräteanzahl |
|---|---|---|---|
| 60 | 1.091 | 1.100 | 10 |
| 600 | 10.910 | 1.100 | 10 |
| 6\.000 | 218.182 | <550 | 10 |
| 60 | 21.819 | 550 | 100 |
| 600 | 218.182 | 550 | 100 |
| 6\.000 | 2.181.819 | <550 | 100 |
Beispielcode zum Ausführen der oben angegebenen nicht partitionierten Konfigurationen befindet sich im Repository "Streaming at Scale " von Azure Samples. Im Code wird ein Stream Analytics-Auftrag ohne Partitionierung auf Funktionsebene erstellt. Die Ein- und Ausgabe erfolgt über Event Hubs. Die Eingabelast wird mithilfe von Testclients generiert. Jedes Eingabeereignis ist ein 1 KB JSON-Dokument. Ereignisse simulieren ein IoT-Gerät, das JSON-Daten sendet (für bis zu 1 K-Geräte). Die Verlaufsgröße, die Fensterdauer und die gesamter Ereignisladevorgang sind über zwei Eingabepartitionen unterschiedlich.
Hinweis
Um eine genauere Schätzung zu erhalten, passen Sie die Beispiele an Ihr Szenario an.
Identifizieren von Engpässen
Um Engpässe in Ihrer Pipeline zu identifizieren, verwenden Sie den Bereich "Metriken" in Ihrem Azure Stream Analytics-Auftrag. Überprüfen Sie Eingabe-/Ausgabeereignisse hinsichtlich des Durchsatzes sowie "Wasserzeichenverzögerung" oder Ereignisse im Rückstand, um festzustellen, ob der Auftrag mit der Eingangsrate Schritt halten kann. Suchen Sie bei Event Hubs-Metriken nach Gedrosselte Anforderungen, und passen Sie die Schwellenwerteinheiten entsprechend an. Überprüfen Sie für Azure Cosmos DB-Metriken Max. genutzte RU/Sek. pro Partitionsschlüsselbereich unter „Durchsatz“, um sicherzustellen, dass Ihre Partitionsschlüsselbereiche gleichmäßig genutzt werden. Überwachen Sie für Azure SQL-DB Protokoll-E/A und CPU.