Modellieren von Beziehungen
In diesem Artikel wird der Modellierungsprozess erörtert, um Sie beim Entwerfen Ihrer Azure Table Storage-Lösungen zu unterstützen.
Erstellen von Domänenmodellen ist ein wichtiger Schritt bei der Entwicklung komplexer Systeme. In der Regel verwenden Sie den Modellierungsprozess, um Entitäten und die Beziehungen zwischen diesen als Möglichkeit zum Verständnis der Geschäftsdomäne und zur Information für den Entwurf Ihres Systems zu identifizieren. Dieser Abschnitt konzentriert sich darauf, wie Sie einige der allgemeinen Beziehungstypen, die in Domänenmodellen als Entwurf für den Tabellenspeicherdienst zu finden sind, übersetzen können. Der Zuordnungsprozess von einem logischen Datenmodell zu einem physischen NoSQL-basierten Datenmodell unterscheidet sich von dem Prozess, der zum Entwerfen einer relationalen Datenbank verwendet wird. Der Entwurf von relationalen Datenbanken setzt einen Daten-Normalisierungsprozess voraus, optimiert auf Minimierung der Redundanz, sowie eine deklarative Abfragefunktionen, die abstrahiert, wie die Implementierung für die Datenbank funktioniert.
1:n-Beziehungen
1:n-Beziehungen zwischen Objekten einer Geschäftsdomäne kommen häufig vor. Beispiel: Eine Abteilung hat viele Mitarbeiter. Es gibt mehrere Möglichkeiten der Implementierung von 1:n-Beziehungen im Tabellenspeicherdienst, jede davon mit Vor-und Nachteilen, die für bestimmte Szenarien von Bedeutung sein können.
Betrachten Sie das Beispiel eines großen multinationalen/überregionalen Unternehmens mit Zehntausenden Entitäten an Abteilungen und Mitarbeitern, in denen jede Abteilung viele Mitarbeiter und jeder Mitarbeiter einer bestimmte Abteilung zugeordnet ist. Ein Ansatz besteht darin, separate Abteilungs- und Mitarbeiterentitäten wie folgt zu speichern:
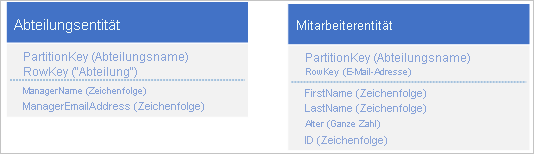
Dieses Beispiel zeigt eine implizite 1:n-Beziehung zwischen den Typen, die auf dem PartitionKey -Wert basieren. Jede Abteilung kann viele Mitarbeiter beinhalten.
Dieses Beispiel zeigt auch die Abteilungsentität und die zugehörigen Mitarbeiterentitäten in derselben Partition. Sie können verschiedene Partitionen, Tabellen oder sogar Speicherkonten für verschiedene Entitätstypen auswählen.
Ein alternativer Ansatz ist, die Daten zu denormalisieren und nur Mitarbeiterentitäten mit denormalisierten Abteilungsdaten zu speichern, wie im folgenden Beispiel gezeigt. In diesem speziellen Szenario ist der Denormalisierungsansatz möglicherweise nicht der beste Ansatz, falls eine Anforderung besteht, die Details eines Abteilungsmanagers ändern zu müssen. Um dies durchführen zu können, müssen Sie jeden Mitarbeiter in der Abteilung aktualisieren.
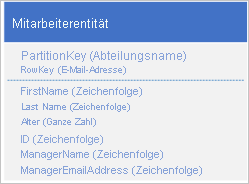
Weitere Informationen finden Sie unter Denormalisierungsmuster weiter unten in diesem Handbuch.
In der folgenden Tabelle werden die Vor- und Nachteile der oben genannten einzelnen Ansätze zum Speichern der Entitäten für Mitarbeiter und Abteilung zusammengefasst, die eine 1:n-Beziehung haben. Sie sollten auch berücksichtigen, wie oft verschiedene Vorgänge ausgeführt werden sollen. Es ist möglicherweise akzeptabel, einen Entwurf zu haben, der einen teuren Vorgang beinhaltet, wenn dieser Vorgang nur selten vorkommt.
| Vorgehensweise | Vorteile | Nachteile |
|---|---|---|
| Getrennte Entitätstypen, dieselbe Partition, dieselbe Tabelle |
|
|
| Separate Entitätstypen, verschiedene Partitionen oder Tabellen oder Speicherkonten |
|
|
| Denormalisieren in einen einzelnen Entitätstyp |
|
|
*Weitere Informationen finden Sie unter Entitätsgruppentransaktionen.
Wie Sie zwischen diesen Optionen wählen und welche Vor- und Nachteile am wichtigsten sind, hängt von Ihren speziellen Anwendungsszenarien ab. Beispiele: Wie oft ändern Sie Abteilungsentitäten? Benötigen alle Abfragen für Mitarbeiter die Zusatzinformationen für die Abteilung? Wie nahe liegen Sie an den Skalierbarkeitsgrenzen auf Ihren Partitionen oder Ihrem Speicherkonto?
1:1-Beziehungen
Domänenmodelle können 1:1-Beziehungen zwischen Entitäten enthalten. Müssen Sie eine 1:1-Beziehung in den Tabellenspeicherdienst implementieren, müssen Sie auch auswählen, wie zwei verknüpfte Entitäten verknüpft werden, wenn sie beide abrufen müssen. Diese Verknüpfung kann entweder implizit sein, basierend auf einer Konvention in den Schlüsselwerten, oder explizit durch das Speichern einer Verknüpfung in Form von PartitionKey- und RowKey-Werten in den einzelnen Entitäten zur verknüpften Entität. Überlegungen dazu, ob die verknüpften Entitäten in derselben Partition gespeichert werden sollten, finden Sie im Abschnitt 1:n-Beziehungen.
Es gibt auch Implementierungsaspekte, die Sie veranlassen könnten, im Tabellenspeicherdienst 1:1-Beziehungen zu implementieren:
- Behandlung großer Entitäten (weitere Informationen finden Sie unter Muster für große Entitäten).
- Implementieren von Zugriffssteuerungen (weitere Informationen finden Sie unter „Steuern des Zugriffs mit Shared Access Signatures“).
Verbinden des Clients
Es gibt zwar Möglichkeiten zum Modellieren von Beziehungen im Tabellenspeicherdienst, Sie sollten aber nicht vergessen, dass die zwei wichtigsten Gründe für die Benutzung des Tabellenspeicherdienstes Skalierbarkeit und Leistung sind. Wenn Sie feststellen, dass Sie viele Beziehungen modellieren, die die Leistung und Skalierbarkeit Ihrer Lösung beeinträchtigen, sollten Sie sich fragen, ob Sie unbedingt alle Datenbeziehungen in Ihren Tabellenentwurf einbeziehen müssen. Sie können möglicherweise den Entwurf vereinfachen und die Skalierbarkeit und Leistung Ihrer Lösung verbessern, wenn Sie Ihre Client-Anwendung alle erforderlichen Verknüpfungen ausführen lassen.
Wenn Sie beispielsweise kleine Tabellen verwenden, die Daten enthalten, die nicht oft geändert werden, dann können Sie diese Daten einmal abrufen und auf dem Client zwischenspeichern. Dies kann wiederholte Roundtrips zum Abrufen derselben Daten vermeiden. In den Beispielen, die wir in diesem Handbuch vorgestellt haben, wird der Satz von Abteilungen in einem kleinen Unternehmen wahrscheinlich klein sein und sich selten ändern. Dadurch wird es zu einem guten Kandidaten für Daten, welche die Clientanwendung einmal herunterladen und als Suchdaten zwischenspeichern kann.
Vererbungsbeziehungen
Wenn die Clientanwendung einen Satz Klassen verwendet, die Teil einer Vererbungsbeziehung zur Darstellung von Geschäftsentitäten sind, können Sie problemlos die Entitäten im Tabellenspeicherdienst beibehalten. Beispiel: Sie haben möglicherweise den folgenden Satz Klassen in Ihrer Clientanwendung definiert, wobei Person eine abstrakte Klasse ist.
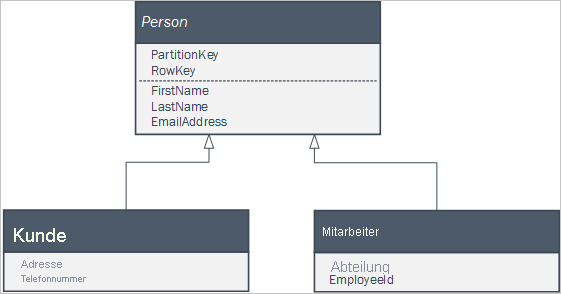
Sie können Instanzen der zwei konkreten Klassen im Tabellenspeicherdienst beibehalten, indem Sie eine einzelne Personentabelle mit Entitäten verwenden, die wie folgt aussieht:

Weitere Informationen zum Arbeiten mit mehreren Entitätstypen in derselben Tabelle im Clientcode finden Sie im Abschnitt Arbeiten mit heterogenen Entitätstypen weiter unten in diesem Handbuch. Hier finden Sie Beispiele darüber, wie der Entitätstyp im Clientcode erkannt wird.