Optimieren der Leistung von Dateifreigaben beim Zugriff auf große Verzeichnisse von Linux-Clients
Dieser Artikel enthält Empfehlungen für das Arbeiten mit Verzeichnissen, die eine große Anzahl von Dateien enthalten. In der Regel empfiehlt es sich, die Anzahl der Dateien in einem einzelnen Verzeichnis zu reduzieren, indem die Dateien über mehrere Verzeichnisse verteilt werden. Es gibt jedoch Situationen, in denen große Verzeichnisse nicht vermieden werden können. Beachten Sie die folgenden Vorschläge beim Arbeiten mit großen Verzeichnissen in Azure-Dateifreigaben, die auf Linux-Clients bereitgestellt werden.
Gilt für:
| Dateifreigabetyp | SMB | NFS |
|---|---|---|
| Standard-Dateifreigaben (GPv2), LRS/ZRS |
|
|
| Standard-Dateifreigaben (GPv2), GRS/GZRS |
|
|
| Premium-Dateifreigaben (FileStorage), LRS/ZRS |
|
|
Empfohlene Bereitstellungsoptionen
Die folgenden Bereitstellungsoptionen sind spezifisch für die Enumeration und können die Latenz beim Arbeiten mit großen Verzeichnissen verringern.
actimeo
Wenn Sie actimeo festlegen, werden die Optionen acregmin, acregmax, acdirmin und acdirmax alle auf denselben Wert festgelegt. Wenn actimeo nicht angegeben ist, verwendet der Client die Standardwerte für jede dieser Optionen.
Es wird empfohlen, beim Arbeiten mit großen Verzeichnissen actimeo zwischen 30 und 60 Sekunden festzulegen. Wenn Sie einen Wert in diesem Bereich festlegen, bleiben die Attribute für einen längeren Zeitraum im Attributcache des Clients gültig, sodass Vorgänge Dateiattribute aus dem Cache statt während der Übertragung abrufen können. Das kann die Latenz in Situationen verringern, in denen die zwischengespeicherten Attribute ablaufen, während der Vorgang noch ausgeführt wird.
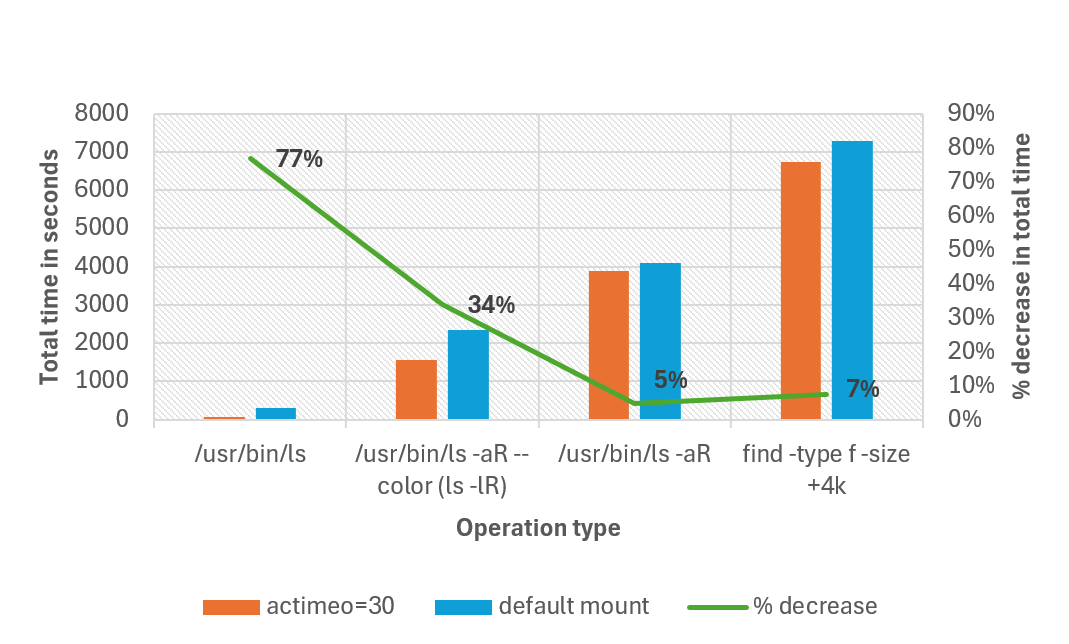
Das folgende Diagramm vergleicht die Gesamtzeit, die zum Abschließen verschiedener Vorgänge mit der Standardbereitstellung erforderlich ist, und das Festlegen eines actimeo-Werts von 30 für eine Workload mit 1 Million Dateien in einem einzigen Verzeichnis. Bei unseren Tests verringerte sich die Gesamtabschlusszeit bei einigen Vorgängen um bis zu 77 %. Alle Vorgänge wurden mit unaliased ls durchgeführt.
nconnect
Nconnect ist eine clientseitige Bereitstellungsoption, mit der Sie mehrere TCP-Verbindungen zwischen dem Client und dem Azure Files Premium-Dienst für NFS 4.1 nutzen können. Wir empfehlen die optimale Einstellung von nconnect=4, um die Latenz zu reduzieren und die Leistung zu verbessern.
Nconnect kann besonders für Workloads nützlich sein, die asynchrone oder synchrone E/A-Vorgänge aus mehreren Threads verwenden.
Weitere Informationen
Befehle und Vorgänge
Die Art und Weise, wie Befehle und Vorgänge angegeben werden, kann sich auch auf die Leistung auswirken. Das Auflisten aller Dateien in einem großen Verzeichnis mithilfe des Befehls ls ist ein gutes Beispiel.
Hinweis
Einige Vorgänge wie rekursive ls-, find- und du-Vorgänge benötigen sowohl Dateinamen als auch Dateiattribute. Sie kombinieren also Verzeichnisenumerationen (um die Einträge abzurufen) mit einem Stat für jeden Eintrag (um die Attribute abzurufen). Wir empfehlen die Verwendung eines höheren Werts für actimeo an Bereitstellungspunkten, an denen Sie solche Befehle wahrscheinlich ausführen.
Verwenden von unaliased ls
In einigen Linux-Distributionen legt die Shell automatisch Standardoptionen für den ls-Befehl fest, zum Beispiel ls --color=auto. Dadurch wird geändert, wie ls sich bei der Übertragung verhält, und der ls-Ausführung werden weitere Vorgänge hinzugefügt. Um Leistungsbeeinträchtigungen zu vermeiden, empfehlen wir die Verwendung von unaliased ls. Hierfür gibt es drei Möglichkeiten:
Entfernen Sie den Alias mithilfe des Befehls
unalias ls. Das ist nur eine temporäre Lösung für die aktuelle Sitzung.Für eine dauerhafte Änderung können Sie den
ls-Alias in derbashrc/bash_aliases-Datei des Benutzers bearbeiten. Bearbeiten Sie in Ubuntu~/.bashrc, um den Alias fürlszu entfernen.Anstatt
lsaufzurufen, können Sie diels-Binärdatei direkt aufrufen, z. B./usr/bin/ls. Auf diese Weise können Sielsohne Optionen verwenden, die sich möglicherweise im Alias befinden. Sie können den Speicherort der Binärdatei herausfinden, indem Sie den Befehlwhich lsausführen.
Verhindern, dass ls die Ausgabe sortiert
Wenn Sie ls mit anderen Befehlen verwenden, können Sie die Leistung verbessern, indem Sie verhindern, dass ls die Ausgabe in Situationen sortiert, in denen die Reihenfolge keine Rolle spielt, in der ls die Dateien zurückgibt. Die Sortierung der Ausgabe sorgt für erheblichen Mehraufwand.
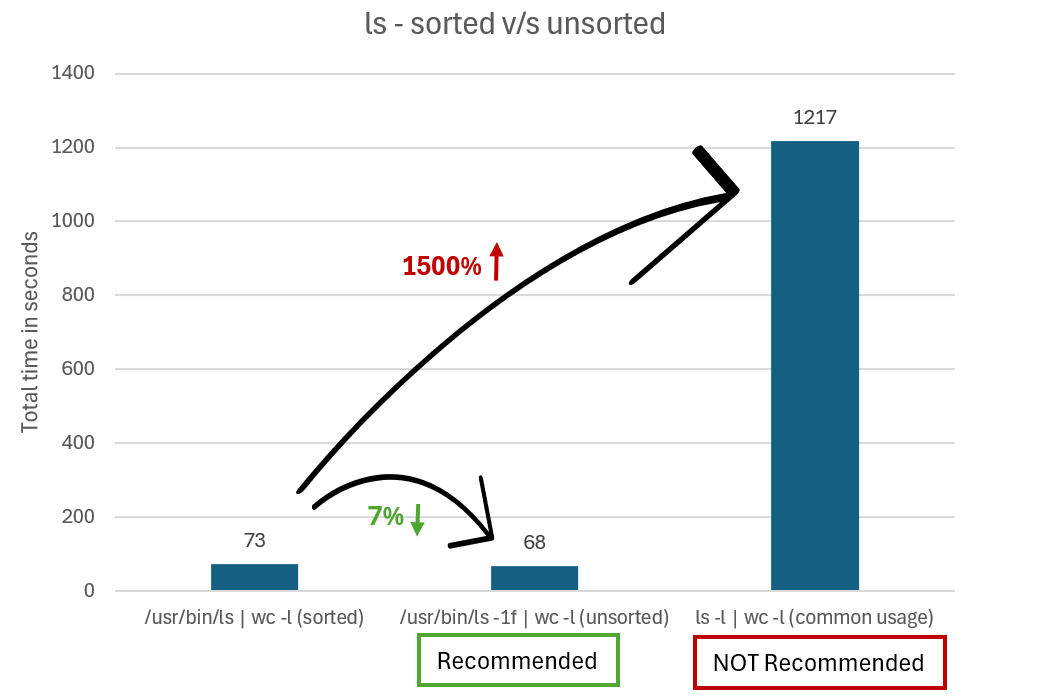
Anstatt ls -l | wc -l auszuführen, um die Gesamtanzahl der Dateien abzurufen, können Sie die Optionen -f oder -U mit ls verwenden, um zu verhindern, dass die Ausgabe sortiert wird. Der Unterschied besteht darin, dass -f auch ausgeblendete Dateien anzeigt und -U nicht.
Wenn Sie beispielsweise die ls-Binärdatei in Ubuntu direkt aufrufen, würden Sie /usr/bin/ls -1f | wc -l oder /usr/bin/ls -1U | wc -l ausführen.
Das folgende Diagramm vergleicht die Zeit, die zum Ausgeben von Ergebnissen mit unaliased für unsortierte ls-Einträge und sortierte ls-Einträge benötigt wird.
Erhöhen der Anzahl der Hashbuckets
Die Gesamtmenge des Arbeitsspeichers des Systems, das die Enumeration vornimmt, beeinflusst die interne Arbeit von Dateisystemprotokollen wie NFS und SMB. Auch wenn Benutzer mit keiner hohen Arbeitsspeicherauslastung konfrontiert sind, beeinflusst die verfügbare Menge an Arbeitsspeicher die Menge der Hashbuckets, die das System hat, was sich positiv auf die Enumerationsleistung für große Verzeichnisse auswirkt. Sie können die Menge der Hashbuckets ändern, die das System besitzt, um die Hashkonflikte zu reduzieren, die während großer Enumerationsworkloads auftreten können.
Dazu müssen Sie Ihre Startkonfigurationseinstellungen ändern, indem Sie einen zusätzlichen Kernelbefehl bereitstellen, der während des Starts wirksam wird, um die Anzahl der Hashbuckets zu erhöhen. Führen Sie die folgenden Schritte aus.
Verwenden Sie einen Text-Editor zum Bearbeiten der
/etc/default/grub-Datei.sudo vim /etc/default/grubFügen Sie der Datei
/etc/default/grubden folgenden Text hinzu: Mit diesem Befehl werden 128 MB als Größe der Hashtabelle abgetrennt, wodurch die Systemspeicherauslastung um maximal 128 MB erhöht wird.GRUB_CMDLINE_LINUX="ihash_entries=16777216"Wenn
GRUB_CMDLINE_LINUXbereits vorhanden ist, fügen Sieihash_entries=16777216durch ein Leerzeichen getrennt folgendermaßen hinzu:GRUB_CMDLINE_LINUX="<previous commands> ihash_entries=16777216"Führen Sie Folgendes aus, um die Änderungen anzuwenden:
sudo update-grub2Starten Sie das System neu:
sudo rebootUm zu überprüfen, ob die Änderungen wirksam geworden sind, überprüfen Sie nach dem Neustart des Systems die Kernel-Cmdline-Befehle:
cat /proc/cmdlineWenn
ihash_entriesangezeigt wird, hat das System die Einstellung angewendet, und die Enumerationsleistung sollte sich exponentiell verbessern.Sie können auch die dmesg-Ausgabe überprüfen, um festzustellen, ob die Kernel-Cmdline angewendet wurde:
dmesg | grep "Inode-cache hash table" Inode-cache hash table entries: 16777216 (order: 15, 134217728 bytes, linear)
Dateikopie- und Sicherungsvorgänge
Wenn Sie Daten aus einer Dateifreigabe kopieren oder von Dateifreigaben an einen anderen Speicherort sichern, empfiehlt es sich, eine Momentaufnahme der Freigabe anstelle der Livedateifreigabe mit aktiver E/A als Quelle zu verwenden. Sicherungsanwendungen sollten Befehle direkt in der Momentaufnahme ausführen. Weitere Informationen finden Sie unter Verwenden von Freigabemomentaufnahmen mit Azure Files.
Empfehlungen auf Anwendungsebene
Wenn Sie Anwendungen entwickeln, die große Verzeichnisse verwenden, befolgen Sie diese Empfehlungen.
Dateiattribute überspringen: Wenn die Anwendung nur den Dateinamen und keine Dateiattribute wie Dateityp oder Uhrzeit der letzten Änderung benötigt, können Sie mehrere Systemaufrufen wie
getdents64mit einer guten Puffergröße verwenden. Dadurch werden die Einträge im angegebenen Verzeichnis ohne den Dateityp abgerufen, wodurch der Vorgang beschleunigt wird, indem zusätzliche Vorgänge vermieden werden, die nicht benötigt werden.Stat-Aufrufe überlappen: Wenn die Anwendung Attribute und den Dateinamen benötigt, empfiehlt es sich, die Stat-Aufrufe zusammen mit
getdents64zu überlappen, anstatt alle Einträge bis zum Ende der Datei mitgetdents64abzurufen und dann einen statx-Aufruf für alle zurückgegebenen Einträge auszuführen. Durch das Überlappen der Stat-Aufrufe wird der Client angewiesen, die Datei und die Attribute gleichzeitig anzufordern, wodurch die Anzahl der Aufrufe an den Server reduziert wird. In Kombination mit einem hohenactimeo-Wert kann dies die Leistung erheblich verbessern. Platzieren Sie z. B. anstelle von[ getdents64, getdents64, ... , getdents64, statx (entry1), ... , statx(n) ]die statx-Aufrufe nach jedemgetdents64-Element wie folgt:[ getdents64, (statx, statx, ... , statx), getdents64, (statx, statx, ... , statx), ... ].E/A-Tiefe erhöhen: Wenn möglich, empfehlen wir,
nconnectauf einen Wert ungleich null (größer als 1) festzulegen und den Vorgang auf mehrere Threads zu verteilen oder asynchrone E/A-Vorgänge zu verwenden. Dadurch werden asynchrone Vorgänge ermöglicht, um von mehreren gleichzeitigen Verbindungen mit der Dateifreigabe zu profitieren.Cachenutzung erzwingen: Wenn die Anwendung die Dateiattribute einer Dateifreigabe abfragt, die nur ein Client bereitgestellt hat, verwenden Sie den statx-Systemaufruf mit dem
AT_STATX_DONT_SYNC-Flag. Mit diesem Flag wird sichergestellt, dass die zwischengespeicherten Attribute aus dem Cache abgerufen werden, ohne mit dem Server zu synchronisieren, sodass zusätzliche Netzwerkroundtrips vermieden werden, um die neuesten Daten abzurufen.