Funktionsweise kundenseitig verwalteter geplanter Failover (Preview)
Ei vom Kunden verwaltetes geplantes Failover kann in Szenarien wie Notfall- und Wiederherstellungsplanung und -tests, proaktive Wartung für erwartete Großkatastrophen und nicht speicherbezogene Ausfälle hilfreich sein.
Während des geplanten Failoverprozesses werden die primären und sekundären Regionen Ihres Speicherkontos ausgetauscht. Die ursprüngliche primäre Region wird herabgestuft und wird zur neuen sekundären Region, während die ursprüngliche sekundäre Region höhergestuft wird und zur neuen primären Region wird. Das Speicherkonto muss sowohl in den primären als auch in sekundären Regionen verfügbar sein, bevor ein geplantes Failover initiiert werden kann.
In diesem Artikel wird beschrieben, was während eines kundenseitig verwalteten geplanten Failovers und eines Failbacks in jeder Phase des Prozesses geschieht. Informationen dazu, wie ein Failover aufgrund eines unerwarteten Speicherendpunktausfalls funktioniert, finden Sie unter Informationen zu kundenseitig verwalteten (ungeplanten) Failovern.
Wichtig
Das kundenseitig verwaltete geplante Failover befindet sich derzeit in der VORSCHAU und ist auf die folgenden Regionen beschränkt:
- Asien, Osten
- Asien, Südosten
- Australien (Osten)
- Australien, Südosten
- Frankreich, Mitte
- Frankreich, Süden
- Indien, Mitte
- Indien, Westen
- Schweiz, Westen
- Schweiz, Norden
Wenn Sie die Vorschauversion aktivieren möchten, informieren Sie sich unter Einrichten von Previewfunktionen im Azure-Abonnement, und geben Sie AllowSoftFailover als Featurenamen an. Der Anbietername für diese Previewfunktion ist Microsoft.Storage.
Die zusätzlichen Nutzungsbestimmungen für Microsoft Azure-Vorschauen enthalten rechtliche Bedingungen. Sie gelten für diejenigen Azure-Features, die sich in der Beta- oder Vorschauversion befinden oder aber anderweitig noch nicht zur allgemeinen Verfügbarkeit freigegeben sind.
Wichtig
Nach einem geplanten Failover kann der Wert für den letzten Synchronisierungszeitpunkt (Last Sync Time, LST) eines Speicherkontos veraltet erscheinen oder als NULL gemeldet werden, wenn Azure Files-Daten vorhanden sind.
Systemmomentaufnahmen werden in regelmäßigen Abständen in der sekundären Region eines Speicherkontos erstellt, um konsistente Wiederherstellungspunkte erhalten, die während des Failovers und Failbacks verwendet werden. Das Initiieren eines kundenseitig verwalteten geplanten Failovers bewirkt, dass die ursprüngliche primäre Region zur neuen sekundären Region wird. In einigen Fällen sind nach Abschluss des geplanten Failovers keine Systemmomentaufnahmen in der neuen sekundären Region verfügbar, sodass der LST-Gesamtwert des Kontos veraltet scheint oder als Null angezeigt wird.
Da Benutzeraktivitäten wie das Erstellen, Ändern oder Löschen von Objekten die Erstellung von Momentaufnahmen auslösen können, erfordern Konten, bei denen diese Aktivitäten nach dem geplanten Failover stattfinden, keine zusätzliche Aufmerksamkeit. Konten ohne Momentaufnahmen oder Benutzeraktivitäten können jedoch weiterhin den LST-Wert Null anzeigen, bis die Erstellung von Systemmomentaufnahmen ausgelöst wird.
Führen Sie bei Bedarf eine der folgenden Aktivitäten für jede Freigabe innerhalb eines Speicherkontos aus, um die Erstellung von Momentaufnahmen auszulösen. Nach Abschluss sollte Ihr Konto innerhalb von 30 Minuten einen gültigen LST-Wert anzeigen.
- Binden Sie die Freigabe ein, und öffnen Sie dann eine beliebige Datei zum Lesen.
- Laden Sie eine Test- oder Beispieldatei in die Freigabe hoch.
Redundanzverwaltung während des geplanten Failovers und Failbacks
Tipp
Detaillierte Definitionen für die unterschiedlichen Redundanzzuständen während des kundenseitig verwalteten Failover- und Failbackprozesses finden Sie unter Azure Storage-Redundanz.
Während des geplanten Failoverprozesses werden die Speicherdienstendpunkte der primären Region schreibgeschützt, während die verbleibenden Updates die Replikation auf die sekundäre Region abschließen. Als Nächstes werden alle DNS-Einträge (Domain Name Service) des Speicherdiensts ausgetauscht. Die sekundären Endpunkte Ihres Speicherkontos werden zu den neuen primären Endpunkten und die ursprünglichen primären Endpunkte werden zu den neuen sekundären. Die Datenreplikation innerhalb jeder Region bleibt unverändert, auch wenn die primäre und sekundäre Region getauscht werden.
Der geplante Failbackprozess ist im Wesentlichen identisch mit dem geplanten Failoverprozess, jedoch mit einer Ausnahme. Während des geplanten Failbacks speichert Azure die ursprüngliche Redundanzkonfiguration Ihres Speicherkontos und stellt sie beim Failback wieder im ursprünglichen Zustand her. Wenn Ihr Speicherkonto beispielsweise ursprünglich als geozonenredundanter Speicher (GZRS) konfiguriert wurde, entspricht das Speicherkonto nach einem Failback einem GZRS.
Hinweis
Im Gegensatz zum kundenseitig verwalteten (ungeplanten) Failover muss beim geplanten Failover die Replikation von der primären zur sekundären Region abgeschlossen sein, bevor die DNS-Einträge für die Endpunkte auf die neue sekundäre Region umgestellt werden. Aus diesem Grund ist bei einem geplanten Failover oder Failback kein Datenverlust zu erwarten, solange sowohl die primäre als auch die sekundäre Region während des gesamten Prozesses verfügbar ist.
So initiieren Sie einen Failover
Informationen zum Initiieren eines Failovers finden Sie unter Initiieren eines Kontofailovers.
Geplanter Failover- und Failbackprozess
Die folgenden Diagramme zeigen, was bei einem kundenseitig verwalteten geplanten Failover und Failback eines Speicherkontos geschieht.
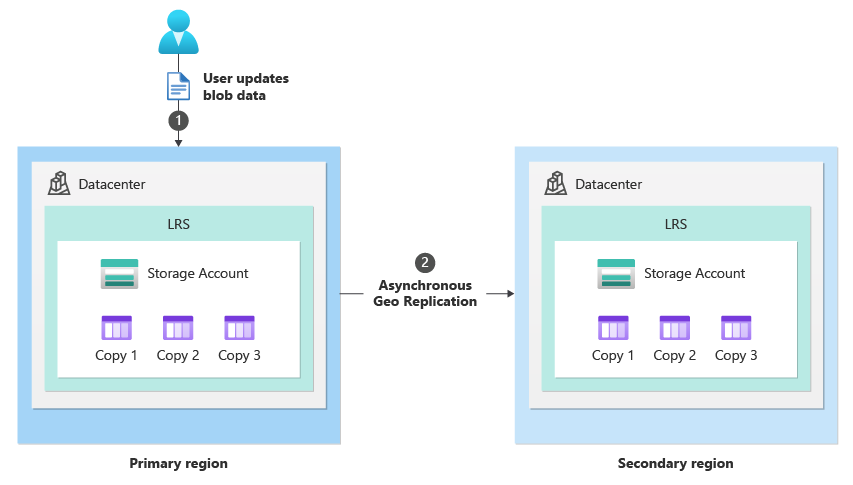
Unter normalen Umständen schreibt ein Client Daten über Speicherdienstendpunkte (1) in ein Speicherkonto in der primären Region. Die Daten werden dann asynchron aus dem primären Bereich in die sekundäre Region kopiert (2). Die folgende Abbildung zeigt den normalen Zustand eines als GRS konfigurierten Speicherkontos:

Geplanter Failoverprozess (GRS/RA-GRS)
Beginnen Sie den Notfallwiederherstellungstest, indem Sie ein Failover Ihres Speicherkontos auf die sekundäre Region initiieren. Im Folgenden werden die Schritte des geplanten Failover-Prozesses beschrieben:, und das nachfolgende Bild dient der Veranschaulichung:
- Der primäre Bereich verliert vorübergehend sowohl Lese- als auch Schreibzugriff. RA-GRS- oder RA-GZRS-Benutzende haben weiterhin Lesezugriff auf ihre sekundäre Region.
- Die Replikation aller Daten aus der primären Region in die sekundäre Region ist abgeschlossen.
- DNS-Einträge für Speicherdienst-Endpunkte in der sekundären Region werden heraufgestuft und werden zu den neuen primären Endpunkten für Ihr Speicherkonto.
Das Failover dauert i. d. r. etwa eine Stunde.

Nach Abschluss des Failovers wird die ursprüngliche primäre Region zur neuen sekundären (1) und die ursprüngliche sekundäre Region zur neuen primären (2). Die URIs für die Dienstendpunkte für Blobs, Tabellen, Warteschlangen und Dateien bleiben gleich, aber ihre DNS-Einträge werden so geändert, dass sie auf die neue primäre Region (3) zeigen. Die Benutzer und Benutzerinnen können mit dem Schreiben von Daten auf das Speicherkonto in der neuen primären Region fortfahren. Die Daten werden dann asynchron in die neue sekundäre Region (4) kopiert, wie in der folgenden Abbildung gezeigt:

Führen Sie im Failoverzustand Ihre Notfallwiederherstellungstests durch.
Geplanter Failbackprozess (GRS/RA-GRS)
Nach Abschluss der Tests führen Sie ein weiteres Failover durch, um zur ursprünglichen primären Region zurückzukehren. Während des Failover-Prozesses, wie in der folgenden Abbildung gezeigt:
- Der primäre Bereich verliert vorübergehend sowohl Lese- als auch Schreibzugriff. RA-GRS- oder RA-GZRS-Benutzende haben weiterhin Lesezugriff auf ihre sekundäre Region.
- Die Replikation aller Daten von der aktuellen primären Region zur aktuellen sekundären Region ist abgeschlossen.
- Die DNS-Einträge für die Dienstendpunkte des Speichers werden so geändert, dass sie wieder auf die Region verweisen, die vor dem ersten Failover die primäre Region war.
Das Failback dauert in der Regel etwa eine Stunde.

Nachdem das Failback abgeschlossen ist, wird das Speicherkonto mit seiner ursprünglichen Redundanzkonfiguration wiederhergestellt. Die Benutzer*innen können wieder Daten auf das Speicherkonto in der ursprünglichen primären Region (1) schreiben, während die Replikation auf die ursprüngliche sekundäre Region (2) wie vor dem Failover fortgesetzt wird: