Überwachen von Site Recovery mit Azure Monitor-Protokollen
In diesem Artikel wird beschrieben, wie Sie die von Azure Site Recovery replizierten Computer mithilfe von Azure Monitor-Protokollen und Log Analytics überwachen.
Azure Monitor-Protokolle bieten eine Protokolldatenplattform, die Aktivitäts- und Ressourcenprotokolle zusammen mit anderen Überwachungsdaten sammelt. In Azure Monitor-Protokollen können Sie Log Analytics verwenden, um Protokollabfragen zu schreiben und zu testen und Protokolldaten interaktiv zu analysieren. Sie können die Protokollergebnisse visualisieren und abfragen, und Sie können Warnungen konfigurieren, damit Aktionen basierend auf überwachten Daten durchgeführt werden.
Für Site Recovery können Sie Azure Monitor-Protokolle für folgende Aufgaben verwenden:
- Überwachen von Integrität und Status von Site Recovery: Sie können z. B. die Replikationsintegrität, den Testfailoverstatus, Site Recovery-Ereignisse, RPOs (Recovery Point Objectives, Wiederherstellungspunktziele) für geschützte Computer und die Änderungsraten von Datenträgern/Daten überwachen.
- Einrichten von Warnungen für Site Recovery: Beispielsweise können Sie Warnungen für die Computerintegrität oder für den Testfailoverstatus oder Site Recovery-Aufträge konfigurieren.
Die Verwendung von Azure Monitor-Protokollen mit Site Recovery wird für die Azure-zu-Azure-Replikation und die Replikation von VMware-VMs/physischen Servern zu Azure unterstützt.
Hinweis
Um die Änderungsdaten- und Uploadratenprotokolle für VMware- und physische Computer zu erhalten, müssen Sie einen Microsoft Monitoring Agent auf dem Prozessserver installieren. Dieser Agent sendet die Protokolle der replizierenden Computer an den Arbeitsbereich. Diese Funktion ist erst ab der Version 9.30 des Mobilitäts-Agents verfügbar.
Voraussetzungen
Sie benötigen Folgendes:
- Mindestens einen Computer, der in einem Recovery Services-Tresor geschützt ist
- Einen Log Analytics-Arbeitsbereich zum Speichern von Site Recovery-Protokollen. Erfahren Sie mehr über das Einrichten eines Arbeitsbereichs.
- Grundlegende Kenntnisse zum Schreiben, Ausführen und Analysieren von Protokollabfragen in Log Analytics. Weitere Informationen
Es wird empfohlen, vor dem Start die allgemeinen Fragen zur Überwachung zu lesen.
Für Azure Site Recovery verfügbare Ereignisprotokolle
Azure Site Recovery bietet die folgenden ressourcenspezifischen Tabellen und Legacytabellen. Jedes Ereignis stellt detaillierte Daten zu einer bestimmten Gruppe von Artefakten im Zusammenhang mit der Sitewiederherstellung bereit.
Ressourcenspezifische Tabellen:
Legacytabellen:
- Azure Site Recovery-Ereignisse
- Replizierte Azure Site Recovery-Elemente
- Azure Site Recovery-Replikationsstatistiken
- Azure Site Recovery-Wiederherstellungspunkte
- Uploadrate für Azure Site Recovery-Replikationsdaten
- Datenänderungen auf mit Azure Site Recovery geschützten Datenträgern
- Details zu replizierten Azure Site Recovery-Elementen
Konfigurieren von Site Recovery für das Senden von Protokollen
Klicken Sie im Tresor auf Diagnoseeinstellungen>Diagnoseeinstellung hinzufügen.
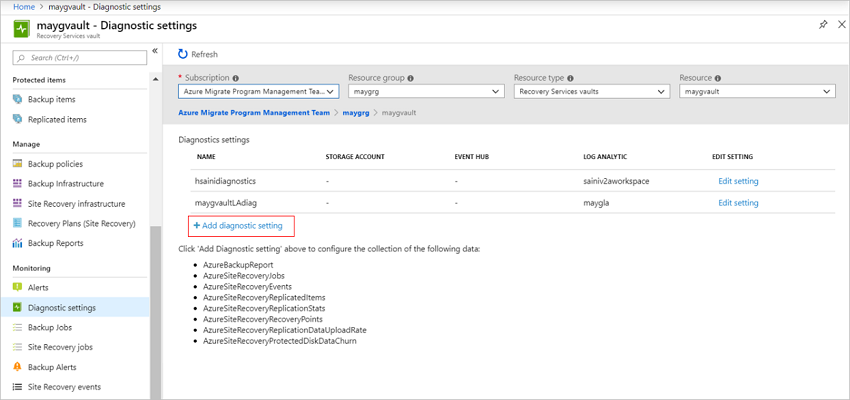
Geben Sie unter Diagnoseeinstellungen einen Namen an, und aktivieren Sie das Kontrollkästchen An Log Analytics senden.
Wählen Sie das Abonnement der Azure Monitor-Protokolle und den Log Analytics-Arbeitsbereich aus.
Wählen mithilfe des Umschalters die Option Azure-Diagnose aus.
Wählen Sie in der Protokollliste alle Protokolle mit dem Präfix AzureSiteRecovery aus. Klicken Sie anschließend auf OK.
Die Site Recovery-Protokolle werden nun in eine Tabelle (AzureDiagnostics) im ausgewählten Arbeitsbereich übertragen.
Konfigurieren des Microsoft Monitoring Agents auf dem Prozessserver zum Senden von Änderungsdaten- und Uploadratenprotokollen
Sie können die Änderungsdateninformationen und die Quelldaten-Uploadrateninformationen für Ihre VMware-/physischen Computer lokal erfassen. Dazu muss ein Microsoft Monitoring Agent auf dem Prozessserver installiert sein.
Wechseln Sie zum Log Analytics-Arbeitsbereich, und wählen Sie Erweiterte Einstellungen aus.
Klicken Sie auf die Seite Verbundene Quellen, und wählen Sie dann Windows-Server aus.
Laden Sie den Windows-Agent (64 Bit) auf dem Prozessserver herunter.
Schließen Sie die Installation des Agents ab, indem Sie die erhaltene Arbeitsbereichs-ID und den Schlüssel angeben.
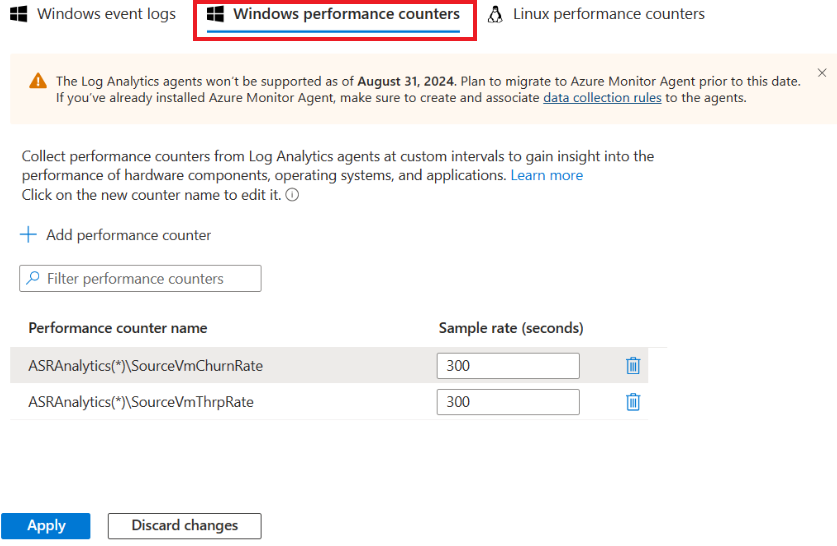
Navigieren Sie nach Abschluss der Installation zum Log Analytics-Arbeitsbereich, und wählen Sie Verwaltung von Agent einer Vorgängerversion. Wechseln Sie zur Seite Daten, und klicken Sie dann auf Windows-Leistungsindikatoren.
Wählen Sie + aus, um die beiden folgenden Indikatoren mit einem Stichprobenintervall von 300 Sekunden hinzuzufügen:
- ASRAnalytics(*)\SourceVmChurnRate
- ASRAnalytics(*)\SourceVmThrpRate
Die Änderungs- und Uploadratendaten werden in den Arbeitsbereich eingegeben.
Die folgenden Site Recovery-Zähler sind derzeit nicht durchsuchbar:
- ASRAnalytics(*)\SourceVmChurnRate
- ASRAnalytics(*)\SourceVmThrpRate
Sie können jedoch durch Einfügen des vollständigen Namens hinzugefügt werden.
Hinweis
Derzeit können Sie nicht nach diesen Leistungsindikatoren suchen. Sie können sie jedoch hinzufügen, indem Sie ihre vollständigen Namen kopieren und einfügen.
- SourceVmThrpRate zeigt die Netzwerkdurchsatzrate für die Quelle an.
- SourceVmChurnRate zeigt die Datenänderungsrate auf dem Datenträger auf dem virtuellen Quellcomputer an.
Abfragen der Protokolle – Beispiele
Daten aus Protokollen werden mithilfe von Protokollabfragen abgerufen, die mit der Abfragesprache Kusto geschrieben werden. Dieser Abschnitt enthält mehrere Beispiele für allgemeine Abfragen, die Sie für die Site Recovery-Überwachung verwenden können.
Hinweis
In einigen Beispielen wird replicationProviderName_s auf A2A festgelegt. Dadurch werden Azure-VMs abgerufen, die mithilfe von Site Recovery in eine sekundäre Azure-Region repliziert werden. In diesen Beispielen können Sie A2A durch InMageRcm ersetzen, wenn Sie lokale VMware-VMs oder physische Server abrufen möchten, die mithilfe von Site Recovery nach Azure repliziert werden.
Abfragen der Replikationsintegrität
Diese Abfrage zeichnet ein Kreisdiagramm der derzeitigen Replikationsintegrität aller geschützten Azure-VMs, das in drei Status unterteilt ist: „Normal“, „Warnung“ und „Kritisch“.
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where isnotempty(name_s) and isnotnull(name_s)
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| project name_s , replicationHealth_s
| summarize count() by replicationHealth_s
| render piechart
Abfragen der Mobility Service-Version
Diese Abfrage zeichnet ein Kreisdiagramm der mit Site Recovery replizierten Azure-VMs, unterteilt nach der ausgeführten Version des Mobilitäts-Agents.
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where isnotempty(name_s) and isnotnull(name_s)
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| project name_s , agentVersion_s
| summarize count() by agentVersion_s
| render piechart
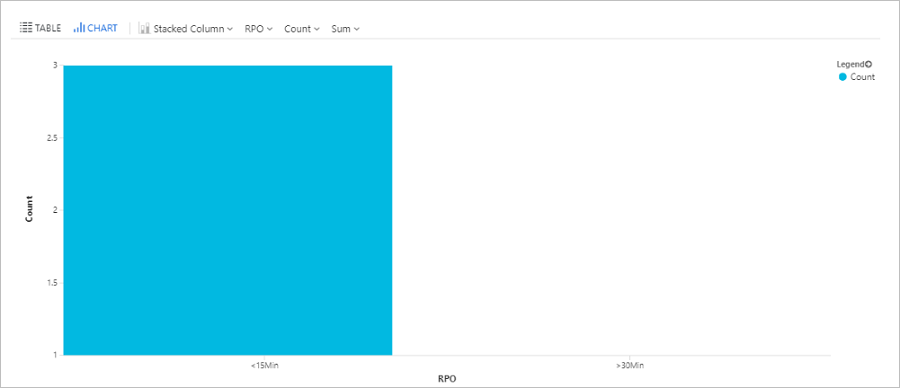
Abfragen der RPO-Zeit
Diese Abfrage zeichnet ein Balkendiagramm der mit Site Recovery replizierten Azure-VMs, unterteilt nach RPO (Recovery Point Objective, Wiederherstellungspunktziel): weniger als 15 Minuten, 15 – 30 Minuten, mehr als 30 Minuten.
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where isnotempty(name_s) and isnotnull(name_s)
| extend RPO = case(rpoInSeconds_d <= 900, "<15Min",
rpoInSeconds_d <= 1800, "15-30Min", ">30Min")
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| project name_s , RPO
| summarize Count = count() by RPO
| render barchart
Abfragen von Site Recovery-Aufträgen
Diese Abfrage ruft alle Site Recovery-Aufträge (für alle Notfallwiederherstellungs-Szenarien) ab, die in den letzten 72 Stunden ausgelöst wurden, sowie deren Abschlussstatus.
AzureDiagnostics
| where Category == "AzureSiteRecoveryJobs"
| where TimeGenerated >= ago(72h)
| project JobName = OperationName , VaultName = Resource , TargetName = affectedResourceName_s, State = ResultType
Abfragen von Site Recovery-Ereignissen
Diese Abfrage ruft alle Site Recovery-Ereignisse (für alle Notfallwiederherstellungs-Szenarien) ab, die in den letzten 72 Stunden ausgelöst wurden, sowie deren Schweregrad.
AzureDiagnostics
| where Category == "AzureSiteRecoveryEvents"
| where TimeGenerated >= ago(72h)
| project AffectedObject=affectedResourceName_s , VaultName = Resource, Description_s = healthErrors_s , Severity = Level
Abfragen des Testfailoverstatus (Kreisdiagramm)
Diese Abfrage zeichnet ein Kreisdiagramm des Testfailoverstatus der mit Site Recovery replizierten Azure-VMs.
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where isnotempty(name_s) and isnotnull(name_s)
| where isnotempty(failoverHealth_s) and isnotnull(failoverHealth_s)
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| project name_s , Resource, failoverHealth_s
| summarize count() by failoverHealth_s
| render piechart
Abfragen des Testfailoverstatus (Tabelle)
Diese Abfrage erstellt eine Tabelle für den Testfailoverstatus der mit Site Recovery replizierten Azure-VMs.
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where isnotempty(name_s) and isnotnull(name_s)
| where isnotempty(failoverHealth_s) and isnotnull(failoverHealth_s)
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| project VirtualMachine = name_s , VaultName = Resource , TestFailoverStatus = failoverHealth_s
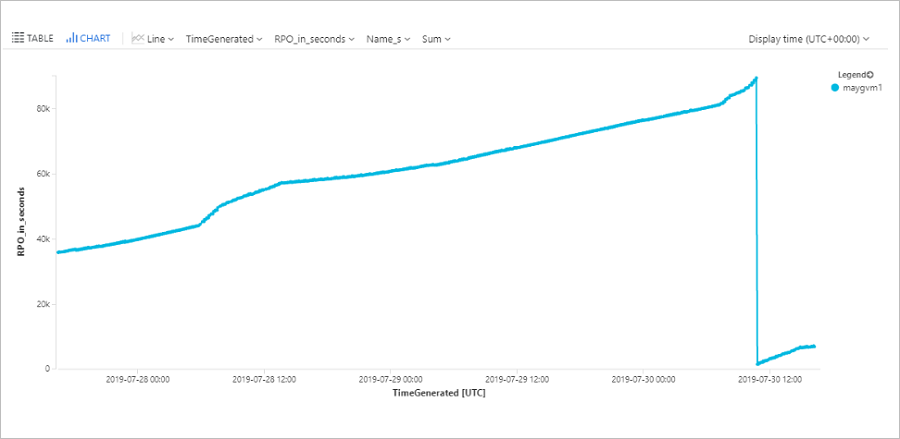
Abfragen des Computer-RPO
Diese Abfrage zeichnet ein Trenddiagramm, das die RPO einer bestimmten Azure-VM (ContosoVM123) für die letzten 72 Stunden nachverfolgt.
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where TimeGenerated > ago(72h)
| where isnotempty(name_s) and isnotnull(name_s)
| where name_s == "ContosoVM123"
| project TimeGenerated, name_s , RPO_in_seconds = rpoInSeconds_d
| render timechart
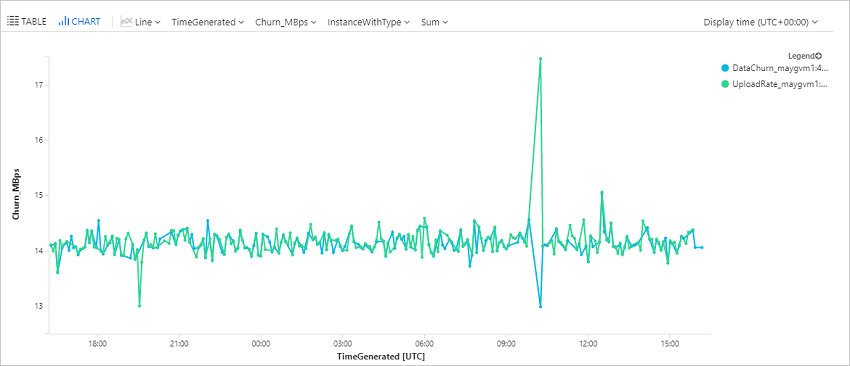
Abfragen der Datenänderungsrate (Churn) und der Uploadrate für eine Azure-VM
Diese Abfrage zeichnet ein Trenddiagramm für eine bestimmte Azure-VM (ContosoVM123), das die Datenänderungsrate (geschriebene Bytes pro Sekunde) und die Datenuploadrate darstellt.
AzureDiagnostics
| where Category in ("AzureSiteRecoveryProtectedDiskDataChurn", "AzureSiteRecoveryReplicationDataUploadRate")
| extend CategoryS = case(Category contains "Churn", "DataChurn",
Category contains "Upload", "UploadRate", "none")
| extend InstanceWithType=strcat(CategoryS, "_", InstanceName_s)
| where TimeGenerated > ago(24h)
| where InstanceName_s startswith "ContosoVM123"
| project TimeGenerated , InstanceWithType , Churn_MBps = todouble(Value_s)/1048576
| render timechart
Abfragen der Datenänderungsrate (Churn) und der Uploadrate für einen VMware- oder physischen Computer
Hinweis
Stellen Sie sicher, dass Sie den Überwachungs-Agent auf dem Prozessserver einrichten, um diese Protokolle abzurufen. Weitere Informationen finden Sie unter Schritte zum Konfigurieren des Überwachungs-Agents.
Diese Abfrage zeichnet ein Trenddiagramm für einen bestimmten Datenträger (disk0) eines replizierten Elements (win-9r7sfh9qlru), das die Datenänderungsrate (geschriebene Bytes pro Sekunde) und die Datenuploadrate darstellt. Sie finden den Datenträgernamen auf dem Blatt Datenträger des replizierten Elements im Recovery Services-Tresor. Der in der Abfrage zu verwendende Instanzenname ist der DNS-Name des Computers, gefolgt von „_“ und dem Datenträgernamen, wie im folgenden Beispiel:
Perf
| where ObjectName == "ASRAnalytics"
| where InstanceName contains "win-9r7sfh9qlru_disk0"
| where TimeGenerated >= ago(4h)
| project TimeGenerated ,CounterName, Churn_MBps = todouble(CounterValue)/5242880
| render timechart
Der Prozessserver pusht diese Daten alle 5 Minuten in den Log Analytics-Arbeitsbereich. Diese Datenpunkte stellen den Durchschnitt dar, der für 5 Minuten berechnet wurde.
Abfragen der Zusammenfassung zur Notfallwiederherstellung (Azure-zu-Azure)
Diese Abfrage erstellt eine Zusammenfassungstabelle für Azure-VMs, die in eine sekundäre Azure-Region repliziert werden. Sie enthält den Namen der VM, den Replikations- und Schutzstatus, die RPO, den Testfailoverstatus, die Version des Mobilitäts-Agents, ggf. aktive Replikationsfehler und den Quellstandort.
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where isnotempty(name_s) and isnotnull(name_s)
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| project VirtualMachine = name_s , Vault = Resource , ReplicationHealth = replicationHealth_s, Status = protectionState_s, RPO_in_seconds = rpoInSeconds_d, TestFailoverStatus = failoverHealth_s, AgentVersion = agentVersion_s, ReplicationError = replicationHealthErrors_s, SourceLocation = primaryFabricName_s
Abfragen der Zusammenfassung einer Notfallwiederherstellung (VMware/physische Server)
Diese Abfrage erstellt eine Zusammenfassungstabelle für VMware-VMs und physische Server, die nach Azure repliziert werden. Sie liefert den Namen des Computers, den Replikations- und Schutzstatus, die RPO, den Testfailoverstatus, die Version des Mobilitäts-Agents, ggf. aktive Replikationsfehler und den zugehörigen Prozessserver.
AzureDiagnostics
| where replicationProviderName_s == "InMageRcm"
| where isnotempty(name_s) and isnotnull(name_s)
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| project VirtualMachine = name_s , Vault = Resource , ReplicationHealth = replicationHealth_s, Status = protectionState_s, RPO_in_seconds = rpoInSeconds_d, TestFailoverStatus = failoverHealth_s, AgentVersion = agentVersion_s, ReplicationError = replicationHealthErrors_s, ProcessServer = processServerName_g
Einrichten von Warnungen – Beispiele
Sie können Site Recovery Warnungen basierend auf Azure Monitor-Daten einrichten. Informieren Sie sich über das Einrichten von Protokollwarnungen.
Hinweis
In einigen Beispielen wird replicationProviderName_s auf A2A festgelegt. Dadurch werden Warnungen für Azure-VMs eingerichtet, die in eine sekundäre Azure-Region repliziert werden. In diesen Beispielen können Sie A2A durch InMageRcm ersetzen, wenn Sie Warnungen für lokale VMware-VMs oder physische Server einrichten möchten, die nach Azure repliziert werden.
Mehrere Computer mit kritischem Status
Richten Sie eine Warnung ein, die ausgelöst wird, wenn mehr als 20 replizierte Azure-VMs den Status „Kritisch“ aufweisen.
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where replicationHealth_s == "Critical"
| where isnotempty(name_s) and isnotnull(name_s)
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| summarize count()
Legen Sie den Schwellenwert für die Warnung auf 20 fest.
Einzelner Computer mit kritischem Status
Richten Sie eine Warnung ein, die ausgelöst wird, wenn eine bestimmte replizierte Azure-VM den Status „Kritisch“ aufweist.
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where replicationHealth_s == "Critical"
| where name_s == "ContosoVM123"
| where isnotempty(name_s) and isnotnull(name_s)
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| summarize count()
Legen Sie den Schwellenwert für die Warnung auf 1 fest.
Mehrere Computer über RPO
Richten Sie eine Warnung ein, die ausgelöst wird, wenn die RPO für mehr als 20 Azure-VMs 30 Minuten überschreitet.
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where isnotempty(name_s) and isnotnull(name_s)
| where rpoInSeconds_d > 1800
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| project name_s , rpoInSeconds_d
| summarize count()
Legen Sie den Schwellenwert für die Warnung auf 20 fest.
Einzelner Computer über RPO
Richten Sie eine Warnung ein, die ausgelöst wird, wenn die RPO für eine einzelne Azure-VM 30 Minuten überschreitet.
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where isnotempty(name_s) and isnotnull(name_s)
| where name_s == "ContosoVM123"
| where rpoInSeconds_d > 1800
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| project name_s , rpoInSeconds_d
| summarize count()
Legen Sie den Schwellenwert für die Warnung auf 1 fest.
Testfailover für mehrere Computer überschreitet 90 Tage
Richten Sie eine Warnung ein, die ausgelöst wird, wenn das letzte erfolgreiche Testfailover für mehr als 20 VMs mehr als 90 Tage zurückliegt.
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where Category == "AzureSiteRecoveryReplicatedItems"
| where isnotempty(name_s) and isnotnull(name_s)
| where lastSuccessfulTestFailoverTime_t <= ago(90d)
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| summarize count()
Legen Sie den Schwellenwert für die Warnung auf 20 fest.
Testfailover für einen Computer übersteigt 90 Tage
Richten Sie eine Warnung ein, die ausgelöst wird, wenn das letzte erfolgreiche Testfailover für eine bestimmte VM mehr als 90 Tage zurückliegt.
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where Category == "AzureSiteRecoveryReplicatedItems"
| where isnotempty(name_s) and isnotnull(name_s)
| where lastSuccessfulTestFailoverTime_t <= ago(90d)
| where name_s == "ContosoVM123"
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| summarize count()
Legen Sie den Schwellenwert für die Warnung auf 1 fest.
Fehler bei Site Recovery-Auftrag
Richten Sie eine Warnung ein, wenn ein Site Recovery-Auftrag (in diesem Fall der Auftrag zum erneuten Schützen) für ein beliebiges Site Recovery-Szenario während des letzten Tages zu einem Fehler geführt hat.
AzureDiagnostics
| where Category == "AzureSiteRecoveryJobs"
| where OperationName == "Reprotect"
| where ResultType == "Failed"
| summarize count()
Legen Sie für die Warnung den Schwellenwert auf „1“ und den Zeitraum auf 1.440 Minuten fest, um alle Fehler des letzten Tags zu überprüfen.
Nächste Schritte
Erfahren Sie mehr über die integrierte Site Recovery Überwachung.