Skalierung in Service Fabric
Azure Service Fabric erleichtert das Erstellen skalierbarer Anwendungen durch Verwalten der Dienste, Partitionen und Replikate auf den Knoten eines Clusters. Das Ausführen vieler Workloads auf derselben Hardware ermöglicht eine maximale Ressourcennutzung, bietet jedoch auch Flexibilität bei der Auswahl der Skalierung für die Workloads. Dieses Channel 9-Video erklärt, wie Sie skalierbare Microserviceanwendungen erstellen können:
Die Skalierung in Service Fabric erfolgt auf verschiedene Weise:
- Skalieren durch das Erstellen oder Entfernen von zustandslosen Dienstinstanzen
- Skalieren durch das Erstellen oder Entfernen von neuen benannten Diensten
- Skalieren durch das Erstellen oder Entfernen von neuen benannten Anwendungsinstanzen
- Skalieren mithilfe partitionierter Dienste
- Skalieren durch das Hinzufügen und Entfernen von Knoten im Cluster
- Skalieren mithilfe von Metriken des Clusterressourcen-Managers
Skalieren durch das Erstellen oder Entfernen von zustandslosen Dienstinstanzen
Eine der einfachsten Methoden zum Skalieren in Service Fabric erfolgt mit zustandslosen Diensten. Wenn Sie einen zustandslosen Dienst erstellen, haben Sie die Möglichkeit zum Definieren eines InstanceCount. InstanceCount legt fest, wie viele auszuführende Kopien des Codes für den Dienst erstellt werden, wenn der Dienst gestartet wird. Nehmen wir z.B. an, dass im Cluster 100 Knoten vorhanden sind. Nehmen wir außerdem an, dass ein Dienst mit dem InstanceCount 10 erstellt wird. Möglicherweise sind alle 10 Kopien des Codes während der Laufzeit zu stark ausgelastet (oder nicht ausreichend ausgelastet). Eine Möglichkeit zum Skalieren der Workload ist das Ändern der Anzahl der Instanzen. Beispielsweise kann ein Abschnitt des Überwachungs- oder Verwaltungscodes die vorhandene Anzahl der Instanzen auf 50 erhöhen oder auf 5 verringern, je nachdem, ob die Workload entsprechend der Auslastung abskaliert oder aufskaliert werden muss.
C#:
StatelessServiceUpdateDescription updateDescription = new StatelessServiceUpdateDescription();
updateDescription.InstanceCount = 50;
await fabricClient.ServiceManager.UpdateServiceAsync(new Uri("fabric:/app/service"), updateDescription);
Mit PowerShell:
Update-ServiceFabricService -Stateless -ServiceName $serviceName -InstanceCount 50
Verwenden einer dynamischen Anzahl von Instanzen
Service Fabric bietet speziell für zustandslose Dienste ein automatisches Verfahren zum Ändern der Anzahl der Instanzen. Dies ermöglicht dem Dienst das dynamische Skalieren der Anzahl verfügbarer Knoten. Zum Aktivieren dieses Verhaltens wird die Anzahl der Instanzen auf -1 festgelegt. InstanceCount = -1 ist eine Anweisung, die Service Fabric mit dem Hinweis "Diesen zustandslosen Dienst auf jedem Knoten ausführen" angezeigt wird. Wenn sich die Anzahl der Knoten ändert, ändert Service Fabric die Anzahl der Instanzen automatisch so, dass sichergestellt wird, dass der Dienst auf allen gültigen Knoten ausgeführt wird.
C#:
StatelessServiceDescription serviceDescription = new StatelessServiceDescription();
//Set other service properties necessary for creation....
serviceDescription.InstanceCount = -1;
await fc.ServiceManager.CreateServiceAsync(serviceDescription);
Mit PowerShell:
New-ServiceFabricService -ApplicationName $applicationName -ServiceName $serviceName -ServiceTypeName $serviceTypeName -Stateless -PartitionSchemeSingleton -InstanceCount "-1"
Skalieren durch das Erstellen oder Entfernen von neuen benannten Diensten
Eine benannte Dienstinstanz ist eine bestimmte Instanz eines Diensttyps (siehe Lebenszyklus der Service Fabric-Anwendung) in einer benannten Anwendungsinstanz im Cluster.
Je nach der sich ändernden Auslastung von Diensten können neue benannte Dienstinstanzen erstellt (oder entfernt) werden. Dies ermöglicht das Verteilen von Anforderungen über weitere Dienstinstanzen, wodurch normalerweise die Auslastung vorhandener Dienste verringert werden kann. Beim Erstellen von Diensten platziert der Clusterressourcen-Manager von Service Fabric die Dienste im Cluster verteilt. Die genauen Entscheidungen unterliegen den Metriken im Cluster und weiteren Platzierungsregeln. Dienste können auf verschiedene Weise erstellt werden. Am häufigsten werden sie jedoch durch administrative Aktionen wie den Aufruf von New-ServiceFabricService oder durch Code, in dem CreateServiceAsync aufgerufen wird, erstellt. CreateServiceAsync kann auch aus anderen im Cluster ausgeführten Diensten aufgerufen werden.
Das dynamische Erstellen von Diensten kann in Szenarien jeder Art verwendet werden und ist ein allgemeines Muster. Betrachten Sie beispielsweise einen zustandsbehafteten Dienst, der einen bestimmten Workflow darstellt. In diesem Dienst treffen Aufrufe ein, die auszuführende Aufgaben darstellen, und der Dienst führt die Schritte für diesen Workflow aus und zeichnet den Fortschritt auf.
Wie können Sie diesen speziellen Dienst skalieren? Der Dienst ist möglicherweise auf irgendeine Weise mehrinstanzenfähig und akzeptiert Aufrufe und startet Schritte für viele unterschiedliche Instanzen desselben Workflows gleichzeitig. Dies kann jedoch den Code komplexer machen, da viele unterschiedliche Instanzen desselben Workflows in jeweils unterschiedlichen Phasen und von unterschiedlichen Kunden zu berücksichtigen sind. Außerdem ist weiterhin Skalierung erforderlich, auch wenn mehrere Workflows gleichzeitig behandelt werden. Der Grund dafür ist, dass der Dienst irgendwann mehr Ressourcen nutzen wird, als auf einem bestimmten Computer vorhanden sein können. Bei vielen Diensten, die nicht für dieses Muster ausgelegt sind, treten außerdem Probleme auf, da der Code einen Engpass oder eine Verlangsamung verursacht. Diese Arten von Problemen bewirken auch, dass der Dienst nicht ausgeführt wird, wenn die Anzahl der gleichzeitigen Workflows, die er nachverfolgt, zunimmt.
Zum Lösen dieser Probleme kann für jede Instanz des zu verfolgenden Workflows eine Instanz des Dienstes erstellt werden. Dies ist ein hervorragendes Muster, das sowohl für zustandslose als auch für zustandsbehaftete Dienste seinen Zweck erfüllt. Für die erfolgreiche Verwendung dieses Musters ist normalerweise ein weiterer Dienst erforderlich, der als Workload-Manager-Dienst fungiert. Dieser Dienst ist für das Empfangen von Anforderungen und das Weiterleiten dieser Anforderungen an andere Dienste verantwortlich. Der Manager kann beim Empfang der Meldung dynamisch eine Instanz des Workloaddiensts erstellen und dann Anforderungen an diese Dienste weiterleiten. Der Manager-Dienst kann auch Rückrufe empfangen, wenn der Auftrag eines bestimmten Workflowdiensts abgeschlossen ist. Wenn der Manager diese Rückrufe empfängt, kann er die betreffende Instanz des Workflowdiensts löschen oder beibehalten, falls weitere Aufrufe erwartet werden.
Erweiterte Versionen dieses Typs von Manager können sogar Pools der von ihm verwalteten Dienste erstellen. Mit dem Pool lässt sich besser sicherstellen, dass bei Eingang einer neuen Anforderung nicht bis zum Starten eines Dienstes gewartet werden muss. Stattdessen kann der Manager einfach einen Workflowdienst, der derzeit nicht ausgelastet ist, aus dem Pool auswählen oder die Anforderung nach dem Zufallsprinzip weiterleiten. Wenn ein Pool von Diensten verfügbar gehalten wird, können neue Anforderungen schneller behandelt werden, da die Wahrscheinlichkeit geringer ist, dass bis zum Starten eines neuen Diensts gewartet werden muss. Das Erstellen neuer Dienste ist eine schnelle Methode, jedoch nicht ohne Kosten und nicht verzögerungsfrei. Der Pool hilft, die Wartezeit bis zur Verarbeitung der Anforderung zu minimieren. Dieses Muster der Verwendung eines Managers und Pools ist häufig anzutreffen, wenn die Antwortzeit Priorität hat. Die Anforderung in die Warteschlange zu stellen, den Dienst im Hintergrund zu erstellen und ihn anschließend weiterzuleiten ist ebenfalls ein beliebtes Muster unter Verwendung eines Managers; ebenso das Erstellen und Löschen von Diensten anhand der Nachverfolgung der derzeit ausstehenden Arbeitsmenge des Diensts.
Skalieren durch das Erstellen oder Entfernen von neuen benannten Anwendungsinstanzen
Das Erstellen und Löschen gesamter Anwendungsinstanzen ist ein ähnliches Muster wie das Erstellen und Löschen von Diensten. In diesem Muster erfolgt die Entscheidung durch einen Manager-Dienst auf Grundlage der erkannten Anforderungen und der Informationen, die er von anderen Diensten im Cluster empfängt.
Wann sollte eine neue benannte Anwendungsinstanz erstellt werden, statt neue benannte Dienstinstanzen in einer bereits vorhandenen Anwendung zu erstellen? Hier sind einige Fälle:
- Die neue Anwendungsinstanz ist für einen Kunden, dessen Code unter bestimmten Identitäts- oder Sicherheitseinstellungen ausgeführt werden muss.
- Service Fabric ermöglicht es, das Ausführen unterschiedlicher Codepakete unter bestimmten Identitäten festzulegen. Um dasselbe Codepaket unter verschiedenen Identitäten zu starten, müssen die Aktivierungen in unterschiedlichen Anwendungsinstanzen erfolgen. Betrachten Sie einen Fall, in dem Sie die Workloads eines vorhandenen Kunden bereitgestellt haben. Diese werden möglicherweise unter einer bestimmten Identität ausgeführt, sodass Sie ihren Zugriff auf andere Ressourcen, z.B. Remotedatenbanken oder andere Systeme, überwachen und steuern können. Wenn sich in diesem Fall ein neuer Kunde registriert, möchten Sie dessen Code wahrscheinlich nicht in demselben Kontext (Prozessraum) aktivieren. Dies ist zwar möglich, es erschwert jedoch das Ausführen des Dienstcodes im Kontext einer bestimmten Identität. In der Regel benötigen Sie mehr Code für die Sicherheits-, Isolations- und Identitätsverwaltung. Statt unterschiedliche benannte Dienstinstanzen in derselben Anwendungsinstanz und somit in demselben Prozessraum zu verwenden, können Sie unterschiedliche benannte Service Fabric-Anwendungsinstanzen verwenden. Dies erleichtert das Definieren unterschiedlicher Identitätskontexte.
- Die neue Anwendungsinstanz dient auch als Möglichkeit zur Konfiguration.
- Standardmäßig werden alle benannten Dienstinstanzen eines bestimmten Diensttyps in einer Anwendungsinstanz in demselben Prozess auf einem bestimmten Knoten ausgeführt. Deshalb ist es zwar möglich, jede Instanz unterschiedlich zu konfigurieren, jedoch ist dies kompliziert. Dienste benötigen ein Token, anhand dessen sie ihre Konfiguration in einem Konfigurationspaket suchen. In der Regel ist dies einfach der Name des Diensts. Dies ist problemlos möglich, jedoch wird dabei die Konfiguration mit den Namen der einzelnen benannten Dienstinstanzen in der Anwendungsinstanz verknüpft. Dies kann verwirrend und schwierig zu verwalten sein, da die Konfiguration normalerweise ein Entwurfszeitartefakt mit speziellen Werten für die jeweilige Anwendungsinstanz ist. Das Erstellen weiterer Werte erfordert stets weitere Anwendungsupgrades, um die Informationen in den Konfigurationspaketen zu ändern oder neue Konfigurationspakete bereitzustellen, damit die neuen Dienste ihre spezifischen Informationen suchen können. Häufig ist es einfacher, eine völlig neue benannte Anwendungsinstanz zu erstellen. Anschließend können Sie mit den Anwendungsparametern die für die Dienste erforderliche Konfiguration festlegen. So können alle in dieser benannten Anwendungsinstanz erstellten Dienste bestimmte Konfigurationseinstellungen erben. Beispielsweise haben Sie dann statt einer einzelnen Konfigurationsdatei mit den Einstellungen und Anpassungen für jeden Kunden, z.B. Geheimnisse oder Ressourcenlimits pro Kunde, für jeden Kunden eine andere Anwendungsinstanz, in der diese Einstellungen überschrieben werden.
- Die neue Anwendung fungiert als Upgradegrenze.
- In Service Fabric fungieren unterschiedliche benannte Anwendungsinstanzen als Grenzen für Upgrades. Ein Upgrade einer benannten Anwendungsinstanz hat keine Auswirkung auf den Code, der von einer anderen benannten Anwendungsinstanz ausgeführt wird. Die verschiedenen Anwendungen führen nach dem Upgrade unterschiedliche Versionen desselben Codes auf demselben Knoten aus. Dies kann ein Faktor bei der Auswahl der Skalierungsmethode sein, da Sie wählen können, ob der Code an die Upgrades eines anderen Diensts angepasst werden soll. Nehmen wir beispielsweise an, dass ein Aufruf bei dem Manager-Dienst eintrifft, der die Workloads eines bestimmten Kunden durch das dynamische Erstellen und Löschen von Diensten skaliert. In diesem Fall erfolgt der Aufruf jedoch für eine Workload, die einem neuen Kunden zugeordnet ist. Die meisten Kunden legen Wert darauf, von anderen Kunden isoliert zu sein, und zwar nicht nur aus den oben aufgeführten Sicherheits- und Konfigurationsgründen. Die Isolation bietet auch eine höhere Flexibilität, da bestimmte Versionen der Software ausgeführt werden können und der Zeitpunkt ihres Upgrades frei gewählt werden kann. Sie können auch eine neue Anwendungsinstanz erstellen und in dieser den Dienst erstellen, einfach um genauer die Anzahl der Dienste festzulegen, die von einem Upgrade betroffen sind. Getrennte Anwendungsinstanzen bieten eine höhere Granularität bei Anwendungsupgrades und ermöglichen zudem A/B-Tests und Blue-Green-Deployments.
- Die vorhandene Anwendungsinstanz ist voll.
- In Service Fabric können Sie mit dem Konzept der Anwendungskapazität die Menge der Ressourcen steuern, die für bestimmte Anwendungsinstanzen verfügbar sind. Beispielsweise können Sie entscheiden, dass zum Skalieren eine weitere Instanz eines bestimmten Diensts erstellt werden muss. Allerdings verfügt diese Anwendungsinstanz über keine weitere Kapazität für eine bestimmte Metrik. Wenn dem betreffenden Kunden oder der betreffenden Workload noch mehr Ressourcen gewährt werden sollen, können Sie die vorhandene Kapazität für diese Anwendung erhöhen oder eine neue Anwendung erstellen.
Skalieren auf Partitionsebene
Service Fabric unterstützt die Partitionierung. Durch Partitionierung wird ein Dienst in mehrere logische und physische Abschnitte unterteilt, von denen jeder eigenständig ausgeführt wird. Dies ist für zustandsbehaftete Dienste hilfreich, da kein Satz Replikate alle Aufrufe auf einmal behandeln und alle Zustände auf einmal ändern muss. Die Übersicht über die Partitionierung enthält Informationen zu den Typen von Partitionierungsschemas, die unterstützt werden. Die Replikate der einzelnen Partitionen sind auf die Knoten in einem Cluster verteilt. Dabei wird auch die Auslastung des Diensts verteilt und sichergestellt, dass weder der Dienst als Ganzes noch irgendeine Partition einen Single Point of Failure aufweist.
Angenommen, ein Dienst verwendet das Bereichspartitionierungsschema mit einem niedrigen Schlüssel 0, einem hohen Schlüssel 99 und 4 Partitionen. In einem Drei-Knoten-Cluster kann der Dienst mit vier Replikaten, welche die Ressourcen auf den einzelnen Knoten gemeinsam nutzen, wie in der folgenden Abbildung gezeigt ausgelegt werden.
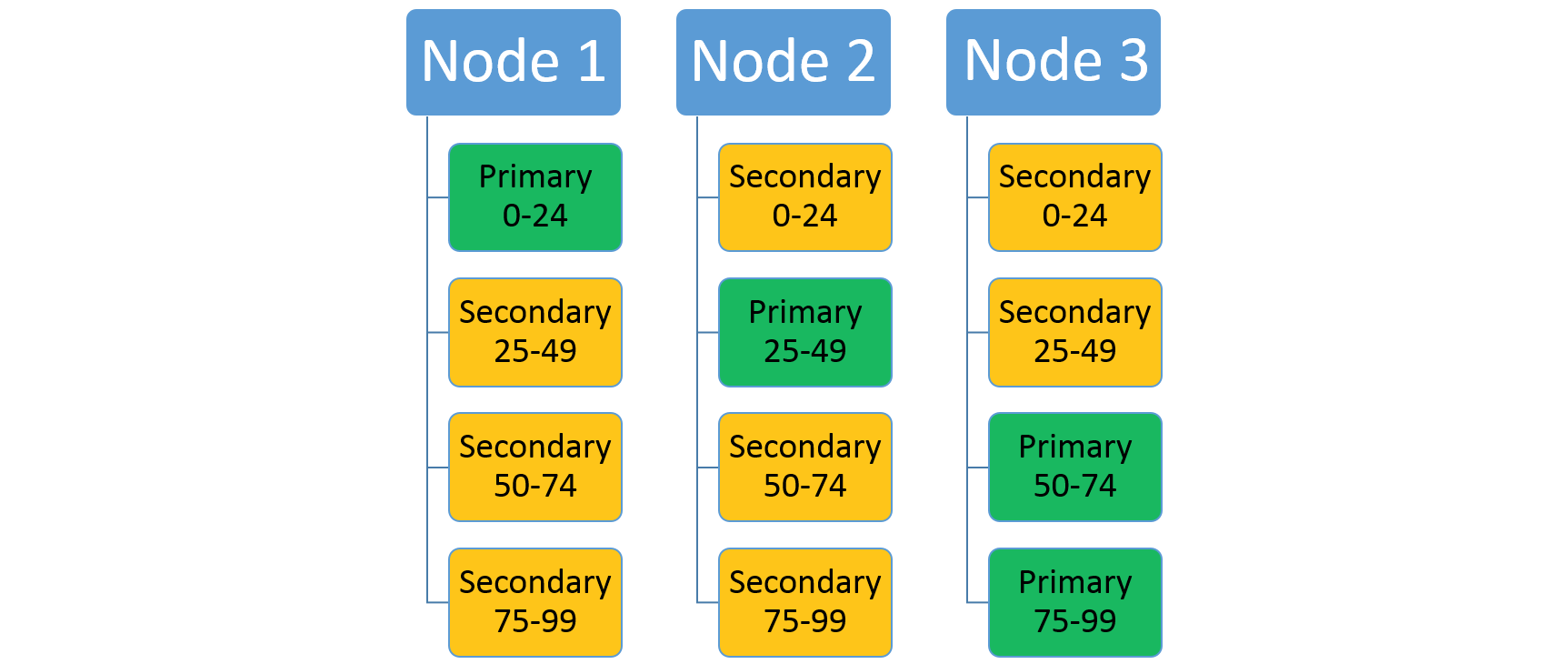
Wenn Sie die Anzahl der Knoten erhöhen, werden einige der vorhandenen Replikate von Service Fabric dorthin verschoben. Nehmen wir beispielsweise an, dass sich die Anzahl der Knoten auf vier erhöht und die Replikate neu verteilt werden. Der Dienst verfügt jetzt über drei Replikate, die auf jedem Knoten ausgeführt werden und jeweils zu unterschiedlichen Partitionen gehören. Dies ermöglicht eine bessere Ressourcennutzung, da der neue Knoten aktiv ist. In der Regel verbessert dies auch die Leistung, da für jeden Dienst mehr Ressourcen verfügbar sind.
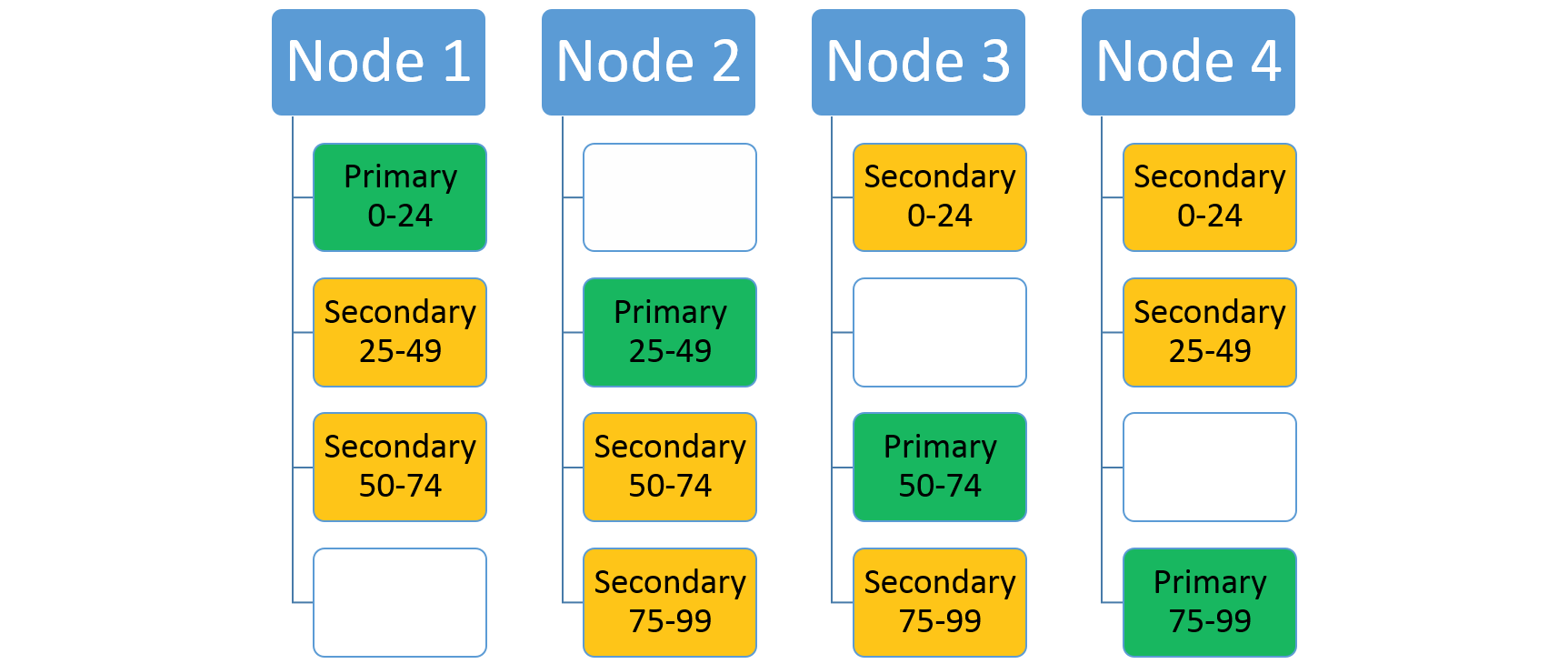
Skalierung mithilfe des Clusterressourcen-Managers von Service Fabric und mithilfe von Metriken
Service Fabric erhält durch Metriken Informationen zum Ressourcenverbrauch der Dienste. Metriken ermöglichen es dem Clusterressourcen-Manager, das Layout des Clusters neu zu organisieren und zu optimieren. Beispielsweise enthält der Cluster eventuell viele Ressourcen, diese werden jedoch nicht den Diensten zugeordnet, die derzeit ausgeführt werden. Metriken ermöglichen dem Clusterressourcen-Manager das Neuorganisieren des Clusters, um sicherzustellen, dass Dienste Zugriff auf die verfügbaren Ressourcen haben.
Skalieren durch das Hinzufügen und Entfernen von Knoten im Cluster
Eine weitere Möglichkeit der Skalierung mit Service Fabric ist das Ändern der Clustergröße. Zum Ändern der Clustergröße müssen Knoten eines oder mehrere Knotentypen im Cluster hinzugefügt oder entfernt werden. Betrachten Sie beispielsweise den Fall, in dem alle Knoten im Cluster aktiv sind. Dies bedeutet, dass fast alle Ressourcen des Clusters genutzt werden. In diesem Fall ist das Hinzufügen weiterer Knoten zum Cluster die beste Skalierungsmethode. Sobald dem Cluster neue Knoten hinzugefügt wurden, verschiebt der Clusterressourcen-Manager von Service Fabric Dienste auf diese Knoten, sodass die Gesamtauslastung der vorhandenen Knoten verringert wird. Für zustandslose Dienste mit der Instanzenanzahl -1 werden automatisch weitere Dienstinstanzen erstellt. Dies ermöglicht das Verschieben einiger Aufrufe von den vorhandenen Knoten zu den neuen Knoten.
Weitere Informationen finden Sie unter Scaling Service Fabric clusters (Skalieren von Service Fabric-Clustern).
Auswählen einer Plattform
Aufgrund von Implementierungsunterschieden zwischen Betriebssystemen kann die Entscheidung, Service Fabric mit Windows oder Linux zu verwenden, ein wichtiger Punkt für die Skalierung Ihrer Anwendung sein. Ein mögliches Hindernis stellt die Art der Stagingprotokollierung dar. Service Fabric unter Windows verwendet einen Kerneltreiber für ein computerspezifisches Protokoll, das von zustandsbehafteten Dienstreplikaten gemeinsam genutzt wird. Dieses Protokoll hat eine Größe von etwa 8 GB. Linux verwendet dagegen für jedes Replikat ein Stagingprotokoll mit einer Größe von 256 MB und eignet sich somit weniger für Anwendungen, bei denen auf einem Knoten möglichst viele einfache Dienstreplikate ausgeführt werden sollen. Diese Unterschiede bei den temporären Speicheranforderungen können bei der Wahl der Plattform für die Service Fabric-Clusterbereitstellung entscheidend sein.
Zusammenfügen des Gesamtbilds
Sehen wir uns alle Ideen, die wir hier besprochen haben, in einem Beispiel an. Betrachten Sie den folgenden Dienst: Sie möchten einen Dienst erstellen, der als Adressbuch fungiert und Namen und Kontaktinformationen speichert.
Bereits im Voraus stellt sich Ihnen eine Reihe von Fragen zur Skalierung: Wie viele Benutzer werden ihn verwenden? Wie viele Kontakte werden von den einzelnen Benutzern gespeichert? All diese Informationen gleich bei der ersten Erstellung des Diensts herauszufinden, ist schwierig. Angenommen, Sie möchten einen einzelnen statischen Dienst mit einer bestimmten Partitionsanzahl verwenden. Wenn Sie die falsche Partitionsanzahl wählen, könnte dies später zu Skalierungsproblemen führen. Auch wenn Sie die richtige Anzahl wählen, haben Sie möglicherweise nicht alle Informationen, die Sie benötigen. Beispielsweise müssen Sie auch die Größe des Clusters im Voraus festlegen, sowohl bezüglich der Anzahl der Knoten als auch bezüglich ihrer jeweiligen Größe. Es ist in der Regel schwer vorherzusagen, wie viele Ressourcen ein Dienst während seiner Lebensdauer nutzen wird. Es kann auch schwierig sein, im Voraus zu wissen, welches Datenverkehrsmuster im Dienst tatsächlich auftritt. Eventuell erfolgt das Hinzufügen und Entfernen von Kontakten durch Benutzer nur zu Arbeitsbeginn am Morgen, oder es ist gleichmäßig über den gesamten Tag verteilt. Basierend auf diesen Informationen müssen Sie möglicherweise dynamisch aufskalieren und abskalieren. Vielleicht lernen Sie vorherzusagen, wann aufskaliert und abskaliert werden muss. In jedem Fall ist jedoch zu erwarten, dass Sie auf Änderungen beim Ressourcenverbrauch des Diensts reagieren müssen. Dies kann das Ändern der Clustergröße erfordern, um weitere Ressourcen bereitzustellen, wenn das Neuorganisieren vorhandener Ressourcen nicht ausreicht.
Aber warum sollte man überhaupt versuchen, für alle Benutzer ein einzelnes Partitionsschema auszuwählen? Warum beschränken Sie sich auf einen einzelnen Dienst und einen einzelnen statischen Cluster? Die reale Situation ist in der Regel dynamischer.
Ziehen Sie beim Planen der Skalierung das folgende dynamische Muster in Betracht. Möglicherweise müssen Sie es an Ihre Situation anpassen:
- Statt zu versuchen, im Vorfeld für jeden ein Partitionierungsschema auswählen, erstellen Sie einen „Manager-Dienst“.
- Der Auftrag des Manager-Diensts besteht darin, die Informationen von Kunden zu prüfen, wenn diese sich für Ihren Dienst registrieren. Abhängig von diesen Informationen erstellt der Manager-Dienst dann eine Instanz Ihres eigentlichen Kontaktspeicherdiensts nur für diesen Kunden. Wenn dieser eine besondere Konfiguration, Isolation oder besondere Upgrades benötigt, können Sie auch eine Anwendungsinstanz für diesen starten.
Dieses dynamische Erstellungsmuster bietet viele Vorteile:
- Sie versuchen nicht, im Voraus die richtige Partitionsanzahl für alle Benutzer zu erraten oder einen einzelnen Dienst zu erstellen, der unbeschränkt und autonom skalierbar ist.
- Es ist nicht erforderlich, dass unterschiedliche Benutzer über die gleiche Partitionsanzahl, Replikatanzahl, die gleichen Platzierungseinschränkungen, Metriken, Standardauslastungen, Dienstnamen, DNS-Einstellungen oder sonstige identische Eigenschaften verfügen, die auf Dienst- oder Anwendungsebene angegeben werden.
- Sie gewinnen zusätzliche Datensegmentierung. Jeder Kunde besitzt eine eigene Kopie des Diensts.
- Die Dienste bei den einzelnen Kunden können unterschiedlich konfiguriert werden, und ihnen können entsprechend der erwarteten Skalierung mehr oder weniger Ressourcen gewährt werden, mit mehr oder weniger Partitionen oder Replikaten.
- Nehmen wir beispielsweise an, der Kunde hat die Ebene „Gold“ erworben. Dann erhält er mehr Replikate und eine größere Partitionsanzahl sowie über Metriken und Anwendungskapazitäten potenziell fest zugeordnete Ressourcen für seine Dienste.
- Alternativ hat der Kunde vielleicht Informationen angegeben, aus denen hervorgeht, dass nur eine geringe Anzahl von Kontakten benötigt wird. In diesem Fall werden ihm nur wenige Partitionen zugeteilt, oder er muss zusammen mit anderen Kunden einen gemeinsamen Pool von Diensten nutzen.
- Die Dienste bei den einzelnen Kunden können unterschiedlich konfiguriert werden, und ihnen können entsprechend der erwarteten Skalierung mehr oder weniger Ressourcen gewährt werden, mit mehr oder weniger Partitionen oder Replikaten.
- Sie führen nicht schon eine Reihe von Dienstinstanzen oder Replikaten aus, während Sie auf Kunden warten.
- Wenn ein Kunde Sie verlässt, können dessen Informationen aus Ihrem Dienst ganz einfach von dem Manager entfernt werden, der den Dienst oder die Anwendung erstellt hat.
Nächste Schritte
Weitere Informationen zu den Service Fabric-Konzepten finden Sie in den folgenden Artikeln: