Replikate und Instanzen
Dieser Artikel bietet einen Überblick über den Lebenszyklus von Replikaten zustandsbehafteter Dienste und Instanzen zustandsloser Dienste.
Instanzen zustandsloser Dienste
Eine Instanz eines zustandslosen Diensts ist eine Kopie der Dienstlogik, die auf einem der Knoten des Clusters ausgeführt wird. Eine Instanz innerhalb einer Partition wird durch die InstanceId eindeutig identifiziert. Der Lebenszyklus einer Instanz ist in der folgenden Abbildung dargestellt:
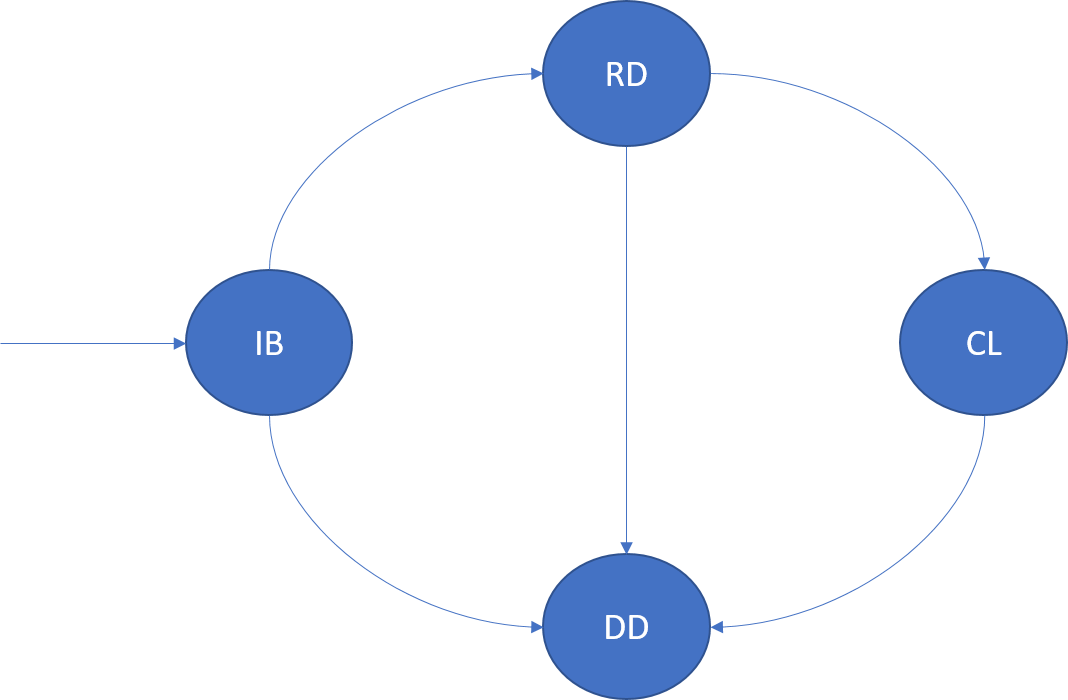
InBuild (IB)
Nachdem der Cluster Resource Manager eine Platzierung für die Instanz bestimmt hat, erhält sie diesen Lebenszykluszustand. Die Instanz wird auf dem Knoten gestartet. Der Anwendungshost wird gestartet, die Instanz wird erstellt und dann geöffnet. Nach dem Start geht die Instanz in den Zustand „Bereit“ über.
Wenn der Anwendungshost oder Knoten für diese Instanz abstürzt, geht sie in den Zustand „Verworfen“ über.
Bereit (Ready, RD)
Im Zustand „Bereit“ wird die Instanz auf dem Knoten ausgeführt. Wenn es sich bei dieser Instanz um einen zuverlässigen Dienst handelt, wurde RunAsync aufgerufen.
Wenn der Anwendungshost oder Knoten für diese Instanz abstürzt, geht sie in den Zustand „Verworfen“ über.
Schließen (Closing, CL)
Im Zustand „Schließen“ fährt Azure Service Fabric die Instanz auf diesem Knoten herunter. Dafür kommen zahlreiche Ursachen infrage, z.B. Anwendungsupgrades, Lastenausgleich oder das Löschen des Diensts. Nachdem das Herunterfahren abgeschlossen ist, geht die Instanz in den Zustand „Verworfen“ über.
Verworfen (Dropped, DD)
Im Zustand „Verworfen“ wird die Instanz nicht mehr auf dem Knoten ausgeführt. An diesem Punkt behält Service Fabric die Metadaten über diese Instanz bei, die schließlich ebenfalls gelöscht werden.
Hinweis
Mithilfe der Option ForceRemove unter Remove-ServiceFabricReplica ist jederzeit der Übergang von einem beliebigen Zustand in den Zustand „Verworfen“ möglich.
Replikate zustandsbehafteter Dienste
Eine Instanz eines zustandsbehafteten Diensts ist eine Kopie der Dienstlogik, die auf einem der Knoten des Clusters ausgeführt wird. Darüber hinaus behält das Replikat eine Kopie des Zustands dieses Diensts bei. Zwei verwandte Konzepte beschreiben den Lebenszyklus und das Verhalten zustandsbehafteter Replikate:
- Replikatlebenszyklus
- Replikatrolle
Im Folgenden werden persistierte zustandsbehaftete Dienste erläutert. Für flüchtige (oder im Arbeitsspeicher befindliche) zustandsbehaftete Dienste sind die Zustände „Ausgefallen“ und „Verworfen“ äquivalent.
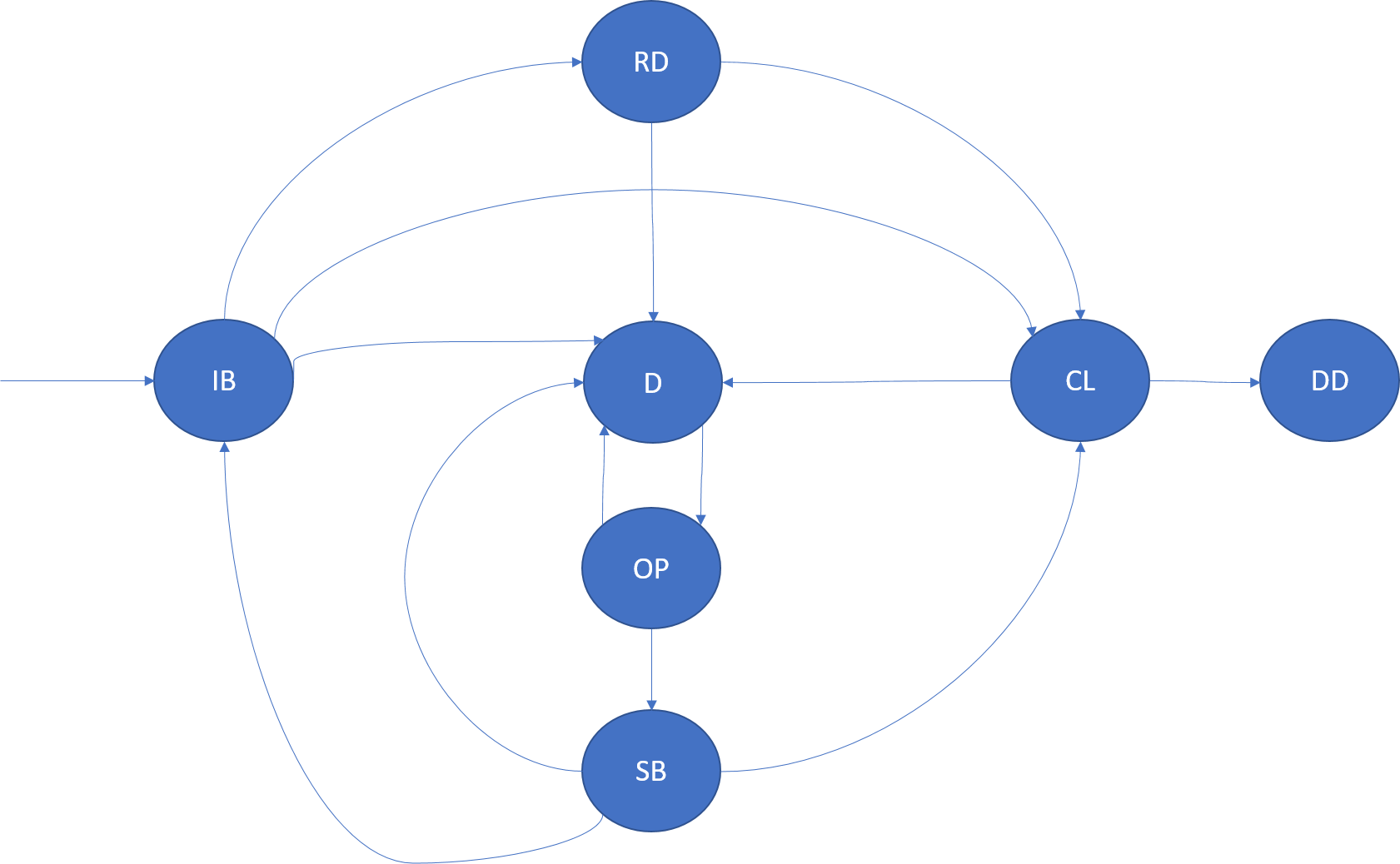
InBuild (IB)
Ein InBuild-Replikat ist ein Replikat, das erstellt oder für das Hinzufügen zur Replikatgruppe vorbereitet wird. Abhängig von der Replikatrolle unterscheidet sich die Semantik von IB.
Wenn der Anwendungshost oder der Knoten für ein InBuild-Replikat abstürzt, geht es in den Zustand „Ausgefallen“ über.
Primäre InBuild-Replikate: Primäre InBuild-Replikate sind die ersten Replikate für eine Partition. Diese Replikate werden normalerweise verwendet, wenn die Partition erstellt wird. Primäre InBuild-Replikate entstehen auch, wenn alle Replikate einer Partition neu gestartet oder verworfen werden.
IdleSecondary-InBuild-Replikate: Hierbei handelt es sich entweder um neue Replikate, die vom Cluster Resource Manager erstellt werden, oder um vorhandene Replikate, die ausgefallen sind und wieder der Gruppe hinzugefügt werden müssen. Diese Replikate werden vom primären Replikat mit Anfangsdaten gefüllt oder erstellt, bevor sie der Replikatgruppe als ActiveSecondary hinzugefügt werden und an der Quorumsbestätigung von Vorgängen teilnehmen können.
ActiveSecondary-InBuild-Replikate: Dieser Zustand wird bei einigen Abfragen beobachtet. Er ist eine Optimierung, bei der die Replikatgruppe nicht geändert wird, aber ein Replikat erstellt werden muss. Das Replikat selbst folgt den normalen Zustandscomputerübergängen (wie im Abschnitt für Replikatrollen beschrieben).
Bereit (Ready, RD)
Ein Replikat mit dem Status „Bereit“ ist ein Replikat, das an der Replikation und an Quorumsbestätigungen von Vorgängen beteiligt ist. Der Zustand „Bereit“ gilt für primäre und aktive sekundäre Replikate.
Wenn der Anwendungshost oder der Knoten für ein Replikat mit dem Status „Bereit“ abstürzt, geht es in den Zustand „Ausgefallen“ über.
Schließen (Closing, CL)
Ein Replikat wechselt in den folgenden Szenarien in den Zustand „Schließen“:
Herunterfahren des Codes für das Replikat: Service Fabric muss möglicherweise den ausgeführten Code für ein Replikat herunterfahren. Hierfür kommen viele Gründe infrage, beispielsweise ein Anwendungs-, Fabric- oder Infrastrukturupgrade oder ein vom Replikat gemeldeter Fehler. Wenn das Replikat geschlossen ist, geht es in den Zustand „Ausgefallen“ über. Der auf dem Datenträger gespeicherte, diesem Replikat zugeordnete persistente Zustand wird nicht bereinigt.
Entfernen des Replikats aus dem Cluster: Service Fabric muss möglicherweise den persistenten Zustand entfernen und den ausgeführten Code für ein Replikat herunterfahren. Hierfür kommen viele Gründe infrage, z.B. ein Lastenausgleich.
Verworfen (Dropped, DD)
Im Zustand „Verworfen“ wird die Instanz nicht mehr auf dem Knoten ausgeführt. Es ist auch kein Zustand auf dem Knoten verblieben. An diesem Punkt behält Service Fabric die Metadaten über diese Instanz bei, die schließlich ebenfalls gelöscht werden.
Ausgefallen (Down, D)
Im Zustand „Ausgefallen“ wird der Replikatcode nicht ausgeführt, aber der persistente Zustand für dieses Replikat ist auf diesem Knoten vorhanden. Ein Replikat kann aus zahlreichen Gründen ausgefallen sein, z.B. Knotenausfall, Absturz im Replikatcode, Anwendungsupgrade oder Replikatfehler.
Ein ausgefallenes Replikat wird nach Bedarf von Service Fabric geöffnet, z.B. wenn das Upgrade auf dem Knoten abgeschlossen ist.
Die Replikatrolle ist im Zustand „Ausgefallen“ nicht relevant.
Öffnen (Opening, OP)
Ein ausgefallenes Replikat wechselt in den Zustand „Öffnen“, wenn Service Fabric das Replikat wieder aufrufen muss. Dies kann z.B. nach Abschluss eines Codeupgrades für die Anwendung auf einem Knoten der Fall sein.
Wenn der Anwendungshost oder der Knoten für ein sich öffnendes Replikat abstürzt, geht es in den Zustand „Ausgefallen“ über.
Die Replikatrolle ist im Zustand „Öffnen“ nicht relevant.
StandBy (SB)
Ein StandBy-Replikat ist ein Replikat eines persistierten Diensts, das ausgefallen ist und dann geöffnet wurde. Dieses Replikat kann von Service Fabric verwendet werden, wenn der Replikatgruppe ein anderes Replikat hinzugefügt werden muss (da es bereits einen Teil des Zustands hat und der Erstellungsprozess schneller ist). Nach Ablauf von StandByReplicaKeepDuration wird das StandBy-Replikat verworfen.
Wenn der Anwendungshost oder der Knoten für ein StandBy-Replikat abstürzt, geht es in den Zustand „Ausgefallen“ über.
Die Replikatrolle ist im Zustand „StandBy“ nicht relevant.
Hinweis
Alle Replikate, die nicht ausgefallen oder verworfen sind, gelten als aktiv.
Hinweis
Mithilfe der Option ForceRemove unter Remove-ServiceFabricReplica ist jederzeit der Übergang von einem beliebigen Zustand in den Zustand „Verworfen“ möglich.
Replikatrolle
Die Rolle des Replikats bestimmt seine Funktion in der Replikatgruppe:
- Primär (P): Es gibt ein primäres Replikat in der Replikatgruppe, das für die Ausführung von Lese- und Schreibvorgängen verantwortlich ist.
- ActiveSecondary (S): Hierbei handelt es sich um Replikate, die Zustandsupdates vom primären Replikat empfangen, anwenden und dann Bestätigungen senden. In der Replikatgruppe sind mehrere aktive sekundäre Replikate vorhanden. Die Anzahl dieser aktiven sekundären Replikate bestimmt die Anzahl der Fehler, die der Dienst verarbeiten kann.
- IdleSecondary (I): Diese Replikate werden von dem primären Replikat erstellt. Sie empfangen den Zustand vom primären Replikat, bevor sie zum aktiven sekundären Replikat heraufgestuft werden können.
- Kein (N): Diese Replikate haben in der Replikatgruppe keine Zuständigkeit.
- Unbekannt (U): Dies ist die erste Rolle eines Replikats, bevor es den ChangeRole-API-Aufruf von Service Fabric empfängt.
In der folgenden Abbildung sind die Replikatrollenübergänge und einige Beispielszenarien dargestellt, in denen sie auftreten können:
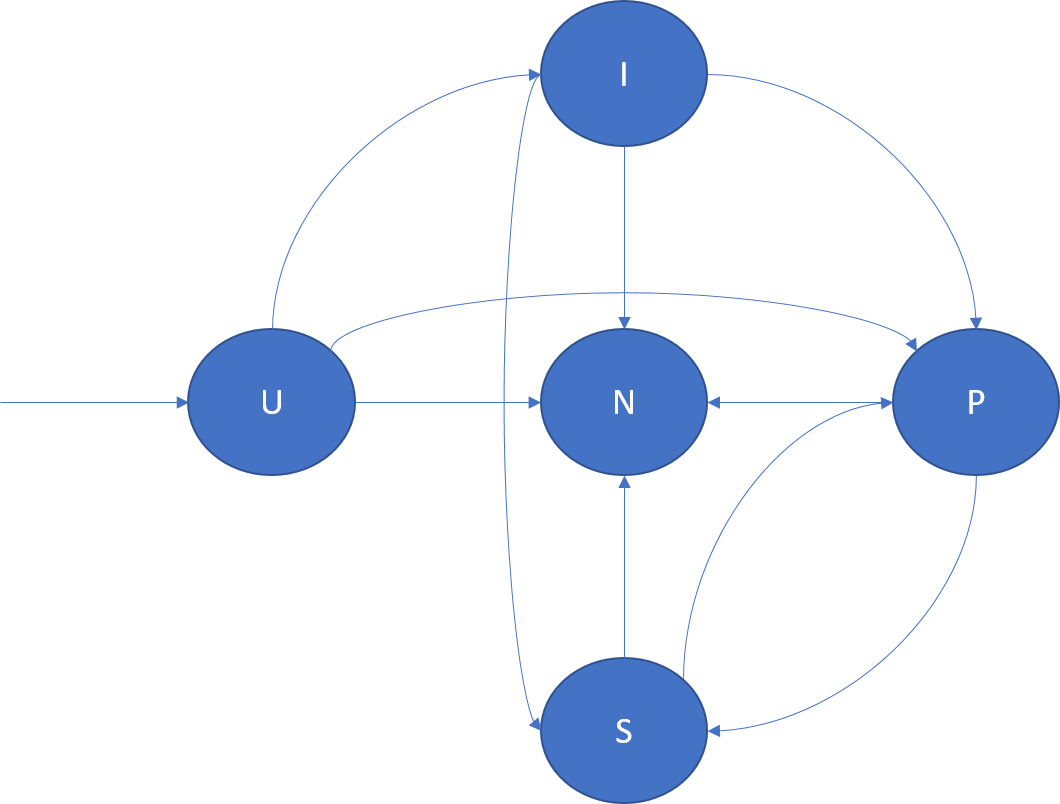
- U -> P: Erstellen eines neuen primären Replikats
- U -> I: Erstellen eines neuen im Leerlauf befindlichen Replikats
- U -> N: Löschen eines Standbyreplikats
- I -> S: Höherstufen des im Leerlauf befindlichen sekundären Replikats zum aktiven sekundären Replikat, sodass es die Teilnahme gegenüber dem Quorum bestätigt
- I -> P: Höherstufen des im Leerlauf befindlichen sekundären Replikats zum primären Replikat. Dies kann bei speziellen Neukonfigurationen vorkommen, wenn das im Leerlauf befindliche sekundäre Replikat der richtige Kandidat für das primäre Replikat ist.
- I -> N: Löschen des im Leerlauf befindlichen sekundären Replikats
- S -> P: Höherstufen des aktiven sekundären Replikats zum primären Replikat. Dies kann aufgrund eines Failovers des primären Replikats oder einer durch den Cluster Resource Manager initiierten Verschiebung der Fall sein. Beispielsweise kann dies eine Reaktion auf ein Anwendungsupgrade oder einen Lastenausgleich sein.
- S -> N: Löschen des aktiven sekundären Replikats
- P -> S: Herabstufen des primären Replikats. Dies kann aufgrund einer durch den Cluster Resource Manager initiierten Verschiebung des primären Replikats der Fall sein. Beispielsweise kann dies eine Reaktion auf ein Anwendungsupgrade oder einen Lastenausgleich sein.
- P -> N: Löschen des primären Replikats.
Hinweis
In komplexen Programmiermodellen, wie z.B. Reliable Actors und Reliable Services, ist das Konzept der Replikatrolle vor den Entwicklern verborgen. Bei „Reliable Actors“ sind Rollen unnötig. In „Reliable Services“ sind sie in den meisten Szenarien stark vereinfacht.
Nächste Schritte
Weitere Informationen zu den Service Fabric-Konzepten finden Sie im folgenden Artikel: