Upgrade und Update von Azure Service Fabric-Clustern
Ein Azure Service Fabric-Cluster ist eine Ressource, die Sie besitzen, die jedoch teilweise von Microsoft verwaltet wird. In diesem Artikel werden die Optionen zum Zeitpunkt und zur Art der Aktualisierung Ihres Azure Service Fabric-Clusters beschrieben.
Automatische im Vergleich zu manuellen Upgrades
Es ist kritische, sicherzustellen, dass in Ihrem Service Fabric-Cluster immer eine unterstützte Runtime-Version ausgeführt wird. Bei jeder Ankündigung von Microsoft zu einer neuen Service Fabric-Version beträgt die verbleibende Supportdauer der vorherigen Version noch mindestens 60 Tage. Neue Releases werden im Blog des Service Fabric-Teams angekündigt.
14 Tage vor Ablauf der in Ihrem Cluster verwendeten Version wird ein Integritätsereignis generiert, das den Cluster in einen Warnzustand versetzt. Der Cluster bleibt so lange in dem Warnzustand, bis Sie ein Upgrade auf eine unterstützte Runtime-Version durchführen.
Sie können für Ihren Cluster festlegen, dass er automatische Service Fabric-Upgrades erhält, sobald Sie von Microsoft freigegeben werden, oder Sie können manuell aus einer Liste der derzeit unterstützten Versionen auswählen. Diese Optionen sind im Abschnitt Fabric-Upgrades Ihrer Service Fabric-Clusterressource verfügbar.
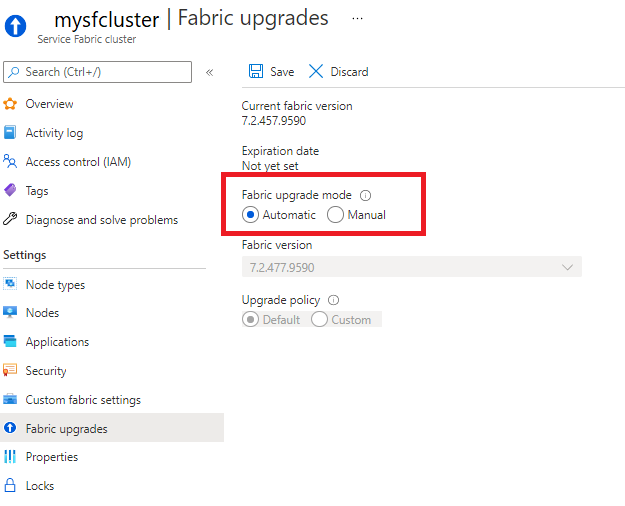
Sie können auch Upgrademodus Ihres Clusters festlegen und eine Runtime-Version auswählen, indem Sie eine Resource Manager-Vorlage verwenden.
Automatische Upgrades sind der empfohlene Upgrademodus, da diese Option sicherstellt, dass Ihr Cluster in einem unterstützten Zustand bleibt, von den neuesten Fixes und Features profitiert und Ihnen gleichzeitig erlaubt, Updates auf eine Weise zu planen, bei der Ihre Workloads dank einer Bereitstellungsstrategie in Zyklen am wenigsten gestört werden.
Hinweis
Wenn Sie einen bestehenden Cluster in den automatischen Modus ändern, wird der Cluster für den nächsten Upgrade-Zeitraum, der mit einer neuen Version beginnt, registriert. Neue Releases werden im Blog des Service Fabric-Teams angekündigt. Pro Upgrade-Periode wird der höchstmögliche Upgrade-Pfad gewählt, siehe unterstützte Versionen. Der manuelle Upgrade-Modus löst ein sofortiges Upgrade aus.
Bereitstellung in Zyklen für automatische Upgrades
Mit der Bereitstellung in Zyklen können Sie die Unterbrechung, die ein Upgrade Ihrem Cluster zufügt, minimieren, indem Sie je nach Workload den Ausgereiftheitsgrad eines Upgrades auswählen. Sie können zum Beispiel einen Test einrichten ->Stage ->Production wave deployment pipeline für Ihre verschiedenen Service Fabric-Cluster, um die Kompatibilität eines Runtime-Upgrades zu testen, bevor Sie es auf Ihre Produktions-Workloads anwenden.
Um die Bereitstellung in Zyklen zu abonnieren, geben Sie einen der folgenden Zykluswerte („Wave“) für Ihren Cluster an (in seiner Bereitstellungsvorlage):
- Wave 0: Cluster werden aktualisiert, sobald ein neuer Service Fabric-Build freigegeben wird. Für Test/Dev-Cluster vorgesehen.
- Wave 1: Cluster werden eine Woche (sieben Tage), nachdem ein neuer Build freigegeben wurde, aktualisiert. Für Vorproduktions-/Stagingcluster vorgesehen.
- Wave 2: Cluster werden zwei Wochen (14 Tage), nachdem ein neuer Build freigegeben wurde, aktualisiert. Für Produktionscluster vorgesehen.
Sie können sich für E-Mail-Benachrichtigungen registrieren, die Links zu weiterer Hilfe enthalten, wenn ein Clusterupgrade fehlschlägt. Informationen zu den ersten Schritten finden Sie unter Bereitstellung in Zyklen für automatische Upgrades.
Phasen eines automatischen Upgrades
Microsoft verwaltet den Service Fabric-Runtime-Code und die Konfiguration, die in einem Azure-Cluster ausgeführt werden. Wir führen bei Bedarf automatisch überwachte Upgrades an der Software durch. Diese Upgrades können sich auf den Code, die Konfiguration oder beides beziehen. Um die Auswirkungen dieser Upgrades auf Ihre Anwendungen zu minimieren, werden sie in den folgenden Phasen ausgeführt:
Phase 1: Ein Upgrade erfolgt unter Einhaltung aller Integritätsrichtlinien für den Cluster.
In dieser Phase erfolgen die Upgrades nacheinander in den einzelnen Upgradedomänen. Die Anwendungen, die im Cluster ausgeführt wurden, werden ohne Ausfallzeit fortgesetzt. Die Clusterintegritätsrichtlinien (für Knoten- und Anwendungsintegrität) werden während des Upgrades befolgt.
Wenn die Clusterintegritätsrichtlinien nicht erfüllt sind, wird für das Upgrade ein Rollback ausgeführt, und es wird eine E-Mail an den Besitzer des Abonnements gesendet. Die E-Mail enthält folgende Informationen:
- Benachrichtigung, dass wir ein Clusterupgrade zurücksetzen mussten.
- Vorgeschlagene Abhilfemaßnahmen, falls vorhanden.
- Die Anzahl der Tage (n), bis wir Phase 2 ausführen.
Wir versuchen, dasselbe Upgrade ein paar weitere Male auszuführen, falls ein Upgrade aus Gründen der Infrastruktur fehlgeschlagen ist. Nach n Tagen ab dem Sendedatum der E-Mail fahren wir mit Phase 2 fort.
Wenn die Clusterintegritätsrichtlinien erfüllt sind, wird das Upgrade als erfolgreich betrachtet und als abgeschlossen markiert. Diese Situation kann während des anfänglichen Upgrades oder während einer der Wiederholungen des Upgrades in dieser Phase erfolgen. Es gibt keine E-Mail-Bestätigung für eine erfolgreiche Ausführung, um das Senden übermäßiger E-Mails zu vermeiden. Der Empfang einer E-Mail weist auf eine Ausnahme beim normalen Betrieb hin. Wir erwarten, dass die meisten Clusterupgrades ohne Beeinträchtigung der Verfügbarkeit der Anwendung funktionieren.
Phase 2: Ein Upgrade erfolgt unter ausschließlicher Einhaltung der Standardintegritätsrichtlinien.
Die Integritätsrichtlinien werden in dieser Phase so festgelegt, dass die Anzahl der Anwendungen, die am Anfang des Upgrades fehlerfrei waren, diesen Status während des Upgradeprozesses beibehalten. Wie in Phase 1 erfolgen in Phase 2 die Upgrades nacheinander in den einzelnen Upgradedomänen. Die Anwendungen, die im Cluster ausgeführt wurden, werden ohne Ausfallzeit fortgesetzt. Bei dem Upgrade werden die Clusterintegritätsrichtlinien (eine Kombination aus Knotenintegrität und Integrität aller im Cluster ausgeführten Anwendungen) berücksichtigt.
Wenn die Integritätsrichtlinien des Clusters tatsächlich nicht erfüllt sind, wird das Upgrade zurückgesetzt. Anschließend wird eine E-Mail an den Besitzer des Abonnements gesendet. Die E-Mail enthält folgende Informationen:
- Benachrichtigung, dass wir ein Clusterupgrade zurücksetzen mussten.
- Vorgeschlagene Abhilfemaßnahmen, falls vorhanden.
- Die Anzahl der Tage (n), bis wir Phase 3 ausführen werden.
Wir versuchen, dasselbe Upgrade ein paar weitere Male auszuführen, falls ein Upgrade aus Gründen der Infrastruktur fehlgeschlagen ist. Mehrere Tage vor Ablauf von „n“ Tagen wird eine Erinnerungs-E-Mail gesendet. Nach „n“ Tagen ab dem Sendedatum der E-Mail fahren wir mit Phase 3 fort. Die E-Mails, die wir Ihnen in Phase 2 senden, müssen ernst genommen werden und Abhilfemaßnahmen müssen erfolgen.
Wenn die Clusterintegritätsrichtlinien erfüllt sind, wird das Upgrade als erfolgreich betrachtet und als abgeschlossen markiert. Dies kann in dieser Phase während des anfänglichen Upgrades oder während einer der Wiederholungen des Upgrades erfolgen. Bei einer erfolgreichen Ausführung gibt es keine Bestätigung per E-Mail.
Phase 3: Ein Upgrade erfolgt unter Einhaltung aggressiver Integritätsrichtlinien.
Diese Integritätsrichtlinien in dieser Phase zielen auf die Vervollständigung des Upgrades und nicht auf die Integrität der Anwendungen ab. Nur sehr wenige Clusterupgrades gelangen in diese Phase. Wenn Ihr Cluster in diese Phase gelangt, besteht eine hohe Wahrscheinlichkeit, dass Ihre Anwendung instabil wird und/oder Verfügbarkeit einbüßt.
Ähnlich wie in den beiden anderen Phasen erfolgen Upgrades in Phase 3 nacheinander in den einzelnen Upgradedomänen.
Wenn die Integritätsrichtlinien des Clusters nicht erfüllt sind, wird das Upgrade zurückgesetzt. Wir versuchen, dasselbe Upgrade ein paar weitere Male auszuführen, falls ein Upgrade aus Gründen der Infrastruktur fehlgeschlagen ist. Danach wird der Cluster fixiert, sodass er keine weitere Unterstützung und/oder Upgrades empfängt.
Eine E-Mail mit diesen Informationen und den Abhilfemaßnahmen wird an den Besitzer des Abonnements gesendet. Wir erwarten nicht, dass Cluster in einen Status gelangen, der die Folge des Misslingens von Phase 3 ist.
Wenn die Clusterintegritätsrichtlinien erfüllt sind, wird das Upgrade als erfolgreich betrachtet und als abgeschlossen markiert. Dies kann in dieser Phase während des anfänglichen Upgrades oder während einer der Wiederholungen des Upgrades erfolgen. Bei einer erfolgreichen Ausführung gibt es keine Bestätigung per E-Mail.
Benutzerdefinierte Richtlinien für manuelle Upgrades
Sie können benutzerdefinierte Richtlinien für manuelle Clusterupgrades angeben. Diese Richtlinien werden jedes Mal angewendet, wenn Sie eine neue Runtime-Version auswählen, wodurch im System der Start des Upgrade Ihres Clusters ausgelöst wird. Wenn Sie die Richtlinien nicht überschreiben, werden die Standardwerte verwendet. Weitere Informationen finden Sie unter Festlegen benutzerdefinierter Richtlinien für manuelle Upgrades.
Andere Clusterupdates
Neben Upgrades der Laufzeit gibt es eine Reihe von Aktionen, die Sie möglicherweise ausführen müssen, um Ihren Cluster auf dem neuesten Stand zu halten, einschließlich der folgenden:
Verwalten von Zertifikaten
Service Fabric verwendet X.509-Serverzertifikate, die Sie beim Erstellen eines Clusters angeben, um eine sichere Kommunikation zwischen Clusterknoten und authentifizierten Clients zu schaffen. Sie können Zertifikate für Cluster und Client im Azure-Portal oder über die PowerShell bzw. Azure-Befehlszeilenschnittstelle (CLI) hinzufügen, aktualisieren oder löschen. Weitere Informationen finden Sie unter Hinzufügen oder Entfernen von Zertifikaten.
Öffnen von Anwendungsports
Sie können Anwendungsports ändern, indem Sie die dem Knotentyp zugeordneten Ressourceneigenschaften des Load Balancers ändern. Hierfür können Sie das Azure-Portal, die PowerShell oder die Azure-Befehlszeilenschnittstelle verwenden. Weitere Informationen finden Sie unter Öffnen von Anwendungsports für einen Cluster.
Definieren von Knoteneigenschaften
Manchmal möchten Sie sicherstellen, dass bestimmte Workloads nur auf bestimmten Knotentypen im Cluster ausgeführt werden. Für einige Workloads sind beispielsweise GPUs oder SSDs erforderlich, für andere hingegen nicht. Für jeden der Knotentypen in einem Cluster können Sie den Clusterknoten benutzerdefinierte Knoteneigenschaften hinzufügen. Platzierungseinschränkungen sind die Anweisungen, die an einzelne Dienste angefügt sind und eine oder mehrere Knoteneigenschaften auswählen. Platzierungseinschränkungen definieren, an welcher Stelle Dienste ausgeführt werden sollen.
Ausführliche Informationen zur Verwendung von Platzierungseinschränkungen, Knoteneigenschaften und deren Definition finden Sie unter Knoteneigenschaften und Platzierungseinschränkungen.
Hinzufügen von Kapazitätsmetriken
Für die einzelnen Knotentypen können Sie benutzerdefinierte Kapazitätsmetriken hinzufügen, die Sie in Ihrer Anwendung zum Melden der Auslastung verwenden möchten. Ausführliche Informationen zur Verwendung von Kapazitätsmetriken zum Melden der Auslastung finden Sie in den Dokumenten zum Clusterressourcen-Manager von Service Fabric unter Beschreiben Ihres Clusters und Metriken und Auslastung.
Anpassen von Einstellungen für Ihren Cluster
Viele verschiedene Konfigurationseinstellungen wie Zuverlässigkeitsstufe des Clusters und Knoteneigenschaften können in einem Cluster angepasst werden. Weitere Informationen finden Sie unter Anpassen von Service Fabric-Clustereinstellungen.
Hinweis
Wenn Sie NTLM-Einstellungen für den FileStoreService geändert haben oder ändern werden, sollten Sie für Cluster mit Runtimeversionen vor 10.0CU6, 10.1CU5 und 9.1CU12 etwas Downtime erwarten, während die Knoten des Clusters neu gestartet werden. Dieser Neustart hängt mit der Bereinigung zusammen, die beim Upgradezyklus auftritt.
Dieses Verhalten wird ab 10.0CU6, 10.1CU5 und 9.1CU12 geändert, und es sollten keine Knotenneustarts auf Clustern auftreten, die diese Versionen oder neuere Versionen ausführen.
Weitere Informationen zur Service Fabric-Versionsverwaltung finden Sie auf der Versionsseite.
Aktualisieren von Betriebssystemimages für Clusterknoten
Die Aktivierung automatischer Upgrades von Betriebssystemimages für Ihre Service Fabric-Clusterknoten ist eine bewährte Methode. Zu diesem Zweck müssen mehrere Clusteranforderungen erfüllt und Schritte ausgeführt werden. Eine weitere Option ist die Verwendung der Patchorchestrierungsanwendung (POA), einer Service Fabric-Anwendung, mit der das Patchen des Betriebssystems in einem Service Fabric-Cluster ohne Ausfallzeiten automatisiert werden kann. Weitere Informationen zu diesen Optionen finden Sie unter Patchen des Windows-Betriebssystems in Ihrem Service Fabric-Cluster.
Nächste Schritte
- Verwalten von Service Fabric-Upgrades
- Anpassen Ihrer Service Fabric-Clustereinstellungen
- Ab- und Aufskalieren Ihres Clusters
- Machen Sie sich mit Anwendungsupgrades