Tutorial: Optimieren der Indizierung unter Verwendung der Push-API
Azure KI Search unterstützt zwei grundlegende Ansätze für das Importieren von Daten in einen Suchindex: Pushen Sie Ihre Daten programmgesteuert in den Index, oder pullen Sie die Daten, indem Sie einen Azure KI-Suche-Indexer auf eine unterstützte Datenquelle verweisen.
In diesem Tutorial erfahren Sie, wie Sie Daten effizient mithilfe des Pushmodells indizieren, indem Sie Anforderungen zu einem Batch zusammenfassen und eine Wiederholungsstrategie mit exponentiellem Backoff verwenden. Sie können die Beispielanwendung herunterladen und ausführen. In diesem Artikel werden die zentralen Aspekte der Anwendung sowie Faktoren erläutert, die beim Indizieren von Daten zu berücksichtigen sind.
In diesem Tutorial werden C# und die Azure.Search.Documents-Bibliothek aus dem Azure SDK für .NET verwendet, um die folgenden Aufgaben auszuführen:
- Erstellen eines Index
- Testen verschiedener Batchgrößen, um die effizienteste Größe zu ermitteln
- Asynchrones Indizieren von Batches
- Erhöhen der Indizierungsgeschwindigkeit durch Verwendung mehrerer Threads
- Verwenden einer Wiederholungsstrategie mit exponentiellem Backoff, um die Indizierung für nicht erfolgreiche Dokumente zu wiederholen
Voraussetzungen
Für dieses Tutorial sind folgende Dienste und Tools erforderlich:
Ein Azure-Abonnement. Wenn Sie noch nicht über eines verfügen, können Sie ein kostenloses Konto erstellen.
Visual Studio (beliebige Edition). Der Beispielcode und die Anleitung wurden in der kostenlosen Community-Edition getestet.
Herunterladen von Dateien
Der Quellcode für dieses Tutorial befindet sich im Ordner optimize-data-indexing/v11 im GitHub-Repository Azure-Samples/azure-search-dotnet-scale.
Wichtige Aspekte
Faktoren, die sich auf die Indizierungsgeschwindigkeit auswirken, werden als Nächstes aufgeführt. Weitere Informationen finden Sie unter Indexieren großer Datasets.
- Dienstebene und Anzahl von Partitionen/Replikaten: Das Hinzufügen von Partitionen oder das Upgraden Ihrer Ebene erhöht die Indizierungsgeschwindigkeit.
- Komplexität des Indexschemas: Das Hinzufügen von Feldern und Feldeigenschaften verringert die Indizierungsgeschwindigkeit. Kleinere Indizes werden schneller indiziert.
- Batchgröße: Die optimale Batchgröße hängt von Ihrem Indexschema und Dataset ab.
- Anzahl von Threads/Workern: Ein einzelner Thread nutzt nicht die volle Indizierungsgeschwindigkeit.
- Wiederholungsstrategie: Eine Wiederholungsstrategie mit exponentielle Backoff ist eine bewährte Methode für eine optimale Indizierung.
- Datenübertragungsgeschwindigkeit im Netzwerk: Die Datenübertragungsgeschwindigkeit kann ein limitierender Faktor sein. Indizieren Sie Daten innerhalb Ihrer Azure-Umgebung, um die Datenübertragungsgeschwindigkeit zu erhöhen.
Schritt 1: Erstellen eines Azure KI-Suche-Diensts
Um dieses Tutorial abzuschließen, benötigen Sie einen Azure KI-Suche-Dienst, den Sie im Azure-Portal erstellen, oder suchen Sie einen vorhandenen Dienst unter Ihrem aktuellen Abonnement. Es empfiehlt sich, den gleichen Tarif zu verwenden, den Sie auch in Ihrer Produktionsumgebung verwenden möchten, um die Indizierungsgeschwindigkeit genau testen und optimieren zu können.
Abrufen eines Administratorschlüssels und einer URL für Azure KI-Suche
In diesem Tutorial wird die schlüsselbasierte Authentifizierung verwendet. Kopieren Sie einen Administrator-API-Schlüssel, um ihn in die Datei appsettings.json einzufügen.
Melden Sie sich beim Azure-Portal an. Rufen Sie die Endpunkt-URL von der Seite Übersicht Ihres Suchdiensts ab. Ein Beispiel für einen Endpunkt ist
https://mydemo.search.windows.net.Rufen Sie unter Einstellungen>Schlüssel einen Administratorschlüssel ab, um Vollzugriff auf den Dienst zu erhalten. Es gibt zwei austauschbare Administratorschlüssel – diese wurden zum Zweck der Geschäftskontinuität bereitgestellt, falls Sie einen Rollover für einen Schlüssel durchführen müssen. Für Anforderungen zum Hinzufügen, Ändern und Löschen von Objekten können Sie den primären oder den sekundären Schlüssel verwenden.
Schritt 2: Einrichten Ihrer Umgebung
Starten Sie Visual Studio, und öffnen Sie OptimizeDataIndexing.sln.
Öffnen Sie im Projektmappen-Explorer die Datei appsettings.json, um Verbindungsinformationen Ihres Diensts anzugeben.
{
"SearchServiceUri": "https://{service-name}.search.windows.net",
"SearchServiceAdminApiKey": "",
"SearchIndexName": "optimize-indexing"
}
Schritt 3: Erkunden des Codes
Nach der Aktualisierung von appsettings.json kann das Programm in OptimizeDataIndexing.sln erstellt und ausgeführt werden.
Dieser Code wird aus dem C#-Abschnitt von Schnellstart: Volltextsuche mithilfe der Azure SDKs abgeleitet. Der Artikel enthält ausführlichere Informationen zu den Grundlagen im Zusammenhang mit der Verwendung des .NET SDK.
Diese einfache C#/.NET-Konsolen-App führt folgende Aufgaben aus:
- Dies erstellt einen neuen Index basierend auf der Datenstruktur der C#-Klasse
Hotel(die auch auf die KlasseAddressverweist) - Sie testet verschiedene Batchgrößen, um die effizienteste Größe zu ermitteln.
- Sie indiziert Daten asynchron:
- Unter Verwendung mehrerer Threads zur Erhöhung der Indizierungsgeschwindigkeit
- Unter Verwendung einer Wiederholungsstrategie mit exponentiellem Backoff, um die Indizierung für nicht erfolgreiche Elemente zu wiederholen
Nehmen Sie sich vor dem Ausführen des Programms etwas Zeit, um sich den Code sowie die Indexdefinitionen für dieses Beispiel etwas genauer anzusehen. Der relevante Code befindet sich in verschiedenen Dateien:
- Hotel.cs und Address.cs enthalten das Schema, das den Index definiert
- DataGenerator.cs enthält eine einfache Klasse, um die Erstellung großer Mengen an Hoteldaten zu vereinfachen.
- ExponentialBackoff.cs enthält Code zur Optimierung des Indizierungsprozesses, wie in diesem Artikel beschrieben
- Program.cs enthält Funktionen zum Erstellen und Löschen des Azure KI Search-Index, zum Indizieren von Datenbatches sowie zum Testen verschiedener Batchgrößen.
Erstellen des Index
In diesem Beispielprogramm wird das Azure SDK für .NET verwendet, um einen Azure KI Search-Index zu definieren und zu erstellen. Das SDK nutzt die Klasse FieldBuilder, um eine Indexstruktur auf der Grundlage einer C#-Datenmodellklasse zu generieren.
Das Datenmodell wird durch die Klasse Hotel definiert, die auch Verweise auf die Klasse Address enthält. „FieldBuilder“ führt ein Drilldown durch die verschiedenen Klassendefinitionen aus, um eine komplexe Datenstruktur für den Index zu generieren. Mithilfe von Metadatentags werden die Attribute der einzelnen Felder definiert, um beispielsweise anzugeben, ob das Feld durchsuchbar oder sortierbar ist.
Die folgenden Codeausschnitte aus der Datei Hotel.cs zeigen, wie ein einzelnes Feld und ein Verweis auf eine andere Datenmodellklasse angegeben werden können.
. . .
[SearchableField(IsSortable = true)]
public string HotelName { get; set; }
. . .
public Address Address { get; set; }
. . .
In der Datei Program.cs wird der Index mit einem Namen und einer Feldsammlung definiert, die durch die Methode FieldBuilder.Build(typeof(Hotel)) generiert wird, und anschließend erstellt:
private static async Task CreateIndexAsync(string indexName, SearchIndexClient indexClient)
{
// Create a new search index structure that matches the properties of the Hotel class.
// The Address class is referenced from the Hotel class. The FieldBuilder
// will enumerate these to create a complex data structure for the index.
FieldBuilder builder = new FieldBuilder();
var definition = new SearchIndex(indexName, builder.Build(typeof(Hotel)));
await indexClient.CreateIndexAsync(definition);
}
Daten generieren
In der Datei DataGenerator.cs wird eine einfache Klasse implementiert, um Testdaten zu generieren. Der einzige Zweck dieser Klasse besteht darin, die Generierung einer großen Anzahl von Dokumenten mit einer eindeutigen ID für die Indizierung zu vereinfachen.
Durch Ausführen der folgenden Codezeilen können Sie eine Liste mit 100.000 Hotels mit jeweils eindeutiger ID generieren:
long numDocuments = 100000;
DataGenerator dg = new DataGenerator();
List<Hotel> hotels = dg.GetHotels(numDocuments, "large");
Zu Testzwecken stehen in diesem Beispiel zwei Hotelgrößen zur Verfügung: small (klein) und large (groß).
Das Schema Ihres Indexes wirkt sich auf die Indizierungsgeschwindigkeit aus. Aus diesem Grund ist es sinnvoll, diese Klasse zu konvertieren, um Daten zu generieren, die am besten mit Ihrem beabsichtigten Indexschema übereinstimmen, nachdem Sie dieses Tutorial durchlaufen haben.
Schritt 4: Testen von Batchgrößen
Azure KI Search unterstützt folgende APIs, um einzelne oder mehrere Dokumente in einen Index zu laden:
Das Indizieren von Dokumenten in Batches verbessert die Indizierungsleistung erheblich. Diese Batches können bis zu 1000 Dokumente oder bis zu etwa 16 MB pro Batch umfassen.
Die Bestimmung der optimalen Batchgröße für Ihre Daten ist ein wichtiger Faktor bei der Optimierung der Indizierungsgeschwindigkeit. Die optimale Batchgröße wird hauptsächlich durch die beiden folgenden Faktoren beeinflusst:
- Indexschema
- Datengröße
Da die optimale Batchgröße von Ihrem Index und von Ihren Daten abhängt, empfiehlt es sich, durch Testen verschiedener Batchgrößen zu ermitteln, bei welcher Größe die Indizierung für Ihr Szenario am schnellsten ist.
Die folgende Funktion veranschaulicht einen einfachen Ansatz zum Testen von Batchgrößen:
public static async Task TestBatchSizesAsync(SearchClient searchClient, int min = 100, int max = 1000, int step = 100, int numTries = 3)
{
DataGenerator dg = new DataGenerator();
Console.WriteLine("Batch Size \t Size in MB \t MB / Doc \t Time (ms) \t MB / Second");
for (int numDocs = min; numDocs <= max; numDocs += step)
{
List<TimeSpan> durations = new List<TimeSpan>();
double sizeInMb = 0.0;
for (int x = 0; x < numTries; x++)
{
List<Hotel> hotels = dg.GetHotels(numDocs, "large");
DateTime startTime = DateTime.Now;
await UploadDocumentsAsync(searchClient, hotels).ConfigureAwait(false);
DateTime endTime = DateTime.Now;
durations.Add(endTime - startTime);
sizeInMb = EstimateObjectSize(hotels);
}
var avgDuration = durations.Average(timeSpan => timeSpan.TotalMilliseconds);
var avgDurationInSeconds = avgDuration / 1000;
var mbPerSecond = sizeInMb / avgDurationInSeconds;
Console.WriteLine("{0} \t\t {1} \t\t {2} \t\t {3} \t {4}", numDocs, Math.Round(sizeInMb, 3), Math.Round(sizeInMb / numDocs, 3), Math.Round(avgDuration, 3), Math.Round(mbPerSecond, 3));
// Pausing 2 seconds to let the search service catch its breath
Thread.Sleep(2000);
}
Console.WriteLine();
}
Da nicht alle Dokumente die gleiche Größe haben (auch wenn dies in diesem Beispiel der Fall ist), schätzen wir die Größe der Daten, die wir an den Suchdienst senden. Dazu können Sie die folgende Funktion verwenden, die das Objekt zuerst in JSON konvertiert und dann seine Größe in Byte bestimmt. Dadurch können wir die effizientesten Batchgrößen im Hinblick auf die Indizierungsgeschwindigkeit (MB/s) ermitteln.
// Returns size of object in MB
public static double EstimateObjectSize(object data)
{
// converting object to byte[] to determine the size of the data
BinaryFormatter bf = new BinaryFormatter();
MemoryStream ms = new MemoryStream();
byte[] Array;
// converting data to json for more accurate sizing
var json = JsonSerializer.Serialize(data);
bf.Serialize(ms, json);
Array = ms.ToArray();
// converting from bytes to megabytes
double sizeInMb = (double)Array.Length / 1000000;
return sizeInMb;
}
Für die Funktion sind ein Element vom Typ SearchClient sowie die Anzahl von Versuchen erforderlich, die für die einzelnen Batchgrößen getestet werden sollen. Da die Indizierungszeiten bei den einzelnen Batches variieren können, testen Sie jeden Batch standardmäßig dreimal, um die Ergebnisse statistisch relevanter zu machen.
await TestBatchSizesAsync(searchClient, numTries: 3);
Wenn Sie die Funktion ausführen, sollte eine Ausgabe auf Ihrer Konsole wie im folgenden Beispiel angezeigt werden:
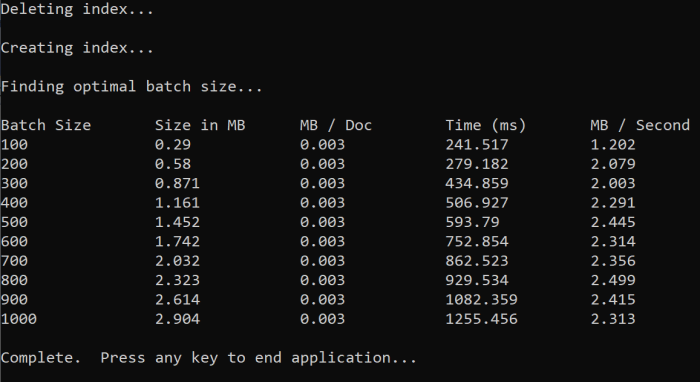
Ermitteln Sie, welche Batchgröße am effizientesten ist, und verwenden Sie sie im nächsten Schritt des Tutorials. Unter Umständen ist bei verschiedenen Batchgrößen eine Stabilisierung auf einem bestimmten Niveau in MB/s zu beobachten.
Schritt 5: Indizierung der Daten
Nachdem Sie nun die zu verwendenden Batchgröße identifiziert haben, die Sie verwenden wollen, besteht der nächste Schritt darin, mit der Indizierung der Daten zu beginnen. In diesem Beispiel werden folgende Schritte unternommen, um Daten effizient zu indizieren:
- verwendet mehrere Threads/Worker
- implementiert eine Wiederholungsstrategie mit exponentiellem Backoff
Heben Sie die Auskommentierung der Zeilen 41 bis 49 auf, und führen Sie dann das Programm erneut aus. Bei dieser Ausführung generiert und sendet das Beispiel Batches von Dokumenten, bis zu 100.000, wenn Sie den Code ausführen, ohne die Parameter zu ändern.
Verwenden mehrerer Threads/Worker
Zur bestmöglichen Nutzung der Indizierungsgeschwindigkeit von Azure KI Search müssen Sie Threads verwenden, um Batchindizierungsanforderungen gleichzeitig an den Dienst zu senden.
Einige der oben erwähnten wichtigsten Aspekte können sich auf die optimale Anzahl von Threads auswirken. Sie können dieses Beispiel ändern und mit einer anderen Threadanzahl testen, um die optimale Threadanzahl für Ihr Szenario zu ermitteln. Solange Sie jedoch mehrere parallel ausgeführte Threads verwenden, sollten von einem Großteil der Effizienzsteigerungen profitieren.
Im Zuge der Erhöhung der Anforderungen für den Suchdienst werden möglicherweise HTTP-Statuscodes mit dem Hinweis zurückgegeben, dass die Anforderung nicht vollständig erfolgreich war. Zwei gängige HTTP-Statuscodes im Zusammenhang mit der Indizierung sind:
- 503 Dienst nicht verfügbar: Dieser Fehler bedeutet, dass die Auslastung des Systems sehr hoch ist und Ihre Anforderung aktuell nicht verarbeitet werden kann.
- 207 Multi-Status: Dieser Fehler bedeutet, dass der Vorgang für einige Dokumente erfolgreich war, bei mindestens einem Dokument aber ein Fehler aufgetreten ist.
Implementieren einer Wiederholungsstrategie mit exponentiellem Backoff
Im Falle eines Fehlers sollten Anforderungen unter Verwendung einer Wiederholungsstrategie mit exponentiellem Backoff wiederholt werden.
Anforderungen mit Fehlern vom Typ 503 und andere fehlgeschlagene Anforderungen werden vom .NET SDK von Azure KI Search automatisch wiederholt. Für die Wiederholung von Anforderungen mit Fehlern vom Typ 207 sollten Sie allerdings eine eigene Logik implementieren. Open-Source-Tools wie Polly können in einer Wiederholungsstrategie nützlich sein.
In diesem Beispiel wird eine eigene Wiederholungsstrategie mit exponentiellem Backoff implementiert. Hierzu werden zunächst einige Variablen definiert, unter anderem maxRetryAttempts und die anfängliche delay bei einer nicht erfolgreichen Anforderung:
// Create batch of documents for indexing
var batch = IndexDocumentsBatch.Upload(hotels);
// Create an object to hold the result
IndexDocumentsResult result = null;
// Define parameters for exponential backoff
int attempts = 0;
TimeSpan delay = delay = TimeSpan.FromSeconds(2);
int maxRetryAttempts = 5;
Die Ergebnisse des Indizierungsvorgangs werden in der Variable IndexDocumentResult result gespeichert. Diese Variable ist wichtig, weil Sie mit ihr überprüfen können, ob bei einigen Dokumenten im Batch Fehler aufgetreten sind, wie im folgenden Beispiel gezeigt. Bei partiellen Fehlern wird anhand der IDs der fehlerhaften Dokumente ein neues Batch erstellt.
RequestFailedException-Ausnahmen sollten ebenfalls abgefangen werden, weil sie darauf hindeuten, dass die gesamte Anforderung nicht erfolgreich war.
// Implement exponential backoff
do
{
try
{
attempts++;
result = await searchClient.IndexDocumentsAsync(batch).ConfigureAwait(false);
var failedDocuments = result.Results.Where(r => r.Succeeded != true).ToList();
// handle partial failure
if (failedDocuments.Count > 0)
{
if (attempts == maxRetryAttempts)
{
Console.WriteLine("[MAX RETRIES HIT] - Giving up on the batch starting at {0}", id);
break;
}
else
{
Console.WriteLine("[Batch starting at doc {0} had partial failure]", id);
Console.WriteLine("[Retrying {0} failed documents] \n", failedDocuments.Count);
// creating a batch of failed documents to retry
var failedDocumentKeys = failedDocuments.Select(doc => doc.Key).ToList();
hotels = hotels.Where(h => failedDocumentKeys.Contains(h.HotelId)).ToList();
batch = IndexDocumentsBatch.Upload(hotels);
Task.Delay(delay).Wait();
delay = delay * 2;
continue;
}
}
return result;
}
catch (RequestFailedException ex)
{
Console.WriteLine("[Batch starting at doc {0} failed]", id);
Console.WriteLine("[Retrying entire batch] \n");
if (attempts == maxRetryAttempts)
{
Console.WriteLine("[MAX RETRIES HIT] - Giving up on the batch starting at {0}", id);
break;
}
Task.Delay(delay).Wait();
delay = delay * 2;
}
} while (true);
Schließen Sie von hier aus den Code für das exponentielle Backoff in eine Funktion ein, damit er mühelos aufgerufen werden kann.
Anschließend wird eine weitere Funktion erstellt, um die aktiven Threads zu verwalten. Der Einfachheit halber ist diese Funktion hier nicht enthalten. Sie finden sie aber in ExponentialBackoff.cs. Die Funktion kann mit dem folgenden Befehl aufgerufen werden. hotels sind hierbei die Daten, die wir hochladen möchten, 1000 ist die Batchgröße, und 8 ist die Anzahl paralleler Threads:
await ExponentialBackoff.IndexData(indexClient, hotels, 1000, 8);
Wenn Sie die Funktion ausführen, sollten Sie eine Ausgabe sehen:
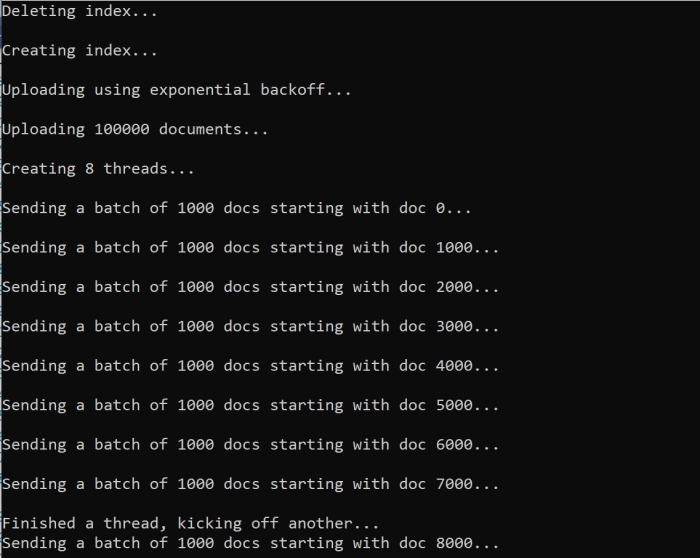
Sollte bei einem Batch von Dokumenten ein Fehler auftreten, wird eine Ausgabe zurückgegeben, die den Fehler sowie die Information enthält, dass der Batch wiederholt wird:
[Batch starting at doc 6000 had partial failure]
[Retrying 560 failed documents]
Nach Abschluss der Funktionsausführung können Sie überprüfen, ob dem Index alle Dokumente hinzugefügt wurden.
Schritt 6: Erkunden des Indexes
Nach Ausführung des Programms können Sie den aufgefüllten Suchindex programmgesteuert oder über den Suchexplorer im Azure-Portal erkunden.
Programmgesteuert
Bei der Überprüfung der Dokumentanzahl in einem Index stehen Ihnen hauptsächlich zwei Optionen zur Verfügung: die API zum Zählen der Dokumente und die API zum Abrufen der Indexstatistik. Beide Pfade erfordern Zeit zum Verarbeiten, sodass Sie sich keine Sorgen machen müssen, wenn die Anzahl der zurückgegebenen Dokumente anfänglich niedriger ist als erwartet.
Dokumentenanzahl
Mit dem Vorgang zum Zählen von Dokumenten wird die Anzahl der in einem Suchindex enthaltenen Dokumente abgerufen:
long indexDocCount = await searchClient.GetDocumentCountAsync();
Indexstatistiken abrufen
Mit dem Vorgang zum Abrufen der Indexstatistik werden Informationen zur Dokumentanzahl für den aktuellen Index sowie zur Speichernutzung zurückgegeben. Die Aktualisierung der Indexstatistik dauert länger als die Aktualisierung der Dokumentanzahl.
var indexStats = await indexClient.GetIndexStatisticsAsync(indexName);
Azure-Portal
Suchen Sie im Azure-Portal über den linken Navigationsbereich den Index optimize-indexing in der Liste Indizes.

Dokumentanzahl und Speichergröße basieren auf der API zum Abrufen der Indexstatistik, und die Aktualisierung kann mehrere Minuten dauern.
Zurücksetzen und erneut ausführen
In den frühen experimentellen Phasen der Entwicklung ist es am praktischsten, die Objekt aus Azure KI-Suche zu löschen und sie durch Ihren Code neu zu erstellen. Ressourcennamen sind eindeutig. Wenn Sie ein Objekt löschen, können Sie es unter dem gleichen Namen neu erstellen.
Im Beispielcode dieses Tutorials wird eine Überprüfung auf bereits vorhandene Indizes durchgeführt. Diese werden gelöscht, damit Sie Ihren Code erneut ausführen können.
Die Indizes können auch über das Azure-Portal gelöscht werden.
Bereinigen von Ressourcen
Wenn Sie in Ihrem eigenen Abonnement arbeiten, ist es ratsam, nach Abschluss eines Projekts die nicht mehr benötigten Ressourcen zu entfernen. Ressourcen, die weiterhin ausgeführt werden, können Sie Geld kosten. Sie können einzelne Ressourcen oder die gesamte Ressourcengruppe mit allen darin enthaltenen Ressourcen löschen.
Sie können Ressourcen im Azure-Portal über den Link Alle Ressourcen oder Ressourcengruppen im linken Navigationsbereich suchen und verwalten.
Nächster Schritt
Weitere Informationen zum Indizieren großer Datenmengen finden Sie im folgenden Tutorial.